使用过滤插件Grok自定义正则表达式模式并引用
可以在样例数据:
192.168.10.1 GET /index.html 19876 0.234中在增加一列,随便写点数字就可以。现在的样例数据为:
192.168.10.1 GET /index.html 19876 0.234 52767我们使用自定义的正则表达式模式来匹配数最后一列,前面五列照样使用内置模式来匹配。
将自定义的正则表达式写入到一个文件中,然后在grok中引用这个文件。
1)首先在kibana上调试增加一个正则模式
模式名称就叫ID 表达式为[0-9]{3,6}$,表示匹配0-9任意数字,且满足至少3位但不能超过6位,最多6位就是结尾,否则就匹配不上。

2)在grok模式中应用自定义的正则模式
%{IP:client_ip} %{WORD:request_type} %{URIPATHPARAM:url} %{NUMBER:bytes} %{NUMBER:response_time} %{ID:id}
在最后一列增加ID正则模式,然后进行模拟,可以过滤出我们需要的内容

3)配置logstash使用自定义的正则模式
1.将自定义的正则模式写入到一个文件中
[root@elkstack-1 ~]# mkdir /data/elk/logstash/regex/
[root@elkstack-1 ~]# vim /data/elk/logstash/regex/patterns
ID [0-9]{3,6}$
2.配置logstash
[root@elkstack-1 ~]# cat /data/elk/logstash/conf.d/test.conf
filter {
grok {
patterns_dir => "/data/elk/logstash/regex/patterns" #指定正则模式文件所在的路径
match => {
"message" => "%{IP:client_ip} %{WORD:request_type} %{URIPATHPARAM:url} %{NUMBER:bytes} %{NUMBER:response_time} %{ID:id}" #增加上我们自定义的正则模式
}
}
}
3.重载logstash
[root@elkstack-1 ~]# ps aux | grep logstash | grep -v grep | awk '{print $2}' |xargs kill -HUP-HUP
4.产生日志数据
[root@elkstack-1 ~]# echo "192.168.10.1 GET /index.html 19876 0.234 52767" >> /var/log/test/access.log
[root@elkstack-1 ~]# echo "192.168.10.1 GET /index.html 19876 0.234 52767" >> /var/log/test/access.log
[root@elkstack-1 ~]# echo "192.168.10.1 GET /login.html 19876 0.234 52767" >> /var/log/test/access.log
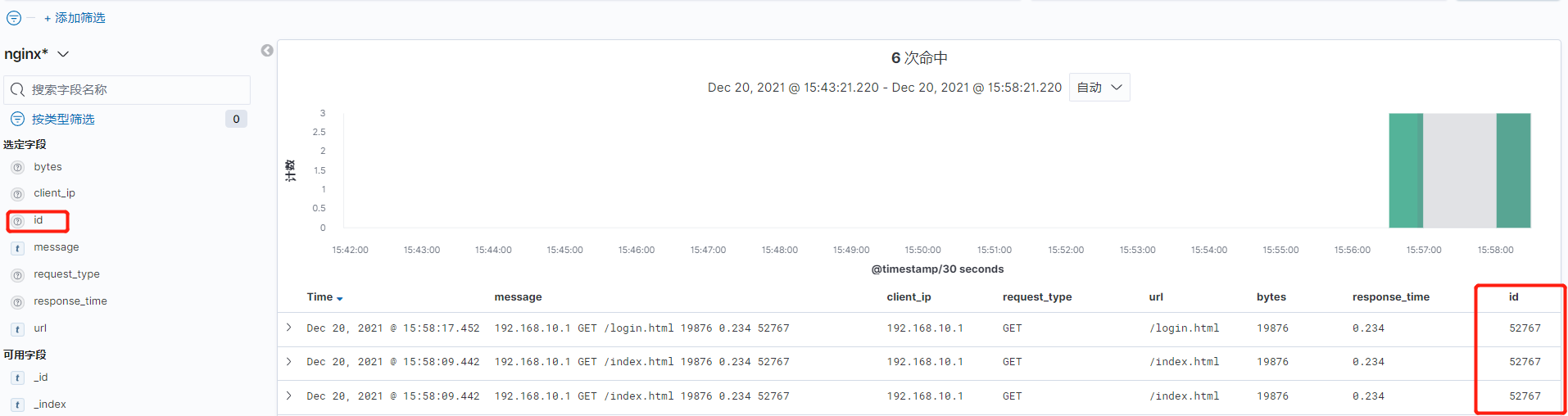
4)在kibana上展示日志数据
增加上新的id字段