目录
引言
经过前面的学习我们了解到集合主要分为Collection集合和Map集合,经过前几篇文章的讲述,我们已经能够了解到Collection集合的使用以及各集合之间的不同之处。那么今天我们将要来学习集合中的另外一个集合体系——Map,相对Collection集合,该集合的内容相对来说要少一些,仅需要这一篇文章就可以了解的差不多了,所以大家既然都看到这了,就不要前功尽弃了,继续坚持下来吧!

概念
回想一下,前面为什么会把集合划分为两种呢?原因是因为Collection集合是单列集合,而Map集合是双列集合(又称为键值对集合),顾名思义就是每个数据中都存在两个值,一个是键(key),另一个则是值(value)。
Collection集合:[元素1,元素2,元素3,~~];
Map集合:{key1=value1,key2=value2,key3=value3,~~};
Map集合体系特点:
- Map集合的特点都是由键决定的
- Map集合的键是无序的,不重复的,无索引的,而值是可以重复的
- Map集合的键值对都可以为null
- Map集合重复的键所对应的值会将前面重复键的值覆盖掉
今天我们只对Map集合中常用的实现类作出讲解,其他在后续可以了解:
- HashMap:元素根据键是无序的,不重复的,无索引的,而值是可以重复的(与Map体系一致)
- LinkedHashMap:元素根据键是有序的,不重复的,无索引的,而值是可以重复的
- TreeMap:元素根据键是排序的,不重复的,无索引的,而值是可以重复的

Map集合实现类
HashMap
接下来我们通过一小段代码来了解该实现类具有哪些性质:
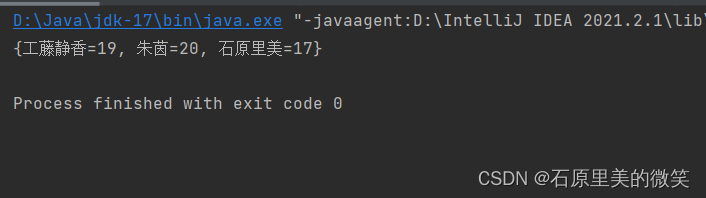
Map<String,Integer> map = new HashMap<>(); map.put("石原里美",18); map.put("工藤静香",19); map.put("朱茵",20); map.put("石原里美",17); System.out.println(map);首先,我们先来分析一下该集合是如何创建与输入数据的,其创建的方法与Collection集合基本类似,唯一不一样的地方在于泛型的个数,Map是两个,这也就体现出来了为什么Map集合是双列集合的原因了,而这两个泛型分别对应着键的数据类型、值的数据类型,通过调用put方法向集合中输入数据,前面的是键,后面的是值。
输出结果:
通过对输出结果的观察,我们能够分析出来该集合具有无序性, 并且在输入重复键时,会将之前的值覆盖掉,由此可得出其具有不重复性。
而在调用get()方法的时候,提示的是通过key来获取其对应的值value,并不是通过索引获取键值对。

LinkedHashMap
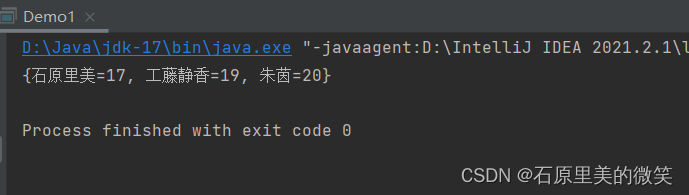
当我们将上面的代码作出更改,运行之后可以得到以下的结果:
Map<String,Integer> map = new LinkedHashMap<>();输出结果:
由此可得出其顺序和添加的顺序有关系,并没有被打乱。
TreeMap
TreeMap的性质和前面学习的TreeSet,都是会对数据进行排列的存储,既可以默认排序,也可以将键按规定的规则排序,不同的地方是TreeMap集合的排序是默认对键升序排列。
TreeMap集合定义排序规则有两种:
类实现Comparable接口,重写比较规则
集合自定义Comparator比较器对象,重写比较规则
默认排序
简单定义一个包含学生姓名和学号的map集合,通过这个集合,我们可以观察TreeMap集合的特点:
public static void main(String[] args) { Map<Integer,String > Students = new TreeMap<>(); Students.put(13,"乔治"); Students.put(11,"欧文"); Students.put(23,"乔丹"); Students.put(22,"阿尔瓦多"); Students.put(23,"詹姆斯"); System.out.println(Students); } //运行结果: {11=欧文, 13=乔治, 22=阿尔瓦多, 23=詹姆斯}通过对上述代码和实验结果的观察,我们可以得知其性质:默认对键进行排序(从小到大),遇到重复的键,后者的值会将前者覆盖,而且同样是不可以使用索引的。
自定义排序方式
定义一个包含员工类和员工职位的map集合,通过这个集合我们可以依次观察两种改变TreeMap集合的排序方式是如何实现的:
当我们向TreeMap集合存储对象元素的时候,若不为其指定该以何种方式进行排序的话,编译器将会发生报错,报错原因则是编译器并不清楚该根据员工类中的哪个数据进行比较,由此便引出了两种方式解决该问题:
类实现Comparable接口:
Employer类: public class Employer implements Comparable<Employer>{ private String name; private int salary; @Override public int compareTo(Employer o) { return o.getSalary()-this.getSalary(); } //其他代码就不在此过多赘述,仅展示有用的代码。在原来的Employer基础上,使其实现Comparable接口,并且重写compareTo方法,定义一种排序方式即可。
Map<Employer,String > employer = new TreeMap<>(); employer.put(new Employer("张三",1000),"Java程序员"); employer.put(new Employer("李四",10000),"python程序员"); employer.put(new Employer("王五",3000),"清洁工"); System.out.println(employer); //实验结果: {[李四'10000]=python程序员, [王五'3000]=清洁工, [张三'1000]=Java程序员}集合自定义Comparator比较器对象:
第二种方法则是在Employer类不变的情况下,实现对TreeMap集合中定义Comparator比较器对象,重新再定义一种排序方式
Map<Employer,String > employer = new TreeMap<>(new Comparator<Employer>() { @Override public int compare(Employer o1, Employer o2) { return o2.getSalary()-o1.getSalary(); } }); employer.put(new Employer("张三",1000),"Java程序员"); employer.put(new Employer("李四",10000),"python程序员"); employer.put(new Employer("王五",3000),"清洁工"); System.out.println(employer); //输出结果: {[李四'10000]=python程序员, [王五'3000]=清洁工, [张三'1000]=Java程序员}在这我们可以重新温习一个知识点,那就是Lambda表达式,可以将自定义的Comparator进行简化的编写(大家可以先独立地尝试以下,再看下面的答案):
Map<Employer,String > employer = new TreeMap<>((o1, o2)-> o2.getSalary()-o1.getSalary());若在简化的时候出现困难的话,不妨去看一下这篇文章:Java中的Lambda表达式如何理解

常用API
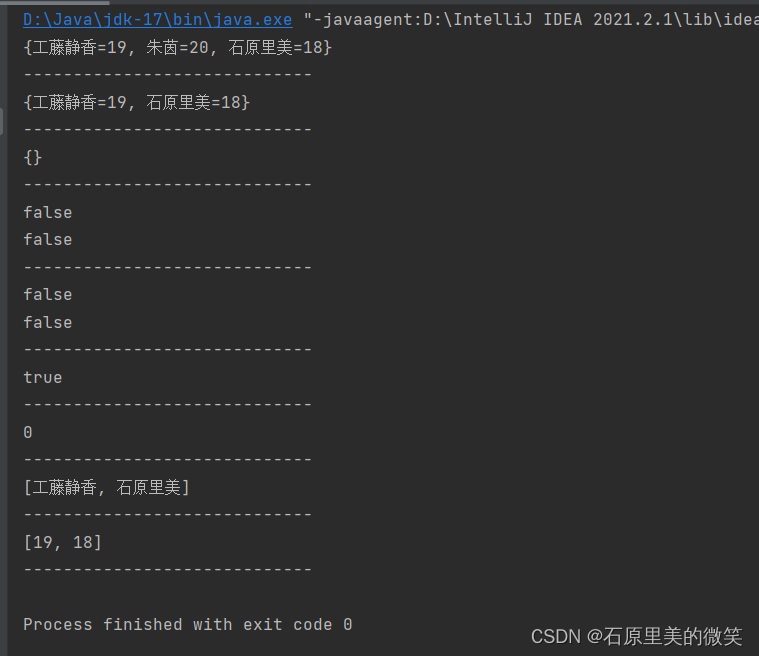
对于Map集合常用的一些API,我们通过一段代码可以生动形象的理解其用法:
Map<String ,Integer> maps = new HashMap<>(); //1、添加元素 maps.put("石原里美",18); maps.put("工藤静香",19); maps.put("朱茵",20); System.out.println(maps); System.out.println("-----------------------------"); //2、根据键key删除键值对key和value maps.remove("朱茵"); System.out.println(maps); System.out.println("-----------------------------"); //3、清除Map集合中的所有元素 maps.clear(); System.out.println(maps); System.out.println("-----------------------------"); //4、判断Map集合中是否包含此key System.out.println(maps.containsKey("石原里美")); System.out.println(maps.containsKey("石原")); System.out.println("-----------------------------"); //5、判断Map集合中是否包含此value System.out.println(maps.containsValue(30)); System.out.println(maps.containsValue(18)); System.out.println("-----------------------------"); //6、判断Map集合是否为空 System.out.println(maps.isEmpty()); System.out.println("-----------------------------"); //7、获取Map集合中元素个数 System.out.println(maps.size()); System.out.println("-----------------------------"); //8、获取集合中所有的键 maps.put("石原里美",18); maps.put("工藤静香",19); Set<String> key = maps.keySet();//将所有键储存在set集合中 System.out.println(key); System.out.println("-----------------------------"); //9、获取集合中的所有值 Collection<Integer> values = maps.values(); System.out.println(values); System.out.println("-----------------------------");输出结果:
遍历Map集合
键找值
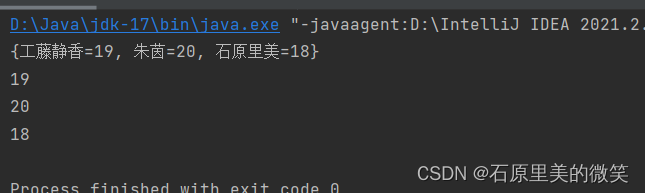
在此遍历中主要用到两个API,一个是keySet(),另一个则是get()方法,使用前者将key储存在set集合中,再通过foreach遍历以及get()方法获取对应的value。
Map<String ,Integer> maps = new HashMap<>(); maps.put("石原里美",18); maps.put("工藤静香",19); maps.put("朱茵",20); System.out.println(maps); Set<String> key = maps.keySet(); for (String k:key ) { System.out.println(maps.get(k)); }输出结果:
键值对
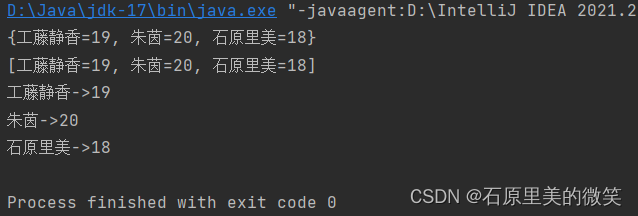
在此遍历中,主要用到三个API,在getkey()和getvalue()的基础上,添加了entrySet(),其可以获取键值对集合
Map<String ,Integer> maps = new HashMap<>(); maps.put("石原里美",18); maps.put("工藤静香",19); maps.put("朱茵",20); System.out.println(maps); Set<Map.Entry<String, Integer>> set = maps.entrySet(); System.out.println(set); for (Map.Entry<String, Integer> s : set) { System.out.println(s.getKey()+"->"+s.getValue()); }输出结果:
Lambda表达式
Map<String ,Integer> maps = new HashMap<>(); maps.put("石原里美",18); maps.put("工藤静香",19); maps.put("朱茵",20); System.out.println(maps); maps.forEach(new BiConsumer<String, Integer>() { @Override public void accept(String k, Integer v) { System.out.println(k+"->"+v); } });结合之前学习的Lambda表达式,我们可以将其进行简化,不知道大家还有没有对此有记忆呢?
maps.forEach((k,v)-> System.out.println(k+"->"+v) );如果没有学过,或者概念不理解了,可以尝试着看这篇文章:Java中Lambda表达式如何理解
结束语
当你看到这的时候,我们的集合就已经大致地学习完了,感谢大家对这几篇文章的支持,虽然在学习Java的这条道路上是枯燥无味的,但是我希望我的文章能够让大家在学习的时候感受到一定的乐趣,做到苦中作乐的境界。
此时此刻大家仍然不能松懈,后边还将会有虽然困难但是有趣的知识在等待着大家去学习,在短暂的休息之后,继续向前走下去吧!同样的,我也会陪伴着大家继续向后走下去的,一起共同奋斗下去吧!最后但同样重要,三连会对我有很大的帮助的哈哈哈哈哈!
