一、目录
-
由断电引发的问题
-
不一会 - 来电了
-
Double write工作流程
-
恢复的过程
-
配置参数
-
Double write并不一定是必须的
-
疑问
二、由断电引发的问题
今天为大家介绍一个新的名词:double write。
相信你还记得,我之前有写笔记跟大家分享过,在MySQL组织数据的基本单位是存在于磁盘上的数据页。数据页被读取到内存(Buffer Pool)中后被称为缓存页。默认情况下每个数据页的大小是16kb,数据页中存储的就是一行行真实的记录,也叫做数据行。
mysql> SHOW GLOBAL VARIABLES LIKE 'innodb_page_size';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| innodb_page_size | 16384 |
+------------------+-------+
当有写操作对Buffer Pool中的数据页做了更新,我们把这种被改变过的数据页叫做:脏页。它是需要被刷新会磁盘的。这时问题就来了,对于计算机硬件或者是操作系统来说,每次原子IO操作的吞吐量量是小于16KB的,一般每个扇区的大小是512字节。
# 文件系统块大小:一般为4k
~]# getconf PAGESIZE
4096
~]# fdisk -l
磁盘 /dev/sda:53.7 GB, 53687091200 字节,104857600 个扇区
Units = 扇区 of 1 * 512 = 512 bytes
扇区大小(逻辑/物理):512 字节 / 512 字节
I/O 大小(最小/最佳):512 字节 / 512 字节
磁盘标签类型:dos
磁盘标识符:0x000a88ef
设备 Boot Start End Blocks Id System
/dev/sda1 * 2048 2099199 1048576 83 Linux
/dev/sda2 2099200 104857599 51379200 8e Linux LVM
磁盘 /dev/mapper/centos-root:50.5 GB, 50457477120 字节,98549760 个扇区
Units = 扇区 of 1 * 512 = 512 bytes
扇区大小(逻辑/物理):512 字节 / 512 字节
I/O 大小(最小/最佳):512 字节 / 512 字节
磁盘 /dev/mapper/centos-swap:2147 MB, 2147483648 字节,4194304 个扇区
Units = 扇区 of 1 * 512 = 512 bytes
扇区大小(逻辑/物理):512 字节 / 512 字节
I/O 大小(最小/最佳):512 字节 / 512 字节
那这么看来,当你想把一个16K大小的数据页写入到磁盘中时,结果刚写了4k,突然断电机器宕机了。那此时只有一部分是写入成功的。这就是大家常说的:partial page write
三、不一会 - 来电了
还是接着上面的描述说,不一会电源正常了,开机重启MYSQL,这时MySQL会进入到崩溃恢复的阶段。
正常的崩溃恢复流程是:
-
将数据页从磁盘中读入到内存中
-
检查数据页中的LSN标记和redo log中的LSN谁更新,如果相同表示此时的数据页中的数据就是最新的,如果redo log的LSN比数据页中的LSN大,说明数据页中的数据是过时的数据,按redo重做出一份最新数据
但是现在问题是:因为MySQL的Crash是由断电引发的,操作系统都没来得及将数据页完整的写入到磁盘中,导致崩溃恢复的第一步就失败了,因为MySQL会检查出:这个数据页是个不完整的数据页。
四、Double write工作流程
结合double write来看一下一条update sql的执行流程

Step1: 满足update条件的数据页如果不再Buffer Pool中,就进行一次IO操作,将其加载进磁盘。
Step2: 将该数据页修改成脏页。
Step3: 当需要将缓冲池的脏页刷新到 data file 时,并不直接写到数据文件中,而是先拷贝至内存中的 double write buffer。
Step4: 接着从 double write buffer 分两次写入磁盘共享表空间中,每次写入 1MB,并马上调用 fsync 函数,同步到磁盘,避免缓冲带来的问题。
Step5: 完成Step2后,再将两次写缓冲区写入其对应的单独的数据文件。
五、恢复的过程

-
将数据页从磁盘中读入到内存中
-
检查到数据页损坏了,尝试通过double write恢复数据。
-
如果 double write 的数据是完整的,用 double buffer 的数据页替换坏掉的数据页。
那,如果 double write 中的数据页被写坏了怎么办?

其实没关系,因为是先往共享表空间中写double write数据页,再往各个表对应的表空间文件中写实际的数据页,如果double write中的数据页坏点了,那恰恰说明,各个表对应的表空间文件中的数据页没坏!恢复的流程不会被打断!
六、配置参数
# 查看是否启用了double write,以及相关参数
mysql> SHOW VARIABLES LIKE 'innodb_doublewrite%';
+-------------------------------+-------+
| Variable_name | Value |
+-------------------------------+-------+
| innodb_doublewrite | ON |
| innodb_doublewrite_batch_size | 120 |
+-------------------------------+-------+
2 rows in set (0.02 sec)
# 查询double write的使用情况
mysql> SHOW STATUS LIKE 'innodb_dblwr_%';
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| Innodb_dblwr_pages_written | 14615 | #从BP写入到dblwr的page数
| Innodb_dblwr_writes | 636 | #写文件的次数
+----------------------------+-------+
2 rows in set (0.02 sec)
七、疑问
看到这里你肯定已经知道了double write解决了数据页被写坏的情况,也就是说,redo log不能对一个本身就坏掉的数据页进行重做。
但是,不知道你有没有这样的疑问,那redo log也是以文件的形式存在于磁盘上的,那假如在write redo log时,断电了呢?那redo log不也被损坏了?那还崩溃恢复个锤子?
答:是这样的:事务产生的redo log先被组织成redo log block。并且redo log block其实就在redo log buffer 中。而redo log block的大小==操作系统一次原子IO的吞吐量512字节就像下图这样:
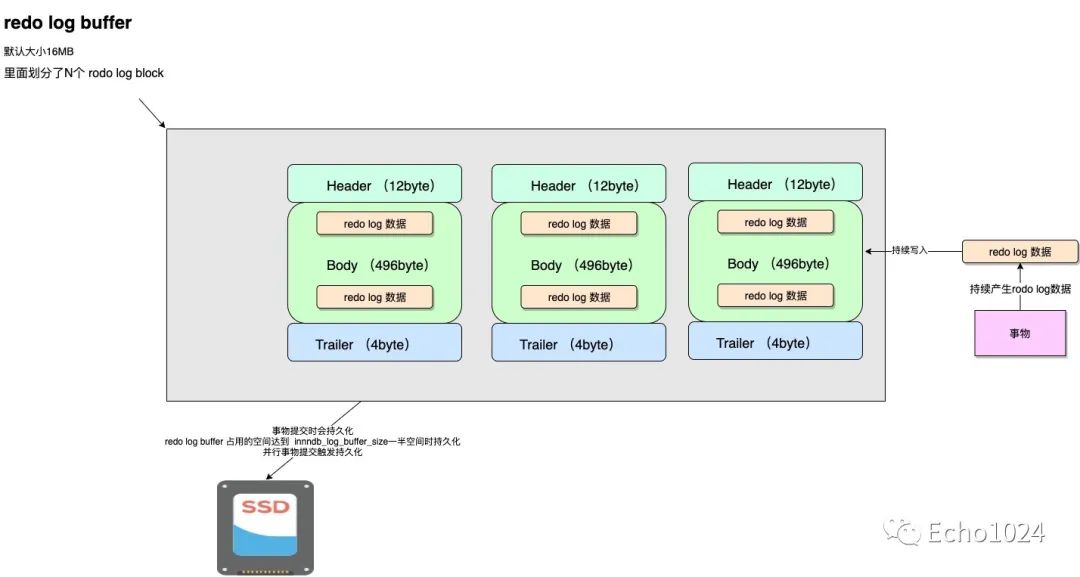
八、Double并不一定是必须的
并不是所有的场景都需要使用 Double Write 这样的机制来保证数据的安全准确性。比如 Solaris 平台上非常著名的 ZFS 文件系统,它就可以自己保证文件写入的完整性。