目标检测的定义
首先什么是分类,什么是回归?
分类和回归都是监督学习,对输入的数据进行预测。
分类的输出结果是离散的,是物体所属的类别,如猫、狗等。
回归的输出结果是连续的,是物体的值,在一段范围内即可。
知乎上有一个高赞回答[1]说:连续与离散是表象,本质区别在于输出的标签是否有距离度量。
分类任务没有距离度量,把1分类为2和把1分类为3没有区别。
回归任务有距离度量,可乐的真实价格是5元,预测为4元,误差为1元,预测为2元,误差为3元。
此外,分类的目的是寻找决策边界,得一个决策面,对数据集中数据进行分类。如判断图片中的动物是猫还是狗等。
回归的目的是找到最优拟合,得一个最优拟合线,这个线最好接近数据集中的各个点。如预测股票、预测房价等。
图像分类、目标检测、图像分割理解
图像分类(image classification):输入图像往往仅包含一个物体,目的是判断每张图像是什么物体,是图像级别的任务,相对简单,发展也最快。
目标检测(object detection):输入图像中往往有很多物体,目的是判断出物体出现的位置与类别,是计算机视觉中非常核心的一个任务。
图像分割(image segmentation):输入与物体检测类似,但是要判断出每一个像素属于哪一个类别,属于像素级分类。图像分割与物体检测任务之间有很多联系,模型也可以相互借鉴。
bounding box的位置
通常有三种格式来表示bounding box的位置:
xyxy,即(x1, y1, x2, y2),其中(x1, y1)是bounding box左上角的坐标,(x2,y2)是bounding box右下角的坐标;
xywh,即(x, y, w, h),其中(x, y)是bounding box左上角的坐标,w是矩形框的宽度,h是矩形框的高度;
cxcywh,即(cx, cy, w, h),其中(cx, cy)是bounding box中心点的坐标,w是矩形框的宽度,h是矩形框的高度。
在检测任务中,训练数据集的标签里会给出目标物体真实边界框所对应的(x1,y1,x2,y2),这样的边界框也被称为真实框(ground truth box),我们训练出的模型会对目标物体可能出现的位置进行预测,由模型预测出的边界框则称为预测框(prediction box)。要完成一项检测任务,我们通常希望模型能够根据输入的图片,输出一些预测的边界框,以及边界框中所包含的物体的类别或者说属于某个类别的概率,例如这种格式: [L, P, x1, y1, x2, y2],其中L是类别标签,P是物体属于该类别的概率。一张输入图片可能会产生多个预测框,我们就根据预测出的prediction box和ground truth box计算损失值来定义损失函数。
NMS的理解
参考:https://zhuanlan.zhihu.com/p/80318430
1,首先从第一类dog开始,将所有dog score <thresh1(0.3)的bb的score值设置为0

2,然后按照当前的dog score值给所有bb排序:
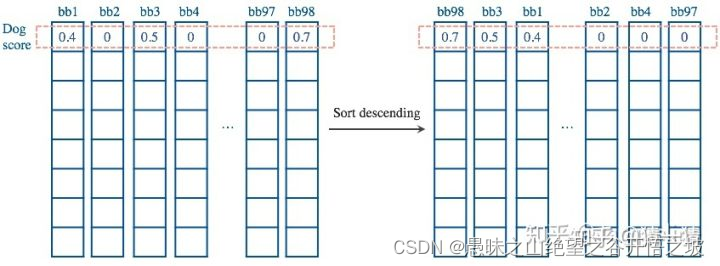
3,排好序之后我们找到当前最高分0.7和其对应的bb98(红色箭头),为了更清楚的描述整个过程,我们单独把dog score这一行拿出来,然后我们算其余的bb和bb98的IOU:
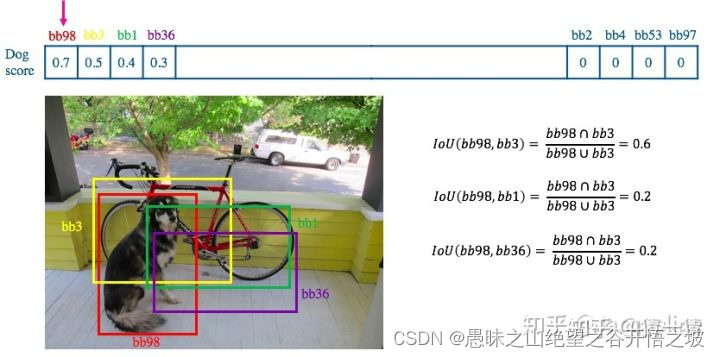
其实,我们不仅仅设置了score阈值,还会设置IOU阈值,高于IOU阈值的,将其删掉。
4,当计算完bb98和其余的bb的IOU值之后,我们便可以删掉一部分bb(设为零),之后我们从未删除的bb中在选取当前的最大值,即0.4,对应的是bb1,然后在计算bb1和其余bb的IOU值:
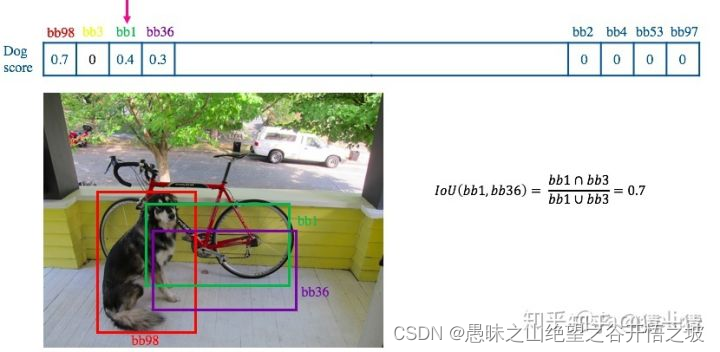
处理完之后,会得到一个score列表,取最大值所对应的框即可。
5,当处理完dog这一类之后,我们再处理下一类,例如bike,和上述过程相同,然后对于每一类都进行同样的操作之后,我们便删掉了大多数的bb,而对于留下的bb,画出所对应的框即可。
注意,NMS算法通常用于测试阶段