什么是ceph?
Ceph到底是什么
Ceph是一个开放、自我修复和自我管理的统一分布式存储系统。具有高扩展性、高性能、高可靠性的优点。
Ceph是一个可大规模伸缩的、开放的、软件定义的存储平台,它将Ceph存储系统的最稳定版本与Ceph管理平台、部署实用程序和支持服务相结合。也称为分布式存储系统,其出现是为了解决分布式文件系统元数据成为存储的瓶颈问题的,常规情况下元数据存储服务会成为整个存储的中心节点,而ceph利用了一致性hash计算的方式将查询变成了取膜计算的方式,将查询变成了实时运算
☑ Ceph是一个对象(object)式存储系统,它把每一个待管理的数据流(例如一个文件)切分为一到多个固定大小的对象数据,并以其为原子单元完成数据存取
☑ 对象数据的底层存储服务是由多个主机(host)组成的存储集群,该集群也被称之为RADOS(Reliable Automatic Distributed Object Store)存储集群,即可靠、自动化、分布式对象存储系统
☑ librados是RADOS存储集群的API,它支持C、C++、Java、Python、Ruby和PHP等编程语言
☑ ceph可以提供对象存储、块存储、文件系统存储,ceph可以提供PB级别的存储空间,软件定义存储(Software Defined Storage)作为存储,行业的一大发展趋势,已经越来越受到市场的认可
☑ 无论您希望向云平台提供Ceph对象存储和/或Ceph块设备服务、部署Ceph文件系统或将Ceph用于其他目的,所有Ceph存储集群部署都是从设置每个Ceph节点、您的网络和Ceph存储集群开始的。
☑ Ceph存储集群至少需要一个Ceph监视器、Ceph管理器和Ceph OSD(对象存储守护进程)。
☑ 在运行Ceph文件系统客户机时,还需要Ceph元数据服务器。
为什么要使用ceph?
ceph目前已得到众多云计算厂商的支持并被广泛应用。RedHat及OpenStack kubernetes都可与Ceph整合以支持虚拟机镜像的后端存储。
国内目前使用ceph搭建分布式存储系统较为成功的企业有华为,阿里,星辰天合存储,杉岩数据,中兴,华三,浪潮,中国移动,网易,乐视,360,等
ceph分布式存储有哪些优势?
官网介绍
高扩展性:使用普通X86服务器,支持10~1000台服务器,支持TB到EB级的扩展。
高可靠性:没有单点故障,多数据副本,自动管理,自动修复。
高性能:数据分布均衡
Ceph支持三种调用接口:块存储 文件系统存储 对象存储。三种方式可以一同使用。
Ceph特点
• 高性能
摒弃了传统的集中式存储元数据寻址的方案,采用CRUSH算法,数据分布均衡,并行度高。 b.考虑了容灾域的隔离,能够实现各类负载的副本放置规则,例如跨机房、机架感知等。
能够支持上千个存储节点的规模,支持TB到PB级的数据。
• 高可用性
副本数可以灵活控制。
支持故障域分隔,数据强一致性。
多种故障场景自动进行修复自愈。
没有单点故障,自动管理。
• 高可扩展性
去中心化。
扩展灵活。
随着节点增加而线性增长。
• 特性丰富
支持三种存储接口:块存储、文件存储、对象存储。
支持自定义接口,支持多种语言驱动。
正常IO流程图
步骤
☑ client 创建cluster handler。
☑ client 读取配置文件。
☑ client 连接上monitor,获取集群map信息。
☑ client 读写io 根据crshmap 算法请求对应的主osd数据节点。
☑ 主osd数据节点同时写入另外两个副本节点数据。
☑ 等待主节点以及另外两个副本节点写完数据状态。
☑ 主节点及副本节点写入状态都成功后,返回给client,io写入完成 [强一致性]
Ceph IO流程及数据分布
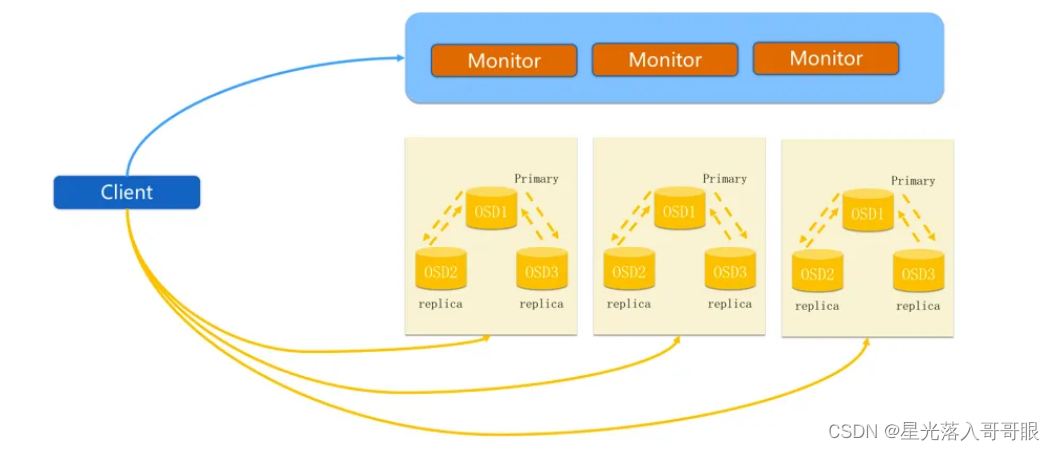
Ceph 的三个主要进程
Monitor监控整个集群的状态,维护集群的cluster MAP数据分布图(二进制表),保证集群数据的一致性。
OSD用于集群中所有数据与对象的存储,处理集群数据的复制、恢复、回填、再均衡,并向其他osd守护进程发送心跳,然后向Monitor提供监控信息。
MDS(可选)为Ceph文件系统提供元数据计算、缓存与同步。MDS进程并不是必须的进程,只有需要使用CephFS时,才需要配置MDS节点。
怎么做?如何在生产环境总快速部署ceph ceph生产环境推荐
1、存储集群采用全万兆网络
2、集群网络与公共网络分离
3,mon、mds与osd分离部署在不同机器上
4、OSD使用SATA亦可
5、根据容量规划集群
6、至强E5 2620 V3或以上cpu,64GB或更高内存
7、集群主机分散部署,避免机柜故障(电源、网络)
Ceph 在一个统一的系统中提供对象、块和文件存储。
Ceph 高度可靠、易于管理且免费。Ceph 提供了非凡的可扩展性:数以千计的客户端访问 EB 级数据。
☑ Ceph 堆栈:架构概述
基于 RADOS 的 Ceph 堆栈
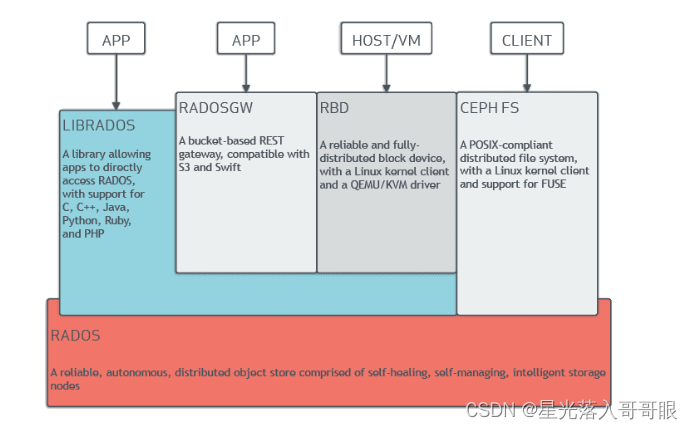
无论您需要什么交付框架,Ceph 都可以相应地进行调整和应用。Ceph 为数据存储提供了一个灵活、可扩展、可靠和智能的分布式解决方案,建立在 RADOS(可靠自主分布式对象存储)的统一基础之上。通过将所有存储作为 RADOS 中的对象进行操作,Ceph 能够轻松地将数据分布在整个集群中,即使是块和文件存储类型也是如此。
▷ 对象存储
Ceph RGW 对象存储服务提供行业领先的 S3 API 兼容性以及一组强大的安全性、分层和互操作性功能。使用 S3 或 Swift 对象存储的应用程序可以在单个数据中心内利用 Ceph 的可扩展性和性能,或者联合全球多个 Ceph 集群来创建具有大量复制、迁移和其他数据服务的全局存储命名空间。
♡ 丰富的元数据属性
利用 Ceph 中对象存储丰富的元数据属性,实现超高效的非结构化数据存储和检索:
创建易于搜索和管理的大型数据存储库。
使用云分层将经常访问的数据保留在集群中,并将不经常使用的数据转移到其他地方。
♡ 透明缓存分层
使用超高速固态硬盘作为缓存层,使用经济型硬盘作为存储层,这可以在 Ceph 中本地实现。
设置一个后备存储池、一个缓存池,然后通过 CRUSH 规则设置您的故障域。
将缓存分层与纠删码相结合,实现更经济的数据存储。
▷ 块存储
Ceph RBD(RADOS 块设备)块存储将虚拟磁盘条带化到 Ceph 存储集群内的对象上,将数据和工作负载分布在所有可用设备上,以实现极高的可扩展性和性能。RBD 磁盘镜像经过精简配置,支持只读快照和可写克隆,并可异步镜像到其他数据中心的远程 Ceph 集群进行容灾或备份,使 Ceph RBD 成为公有/私有云块存储的首选和虚拟化环境。
♡ 提供完全集成的块存储基础架构
使用 Ceph 的 iSCSI 网关享受传统存储区域网络的所有功能和优势,它提供了一个高度可用的 iSCSI 目标,可将 RBD 映像导出为 SCSI 磁盘。
♡ 与 Kubernetes 集成
动态配置 RBD 映像以支持 Kubernetes 卷,将 RBD 映像映射为块设备。因为 Ceph 最终将块设备存储为在其集群中条带化的对象,所以您将获得比使用独立服务器更好的性能!
♡ 使用 RBD 创建集群快照
▷ 文件系统
Ceph 文件系统 (CephFS) 是一个健壮、功能齐全、符合 POSIX 标准的分布式文件系统,即具有快照、配额和多集群镜像功能的服务。CephFS 文件跨 Ceph 存储的对象进行条带化,以实现极高的规模和性能。Linux 系统可以通过基于 FUSE 的客户端或通过 NFSv4 网关本地挂载 CephFS 文件系统。
♡ 可扩展的文件存储
文件元数据与文件数据存储在单独的 RADOS 池中,并通过可调整大小的元数据服务器(MDS)集群提供服务,该集群可以根据需要进行扩展以支持元数据工作负载
由于文件系统客户端直接访问 RADOS 以读取和写入文件数据块,因此工作负载可以随着底层 RADOS 对象存储的大小线性扩展,从而无需网关或代理为客户端调解数据 I/O。
♡ 导出到 NFS
CephFS 命名空间可以使用 NFS-Ganesha NFS 服务器通过 NFS 协议导出。可以使用 RGW 运行多个 NFS,从集群中导出相同或不同的资源。
▷ CRUSH 算法
CRUSH(可扩展散列下的受控复制)算法通过自动复制保持组织的数据安全和存储可扩展。使用 CRUSH 算法,Ceph 客户端和 Ceph OSD 守护进程能够跟踪存储对象的位置,避免依赖于中央查找表的架构固有的问题。
▷ 可靠的自主分布式对象存储 (RADOS)
RADOS(可靠的自主分布式对象存储)旨在利用设备智能在由数千个存储设备组成的集群中分布围绕一致数据访问、冗余存储、故障检测和故障恢复的复杂性。RADOS 专为 PB 级存储系统而设计:此类系统必然是动态的,因为它们会随着新存储的部署和旧设备的退役而逐渐增长和收缩。RADOS 确保有一致的数据分布视图,同时保持对数据对象的一致读写访问。
ceph集群部署-cephfs
CEPH 文件系统
Ceph 文件系统或CephFS是一个符合 POSIX 的文件系统,构建在 Ceph 的分布式对象存储RADOS之上。CephFS 致力于为各种应用程序(包括共享主目录、HPC 暂存空间和分布式工作流共享存储等传统用例)提供最先进的、多用途、高可用性和高性能文件存储。
CephFS 通过使用一些新颖的架构选择来实现这些目标。值得注意的是,文件元数据与文件数据存储在单独的 RADOS 池中,并通过可调整大小的元数据服务器集群或MDS提供服务,该集群可以扩展以支持更高吞吐量的元数据工作负载。文件系统的客户端可以直接访问 RADOS 以读取和写入文件数据块。出于这个原因,工作负载可能会随着底层 RADOS 对象存储的大小而线性扩展;也就是说,没有网关或代理为客户端调解数据 I/O。
对数据的访问是通过 MDS 集群来协调的,MDS 集群作为由客户端和 MDS共同维护的分布式元数据缓存状态的权限。元数据的突变由每个 MDS 聚合成一系列有效的写入 RADOS 上的日志;MDS 没有在本地存储元数据状态。该模型允许在 POSIX 文件系统的上下文中客户端之间进行一致和快速的协作。
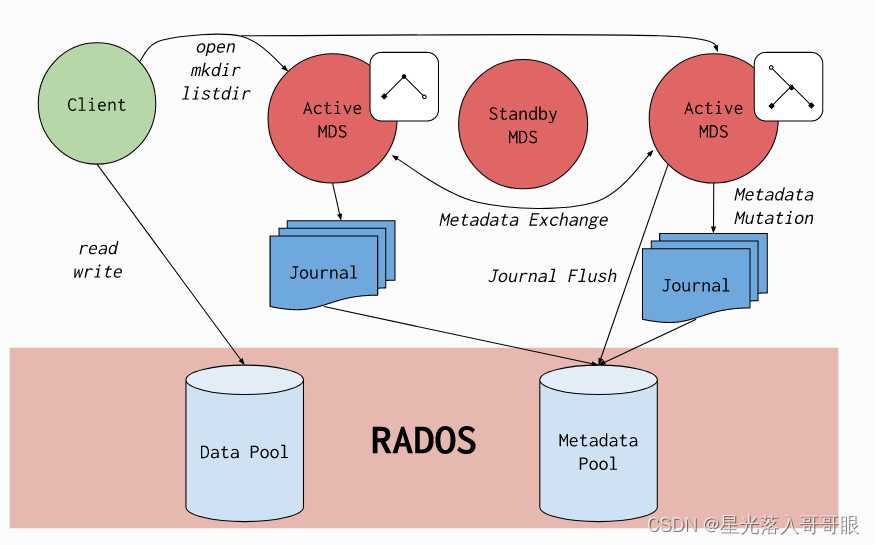
CephFS 因其新颖的设计和对文件系统研究的贡献而成为众多学术论文的主题。它是 Ceph 中最古老的存储接口,曾经是 RADOS 的主要用例。现在它与另外两个存储接口相结合,形成了一个现代的统一存储系统:RBD(Ceph Block Devices)和RGW(Ceph Object Storage Gateway)。
1.1、 环境准备 (禁用selinux, 关闭防火墙)
拓扑,cong11为管理节点

前3台机器添加一块100G的硬盘,硬盘给osd做存储使用
在安装ceph之前推荐把所有的ceph节点设置成无需密码ssh互访,配置hosts支持主机名互访,同步好时间,并关闭iptables和selinux。
1.1.1、 时间服务器的安装与启动
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
yum -y install chrony ; systemctl enable chronyd --now ; timedatectl set-ntp true ; chronyc -a makestep
1.1.2、 禁用selinux, 关闭防火墙
所有服务器都需要关闭防火墙,selinux
systemctl stop firewalld
systemctl disable firewalld --now
setenforce 0
sed -i "s/SELINUX=enforcing/SELINUX=disabled/g" /etc/selinux/config
1.1.3、 编辑hosts文件
(规范系统主机名添加hosts文件实现集群主机名与主机名之间相互能够解析(host 文件添加主机名不要使用fqdn方式)可用hostnamectl set-hostname name设置,所有的服务器都需要设置hosts
[root@cong11 ~]# vim /etc/hosts #在文件最后加入以下行
192.168.1.11 cong11
192.168.1.12 cong12
192.168.1.13 cong13
192.168.1.14 cong14
1.1.4、 SSH免密码登录
在管理节点使用ssh-keygen 生成ssh keys 发布到各节点,这里使用主机名
[root@cong11 ~]# ssh-keygen #一直回车,不设密码
[root@cong11 ~]# ssh-copy-id cong11
[root@cong11 ~]# ssh-copy-id cong12
[root@cong11 ~]# ssh-copy-id cong13
[root@cong11 ~]# ssh-copy-id cong14
# 测试ssh无交互式验证
[root@cong11 ~]# for i in 11 12 13 14 ; do ssh cong$i hostname ; done
cong11
cong12
cong13
cong14
1.2、yum源配置
1.2.1、 配置阿里网络源(所有节点)
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
1.2.2、 配置ceph源(所有节点)
[root@cong11 ~]# vim /etc/yum.repos.d/ceph.repo
[ceph]
name=ceph
baseurl=http://mirrors.163.com/ceph/rpm-luminous/el7/x86_64/
gpgcheck=0
[ceph-noarch]
name=ceph-noarch
baseurl=http://mirrors.163.com/ceph/rpm-luminous/el7/noarch/
gpgcheck=0
也可直接复制如下命令
cat > /etc/yum.repos.d/ceph.repo <<-'EOF'
[ceph]
name=ceph
baseurl=http://mirrors.163.com/ceph/rpm-luminous/el7/x86_64/
gpgcheck=0
[ceph-noarch]
name=ceph-noarch
baseurl=http://mirrors.163.com/ceph/rpm-luminous/el7/noarch/
gpgcheck=0
EOF
1.2.3、 安装epel-release(所有节点)
yum -y install epel-release yum-plugin-priorities yum-utils ntpdate
1.3、在每服务器上部署ceph
Ceph官方推出了一个用python写的工具 ceph-deploy,可以很大的简化ceph集群的配置过程,建议可以用用。
在cong11、cong12、cong13上安装,ceph-deploy是ceph集群部署工具。其他软件是依赖包。
yum install -y ceph-deploy ceph ceph-radosgw snappy leveldb gdisk python-argparse gperftools-libs yum-plugin-priorities yum-utils ntpdate
也可以预先将其下载到本地在进行安装:
yum -y install --downloadonly --downloaddir=/root/ceph/ ceph-deploy ceph ceph-radosgw snappy leveldb gdisk python-argparse gperftools-libs
本地安装(压缩包)
tar -zxf ceph-12.2.13.tar.gz
cd /root/ceph
yum localinstall *.rpm
1.4、 管理节点cong11上部署服务
1.4.1、 创建一个新集群
注:也可以同时在cong12,cong13上部署mon实现高可用,生产环境至少3个mon独立
在/etc/ceph目录操作,创建一个新集群,并设置cong11为mon节点
[root@cong11 ~]# cd /etc/ceph
[root@cong11 ceph]# ceph-deploy new cong11
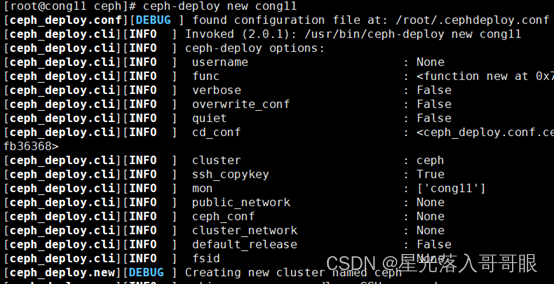
执行完毕后,可以看到/etc/ceph目录中生成了三个文件,其中有一个ceph配置文件可以做各种参数优化。(注意,在osd进程生成并挂载使用后,想修改配置需要使用命令行工具,修改配置文件是无效的,所以需要提前规划好优化的参数。),一个是监视器秘钥环。
[root@cong11 ceph]# ls
ceph.conf ceph-deploy-ceph.log ceph.mon.keyringrbdmap
1.4.2、 修改副本数
配置文件的默认副本数从3改成2,这样只有两个osd也能达到active+clean状态
[root@cong11 ceph]# vim ceph.conf
[global]
fsid = 085c7b61-cac0-494b-9bfc-18fe2cc2deb0
mon_initial_members = cong11
mon_host = 192.168.1.11
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
osd_pool_default_size = 2 #最后添加这行
1.4.3、 安装ceph monitor
[root@cong11 ceph]# ceph-deploy mon create cong11
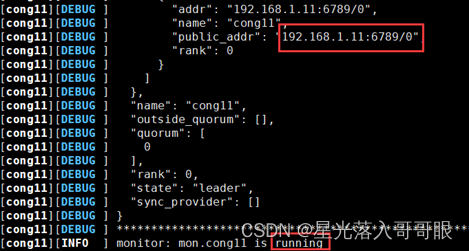
1.4.4、 收集节点的keyring文件
# 收集Ceph集群的密码文件
[root@cong11 ceph]# ceph-deploy gatherkeys cong11
[root@cong11 ceph]# ls
#连接ceph集群的admin账号秘钥
[root@cong11 ceph]# cat ceph.client.admin.keyring
[client.admin]
key = AQCNje9cfRjLFBAAdmAhq/sTE97Sbr+8dI5Ouw==

1.4.5、 部署osd服务
Ceph 12版本部署osd格式化命令跟之前不同
添加完硬盘直接使用,不要分区
1.4.5.1、 使用ceph自动分区
用下列命令擦净(删除分区表)磁盘,以用于 Ceph :
[root@cong11 ceph]# cd /etc/ceph/
[root@cong11 ceph]# ceph-deploy disk zap cong11 /dev/sdb
[root@cong11 ceph]# ceph-deploy disk zap cong12 /dev/sdb
[root@cong11 ceph]# ceph-deploy disk zap cong13 /dev/sdb
1.4.5.2、 添加osd节点
[root@cong11 ceph]# ceph-deploy osd create cong11 --data /dev/sdb
[root@cong11 ceph]# ceph-deploy osd create cong12 --data /dev/sdb
[root@cong11 ceph]# ceph-deploy osd create cong13 --data /dev/sdb

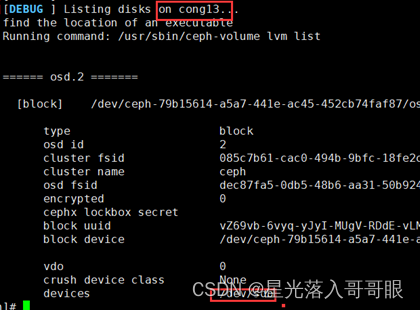
1.4.5.3、 查看osd状态
[root@cong11 ceph]# ceph-deploy osd list cong11 cong12 cong13
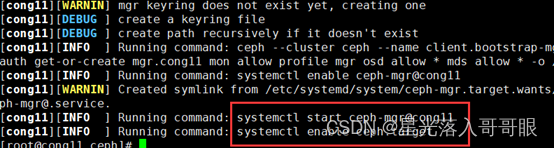
1.4.5.4、 部署 mgr 管理服务
在管理主机上部署mgr管理服务,也可以同时在cong12,cong13上部署mgr,实现高可用。
[root@cong11 ceph]# ceph-deploy mgr create cong11
1.4.5.5、 统一集群配置
用ceph-deploy把配置文件和admin密钥拷贝到所有节点,这样每次执行Ceph命令行时就无需指定monitor地址和ceph.client.admin.keyring了
[root@cong11 ceph]# ceph-deploy admin cong11 cong12 cong13
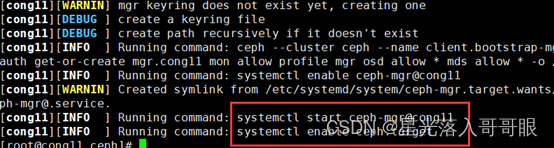
1.4.5.6、各节点修改ceph.client.admin.keyring权限
[root@cong11 ceph]# chmod +r /etc/ceph/ceph.client.admin.keyring
[root@cong12 ~]# chmod +r /etc/ceph/ceph.client.admin.keyring
[root@cong13 ~]# chmod +r /etc/ceph/ceph.client.admin.keyring
1.4.7、 部署mds服务
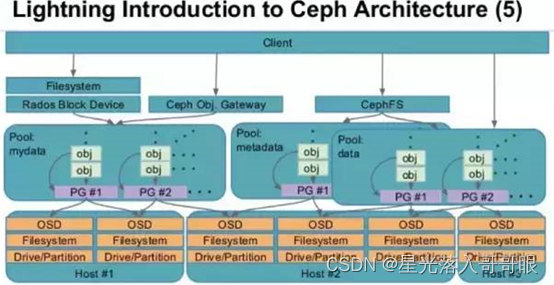
Mds是ceph集群中的元数据服务器,而通常它都不是必须的,因为只有在使用cephfs的时候才需要它,而目在云计算中用的更广泛的是另外两种存储方式。
Mds虽然是元数据服务器,但是它不负责存储元数据,元数据也是被切成对象存在各个osd节点中的,如下图:
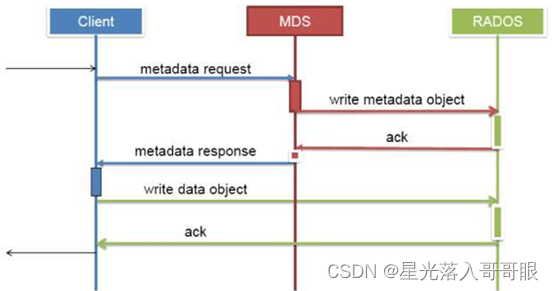
在创建CEPH FS时,要至少创建两个POOL,一个用于存放数据,另一个用于存放元数据。Mds只是负责接受用户的元数据查询请求,然后从osd中把数据取出来映射进自己的内存中供客户访问。所以mds其实类似一个代理缓存服务器,替osd分担了用户的访问压力,如下图:
安装mds
[root@cong11 ceph]# ceph-deploy mds create cong12 cong13
查看mds服务
[root@cong11 ceph]# ceph mds stat
, 2 up:standby
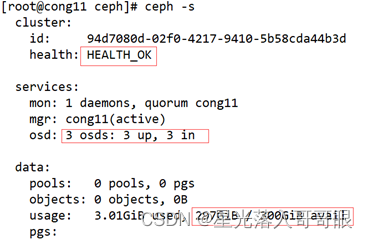
查看集群状态
[root@cong11 ceph]# ceph -s
1.5、创建ceph文件系统
创建之前查看文件系统
[root@cong11 ceph]# ceph fs ls #没有ceph文件系统
No filesystems enabled
创建存储池
命令:ceph osd pool create cephfs_data <pg_num>
ceph osd pool create cephfs_metadata <pg_num>
其中:<pg_num> = 128 ,
关于创建存储池
确定 pg_num 取值是强制性的,因为不能自动计算。下面是几个常用的值:
*少于 5 个 OSD 时可把 pg_num 设置为 128
*OSD 数量在 5 到 10 个时,可把 pg_num 设置为 512
*OSD 数量在 10 到 50 个时,可把 pg_num 设置为 4096
*OSD 数量大于 50 时,你得理解权衡方法、以及如何自己计算 pg_num 取值
*自己计算 pg_num 取值时可借助 pgcalc 工具
随着 OSD 数量的增加,正确的 pg_num 取值变得更加重要,因为它显著地影响着集群的行为、以及出错时的数据持久性(即灾难性事件导致数据丢失的概率)。
[root@cong11 ceph]# ceph osd pool create cephfs_data 128
pool 'cephfs_data' created
[root@cong11 ceph]# ceph osd pool create cephfs_metadata 128
pool 'cephfs_metadata' created
创建文件系统
创建好存储池后,你就可以用 fs new 命令创建文件系统了
命令:ceph fs new <fs_name> cephfs_metadata cephfs_data
其中:<fs_name> = cephfs 可自定义
给刚才创建的2个存储池创建文件系统
[root@cong11 ceph]# ceph fs new cephfs cephfs_metadata cephfs_data
new fs with metadata pool 2 and data pool 1
如图所示:

查看ceph文件系统
[root@cong11 ceph]# ceph fs ls
name: cephfs, metadata pool: cephfs_metadata, data pools: [cephfs_data ]
查看mds节点状态
[root@cong11 ceph]# ceph mds stat
cephfs-1/1/1 up {
0=cong13=up:active}, 1 up:standby
active是活跃的,另1个是处于热备份的状态
1.6、用内核驱动挂载Ceph文件系统
要挂载 Ceph 文件系统,如果你知道监视器 IP 地址可以用 mount 命令、或者用 mount.ceph 工具来自动解析监视器 IP 地址。
创建挂载点
[root@cong14 ~]# mkdir /data/aa
# 存储密钥(如果没有在管理节点使用ceph-deploy拷贝ceph配置文件)
[root@cong11 ~]# cat /etc/ceph/ceph.client.admin.keyring
[client.admin]
key = AQCNje9cfRjLFBAAdmAhq/sTE97Sbr+8dI5Ouw== 将`key对应的值`复制下来保存到文件:/etc/ceph/admin.secret中。
使用密钥挂载
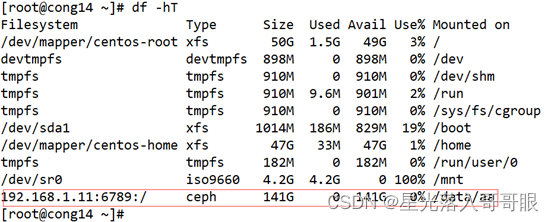
[root@cong14 ~]# mount -t ceph 192.168.1.11:6789:/ /data/aa -o name=admin,secret=AQCNje9cfRjLFBAAdmAhq/sTE97Sbr+8dI5Ouw==
[root@cong14 ~]# df -h
使用密钥文件挂载
创建秘钥文件:
[root@cong14 ~]# mkdir /etc/ceph
[root@cong14 ~]# vim /etc/ceph/admin.secret
AQCNje9cfRjLFBAAdmAhq/sTE97Sbr+8dI5Ouw==
注:adminn.secret文件中的秘钥即管理节点上/etc/ceph/ceph.client.admin.keyring的key对应的值。
[root@cong14 ~]# umount /data/aa
使用秘钥文件挂在需要安装ceph-common-12.2.12(版本要和ceph版本一致,否则无法使用密钥文件挂载)报错:

解决:
lsof /data/aa kill -9 进程PID即可
# 拷贝ceph软件包和yum配置文件到cong14
[root@cong11 ~]# scp -r ceph cong14:/root
[root@cong11 ~]# scp /etc/yum.repos.d/ceph-package.repo cong14:/etc/yum.repos.d/
# 安装ceph-common-12.2.12
[root@cong14 ~]# yum install -y ceph-common-12.2.12
# 挂载
[root@cong14 ~]# mount -t ceph 192.168.1.11:6789:/ /data/aa -o name=admin,secretfile=/etc/ceph/admin.secret
# 查看
[root@cong14 ~]# df -hT
# 取消挂载
[root@cong14 ~]# umount /data/aa
1.7、用户控件挂载Ceph文件系统(开机自动挂载)
# 安装ceph-fuse
[root@cong14 ~]# yum install -y ceph-fuse
# 挂载
[root@cong11 ~]# cd /etc/ceph
[root@cong11 ceph]# scp ceph.client.admin.keyring ceph.conf cong14:/etc/ceph/
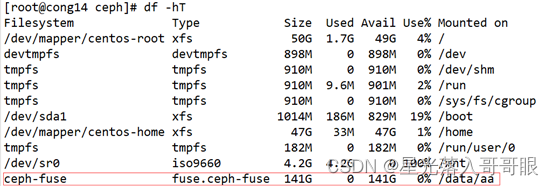
[root@cong14 ~]# ceph-fuse -m 192.168.1.11:6789 /data/aa
[root@cong14 ~]# df -hT
1.8、Ceph可视化管理dashboard
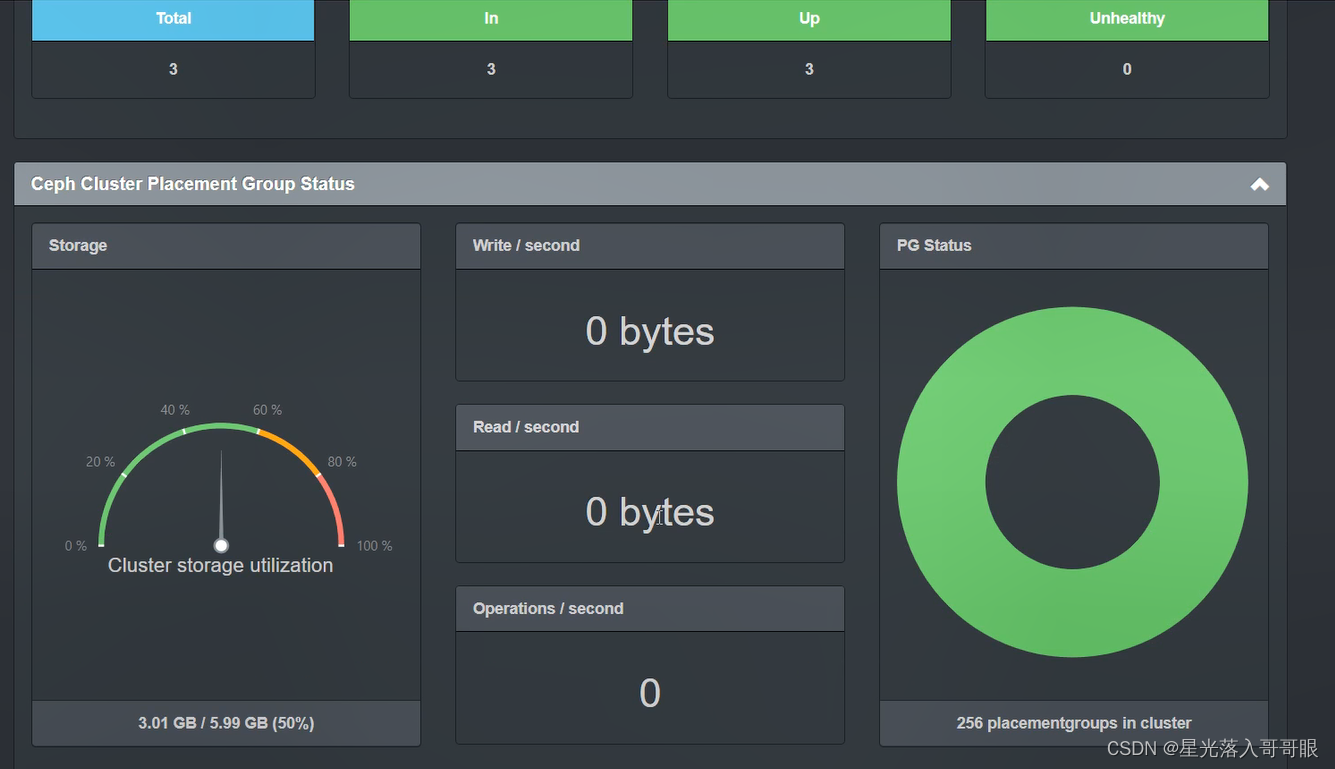
ceph-dash简介
ceph-dash极其简单,提供类似ceph -s命令的信息及实时的IO速率等。
1. 下载ceph-dash
mkdir /ceph-dash
cd /ceph-dash
git clone https://github.com/Crapworks/ceph-dash.git
2. 安装python-pip(如果系统已经安装,跳过)
yum -y install python-pip
3. 启动ceph-dash
cd /ceph-dash/ceph-dash
./ceph-dash.py &
4.修改端口
默认端口5000如果想修改端口:
vi ./ceph-dash.py
app.run(host='0.0.0.0', port=8000, debug=True)
Don’t worry too much about the vague future, only to work hard for the clear now.