Linux下C语言开发
Linux下C语言开发
Linux下C语言开发流程
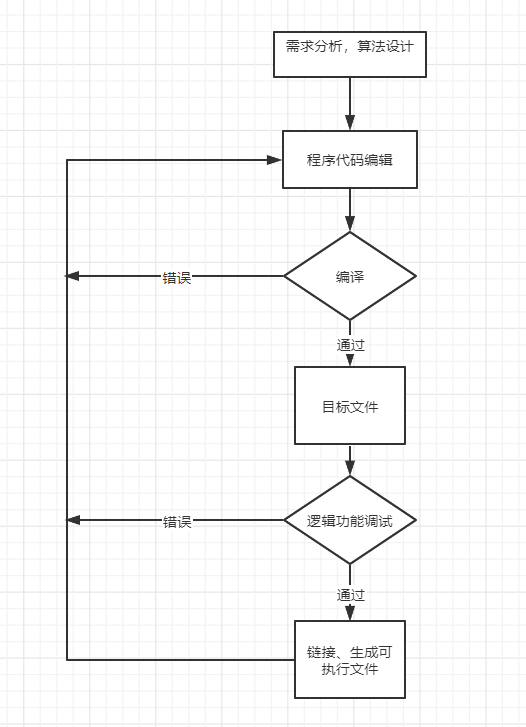
C语言开发工具
-
编辑工具:文本编辑工具 (vim)
-
编译工具:源码转换为可执行代码的过程
最常用的编译器是gcc编译器
 、
、 -
调试工具: 方便对C语言的目标代码进行调试
GDB是绝大多数开发人员使用的调试器
-
项目管理和维护工具: make 等是一种控制编译或者重复编译软件的工具,可以对C语言的程序源文件进行有效的管理
c语言代码编辑工具
-
Vim
-
vim的启动和退出
在终端输入vim 或者(vim + 文件名) ,即可启动vim编辑器 退出: Esc 回到vim的命令行工作模式 输入 :q <回车> -
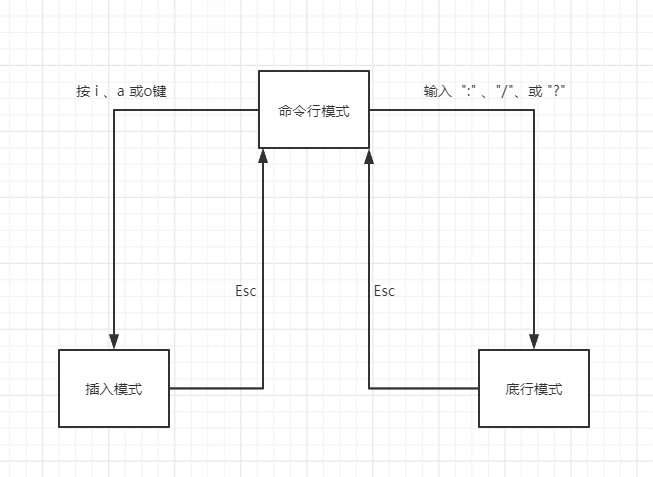
vim 的工作模式及其切换
有三种工作模式: 命令行模式、插入工作模式、底行工作模式 1. 命令行模式 启动后默认进入此模式,实现光标的移动、复制、粘贴、删除等 但不接受用户从键盘输入的任何字符来作为文档的编辑内容 2. 插入工作模式 用户输入的任何字符都被认为是编辑到某一个文件的内容,并直接显示在vim的文本编辑区 3. 底行工作模式 用户输入的任何字符串都会被当作命令,会在vim的最下面一行显示,<回车> 便会执行该命令,若不是一个有效命令,会出现错误提示三种模式的切换:
-
vim的命令行工作模式
vim在命令行工作模式下的主要操作是使用方向键或快捷键对当前光标进行定位,以及使用相应的命令对当前文件中的文本进行诸如复制、删除、粘贴等基础编辑操作。
移动光标的常用命令
命令 操作说明 h 左移光标 l 右 j 下 k 上 ^ 移到该行的开头,第一个非空字符 $ 该行行尾 0 该行的行首 G 文档最后一行的开头(第一个非空字符) nG 文档的第n行的开头,n为正整数 w 后移一个字(单词) nw 后移n个字 b 前移一个字 nb 前移n个字 e 移动到本单词的最后一个字符。若光标所在的位置为本单词的最后一个字符,则跳到下一个单词的最后一个字符,"." , “,” , “#”, “/” 等特殊字符都会被当作一个字 { 移动到前面的{处,进行c语言编程时很适用 } 移动到后面的} 处 Ctrl+b 向上翻一页 Ctrl+f 向下翻一页 Ctrl+u 向上移动半页 Ctrl+d 向下移动半页 Ctrl+e 向下翻一行 Ctrl+y 向上翻一行 复制、粘贴命令
命令 操作说明 yy 复制光标所在行的整行内容 yw 复制光标所在单词的内容 nyy 复制从光标所在行开始向下的n行 nyw 复制向后的n个字 p 在光标位置粘贴 删除文本命令
命令 操作说明 x 删除光标所在的字(后删),同delete X 删除光标所在位置的前一个字符 nx 删除光标后的n个字 nX 删除光标前的n个字 dw 删除光标所在位置的字符 ndw 光标所在位置向后的n个字符 d0 删除当前行光标所在位置前的所有字符 d$ 删除当前行光标所在位置后的所有字符 dd 删除光标所在的行 ndd 向下的n行,共n行 nd+上方向键 删除光标所在行及其向上的n行,共n+1行 nd+下方向键 删除光标所在行及其向下的n行,共n+1行 常用的其他命令:字符替换、插销、符号匹配
命令 操作说明 r 替换光标所在位置的字符,rx是将光标所在位置的字符替换为x R 替换光标所到之处的字符,直到按下esc键为止 u 恢复,撤销上一次的操作 U 取消对当前行所做的所有改变 . 重复执行上一次的命令 ZZ 保存文档后退出vim编辑器 % 符号匹配,在编辑时若输入 " %( “,则系统会自动匹配相应的”)" -
vim 的插入工作模式
只有在插入模式下,才可以进行文本的输入操作。
Esc 返回到vim的命令行工作模式
命令行工作模式切换到插入工作模式的命令
命令 操作说明 i 从光标所在的位置开始插入新的字符 I 从光标所在行的行首开始插入新的字符 a 从光标所在位置的 下一个字符 开始插入新的输入字符 A 从光标所在行的行尾开始插入新的字符 o 增加一行,并将光标移动到下一行的开头开始插入字符 O 在当前行的上面增加一行,并将光标移动到上一行的开头开始插入字符 -
vim的底行工作模式
主要用来进行一些文字编辑的辅助功能,例如: 字符串搜索、替换、保存文件,以及退出vim等
在命令行模式下输入 : 或 ? 和 / 即可进入
底行工作模式下的常用命令
命令 操作说明 q 退出vim程序,若文件有过修改,必须先保存 q! 强制退出而不保存文件 x 保存文件并退出vim(exit) x! 强制保存文件并退出 w 保存文件,但不退出vim w! 对于只读文件,强制保存修改的内容,但不退出vim wq 保存并退出vim,同x E 在vim中创建新的文件,并为文件命名 N 在本vim窗口打开新的文件 w filename 另存为filename文件,不退出 w! filename 强制另存为filename 文件,不退出 r filename 读入filename指定的文件内容插入到光标位置(read) set nu 在vim 的每行开头处显示行号 s/pattern1/pattern2/g 将光标当前行的字符串pattern1替换为pattern2 %s/pattern1/pattern2/g 将所有行的字符串pattern1替换为pattern2 g/pattern1/s//pattern2 将所有行的字符串pattern1替换为pattern2 num1,num2 s/pattern1/pattern2/g 将从行num1~num2的字符串pattern1替换为pattern2 / 查找匹配字符串功能,利用"/字符串"的命令模式,查找突出显示所有找到的字符串,然后转到找到的第一个字符串。如果想继续向下查找,可以按n键,向前继续查找则按N键 ? “? 字符串” 模式查找特定的字符串,与/类似,但它是向前查找字符串。 -
vim的操作步骤
1. 使用 vim+文件名 命令启动vim 2. 进入插入模式 3. 对c语言源文件进行编辑 4. Esc退出插入模式,再进入底行工作模式 5. 保存并退出::wq -
使用vim的配置文件
vim的配置文件是一个vimrc文件,启动vim,进入底行模式,输入
echo $VIM命令可以查看当前vim编辑器的配置文件所在位置。(通常位于/usr/share/vim路径下 , vimxx 下有vimrc的例子)
使用vim打开vimrc文件,但要注意修改文件后保存,需要root权限(sudo)
将vimrc 文件放在 ~/下,命名为 .vimrc即可
vimrc文件中使用双引号作为注释符
1 if v:lang =~ "utf8$" || v:lang =~ "UTF-8$" 2 set fileencodings=ucs-bom,utf-8,latin1 3 endif 4 5 set nocompatible " Use Vim defaults (much better!) 6 set bs=indent,eol,start " allow backspacing over everything in insert mode 7 "set ai " always set autoindenting on 8 "set backup " keep a backup file 9 set viminfo='20,\"50 " read/write a .viminfo file, don't store more 10 " than 50 lines of registers 11 set history=50 " keep 50 lines of command line history 12 set ruler " show the cursor position all the time 13 14 " Only do this part when compiled with support for autocommands 15 if has("autocmd") 16 augroup redhat 17 autocmd! 18 " In text files, always limit the width of text to 78 characters 19 " autocmd BufRead *.txt set tw=78 20 " When editing a file, always jump to the last cursor position 21 autocmd BufReadPost * 22 \ if line("'\"") > 0 && line ("'\"") <= line("$") | 23 \ exe "normal! g'\"" | 24 \ endif 25 " don't write swapfile on most commonly used directories for NFS mounts or USB sticks 26 autocmd BufNewFile,BufReadPre /media/*,/run/media/*,/mnt/* set directory=~/tmp,/var/tmp,/tmp 27 " start with spec file template 28 autocmd BufNewFile *.spec 0r /usr/share/vim/vimfiles/template.spec 29 augroup END 30 endif 31 32 if has("cscope") && filereadable("/usr/bin/cscope") 33 set csprg=/usr/bin/cscope 34 set csto=0 35 set cst 36 set nocsverb 37 " add any database in current directory 38 if filereadable("cscope.out") 39 cs add $PWD/cscope.out 40 " else add database pointed to by environment 41 elseif $CSCOPE_DB != "" 42 cs add $CSCOPE_DB 43 endif 44 set csverb 45 endif 46 47 " Switch syntax highlighting on, when the terminal has colors 48 " Also switch on highlighting the last used search pattern. 49 if &t_Co > 2 || has("gui_running") 50 syntax on 51 set hlsearch 52 endif 53 54 filetype plugin on 55 56 if &term=="xterm" 57 set t_Co=8 58 set t_Sb=^[[4%dm 59 set t_Sf=^[[3%dm 60 endif要进行的选项设置:
1. syntax on: 打开文件类型高亮显示,打开后会对C语言的关键字使用特殊颜色显示 2. set showmatch: 显示配对的括号 3. set nu : 显示行号,这是vimrc文件中没有的,要自己加 4. set autoindent: 打开换行自动缩进 5. set cindent :按照c语言的的书写习惯自动缩进,每个缩进按8个空格来的 6. set mouse=a : 打开鼠标支持,此时在vim中使用滚轮和点击均可 7. set tabstop=4 设置一个tab为4个空格
-
-
Emacs
Emacs,即Editor Macros(编辑器宏),是Linux下一个功能强大的图形化文本编辑器。
是一个集成开发环境
-
gedit
兼容UTF-8的纯文本编辑器,对中文支持很好,支持包括GB2312、GBK在内的多种字符编码。
LinuxC语言的编译器gcc
gcc 的安装和配置
在许多发行版中gcc默认安装,但是缺少常用的头文件和库文件。
要安装 build-essential这个包
sudo apt-get instal build-essential
apt-get 是ubuntu 下的软件管理命令,可以安装、删除、更新系统中的软件包
install 是安装软件包
系统在安装build-essential时,会把程序文件放入以下几个目录:
- /usr/lib : 大部分的编译程序都放在这个目录。这里有编译需要的可执行程序,还有一些特定版本的库文件与头文件
- /usr/bin/gcc: 指的是编译程序,即实际在命令中执行的程序。这个目录可供各个版本的gcc使用,只要利用不同的编译程序目录来安装就可以了
- /usr/include : 这个目录及其子目录下包含程序所需要的头文件
完成安装后,可以使用gcc-v命令查看gcc的版本号
gcc 网址: http://www.gnu.org/software/gcc 来了解gcc的最近发展
关于centos安装相应包的说明:
yum install gcc gcc-c++ kernel-devel
其他:

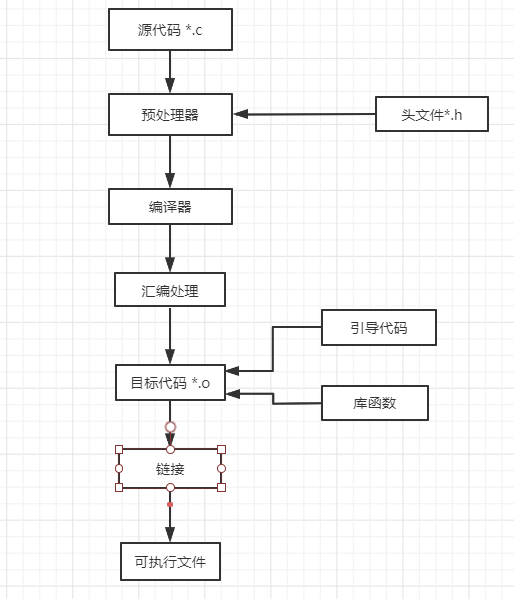
gcc对c语言的处理过程
4个步骤:
- 预处理,C语言处理的第一阶段,gcc需要对C语言源文件中包含的各种头文件和宏定义进行处理,如:#define #include #if等
- 编译,根据源文件产生汇编语言,首先检查代码的规范性、是否有语法错误等
- 汇编, 将刚得到的汇编语言用于输入,产生.o 拓展名的目标文件
- 链接,各目标文件被gcc放在可执行文件的适当位置上
预处理阶段产生预处理文件,后缀名为.i
编译阶段,会生成汇编代码文件.s
汇编阶段,将.s文件转换为目标文件.o
默认gcc会到/usr/lib下查找库文件
函数库有静态库和动态库两种
- 静态库是指编译链接时,将库文件的代码全部加入可执行文件中,因此生成的文件比较大,但在运行时就不需要库文件了,其后缀名为.a
- 动态库与之相反,在编译链接时并没有将库文件的代码加入可执行文件中,而是在程序执行时加载库,节省开销,一般动态库的后缀为.so
gcc 在编译时默认使用动态库
gcc的基础使用方法
gcc基本使用格式
gcc [选项] 文件名
gcc 可以通过选项对程序的生成进行全面控制,每个选线可以有多种值。
常用选项:
| 选项 | 说明 |
|---|---|
| -c | 仅对源文件进行编译,不链接生成可执行文件。进行差错或只生成目标文件时可以使用 |
| -o filename | 将经过gcc处理过的结果保存为filename,这个结果文件可以是预处理文件、汇编文件、目标文件或者最终的可执行文件。假设被处理的源文件为file1,如果这个选型被忽略,那么生成的可执行文件的默认名称为a.out,目标文件默认为file1.o,汇编文件默认名为file1.s,生成的预处理文件发送到标准输出设备stdout |
| -g或-gdb | 在可执行文件中加入调试信息,方便进行程序的调试,如果使用 -gdb 选项,表示加入gdb扩展的调试信息,以便使用gdb进行调试 |
| -O[0,1,2,3] | 对生成的代码进行优化,括号中的部分为优化等级,默认为2级优化,0为不优化。优化和调试通常不兼容,不要同时使用-g 和-O选项 |
| -Idir | 将dir目录加到搜索头文件的目录中,并优先于gcc缺省的搜索目录。在有多个-I 选项的时候,按命令行上-I的前后顺序搜索,dir可以使用相对路径 |
| -Ldir | 将dir目录加到搜寻 -L选型指定的函数库文件的目录列表中,并优先于gcc缺省的搜索目录,在有多个 -L 的选项下,按 -L 的前后顺序搜索,可使用相对路径。 |
| -lname | 在链接时使用函数库name.a, 链接程序在 “-Ldir"选项指定的目录下,以及”/lib",“usr/lib” 下寻找该库文件。在没有使用"-static" 选项时,如果发现共享函数库name.so, 则使用 name.so进行动态链接。 |
gcc命令可以组合使用,不过每个命令选项都要有一个自己的连字符"-"
在Linux下生成的可执行文件没有固定的拓展名。
gcc命令中的第2部分是一个输入给gcc命令的文件。gcc通过输入文件的拓展名来确认文件类型。
gcc支持的与c语言相关的输入文件类型
| 拓展名 | 类型 |
|---|---|
| .c | c语言源程序 |
| .C, .cc ,.cp,.cpp,.c++,.cxx | C++语言源程序 |
| .i | 预处理后的C语言源程序 |
| .ii | 预处理后的C++源程序 |
| .s | 预处理后的汇编程序 |
| .S | 未预处理的汇编程序 |
| .h | 头文件 |
| .o | 编译后的目标代码 |
| .a | 目标文件库 |
可执行文件,通常以绿色在终端中显示。
实际开发中,常将主函数和其他函数放在不同文件中。
例: 对两个c语言文件进行编译,并且链接生成可执行文件
Examhellosun.c是一个函数的实现文件
Examhello.c 是一个有主函数的文件,且调用了Examhellosum.c中的函数(有头文件)
gcc Examhello.c Examhellosun.c -o Examhello
Linux C语言的调试工具gdb
GBK调试程序,主要提供的功能:
- 监视程序中变量的值
- 设置断点以使程序的指定的代码行上停止执行
- 一行行的执行代码
gdb的基础使用
gdb是在Linux安装时自带的,在命令行上输入"gdb" 会启动gdb调试环境
gdb的功能很强大,包括从简单的文件装入到允许检查所调用的堆栈内容的复杂命令。
使用gdb调试时会用到的一些常用命令:
| 命令 | 说明 |
|---|---|
| file | 装入想要调试的可执行文件 |
| kill | 终止正在调试的程序 |
| list | 列出产生执行文件的部分源代码 |
| next | 执行一行代码,但不进入函数内部 |
| step | 执行一行源代码并且进入函数内部 |
| run | 执行当前被调试的程序 |
| quit | 退出gdb |
| watch | 动态监视一个变量的值 |
| make | 不退出gdb而重新产生可执行文件 |
| call name(args) | 调用并执行名为name,参数为args的函数 |
| return value | 停止执行当前函数,并将value返回给调用者 |
| break | 在代码里设置端点,使程序执行到此处被挂起 |
通常来说,调用gdb只需要一个参数,其标准格式:
gdb<可执行程序名>
如果程序运行时产生了错误,会在当前目录下产生一个核心内存映像core文件,可以在指定执行文件的同时为可执行文件指定一个core文件:
还可以为要执行的文件指定一个进程号PID:
gdb <可执行文件名> <进程号>
当gdb运行时,把任何一个不带选项前缀的参数都作为一个可执行文件、core文件或被调试程序相关关联的进程号。
不带任何选项前缀的参数和前面加了 “-se"或”-c"选项的参数效果相同。
gdb把第一个前面没有选项说明的参数看作前面加了"-se"选项,也就是需要调试的可执行文件并从此文件里读取符号表,如果有第2个前面没有选项说明的参数,将被看作是跟在"-c"选项后面,也就是需要调试的core文件名。
如果不希望看到gdb开始的提示信息,可以用 "gdb -silent"执行调试工作。
输入"gdb -help"或"-h" 可以得到gdb启动时的所有选项提示。
gdb命令行中的所有参数都按照排列的顺序传给gdb,除非使用了"-x"参数。
gdb的许多选项都可以使用缩写的形式代表,也可以用"-h" 查看。
在gdb中也可以采用任意长的字符串代表选项,只要保证gdb能唯一的识别此参数就可。
gdb中一些常用的参数选项:
| 选项 | 说明 |
|---|---|
| -s filename | 从filename指定的文件中读取要调试的程序符号表 |
| -e filename | 执行filename指定的文件,并通过与core文件进行比较来检查正确的数据 |
| -se filename | 从filename中读取符号表并作为可执行文件进行调试 |
| -c filename | 把filename指定的文件作为一个core文件 |
| -c num | 把数字num作为进程号和调试的程序进行关联,与attach命令相似 |
| -command filename | 按照filename指定的文件中的命令执行gdb命令,在filename指定的文件中存放着一系列的gdb命令,就像一个批处理 |
| -d path | 指定源文件的路径,把path加入到搜索源文件的路径中 |
| -r | 从符号文件中一次读入整个符号表,而不是使用默认的方式首先调入一部分符号表,当需要时再读入其他部分。这会使gdb的启动较慢,但可以加快以后的调试速度。 |
gdb运行模式的选择
gdb提供了包括"批模式"或"安静模式"在内的一系列运行模式,可以通过gdb运行时在命令行中通过选项来选择
gdb运行模式的相关选项:
| 选项 | 说明 |
|---|---|
| -n | 不执行任何初始化文件中的命令(一级初始化文件就称为.gdbinit)。一般情况下在这些文件中的命令会在所有的命令行参数都被传递给gdb后执行。 |
| -q | 设定gdb的运行模式为“安静模式”,可以不输出介绍和版权信息,这些信息在“批模式”中也不会显示。 |
| -batch | 设定gdb的运行模式为“批模式”,gdb在“批模式”下运行时,会执行命令文件中的所有命令,当所有命令都被成功执行后gdb返回状态0,如果在执行过程中出错,返回一个非0值。 |
| -cd dir | 把dir作为gdb的工作目录,而非当前目录(gdb缺省时把当前目录作为工作目录) |
使用gdb对c语言生成的可执行文件进行调试。
例:使用gdb进行调试
- 运行
gdb + 待调试的可执行文件名称命令来启动调试 (是可执行文件名) - 使用"b"快捷键在程序开始出设置断点,然后使用"run"开始调试
- 使用"n"快捷键即可执行下一条语句,其间还可以使用其他命令来观察相应的变量运行情况。
b main 在main函数处设置一个断点
n 执行下一条语句
Linux C语言的项目管理工具make
为了对多个文件进行管理和处理
make 项目管理器的基础
管理较多的文件
可以通过读入makefile文件的内容来执行大量的编译工作
-
make 的基本结构
makefile是make项目管理器中使用的配置文件,通常的组成部分:
- 目标体: make项目管理器生成的目标文件(target)或者可执行文件
- 依赖文件:创建目标体所需要的文件,通常是c语言文件、C语言头文件
- 相关操作命令: make项目管理器使用依赖文件来创建目标所需要的命令,这些操作命令必须以制表符开头
一个标准的makefile文件的写法:
两个makefile文件分别命名为hello.c和hello.h的文件经过编译生成目标文件hello.o,执行的命令为gcc编译命令: gcc -c hello.c 实例的应用代码: hello.o: hello.c hello.h //以tab开头 gcc -c hello.c -o hello.o 此时可以使用make项目管理器,标准格式: make target //例如make hello.o 运行make项目管理器会自动读入makefile文件,找到相应的依赖文件执行相应的target的command语句 -
make 的变量
实际应用中makefile通常包含了大量的依赖文件和操作命令
一个复杂一些的例子:
有三个目标体,exam1、exam2、exam3,其中exam1的依赖文件是后两个目标体,若使用命令 make exam1 ,则make管理器找到exam1目标体开始执行。
实例代码
exam1:exam2.o exam3.o gcc exam2.o bar.o -o myprog exam2.o: exam.c exam2.h head.h gcc-Wall -O -g -c exam2.c -o exam2.o exam3.o: bar.c head.h gcc-Wall -O -g -c yul.c -o exam3.omake项目管理器会自动检查相关文件的时间戳,然后开始编译工作。
为了进一步简化编辑和维护makefile文件,make允许在makefile中创建和使用变量
变量是在makefile中定义的名字,用来代替一个文本字符串。
可以代替目标体、依赖文件、命令以及makefile文件中的其他部分。
变量的定义有两种方式: 递归展开方式, 简单方式
-
递归展开方式定义的变量,在引用这个变量时进行替换,若该变量包含了其他变量的引用,则在引用改变量的时候一次性的将内嵌的变量全部展开。
这种命令可以很好的完成用户的指令,但是也有严重的缺点:例如不能在变量的后面追加内容,可能会导致无限循环
-
简单变量的值在定义处展开,并且只展开一次,不包含任何其他变量的引用,从而消除变量的嵌套关系。
递归方式的第一格式: VAR=var简单方式的定义格式: VAR:=varmake中的变量均使用的格式为:$(VAR)makefile 的变量名是不包括":"、 “#” 、"=" 以及结尾空格的任何字符串,同时,应尽量避免变量名中包含字母、数字、下划线以外的情况。
变量名大小写敏感
建议在makefile内部使用小写字母,预留大写字母作为控制隐含规则参数或用户重载命令选项参数的变量名。
makefile中的变量的定义形式,变量可以包含多个文字,本质感觉就是一个字符串,用来做替换
例如:
OBJS=exam2.o exam3.o$(OBJS) 就是 exam2.o exam3.o
makefile中的变量分为用户自定义变量、预定义变量、自动变量以及环境便令。
-
自定义变量由用户自行设定
-
预定义变量和自动变量为通常在makefile中都会出现的变量,其中的一部份有默认值,就常见的设定值,用户可以修改
预定义变量包含了常见编译器、汇编器的名称以及其编译选项。
-
环境变量为系统当前已经定义了的环境变量。
用户定义的相同名称的变量会覆盖(屏蔽)同名的环境变量、
本地测试:
add.c
function.c

func.h
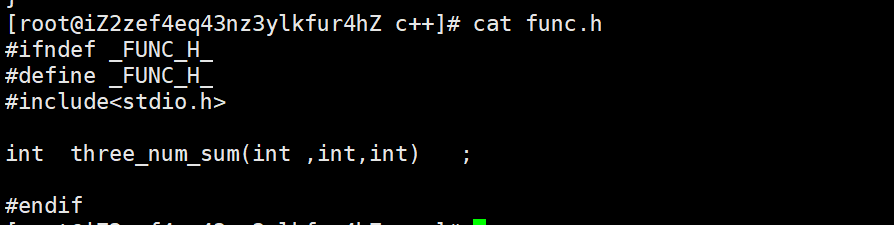
makefile文件

-

makefile中的变量
预定义变量包含了常见的编译器、汇编器的名称以及其编译选项
makefile中的预定义变量以及其部分默认值
| 预定义变量 | 含义 |
|---|---|
| AR | 库文件维护程序的名称,默认为ar |
| AS | 汇编程序的名称,默认as |
| CC | c编译器的名称 默认cc |
| CPP | c预编译器的名称,默认值为 “$(CC) -E” |
| CXX | c++编译器的名称,默认值为g++ |
| FC | Fortran编译器的名称,默认为f77 |
| RM | 文件删除程序的名称,默认"rm -f" |
| ARFLAGS | 库文件维护程序的名称,无默认值 |
| ASFLAGS | 汇编程序的选项,无默认 |
| CFLAGS | c编译器的选项,无默认 |
| CPPFLAGS | C预编译的选项,无默认 |
| CXXFLAGS | c++预编译器的选项,无默认 |
| FFLAGS | Fortran编译器的选项,无默认 |
由于常见的gcc编译语句中通常包含了目标文件和依赖文件,而这些文件在makefile文件中的目标体所在的行中已经有所体现。
为了进一步简化makefile的编写,引入自动变量。
自动变量通常可以代表编译语句中出现目标文件和依赖文件等,并且具有本地含义(即下一语句中出现的相同变量代表的是下一语句的目标文件和依赖文件)
makefile中的常见自动变量
| 自动变量 | 含义 |
|---|---|
| $* | 不包含拓展名的目标文件名称 |
| $+ | 所有的依赖文件,以空格分开,并以出现的先后为序,可能包含重复的依赖文件 |
| $< | 第一个依赖文件的名称 |
| $? | 所有时间戳比目标文件晚的依赖文件,并以空格分开 |
| $@ | 目标文件的完整名称 |
| $^ | 所有不重复的依赖文件,以空格分开 |
| $% | 如果目标是归档成员,则该变量表示目录的归档成员名称 |
例:
实例的应用代码:
exam1:exam2.o exam3.o
gcc exam2.o bar.o -o exam1
exam2.o: exam2.c exam2.h head.h
gcc -Wall-O -g -c exam2.c -o exam2.o
exam3.o: bar.c head.h
gcc -Wall -O -g -c yul.c -o exam3.o
使用变量:
OBJS=exam2.o exam3.o
CC=gcc
CFLAGS=-Wall -O -g
exam1:$(BOJS)
$(CC) $(OBJS) -o
exam2:exam2.c exam2.h
$(CC) $(CFLAGS) -c exam2.c -o exam2.o
exam3:yul.c yul.h
$(CC) $(CFLAGS) -c yul.c -o exam3.o
使用变量模式的进一步改写:
OBJS=exam2.o exam3.o
CC=gcc
CFLAGS=-Wall -O -g
exam1:$(OBJS)
$(CC) $^ -o $@
exam2.o: exam2.c exam2.h
$(CC) $(CFLAGS) -c $< -o $@
exam3.o: yul.c yul.h
$(CC) $(CFLAGS) -c $< -o $@
在makefile中可以使用环境变量。
make在启动的时候会自动读取系统当前已经定义的环境变量,并且会创建与之具有相同名称和数值的变量。但是,如果用户在makefile中定义了相同名称的变量,那么用户自定义的变量将会覆盖同名的环境变量。
-
make的规则
makefile的规则是make进行处理的依据。
包括目标体、依赖文件以及其之间的关系的命令语句。
以上的显示的指出了makefile中的规则的规则关系。
make工程管理器还定义了隐式规则和模式规则
(1)隐式规则
用户使用时不必详细的指定编译的具体细节,只需把目标文件列出即可
如上述的自动变量的例子可以用隐式规则写为:
OBJS=exam2.o exam3.oCC=gccCFLAGS=-Wall -O -gexam1:$(OBJS) $(CC) $< -o $@在makefile的隐式规则中指出所有的".o" 文件都可以自动由".c"文件使用命令" $(CC) $(CPPFLAGS) $(CFLAGS) -c file.c -o file.o"来生成
常见的隐式规则目录:
对应语言后缀名 隐式规则 C编译: .c 变为 .o $(CC) -c $(CPPFLAGS) $(CFLAGS) C++编译: cc或.C变为.o $(CXX) -c $(CPPFLAGS) $(CXXFLAGS) Pascal编译: .p 变为.o $(PC) -c $(PFLAGS) Fortran编译: .r 变为 .o $(FC) -c $(FFLAGS) (2)模式规则
用来定义相同处理规则的多个文件。
隐式规则仅能利用make默认的变量来进行操作,而模式规则还能引入用户的自定义变量,为多个文件建立相同的规则
模式规则的格式类似普通规则,但这个规则中的相关文件前必须使用"%"标明。
使用模式规则后的makefile文件的示例如下:
OBJS=exam2.o exam3.oCC=gccCFLAGS=-Wall -O -gexam1:$(OBJS) $(CC) $^ -o $@%.o:%.c $(CC)$(CFLAGS) -c $< -o $@对模式规则的自我理解: 模式规则相当于自定义隐式规则,使用 “%” 相当于是一个通配符, %.o 可以理解为 %.o这个文件,但%是一个占位符 ,%.o:%.c 中的%代表的是同一个名称
make项目管理器的使用
参考内容: <Linux下使用automake、autoconf生成configure文件 - 步孤天 - 博客园 (cnblogs.com)>
在make 命令的后面键入目标名即可建立指定的目标
如果直接运行make,则建立makefile中的第一个目标
make具有丰富的命令行选项,可以完成各种不同的功能
| 命令格式 | 含义 |
|---|---|
| -C dir | 读入指定目录下的makefile |
| -f file | 读入当前目录下的file文件作为makefile |
| -i | 忽略所有的命令执行错误 |
| -I dir | 指定被包含的makefile所在的目录 |
| -n | 只打印要执行的命令,但不执行这些命令 |
| -p | 显示make变量数据库和隐式规则 |
| -s | 在执行命令时不显示命令 |
| -w | 如果make在执行过程中改变目录,则打印当前目录名 |
对于较大的项目可以使用autotools来自动生成makefile
安装autotools:
ubuntu系统:
sudo apt-get install autoconf
centos系统:
yum install autoconf
autotools是一个系列工具,使用autotools的过程就是使用这些系列工具的脚本文件来生成最后的makefile的过程。
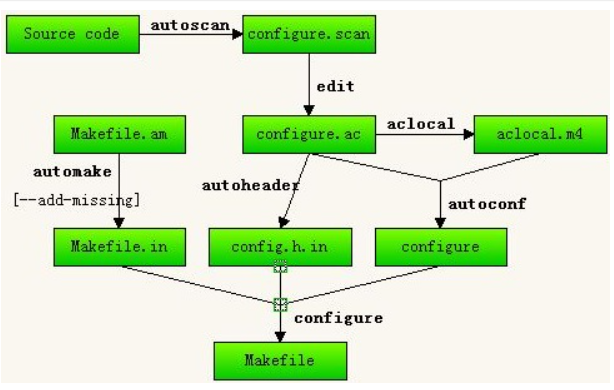
- aclocal: 生成一个名称为aclocal.m4的用于处理本地宏定义的文件
- autoscan: 在给定的目录以及其子目录树中检查源文件,若没有给出目录,就在当前目录及其子目录树中进行检查。它会搜索源文件以寻找一般的移植性问题并创建一个文件"configure.scan",该文件就是接下来autoconf要用到的"configure.in"原型
- autoconf: 对configure.in 脚本配置文件进行处理,生成configure脚本。这个过程可能要用到aclocal.m4中定义的宏。
- autoheader: 负责生成configure.h.in 文件,该工具通常从"acconfig.h"文件中复制用户附加的符号定义。
- automake: 其要用到的脚本配置文件是makefile.am ,用户需要自己创建相应的文件,然后利用automake工具转换为makefile.in, 此时运行configure自动配置设置文件即可将该.in 文件生成makefile文件。
使用autotools工具生成makefile文件的流程:

生成configure过程中的各文件之间的关系图:
使用autotools工具生成的makefile文件除了能完成编译操作外,还可以完成以下操作:
- 使用make命令默认执行 "make all "操作,可以生成对应的可执行文件
- 使用make install 命令会将生成的可执行文件安装到系统目录中(通常为usr/local/bin 目录) 并添加对应的全局变量,此时在任意路径下可以对该文件进行操作
- 使用make clean 命令会清除之前所编译的可执行文件和目标文件
- 使用make dist 命令会将可执行文件和涉及的文件生成一个压缩文件包(tar.gz)
使用autotools工具为hello.c的C语言文件生成makefile文件并且使用的例子
-
首先运行autoscan(可能需要sudo权限),其会搜寻指定的目录(默认当前目录及子目录树)中的源文件,并创建configure.scan文件
sudo autoscanautoscan会尝试读入"configure.ac"(同configure.in的配置文件)文件,若此时没有创建该配置文件,它会自动生成一个"configure.in"的原型文件"configure.scan",该文件和源文件位于同一个目录中。该.scan文件的内容可以使用cat 命令查看。
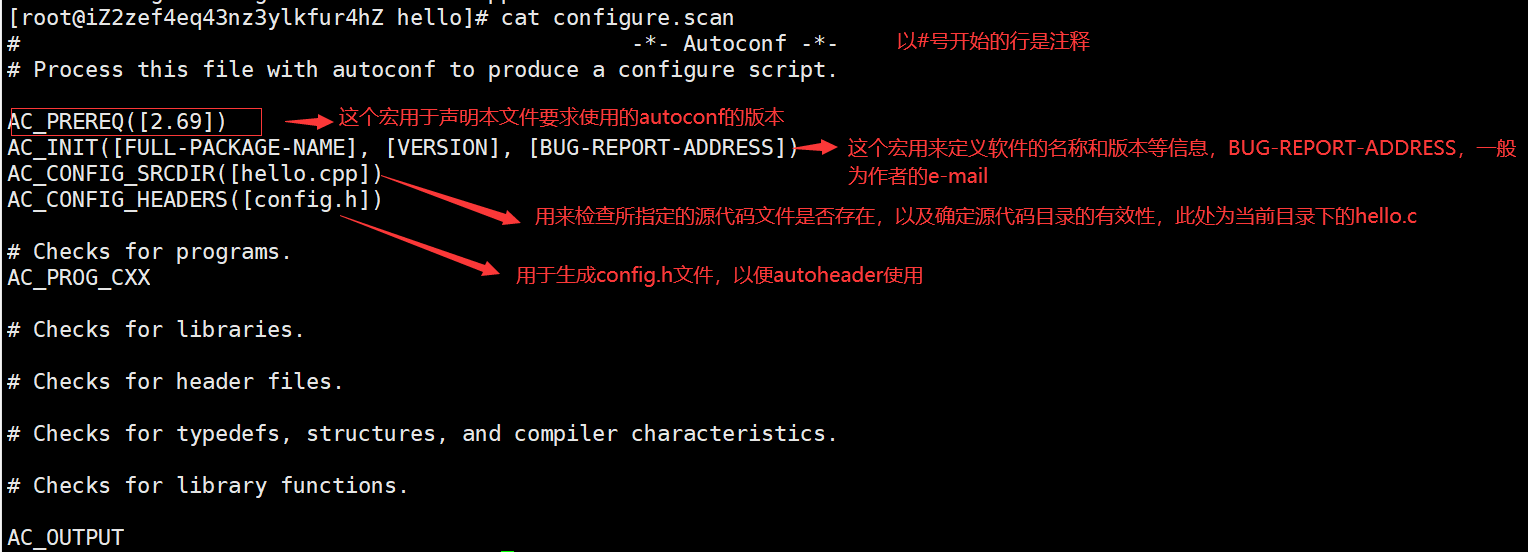
# -*- Autoconf -*- # Process this file with autoconf to produce a configure script. AC_PREREQ([2.69]) #AC_INIT([FULL-PACKAGE-NAME], [VERSION], [BUG-REPORT-ADDRESS]) AC_INIT(hello,1.0) # !!!!自己添加的 要注释掉原有的 #The next one is added by self AM_INIT_AUTOMAKE(hell,1.0) #!!!!自己添加的 AC_CONFIG_SRCDIR([hello.cpp]) AC_CONFIG_HEADERS([config.h]) # Checks for programs. AC_PROG_CXX # Checks for libraries. # Checks for header files. # Checks for typedefs, structures, and compiler characteristics. # Checks for library functions. AC_CONFIG_FILES([makefile]) # !!!自己添加的 最好使用Makefile AC_OUTPUT说明:
- AM_INIT_AUTOMAKE 是自添加的,它是automake所必备的宏,使automake自动的生成makefile,PACKAGE是所需要产生软件套件的名称,VERSION是版本 编号
- AC_CONFIG_FILES 宏用于生成相应的makefile文件
- 中间的注释之间可以分别添加用户测试程序、测试函数库、测试头文件等宏定义。
-
运行aclocal生成一个名称为aclocal.m4的文件,用于处理相应的宏定义;然后再运行autoconf以生成configure可执行文件
aclocal报错: aclocal: error: ‘configure.ac’ is required
将configure.scan 重命令为 configure.ac 即可
生成aclocal.m4的文件,用于处理相应的宏定义
-
运行autoconf生成configure可执行文件
autoconf -
运行autoheader生成config.h.in文件
autoheader -
创建一个脚本配置文件makefile.am
AUTOMAKE_OPTIONS=foreign bin_PROGRAMS=hello hello_SOURCES=hello.c-
AUTOMAKE_OPTIONS为设置automake的选项。GNU对自己发布的软件有严格的规范,例如必须附带许可证声明文件COPYING 等,否则automake执行报错。automake提供了3种软件等级:foreign,gnu和gnits。 默认gnu 。 foreign 等级只检测必须的文件。
-
bin_PROGRAMS 定义要产生的执行文件的名字。若要产生多个执行文件,每个文件名用空格隔开
-
hello_SOURCES 用于定义"hello" 这个执行程序所需要的原始文件,如果"hello"这个程序由多个原始文件产生,则必须要把它用到的所有原始文件都列出来,空格分隔。(包含头文件也要列出)
如果要定义多个执行文件,则对每个执行文件,都要定义相应的file_SOURCES
创建的.am文件名字要和 AC_CONFIG_FILES([makefile]) 指定的文件名字相同 (建议使用Makefile)
-
-
使用"automake -a"命令来自动添加一些脚本并且生成configure.in 文件,容纳后使用ls命令查看生成的文件
-
运行configure将makefile.in文件生成最终的makefile文件。
在运行configure时收集了系统的信息。
./configure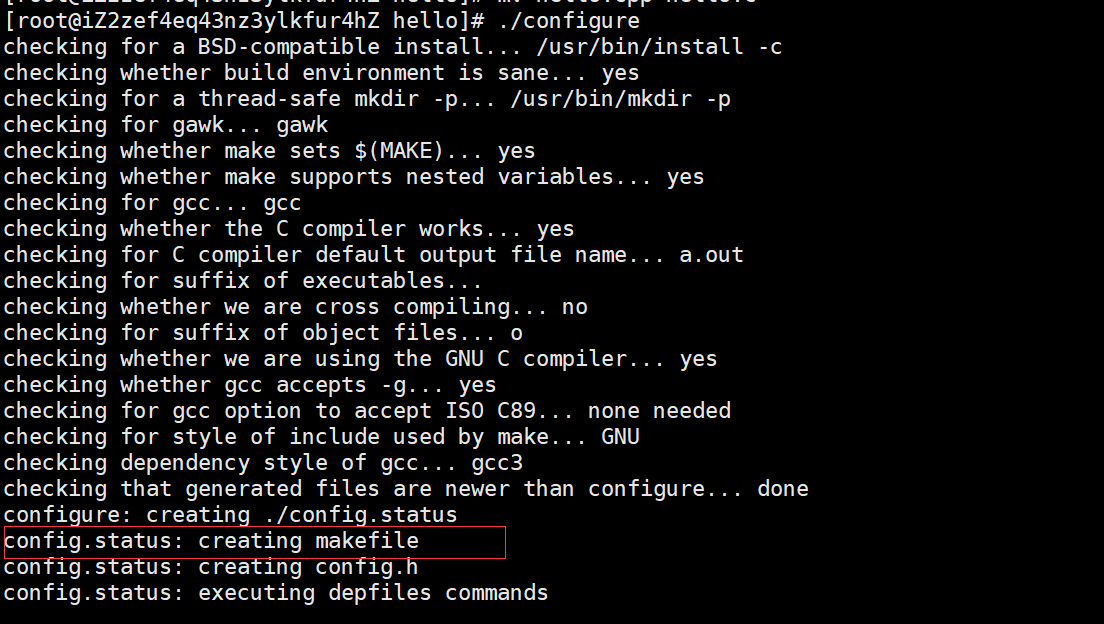
注意: .c c语言文件
.cpp c++语言文件
Linux中的C语言应用代码
代码的运行机制、内存的分配机制、系统调用和库函数
C语言代码的运行机制
Linux中的程序是一个在磁盘上的可执行文件,内核调用一个exec函数将这个可执行文件调入存储器中然后执行它,这个程序的执行实例成为进程。
在Linux中每个进程都对应唯一的非负数据标识符,成为进程ID
有8种方式可以终止一个进程:
- 在main中return
- 调用exit函数
- 调用_exit或者_Exit函数终止进程
- 最后一个线程从其启动例程返回
- 最后一个线程调用了pthread_exit函数
- 调用abort函数
- 接到一个信号并且终止
- 最后一个线程对取消请求做出了响应
前5中为正常终止一个进程,后三种是异常终止。
在Linux操作系统中,内核使程序执行的唯一方法是调用一个exec函数,进程自愿终止的唯一方法是显式或者隐式的调用_exit或者_Exit,又或者一个外部信号来使得该进程终止。、
在Linux中运行一个用户自行设计的可执行文件的流程:

C语言代码的程序存储空间
目标对象: 用户的C语言代码编译生成的可执行文件
这些可执行文件的存储空间可以分为几个部分:
-
正文段: 存放了处理器执行的机器指令,通常来说正文段可以共享
所以包括shell、gcc在内的程序在存储器中只需要一个副本
正文段通常来说是只读的,为了防止程序的可执行代码被恶意修改
-
初始化数据段: 通常又被 称为数据段,包含了程序中需要进行初始化的变量值
通常是全局变量,非全局变量在调用时才分配空间并初始化
-
非初始化数据段: 和初始化数据段是对应的,用来存放不需要初始化(其实是被自动初始化为0或者空指针)的变量,这个段又被称为bss段
-
栈:存放自动变量以及每次函数调用时要保存的信息
-
堆:用于动态存储分配,这个段位于非初始化数据段和栈之间。在很多场合下和栈被合称堆栈段
对于一个可执行文件,通常还有若干其他类型的段。例: 包含符号表的段,包含gdb调试信息的段和包含动态共享库链接表的段,但是这些段并不会在进程调用的时候被装入存储区中。
在shell命令行中,可以使用size命令查看一个可执行文件的正文段、数据段和bss段的长度信息,单位:字节

Linux对这些字段的典型安排方式,正文通常从0x0804800地址单元开始,而栈底则位于0xC0000000之下从高地址向低地址方向增长。

C语言代码的main函数和参数
main函数的标准调用格式说明:
int main(int argc,char*argv[])
在main的两个参数中,argc整型,是命令行参数的数目
argv指向字符串的指针数组,这些指针分别指向各个命令行参数
当Linux使用exec函数来启动一个c语言的生成可执行文件的时候,其在调用main函数之前先调用一个特殊的启动例程,并且将此启动例程指定为程序的起始位置,这个启动例程将从内核取得该可执行文件的命令行参数和环境变量值,然后传递给main函数
在Linux命令行下键入文件名,再输入实际参数即可把这些实参传送到main函数中
可执行文件名 参数1 参数2 ...
参数均按字符串处理
指针数据的长度即为参数个数,数组元素初值由系统自动赋值。
注意: main的两个形参和命令行中的参数在位置上不是一一对应的,因为main的形参只有两个,而命令行中的参数个数原则上未加限制。
第一个参数(字符串)是可执行文件的文件名
argc参数表示了命令行中参数的个数,可执行文件名本身也算一个参数。
argc的值是在输入命令行时由系统按实际参数的个数自动赋值的。
main函数的参数可以省略在应用中的参数输入读取步骤,即不需要调用相应的输入代码等待用户的输入
若不需要传递参数,可以省略main的参数
main函数也带有返回值,默认类型为int ,返回值会直接传递给linux内核。
若main函数的最后没有写return 语句,gcc会自动在生成的目标文件中加入return 0,表示程序正常退出。
main函数的返回值可以将执行的相应结果反馈给内核。

C 语言代码的出错处理
在Linux中,如果调用的函数出现出错事件,往往会返回一个负值,并且此时整型变量errno常常会被设置为含有附加信息的一个值。
在errno.h文件中Linux定义了常用的错误常量。
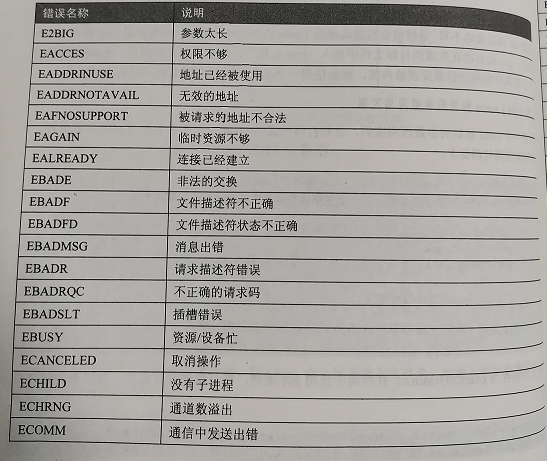
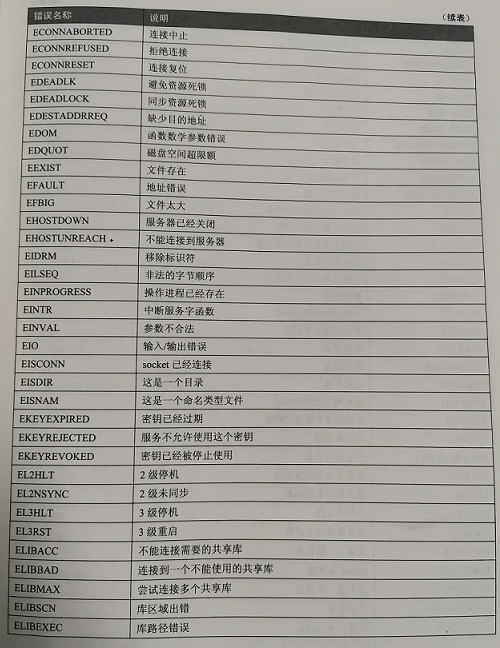

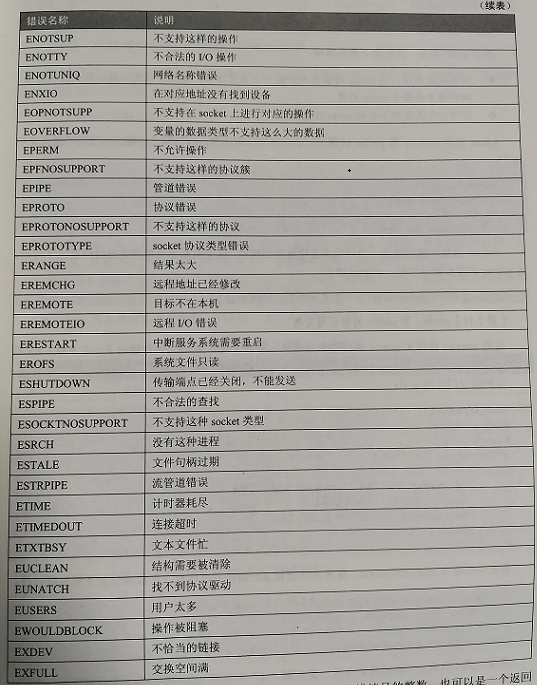
在Linux系统中,errno可以是一个包含出错编号的整数,也可以是一个返回出错编号指针的函数。
定义: extern int errno;
对于errno而言,有如下两条规则:
- 如果没有出错,则errno的值并不会被一个例程清除,因此可以当函数返回值指明出错的时候才去检查errno的值
- 任何一个函数都不会把errno的值设置为0
Linux使用strerror和perror函数来打印相应的出错信息。
这两个函数的标准调用格式说明:
#include<string.h>
char* strerror(int errnum);
#include<stdio.h>
void perror(const char*msg);
strerror函数的返回值是一个指向消息字符串的指针,这个消息字符串即为出错信息的字符串。
perror函数没有返回值,其输出如下:
"由msg指针指向的字符串" + ":" +"errno值表示的错误"+ "回车换行"
一个实例:
分别调用strerror函数输出一个EACCES错误值对应的错误提示,调用perror函数给出一个带调用执行文件名的错误提示。
#include<string.h>
#include<stdio.h>
#include<errno.h>
int main(int agrc,char* argv[]){
fprintf(stderr,"EACCES:%s\n",strerror(EACCES)); //stderr 标准错误
errno=ENOSPC; //传递错误标号
perror(argv[0]);
return 0;
}
输出结果:

C语言代码的标准输入和输出函数
-
printf()
#include<stdio.h> int printf(const char*format,...); 如果输出成功,函数的返回值为输出的字符数目,如果输出失败,返回一个负数 format的格式说明: %_flags_width_.precision_{ b|B|l|L}_type flags是标记: - 左对齐 + 有符号,数值总是以正负号开始 空格 数字总是以符号或者空格开始 * 忽略 -
scanf()
#include<stdio.h> int scanf(const char*format,...); 如果函数调用成功则返回指定的输入项数,若输入出错或在任意变换前已至文件尾端则为EOF
C语言代码的时间处理
Linux内核提供了一些相应的函数用于获取时间
#include<time.h>
char*asctime(const struct tm*tm);
char*asctime_r(const struct tm* tm,char*buf);
char*ctime(const time_t*timep);
char*ctime_r(const time_t*timep,char*buf);
struct tm*gmtime(const time_t*timep);
struct tm*gmtime_r(const time_t*timep,struct tm*result);
struct tm*localtime(const time_t*timep);
struct tm*localtime_r(const time_t*timep,struct tm*result);
time_t mktime(struct tm*tm);
int gettimeofday(struct timeval*tv,struct timezone*tz);
int settimeofday(const struct timeval*tv,const struct timezone*tz);
各个时间函数的关系说明:
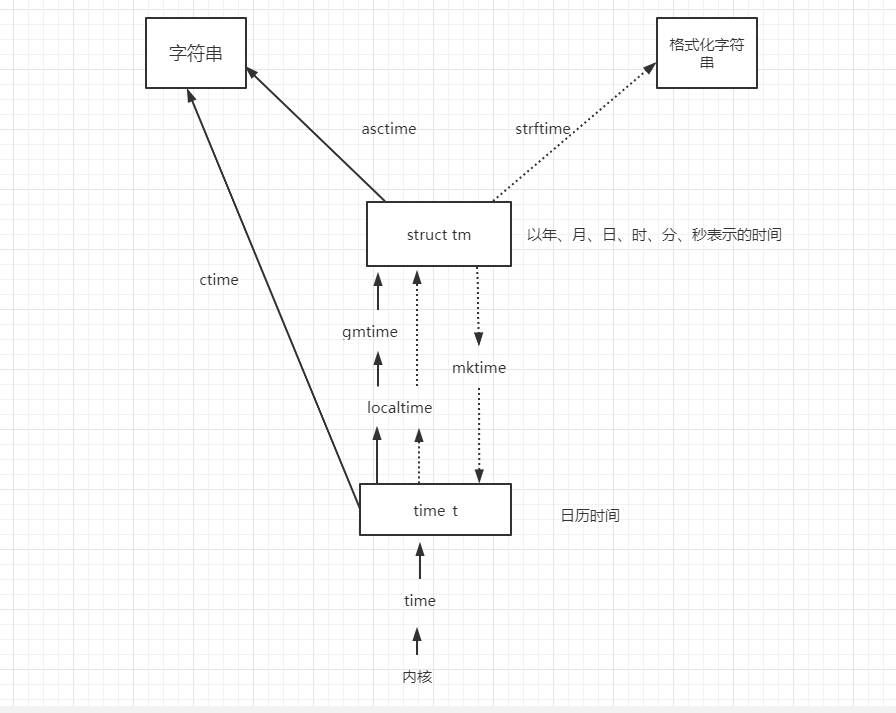
函数详解:
-
asctime函数
将参数timeptr所指向的tm结构中的信息转换成真实世界所使用的时间日期表示方法,将结果以字符串的方式返回。
字符串表示格式: “Wed Jun 30 21:48:00 2000/n”
此函数与ctime的不同之处在于传入的参数是不同的结构。
tm时间信息结构:
struct tm{ int tm_sec; //秒 int tm_min; //分 int tm_hour; //时 int tm_mday; //日 int tm_mon; //月 从0开始 ,结果要加1 int tm_year; //年 从1900年开始的 结果要加1900 int tm_wday; //星期 int tm_yday; //从1月1日开始到当日日期的编号 int tm_isdst;//夏令时标识符,实行夏令时的时候,tm_isdst为正,不实行夏令时为0,不了解情况时为负。 };夏令时,表示为了节约能源,人为规定时间的意思。也叫夏时制,夏时令(Daylight Saving Time:DST),又称“日光节约时制”和“夏令时间”,在这一制度实行期间所采用的统一时间称为“夏令时间”。
一般在天亮早的夏季人为将时间调快一小时,可以使人早起早睡,减少照明量,以充分利用光照资源,从而节约照明用电。各个采纳夏时制的国家具体规定不同。全世界有近110个国家每年要实行夏令时。
-
asctime_r函数
是asctime函数的一个扩展,提供了一个缓冲器件buf用于存放返回值,该缓冲区的长度不能低于26个字节。
-
ctime函数
将参数timep所指向的time_t结构中的信息转换为真实世界中所使用的时间日期格式,然后将结果以字符串的形态返回。
“Wed Jun 30 21:48:00 2000/n”
-
ctime_r函数
和ctime函数功能相同,也提供一个缓冲区用于存放返回值
-
gmtime函数
将所指的time_t结构中的信息转换为真实世界所使用的时间日期表示方法,然后将结果返回到tm结构体中
-
gmtime_r函数
和gmtime类似,提供一个由result指针指向的内存空间,用于存放返回值
-
localtime函数
当地的目前时间和日期,将其参数timep所指的结构体中的信息转换为真实世界所使用的时间日期表示方法,然后返回
-
localtime_r函数
和localtime类似,同时提供一个由result指针指向的内存空间,用于存放返回值
-
mktime函数
将参数tm所指向的结构体数据转换为从1970.1.1 0:0:0开始所经历的秒数,然后返回
-
gettimeofday函数
获取当前时间和时区信息,需要超级用户权限。
tv参数用于指向存放返回时间信息的缓冲区。
结构说明:
struct timeval{ time_t tv_sec; //秒 suseconds_t tv_usec; //微秒 }tz用于存放相应的时钟信息,结构如下:
struct timezone{ int tz_minuteswest; //minutes west of Greenwich 格林威治以西的分钟数 int tz_dsttime; //type of DST correction 夏时制校正 } -
settimeofday 函数
用于设置当前时间和时区信息,参数和用法和gettimeofday类似
时间结构体类型: time_t
time(time_t *)函数 可以用于获得时间参数
例:打印当前Linux系统的时间信息
#include<stdio.h>
#include<time.h>
int main(){
time_t timetemp; //定义一个时间结构体变量
char * wday[]={
"SUN","MON","TUE","WED","THU","FRI","SAT"};
struct tm *p; //定义结构体指针
time(&timetemp); //获取时间参数
printf("%s",asctime(gmtime(&timetemp)));//不是本时区的时间
p=localtime(&timetemp);
printf("%d:%d:%d\n",1900+p->tm_year,1+p->tm_mon,p->tm_mday);//年份要加1900校正,月份加1校正
printf("%s %d:%d:%d\n",wday[p->tm_wday],p->tm_hour,p->tm_min,p->tm_sec);
return 0;
}
结果:

例: 计算代码运行时间
#include<stdio.h>
#include<sys/time.h>
int main(){
//获取秒和微秒时间,现实和Greenwich的时间差,并且测试运行这段代码需要的时间
struct timeval time1,time2; //struct timeval 包含在头文件 sys/time.h中
struct timezone timez;
gettimeofday(&time1,&timez);
printf("tv_sec: %d, tv_usec: %d\n",(int)(time1.tv_sec),(int)(time1.tv_usec));
printf("tv_minuteswest: %d, tz_dsttime: %d\n",(int)(timez.tz_minuteswest),(int)(timez.tz_dsttime));
gettimeofday(&time2,&timez);
printf("interval: %d\n",(int)(time2.tv_usec-time1.tv_usec));
return 0;
}
要包含头文件: sys/time.h
结果:

time.h 是 ISO C99 标准日期时间头文件。
sys/time.h 是 Linux系统 的日期时间头文件。sys/time.h 通常会包含 #include <time.h> 。
编写的代码如果是平台无关的,则需要在代码里include time.h,但这样的话,使用time_t等数据结构的话可能需要手动:
#define __need_time_t
#define __need_timespec
通常如果代码可以是平台相关的,则只需要include <sys/time.h>。
C语言代码的分配机制
三个用于存储空间动态分配的函数和一个用于释放内存空间的函数
-
malloc: 给进程分配指定字节数的存储区,分配后,初始值不为0
-
calloc: 为指定流数量具有指定长度的对象分配存储空间,该空间中每一位都被初始化为0
-
realloc: 更改以前分配区的长度(可增可减),当为增加长度时,可能需要将以前分配区间的内容迁移到另一个足够大的区域,在尾部提供增加的存储区,而新增加的区间内的初始值不确定。
-
free函数:释放参数指针指向的存储区间
三个分配函数调用成功,返回一个指向分配区的非空指针,否则返回空指针,free函数没有返回值
#include<stdio.h>
void *malloc(size_t size);
void *calloc(size_t nobj,size_t size);
void *realloc(void *ptr,size_t newsize); //newsize 是新分配的存储区长度,而不是分配后的存储区的总长度
void free(void*ptr);
对于realloc函数,如果ptr指向一个空指针的话,则realloc函数的功能和malloc是完全相同的。
三个分配函数通常都是通过调用sbrk系统调用来实现的。
对该系统调用的标准化格式说明:
#include<unistd.h>
int brk(void *addr);
void *sbrk(intptr_t increment);
在内存空间使用完成之后必须立即释放,否则可能导致内存泄露。
C语言代码的系统调用和库函数
Linux内核提供了一些内建函数可以用来完成一些系统级别的功能,这些函数称为"系统函数",systemcall,这些函数代表了从用户空间到内核空间的一种转换。
系统调用的相关声明可以在syscall.h中找到,这些系统调用都对应一个具体的数字,Linux内核通过位于0x80的中断来管理这些系统调用,而这些系统调用的对应数字和相应的参数都在被调用的时候送到对应的寄存器中。
系统调用的数字实际上是一个序列号,表示其在系统的一个数组sys_call_table[]中的位置 。
在具体的使用中,Linux为这些系统调用在标准c函数库中设置了一个具有相同名字的函数,用户可以通过相应的调用方法来对这些函数进行调用,然后这些函数使用系统所需要的技术调用相应的内核服务。从应用角度来说,可以将这些系统调用看成C语言函数。
Linux还提供了一些通用库函数,以供用户调用。
从操作系统的角度来说,系统调用和库函数的实现方法有重大的区别,但从用户角度来看是一样的。
很多实际应用中,应用程序会调用系统调用或者库函数,库函数又会调用系统调用。
Linux下库函数和系统调用的关系:

系统调用通常只提供一种最小化的接口,而库函数通常提供比较复杂的功能。
在必要的时候,可以修改或者替换库函数,但是不可以替换或者修改系统调用。
//sqrtf是平方根函数
#include<math.h>
float sqrtf(float x);