一、什么是Zookeeper
Zookeeper是一个分布式协调服务,它是一个典型的分布式数据一致性解决方案,因此,可以为分布式系统提供以下功能:
数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等。
接下来我们就分析Zookeeper是如何保证分布式数据一致性的。以及Zookeeper在分布式场景下的几个典型应用。
二、Zookeeper数据模型
Zookeeper的数据结构类似于linux的文件结构类型,根路径以 / 开头,是一个树形结构。每个节点称之为znode,由key和value组成。每个znode都有一个key,并可以设置对应的value。且每个znode下,可以有多个子znode,每个子znode也有其自己的key和value。和文件系统一样,同一个路径下,不允许有重名的文件,在zk的同一个父znode下,也不可能出现相同的key的znode子节点。
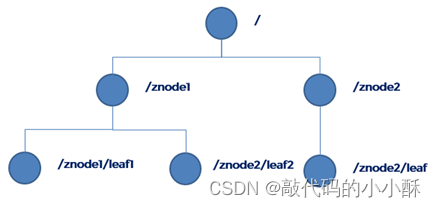
zk的数据节点分为临时节点,临时有序节点,持久节点,持久有序节点四个类型。临时节点与会话(session)有关,当会话关闭后,临时节点自动删除。临时节点不能再创建子节点。持久节点数据会存储在磁盘,zk重启后,数据会重新加载到内存中。
有序节点是zk内部会保证创建节点的有序性,是一个线程安全的功能,有序节点的key结尾都会自动添加上0000000xx格式的序号。
zk服务有自己的命令,通过命令,可以进入节点,查看节点信息,还有一些增删改节点数据的命令操作,这里不再一一赘述,用到的时候直接搜索相关命令使用即可。
经验:如何查看某个节点是临时节点还是持久节点呢?
进入zk服务,使用命令ls -s /xxx 查看节点信息,ephemeralowner属性如果为0x0就是持久节点。如果为其他值,就是临时节点,这个属性存的就是临时节点id。
Zookeeper的所有应用场景,都是基于其数据模型的特点上,结合zk提供的数据一致性的解决方案,来进行的分布式系统的协调工作。
三、Session会话
会话:
客户端与服务端的一次会话连接,本质是 TCP 长连接,通过会话可以进行心跳检测和数据传输:
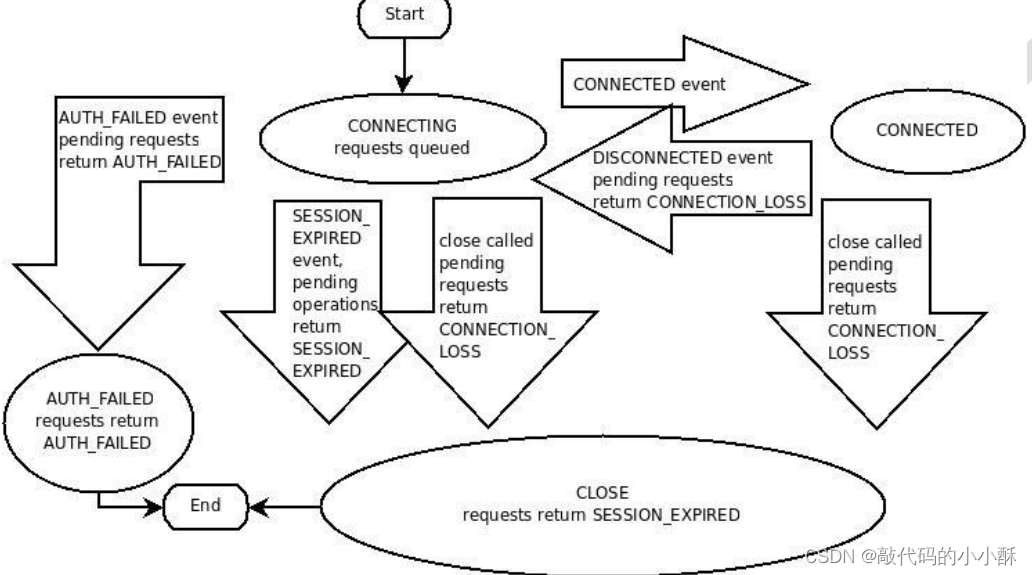
ZK 会话在整个运行期间的 生命周期中,会在不同的会话状态之间切换,这些状态包括: CONNECTING、CONNECTED、RECONNECTING、RECONNECTED、CLOSE。
一旦客户端开始创建 Zookeeper 对象,那么客户端状态就会变成 CONNECTING 状态, 同时客户端开始尝试连接服务端,连接成功后,客户端状态变为 CONNECTED,通常情况 下,由于断网或其他原因,客户端与服务端之间会出现断开情况,一旦碰到这种情况, Zookeeper 客户端会自动进行重连服务,同时客户端状态再次变成 CONNCTING,直到重新连 上服务端后,状态又变为 CONNECTED,在通常情况下,客户端的状态总是介于 CONNECTING 和 CONNECTED 之间。但是,如果出现诸如会话超时、权限检查或是客户端主动退出程序等
情况,客户端的状态就会直接变更为 CLOSE 状态。
四、java客户端及Watcher机制
java连接zk服务的客户端一般使用zkClient和curator-frameword,其中curator-frameword使用最多。客户端对zk服务的操作,无非就是对数据节点的增删改查操作,这里不再进行赘述,主要记录一下watcher机制的原理。
zk客户端可以监听zk服务的某个节点,当这个节点发生变化时,会触发不同的事件,此时,zk服务会通知zk客户端的监听,触发了某个事件,然后zk客户端做相应的处理逻辑。
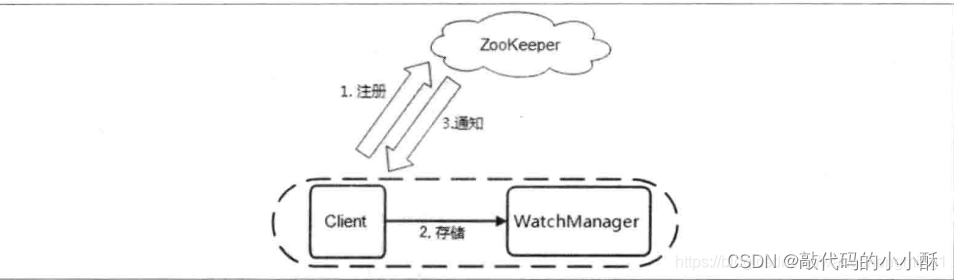
客户端中有一个专门的watchManager管理器,专门用于管理监听器,接收zk服务发送来的事件变更的通知。
watcher监听的事件类型包括:被监听的节点创建、删除、数据内容发生变化、子节点列表发生变化。
需要注意的是,在zk服务的通知信息里,不会携带被监听节点改变前的数据和改变后的数据,需要客户端调用相应方法单独获取znode的数据。
客户端注册watcher流程:
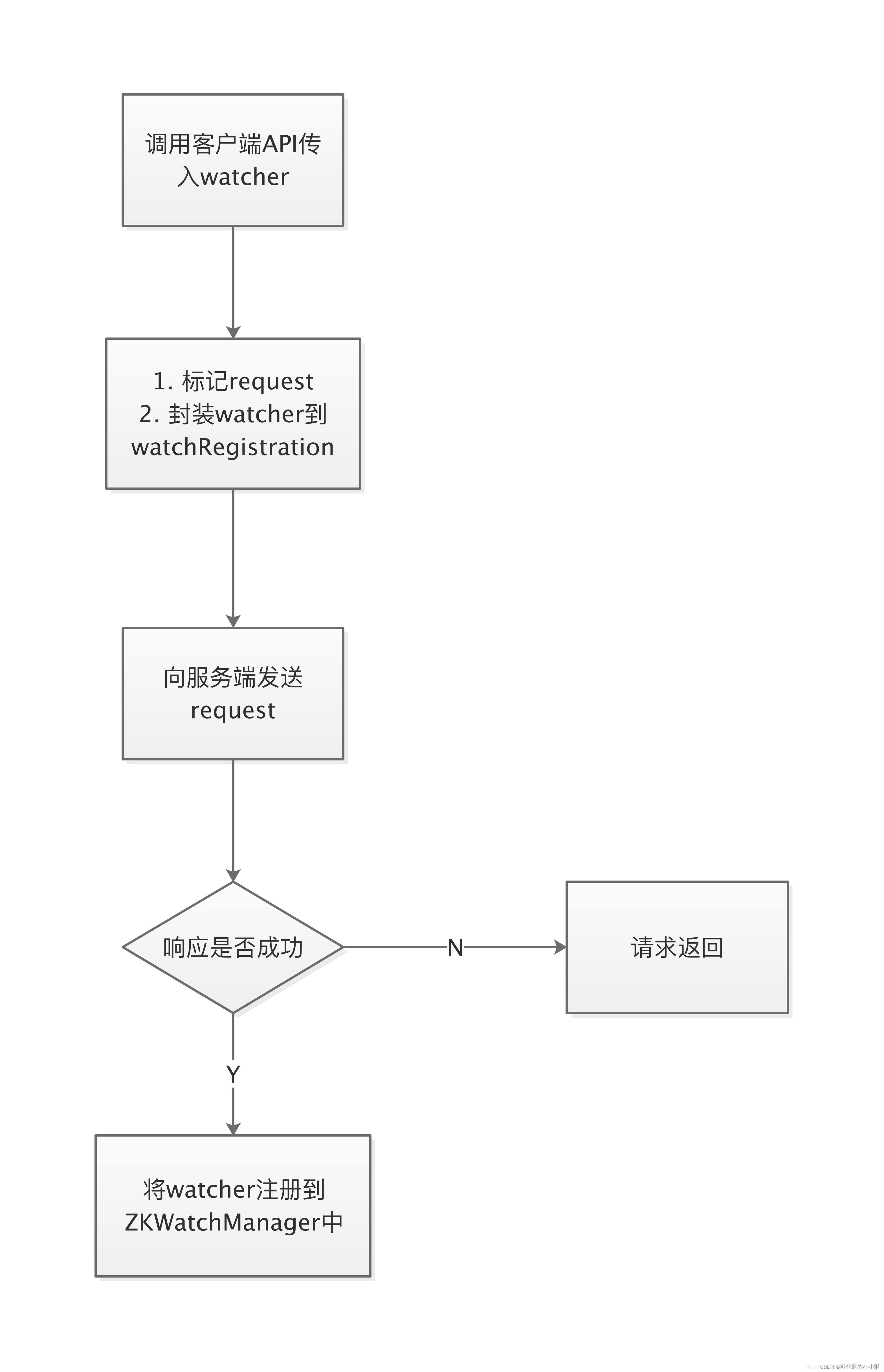
zk服务端处理watcher流程:
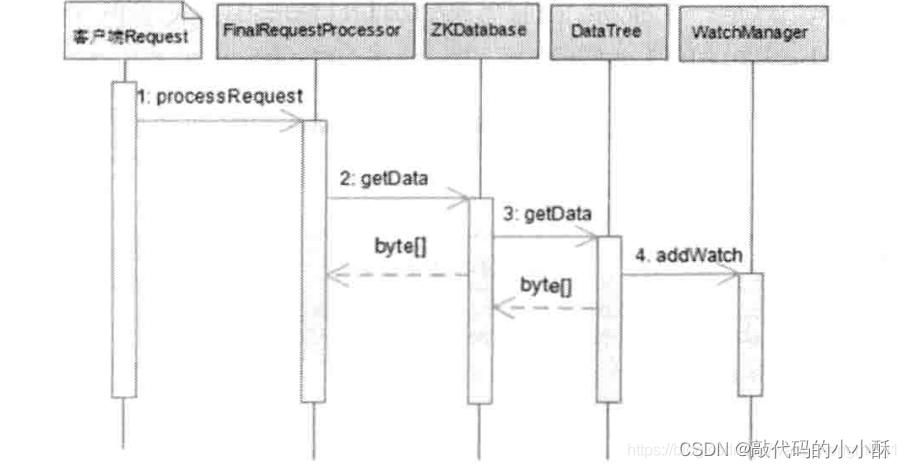
特点:
1.一次性:
无论是服务端还是客户端,一旦一个 Watcher 被触发,ZooKeeper都会将其从相应的存储中移除。因此,开发人员在 Watcher 的使用上要记住的一点是需要反复注册。这样的设计有效地减轻了服务端的压力。试想,如果注册一个 Watcher 之后一直有效,那么,针对那些更新非常频繁的节点,服务端会不断地向客户端发送事件通知,这无论对于网络还是服务端性能的影响都非常大。需要注意的是:ZooKeeper 在 3.6.0 版本中引入了永久 Watcher 机制,利用这个机制可以避免反复注册 Watcher。
2.客户端串行执行:
客户端 Watcher 回调的过程是一个串行同步的过程,这为我们保证了顺序,同时,需要开发人员注意的一点是,千万不要因为一个 Watcher 的处理逻辑影响了整个客户端的 Watcher 回调。
3.轻量:
WatchedEvent 是 ZooKeeper 整个 Watcher 通知机制的最小通知单元,这个数据结构中只包含三部分内容:通知状态、事件类型和节点路径。也就是说,Watcher 通知非常简单,只会告诉客户端发生了事件,而不会说明事件的具体内容。例如针对 NodeDataChanged 事件,ZooKeeper 的 Watcher 只会通知客户端指定数据节点的数据内容发生了变更,而对于原始数据以及变更后的新数据都无法从这个事件中直接获取到,而是需要客户端主动重新去获取数据。这也是ZooKeeper 的 Watcher机制的一个非常重要的特性。
另外,客户端向服务端注册 Watcher 的时候,并不会把客户端真实的 Watcher 对象传递到服务端,仅仅只是在客户端请求中使用 boolean 类型属性进行了标记,同时服务端也仅仅只是保存了当前连接的 ServerCnxn 对象。如此轻量的 Watcher 机制设计,在网络开销和服务端内存开销上都是非常廉价的。
参考文章:zookeeper的watcher机制
Zookeeper的订阅/发布功能就是基于watcher机制实现的。以被监听节点的事件为触发点,来发布消息。
Zookeeper还有ACL权限鉴定的相关操作,这里不再赘述。