这里仅为自己收藏学习用-并无其他利益--whaosoft aiot http://143ai.com
正则化主要包括标签正则、数据正则、参数正则等,可以限制网络权重过大、层数过多,避免模型过于复杂,是解决过拟合问题的重要方法。标签正则通过某种方式构建soft label,用于模型学习,以缓解hard label的诸多问题,提升模型的泛化能力。
一、过拟合
近年来,深度神经网络广泛应用于文本、图像、视频等领域的各类任务中,取得了惊艳的效果。通常而言,增加神经元数量、提升神经网络模型的深度,可以增强模型的学习能力,取得更佳的效果。然而,如果模型过于复杂,参数量过多,其不仅可以学习到训练集上的有用规律,还可能学到训练数据的噪声,使得模型泛化能力变差,这种现象称为过拟合。
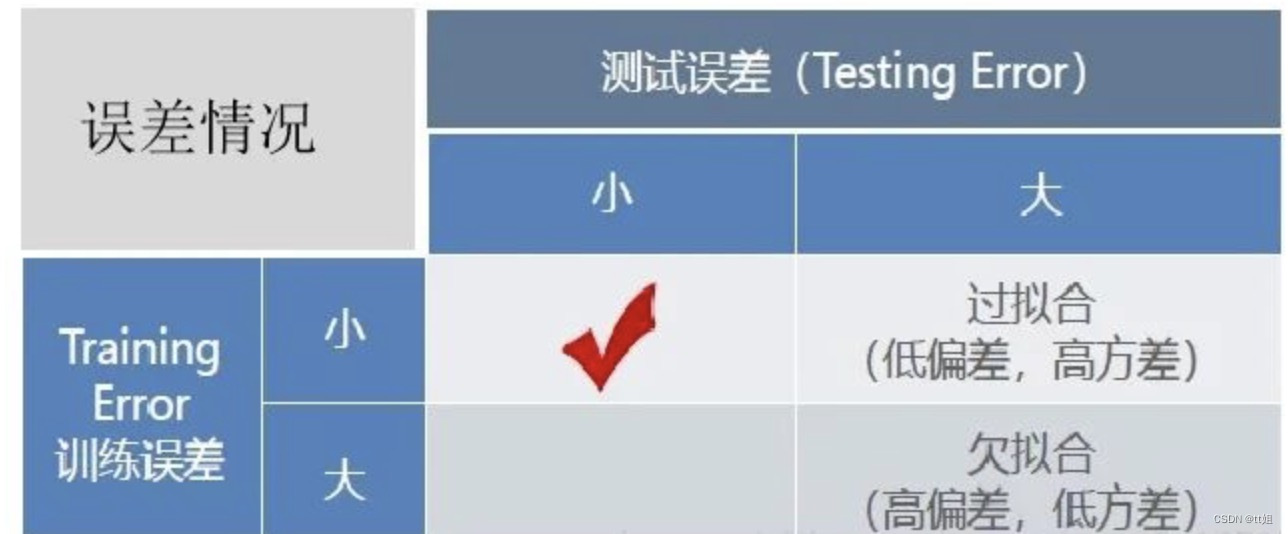
图1-1 过拟合与欠拟合[3]
究其原因,主要包括以下几点:训练样本较少,无法反映真实的数据分布;数据噪声干扰较大,模型学习到噪声;模型参数过多,复杂度过高;模型迭代次数过多等。解决过拟合的方法: (1) 扩充训练集;(2) 清洗数据、减少特征维度;(3) 增加噪声;(4) 正则化;(5) 集成学习等。正则化方法主要有数据增强、L1/L2正则、Dropout、Early stop、标签正则化等。其中标签正则本质上是通过某种方式,构建soft label,提升模型的泛化能力。
二、Soft Label
在分类任务中,通常将数据的标签标注为hard label,也即one-hot或multi-hot的形式。然而,hard label存在诸多缺点。图2-1展示了hard label和soft label的对比。数据通常包含不同类别的相关信息,如果直接标注为hard label,会导致大量信息的损失。如果左图直接标注为hard label,one-hot标签只标记了天空类别,会损失白云、草地等信息;而multi-hot,同等对待天空、白云和草地,也是对信息对的一种损失。而如果标注为soft label,则可以较好的体现图中的信息。此外,hard标签通常会使模型过于自信,导致过拟合问题。总体而言,hard label容易获取,但是可能会丢失类内、类间的关联信息,并且引入噪声。soft label携带更多的信息,对噪声更加鲁棒,给模型带来更强的泛化能力,但是获取难度较大。

图2-1 Soft label与Hard label[4]
那么既然soft label难以获取,是否可以进行构造呢?标签正则正是通过某种方式构造soft label,用于模型学习,以缓解hard label的诸多问题,提升模型的泛化能力。标签平滑通过人为制定的规则构建soft label;知识蒸馏通过固定权重参数的teacher模型进行推理得到soft label,与标签平滑相比,知识蒸馏得到的soft label相当于对数据集的有效信息进行了统计,保留了类间的关联信息,剔除部分无效的冗余信息。通过知识蒸馏,将teacher模型的预测作为student模型的标签,但是teacher模型的预测结果可能本身是存在问题的,该问题并没有考虑。自纠正学习循环(称为 ReLoop)构建自定义损失来鼓励每个新模型版本在训练期间减少对先前模型版本的预测误差,利用前一次训练的预测结果来约束当前次训练的性能不能差于前一次,从而进一步提升了模型的性能。
三、标签正则
3.1 标签平滑
在分类任务中,通常采用hard label作为标签,训练数据中标签向量的目标类别概率为1,非目标类别概率为0。one-hot编码的标签向量 可以表示为
交叉熵损失的公式如下,
其中是真实概率,是预测概率,由对模型倒数第二层输出的logits向量 应用Softmax计算得到,在训练模型时,目标是最小化该损失。
为了最小化损失,当基于one-hot标签学习时,模型被鼓励预测为目标类别的概率趋近1,非目标类别的概率趋近0,最终预测的logits向量中目标类别 的值会趋于无穷大,模型会向预测正确与错误标签的logit差值无限增大的方向学习,然而过大的logit差值会使模型缺乏适应性,对它的预测过于自信,当训练数据不足够多时,这就容易导致网络过拟合,泛化能力差。如果对该处感兴趣,具体解释可以参考论文[6]的第七部分——Model Regularization via Label Smoothing。
标签平滑结合了均匀分布,用标签向量 替换ont-hot的标签向量
其中K是多分类的类别个数, 是一个较小的超参数,一般取值0.1。这样,标签平滑后的分布就相当于往真实分布中加入了噪声,避免模型对于正确标签过于自信,使得预测正负样本的输出值差别不那么大,从而避免过拟合,提高模型的泛化能力。关于标签平滑的公式推导可以参考[9]。
此外,论文[15]揭示了为什么标签平滑是有效的,指出标签平滑可以使分类之间的cluster更加紧凑,增加类间距离,减少类内距离,提高泛化性,同时还能提高Model Calibration(模型对于预测值的confidences和accuracies之间aligned的程度);文中还提出在模型蒸馏中使用标签平滑会导致性能下降,[16]则对这一点进行了矫正。
3.2 标签蒸馏
知识蒸馏是模型压缩的一种方式,和剪枝、量化属于同宗,目的是解决推理速度慢、部署要求高等问题。在本文中,我们从soft label角度进行介绍。知识蒸馏是teacher模型指导student模型进行学习的方式,包括特征蒸馏、标签蒸馏等,标签蒸馏可以看作是一种更高级的标签平滑方式。相比于标签平滑,标签蒸馏的soft label是通过网络推理得到的,而标签平滑的soft label是人为设置的。

图3-1 知识蒸馏[17]
如图3-1所示,知识蒸馏的过程分为2个阶段,第一阶段是训练教师网络Net-T;第二阶段是在高温T下,蒸馏Net-T的知识到Net-S。训练Net-T的过程就是普通的训练方法,下面介绍第二步——高温蒸馏的过程。高温蒸馏过程的目标函数由distill loss(对应soft target)和student loss(对应hard target)加权得到:
Net-T 和 Net-S同时输入 transfer set (这里可以直接复用训练Net-T用到的training set), 用Net-T产生的softmax distribution (with high temperature) 来作为soft target,Net-S在相同温度T条件下的softmax输出和soft target的cross entropy就是Loss函数的第一部分
,
其中 ,
Net-S在T=1的条件下的softmax输出和ground truth的cross entropy就是Loss函数的第二部分 。
,其中
第二部分Loss 的必要性其实很好理解: Net-T也有一定的错误率,使用ground truth可以有效降低错误被传播给Net-S的可能。打个比方,老师虽然学识远远超过学生,但是他仍然有出错的可能,而这时候如果学生在老师的教授之外,可以同时参考到标准答案,就可以有效地降低被老师偶尔的错误“带偏”的可能性。
经过训练的teacher模型,其softmax分布包含有一定的知识:真实标签只能告诉我们,某个图像样本是一条狗,不是一只猫,也不是一个土豆;而经过训练的softmax可能会告诉我们,它最可能是一条狗,不大可能是一只猫,但绝不可能是一个土豆。知识蒸馏得到的soft label相当于对数据集的有效信息进行了统计,保留了类间的关联信息,剔除部分无效的冗余信息。相比于标签平滑是一种更加可靠的方式。
3.3 自纠正
自纠正 (ReLoop)是SIGIR‘22推荐系统领域的一篇论文,思路比较简单,直接基于[13],以标签蒸馏的角度进行介绍。
推荐系统可以简单看作是每天增量训练的二分类模型,考虑标签蒸馏,模型训练过程通常只获取teacher模型的logits作为soft label,配合hard label进行联合训练,对teacher模型可能的错误并未进行有效的处理。ReLoop提出自纠正学习循环模块,通过构建自定义损失来抑制student模型在训练期间对teacher模型的预测误差进行学习,从而可以在之前的错误中学习知识。其核心在于,利用前一次训练的预测结果来约束当前轮次训练的性能,使其不能差于前一次。
将样本的预估点击率 (预测概率)与其真实标签之间的差距定义为所犯的错误,根据上一个版本的模型的预测可以得到每个样本的前次预估点击率。至于当前误差,它表示当前预测与训练期间的真实标签之间的差距。我们希望模型可以从错误中学习,在这里是希望模型在时间t的性能优于t-1版本。
为了达到上述“希望”,作者设计了一个损失函数来对训练过程进行约束,这当前的误差要小于之前的误差。以正样本(y=1)为例,公式如下,
从而损失函数可以构建为下式,即约束正负样本的预测值在前后两次训练中的关系
除了上述损失函数还需要正常的推荐模型训练,此处采用交叉熵损失,
因此总损失为
本文方法和知识蒸馏存在相似之处,知识蒸馏的损失函数可以表示为下式,
通过知识蒸馏,将前一次的预测作为这一次的标签,可以使得当前轮次的训练至少要达到上一轮的效果,这个想法和本文的想法的一样的,但是上述损失存在的问题就是前一轮的预测结果本身可以存在问题,即教师模型的预测可能错误。从论文的实验结果中也可以发现ReLoop方法要比知识蒸馏略好。
四、总结
标签正则通过某种方式构建soft label,用于模型学习,以缓解hard label的诸多问题,提升模型的泛化能力。具体来说,标签正则主要有标签平滑、标签蒸馏、自纠正等方法,这些方法被AI领域的一篇或多篇顶会提出,并做进一步的拓展,