持续集成和持续交付
持续集成(continuous integration,CI)是一系列软件开发实践,在这一系列软件开发实践中,团队成员在短时间内将他们的更改集成到存储库中,以检测可能的错误并分析他们创建的软件质量。这是通过使用包含执行测试代码的自动持续代码检查(构建)来实现的。另一方面,持续交付(continuous delivery,CD)是一种软件开发实践,在这种实践中,交付软件的流程是自动化的,允许在生产环境中进行短期交付。
当我们将这些流程应用到我们的微服务架构时,一定要记住,永远不应该有一个集成和发布到生产环境的“等待列表”。例如,负责服务X的团队必须能够在任何时候将更改发布到生产环境中,而不必等待其他服务的发布。图A-6展示了与多个团队合作时,我们的CI/CD流程应该是什么样子的高层图。
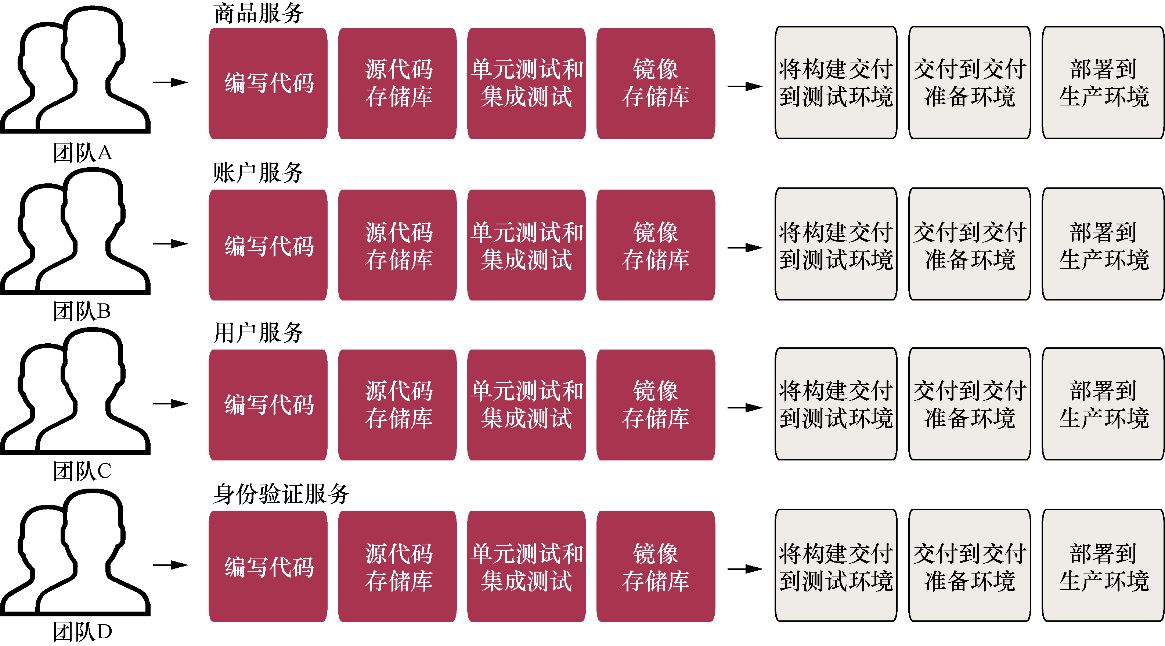
图A-6 测试环境和交付准备环境的微服务CI/CD流程。在该图中,每个团队都有自己的源代码存储库、单元测试和集成测试、镜像存储库以及部署流程。这使得各个团队在部署和发布新的版本时无须等待其他发布
持续部署与持续交付
很多人认为,持续部署(continuous deployment)是持续交付(continuous delivery)的进阶状态,是指代码提交后一旦成功通过所有质量验证,就立即自动部署到生产环境中,不需要任何人的审批。事实上,“部署”与“交付”这两个主干词的意义并不相同。
“部署”是一种技术领域的操作,也就是说,从某处获取软件包,并按照预先设计的方案将其安装到计算节点上,并确保系统可以正常启动,但它并不一定意味着“必须包含业务功能的发布或交付”。“交付”则是一个业务决策活动,通常也被称为“发布”,也就是说,如果将新构建的特性交付到客户(用户)手中,用户就可以看到并使用它们。
之所以“部署”与“发布”几乎成为等价词,是历史原因造成的。很久以前,软件的发布周期较长,每次新功能部署之后就会立即发布。久而久之,“部署”就成了“发布”的代名词。为了保证软件质量,IT部门通常不允许无关代码(即与本次发布新特性集合无关,例如未开发完成的功能、不完善的功能集)被带到生产环境中。因此,每次部署就一定是重大功能的发布。
随着互联网软件的出现,“部署”和“发布”内容与频率不同的情况也是很常见的。我们可以向环境多次部署,但只有当业务需要时才向用户发布,如图1-4中的箭头所示。例如,Facebook公司的发布工程师Chuck Rossi在2011年该公司举办的技术分享会上指出:“我们现在每天会对Facebook网站进行一次部署操作……Facebook公司在半年后将要主推的功能特性,现在已经上线了,只是用户看不到而已。”
持续部署
持续部署是把低效的人工部署过程自动化,大规模部署的问题在持续部署时也将持续发生。现在人们倾向于通过容器化来简化服务的管理,这解决了一些问题,但存在的问题也不少。对于蓝鲸与云效这两个售价百万余人民币的产品,其最基础功能就是解决大规模部署的问题,所以从事这方面的研究与实践还是相当有价值的。下面简单罗列一下大规模部署的一些问题,这样在落实持续部署时好有个方向,知道要解决什么问题。
- 服务日志:当有成百上千个容器在运行时,试图从日志分析某一单业务问题并找到日志所在的容器或主机就已经让你头痛。显然,这种行为十分低效,这种方式不适合大规模部署的场景。另外,当业务量足够大时,用户的访问行为也许能够说明一些商业问题,可以通过分析用户行为来促进商业推广。所以日志不仅可以用来分析问题,还可以用来做大数据分析,日志问题是一个非常重要的问题。
- 服务监控:当服务实例(在执行集群部署时一个节点便是一个服务实例)够多时,对实例的监控就会变得复杂。比如,要监控每个实例的硬件(CPU、内存、I/O等)使用率以掌握实例的运行状态,从而确定是否要扩容或限流。当监控到一些服务实例负载很重时,为了维持优质服务,需要水平扩展实例数。当监控到某一实例处于不可用状态时,可以立刻下线这个实例,启动一个新的实例来替换。
- 服务网络:大规模部署中一个网段的机器(拥有一个IP,不管是物理机还是虚拟机)是有限的,如果还有异地的网络通信需求(一个内网的机器要访问异地的另一个内网的机器),网络就变得复杂,IP的管理、端口的管理都将成为十分琐碎的事情。
- 服务编排:现在人们都习惯于把各种功能服务化,比如,日志收集方案由专门的服务提供,网络方案由专门的服务提供。在部署一个服务时,可以自由选择这个服务的网络、存储、日志收集等方案,完成服务的定制。另外,还可以给虚拟机或容器限定硬件资源的使用量,做到服务的部分资源隔离,减少服务之间的相互影响(不会导致同一主机上的某一容器由于资源占用过多而导致其他容器的服务质量突降)。
- 服务调度:在生活中我们喜欢把紧要或重要的事分配给更靠谱、能力更强的人去做,甚至会专门成立工作小组。同样,在部署服务时,我们也会倾向于把重要的服务部署到更适合的机器上,比如,有些服务需要较强的运算能力,我们可以在运算能力更强的主机上启动它们,或者限制主机上的容器数量以保证容器的运算能力。
- 服务调度:大量容器在更新时,为了保证服务的无缝衔接,我们通常会滚动更新,而不是让服务一次性更新最新版本,服务调度可以用来控制更新频率。
- 负载均衡:大规模部署结构中,负载均衡是一个必选项,把用户请求分发到服务实例,有些场景还需要保持用户状态。比如,当把用户请求分发到某一实例时,此实例刚好发生故障,用户请求能够转到其他实例正常处理,对用户来说无感知。
- 服务发现:在执行集群部署时,代理服务器要知道代理了多少服务,利用分发规则分发到各个服务上,初次部署时人工配置这些代理似乎还可以理解,但当服务实例成百上千时,人工配置是万万不可能的事情,费力还容易出错。特别是增加或下线实例时,都需要修改这个配置。显然,此时我们需要一个自动处理程序,服务发现的职责就是帮助探测服务,把服务实例加入集群,把不可用服务从集群中踢除。
- 微服务支持:互联网的发展推动了服务化的落地,SOA(面向服务的架构)成为应用系统构建的不二之选。当前开源社区流行多种服务治理框架,习惯上叫它们微服务,如Spring Cloud、Dubbo、lstio等。微服务框架能帮助解决微服务的发现、连接、管理、监控及安全等问题,大大简化了传统的集群部署方式,所以微服务就是为大规模部署而生的,能帮助简化部署结构、降低部署成本。
- 服务健康检查:自动检查容器实例的状态,方便做一些后续操作,如重启、增加容器实例。
- 服务自动伸缩:提供自动的伸缩能力,比如,当服务性能达到阈值时,自动增加容器实例,而且这一过程完全不需要人工干预。
- 数据存储:系统中流动的数据就是价值所在,要保存价值,就要存储数据。当数据量少时,我们可以保存在一两张磁盘上。后面数据多了,我们会使用条带化技术,把硬盘阵列挂载到主机上。但如今数据量暴增,云及容器化技术飞速发展,传统的存储方式面临挑战。比如,我们需要跨网存储,读者应该多少使用过网盘,这就是云存储技术。我们知道容器实例状态不是持久化的,当实例删除后数据也不复存在,所以会把数据存储在主机上,但在容器迁移时就麻烦了,主机上的数据也得迁移。显然,这也不太友好。我们需要让容器不管在哪台机器上都可以访问主机上的数据,网络存储可以帮助我们解决这个问题。
书籍推荐
持续交付2.0:业务引领的DevOps精要(增订本)

本书主要服务于那些身处IT业务一线的管理者,或即将成为一线管理者的骨干技术人员,当然也包括那些从事软件产品项目管理和软件过程改进的人们。
本书“重新定义”了持续交付,增补了组织管理和架构两个维度,辅助以真实案例,对持续交付的诸多原则和实践加以解读,并对持续交付过程中的取舍原则加以论述。
本书分为3个部分:第一部分作者根据自己近十年的工作及咨询经历,通过不断总结、提炼和反思,对原有的持续交付进行修正,重新定义持续交付为实现组织战略目标的能力,并引入持续交付的能力模型;第二部分阐述组织打造持续交付能力模型所需遵循的原则,包括基础原则、组织原则和架构原则;第三部分通过对多个互联网公司案例的解读,阐述如何根据组织的当前状况应用相关原则对最佳实践进行取舍,并快速达到组织能力目标。
本书适合大型互联网公司的技术VP、技术负责人,中小型互联网公司的CTO、技术VP、研发/测试/运维负责人、主管及骨干,以及组织变革者阅读。