如果需要对检测器获取的关键点做分类的话,还需要了解特征工程相关算法,这也是为什么博主把该算法放到关键点检测专栏。本篇文章会把KNN相关的绝大部分内容过一遍,直接开始吧。
什么是KNN?
- 根据你相邻的K个对象的类别,推断出你的类别。
- 之所以会用到KNN,是因为其伟大且渺小。虽然算法简单,但精确度真的很高。
算法具体原理
- 第一步:计算距离(欧氏距离或马氏距离),确定待分类的点的每一个特征与其他点的每一个特征的距离。将所有特征的距离相加再开方。距离公式如下:
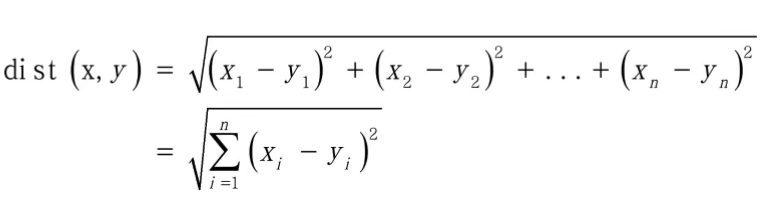
- 第二步:按照距离升序排列。距离最近的排在前面,距离最远的排在后面。
- 第三步:取前K个距离最近的点,计算加权距离。之所以计算加权距离是因为比如前三个点离待分类点特别近,那么理应赋予更高的权重。但比如前五个点的后两个点,虽然也在前五,但是和待分类点的距离并不接近,因此需要赋予一个更低的权重。如果直接做算数平均那就跑偏了,距离也就没用参考价值了。
K的选取
- 太大:导致分类模糊。因为如果K过于接近整个数据集的个数,那么无论怎么分都是整个数据集的状态,导致任何数据进来都是相同的类。
- 太小:容易受到个例影响,波动较大。
- 那么如何选取呢,有两个方法:
- 经验法。也就是试一试。随便选一个K,跑一跑数据看看结果,接着不断向精度更高的方向微调K的值。
- 均方根误差。
代码实现 (数据集:提取码:bzlz)
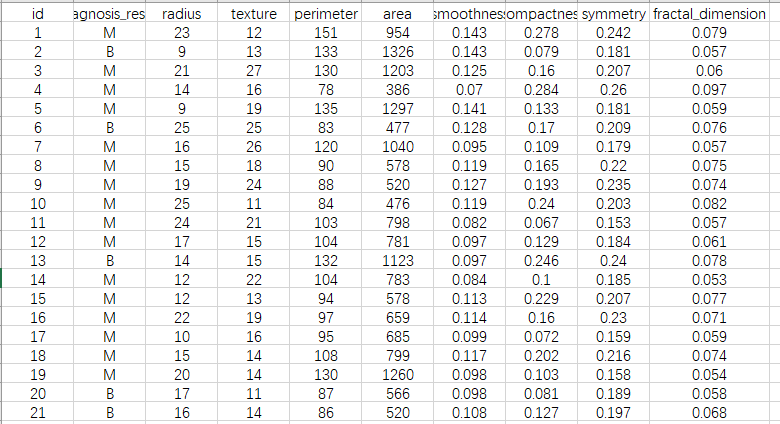
- 不用官方的代码:
import csv
import random
# 读取
with open(r"J:\KNN源码及数据集\prostate-cancer\Prostate_Cancer.csv") as file:
reader = csv.DictReader(file)
datas = [row for row in reader]
random.shuffle(datas) # 打乱数据的顺序
# 分组
n = len(datas) // 3
test_set = datas[0:n] # 测试集
train_set = datas[n:] # 训练集
# KNN
# 将传入单个字典
def distance(d1, d2): # 求距离
res = 0
for key in ("radius", "texture", "perimeter",
"area", "smoothness", "compactness", "symmetry", "fractal_dimension"):
res += (float(d1[key]) - float(d2[key])) ** 2
return res ** 0.5
k = 6 # K取几
# 将传入单个字典
def knn(data):
res = [
{"result": train["diagnosis_result"], "distance": distance(data, train)} # 1.距离
for train in train_set
]
sorted(res, key=lambda item: item['distance']) # 2.排序-----升序
# 取前K个值
res2 = res[0:k]
# 加权平均(result是最终判据)
result = {'B': 0, 'M': 0}
# 总长度
sum_dist = 0
for r1 in res2:
sum_dist += r1['distance']
# 逐个分类加和
for r2 in res2:
result[r2["result"]] += 1 - r2["distance"] / sum_dist # 1 - r2["distance"] / sum_dist就是权重
print(result)
if result['B'] > result['M']:
return 'B'
else:
return 'M'
# ----------------------------测试阶段(判断准确率)------------------------------------------#
correct = 0
for test in test_set:
result = test['diagnosis_result'] # 真实结果
result2 = knn(test) # 测试结果
if result == result2:
correct = correct + 1;
print(str(correct / len(test_set)))
- 用官方的代码:
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
import random
import pandas as pd
def knn():
K = 8
data=pd.read_csv(r"Prostate_Cancer.csv")
n = len(data) // 3
test_set = data[0:n]
train_set = data[n:]
train_set = np.array(train_set)
test_set = np.array(test_set)
A = [i for i in range(0, len(train_set))]
B = [i for i in range(2, 10)]
C = [i for i in range(n)]
D = [1]
x_train = train_set[A]
x_train = x_train[:, B]
y_train = train_set[A]
y_train = y_train[:, D]
x_test = test_set[C]
x_test = x_test[:, B]
y_test = test_set[C]
y_test = y_test[:, D]
# 训练模型
model = KNeighborsClassifier(n_neighbors=K)
model.fit(x_train, y_train)
score = model.score(x_test, y_test)
print("准确率为:", score)
if __name__=='__main__':
knn()