在生产线上面,虽然etcd使用起来很简单,只需要put get watch这几条命令就可以将整个数据让它流转起来,在生产线上面etcd还有很多很多的问题,包括第一安全如何保证,第二高可用的etcd集群如何构建,第三数据如何备份,这些都和整个集群安全性息息相关。
Etcd成员重要参数

ETCD_NAME:节点名称,集群中唯一
参数有几类,第一类就是核心参数,最基本的参数,和成员相关,每个etcd成员都有它自己的名字,默认是default,所以去建Etcd集群的时候,什么参数都不加的时候,这个Etcd成员叫做default。
ETCD_NAME="etcd-1"
ETCD_NAME="etcd-2"
ETCD_NAME="etcd-3"ETCD_DATA_DIR:数据目录
etcd最终的数据落盘,etcd成员member的名字.etcd。
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"ETCD_LISTEN_PEER_URLS:集群通信监听地址
ETCD_LISTEN_CLIENT_URLS:客户端访问监听地址
支持两类的url,一类是peer url,因为etcd是集群,member和member之间的通信是走peer url的,客户端发送到etcd server的这种请求是走client url的,所以这两类不同的请求,不同类型的数据,它是用不同的端口提供数据的。
为了更好的保障说peer之间,可能它的优先级更加高,将来做网络调优的时候可以针对peer的端口去做网络层面的数据保证。
所以它们是隔离的,client走client,peer走peer。
ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.31.71:2380"
ETCD_ADVERTISE_CLIENT_URLS="https://192.168.31.71:2379"Etcd集群重要参数

ETCD_INITIAL_CLUSTER_STATE:加入集群的当前状态,new是新集群,existing表示加入已有集群
新建一个集群呢,还是启动一个etcd实例加入已存在的集群。
ETCD_INITIAL_CLUSTER_TOKEN:初始化集群Token
ETCD_INITIAL_ADVERTISE_PEER_URLS:集群通告地址
ETCD_ADVERTISE_CLIENT_URLS:客户端通告地址
对外宣告的地址是什么
Etcd安全相关的参数
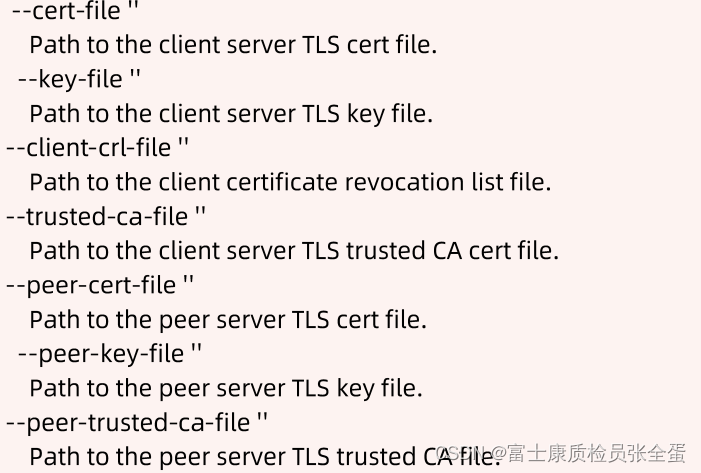
既然peer和client是两个端口,每一个端口都需要做安全保证的,etcd最常用的一种安全保障方式是mutal TLS,就是双向的TLS,一个是客户端要访问server的时候,要验证server端,一个是server端要验证你的客户端。
对应的每个端口上面都有相关的这种TLS配置参数,比如cert是什么,key是什么,client crl是什么。
要去访问一个TLS的etcd,那么就要带着它的key server 以及ca去访问。
--cert-file=/opt/etcd/ssl/server.pem \
--key-file=/opt/etcd/ssl/server-key.pem \
--peer-cert-file=/opt/etcd/ssl/server.pem \
--peer-key-file=/opt/etcd/ssl/server-key.pem \
--trusted-ca-file=/opt/etcd/ssl/ca.pem \
--peer-trusted-ca-file=/opt/etcd/ssl/ca.pem \
有了上面的参数就可以将集群搭建起来了。
灾备

有了上面这些参数就可以将集群搭建起来,搭建起来的集群是个多member的,这些member会在不同的节点上面,一个节点坏了,还有其他节点保存着数据,所以数据不会丢失。
通过这种情况,数据大部分是安全的,但是会有一些极端的情况,如果所有的member一起消失了,那么数据就丢掉了,所以这是不可忍受的。
比如etcd是以pod的方式跑起来的,pod本身它的数据盘有没有mount到外面来,这个pod因为某些原因导致它写入的数据太多,被驱逐了,驱逐之后这些数据就全部丢掉了,etcd所有的pod被驱逐,数据丢掉了。
数据丢了会意味着非常严重的问题,etcd保存了kubernetes集群当中所有重要的信息。
比如calico cni插件,他可以有自己的etcd,它会保存当前集群所有IP分配的信息,如果这个信息丢了,假设这个集群你跑了10W个Pod,这个集群10W个pod它IP分配情况是什么样的已经全部消失了,当你去启动新pod的时候,这个pod的IP在别的地方分配过你根本不知道,很可能是这个IP被重复分配,分配到另外一个节点或者当前节点pod上面。
它导致的问题非常严重,整个集群的IP就混乱了,那么可能就会发生两个pod抢占一个IP的情况,那么当用户来访问一个服务的时候,本来是要访问这个服务的,结果跳到另外一个服务上面去了,这是非常严重的问题,这种结果是谁也承受不了的。
所以etcd的数据安全性非常的重要,除了多副本保证数据安全性之外,我们还要经常性的去做备份。
备份的好处是即使实例掉了,那么还可以从备份还原,虽然时效性没有那么强,损失的数据从备份产生的时间点到当前的集群的时间点,如果备份频度越高,那么丢失的数据就越少。
etcd本身支持通过snapshot命令来为集群的数据创建快照,同时支持restore的命令将快照里面的信息回放出来,将数据恢复。
如何去构建一个kubernetes高可用集群,其实最后还是要看etcd的高可用怎么做,apiserver的高可用怎么做,control manager和scheduel调度器怎么做。
上面就是etcd的高可用方面的管理。
Etcd容量管理、碎片清理
容量管理

Etcd它给了一些建议,单个对象不超过1.5M,当你数据很大的时候,它的同步开销和内存快照的开销都非常大,会使得整个etcd的性能显著下降,所以建议对象不要太大。
etcd默认容量是2G,它不建议超过8G,一般生产系统就会设置为8G。
清理磁盘碎片 defrag

上面就是设置etcd存储大小为16M,然后不停往里面写数据,超过容量报错如下,集群被我写爆了,超出配额之后就没有办法写入数据了

现在处于alarm状态,出事了,没有空间了,对于alarm状态的集群来说,任何的写操作就不能成功了。
![]()

可以通过defrag清理硬盘,这个时候其实可以清理出一些硬盘空间,但是alarm的no space还在的,这个时候去写还是一样会报错。

所以要先去解除alarm,然后再去写入才能成功。 如果去做etcd的运维一定会出现这种情况,因为数据的写入导致磁盘的暴涨,导致db被撑爆了,这个时候会出现alarm状态,做了数据的清理如果想要继续写数据,要去先禁用一下alarm,这样才能数据的写入。
那么defrag是清理磁盘碎片,磁盘碎片清理还要其他操作,比如有compact命令,etcd是一个多版本的管理系统,在bolt db里面,它的所有的key都是version信息,所以它会有很多历史版本的信息,但是很多时候历史版本信息可能用不上了,这个时候我们希望它做一些压缩,那么它支持compact命令,让你指定reversion的版本,那么会将之前所有版本清除掉,这样节省空间。
其次defrag做磁盘碎片的整理,很多碎片导致磁盘的利用率不高,那么defrag一下就ok了。
etcd后面版本其实自动支持了compact,之前需要手动,在老版本里面etcd是非常需要运维的,经常会出现硬盘又被撑爆了,那么我们要去上线查原因,去从compcat,后面etcd支持自动的去做compcat这样一个操作。