1. synchronized 的实现原理以及锁优化?
synchronized 的实现原理
- synchronized 作用于「方法」或者「代码块」,保证被修饰的代码在同一时间只能被一个线程访问。
- synchronized 修饰代码块时,JVM 采用「monitorenter、monitorexit」两个指令来实现同步
- synchronized 修饰同步方法时,JVM 采用「ACC_SYNCHRONIZED」标记符来实现同步
- monitorenter、monitorexit 或者 ACC_SYNCHRONIZED 都是「基于 Monitor 实现」的
- 实例对象里有对象头,对象头里面有 Mark Word,Mark Word 指针指向了「monitor」
- Monitor 其实是一种「同步工具」,也可以说是一种「同步机制」。
- 在 Java 虚拟机(HotSpot)中,Monitor 是由「ObjectMonitor 实现」的。ObjectMonitor 体现出 Monitor 的工作原理~
ObjectMonitor() {
_header = NULL;
_count = 0; // 记录线程获取锁的次数
_waiters = 0,
_recursions = 0; //锁的重入次数
_object = NULL;
_owner = NULL; // 指向持有ObjectMonitor对象的线程
_WaitSet = NULL; // 处于wait状态的线程,会被加入到_WaitSet
_WaitSetLock = 0 ;
_Responsible = NULL ;
_succ = NULL ;
_cxq = NULL ;
FreeNext = NULL ;
_EntryList = NULL ; // 处于等待锁block状态的线程,会被加入到该列表
_SpinFreq = 0 ;
_SpinClock = 0 ;
OwnerIsThread = 0 ;
}
ObjectMonitor 的几个关键属性 count、recursions、owner、WaitSet、 _EntryList 体现了 monitor 的工作原理

锁优化
在讨论锁优化前,先看看 JAVA 对象头 (32 位 JVM) 中 Mark Word 的结构图吧~
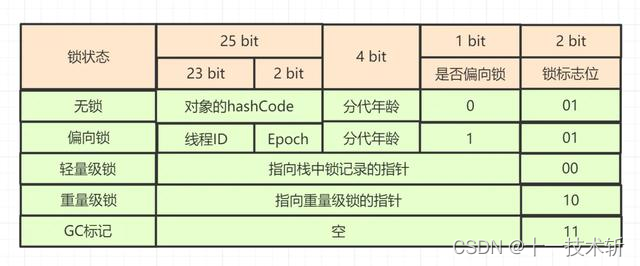
Mark Word 存储对象自身的运行数据,如「哈希码、GC 分代年龄、锁状态标志、偏向时间戳(Epoch)」 等,为什么区分「偏向锁、轻量级锁、重量级锁」等几种锁状态呢?
❝
在 JDK1.6 之前,synchronized 的实现直接调用 ObjectMonitor 的 enter 和 exit,这种锁被称之为「重量级锁」。从 JDK6 开始,HotSpot 虚拟机开发团队对 Java 中的锁进行优化,如增加了适应性自旋、锁消除、锁粗化、轻量级锁和偏向锁等优化策略。
❞
- 偏向锁:在无竞争的情况下,把整个同步都消除掉,CAS 操作都不做。
- 轻量级锁:在没有多线程竞争时,相对重量级锁,减少操作系统互斥量带来的性能消耗。但是,如果存在锁竞争,除了互斥量本身开销,还额外有 CAS 操作的开销。
- 自旋锁:减少不必要的 CPU 上下文切换。在轻量级锁升级为重量级锁时,就使用了自旋加锁的方式
- 锁粗化:将多个连续的加锁、解锁操作连接在一起,扩展成一个范围更大的锁。
❝
举个例子,买门票进动物园。老师带一群小朋友去参观,验票员如果知道他们是个集体,就可以把他们看成一个整体(锁租化),一次性验票过,而不需要一个个找他们验票。
❞
- 锁消除:虚拟机即时编译器在运行时,对一些代码上要求同步,但是被检测到不可能存在共享数据竞争的锁进行消除。
有兴趣的朋友们可以看看我这篇文章: Synchronized 解析 —— 如果你愿意一层一层剥开我的心 [1]
2. ThreadLocal 原理,使用注意点,应用场景有哪些?
回答四个主要点:
- ThreadLocal 是什么?
- ThreadLocal 原理
- ThreadLocal 使用注意点
- ThreadLocal 的应用场景
ThreadLocal 是什么?
ThreadLocal,即线程本地变量。如果你创建了一个 ThreadLocal 变量,那么访问这个变量的每个线程都会有这个变量的一个本地拷贝,多个线程操作这个变量的时候,实际是操作自己本地内存里面的变量,从而起到线程隔离的作用,避免了线程安全问题。
//创建一个ThreadLocal变量 static ThreadLocal<String> localVariable = new ThreadLocal<>();
ThreadLocal 原理
ThreadLocal 内存结构图:
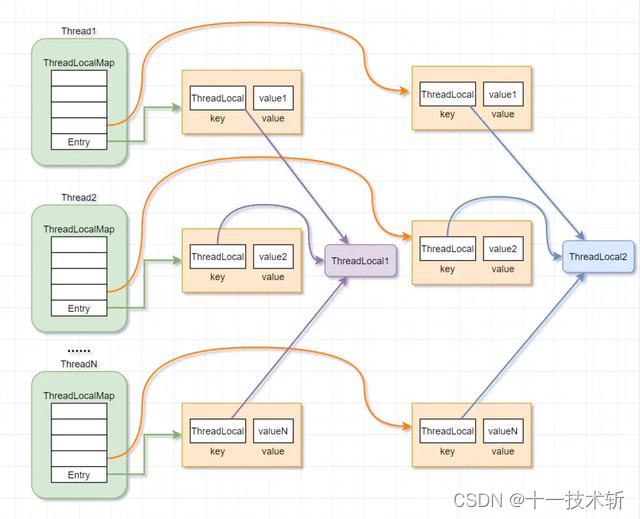
由结构图是可以看出:
- Thread 对象中持有一个 ThreadLocal.ThreadLocalMap 的成员变量。
- ThreadLocalMap 内部维护了 Entry 数组,每个 Entry 代表一个完整的对象,key 是 ThreadLocal 本身,value 是 ThreadLocal 的泛型值。
对照这几段关键源码来看,更容易理解一点哈~
public class Thread implements Runnable {
//ThreadLocal.ThreadLocalMap是Thread的属性
ThreadLocal.ThreadLocalMap threadLocals = null;
}
ThreadLocal 中的关键方法 set () 和 get ()
public void set(T value) {
Thread t = Thread.currentThread(); //获取当前线程t
ThreadLocalMap map = getMap(t); //根据当前线程获取到ThreadLocalMap
if (map != null)
map.set(this, value); //K,V设置到ThreadLocalMap中
else
createMap(t, value); //创建一个新的ThreadLocalMap
}
public T get() {
Thread t = Thread.currentThread();//获取当前线程t
ThreadLocalMap map = getMap(t);//根据当前线程获取到ThreadLocalMap
if (map != null) {
//由this(即ThreadLoca对象)得到对应的Value,即ThreadLocal的泛型值
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
ThreadLocalMap 的 Entry 数组
static class ThreadLocalMap {
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
}
所以怎么回答「ThreadLocal 的实现原理」?如下,最好是能结合以上结构图一起说明哈~
❝ Thread 类有一个类型为 ThreadLocal.ThreadLocalMap 的实例变量 threadLocals,即每个线程都有一个属于自己的 ThreadLocalMap。ThreadLocalMap 内部维护着 Entry 数组,每个 Entry 代表一个完整的对象,key 是 ThreadLocal 本身,value 是 ThreadLocal 的泛型值。每个线程在往 ThreadLocal 里设置值的时候,都是往自己的 ThreadLocalMap 里存,读也是以某个 ThreadLocal 作为引用,在自己的 map 里找对应的 key,从而实现了线程隔离。 ❞
ThreadLocal 内存泄露问题
先看看一下的 TreadLocal 的引用示意图哈,

ThreadLocalMap 中使用的 key 为 ThreadLocal 的弱引用,如下
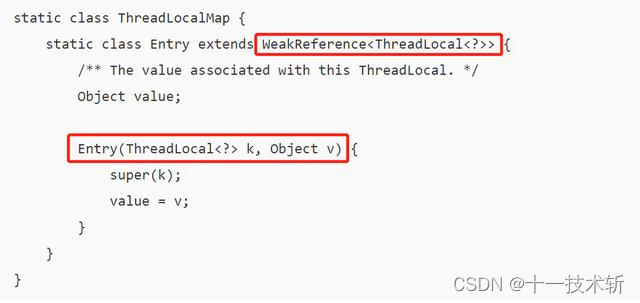
❝
弱引用:只要垃圾回收机制一运行,不管 JVM 的内存空间是否充足,都会回收该对象占用的内存。
❞
弱引用比较容易被回收。因此,如果 ThreadLocal(ThreadLocalMap 的 Key)被垃圾回收器回收了,但是因为 ThreadLocalMap 生命周期和 Thread 是一样的,它这时候如果不被回收,就会出现这种情况:ThreadLocalMap 的 key 没了,value 还在,这就会「造成了内存泄漏问题」。
如何「解决内存泄漏问题」?使用完 ThreadLocal 后,及时调用 remove () 方法释放内存空间。
ThreadLocal 的应用场景
- 数据库连接池
- 会话管理中使用
3. synchronized 和 ReentrantLock 的区别?
我记得校招的时候,这道面试题出现的频率还是挺高的~可以从锁的实现、功能特点、性能等几个维度去回答这个问题,
- 「锁的实现:」 synchronized 是 Java 语言的关键字,基于 JVM 实现。而 ReentrantLock 是基于 JDK 的 API 层面实现的(一般是 lock () 和 unlock () 方法配合 try/finally 语句块来完成。)
- 「性能:」 在 JDK1.6 锁优化以前,synchronized 的性能比 ReenTrantLock 差很多。但是 JDK6 开始,增加了适应性自旋、锁消除等,两者性能就差不多了。
- 「功能特点:」 ReentrantLock 比 synchronized 增加了一些高级功能,如等待可中断、可实现公平锁、可实现选择性通知。
❝ ReentrantLock 提供了一种能够中断等待锁的线程的机制,通过 lock.lockInterruptibly () 来实现这个机制。ReentrantLock 可以指定是公平锁还是非公平锁。而 synchronized 只能是非公平锁。所谓的公平锁就是先等待的线程先获得锁。synchronized 与 wait () 和 notify ()/notifyAll () 方法结合实现等待 / 通知机制,ReentrantLock 类借助 Condition 接口与 newCondition () 方法实现。ReentrantLock 需要手工声明来加锁和释放锁,一般跟 finally 配合释放锁。而 synchronized 不用手动释放锁。 ❞
4. 说说 CountDownLatch 与 CyclicBarrier 区别
- CountDownLatch:一个或者多个线程,等待其他多个线程完成某件事情之后才能执行;
- CyclicBarrier:多个线程互相等待,直到到达同一个同步点,再继续一起执行。
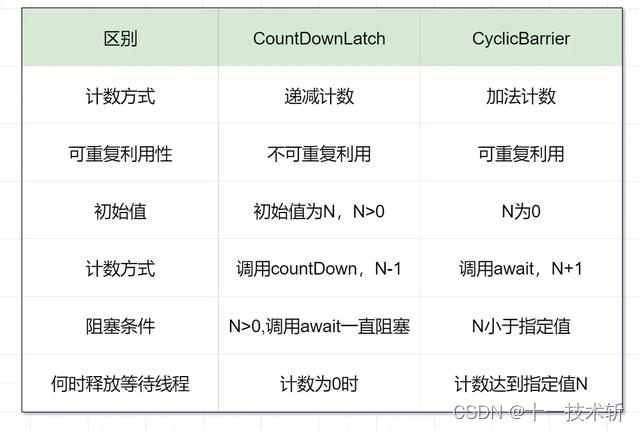
举个例子吧:
❝ CountDownLatch:假设老师跟同学约定周末在公园门口集合,等人齐了再发门票。那么,发门票(这个主线程),需要等各位同学都到齐(多个其他线程都完成),才能执行。CyclicBarrier: 多名短跑运动员要开始田径比赛,只有等所有运动员准备好,裁判才会鸣枪开始,这时候所有的运动员才会疾步如飞。 ❞
5. Fork/Join 框架的理解
❝
Fork/Join 框架是 Java7 提供的一个用于并行执行任务的框架,是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架。
❞
Fork/Join 框架需要理解两个点,「分而治之」和「工作窃取算法」。
「分而治之」
以上 Fork/Join 框架的定义,就是分而治之思想的体现啦

「工作窃取算法」
把大任务拆分成小任务,放到不同队列执行,交由不同的线程分别执行时。有的线程优先把自己负责的任务执行完了,其他线程还在慢慢悠悠处理自己的任务,这时候为了充分提高效率,就需要工作盗窃算法啦~
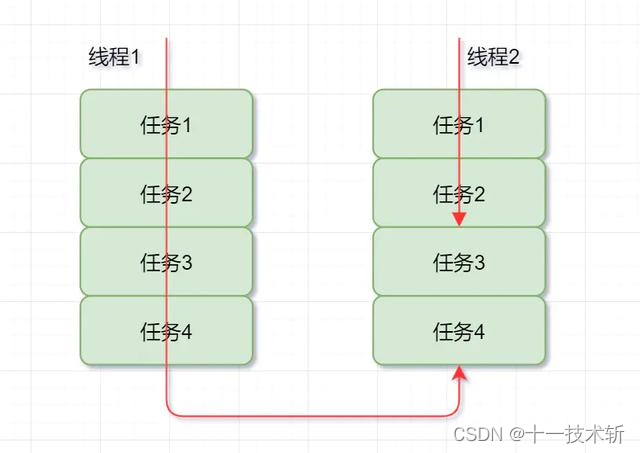
工作盗窃算法就是,「某个线程从其他队列中窃取任务进行执行的过程」。一般就是指做得快的线程(盗窃线程)抢慢的线程的任务来做,同时为了减少锁竞争,通常使用双端队列,即快线程和慢线程各在一端。
6. 为什么我们调用 start () 方法时会执行 run () 方法,为什么我们不能直接调用 run () 方法?
看看 Thread 的 start 方法说明哈~
/**
* Causes this thread to begin execution; the Java Virtual Machine
* calls the <code>run</code> method of this thread.
* <p>
* The result is that two threads are running concurrently: the
* current thread (which returns from the call to the
* <code>start</code> method) and the other thread (which executes its
* <code>run</code> method).
* <p>
* It is never legal to start a thread more than once.
* In particular, a thread may not be restarted once it has completed
* execution.
*
* @exception IllegalThreadStateException if the thread was already
* started.
* @see #run()
* @see #stop()
*/
public synchronized void start() {
......
}
JVM 执行 start 方法,会另起一条线程执行 thread 的 run 方法,这才起到多线程的效果~「为什么我们不能直接调用 run () 方法?」 如果直接调用 Thread 的 run () 方法,其方法还是运行在主线程中,没有起到多线程效果。
7. CAS?CAS 有什么缺陷,如何解决?
CAS,Compare and Swap,比较并交换;
❝
CAS 涉及 3 个操作数,内存地址值 V,预期原值 A,新值 B; 如果内存位置的值 V 与预期原 A 值相匹配,就更新为新值 B,否则不更新
❞
CAS 有什么缺陷?

「ABA 问题」
❝
并发环境下,假设初始条件是 A,去修改数据时,发现是 A 就会执行修改。但是看到的虽然是 A,中间可能发生了 A 变 B,B 又变回 A 的情况。此时 A 已经非彼 A,数据即使成功修改,也可能有问题。
❞
可以通过 AtomicStampedReference「解决 ABA 问题」,它,一个带有标记的原子引用类,通过控制变量值的版本来保证 CAS 的正确性。
「循环时间长开销」
❝
自旋 CAS,如果一直循环执行,一直不成功,会给 CPU 带来非常大的执行开销。
❞
很多时候,CAS 思想体现,是有个自旋次数的,就是为了避开这个耗时问题~
「只能保证一个变量的原子操作。」
❝
CAS 保证的是对一个变量执行操作的原子性,如果对多个变量操作时,CAS 目前无法直接保证操作的原子性的。
❞
可以通过这两个方式解决这个问题:
❝ 使用互斥锁来保证原子性;将多个变量封装成对象,通过 AtomicReference 来保证原子性。 ❞
有兴趣的朋友可以看看我之前的这篇实战文章哈~CAS 乐观锁解决并发问题的一次实践 [2]
8. 如何保证多线程下 i++ 结果正确?
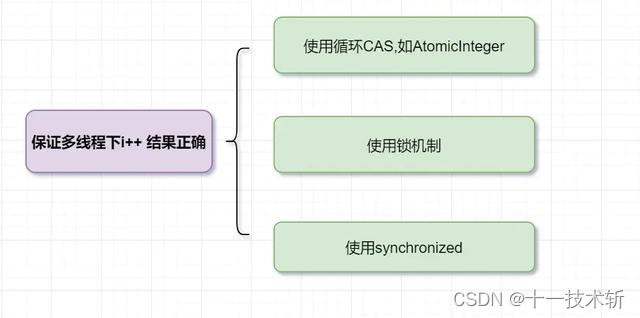
- 使用循环 CAS,实现 i++ 原子操作
- 使用锁机制,实现 i++ 原子操作
- 使用 synchronized,实现 i++ 原子操作
没有代码 demo,感觉是没有灵魂的~如下:
/**
* @Author 捡田螺的小男孩
*/
public class AtomicIntegerTest {
private static AtomicInteger atomicInteger = new AtomicInteger(0);
public static void main(String[] args) throws InterruptedException {
testIAdd();
}
private static void testIAdd() throws InterruptedException {
//创建线程池
ExecutorService executorService = Executors.newFixedThreadPool(2);
for (int i = 0; i < 1000; i++) {
executorService.execute(() -> {
for (int j = 0; j < 2; j++) {
//自增并返回当前值
int andIncrement = atomicInteger.incrementAndGet();
System.out.println("线程:" + Thread.currentThread().getName() + " count=" + andIncrement);
}
});
}
executorService.shutdown();
Thread.sleep(100);
System.out.println("最终结果是 :" + atomicInteger.get());
}
}
运行结果:
... 线程:pool-1-thread-1 count=1997 线程:pool-1-thread-1 count=1998 线程:pool-1-thread-1 count=1999 线程:pool-1-thread-2 count=315 线程:pool-1-thread-2 count=2000 最终结果是 :2000
9. 如何检测死锁?怎么预防死锁?死锁四个必要条件
死锁是指多个线程因竞争资源而造成的一种互相等待的僵局。如图感受一下:

「死锁的四个必要条件:」
- 互斥:一次只有一个进程可以使用一个资源。其他进程不能访问已分配给其他进程的资源。
- 占有且等待:当一个进程在等待分配得到其他资源时,其继续占有已分配得到的资源。
- 非抢占:不能强行抢占进程中已占有的资源。
- 循环等待:存在一个封闭的进程链,使得每个资源至少占有此链中下一个进程所需要的一个资源。
「如何预防死锁?」
- 加锁顺序(线程按顺序办事)
- 加锁时限 (线程请求所加上权限,超时就放弃,同时释放自己占有的锁)
- 死锁检测
怎么样,这几道题你遇到了能回答多少?
而这,只是常见的多线程,高并发以及 jvm 调优的源码问题中最常见的几道面试题,其他的面试题我已经整理到我的文档,并在不断地更新上传中
需要的同学可以私信我(资料)即可免费获取!
