文章目录
1 字典
字典可能是Python最为重要的数据结构。它更为常见的名字是哈希映射或关联数组。
它是键值对的大小可变集合,键和值都是Python对象。创建字典的方法之一是使用花括号{},用冒号分隔键和值:
In [101]: empty_dict = {
}
In [102]: d1 = {
'a' : 'some value', 'b' : [1, 2, 3, 4]}
In [103]: d1
Out[103]: {
'a': 'some value', 'b': [1, 2, 3, 4]}
- 可以像访问列表或元组中的元素一样,访问、插入或设定字典中的元素。
注意d1[7] = 'an interger'的写法
In [104]: d1[7] = 'an integer'
In [105]: d1
Out[105]: {
'a': 'some value', 'b': [1, 2, 3, 4], 7: 'an integer'}
In [106]: d1['b']
Out[106]: [1, 2, 3, 4]
1.1 in方法
- 可以用检查列表和元组是否包含某个值的方法,检查字典中是否包含某个键。
注意,这里是检查键,不是值
In [107]: 'b' in d1
Out[107]: True
1.2 del函数和pop方法
- 可以用
del关键字或pop方法(返回值的同时删除键)删除值
注意,del方法是直接删去键+值,pop方法在删去键+值之后,还是会返回值的!
值得注意的是,两者的调用方式不一样!
In [112]: del d1[5]
In [114]: ret = d1.pop('dummy')
In [108]: d1[5] = 'some value'
In [109]: d1
Out[109]:
{
'a': 'some value',
'b': [1, 2, 3, 4],
7: 'an integer',
5: 'some value'}
In [110]: d1['dummy'] = 'another value'
In [111]: d1
Out[111]:
{
'a': 'some value',
'b': [1, 2, 3, 4],
7: 'an integer',
5: 'some value',
'dummy': 'another value'}
In [112]: del d1[5]
In [113]: d1
Out[113]:
{
'a': 'some value',
'b': [1, 2, 3, 4],
7: 'an integer',
'dummy': 'another value'}
In [114]: ret = d1.pop('dummy')
In [115]: ret
Out[115]: 'another value'
In [116]: d1
Out[116]: {
'a': 'some value', 'b': [1, 2, 3, 4], 7: 'an integer'}
1.3 keys、values 方法
keys和values是字典的键和值的迭代器方法。虽然键值对没有顺序,这两个方法可以用相同的顺序输出键和值:
In [117]: list(d1.keys())
Out[117]: ['a', 'b', 7]
In [118]: list(d1.values())
Out[118]: ['some value', [1, 2, 3, 4], 'an integer']
1.4 update 方法
- 用
update方法可以将一个字典与另一个融合:
In [116]: d1
Out[116]: {
'a': 'some value', 'b': [1, 2, 3, 4], 7: 'an integer'}
In [119]: d1.update({
'b' : 'foo', 'c' : 12})
In [120]: d1
Out[120]: {
'a': 'some value', 'b': 'foo', 7: 'an integer', 'c': 12}
- 注意:
update方法是原地改变字典,因此任何传递给update的键的旧的值都会被舍弃。
可以关注一下键 ‘b’ 的值的变化
1.5 用序列创建字典
- 将两个序列配对组合成字典
mapping = {
}
for key, value in zip(key_list, value_list):
mapping[key] = value
1.6 dict函数
In [121]: mapping = dict(zip(range(5), reversed(range(5))))
In [122]: mapping
Out[122]: {
0: 4, 1: 3, 2: 2, 3: 1, 4: 0}
1.7 get方法
介绍:返回指定的键,如果键不在字典中,则返回默认值None,或者指定的默认值。
- 下面代码的逻辑:如果some_dict字典中存在key对应的键,就返回key对应的值;否则返回default_value
if key in some_dict:
value = some_dict[key]
else:
value = default_value
- 与上等价的代码:
value = some_dict.get(key, default_value)
1.8 setdefault方法
-
这个方法很复杂!
-
Python 字典
setdefault()函数和get()方法 类似, 如果键不存在于字典中,将会添加键并将值设为默认值。
返回值:如果字典中包含有给定键,则返回该键对应的值,否则返回为该键设置的值。 -
下面两段代码是等价的,可以好好体会python语言的优雅!
In [123]: words = ['apple', 'bat', 'bar', 'atom', 'book']
In [124]: by_letter = {
}
In [125]: for word in words:
.....: letter = word[0]
.....: if letter not in by_letter:
.....: by_letter[letter] = [word]
.....: else:
.....: by_letter[letter].append(word)
.....:
In [126]: by_letter
Out[126]: {
'a': ['apple', 'atom'], 'b': ['bat', 'bar', 'book']}
for word in words:
letter = word[0]
by_letter.setdefault(letter, []).append(word)
1.9 hash函数(有效的键类型)
字典的值可以是任意Python对象。
而键通常是不可变的标量类型(整数、浮点型、字符串)或元组(元组中的对象必须是不可变的)。
这被称为“可哈希性”。
- 可以用
hash函数检测一个对象是否是可哈希的 == 可被用作字典的键:
In [127]: hash('string')
Out[127]: 5023931463650008331
In [128]: hash((1, 2, (2, 3)))
Out[128]: 1097636502276347782
In [129]: hash((1, 2, [2, 3])) # fails because lists are mutable
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-129-800cd14ba8be> in <module>()
----> 1 hash((1, 2, [2, 3])) # fails because lists are mutable
TypeError: unhashable type: 'list'
- 要用列表当做键,一种方法是将列表转化为元组,只要内部元素可以被哈希,它也就可以被哈希。
【这个真的太超纲了吧,谁会用列表当成键啊…】
In [130]: d = {
}
In [131]: d[tuple([1, 2, 3])] = 5
In [132]: d
Out[132]: {
(1, 2, 3): 5}
2 集合
- 定义:集合是无序的不可重复的元素的集合。
(1)可以把它当做字典,但是只有键没有值。
(2)可以用两种方式创建集合:通过set函数或使用花括号set语句:
In [133]: set([2, 2, 2, 1, 3, 3])
Out[133]: {
1, 2, 3}
In [134]: {
2, 2, 2, 1, 3, 3}
Out[134]: {
1, 2, 3}
2.1 数学集合运算(合并、交集)
- 合并是取两个集合中不重复的元素。可以用
union方法,或者| 运算符:
In [135]: a = {
1, 2, 3, 4, 5}
In [136]: b = {
3, 4, 5, 6, 7, 8}
In [137]: a.union(b)
Out[137]: {
1, 2, 3, 4, 5, 6, 7, 8}
In [138]: a | b
Out[138]: {
1, 2, 3, 4, 5, 6, 7, 8}
- 交集的元素包含在两个集合中。可以用
intersection或& 运算符:
In [139]: a.intersection(b)
Out[139]: {
3, 4, 5}
In [140]: a & b
Out[140]: {
3, 4, 5}
- 总结:
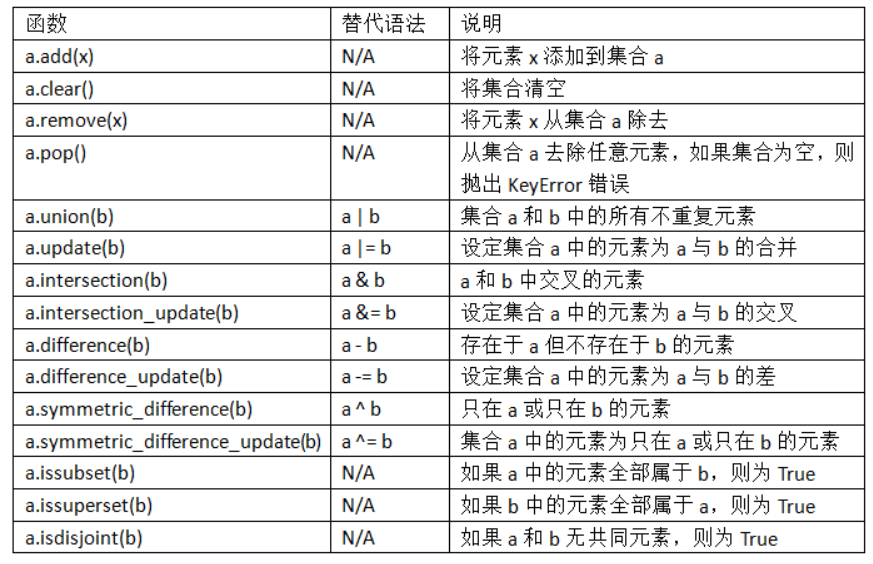
- 所有逻辑集合操作都有另外的原地实现方法,可以直接用结果替代集合的内容。对于大的集合,这么做效率更高:
In [141]: c = a.copy()
In [142]: c |= b
In [143]: c
Out[143]: {
1, 2, 3, 4, 5, 6, 7, 8}
In [144]: d = a.copy()
In [145]: d &= b
In [146]: d
Out[146]: {
3, 4, 5}
- 与字典类似,集合元素通常都是不可变的。要获得类似列表的元素,必须转换成元组:
In [147]: my_data = [1, 2, 3, 4]
In [148]: my_set = {
tuple(my_data)}
In [149]: my_set
Out[149]: {
(1, 2, 3, 4)}
2.1 issubset方法,issuperset方法
- 你还可以检测一个集合是否是另一个集合的子集或父集:
In [150]: a_set = {
1, 2, 3, 4, 5}
In [151]: {
1, 2, 3}.issubset(a_set)
Out[151]: True
In [152]: a_set.issuperset({
1, 2, 3})
Out[152]: True
- 集合的内容相同时,集合才对等
In [153]: {
1, 2, 3} == {
3, 2, 1}
Out[153]: True
3 列表、集合、字典 之推导式
3.1 列表的推导式
- 列表推导式是Python最受喜爱的特性之一。
它允许用户方便的从一个集合过滤元素,形成列表,在传递参数的过程中还可以修改元素。
形式如下:
[expr for val in collection if condition]
- 它等同于下面的for循环:
result = []
for val in collection:
if condition:
result.append(expr)
- filter条件可以被忽略,只留下表达式就行。
例如,给定一个字符串列表,我们可以过滤出长度在2及以下的字符串,并将其转换成大写:
In [154]: strings = ['a', 'as', 'bat', 'car', 'dove', 'python']
In [155]: [x.upper() for x in strings if len(x) > 2]
Out[155]: ['BAT', 'CAR', 'DOVE', 'PYTHON']
3.2 字典的推导式
dict_comp = {
key-expr : value-expr for value in collection if condition}
3.3 集合的推导式
- 集合和列表的推导式很像,一个是
方括号[],一个是花括号{}
set_comp = {
expr for value in collection if condition}
- 这个例子,注意一下,集合中是不会出现重复数据的。
In [154]: strings = ['a', 'as', 'bat', 'car', 'dove', 'python']
In [156]: unique_lengths = {
len(x) for x in strings}
In [157]: unique_lengths
Out[157]: {
1, 2, 3, 4, 6}
3.3.1 介绍一下map函数
map()函数:
map()是 Python 内置的高阶函数,它接收一个函数 f 和一个 list,并通过把函数 f 依次作用在 list、
注意:map()函数不改变原有的 list,而是返回一个新的 list。
- 上面的例子,用map函数改写如下:(传入的参数1是函数求列表长度len,参数2是一个列表strings)
In [154]: strings = ['a', 'as', 'bat', 'car', 'dove', 'python']
In [158]: set(map(len, strings))
Out[158]: {
1, 2, 3, 4, 6}