yolox作为当下地表最强的目标检测算法,用yolox来做工程必定能事半功倍。然而,mmdetection训练yolox的配置文件写法与faster-rcnn有些不太一样,如果直接套用faster-rcnn的配置文件会存在多个异常。且在网上很难找到mmdetection用yolox训练coco数据集的案例,为此博主经过多次实践通过实践,最终实现了yolox的训练,并找出了yolox与faster-rcnn的配置文件编写的不同。
博主发现yolox与faster-rcnn的配置文件存在以下不同:1.在修改模型输出的class上有所不同、2。在设置数据集的方式上有所不同、3.在lr_config设置方式的上有所不同、4.设置输入数据size方式的不同。为此撰写博客分享经验,完整的yolox训练配置代码在博客的最后面。
1、num_classes设置的区别
faster-rcnn:
model = dict(
roi_head=dict(bbox_head=dict(num_classes=len(classes))))yolox:
model = dict(
#roi_head=dict(bbox_head=dict(num_classes=len(classes))))
bbox_head=dict(type='YOLOXHead', num_classes=len(classes)))用faster-rcnn的方式设置yolox的输出头会报以下错误

2、在设置数据集的方式上有所不同
虽然yolox与faster-rcnn都设置用coco数据集进行训练,但是yolox的config中会将训练数据的datatype调整为MultiImageMixDataset,具体可以下图所示
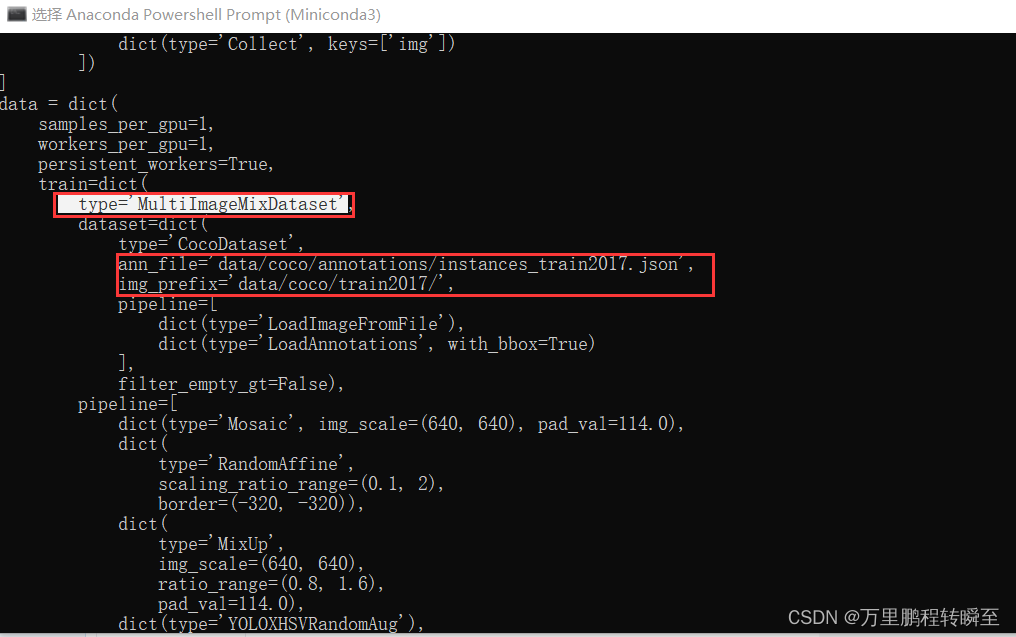
在相同的配置中,如下图所示。faster-rcnn已经可以正常训练模型了,而yolox则会保存,提示FileNotFoundError: CocoDataset: [Errno 2] No such file or directory: 'data/coco/annotations/instances_train2017.json'。
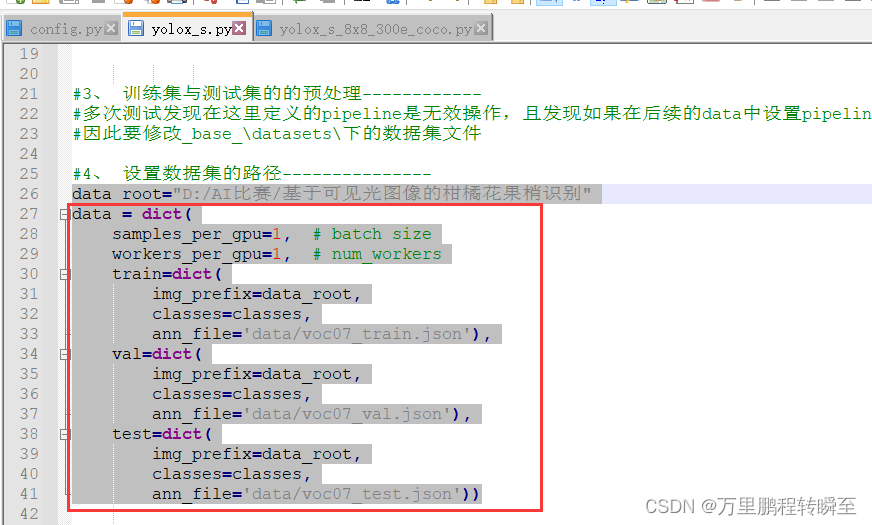
这是因为yolox的train daset中多了一个dataset对象,因此需要对dataset进行设置,且要将train dataset的type调整为MultiImageMixDataset。所以,在yolox中数据的设置要按照以下格式调整。
data = dict(
samples_per_gpu=1, # batch size
workers_per_gpu=1, # num_workers
train=dict(
type='MultiImageMixDataset',
dataset=dict(
type='CocoDataset',
ann_file='data/voc07_train.json',
img_prefix=data_root,
classes=classes,
filter_empty_gt=False),
),
val=dict(
img_prefix=data_root,
classes=classes,
ann_file='data/voc07_val.json'),
test=dict(
img_prefix=data_root,
classes=classes,
ann_file='data/voc07_test.json'))3、lr_config设置的区别
博主一开始也是以为yolox的学习率调度方式应该是可以与faster-rcnn通用的,结果出乎意料。faster-rcnn与yolox支持的学习率调度方式不太一样。
faster-rcnn默认的调度器:
lr_config = dict(
policy='step',
warmup='linear',
warmup_iters=500,
warmup_ratio=0.001,
step=[7])yolox默认的学习率调度器:
lr_config = dict(
_delete_=True,
policy='YOLOX',
warmup='exp',
by_epoch=False,
warmup_by_epoch=True,
warmup_ratio=1,
warmup_iters=5, # 5 epoch
num_last_epochs=10,
min_lr_ratio=0.05)如果yolox使用faster-rcnn的学习率调度器,则因为config的继承关系会报以下错误。因为yolox默认的学习率调度器(policy=‘YOLOX’)中存在num_last_epochs参数,而faster-rcnn默认的调度器(policy=‘step’)中不存在该参数。
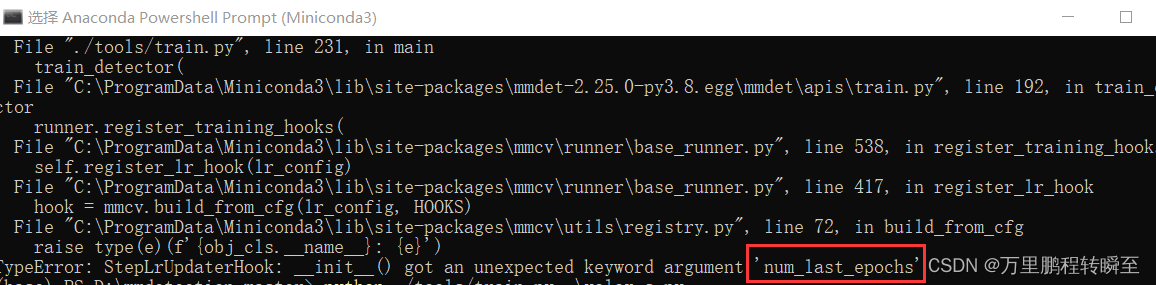
4、设置数据输入size的区别
faster-rcnn的模型配置文件中不存在图像size的设置参数,是通过设置configs\_base_\datasets\coco_detection.py中的size来控制输入图像的size,具体可见图5
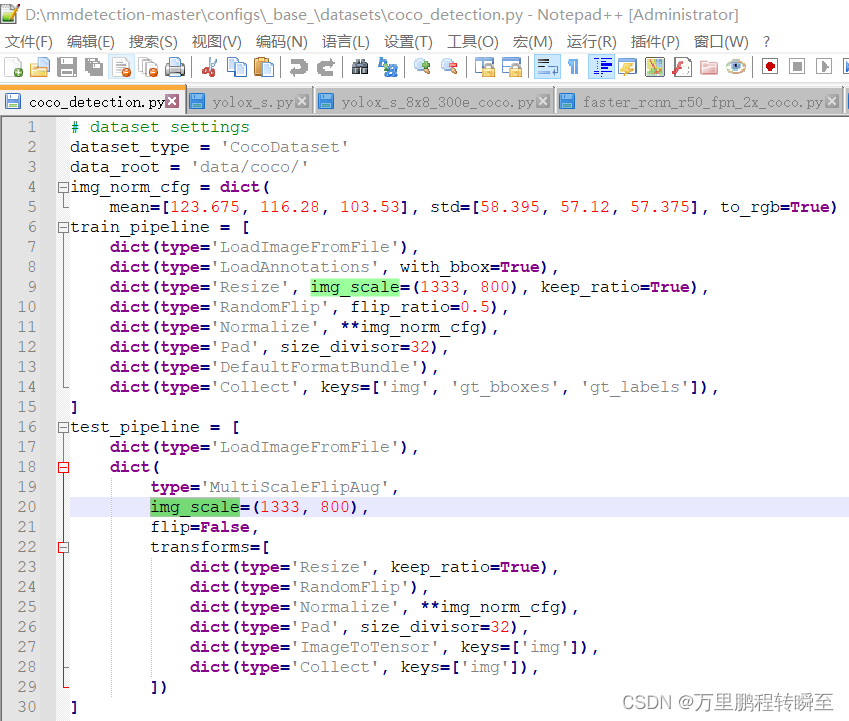
然而,在yolox中,模型的配置文件对pipeline进行的调整,设置输入数据的size需要到configs\yolox\yolox_s_8x8_300e_coco.py中设置
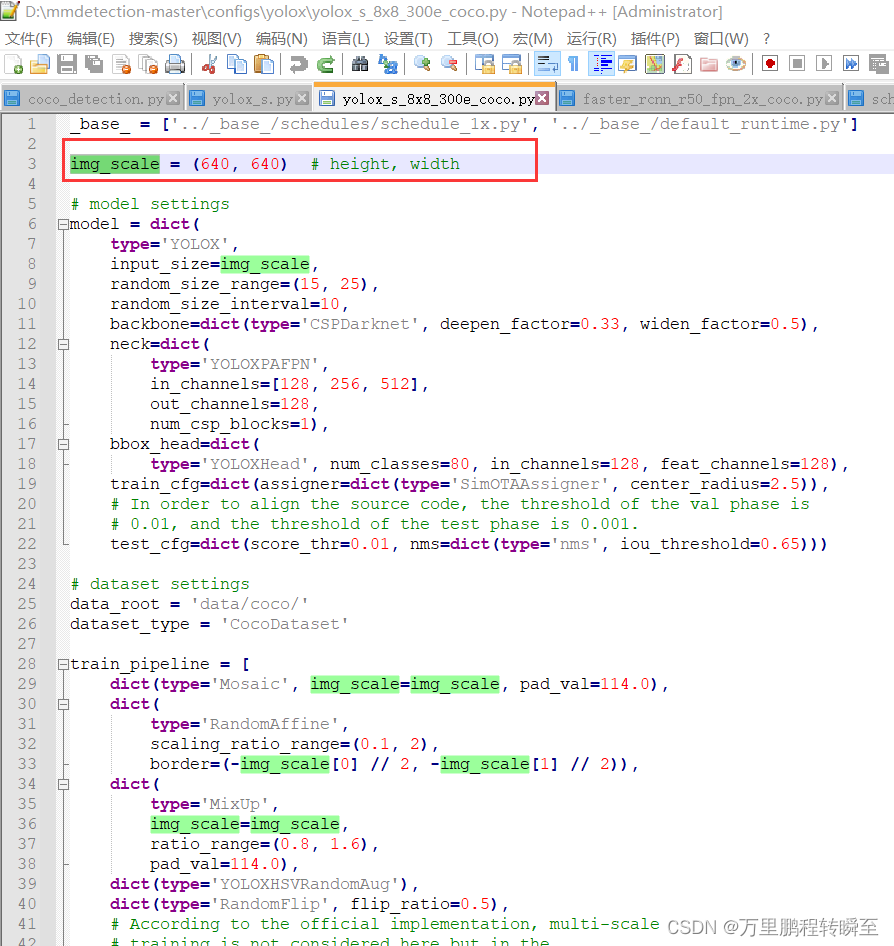
5、完整的yolox训练配置文件
完整的训练配置文件如下所示,博主的数据集这里只有shoot一个类别,博主的图片路径在‘D:/AI比赛/基于可见光图像的柑橘花果梢识别’下,而coco数据在mmdetection的data下。因为博主的coco数据是由voc数据转换而来的,数据集转换方式可以参考下列链接的第一章,配置文件编写得按本博客的来。mmdetection2的使用教程从数据处理、配置文件到训练与测试(支持coco数据和pascal_voc数据)_万里鹏程转瞬至的博客-CSDN博客_mmdetection2本文主要讲述mmdetection的训练与测试,以数据处理为起点,到数据集划分、数据集转换、配置文件编写、模型训练与测试和使用。由于mmdetection2默认的数据格式是coco格式,而labelimg生成的标注文件却是xml(最贴近voc数据),为此以coco数据集为基准。我们可以使用mmdetection中的数据转换方法将pascal_voc数据集转换为coco数据集,从而实现对coco数据和pascal_voc数据的支持。pascal_voc数据集转换为coco数据集前需要注意,一定要先划分数据集(https://hpg123.blog.csdn.net/article/details/124617894
# 这个新的配置文件继承自一个原始配置文件,只需要突出必要的修改部分即可
_base_ = './configs/yolox/yolox_s_8x8_300e_coco.py'
#1、 修改数据集相关设置----------
#数据集类型
dataset_type = 'COCODataset'
#label值
classes = ('shoot',)
#2、 设置训练超参数----------
#修改模型分类数
model = dict(
#roi_head=dict(bbox_head=dict(num_classes=len(classes))))
bbox_head=dict(type='YOLOXHead', num_classes=len(classes)))
#要加载的预训练权重
#load_from="./work_dirs/faster_rcnn_r50_fpn_1x_coco/epoch_12.pth"
#训练的epcoh数
runner = dict(type='EpochBasedRunner', max_epochs=3)
#3、 训练集与测试集的的预处理------------
#多次测试发现在这里定义的pipeline是无效操作,且发现如果在后续的data中设置pipeline会导致报错
#因此要修改_base_\datasets\下的数据集文件
#4、 设置数据集的路径---------------
data_root="D:/AI比赛/基于可见光图像的柑橘花果梢识别"
data = dict(
samples_per_gpu=1, # batch size
workers_per_gpu=1, # num_workers
train=dict(
type='MultiImageMixDataset',
dataset=dict(
type='CocoDataset',
ann_file='data/voc07_train.json',
img_prefix=data_root,
classes=classes,
filter_empty_gt=False),
),
val=dict(
img_prefix=data_root,
classes=classes,
ann_file='data/voc07_val.json'),
test=dict(
img_prefix=data_root,
classes=classes,
ann_file='data/voc07_test.json'))
#5、 训练策略设置
optimizer = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0001)
optimizer_config = dict(grad_clip=None)
# 学习策略
lr_config = dict(
_delete_=True,
policy='YOLOX',
warmup='exp',
by_epoch=False,
warmup_by_epoch=True,
warmup_ratio=1,
warmup_iters=5, # 5 epoch
num_last_epochs=50,
min_lr_ratio=0.05)训练方法:进入mmdetection的代码路径,将上述的配置文件保存为yolox_s.py,并执行训练代码即可。
训练代码: python ./tools/train.py .\yolox_s.py
yolox模型的预训练模型下载链接为:mmdetection: 同步更新官方最新版 mmdetectionhttps://github.com/open-mmlab/mmdetection - Gitee.com