一 核心思想
为了降低内存和计算成本,现有的基于point的pipeline通常采用随机采样或FPS采样来逐步下采样输入点云,尽管并非所有的点对目标检测任务都同等重要。特别是,前景点在本质上比背景点对目标探测器更重要。基于此,本文提出了一种高效的single-stage point-based 3D detection——IA-SSD。
该方法的关键是利用两种可学习的、面向任务的、实例感知的down sample strategy来分层次地选择属于object的foreground point。此外,我们还引入了contextual centroid perception module来进一步估计精确的object center。最后,为了提高效率,我们按照只使用encoder-only的体系结构构建IA-SSD。
本文的方法中借鉴了3DSSD的框架,主要的贡献在于将每一层的采样策略进行了调整,让每次down sample采样中,前景点都占大多数。
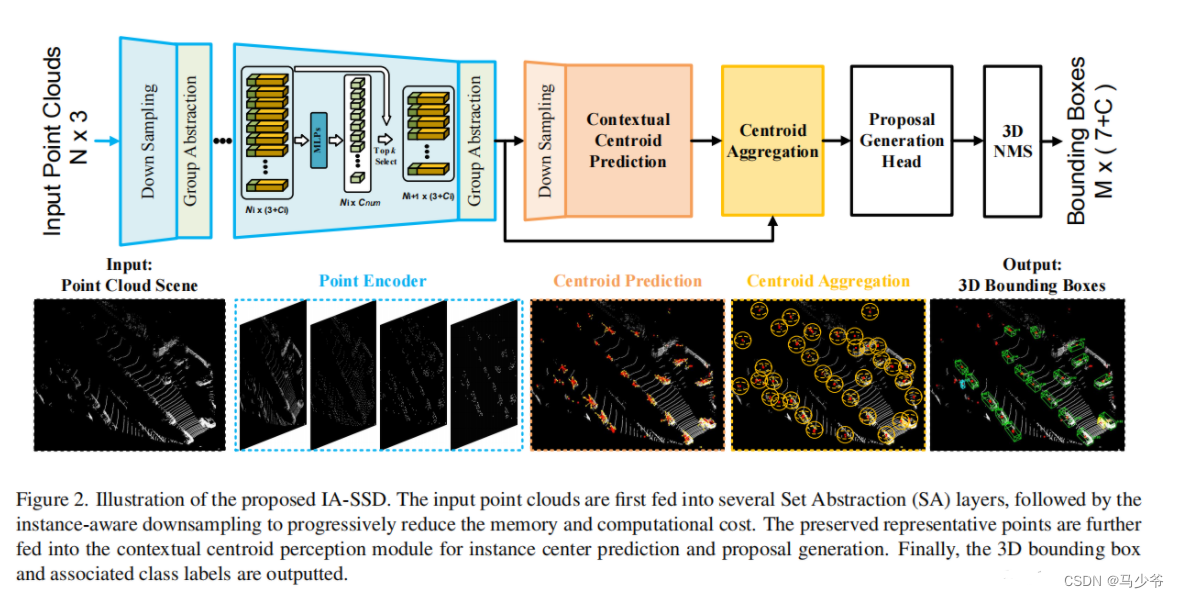
具体框架如下图所示:
二 核心步骤
现有的point-based的检测器在其框架中通常采用与任务无关的采样方法,如随机采样或最远点采样。尽管对于降低内存/计算成本有效,但在渐进式下采样中,最重要的foreground point也会减少。此外,由于不同物体的大小和几何形状存在很大差异,现有的探测器通常针对不同类型的物体训练具有各种精心调整的超参数的单独模型。然而,这不可避免地会影响这些模型在实践中的部署。因此,本文的目标是:能否训练出一种基于单点的模型,这种模型能够高效地一次检测出多类目标。
基于此,本文提出了一种高效的单级检测器,通过引入instance-aware downsampling和contextual centroid perception module。如上图所示, IA-SSD采用了3DSSD中的特征提取架构。首先将输入的LiDAR点云输入到网络中提取point features,然后提出instance-aware downsampling,以逐步降低计算成本,同时保留信息丰富的foreground point。学习到的潜在特征进一步输入到contextual centroid perception module,生成proposal并回归最终的边界框。
由此本文主要有两个重点: instance-aware downsampling和contextual centroid perception module。
2.1 Instance-aware Downsampling Strategy
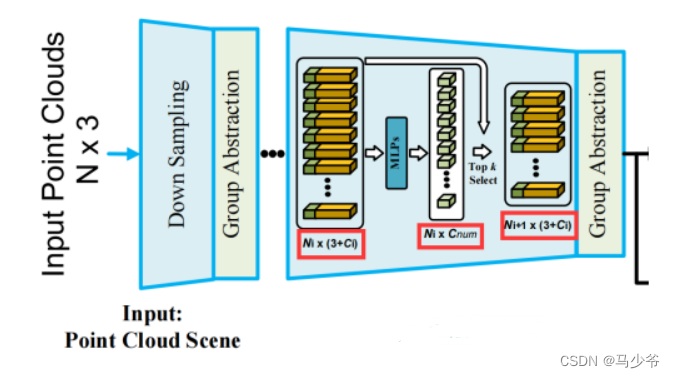
如上图所示,为了尽可能地保留foreground point,我们转向利用每个点的潜在语义,因为随着分层聚合在每个层中操作,学习到的点特征可能包含更丰富的语义信息。基于这一思想,我们提出了class-aware sampling和centroid-aware sampling两种面向任务的采样方法,将前景语义先验整合到网络训练pipeline中。
Class-aware sampling:就是在采样中,加入前景点的预测head,具体公式如下:

Centroid-aware sampling(只在training过程中被用到):这里就是在进行class-aware sampling时,考虑到距离object中心的点应该更被考虑到,因此使用了预测距离中心的权重head,具体公式如下:
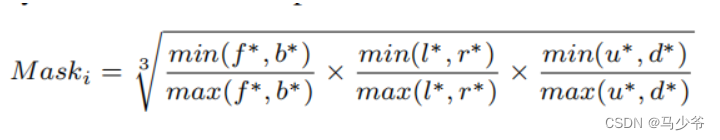
这个也是本人想的一种预测距离中心的方法。
这样子就可以将得分的损失函数改为:
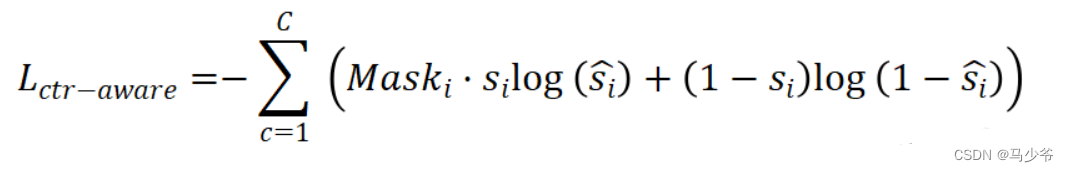
将soft point mask与foreground point的损失项相乘,使靠近中心的点具有更高的概率。注意,在inference过程中不再需要边界框,如果模型训练良好,我们只需保留下采样后得分最高的k个点。
经过上面的策略详解,我们的采样策略与其他策略对比如下所示:
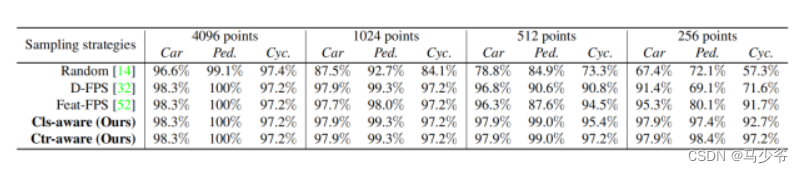
2.2 Contextual Instance Centroid Perception
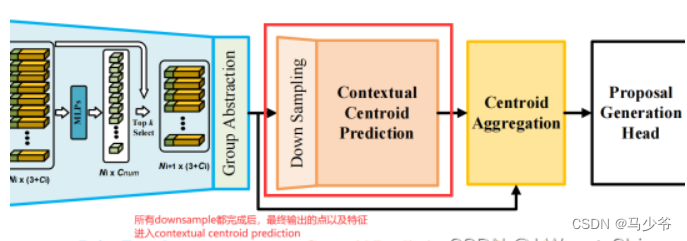
我们试图利用bounding box周围的上下文线索进行例如质心预测。具体来说,我们遵循VoteNet来显式预测到object中心的偏移量。(也就是进行聚集操作,如下图的VoteNet所示,就是用FPS选择出k个点然后对周围的点进行聚集操作。)
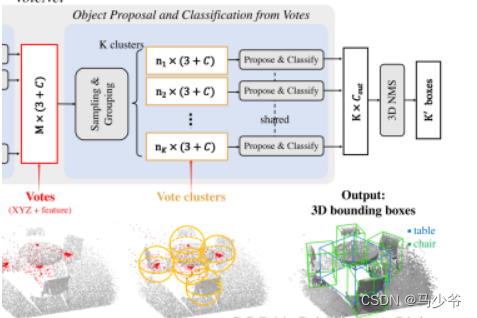

值得注意的是,在本文中,我们并不是仅仅使用边界框内的点或移位点来进行中心预测,我们手动扩展ground truth bounding box,或者按比例放大该框,以覆盖物体附近更多相关的上下文。利用落在扩展包围框内的采样点估计偏移量,然后进行偏移。
2.3 Centroid-based Instance Aggregation
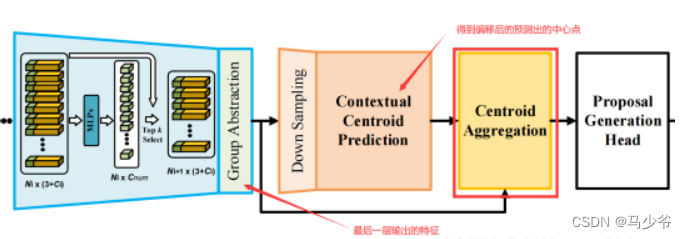
2.4 End-to-End Learning
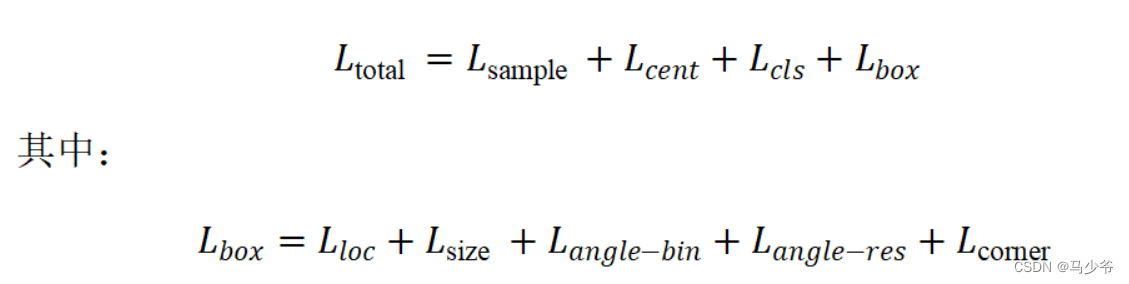
文中提出的方法主要在速度上存在优势,在检测精度上还是没有达到SOTA。