目录
1. 基本概念





2. Pychram中的Scrapy




3.一个解析页面的基本说明(CCS选择器的使用)



4. 利用Items.py接收数据

items.py文件中:
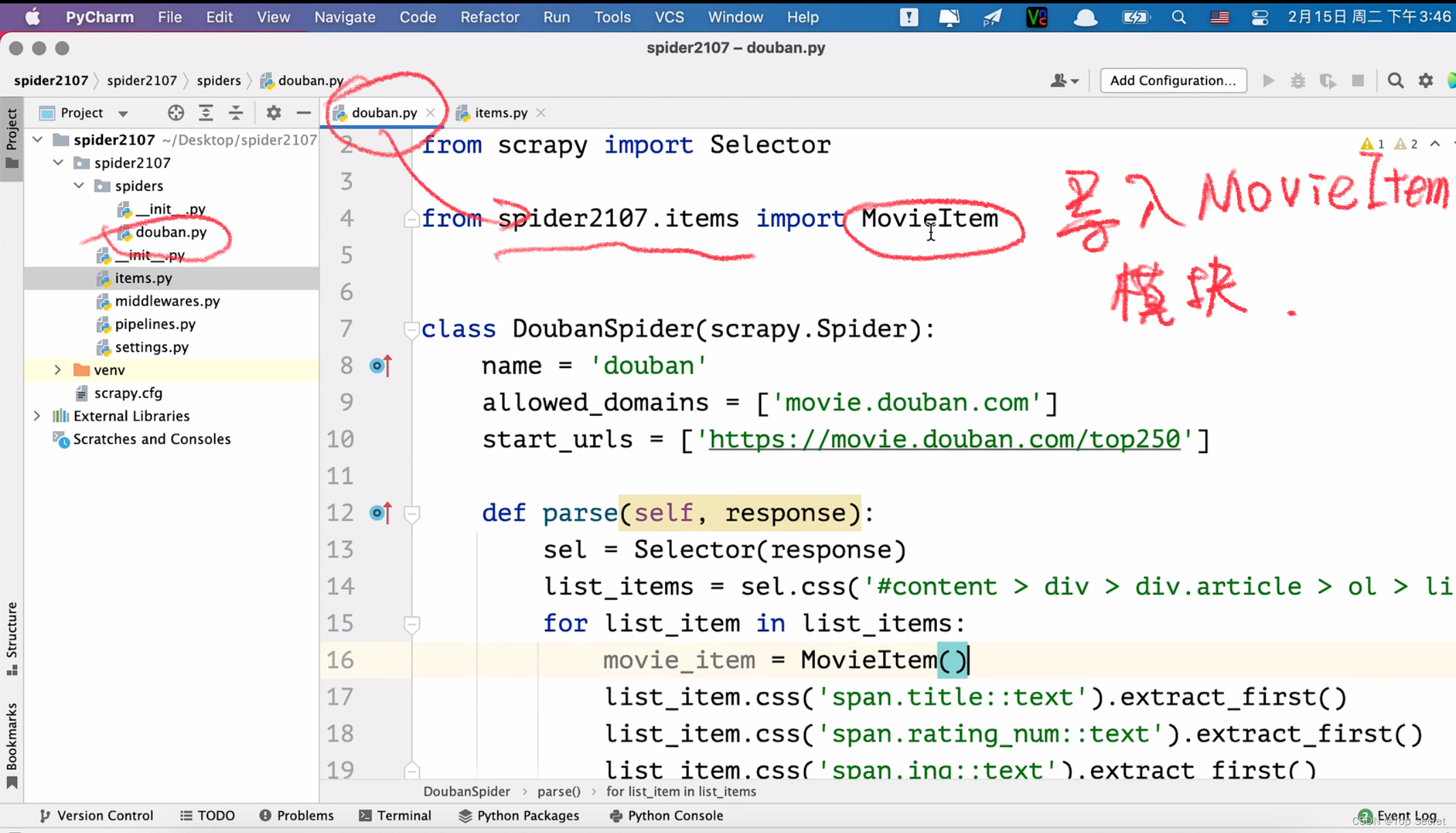
实例化MovieItem(),得到movie_item对象,并将css选择器提取的页面数据存入movie_item对象中:

5.在Setting.py中设置爬虫伪装

6.运行爬虫项目并保存为SCV文件


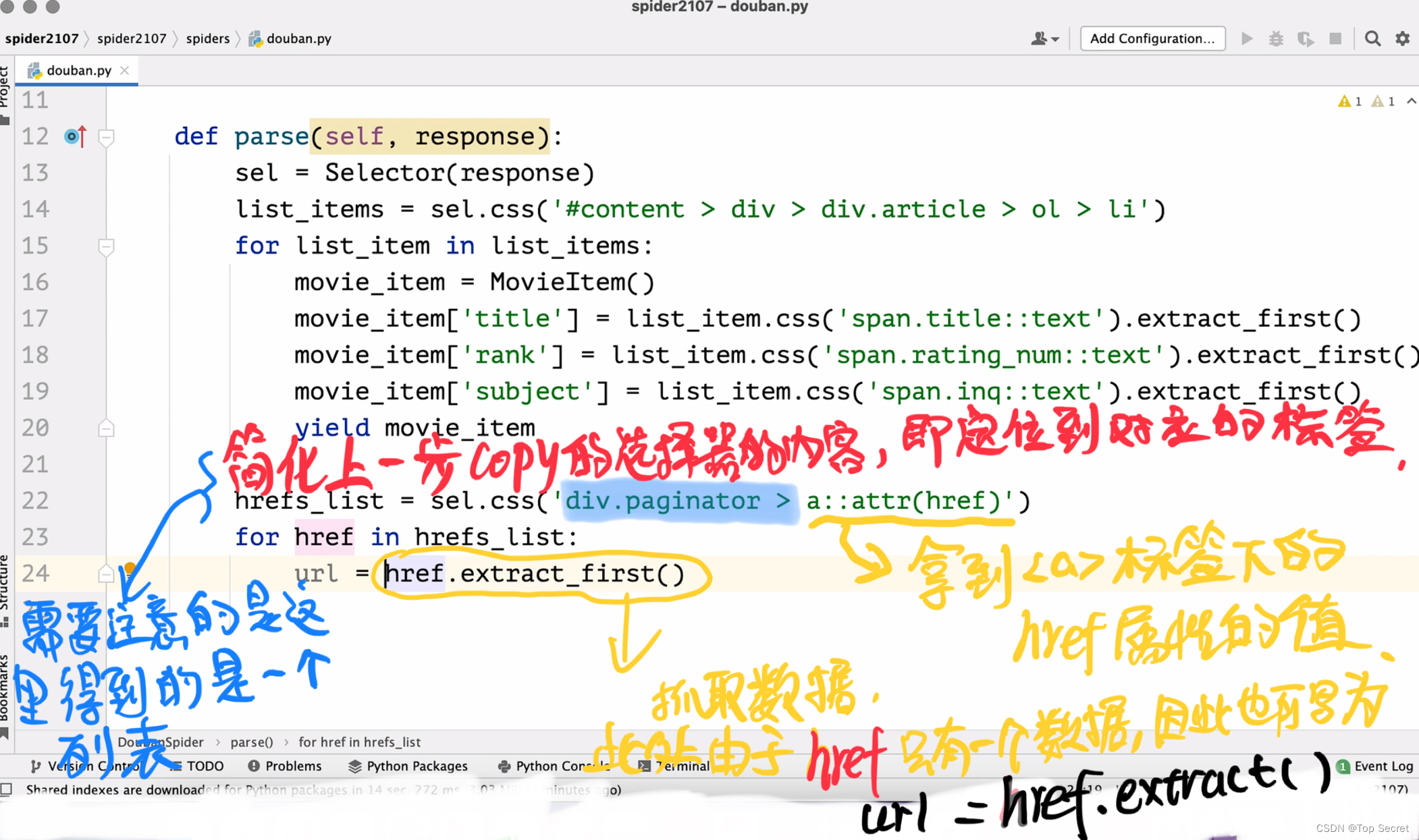
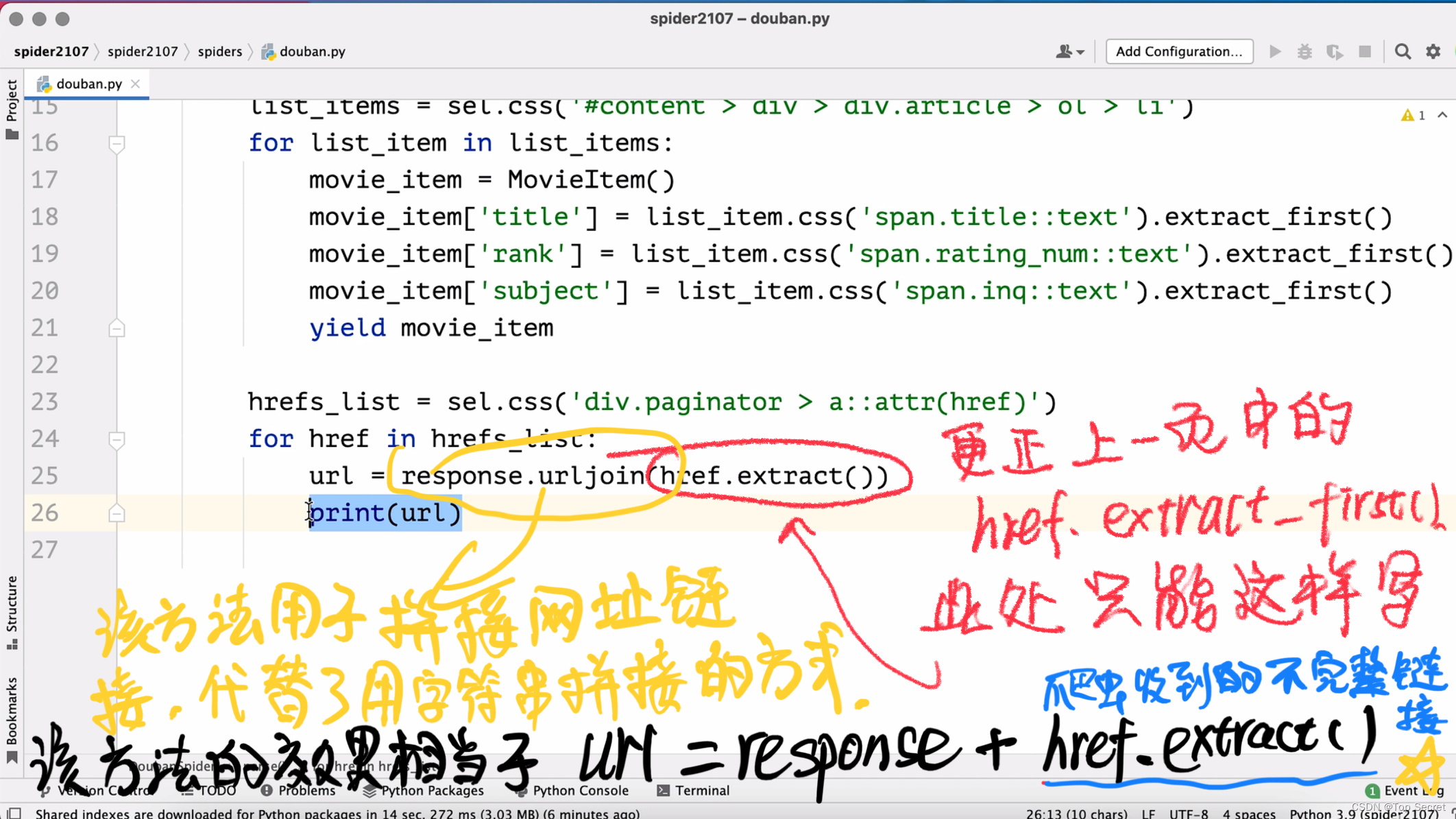
7. 分页爬取豆瓣数据











目录
items.py文件中:
实例化MovieItem(),得到movie_item对象,并将css选择器提取的页面数据存入movie_item对象中: