队列的顺序实现是指分配一块连续的存储单元存放队列中的元素,并附设两个指针,队头指针 front 指向队头元素,队尾指针 rear 指向队尾元素的下一个位置,如图:

但这种存储方法容易造成 “假溢出”,即(d)所示,队列判定已满,但还有大量的空闲空间未使用,我们一般使用循环队列,如图:
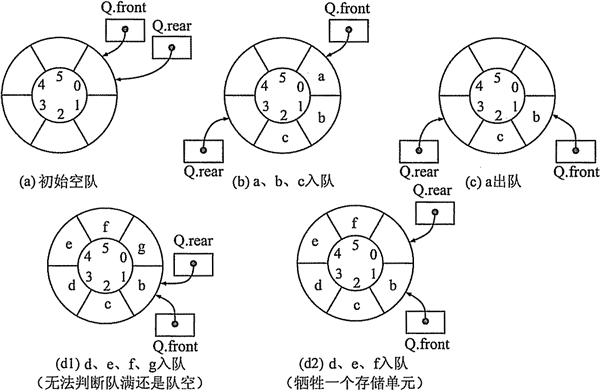
一、顺序存储(循环队列)
一、定义
typedef struct //循环队列
{
int data[MaxSize]; //存放队列元素
int front, rear; //队头指针和队尾指针
} SqQueue;二、初始化、队判空、入队、出队
//初始化
void InitQueue(SqQueue& Q){Q.rear = Q.front = 0;}
//队判空
bool isEmpty(SqQueue Q){if (Q.rear == Q.front) return true;return false;}
//入队
bool EnQueue(SqQueue& Q, int x)
{
if ((Q.rear + 1) % MaxSize == Q.front) return false;
Q.data[Q.rear] = x;
Q.rear = (Q.rear + 1) % MaxSize;
return true;
}
//出队
bool DeQueue(SqQueue& Q, int& x)
{
if (Q.rear == Q.front) return false;
x = Q.data[Q.front];
Q.front = (Q.front + 1) % MaxSize;
return true;
}说明:
- 以上采取的方法是:牺牲一个存储单元来区分队空或者队满,入队时少用一个队列单元。
- 这样,队空仍然为:Q.front == Q.rear
- 队满的条件为:(Q.rear+1)%MaxSize == Q.front
- 队列中元素的个数为:(Q.rear-Q.front+MaxSize)%MaxSize
二、链式存储
一、定义
typedef struct LinkLNode //链式队列结点
{
int data;
struct LinkLNode* next;
} LinkLNode;
typedef struct //链式队列
{
LinkLNode *front, *rear; //队列的队头和队尾
} LinkQueue;二、初始化(带头节点)、判队空、入队、出队
//初始化(带头结点)
void InitQueue(LinkQueue& Q)
{
Q.front = Q.rear = (LinkLNode*)malloc(sizeof(LinkLNode));
Q.front->next = NULL;
}
//判队空
bool IsEmpty(LinkQueue Q)
{
if (Q.front == Q.rear) return true;
return false;
}
//入队
void EnQueue(LinkQueue& Q, int x)
{
LinkLNode* s = (LinkLNode*)malloc(sizeof(LinkLNode));
s->data = x;
Q.rear->next = s;
s->next = NULL;
Q.rear = s;
}
//出队
bool DeQueue(LinkQueue& Q, int& x)
{
if (Q.front == Q.rear) return false;
LinkLNode* p = Q.front->next;
x = p->data;
Q.front->next = p->next;
if (Q.rear == p) //若原队列中只有一个结点,删除后变空
Q.rear = Q.front;
free(p);
return true;
}用单链表表示的链式队列特别适合于数据元素变动比较大的情形,而且不存在队列满且产生溢出的问题。
另外,假如程序中要使用多个队列,与多个栈的情形一样,最好使用链式队列,这样就不会出现存储分配不合理和“溢出”的问题。