一、系统架构演进
你开发了一个网站(例如网上商店、社交网站或者其他任何东西),之后你把它发布到了网上,网站运行良好,每天有几百的访问量,能快速地相响应用户的请求。
但是有一天,不知道什么原因,你的网站出名了!
每分每秒都有成千上万的用户蜂拥而至,你的网站变得越来越慢……
对你来讲,这是个好消息,但是对你的Web应用来说这是个坏消息。因为现在它需要扩展了,你的应用需要为全球用户提供7*24不宕机服务。
如何进行扩展?
几年前,我讨论过水平扩展与垂直扩展。简而言之, 垂直扩展意味着在性能更强的计算机上运行同样的服务,而水平扩展是并行地运行多个服务。
如今,几乎没有人说垂直扩展了。原因很简单:
-
随着计算机性能的增长,其价格会成倍增长。
-
单台计算机的性能是有上限的,不可能无限制地垂直扩展。
-
多核CPU意味着即使是单台计算机也可以并行的。那么,为什么不一开始就并行化呢。
现在我们水平扩展服务。需要哪些步骤呢?
1、单台服务器 + 数据库

上图可能是你后端服务最初的样子。有一个执行业务逻辑的应用服务器(Application Server)和保存数据的数据库。
看上去很不错。但是这样的配置,满足更高要求的唯一方法是在性能更强的计算机上运行,这点不是很好。
2、增加一个反向代理
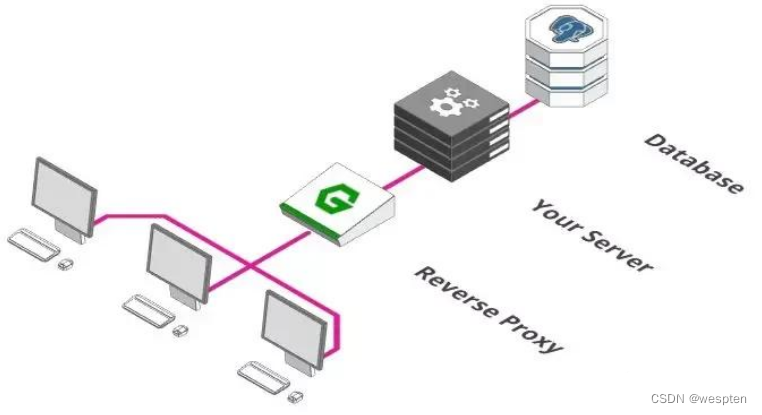
成为大规模服务架构的第一步是添加反向代理。类似于酒店大堂的接待处。
你也可以让客人直接去他们的客房。但是实际上,你需要一个中间人他去检查是否允许客人进入, 如果客房没有开放,得有人告诉客人,而不是让客人处于尴尬的境地。这些事情正是反向代理需要做的。
通常,代理是一个接收和转发请求的过程。正常情况下,「正向代理」代理的对象是客户端,「反向代理」代理的对象是服务端,它完成这些功能:
-
健康检查功能,确保我们的服务器是一直处于运行状态的。
-
路由转发功能,把请求转发到正确的服务路径上。
-
认证功能,确保用户有权限访问后端服务器。
-
防火墙功能,确保用户只能访问允许使用的网络部分等等。
3、引入负载均衡器
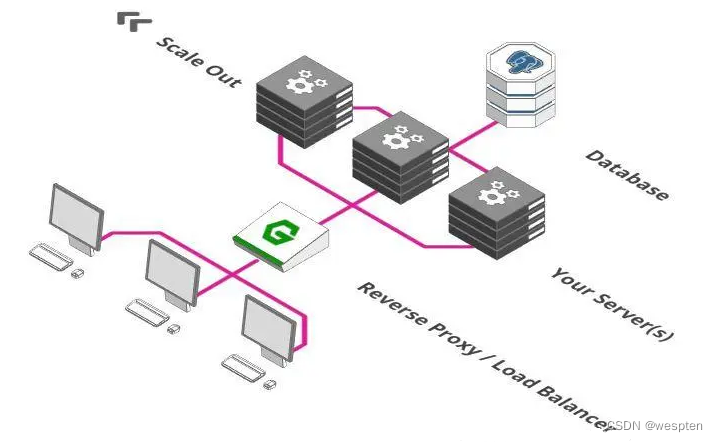
大多数反向代理还有另外一个功能:他们也可以充当负载均衡器。
负载均衡器是个简单概念,想象下有一百个用户在一分钟之内在你的网店里付款。遗憾的是,你的付款服务器在一分钟内只能处理50笔付款。这怎么办呢?同时运行两个付款服务器就行了。
负载均衡器的功能就是把付款请求分发到两台付款服务器上。用户1往左,用户2往右,用户3再往左...以此类推。
如果一次有500个用户需要立刻付款,这该怎么解决呢?确切地说,你可以扩展到十台付款服务器,之后让负载均衡器分发请求到这十台服务器上。
4、扩展数据库
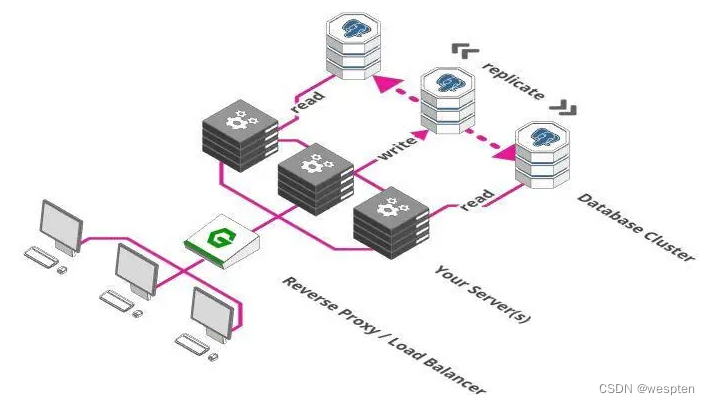
负载均衡器的使用使得我们可以在多个服务器之间分配负载。但是你发现问题了吗?尽管我们可以用成百上千台服务器处理请求,但是他们都是用同一个数据库存储和检索数据。
那么,我们不能以同样的方式来扩展数据库吗?很遗憾,这里有个一致性的问题。
系统使用的所有服务需要就他们使用的数据达成一致。数据不一致会导致各种问题,如订单被多次处理,从一个余额只有100元的账户中扣除两笔90元的付款等等......那么我们在扩展数据库的时候如何确保一致性呢?
我们需要做的第一件事是把数据库分成多个部分。一部分专门负责接收并存储数据,其他部分负责检索数据。这个方案有时称为主从模式或者单实例写多副本读。这里假设是从数据库读的频率高于写的频率。这个方案的好处是保证了一致性,因为数据只能被单实例写入,之后把写入数据同步到其他部分即可。缺点是我们仍然只有一个写数据库实例。
这对于中小型的Web应用来说没问题, 但是像Facebook这样的则不会这样做了。我们会在第九节中研究扩展数据库的步骤。
5、微服务

到目前为止,我们的付款、订单、库存、用户管理等等这些功能都在一台服务器上。
这也不是坏事,单个服务器同时意味着更低的复杂性。随着规模的增加,事情会变得复杂和低效:
-
开发团队随着应用的发展而增长。但是随着越来越多的开发人员工作在同一台服务器上,发生冲突的可能性很大。
-
仅有一台服务器,意味着每当我们发布新版本时,必须要等所有工作完成后才能发布。当一个团队想快速地发布而另外一个团队只完成了一半工作的时候,这种互相依赖性很危险。
对于这些问题的解决方案是一个新的架构范式:微服务, 它已经在开发人员中掀起了风暴。
-
每个服务都可以单独扩展,更好地适应需求
-
开发团队之间相互独立,每个团队都负责自己的微服务生命周期(创建,部署,更新等)
-
每个微服务都有自己的资源,比如数据库,进一步缓解了第4节中的问题。
6、缓存和内容分发网络(CDN)
有什么方式能使服务更高效? 网络应用的很大一部由静态资源构成,如图片、CSS样式文件、JavaScript脚本以及一些针对特定产品提前渲染好的页面等等。
我们使用缓存而不是对每个请求都重新处理,缓存用于记住最后一次的结果并交由其他服务或者客户端,这样就不用每次都请求后端服务了。
缓存的加强版叫内容分发网络(Content Delivery Network),遍布全球的大量缓存。这使得用户可以从物理上靠近他们的地方来获取网页内容,而不是每次都把数据从源头搬到用户那里。
7、消息队列
你去过游乐园吗?你是否走到售票柜台去买票?也许不是这样,可能是排队等候。***机构、邮局、游乐园入口都属于并行概念的例子,多个售票亭同时售票,但似乎也永远不足以为每个人立即服务,于是队列形成了。
队列同样也是用于大型Web应用。每分钟都有成千上万的图片上传到Instagram、Facebook每个图片都需要处理,调整大小,分析与打标签,这些都是耗时的处理过程。
因此,不要让用户等到完成所有步骤,图片接收服务只需要做以下三件事:
-
存储原始的、未处理的图片
-
向用户确认图片已经上传
-
创建一个待办的任务
这个待办事项列表中的任务可以被其他任意数量服务接收,每个服务完成其中一个任务,直到所有的待办事项完成。管理这些“待办事项列表”的称为消息队列。使用这样的队列有许多优点:
-
解耦了任务和处理过程。有时需要处理大量的图片,有时很少。有时有大量服务可用,有时很少可用。简单地把任务添加到待办事项而不是直接处理它们,这确保了系统保持响应并且任务也不会丢失。
-
可以按需扩展。启动大量的服务比较耗时,所以当有大量用户上传图片时再去启动服务,这已经太晚了。我们把任务添加到队列中,我们可以推迟提供额外的处理能力。
好了,如果按照我们上面的所有步骤操作下来,我们的系统已经做好提供大流量服务的准备了。但是如果还想提供更大量的,该怎么做呢?还有一些可以做:
8、分片,分片,还是分片

什么是分片?好吧,深呼吸一下,准备好了吗?我们看下定义:
"Sharding is a technique of parallelizing an application's stacks by separating them into multiple units, each responsible for a certain key or namespace"
哎呦...... 分片究竟是是什么意思呢?
其实也很简单:Facebook上需要为20亿用户提供个人资料, 可以把你的应用架构分解为 26个mini-Facebook, 用户名如果以A开头,会被mini-facebook A处理, 用户名如果以B开头,会被mini-facebook B来处理……
分片不一定按字母顺序,根据业务需要,你可以基于任何数量的因素,比如位置、使用频率(特权用户被路由到好的硬件)等等。你可以根据需要以这种方式切分服务器、数据库或其他方面。
9、对负载均衡器进行负载均衡

到目前为止,我们一直使用一个负载均衡器,即使你购买的一些功能强悍(且其价格极其昂贵)的硬件负载均衡器,但是他们可以处理的请求量也存在硬件限制。
幸运地是,我们可以有一个全球性、分散且稳定的层,用于在请求达到负载均衡器之前对请求负载均衡。最棒的地方是免费,这是域名系统或简称DNS。DNS将域名(如arcentry.com)映射到IP,143.204.47.77。DNS允许我们为域名指定多个IP,每个IP都会解析到不同的负载均衡器。
你看,扩展Web应用确实需要考虑很多东西,感谢你和我们一起待了这么久。我希望这篇文章能给你一些有用的东西。但是如果你做任何IT领域相关的工作,你在阅读本文的时候,可能有个问题一直萦绕在你的脑海:"云服务是怎样的呢?"
Cloud Computing / Serverless
但是云服务如何呢?确实,它是上面许多问题最有效的解决方案。
你无需解决这些难题。相反,这些难题留给了云厂商,他们为我们提供一个系统,可以根据需求进行扩展,而不用担心错综复杂的问题。
例如。Arcentry网站不会执行上述讨论的任何操作(除了数据库的读写分离),而只是把这些难题留给Amazon Web Service Lambda函数处理了,用户省去了烦恼。
但是,并不是说你使用了云服务以后(如 Amazon Web Service Lambda),所有的问题都解决了,它随之而来的是一系列挑战和权衡。
同样,一旦我们打破了我们的单体,我们如何将它重新组合成一个仍然有意义的更大系统?尽管 Istio、Kong 或 Kafka 爱好者会告诉你如何做,但这个问题的答案不止一个,而且不同的解决方案也有不同的适合不同需求的方式。
为了正常运行,基于微服务的架构必须解决一些特定于其分布式特性的挑战:
1)弹性
任何给定的微服务可能有数十甚至数百个实例——每个实例都可能在任何时间点由于多种原因而失败。
2)负载平衡和自动缩放
由于可能有数百个端点能够满足请求,路由和扩展绝不是微不足道的。事实上,对于大型架构而言,最有效的成本节约措施之一就是提高路由和扩展决策的精度。
3)服务发现
应用程序越复杂和分布式,就越难找到现有的端点并与它们建立通信通道。
4)追踪与监控
微服务架构中的单个事务可能会穿越多个服务,因此很难追踪其旅程。
5)版本控制
随着系统的成熟,更新可用的端点和 API 变得至关重要,同时确保旧版本仍然可用。
解决方案:
好的,是时候与解决这些问题的竞争者见面了:服务网格、API 网关和消息队列。当然,还有许多其他方法,从简单的静态负载平衡和固定 IP 到中央编排服务器 - 但出于本文的目的,让我们看看当前最流行且在许多方面最复杂的选项。
10、 API网关

API 网关是用于 HTTP 调用的老式反向代理的大哥。它是一个可扩展的、通常面向 Web 的服务器,可以接收来自公共互联网和内部服务的请求,并将它们转发到最适合的微服务实例。API 网关通常带有许多有用的功能,包括负载平衡和健康检查、API 版本控制和路由、请求身份验证和授权、数据转换、分析、日志记录、SSL 终止等。流行的开源 API 网关的示例是 Kong 或 Tyk。大多数云提供商也提供自己的实现,例如 AWS API Gateway、Azure Api Management 或 Google Cloud Endpoints。
好处
API 网关功能强大,复杂性相对较低,并且很容易被经验丰富的网络老手理解。它们为公共互联网提供了坚实的防御层,并减轻了许多重复性任务,例如用户身份验证或数据验证。
缺点
API 网关是相当集中的。它们可以以水平可扩展的方式部署,但与服务网格不同,它们仍然需要单点来注册新的 API 或更改配置。从组织的角度来看,它们很可能由单个团队维护。
11、服务网关(Service Meshes)
服务网格是处理负载平衡、端点发现、健康检查、监控和跟踪的微服务实例之间的分散和自组织网络。它们通过为每个实例附加一个称为“sidecar”的小型代理来工作,该代理负责调解流量并处理实例注册、指标收集和维护。虽然在概念上是分散的,但大多数服务网格都带有一个或多个中心元素来收集数据或提供管理界面。流行的例子包括 Istio、Linkerd 或 Hashicorp 的 Consul。
好处
服务网格更具动态性,可以轻松改变形状并适应新的功能和端点。它们的去中心化特性使得在相当孤立的团队中更容易处理微服务。
缺点
服务网格可能非常复杂,需要大量移动部件。例如,充分利用 Istio 需要为每个节点部署单独的流量管理器、遥测收集器、证书管理器和 sidecar 进程。它们也是一个相当新的发展,使构成您架构的支柱的东西年轻得令人担忧。
12、消息队列

乍一看,将服务网格与消息队列进行比较就像将苹果与橙子进行比较:它们是完全不同的东西,但它们解决了相同的问题,尽管方式非常不同。
消息队列允许您通过解耦发送方和接收方在服务之间建立复杂的通信模式它们使用许多概念来实现这一点,例如基于主题的路由或发布-订阅消息传递,以及使多个实例变得容易的缓冲任务队列随着时间的推移处理任务的不同方面。
消息队列已经存在了很长时间,因此有多种选择:流行的开源替代品包括 Apache Kafka、AMQP 代理(如 RabbitMQ 或 HornetQ)以及云提供商版本(如 AWS SQS 或 Kinesis、Google PubSub 或 Azure 服务总线)。
好处
简单地将发送者和接收者解耦是一个强有力的概念,它使得许多其他概念(如健康检查、路由、端点发现或负载平衡)变得不必要。实例可以在准备好时从缓冲队列中选择相关任务。当自动编排和扩展决策基于每个队列中的消息计数时,这变得特别强大,从而导致资源高效的系统。
缺点
消息队列不擅长请求/响应通信。有些人允许将其硬塞到现有概念之上,但这并不是它们的真正目的。由于它们的缓冲特性,它们还可以为系统增加显着的延迟。它们也相当集中(尽管可以水平扩展)并且大规模运行的成本可能相当高
该如何选择?
实际上 - 这不一定是一个非此即彼的决定。事实上,使用 API 网关前端面向公众的 API、运行服务网格来处理服务间通信并使用消息队列支持异步任务调度是非常有意义的。
但是,如果我们只关注服务间通信,一个可能的答案可能是:
- 如果您已经为面向公众的 API 运行了 API 网关,那么您不妨保持较低的复杂性并将其重用于服务间通信
- 如果您在一个团队孤立且沟通不畅的大型组织中工作,那么服务网格可以为您提供最高程度的独立性,从而可以轻松地随着时间的推移添加新服务。
- 如果您正在设计一个系统,其中各个步骤随着时间的推移而间隔开,例如,上传、处理和发布视频可能需要几分钟的 youtube 类服务,请使用消息或任务队列。
服务网格还是一个相当年轻的概念,例如 Istio。将来这些概念将越来越多地融合在一起,从而产生一个更加分散的服务网格,提供两者外部 API 访问和内部通信——甚至可能是以缓冲的、类似队列的方式。
二、高并发系统架构
高并发,几乎是每个程序员都想拥有的经验。原因很简单:随着流量变大,会遇到各种各样的技术问题,比如接口响应超时、CPU load升高、GC频繁、死锁、大数据量存储等等,这些问题能推动我们在技术深度上不断精进。
在过往的面试中,如果候选人做过高并发的项目,我通常会让对方谈谈对于高并发的理解,但是能系统性地回答好此问题的人并不多,大概分成这样几类:
1. 对数据化的指标没有概念:不清楚选择什么样的指标来衡量高并发系统?分不清并发量和QPS,甚至不知道自己系统的总用户量、活跃用户量,平峰和高峰时的QPS和TPS等关键数据。
2. 设计了一些方案,但是细节掌握不透彻:讲不出该方案要关注的技术点和可能带来的副作用。比如读性能有瓶颈会引入缓存,但是忽视了缓存命中率、热点key、数据一致性等问题。
3. 理解片面,把高并发设计等同于性能优化:大谈并发编程、多级缓存、异步化、水平扩容,却忽视高可用设计、服务治理和运维保障。
4. 掌握大方案,却忽视最基本的东西:能讲清楚垂直分层、水平分区、缓存等大思路,却没意识去分析数据结构是否合理,算法是否高效,没想过从最根本的IO和计算两个维度去做细节优化。
结合自己的高并发项目经验,系统性地总结下高并发需要掌握的知识和实践思路,希望对你有所帮助。内容分成以下3个部分:
- 如何理解高并发?
- 高并发系统设计的目标是什么?
- 高并发的实践方案有哪些?
1、如何理解高并发
高并发意味着大流量,需要运用技术手段抵抗流量的冲击,这些手段好比操作流量,能让流量更平稳地被系统所处理,带给用户更好的体验。
我们常见的高并发场景有:淘宝的双11、春运时的抢票、微博大V的热点新闻等。除了这些典型事情,每秒几十万请求的秒杀系统、每天千万级的订单系统、每天亿级日活的信息流系统等,都可以归为高并发。
很显然,上面谈到的高并发场景,并发量各不相同,那到底多大并发才算高并发呢?
1、不能只看数字,要看具体的业务场景。不能说10W QPS的秒杀是高并发,而1W QPS的信息流就不是高并发。信息流场景涉及复杂的推荐模型和各种人工策略,它的业务逻辑可能比秒杀场景复杂10倍不止。因此,不在同一个维度,没有任何比较意义。
2、业务都是从0到1做起来的,并发量和QPS只是参考指标,最重要的是:在业务量逐渐变成原来的10倍、100倍的过程中,你是否用到了高并发的处理方法去严谨你的系统,从架构设计、编码实现、甚至产品方案等维度去预防和解决高并发引起的问题?而不是一味的升级硬件、加机器做水平扩展。
此外,各个高并发场景的业务特点完全不同:有读多写少的信息流场景、有读多写多的交易场景,那是否有通用的技术方案解决不同场景的高并发问题呢?
我觉得大的思路可以借鉴,别人的方案也可以参考,但是真正落地过程中,细节上还会有无数的坑。另外,由于软硬件环境、技术栈、以及产品逻辑都没法做到完全一致,这些都会导致同样的业务场景,就算用相同的技术方案也会面临不同的问题,这些坑还得一个个趟。
因此,这篇文章我会将重点放在基础知识、通用思路、和我曾经实践过的有效经验上,希望让你对高并发有更深的理解。
2、高并发系统设计的目标是什么
先搞清楚高并发系统设计的目标,在此基础上再讨论设计方案和实践经验才有意义和针对性。
宏观目标:
高并发绝不意味着只追求高性能,这是很多人片面的理解。从宏观角度看,高并发系统设计的目标有三个:高性能、高可用,以及高可扩展。
1、高性能:性能体现了系统的并行处理能力,在有限的硬件投入下,提高性能意味着节省成本。同时,性能也反映了用户体验,响应时间分别是100毫秒和1秒,给用户的感受是完全不同的。
2、高可用:表示系统可以正常服务的时间。一个全年不停机、无故障;另一个隔三差五出现上事故、宕机,用户肯定选择前者。另外,如果系统只能做到90%可用,也会大大拖累业务。
3、高扩展:表示系统的扩展能力,流量高峰时能否在短时间内完成扩容,更平稳地承接峰值流量,比如双11活动、明星离婚等热点事件。

这3个目标是需要通盘考虑的,因为它们互相关联、甚至也会相互影响。
比如说:考虑系统的扩展能力,你会将服务设计成无状态的,这种集群设计保证了高扩展性,其实也间接提升了系统的性能和可用性。
再比如说:为了保证可用性,通常会对服务接口进行超时设置,以防大量线程阻塞在慢请求上造成系统雪崩,那超时时间设置成多少合理呢?一般,我们会参考依赖服务的性能表现进行设置。
再从微观角度来看,高性能、高可用和高扩展又有哪些具体的指标来衡量?为什么会选择这些指标呢?
3、性能指标
通过性能指标可以度量目前存在的性能问题,同时作为性能优化的评估依据。一般来说,会采用一段时间内的接口响应时间作为指标。
1. 平均响应时间:最常用,但是缺陷很明显,对于慢请求不敏感。比如1万次请求,其中9900次是1ms,100次是100ms,则平均响应时间为1.99ms,虽然平均耗时仅增加了0.99ms,但是1%请求的响应时间已经增加了100倍。
2. TP90、TP99等分位值:将响应时间按照从小到大排序,TP90表示排在第90分位的响应时间, 分位值越大,对慢请求越敏感。

3. 吞吐量:和响应时间呈反比,比如响应时间是1ms,则吞吐量为每秒1000次。
通常,设定性能目标时会兼顾吞吐量和响应时间,比如这样表述:在每秒1万次请求下,AVG控制在50ms以下,TP99控制在100ms以下。对于高并发系统,AVG和TP分位值必须同时要考虑。
另外,从用户体验角度来看,200毫秒被认为是第一个分界点,用户感觉不到延迟,1秒是第二个分界点,用户能感受到延迟,但是可以接受。
因此,对于一个健康的高并发系统,TP99应该控制在200毫秒以内,TP999或者TP9999应该控制在1秒以内。
4、可用性指标
高可用性是指系统具有较高的无故障运行能力,可用性 = 平均故障时间 / 系统总运行时间,一般使用几个9来描述系统的可用性。

对于高并发系统来说,最基本的要求是:保证3个9或者4个9。原因很简单,如果你只能做到2个9,意味着有1%的故障时间,像一些大公司每年动辄千亿以上的GMV或者收入,1%就是10亿级别的业务影响。
5、可扩展性指标
面对突发流量,不可能临时改造架构,最快的方式就是增加机器来线性提高系统的处理能力。
对于业务集群或者基础组件来说,扩展性 = 性能提升比例 / 机器增加比例,理想的扩展能力是:资源增加几倍,性能提升几倍。通常来说,扩展能力要维持在70%以上。
但是从高并发系统的整体架构角度来看,扩展的目标不仅仅是把服务设计成无状态就行了,因为当流量增加10倍,业务服务可以快速扩容10倍,但是数据库可能就成为了新的瓶颈。
像MySQL这种有状态的存储服务通常是扩展的技术难点,如果架构上没提前做好规划(垂直和水平拆分),就会涉及到大量数据的迁移。
因此,高扩展性需要考虑:服务集群、数据库、缓存和消息队列等中间件、负载均衡、带宽、依赖的第三方等,当并发达到某一个量级后,上述每个因素都可能成为扩展的瓶颈点。
6、并发的实践方案有哪些
了解了高并发设计的3大目标后,再系统性总结下高并发的设计方案,会从以下两部分展开:先总结下通用的设计方法,然后再围绕高性能、高可用、高扩展分别给出具体的实践方案。
通用的设计方法
通用的设计方法主要是从「纵向」和「横向」两个维度出发,俗称高并发处理的两板斧:纵向扩展和横向扩展。
1)纵向扩展(scale-up)
它的目标是提升单机的处理能力,方案又包括:
1. 提升单机的硬件性能:通过增加内存、CPU核数、存储容量、或者将磁盘升级成SSD等堆硬件的方式来提升。
2. 提升单机的软件性能:使用缓存减少IO次数,使用并发或者异步的方式增加吞吐量。
2)横向扩展(scale-out)
因为单机性能总会存在极限,所以最终还需要引入横向扩展,通过集群部署以进一步提高并发处理能力,又包括以下2个方向:
1. 做好分层架构:这是横向扩展的提前,因为高并发系统往往业务复杂,通过分层处理可以简化复杂问题,更容易做到横向扩展。
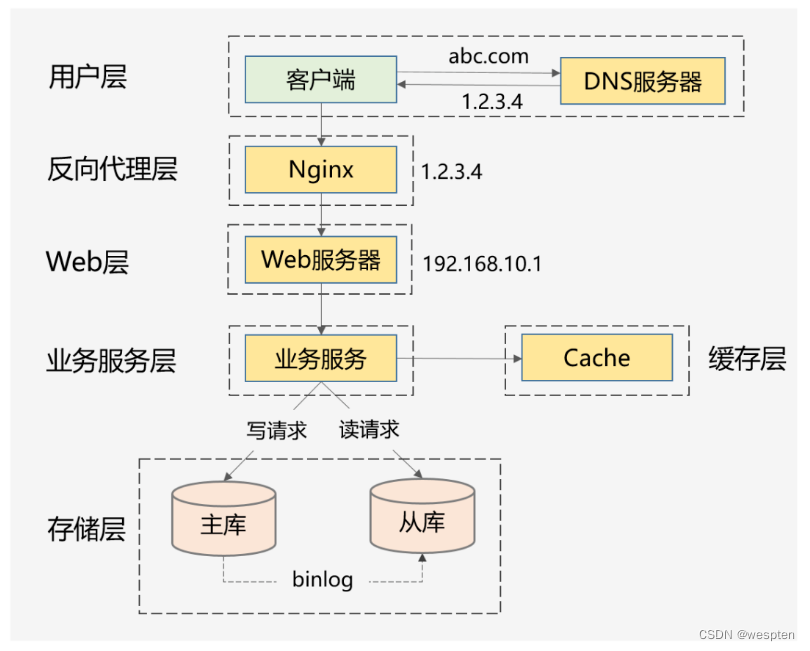
上面这种图是互联网最常见的分层架构,当然真实的高并发系统架构会在此基础上进一步完善。比如会做动静分离并引入CDN,反向代理层可以是LVS+Nginx,Web层可以是统一的API网关,业务服务层可进一步按垂直业务作为服务化,存储层可以是各种异构数据库。
2. 各层进行水平扩展:无状态水平扩容,有状态做分片路由。业务集群通常能设计成无状态的,而数据库和缓存往往是有状态的,因此需要设计分区键做好存储分片,当然也可以通过主从同步、读写分离的方案提升读性能。
下面再结合我的个人经验,针对高性能、高可用、高扩展3个方面,总结下可落地的实践方案。
7、高性能的实践方案
1. 集群部署,通过负载均衡减轻单机压力。
2. 多级缓存,包括静态数据使用CDN、本地缓存、分布式缓存等,以及对缓存场景中的热点key、缓存穿透、缓存并发、数据一致性等问题的处理。
3. 分库分表和索引优化,以及借助搜索引擎解决复杂查询问题。
4. 考虑NoSQL数据库的使用,比如HBase、TiDB等,但是团队必须熟悉这些组件,且有较强的运维能力。
5. 异步化,将次要流程通过多线程、MQ、甚至延时任务进行异步处理。
6. 限流,需要先考虑业务是否允许限流(比如秒杀场景是允许的),包括前端限流、Nginx接入层的限流、服务端的限流。
7. 对流量进行削峰填谷,通过MQ承接流量。
8. 并发处理,通过多线程将串行逻辑并行化。
9. 预计算,比如抢红包场景,可以提前计算好红包金额缓存起来,发红包时直接使用即可。
10. 缓存预热,通过异步任务提前预热数据到本地缓存或者分布式缓存中。
11. 减少IO次数,比如数据库和缓存的批量读写、RPC的批量接口支持、或者通过冗余数据的方式干掉RPC调用。
12. 减少IO时的数据包大小,包括采用轻量级的通信协议、合适的数据结构、去掉接口中的多余字段、减少缓存key的大小、压缩缓存value等。
13. 程序逻辑优化,比如将大概率阻断执行流程的判断逻辑前置、For循环的计算逻辑优化,或者采用更高效的算法。
14. 各种池化技术的使用和池大小的设置,包括HTTP请求池、线程池(考虑CPU密集型还是IO密集型设置核心参数)、数据库和Redis连接池等。
15. JVM优化,包括新生代和老年代的大小、GC算法的选择等,尽可能减少GC频率和耗时。
16. 锁选择,读多写少的场景用乐观锁,或者考虑通过分段锁的方式减少锁冲突。
上述方案无外乎从计算和 IO 两个维度考虑所有可能的优化点,需要有配套的监控系统实时了解当前的性能表现,并支撑你进行性能瓶颈分析,然后再遵循二八原则,抓主要矛盾进行优化。
8、高可用的实践方案
1. 对等节点的故障转移,Nginx和服务治理框架均支持一个节点失败后访问另一个节点。
2. 非对等节点的故障转移,通过心跳检测并实施主备切换(比如redis的哨兵模式或者集群模式、MySQL的主从切换等)。
3. 接口层面的超时设置、重试策略和幂等设计。
4. 降级处理:保证核心服务,牺牲非核心服务,必要时进行熔断;或者核心链路出问题时,有备选链路。
5. 限流处理:对超过系统处理能力的请求直接拒绝或者返回错误码。
6. MQ场景的消息可靠性保证,包括producer端的重试机制、broker侧的持久化、consumer端的ack机制等。
7. 灰度发布,能支持按机器维度进行小流量部署,观察系统日志和业务指标,等运行平稳后再推全量。
8. 监控报警:全方位的监控体系,包括最基础的CPU、内存、磁盘、网络的监控,以及Web服务器、JVM、数据库、各类中间件的监控和业务指标的监控。
9. 灾备演练:类似当前的“混沌工程”,对系统进行一些破坏性手段,观察局部故障是否会引起可用性问题。
高可用的方案主要从冗余、取舍、系统运维3个方向考虑,同时需要有配套的值班机制和故障处理流程,当出现线上问题时,可及时跟进处理。
9、高扩展的实践方案
1. 合理的分层架构:比如上面谈到的互联网最常见的分层架构,另外还能进一步按照数据访问层、业务逻辑层对微服务做更细粒度的分层(但是需要评估性能,会存在网络多一跳的情况)。
2. 存储层的拆分:按照业务维度做垂直拆分、按照数据特征维度进一步做水平拆分(分库分表)。
3. 业务层的拆分:最常见的是按照业务维度拆(比如电商场景的商品服务、订单服务等),也可以按照核心接口和非核心接口拆,还可以按照请求去拆(比如To C和To B,APP和H5)。
总结:
并发确实是一个复杂且系统性的问题,由于篇幅有限,诸如分布式Trace、全链路压测、柔性事务都是要考虑的技术点。另外,如果业务场景不同,高并发的落地方案也会存在差异,但是总体的设计思路和可借鉴的方案基本类似。
高并发设计同样要秉承架构设计的3个原则:简单、合适和严谨。“过早的优化是万恶之源”,不能脱离业务的实际情况,更不要过度设计,合适的方案就是最完美的。
三、接口优化方案
最近对外接口偶现504超时问题,原因是代码执行时间过长,超过nginx配置的15秒,然后真枪实弹搞了一次接口性能优化。
性能优化的八个要点:
- 数据量比较大,批量操作数据入库
- 耗时操作考虑异步处理
- 恰当使用缓存
- 优化程序逻辑、代码
- SQL优化
- 压缩传输内容
- 考虑使用文件/MQ等其他方式暂存,异步再落地DB
- 跟产品讨论需求最恰当,最舒服的实现方式
先看一下我们对外转账接口的大概流程吧:

1、数据量比较大,批量操作数据入库
优化前:
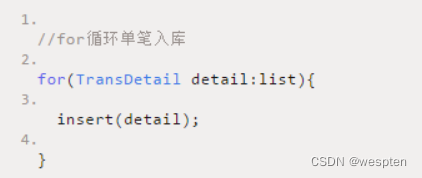
优化后:

性能对比:

- 批量插入性能更好,更加省时间,为什么呢?
打个比喻:假如你需要搬一万块砖到楼顶,你有一个电梯,电梯一次可以放适量的砖(最多放500),你可以选择一次运送一块砖,也可以一次运送500,你觉得哪种方式更方便,时间消耗更少?
2、耗时操作考虑异步处理
耗时操作,考虑用异步处理,这样可以降低接口耗时。本次转账接口优化,匹配联行号的操作耗时有点长,所以优化过程把它移到异步处理了,如下:
优化前:

优化后:
匹配联行号的操作异步处理。

性能对比:
假设一个联行号匹配6ms。
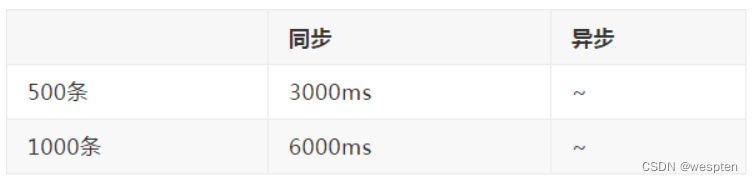
解析:
- 因为联行号匹配比较耗时,放在异步处理的话,同步联机返回可以省掉这部分时间,大大提升接口性能,并且不会影响到转账主流程功能。
- 除了这个例子,平时我们类似功能,如用户注册成功后,短信邮件通知,也是可以异步处理。
- 所以,太耗时的操作,在不影响主流程功能的情况下,可以考虑开子线程异步处理的。
3、恰当使用缓存
在适当的业务场景,恰当地使用缓存,是可以大大提高接口性能的。这里的缓存包括:Redis,JVM本地缓存,memcached,或者Map等。
这次转账接口,使用到缓存啦,举个简单例子。
优化前:
以下是输入用户账号,匹配联行号的流程图:
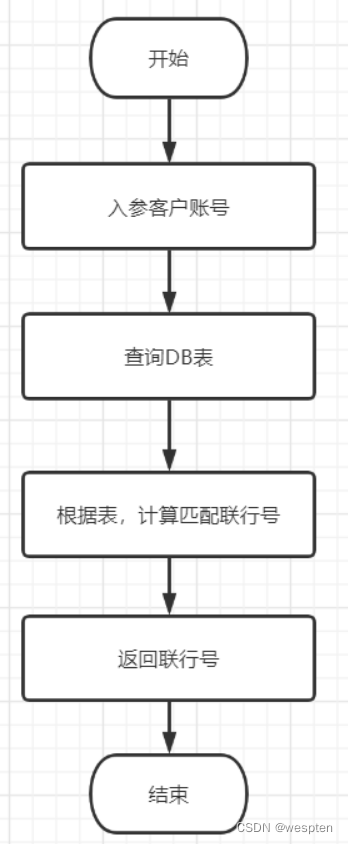
优化后:
恰当使用缓存,代替查询DB表,流程图如下:

解析:
- 把热点数据放到缓存,不用每次查询都去DB拉取,节省了这部分查SQL的耗时。
- 当然,不是什么数据都适合放到缓存的哦,访问比较频繁的热点数据才考虑缓存起来。
4、优化程序逻辑、代码
优化程序逻辑、程序代码,是可以节省耗时的。
我这里就本次的转账接口优化,举个例子:
优化前:
优化前,联行号查询了两次(检验参数一次,插入DB前查询一次),如下伪代码:

优化后:
优化后,只在校验参数的时候插叙一次,然后设置到对象里面,入库前就不用再查啦,伪代码如下:

说明:
- 对于优化程序逻辑、代码,是可以降低接口耗时的。以上demo只是一个很简单的例子,就是优化前payeeBankNo查询了两次,但是其实只查一次就可以了。很多时候,我们都知道这个点,但就是到写代码的时候,又忘记了呀~所以,写代码的时候,留点心吧,优化你的程序逻辑、代码。
- 除了以上demo这点,还有其它特点,如优化if复杂的逻辑条件,考虑是否可以调整顺序,或者for循环,是否重复实例化对象等等,这些适当优化,都是可以让你的代码跑得更快的。
5、优化你的SQL
很多时候,你的接口性能瓶颈就在SQL这里,慢查询需要我们重点关注的点呢。
我们可以通过这些方式优化我们的SQL:
- 加索引
- 避免返回不必要的数据
- 优化sql结构
- 分库分表
- 读写分离
6、压缩传输内容
压缩传输内容,文件变得更小,因此传输会更快啦。10M带宽,传输10k的报文,一般比传输1M的会快呀;打个比喻,一匹千里马,它驮着一百斤的货跑得快,还是驮着10斤的货物跑得快呢?
解析:
- 如果你的接口性能不好,然后传输报文比较大的话,这时候是可以考虑压缩文件内容传输的,最后优化效果可能很不错的。
7、考虑使用文件/MQ等其他方式暂存数据,异步再落地DB
如果数据太大,落地数据库实在是慢的话,可以考虑先用文件的方式保存,或者考虑MQ,先落地,再异步保存到数据库。
本次转账接口,如果是并发开启,10个并发度,每个批次1000笔数据,数据库插入会特别耗时,大概10秒左右,这个跟我们公司的数据库同步机制有关,并发情况下,因为优先保证同步,所以并行的插入变成串行啦,就很耗时。
优化前:
优化前,1000笔先落地DB数据库,再异步转账,如下:
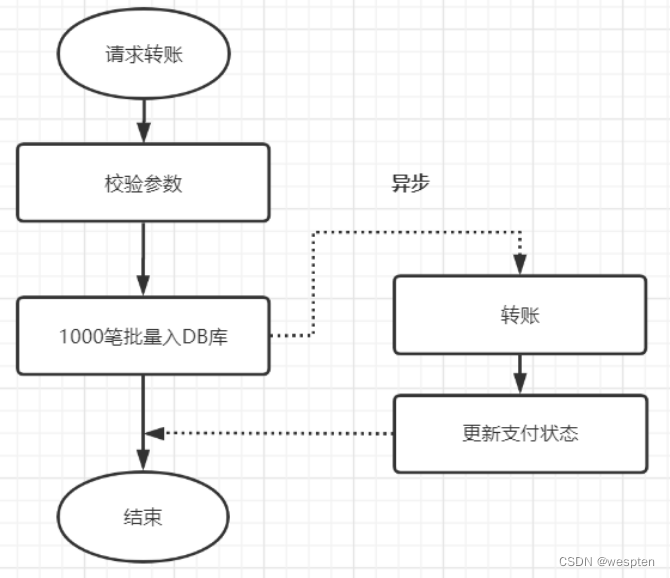
优化后:
先保存数据到文件,再异步下载下来,插入数据库,如下:
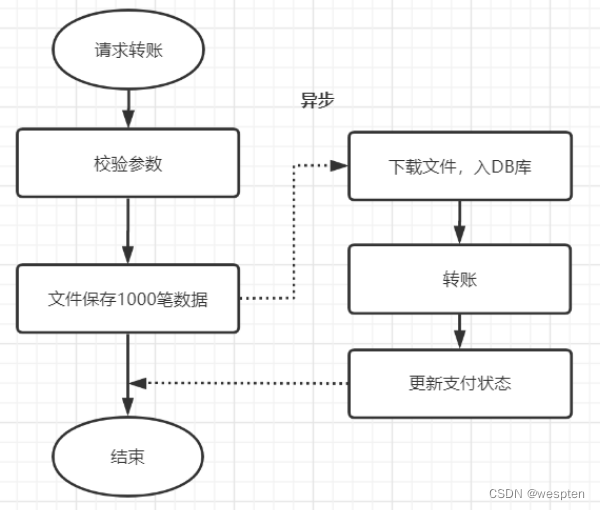
解析:
- 如果你的耗时瓶颈就在数据库插入操作这里了,那就考虑文件保存或者MQ或者其他方式暂存吧,文件保存数据,对比一下耗时,有时候会有意想不到的效果。
8、跟产品讨论需求最恰当,最舒服的实现方式
这点个人觉得还是很重要的,有些需求需要好好跟产品沟通的。
比如有个用户连麦列表展示的需求,产品说要展示所有的连麦信息,如果一个用户的连麦列表信息好大,你拉取所有连麦数据回来,接口性能就降下来了。
如果产品打桩分析,会发现,一般用户看连麦列表,也就看前几页。其实,那个超大分页加载问题也是类似的,即limit +一个超大的数,一般会很慢的
四、线上问题排查定位
排除工具:
jps:列出正在运行的虚拟机进程
jstat:监视虚拟机各种运行状态信息,可以显示虚拟机进程中的类装载、内存、垃圾收集、JIT编译等运行数据
jinfo:实时查看和调整虚拟机各项参数
jmap:生成堆转储快照,也可以查询 finalize 执行队列、Java 堆和永久代的详细信息
jstack:生成虚拟机当前时刻的线程快照
jhat:虚拟机堆转储快照分析工具
与 jmap 搭配使用,分析 jmap 生成的堆转储快照,与 MAT 的作用类似。
Eclipse Memory Analyer:是一款内存分析工具,插件版MAT。
JProfile: Windows 可视化工具。
JProbe Profiler:监控应用程序字节码。
JVisualVM:对堆内存进行dump、快照以及性能可视化分析。
JConsole:实时监控JVM的一些简单状态信息。
Plumbr:自动性能监控工具。
排除步骤:
1. 先找到对应的进程: PID
2. 生成线程快照 stack (或堆转储快照: hprof )
3. 分析快照(或堆转储快照),定位问题
内存泄露、内存溢出和 CPU 100% 关系:

1、CPU 100%
① Windows
1. 找到 cpu 占有率最高的 java 进程号

PID: 20260
2. 根据进程号找到 cpu 占有率最高的线程号。
双击刚刚找到的 java 进程:
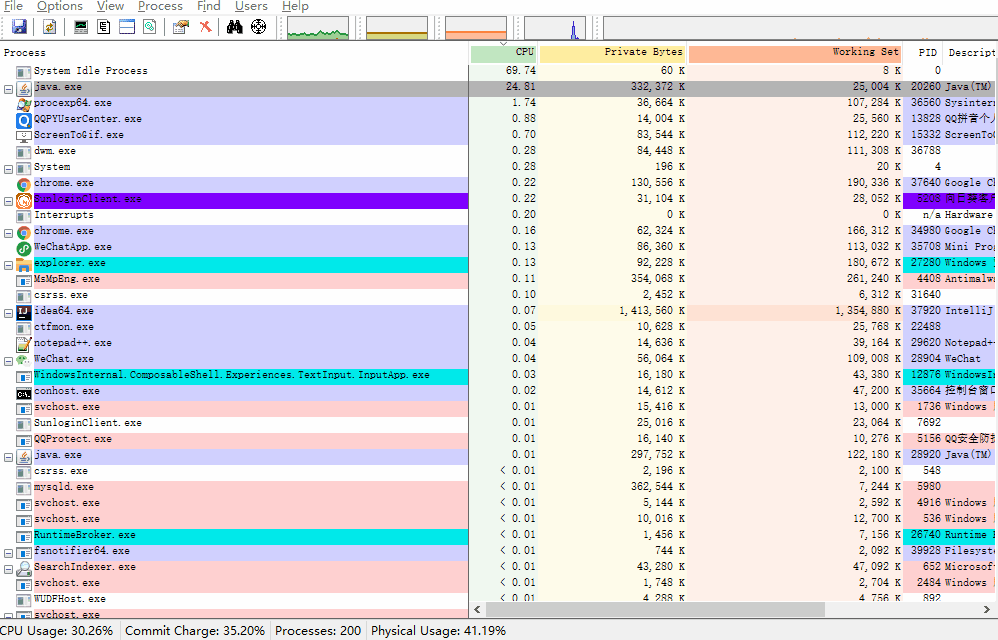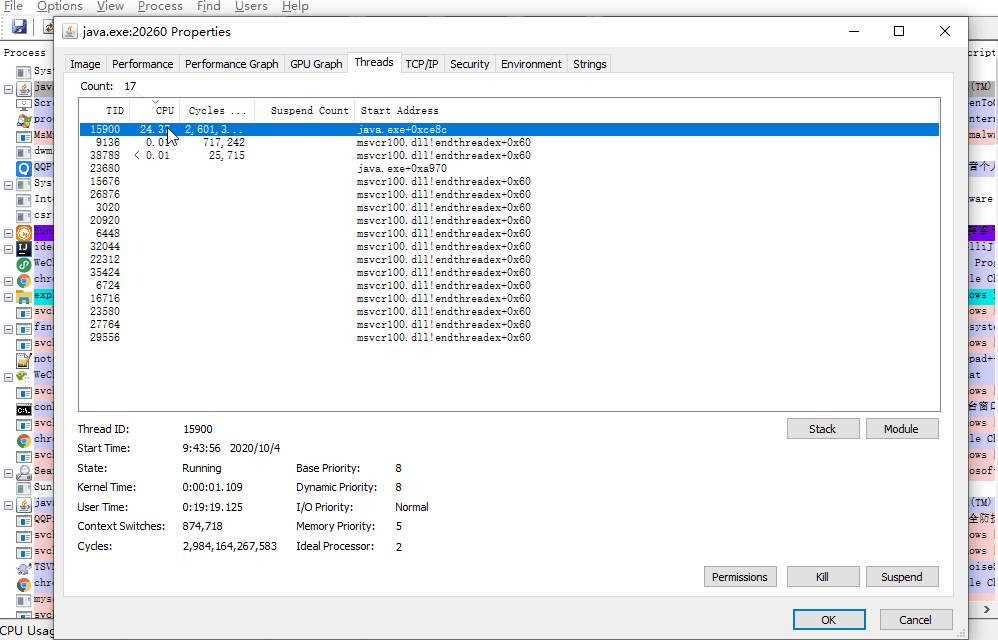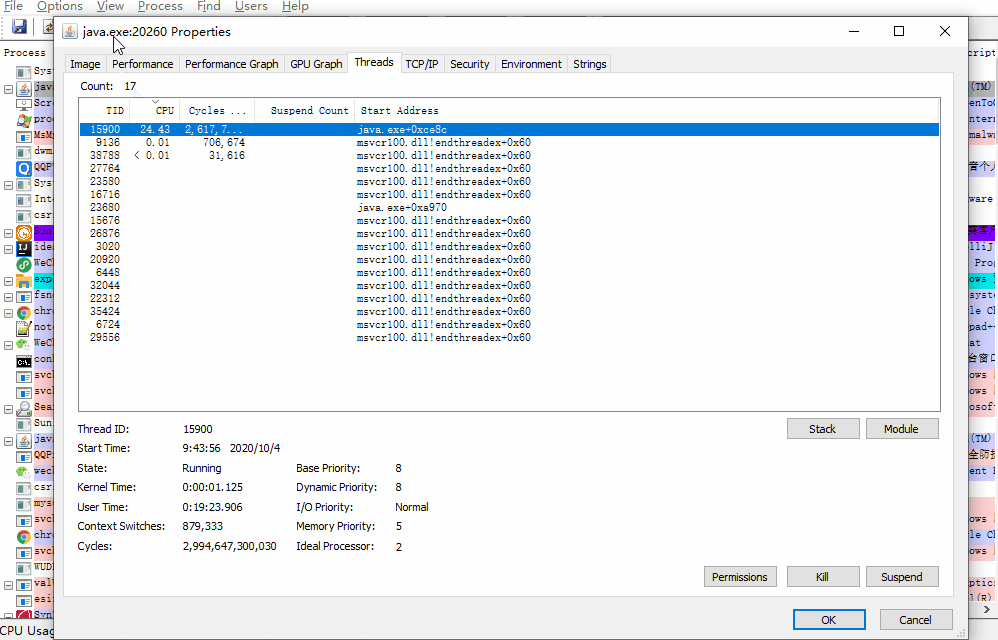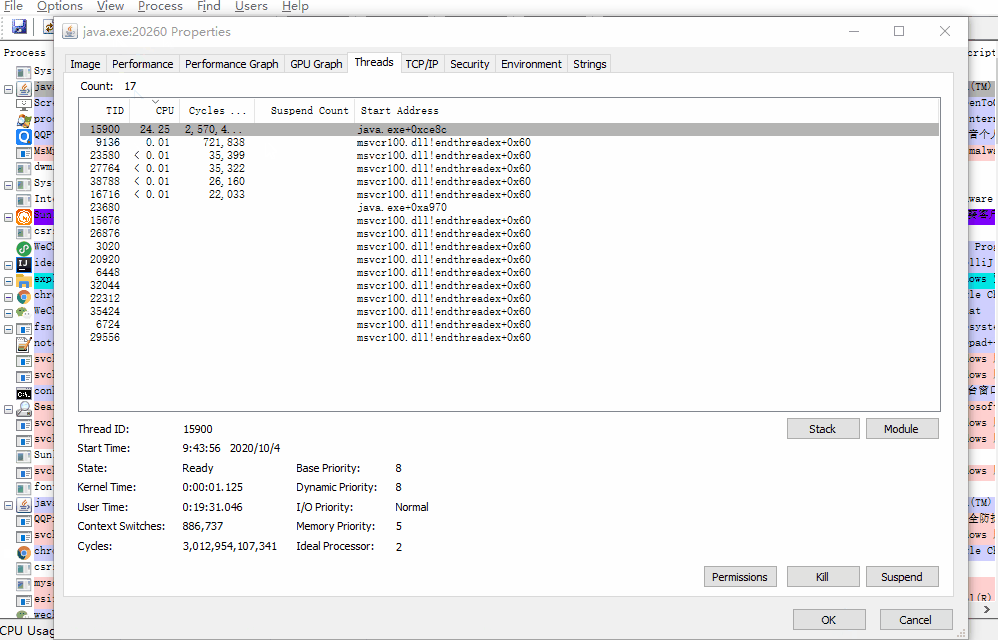
线程号: 15900 ,转成十六进制: 3e1c
3. 利用 jstack 生成虚拟机中所有线程的快照。
命令: jstack -l {pid} > {path}

文件路径: D:\20260.stack
4. 线程快照分析
我们先浏览下快照内容

内容还算比较简洁,线程快照格式都是统一的,我们以一个线程快照简单说明下:
"main" #1 prio=5 os_prio=0 tid=0x0000000002792800 nid=0x3e1c runnable [0x00000000025cf000]
我们前面找到占 cpu 最高的线程号: 15900 ,十六进制: 3e1c ,用 3e1c 去快照文件里面搜一下:

自此,找到问题:

② Linux
排查方式与 Windows 版一样,只是命令有些区别。
1. 找到 cpu 占有率最高的 java 进程号
使用命令: top -c 显示运行中的进程列表信息, shift + p 使列表按 cpu 使用率排序显示:
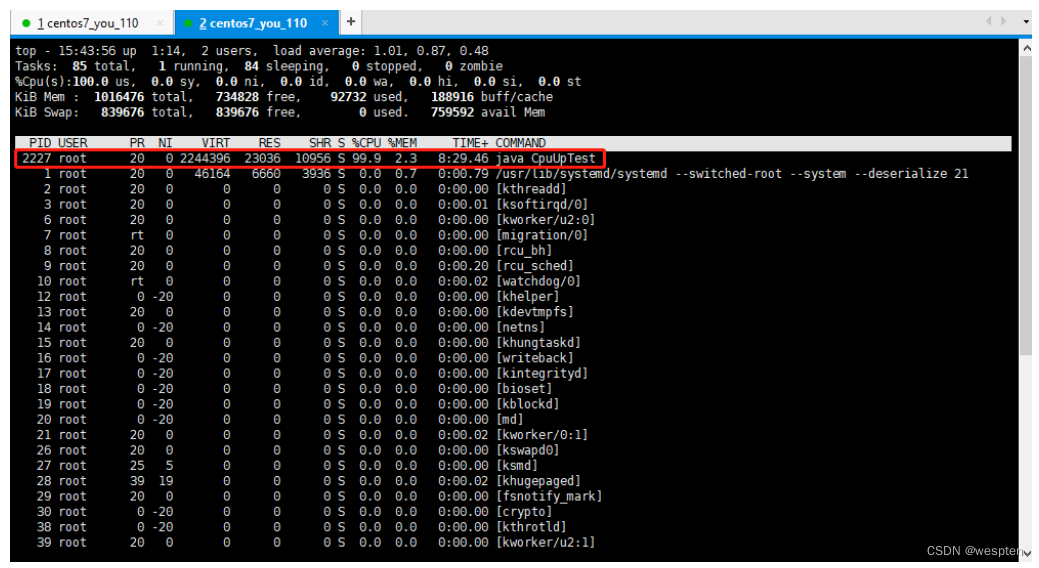
PID = 2227 的进程,cpu 使用率最高。
2. 根据进程号找到 cpu 占有率最高的线程号
使用命令: top -Hp {pid} ,同样 shift + p 可按 cpu 使用率对线程列表进行排序:

PID = 2228 的线程消耗 cpu 最高,十进制的 2228 转成十六进制 8b4
3. 利用 jstack 生成虚拟机中所有线程的快照

4. 线程快照分析
分析方式与 Windows 版一致,我们可以把 2227.stack 下载到本地进行分析,也可直接在 Linux 上分析。
在 Linux 上分析,命令:
cat 2227.stack |grep '8b4' -C 5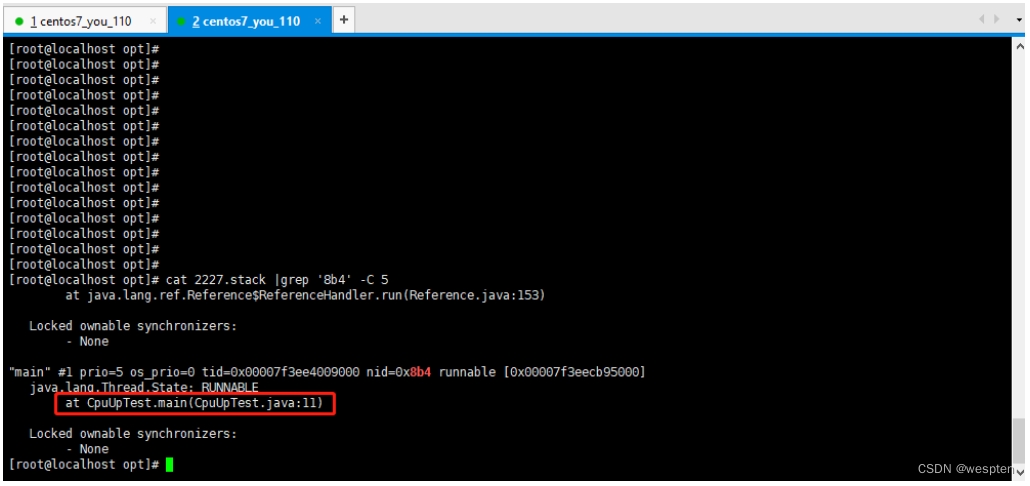
至此定位到问题:
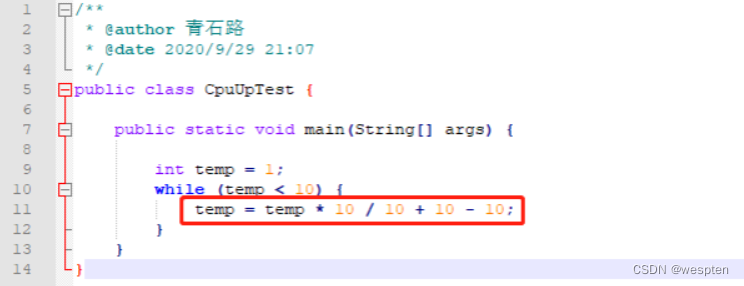
不管是在 Windows 下,还是在 Linux 下,排查套路都是一样的:

2、内存泄露
同样的,Windows、Linux 各展示一个示例。
① Windows
1. 找到内存占有率最高的进程号 PID

第一眼看上去, idea 内存占有率最高,因为我是以 idea 启动的 java 进程;idea 进程我们无需关注,我们找到内存占有率最高的 java 的 PID: 10824
2. 利用 jmap 生成堆转储快照
命令:
jmap -dump:format=b,file={path} {pid}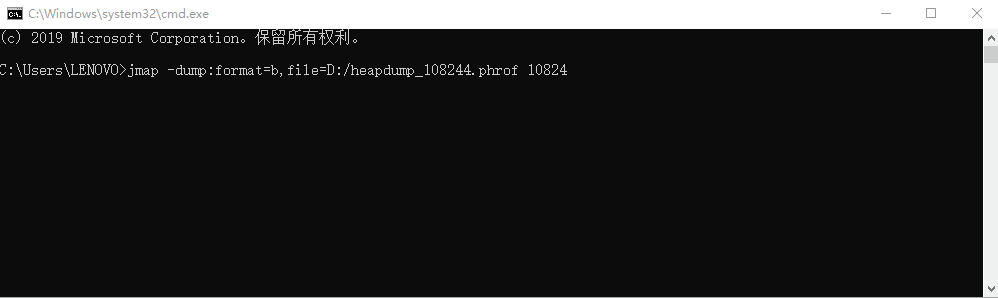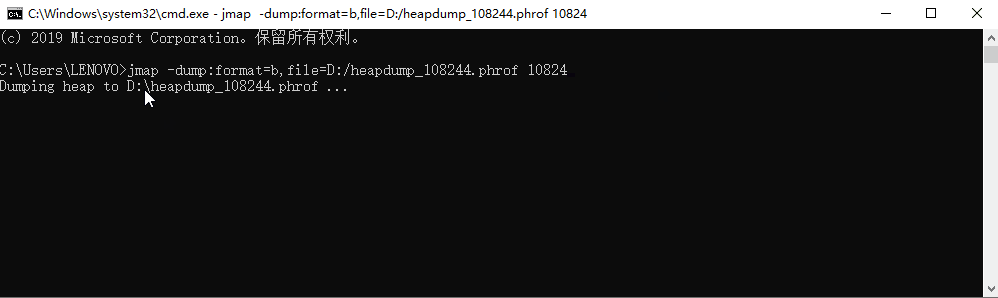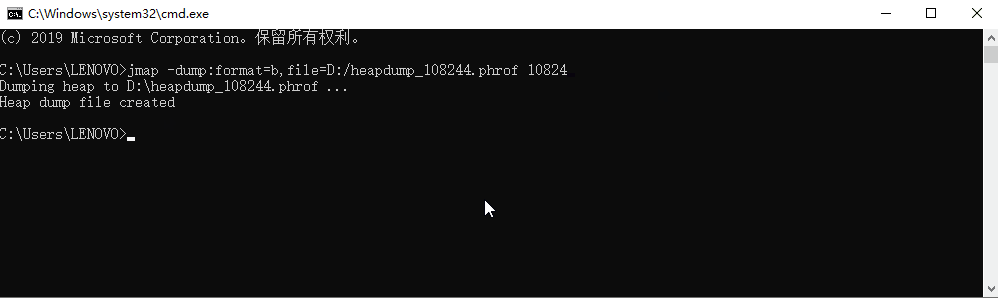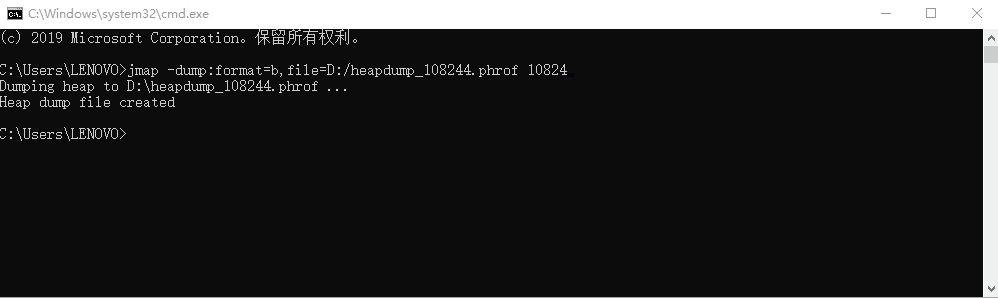
dump 文件路径: D:\heapdump_108244.hprof
3. 利用 MAT 分析 dump 文件
MAT:Memory Analyzer Tool,是针对 java 的内存分析工具。

选择对应的版本,下载后直接解压;默认情况下,mat 最大内存是 1024m ,而我们的 dump 文件往往大于 1024m,所以我们需要调整,在 mat 的 home 目录下找到 MemoryAnalyzer.ini ,将 -Xmx1024m 修改成大于 dump 大小的空间, 我把它改成了 -Xmx4096m。
接着我们就可以将 dump 文件导入 mat 中,开始 dump 文件的解析:

解析是个比较漫长的过程,我们需要耐心等待。

解析完成后,我们可以看到如下概况界面:

各个窗口的各个细节就不做详细介绍了,有兴趣的可自行去查阅资料;我们来看看几个图:饼状图、直方图、支配树、可疑的内存泄露报告。
饼状图:
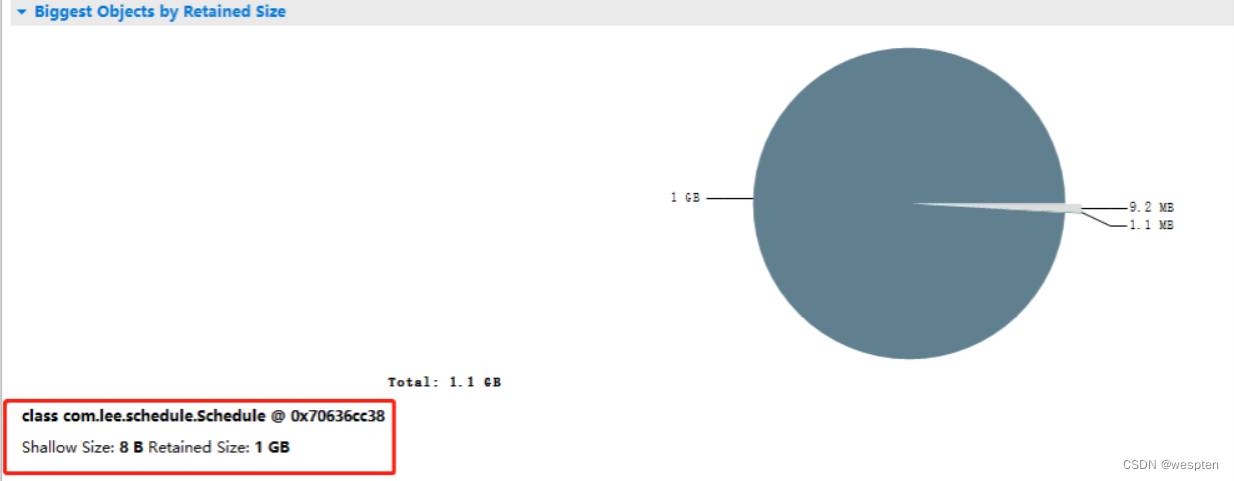
可以看出, com.lee.schedule.Schedule 对象持有 1G 内存,肯定有问题。
直方图:

我们看下 Person 定义:

可想而知,上图标记的几项都与 Person 有关。
支配树:

这就非常直观了,Schedule 中的 ArrayList 占了 99.04% 的大小
可疑的内存泄露报告:

通过这些数据,相信大家也能找到问题所在了:

② Linux
排查方式与 Windows 一样,只是有稍许的命令区别。
1. 找到内存占有率最高的进程号
使用命令: top -c 显示运行中的进程列表信息, shift + m 按内存使用率进行排序:
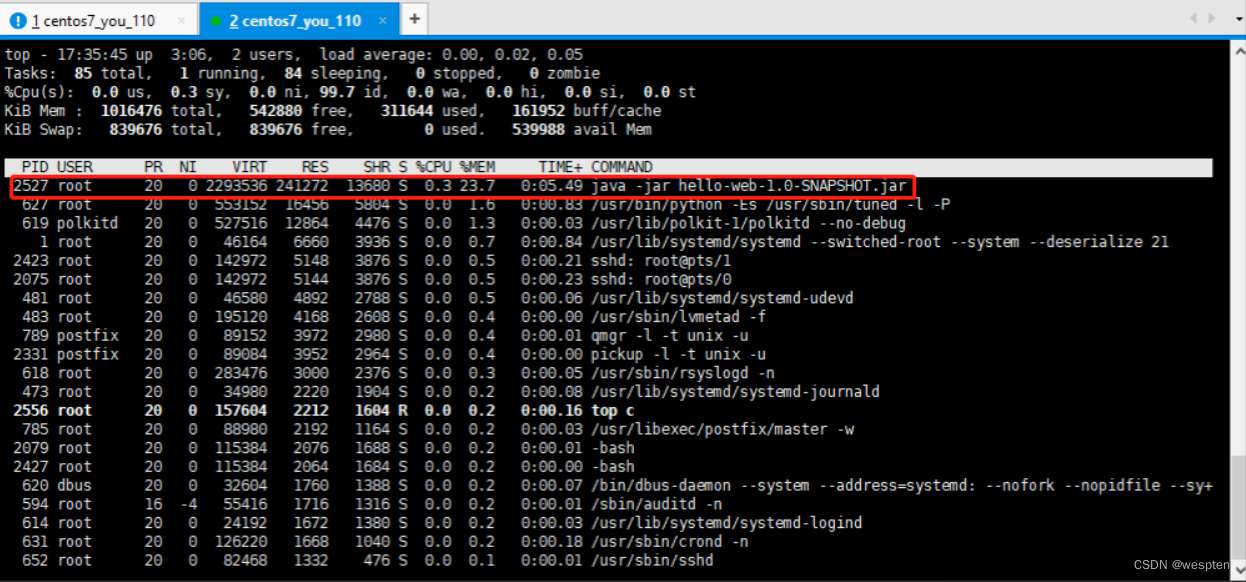
进程号: 2527
2. 利用 jmap 生成堆转储快照
命令:
jmap -dump:format=b,file={path} {pid}
堆转储快照文件路径: /opt/heapdump_2527.hprof
3. 利用 MAT 分析堆转储快照
将 heapdump_2448.phrof 下载到本地,利用 MAT 进行分析;分析过程与 Windows 版完全一致:

自此,定位到问题。
Windows下 与 Linux 下,排查流程是一样的:

3、IO 过高
工具准备:
iotop: Iotop's homepage
pt-ioprofile: Download Percona Toolkit
排查步骤:
1. 查看磁盘使用率 df -lh。
2. 安装iostat 安装命令: yum install sysstat。
3. iostat -d -k 2 查看IO情况。
哪个磁盘的IO负载较高,接下来我们就来定位具体的负载来源:
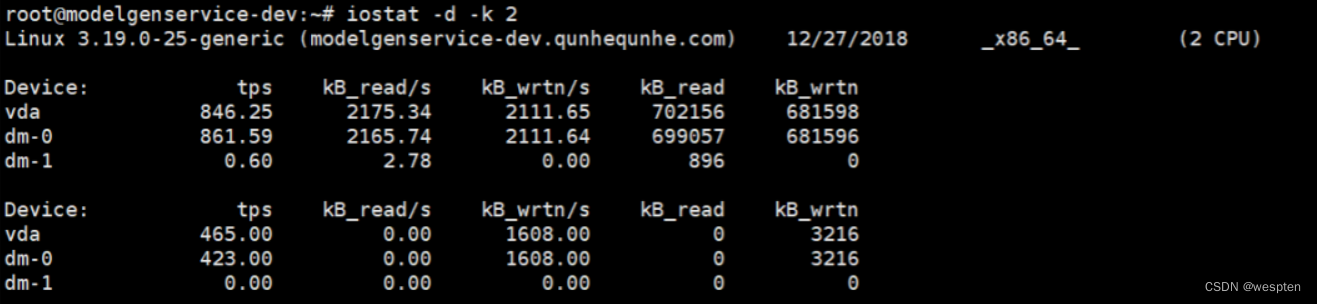
%util: 一秒中有百分之多少的时间用于 I/O 操作,或者说一秒中有多少时间 I/O 队列是非空的。即 delta(use)/s/1000 (因为use的单位为毫秒)
如果 %util 接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。

4. 安装iotop 命令
安装命令:yum install iotop iotop 查看哪个线程耗IO比较高、按 o 只显示有磁盘 IO 活动的进程。

5. pt-ioprofile定位负载来源文件
pt-ioprofile --profile-pid=1236 --cell=sizespt-ioprofile的原理是对某个pid附加一个strace进程进行IO分析。

对于定位问题更有用的是通过IO的吞吐量来进行定位。使用参数 --cell=sizes,该参数将结果已 B/s 的方式展示出来:
pt-ioprofile --profile-pid=1236 --cell=sizes从上图可以看出IO负载的主要来源是jetty,并且压力主要集中在读取上。
五、高并发优化案例
随着并发量越来越高,服务容器性能会急剧下降,高并发环境下如何优化性能呢?
1、限流
在电商高并发场景下,我们经常会使用一些常用方法,去应对流量高峰,比如限流、熔断、降级,今天我们聊聊限流。
什么是限流呢?限流是限制到达系统的并发请求数量,保证系统能够正常响应部分用户请求,而对于超过限制的流量,则通过拒绝服务的方式保证整体系统的可用性。
根据限流作用范围,可以分为单机限流和分布式限流;根据限流方式,又分为计数器、滑动窗口、漏桶和令牌桶限流,下面我们对这块详细进行讲解。
1)常用限流方式
① 计数器
计数器是一种最简单限流算法,其原理就是:在一段时间间隔内,对请求进行计数,与阀值进行比较判断是否需要限流,一旦到了时间临界点,将计数器清零。
这个就像你去坐车一样,车厢规定了多少个位置,满了就不让上车了,不然就是超载了,被交警叔叔抓到了就要罚款的,如果我们的系统那就不是罚款的事情了,可能直接崩掉了。
程序执行逻辑:
-
可以在程序中设置一个变量 count,当过来一个请求我就将这个数 +1,同时记录请求时间。
-
当下一个请求来的时候判断 count 的计数值是否超过设定的频次,以及当前请求的时间和第一次请求时间是否在 1 分钟内。
-
如果在 1 分钟内并且超过设定的频次则证明请求过多,后面的请求就拒绝掉。
-
如果该请求与第一个请求的间隔时间大于计数周期,且 count 值还在限流范围内,就重置 count。
那么问题来了,如果有个需求对于某个接口 /query 每分钟最多允许访问 200 次,假设有个用户在第 59 秒的最后几毫秒瞬间发送 200 个请求,当 59 秒结束后 Counter 清零了,他在下一秒的时候又发送 200 个请求。
那么在 1 秒钟内这个用户发送了 2 倍的请求,这个是符合我们的设计逻辑的,这也是计数器方法的设计缺陷,系统可能会承受恶意用户的大量请求,甚至击穿系统。这种方法虽然简单,但也有个大问题就是没有很好的处理单位时间的边界。

不过说实话,这个计数引用了锁,在高并发场景,这个方式可能不太实用,我建议将锁去掉,然后将 l.count++ 的逻辑通过原子计数处理,这样就可以保证 l.count 自增时不会被多个线程同时执行,即通过原子计数的方式实现限流。
② 滑动窗口
滑动窗口是针对计数器存在的临界点缺陷,所谓滑动窗口(Sliding window)是一种流量控制技术,这个词出现在 TCP 协议中。滑动窗口把固定时间片进行划分,并且随着时间的流逝,进行移动,固定数量的可以移动的格子,进行计数并判断阀值。
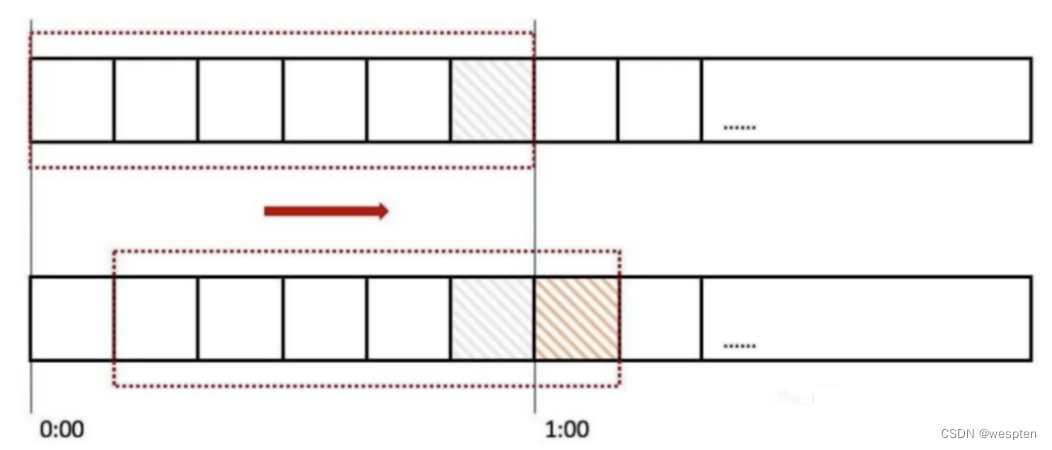
上图中我们用红色的虚线代表一个时间窗口(一分钟),每个时间窗口有 6 个格子,每个格子是 10 秒钟。每过 10 秒钟时间窗口向右移动一格,可以看红色箭头的方向。我们为每个格子都设置一个独立的计数器 Counter,假如一个请求在 0:45 访问了那么我们将第五个格子的计数器 +1(也是就是 0:40~0:50),在判断限流的时候需要把所有格子的计数加起来和设定的频次进行比较即可。
那么滑动窗口如何解决我们上面遇到的问题呢?来看下面的图:
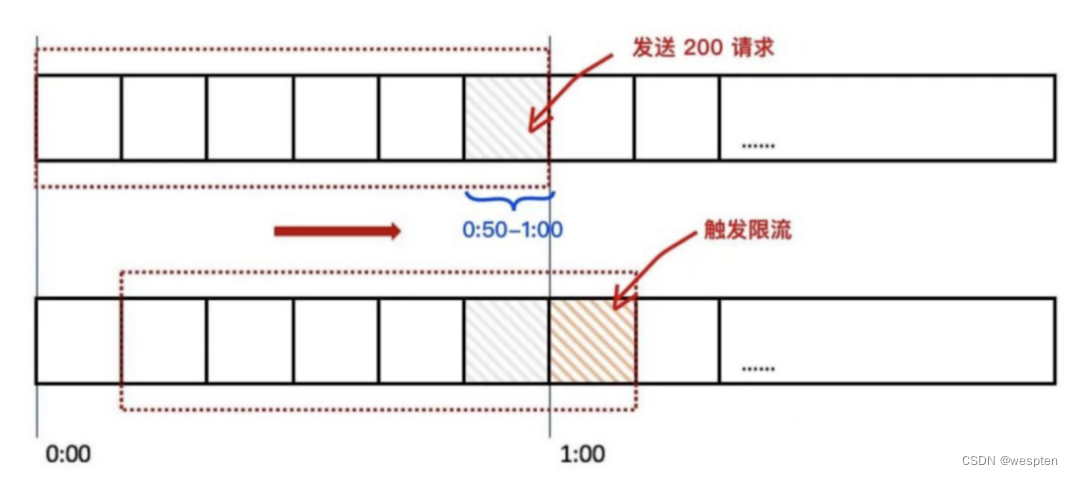
当用户在 0:59 秒钟发送了 200 个请求就会被第六个格子的计数器记录 +200,当下一秒的时候时间窗口向右移动了一个,此时计数器已经记录了该用户发送的 200 个请求,所以再发送的话就会触发限流,则拒绝新的请求。
其实计数器就是滑动窗口啊,只不过只有一个格子而已,所以想让限流做的更精确只需要划分更多的格子就可以了,为了更精确我们也不知道到底该设置多少个格子,格子的数量影响着滑动窗口算法的精度,依然有时间片的概念,无法根本解决临界点问题。
③ 漏桶
漏桶算法(Leaky Bucket),原理就是一个固定容量的漏桶,按照固定速率流出水滴。
用过水龙头都知道,打开龙头开关水就会流下滴到水桶里,而漏桶指的是水桶下面有个漏洞可以出水,如果水龙头开的特别大那么水流速就会过大,这样就可能导致水桶的水满了然后溢出。

一个固定容量的桶,有水流进来,也有水流出去。对于流进来的水来说,我们无法预计一共有多少水会流进来,也无法预计水流的速度。但是对于流出去的水来说,这个桶可以固定水流出的速率(处理速度),从而达到流量整形和流量控制的效果。
漏桶算法有以下特点:
-
漏桶具有固定容量,出水速率是固定常量(流出请求)
-
如果桶是空的,则不需流出水滴
-
可以以任意速率流入水滴到漏桶(流入请求)
-
如果流入水滴超出了桶的容量,则流入的水滴溢出(新请求被拒绝)
漏桶限制的是常量流出速率(即流出速率是一个固定常量值),所以最大的速率就是出水的速率,不能出现突发流量。
④ 令牌桶
令牌桶算法(Token Bucket)是网络流量整形(Traffic Shaping)和速率限制(Rate Limiting)中最常使用的一种算法。典型情况下,令牌桶算法用来控制发送到网络上的数据的数目,并允许突发数据的发送。

我们有一个固定的桶,桶里存放着令牌(token)。一开始桶是空的,系统按固定的时间(rate)往桶里添加令牌,直到桶里的令牌数满,多余的请求会被丢弃。当请求来的时候,从桶里移除一个令牌,如果桶是空的则拒绝请求或者阻塞。
令牌桶有以下特点:
-
令牌按固定的速率被放入令牌桶中
-
桶中最多存放 B 个令牌,当桶满时,新添加的令牌被丢弃或拒绝
-
如果桶中的令牌不足 N 个,则不会删除令牌,且请求将被限流(丢弃或阻塞等待)
令牌桶限制的是平均流入速率(允许突发请求,只要有令牌就可以处理,支持一次拿3个令牌,4个令牌...),并允许一定程度突发流量,所以也是非常常用的限流算法。
⑤ Redis + Lua 分布式限流
单机版限流仅能保护自身节点,但无法保护应用依赖的各种服务,并且在进行节点扩容、缩容时也无法准确控制整个服务的请求限制。
而分布式限流,以集群为维度,可以方便的控制这个集群的请求限制,从而保护下游依赖的各种服务资源。
分布式限流最关键的是要将限流服务做成原子化,我们可以借助 Redis 的计数器,Lua 执行的原子性,进行分布式限流,大致的 Lua 脚本代码如下:
local key = "rate.limit:" .. KEYS[1] --限流KEY
local limit = tonumber(ARGV[1]) --限流大小
local current = tonumber(redis.call('get', key) or "0")
if current + 1 > limit then --如果超出限流大小
return 0
else --请求数+1,并设置1秒过期
redis.call("INCRBY", key,"1")
redis.call("expire", key,"1")
return current + 1
end限流逻辑(Java 语言):
public static boolean accquire() throws IOException, URISyntaxException {
Jedis jedis = new Jedis("127.0.0.1");
File luaFile = new File(RedisLimitRateWithLUA.class.getResource("/").toURI().getPath() + "limit.lua");
String luaScript = FileUtils.readFileToString(luaFile);
String key = "ip:" + System.currentTimeMillis()/1000; // 当前秒
String limit = "5"; // 最大限制
List<String> keys = new ArrayList<String>();
keys.add(key);
List<String> args = new ArrayList<String>();
args.add(limit);
Long result = (Long)(jedis.eval(luaScript, keys, args)); // 执行lua脚本,传入参数
return result == 1;
}⑥ 其他方式
上面的限流方式,主要是针对服务器进行限流,我们也可以对容器进行限流,比如 Tomcat、Nginx 等限流手段。
Tomcat 可以设置最大线程数(maxThreads),当并发超过最大线程数会排队等待执行;而 Nginx 提供了两种限流手段:一是控制速率,二是控制并发连接数。
对于 Java 语言,我们其实有相关的限流组件,比如大家常用的 RateLimiter,其实就是基于令牌桶算法,大家知道为什么唯独选用令牌桶么?
对于 Go 语言,也有该语言特定的限流方式,比如可以通过 channel 实现并发控制限流,也支持第三方库 httpserver 实现限流。
在实际的限流场景中,我们也可以控制单个 IP、城市、渠道、设备 id、用户 id 等在一定时间内发送的请求数;如果是开放平台,需要为每个 appkey 设置独立的访问速率规则。
2)限流方式对比
下面我们就对常用的限流策略,总结它们的优缺点,便于以后选型。
计数器:
-
优点:固定时间段计数,实现简单,适用不太精准的场景;
-
缺点:对边界没有很好处理,导致限流不能精准控制。
滑动窗口:
-
优点:将固定时间段分块,时间比“计数器”复杂,适用于稍微精准的场景;
-
缺点:实现稍微复杂,还是不能彻底解决“计数器”存在的边界问题。
漏桶:
-
优点:可以很好的控制消费频率;
-
缺点:实现稍微复杂,单位时间内,不能多消费,感觉不太灵活。
令牌桶:
-
优点:可以解决“漏桶”不能灵活消费的问题,又能避免过渡消费,强烈推荐;
-
缺点:实现稍微复杂,其它缺点没有想到。
Redis + Lua 分布式限流:
-
优点:支持分布式限流,有效保护下游依赖的服务资源;
-
缺点:依赖 Redis,对边界没有很好处理,导致限流不能精准控制。
2、缓存穿透、击穿、雪崩
我们先看一下正常情况的查询过程:
-
先查询 Redis,如果查询成功,直接返回,查询不存在,去查询 DB;
-
如果 DB 查询成功,数据回写 Redis,查询不存在,直接返回。

1)缓存穿透
定义:当查询数据库和缓存都无数据时,因为数据库查询无数据,出于容错考虑,不会将结果保存到缓存中,因此每次请求都会去查询数据库,这种情况就叫做缓存穿透。

红色的线条,就是缓存穿透的场景,当查询的 Key 在缓存和 DB 中都不存在时,就会出现这种情况。
可以想象一下,比如有个接口需要查询商品信息,如果有恶意用户模拟不存在的商品 ID 发起请求,瞬间并发量很高,估计你的 DB 会直接挂掉。
可能大家第一反应就是对入参进行正则校验,过滤掉无效请求,对!这个没错,那有没有其它更好的方案呢?
① 缓存空值
当我们从数据库中查询到空值时,我们可以向缓存中回种一个空值,为了避免缓存被长时间占用,需要给这个空值加一个比较短的过期时间,例如 3~5 分钟。
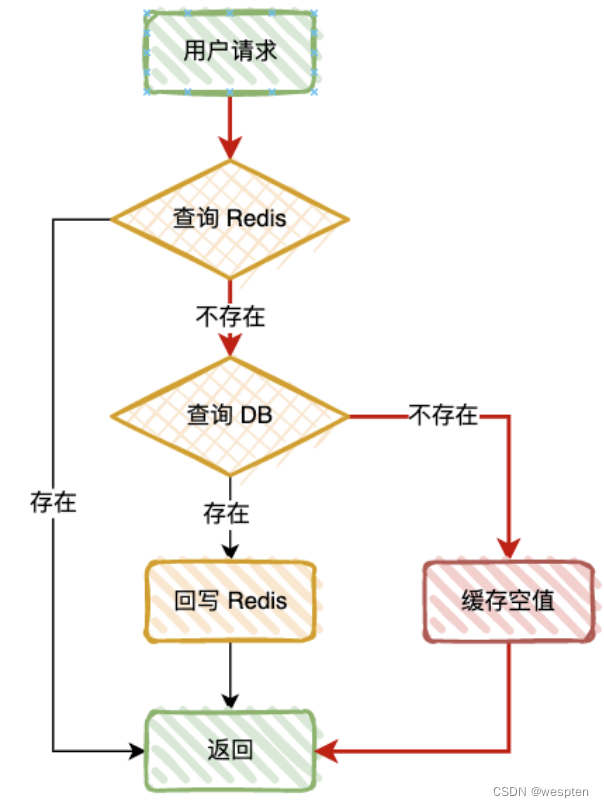
不过这个方案有个问题,当大量无效请求穿透过来时,缓存内就会有有大量的空值缓存,如果缓存空间被占满了,还会因剔除掉一些已经被缓存的用户信息,反而会造成缓存命中率的下降,所以这个方案,需要评估缓存容量。
如果缓存空值不可取,这时你可以考虑使用布隆过滤器。
② 布隆过滤器
布隆过滤器是由一个可变长度为 N 的二进制数组与一组数量可变 M 的哈希函数构成,说的简单粗暴一点,就是一个 Hash Map。
原理相当简单:比如元素 key=#3,假如通过 Hash 算法得到一个为 9 的值,就存在这个 Hash Map 的第 9 位元素中,通过标记 1 标识该位已经有数据,如下图所示,0 是无数据,1 是有数据。
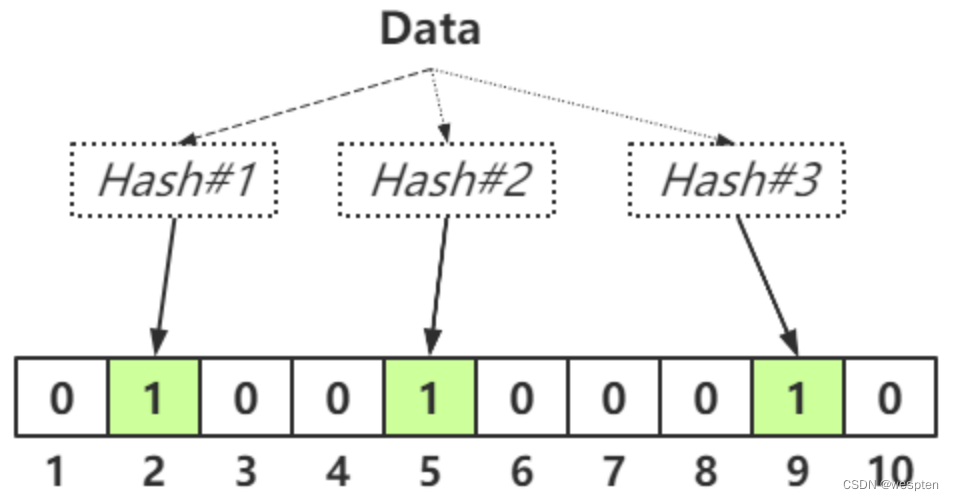
所以通过该方法,会得到一个结论:在 Hash Map 中,标记的数据,不一定存在,但是没有标记的数据,肯定不存在。
为什么“标记的数据,不一定存在”呢?因为 Hash 冲突!
比如 Hash Map 的长度为 100,但是你有 101 个请求,假如你运气好到爆,这 100 个请求刚好均匀打在长度为 100 的 Hash Map 中,此时你的 Hash Map 已经全部标记为 1。
当第 101 个请求过来时,就 100% 出现 Hash 冲突,虽然我没有请求过,但是得到的标记却为 1,导致布隆过滤器没有拦截。
如果需要减少误判,可以增加 Hash Map 的长度,并选择却分度更高的 Hash 函数,比如多次对 key 进行 hash。
除了 Hash 冲突,布隆过滤器其实会带来一个致命的问题:布隆过滤器更新失败。
比如有一个商品 ID 第一次请求,当 DB 中存在时,需要在 Hash Map 中标记一下,但是由于网络原因,导致标记失败,那么下次这个商品 ID 重新发起请求时,请求会被布隆过滤器拦截,比如这个是双11的爆款商品库存,明明有 10W 件商品,你却提示库存不存在,领导可能会说“明天你可以不用来了”。
所以如果使用布隆过滤器,在对 Hash Map 进行数据更新时,需要保证这个数据能 100% 更新成功,可以通过异步、重试的方式,所以这个方案有一定的实现成本和风险。
2)缓存击穿
定义:某个热点缓存在某一时刻恰好失效,然后此时刚好有大量的并发请求,此时这些请求将会给数据库造成巨大的压力,这种情况就叫做缓存击穿。
这个其实和“缓存穿透”流程图一样,只是这个的出发点是“某个热点缓存在某一时刻恰好失效”,比如某个非常热门的爆款商品,缓存突然失效,流量直接全部打到 DB,造成某一时刻数据库请求量过大,更强调瞬时性。
解决问题的方法主要有 2 种:
-
分布式锁:只有拿到锁的第一个线程去请求数据库,然后插入缓存,当然每次拿到锁的时候都要去查询一下缓存有没有,这种在高并发场景下,个人不太建议用分布式锁,会影响查询效率;
-
设置永不过期:对于某些热点缓存,我们可以设置永不过期,这样就能保证缓存的稳定性,但需要注意在数据更改之后,要及时更新此热点缓存,不然就会造成查询结果的误差,比如热门商品,都先预热到数据库,后续再下线掉。
网上还有“缓存续期”的方式,比如缓存 30 分钟失效,可以搞个定时任务,每 20 分钟跑一次,感觉这种方式不伦不类,仅供大家参考。
3)缓存雪崩
定义:在短时间内有大量缓存同时过期,导致大量的请求直接查询数据库,从而对数据库造成了巨大的压力,严重情况下可能会导致数据库宕机的情况叫做缓存雪崩。
如果说“缓存击穿”是单兵反抗,那“缓存雪崩”就是集体起义了,那什么情况会出现缓存雪崩呢?
-
短时间内有大量缓存同时过期;
-
缓存服务宕机,导致某一时刻发生大规模的缓存失效。
那么有哪些解决方案呢?
-
缓存添加随机时间:可在设置缓存时添加随机时间,比如 0~60s,这样就可以极大的避免大量的缓存同时失效;
-
分布式锁:加一个分布式锁,第一个请求将数据持久化到缓存后,其它的请求才能进入;
-
限流和降级:通过限流和降级策略,减少请求的流量;
-
集群部署:Redis 通过集群部署、主从策略,主节点宕机后,会切换到从节点,保证服务的可用性。
缓存添加随机时间示例:
// 缓存原本的失效时间
int exTime = 10 * 60;
// 随机数生成类
Random random = new Random();
// 缓存设置
jedis.setex(cacheKey, exTime + random.nextInt(1000) , value);3、Redis 高可用
1)Redis 分片策略
1. Hash 分片
我们都知道,对于 Reids 集群,我们需要通过 hash 策略,将 key 打在 Redis 的不同分片上。
假如我们有 3 台机器,常见的分片方式为 hash(IP)%3,其中 3 是机器总数。

目前很多小公司都这么玩,上手快,简单粗暴,但是这种方式有一个致命的缺点:当增加或者减少缓存节点时,总节点个数发生变化,导致分片值发生改变,需要对缓存数据做迁移。
那如何解决该问题呢,答案是一致性 Hash。
2. 一致性 Hash
一致性哈希算法是 1997 年由麻省理工学院提出的一种分布式哈希实现算法。
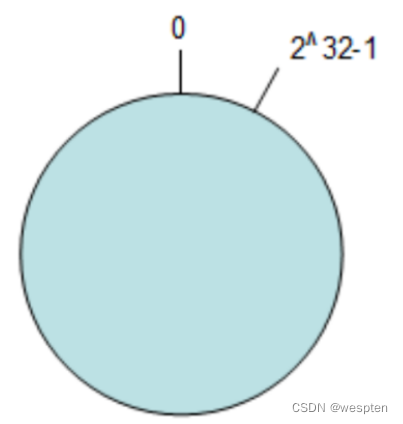
环形空间:按照常用的 hash 算法来将对应的 key 哈希到一个具有 2^32 次方个桶的空间中,即 0~(2^32)-1 的数字空间中,现在我们可以将这些数字头尾相连,想象成一个闭合的环形。
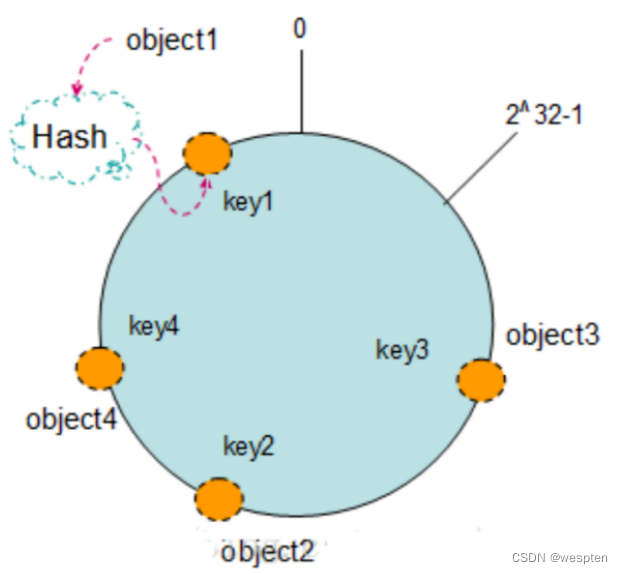
Key 散列 Hash 环:现在我们将 object1、object2、object3、object4 四个对象通过特定的 Hash 函数计算出对应的 key 值,然后散列到 Hash 环上。
机器散列 Hash 环:假设现在有 NODE1、NODE2、NODE3 三台机器,以顺时针的方向计算,将所有对象存储到离自己最近的机器中,object1 存储到了 NODE1,object3 存储到了 NODE2,object2、object4 存储到了 NODE3。

节点删除:如果 NODE2 出现故障被删除了,object3 将会被迁移到 NODE3 中,这样仅仅是 object3 的映射位置发生了变化,其它的对象没有任何的改动。

添加节点:如果往集群中添加一个新的节点 NODE4,object2 被迁移到了 NODE4 中,其它对象保持不变。
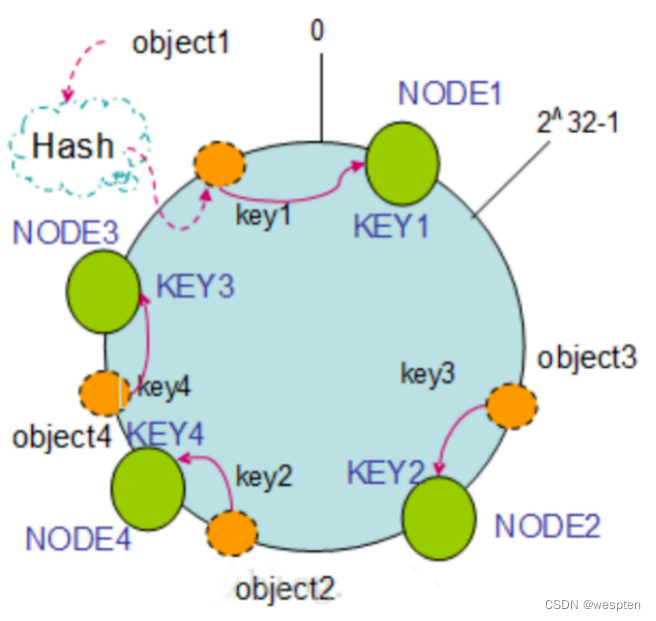
通过对节点的添加和删除的分析,一致性哈希算法在保持了单调性的同时,还使数据的迁移达到了最小,这样的算法对分布式集群来说是非常合适的,避免了大量数据迁移,减小了服务器的的压力。
如果机器个数太少,为了避免大量数据集中在几台机器,实现平衡性,可以建立虚拟节点(比如一台机器建立 3-4 个虚拟节点),然后对虚拟节点进行 Hash。
2)高可用方案
很多时候,公司只给我们提供一套 Redis 集群,至于如何计算分片,我们一般有 2 套成熟的解决方案。
客户端方案:也就是客户端自己计算 Redis 分片,无论你使用Hash 分片,还是一致性 Hash,都是由客户端自己完成。
客户端方案简单粗暴,但是只能在单一语言系统之间复用,如果你使用的是 PHP 的系统,后来 Java 也需要使用,你需要用 Java 重新写一套分片逻辑。
为了解决多语言、不同平台复用的问题,就衍生出中间代理层方案。
中间代理层方案:将客户端解决方案的经验移植到代理层中,通过通用的协议(如 Redis 协议)来实现在其他语言中的复用,用户无需关心缓存的高可用如何实现,只需要依赖你的代理层即可。
代理层主要负责读写请求的路由功能,并且在其中内置了一些高可用的逻辑。

你可以看看,你们公司的 Redis 使用的是哪种方案呢?对于“客户端方案”,其实有的也不用自己去写,比如负责维护 Redis 的部门会提供不同语言的 SDK,你只需要去集成对应的 SDK 即可。
3)高可用原理
1. Redis 主从
Redis 基本都通过“主 - 从”模式进行部署,主从库之间采用的是读写分离的方式。

同 MySQL 类似,主库支持写和读,从库只支持读,数据会先写到主库,然后定时同步给从库,具体的同步规则,主要将 RDB 日志从主库同步给从库,然后从库读取 RDB 日志,这里比较复杂,其中还涉及到 replication buffer,就不再展开。
这里有个问题,一次同步过程中,主库需要完成 2 个耗时操作:生成 RDB 文件和传输 RDB 文件。
如果从库数量过多,主库忙于 fock 子进程生成 RDB 文件和数据同步,会阻塞主库正常请求。
这个如何解决呢?答案是 “主 - 从 - 从” 模式。
为了避免所有从库都从主库同步 RDB 日志,可以借助从库来完成同步:比如新增 3、4 两个 Slave,可以等 Slave 2 同步完后,再通过 Slave 2 同步给 Slave 3 和 Slave 4。
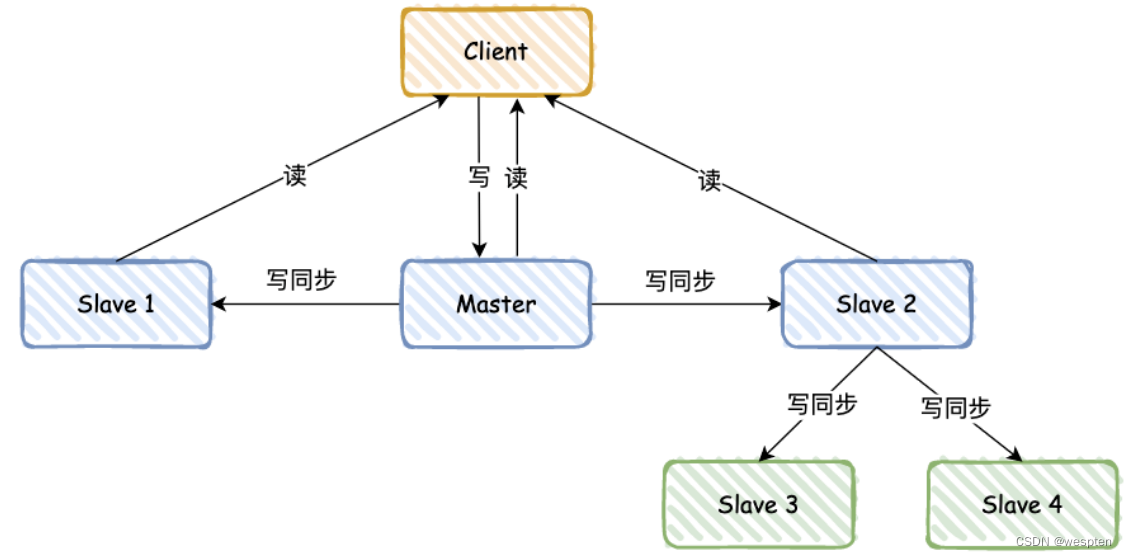
如果我是面试官,我可能会继续问,如果数据同步了 80%,网络突然终端,当网络后续又恢复后,Redis 会如何操作呢?
2. Redis 分片
这个有点像 MySQL 分库分表,将数据存储到不同的地方,避免查询时全部集中到一个实例。
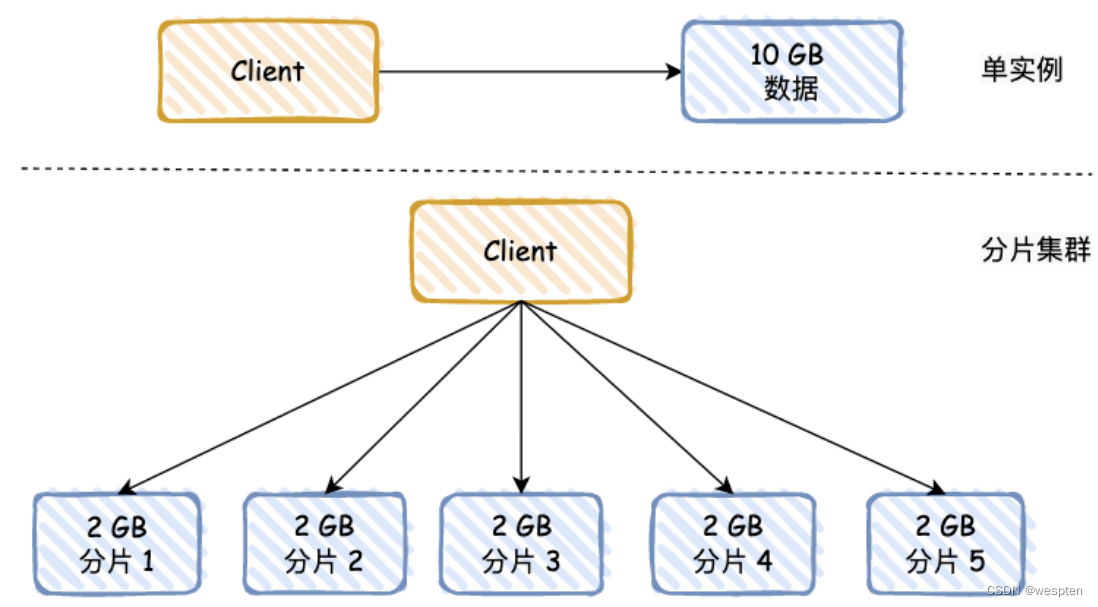
其实还有一个好处,就是数据进行主从同步时,如果 RDB 数据过大,会严重阻塞主线程,如果用分片的方式,可以将数据分摊,比如原来有 10 GB 的数据,分摊后,每个分片只有 2 GB。
可能有同学会问,Redis 分片,和“主 - 从”模式有啥关系呢?你可以理解,图中的每个分片都是主库,每个分片都有自己的“主 - 从”模式结构。
那么数据如何找到对应的分片呢,前面其实已经讲过,假如我们有 3 台机器,常见的分片方式为 hash(IP)%3,其中 3 是机器总数,hash 值为机器 IP,这样每台机器就有自己的分片号。
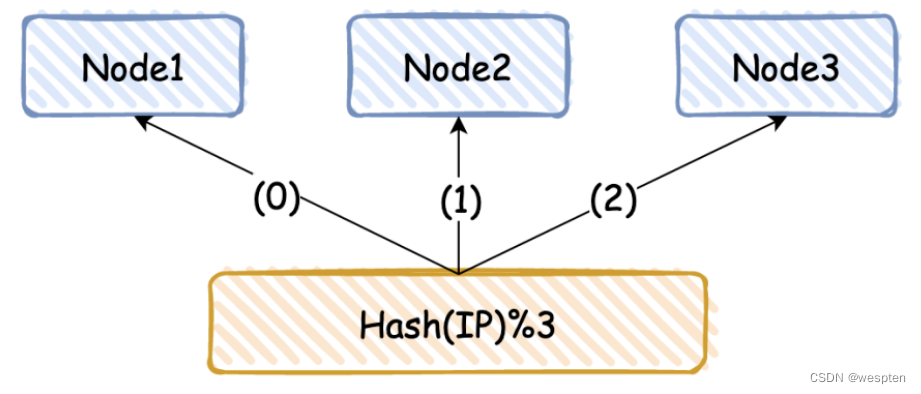
对于 key,也可以采用同样的方式,找到对应的机器分片号 hash(key)%3,hash 算法有很多,可以用 CRC16(key),也可以直接取 key 中的字符,通过 ASCII 码转换成数字。
3. Redis 哨兵机制
① 什么是哨兵机制
在主从模式下,如果 master 宕机了,从库不能从主库同步数据,主库也不能提供读写功能。

怎么办呢 ?这时就需要引入哨兵机制 !
哨兵节点是特殊的 Redis 服务,不提供读写服务,主要用来监控 Redis 实例节点。

那么当 master 宕机,哨兵如何执行呢?
② 判断主机下线
哨兵进程会使用 PING 命令检测它自己和主、从库的网络连接情况,用来判断实例的状态,如果哨兵发现主库或从库对 PING 命令的响应超时了,哨兵就会先把它标记为“主观下线”。
那是否一个哨兵判断为“主观下线”,就直接下线 master 呢?
答案肯定是不行的,需要遵循 “少数服从多数” 原则:有 N/2+1 个实例判断主库“主观下线”,才判定主库为“客观下线”。
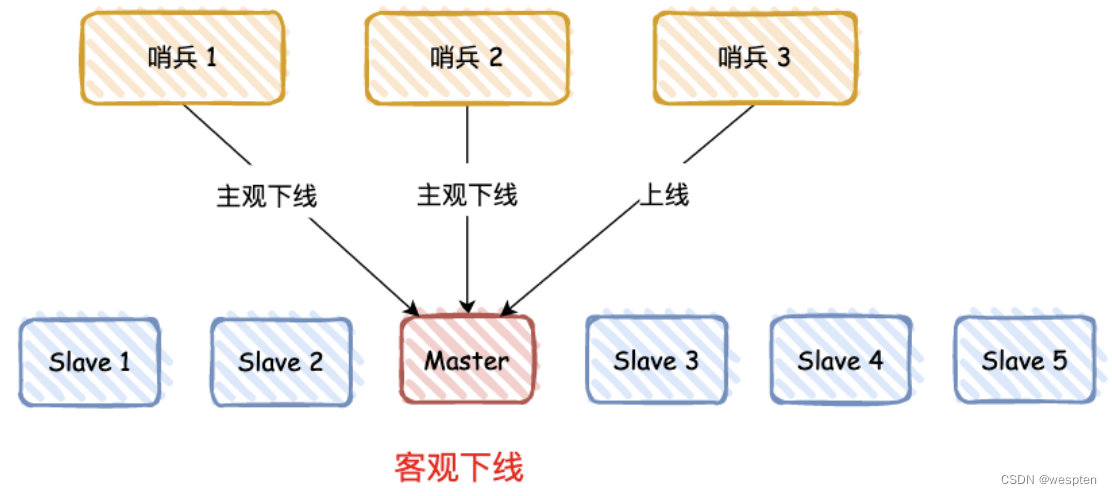
比如上图有 3 个哨兵,有 2 个判断 “主观下线”,那么就标记主库为 “客观下线”。
③ 选取新主库
我们有 5 个从库,需要选取一个最优的从库作为主库,分 2 步:
-
筛选:检查从库的当前在线状态和之前的网络连接状态,过滤不适合的从库;
-
打分:根据从库优先级、和旧主库的数据同步接近度进行打分,选最高分作为主库。

如果分数一致怎么办 ? Redis 也有一个策略:ID 号最小的从库得分最高,会被选为新主库。
当 slave 3 选举为新主库后,会通知其它从库和客户端,对外宣布自己是新主库,大家都得听我的哈!
4、分库分表
1)什么是分库分表
分库:就是一个数据库分成多个数据库,部署到不同机器。

分表:就是一个数据库表分成多个表。
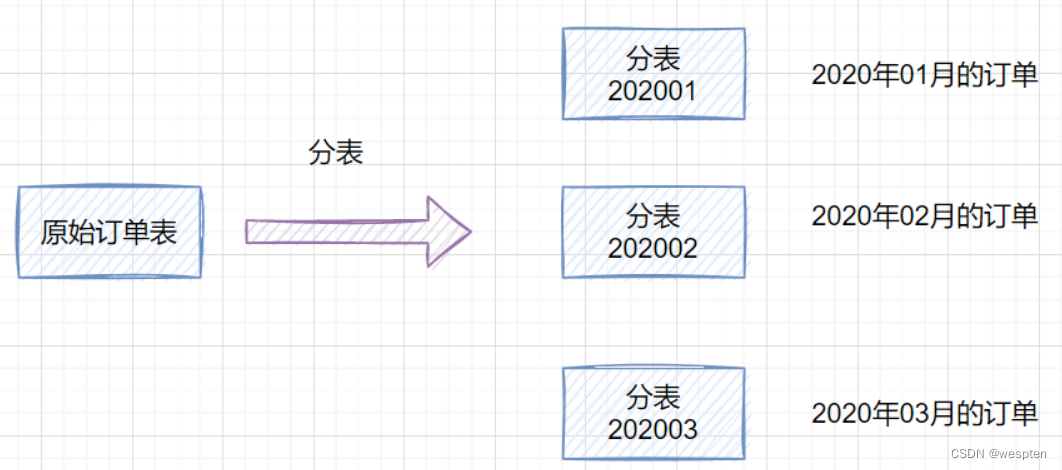
2)为什么需要分库分表
1. 什么需要分库
如果业务量剧增,数据库可能会出现性能瓶颈,这时候我们就需要考虑拆分数据库。从这几方面来看:
-
磁盘存储
业务量剧增,MySQL单机磁盘容量会撑爆,拆成多个数据库,磁盘使用率大大降低。
-
并发连接支撑
我们知道数据库连接是有限的。在高并发的场景下,大量请求访问数据库,MySQL单机是扛不住的!当前非常火的微服务架构出现,就是为了应对高并发。它把订单、用户、商品等不同模块,拆分成多个应用,并且把单个数据库也拆分成多个不同功能模块的数据库(订单库、用户库、商品库),以分担读写压力。
2. 为什么需要分表
数据量太大的话,SQL的查询就会变慢。如果一个查询SQL没命中索引,千百万数据量级别的表可能会拖垮整个数据库。
即使SQL命中了索引,如果表的数据量超过一千万的话,查询也是会明显变慢的。这是因为索引一般是B+树结构,数据千万级别的话,B+树的高度会增高,查询就变慢啦。
小伙伴们是否还记得,MySQL的B+树的高度怎么计算的呢? 顺便复习一下吧
InnoDB存储引擎最小储存单元是页,一页大小就是16k。B+树叶子存的是数据,内部节点存的是键值+指针。索引组织表通过非叶子节点的二分查找法以及指针确定数据在哪个页中,进而再去数据页中找到需要的数据,B+树结构图如下:
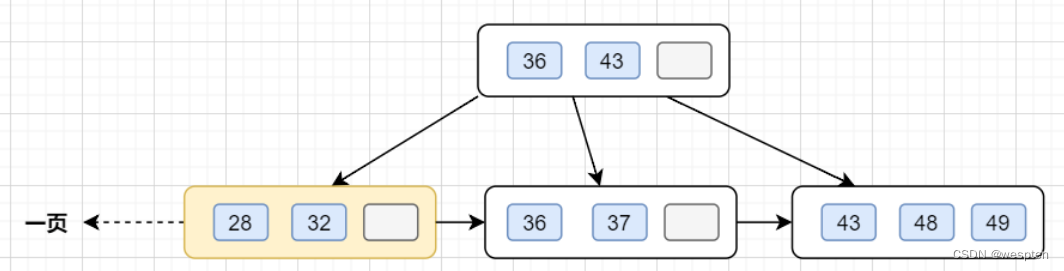
假设B+树的高度为2的话,即有一个根结点和若干个叶子结点。这棵B+树的存放总记录数为=根结点指针数*单个叶子节点记录行数。
-
如果一行记录的数据大小为1k,那么单个叶子节点可以存的记录数
=16k/1k =16. -
非叶子节点内存放多少指针呢?我们假设主键ID为bigint类型,长度为8字节(面试官问你int类型,一个int就是32位,4字节),而指针大小在InnoDB源码中设置为6字节,所以就是
8+6=14字节,16k/14B =16*1024B/14B = 1170
因此,一棵高度为2的B+树,能存放1170 * 16=18720条这样的数据记录。同理一棵高度为3的B+树,能存放1170 *1170 *16 =21902400,大概可以存放两千万左右的记录。B+树高度一般为1-3层,如果B+到了4层,查询的时候会多查磁盘的次数,SQL就会变慢。
因此单表数据量太大,SQL查询会变慢,所以就需要考虑分表啦。
3)如何分库分表
1. 垂直拆分
① 垂直分库
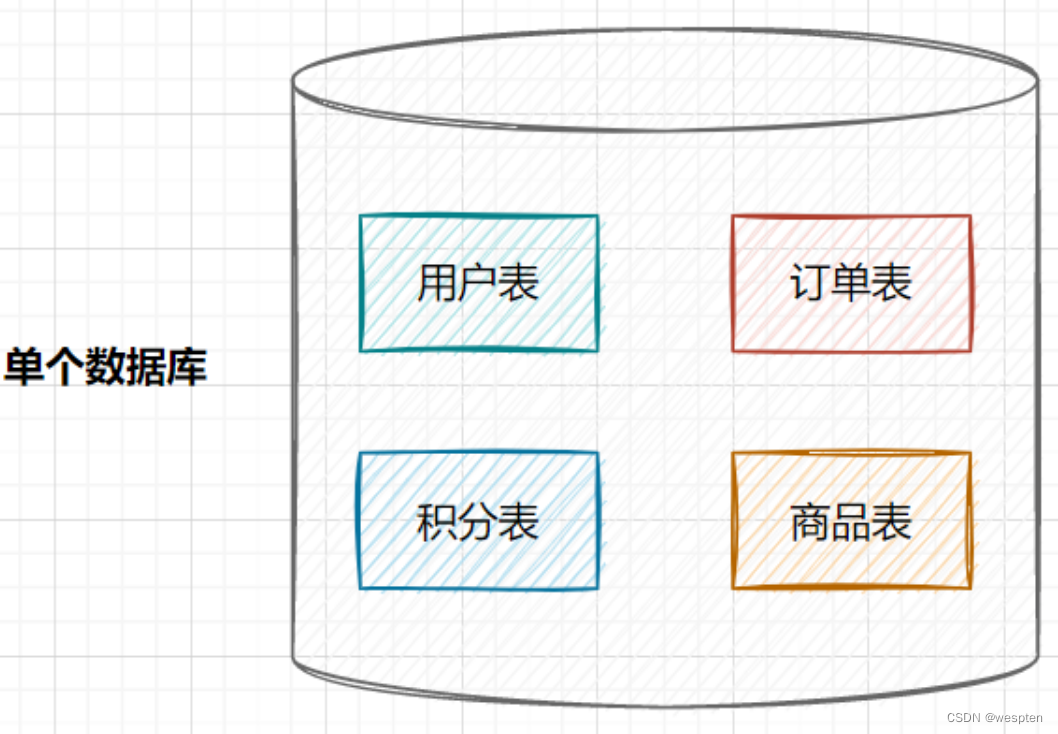
在业务发展初期,业务功能模块比较少,为了快速上线和迭代,往往采用单个数据库来保存数据。数据库架构如下:
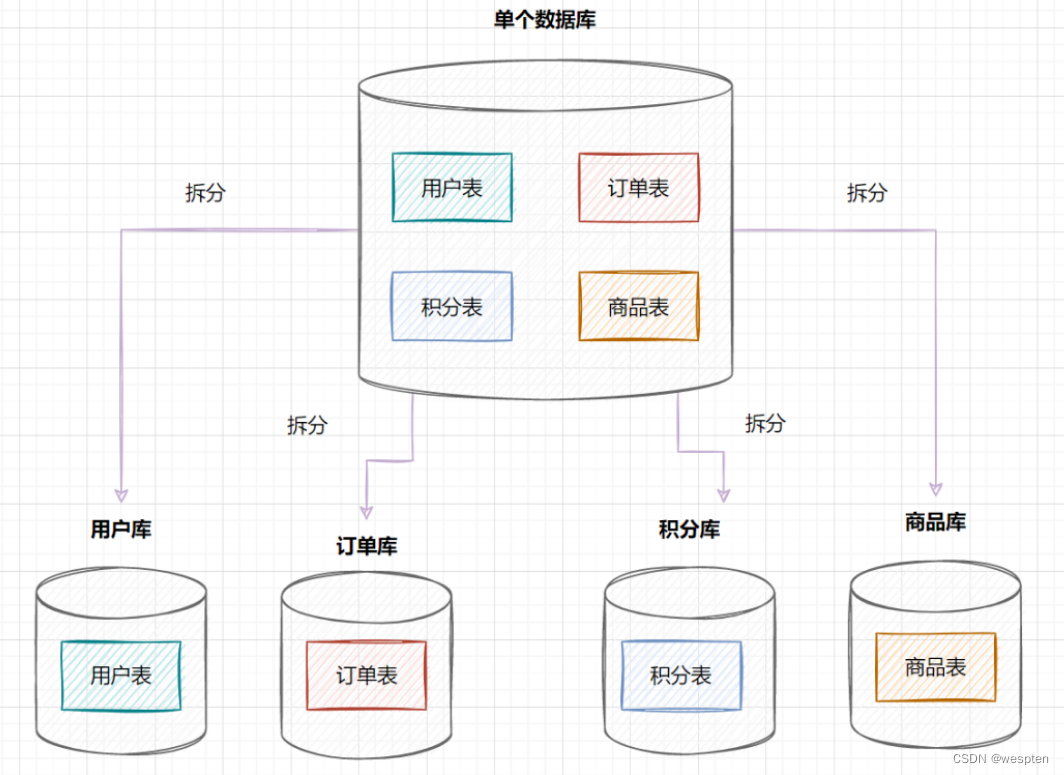
但是随着业务蒸蒸日上,系统功能逐渐完善。这时候,可以按照系统中的不同业务进行拆分,比如拆分成用户库、订单库、积分库、商品库,把它们部署在不同的数据库服务器,这就是垂直分库。
垂直分库,将原来一个单数据库的压力分担到不同的数据库,可以很好应对高并发场景。数据库垂直拆分后的架构如下:
② 垂直分表
如果一个单表包含了几十列甚至上百列,管理起来很混乱,每次都select *的话,还占用IO资源。这时候,我们可以将一些不常用的、数据较大或者长度较长的列拆分到另外一张表。
比如一张用户表,它包含user_id、user_name、mobile_no、age、email、nickname、address、user_desc,如果email、address、user_desc等字段不常用,我们可以把它拆分到另外一张表,命名为用户详细信息表。这就是垂直分表

2. 水平拆分
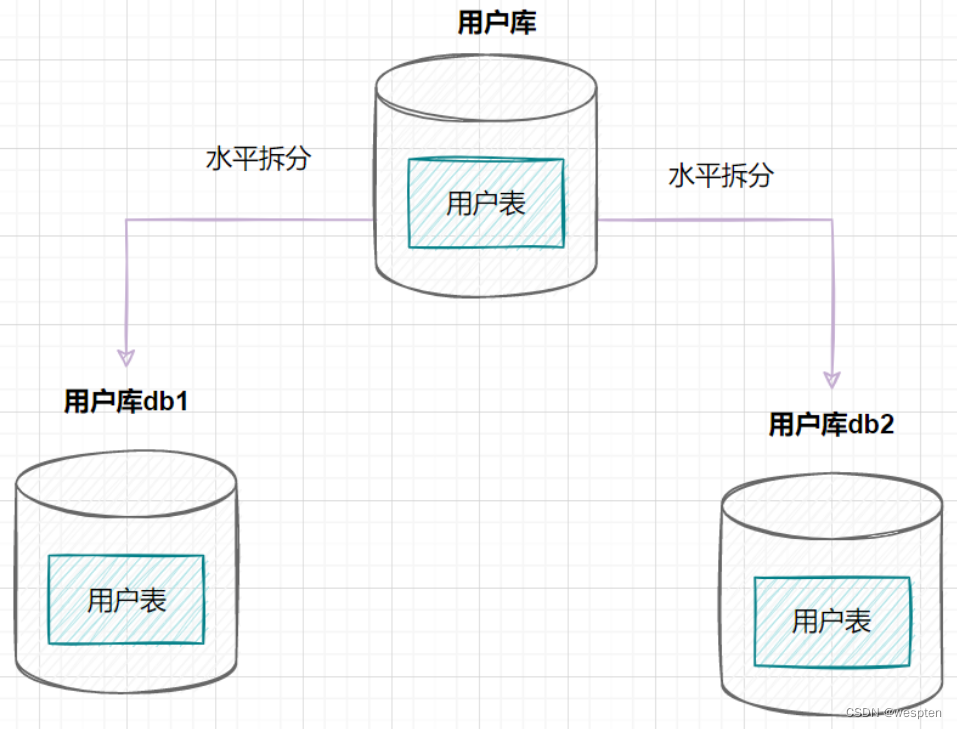
① 水平分库
水平分库是指,将表的数据量切分到不同的数据库服务器上,每个服务器具有相同的库和表,只是表中的数据集合不一样。它可以有效的缓解单机单库的性能瓶颈和压力。
用户库的水平拆分架构如下:
② 水平分表
如果一个表的数据量太大,可以按照某种规则(如hash取模、range),把数据切分到多张表去。
一张订单表,按时间range拆分如下:

3. 水平分库分表策略
分库分表策略一般有几种,使用与不同的场景:
-
range范围
-
hash取模
-
range+hash取模混合
① range范围
range,即范围策略划分表。比如我们可以将表的主键,按照从0~1000万的划分为一个表,1000~2000万划分到另外一个表。如下图:

当然,有时候我们也可以按时间范围来划分,如不同年月的订单放到不同的表,它也是一种range的划分策略。
这种方案的优点:
-
这种方案有利于扩容,不需要数据迁移。假设数据量增加到5千万,我们只需要水平增加一张表就好啦,之前
0~4000万的数据,不需要迁移。
缺点:
-
这种方案会有热点问题,因为订单id是一直在增大的,也就是说最近一段时间都是汇聚在一张表里面的。比如最近一个月的订单都在
1000万~2000万之间,平时用户一般都查最近一个月的订单比较多,请求都打到order_1表啦,这就导致数据热点问题。
② hash取模
hash取模策略:指定的路由key(一般是user_id、订单id作为key)对分表总数进行取模,把数据分散到各个表中。
比如原始订单表信息,我们把它分成4张分表:
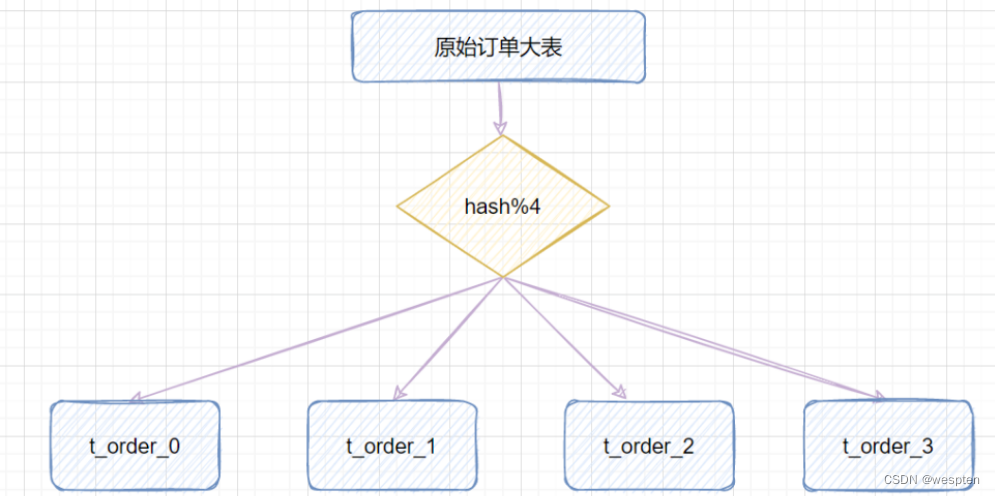
-
比如id=1,对4取模,就会得到1,就把它放到
t_order_1; -
id=3,对4取模,就会得到3,就把它放到
t_order_3;
这种方案的优点:
-
hash取模的方式,不会存在明显的热点问题。
缺点:
-
如果一开始按照hash取模分成4个表了,未来某个时候,表数据量又到瓶颈了,需要扩容,这就比较棘手了。比如你从4张表,又扩容成
8张表,那之前id=5的数据是在(5%4=1,即t_order_1),现在应该放到(5%8=5,即t_order_5),也就是说历史数据要做迁移了。
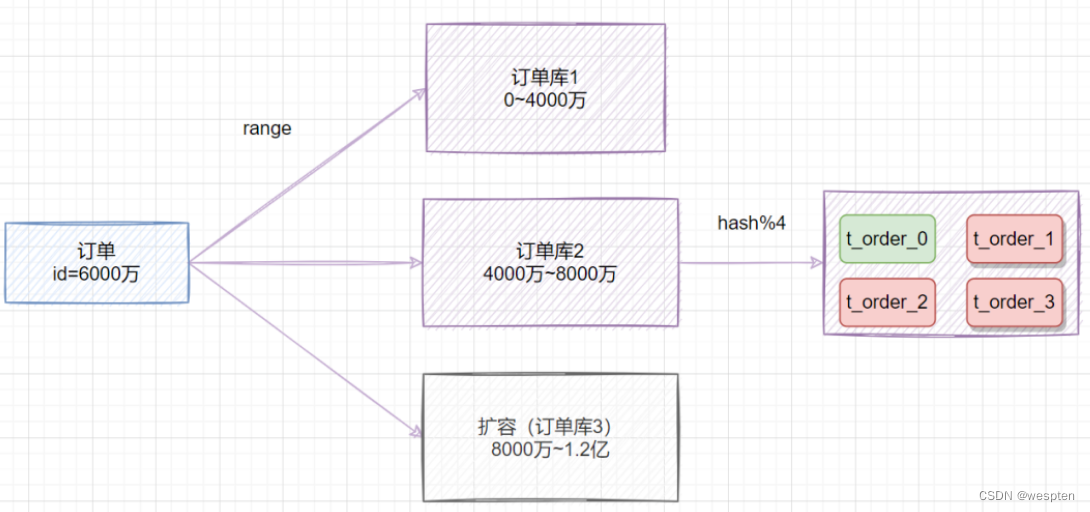
③ range+hash取模混合
既然range存在热点数据问题,hash取模扩容迁移数据比较困难,我们可以综合两种方案一起嘛,取之之长,弃之之短。
比较简单的做法就是,在拆分库的时候,我们可以先用range范围方案,比如订单id在0~4000万的区间,划分为订单库1;id在4000万~8000万的数据,划分到订单库2,将来要扩容时,id在8000万~1.2亿的数据,划分到订单库3。然后订单库内,再用hash取模的策略,把不同订单划分到不同的表。
4)什么时候才考虑分库分表
1. 什么时候分表
如果你的系统处于快速发展时期,如果每天的订单流水都新增几十万,并且,订单表的查询效率明变慢时,就需要规划分库分表了。一般B+树索引高度是2~3层最佳,如果数据量千万级别,可能高度就变4层了,数据量就会明显变慢了。不过业界流传,一般500万数据就要考虑分表了。
2. 什么时候分库
业务发展很快,还是多个服务共享一个单体数据库,数据库成为了性能瓶颈,就需要考虑分库了。比如订单、用户等,都可以抽取出来,新搞个应用(其实就是微服务思想),并且拆分数据库(订单库、用户库)。
5)分库分表会导致哪些问题
分库分表之后,也会存在一些问题:
-
事务问题
-
跨库关联
-
排序问题
-
分页问题
-
分布式ID
① 事务问题
分库分表后,假设两个表在不同的数据库,那么本地事务已经无效啦,需要使用分布式事务了。
② 跨库关联
跨节点Join的问题:解决这一问题可以分两次查询实现。
③ 排序问题
跨节点的count,order by,group by以及聚合函数等问题:可以分别在各个节点上得到结果后在应用程序端进行合并。
④ 分页问题
-
方案1:在个节点查到对应结果后,在代码端汇聚再分页。
-
方案2:把分页交给前端,前端传来pageSize和pageNo,在各个数据库节点都执行分页,然后汇聚总数量前端。这样缺点就是会造成空查,如果分页需要排序,也不好搞。
⑤ 分布式ID
数据库被切分后,不能再依赖数据库自身的主键生成机制啦,最简单可以考虑UUID,或者使用雪花算法生成分布式ID。
6)分库分表中间件
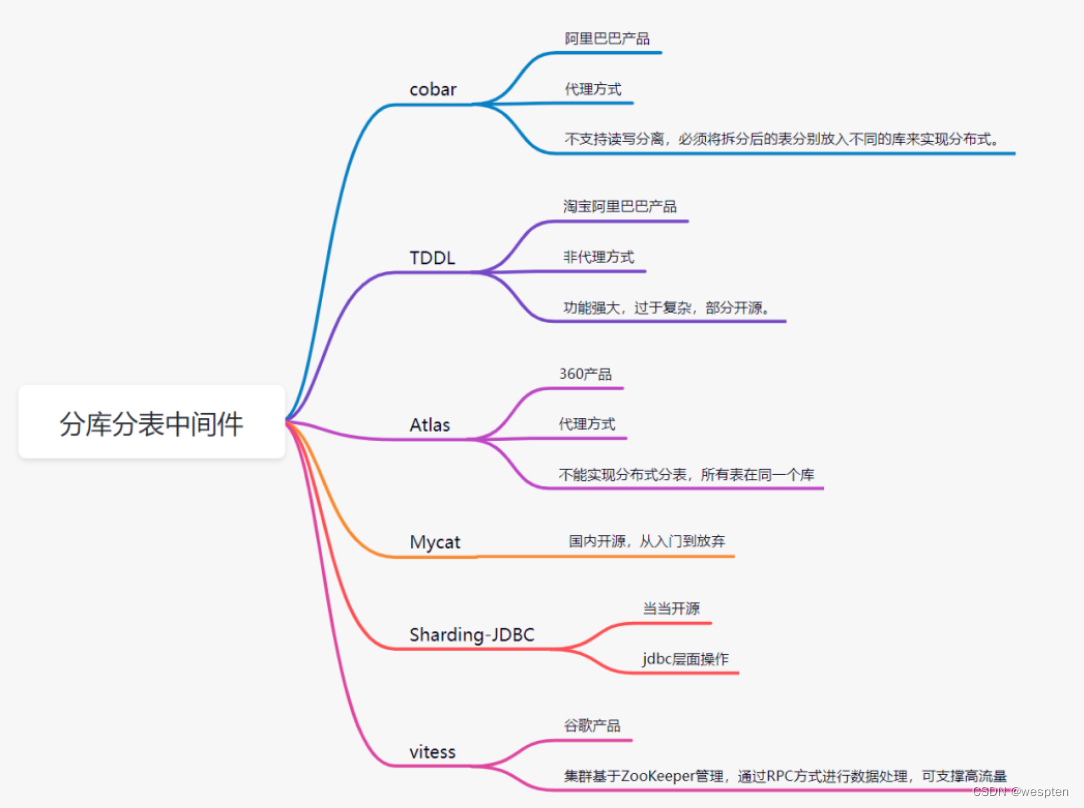
目前流行的分库分表中间件比较多:
-
cobar
-
Mycat
-
Sharding-JDBC
-
Atlas
-
TDDL(淘宝)
-
vitess
5、MySQL 主从
1)MySQL 主从
1. 什么是 MySQL 主从
所谓 MySQL 主从,就是建立两个完全一样的数据库,一个是主库,一个是从库,主库对外提供读写的操作,从库对外提供读的操作。

2. 为什么使用 MySQL 主从
对于数据库单机部署,在 4 核 8G 的机器上运行 MySQL 5.7 时,大概可以支撑 500 的 TPS 和 10000 的 QPS,当遇到一些活动时,查询流量骤然,就需要进行主从分离。
大部分系统的访问模型是读多写少,读写请求量的差距可能达到几个数量级,所以我们可以通过一主多从的方式,主库只负责写入和部分核心逻辑的查询,多个从库只负责查询,提升查询性能,降低主库压力。
当主库宕机时,从库可以切成主库,保证服务的高可用,然后主库也可以做数据的容灾备份,整体场景总结如下:
-
读写分离:从库提供查询,减少主库压力,提升性能;
-
高可用:故障时可切换从库,保证服务高可用;
-
数据备份:数据备份到从库,防止服务器宕机导致数据丢失。
2)主从复制
1. 主从复制原理
MySQL 的主从复制是依赖于 binlog,也就是记录 MySQL 上的所有变化并以二进制形式保存在磁盘上二进制日志文件。
主从复制就是将 binlog 中的数据从主库传输到从库上,一般这个过程是异步的,即主库上的操作不会等待 binlog 同步地完成。
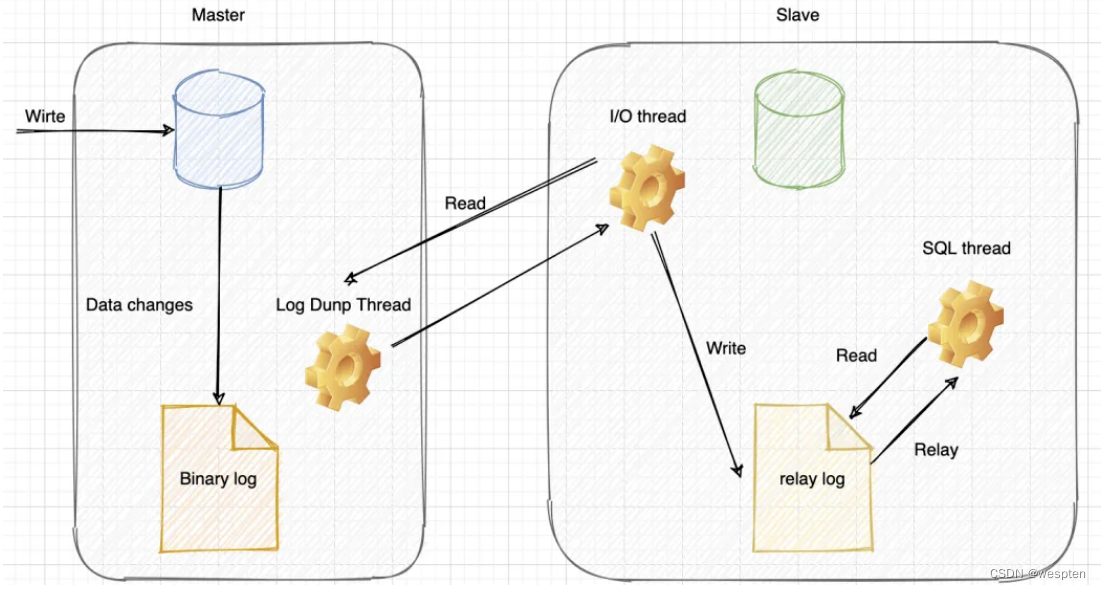
详细流程如下:
-
主库写 binlog:主库的更新 SQL(update、insert、delete) 被写到 binlog;
-
主库发送 binlog:主库创建一个 log dump 线程来发送 binlog 给从库;
-
从库写 relay log:从库在连接到主节点时会创建一个 IO 线程,以请求主库更新的 binlog,并且把接收到的 binlog 信息写入一个叫做 relay log 的日志文件;
-
从库回放:从库还会创建一个 SQL 线程读取 relay log 中的内容,并且在从库中做回放,最终实现主从的一致性。
2. 如何保证主从一致
当主库和从库数据同步时,突然中断怎么办?因为主库与从库之间维持了一个长链接,主库内部有一个线程,专门服务于从库的这个长链接。
对于下面的情况,假如主库执行如下 SQL,其中 a 和 create_time 都是索引:
delete from t where a > '666' and create_time<'2022-03-01' limit 1;我们知道,数据选择了 a 索引和选择 create_time 索引,最后 limit 1 出来的数据一般是不一样的。
所以就会存在这种情况:在 binlog = statement 格式时,主库在执行这条 SQL 时,使用的是索引 a,而从库在执行这条 SQL 时,使用了索引 create_time,最后主从数据不一致了。
那么我们该如何解决呢?
可以把 binlog 格式修改为 row,row 格式的 binlog 日志记录的不是 SQL 原文,而是两个 event:Table_map 和 Delete_rows。
Table_map event 说明要操作的表,Delete_rows event用于定义要删除的行为,记录删除的具体行数。row 格式的 binlog 记录的就是要删除的主键 ID 信息,因此不会出现主从不一致的问题。
但是如果 SQL 删除 10 万行数据,使用 row 格式就会很占空间,10 万条数据都在 binlog 里面,写 binlog 的时候也很耗 IO。但是 statement 格式的 binlog 可能会导致数据不一致。
设计 MySQL 的大叔想了一个折中的方案,mixed 格式的 binlog,其实就是 row 和 statement 格式混合使用,当 MySQL 判断可能数据不一致时,就用 row 格式,否则使用就用 statement 格式。
3)主从延迟
有时候我们遇到从数据库中获取不到信息的诡异问题时,会纠结于代码中是否有一些逻辑会把之前写入的内容删除,但是你又会发现,过了一段时间再去查询时又可以读到数据了,这基本上就是主从延迟在作怪。
主从延迟,其实就是“从库回放” 完成的时间,与 “主库写 binlog” 完成时间的差值,会导致从库查询的数据,和主库的不一致。
1. 主从延迟原理
谈到 MySQL 数据库主从同步延迟原理,得从 MySQL 的主从复制原理说起:
-
MySQL 的主从复制都是单线程的操作,主库对所有 DDL 和 DML 产生 binlog,binlog 是顺序写,所以效率很高;
-
Slave 的 Slave_IO_Running 线程会到主库取日志,放入 relay log,效率会比较高;
-
Slave 的 Slave_SQL_Running 线程将主库的 DDL 和 DML 操作都在 Slave 实施,DML 和 DDL 的 IO 操作是随机的,不是顺序的,因此成本会很高,还可能是 Slave 上的其他查询产生 lock 争用,由于 Slave_SQL_Running 也是单线程的,所以一个 DDL 卡住了,需要执行 10 分钟,那么所有之后的 DDL 会等待这个 DDL 执行完才会继续执行,这就导致了延时。
总结一下主从延迟的主要原因:主从延迟主要是出现在 “relay log 回放” 这一步,当主库的 TPS 并发较高,产生的 DDL 数量超过从库一个 SQL 线程所能承受的范围,那么延时就产生了,当然还有就是可能与从库的大型 query 语句产生了锁等待。
2. 主从延迟情况
-
从库机器性能:从库机器比主库的机器性能差,只需选择主从库一样规格的机器就好。
-
从库压力大:可以搞了一主多从的架构,还可以把 binlog 接入到 Hadoop 这类系统,让它们提供查询的能力。
-
从库过多:要避免复制的从节点数量过多,从库数据一般以3-5个为宜。
-
大事务:如果一个事务执行就要 10 分钟,那么主库执行完后,给到从库执行,最后这个事务可能就会导致从库延迟 10 分钟啦。日常开发中,不要一次性 delete 太多 SQL,需要分批进行,另外大表的 DDL 语句,也会导致大事务。
-
网络延迟:优化网络,比如带宽 20M 升级到 100M。
-
MySQL 版本低:低版本的 MySQL 只支持单线程复制,如果主库并发高,来不及传送到从库,就会导致延迟,可以换用更高版本的 MySQL,支持多线程复制。
3. 主从延迟解决方案
我们一般会把从库落后的时间作为一个重点的数据库指标做监控和报警,正常的时间是在毫秒级别,一旦落后的时间达到了秒级别就需要告警了。
解决该问题的方法,除了缩短主从延迟的时间,还有一些其它的方法,基本原理都是尽量不查询从库,具体解决方案如下:
-
使用缓存:我们在同步写数据库的同时,也把数据写到缓存,查询数据时,会先查询缓存,不过这种情况会带来 MySQL 和 Redis 数据一致性问题。
-
查询主库:直接查询主库,这种情况会给主库太大压力,不建议这种方式。
-
数据冗余:对于一些异步处理的场景,如果只扔数据 ID,消费数据时,需要查询从库,我们可以把数据全部都扔给消息队列,这样消费者就无需再查询从库。(这种情况应该不太能出现,数据转了一圈,MySQL 主从还没有同步好,直接去撕 DBA 吧)
在实际应用场景中,对于一些非常核心的场景,比如库存,支付订单等,需要直接查询主库,其它非核心场景,就不要去查主库了。
4)主从切换
1. 一主一从
两台机器 A 和 B,A 为主库,负责读写,B 为从库,负责读数据。
如果 A 库发生故障,B 库成为主库负责读写,修复故障后,A 成为从库,主库 B 同步数据到从库 A。

-
优点:从库支持读,分担了主库的压力,提升了并发度,且一个机器故障了可以自动切换,操作比较简单,公司从库还可以充当数据备份的角色;
-
缺点:一台从库,并发支持还是不够,并且一共两台机器,还是存在同时故障的机率,不够高可用。
对于一主一从的模式,一般小公司会这么用,不过该模式下,主从分离的意义其实并不大,因为小公司的流量不高,更多是为了数据库的可用性,以及数据备份。
2. 一主多从
一台主库多台从库,A 为主库,负责读写,B、C、D为从库,负责读数据。
如果 A 库发生故障,B 库成为主库负责读写,C、D 负责读,修复故障后,A 也成为从库,主库 B 同步数据到从库 A。
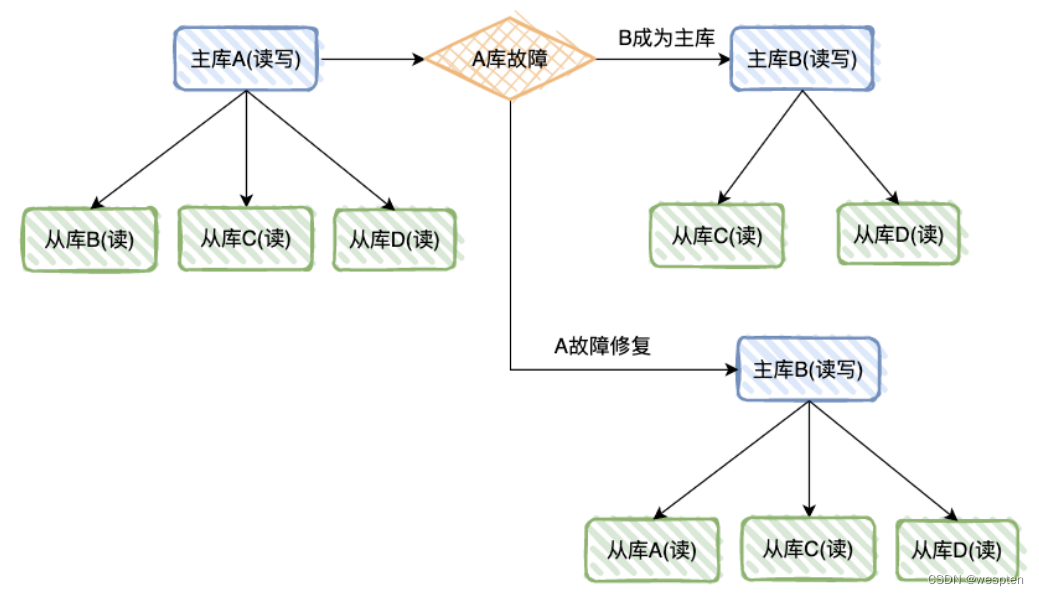
-
优点:多个从库支持读,分担了主库的压力,明显提升了读的并发度。
-
缺点:只有一台主机写,因此写的并发度不高。
基本上大公司,比如百度、滴滴,都是这种一主多从的模式,因为查询流量太高,一定需要进行读写分离,同时也需要支持服务的高可用、数据容灾。
再结合上一篇文章讲的分库分表,基本就是大公司的标配了。
6、MySQL 和 Redis 一致性

1)不好的方案
1. 先写 MySQL,再写 Redis
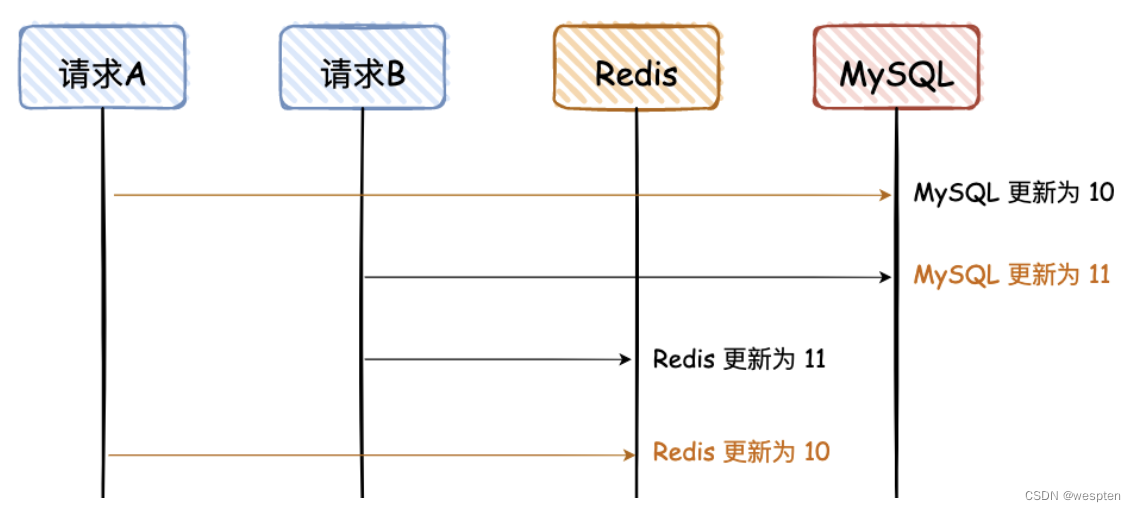
图解说明:
这是一副时序图,描述请求的先后调用顺序;
橘黄色的线是请求 A,黑色的线是请求 B;
橘黄色的文字,是 MySQL 和 Redis 最终不一致的数据;
数据是从 10 更更新为 11;
后面所有的图,都是这个含义,不不再赘述。
请求 A、B 都是先写 MySQL,然后再写 Redis,在高并发情况下,如果请求 A 在写 Redis 时卡了了一会,请求 B 已经依次完成数据的更更新,就会出现图中的问题。
这个图已经画的很清晰了,我就不用再去啰嗦了了吧,不过这里有个前提,就是对于读请求,先去读 Redis,如果没有,再去读 DB,但是读请求不不会再回写 Redis。 大白话说一下,就是读请求不不会更更新Redis。
2. 先写 Redis,再写 MySQL
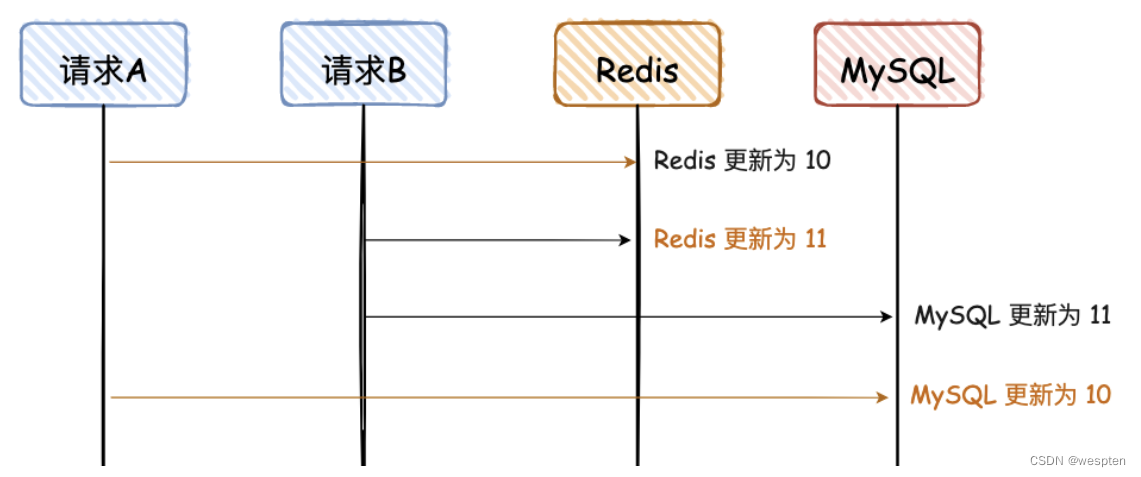
同“先写 MySQL,再写 Redis,看图可秒懂。
3. 先删除 Redis,再写 MySQL
这幅图和上面有些不一样,前面的请求 A 和 B 都是更更新请求,这里的请求 A 是更新请求,但是请求 B 是读请求,且请求 B 的读请求会回写 Redis。
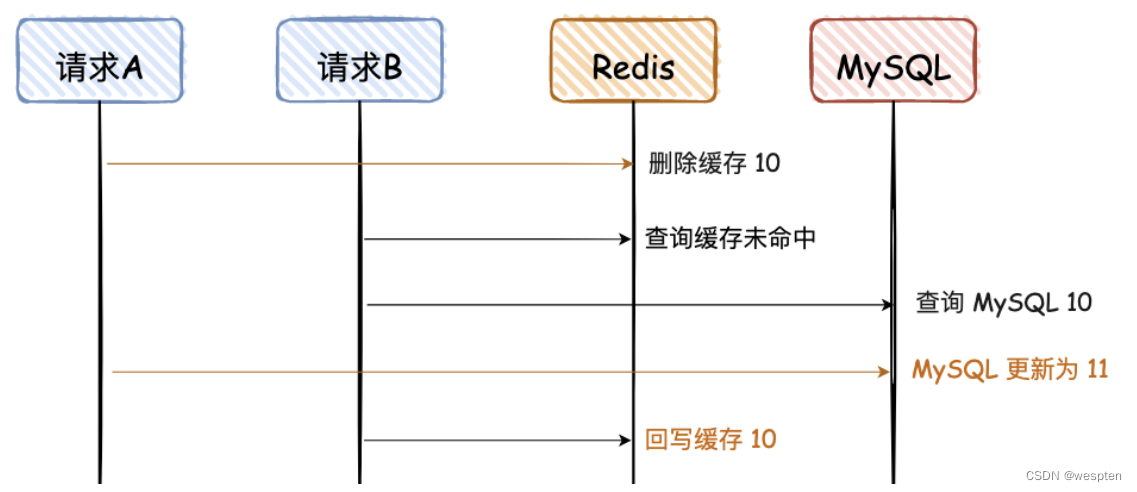
请求 A 先删除缓存,可能因为卡顿,数据⼀一直没有更更新到 MySQL,导致两者数据不一致。
这种情况出现的概率比较大,因为请求 A 更更新 MySQL 可能耗时会比较长,而请求 B 的前两步都是查询,会非常快。
2)好的方案
1. 先删除 Redis,再写 MySQL,再删除 Redis
对于 “先删除 Redis,再写 MySQL”,如果要解决最后的不一致问题,其实再对 Redis 重新删除即可,这个也是大家常说的 “缓存双删”。

为了便于大家看图,对于蓝色的文字,“删除缓存 10”必须在“回写缓存10”后面,那如何才能保证一定是在后面呢?
网上给出的第一个方案是,让请求 A 的最后一次删除,等待 500ms。对于这种方案,看看就行,反正我是不会用,太 Low 了,风险也不可控。
那有没有更好的方案呢,我建议异步串行化删除,即删除请求入队列。

异步删除对线上业务无影响,串行化处理保障并发情况下正确删除。
如果双删失败怎么办,网上有给 Redis 加一个缓存过期时间的方案,这个不敢苟同。个人建议整个重试机制,可以借助消息队列的重试机制,也可以自己整个表,记录重试次数,方法很多。
总结:
“缓存双删” 不要用无脑的 sleep 500 ms;
通过消息队列的异步&串行,实现最后一次缓存删除;
缓存删除失败,增加重试机制。
2. 先写 MySQL,再删除 Redis
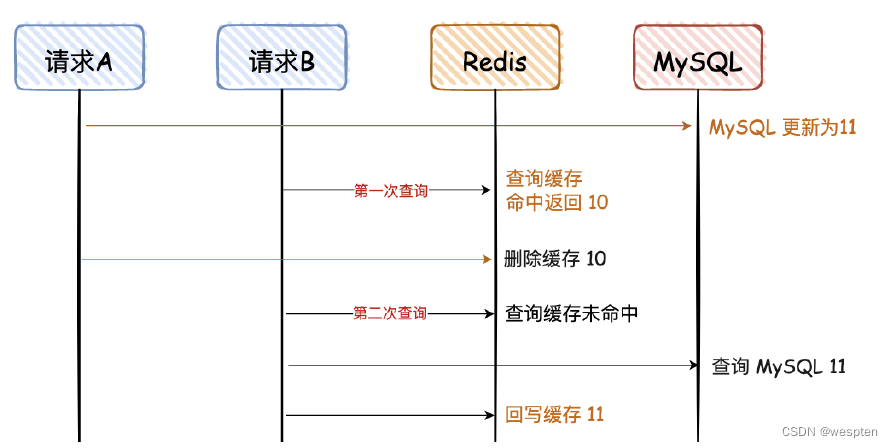
对于上面这种情况,对于第一次查询,请求 B 查询的数据是 10,但是 MySQL 的数据是 11,只存在这一次不一致的情况,对于不是强一致性要求的业务,可以容忍。(那什么情况下不能容忍呢,比如秒杀业务、库存服务等。)
当请求 B 进行第二次查询时,因为没有命中 Redis,会重新查一次 DB,然后再回写到 Reids。

这里需要满足2个条件:
1. 缓存刚好自动失效;
2. 请求 B 从数据库查出 10,回写缓存的耗时,比请求 A 写数据库,并且删除缓存的还长。
对于第二个条件,我们都知道更更新 DB 肯定比查询耗时要长,所以出现这个情况的概率很小,同时满足上述条件的情况更小。
3. 先写 MySQL,通过 Binlog,异步更更新 Redis
这种方案,主要是监听 MySQL 的 Binlog,然后通过异步的方式,将数据更更新到 Redis,这种方案有个前提,查询的请求,不会回写 Redis。
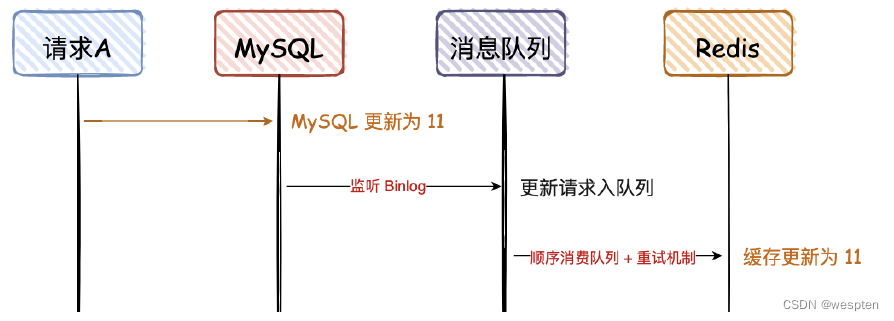
这个方案,会保证 MySQL 和 Redis 的最终一致性,但是如果中途请求 B 需要查询数据,如果缓存无数据,就直接查 DB;如果缓存有数据,查询的数据也会存在不一致的情况。
所以这个方案,是实现最终一致性的终极解决方案,但是不能保证实时性。
几种方案比较:
我们对比上面讨论的6种方案∶
1. 先写Redis,再写MySQL
● 这种方案,我肯定不会用,万一DB挂了,你把数据写到缓存,DB无数据,这个是灾难性的;
● 我之前也见同学这么用过,如果写DB失败,对Redis进行逆操作,那如果逆操作失败呢,是不是还要搞个重试?
2. 先写MySQL,再写Redis
● 对于并发量、一致性要求不高的项目,很多就是这么用的,我之前也经常这么搞,但是不建议这么做;● 当 Redis 瞬间不可用的情况,需要报警出来,然后线下处理。
3. 先删除Redis,再写MySQL ● 这种方式,我还真没用过,直接忽略吧。
4. 先删除Redis,再写MySQL,再删除Redis
● 这种方式虽然可行,但是感觉好复杂,还要搞个消息队列去异步删除Redis。
5. 先写MySQL,再删除Redis
● 比较推荐这种方式,删除Redis如果失败,可以再多重试几次,否则报警出来;
● 这个方案,是实时性中最好的方案,在一些高并发场景中,推荐这种。
6. 先写MySQL,通过Binlog,异步更新Redis
● 对于异地容灾、数据汇总等,建议会用这种方式,比如 binlog + kafka,数据的一致性也可以达到秒级;
● 纯粹的高并发场景,不建议用这种方案,比如抢购、秒杀等。
个人结论∶
● 实时-致性方案;采用“先写 MSQL,再删除 Fedlis”的策略,这种情况虽然也会存在两者不一致,但是需要满足的条件有点苛刻,所以是满足实时性条件下,能尽量满足一致性的最优解。
● 最终一致性方案;采用“先写 MySQL,通过 BInlog,异步更新 Redis”,可以通过 Binlog,结合消息队列异步更新 Redis,是最终一致性的最优解。
7、数据库连接池调优
数据库连接池的配置是开发者们常常搞出坑的地方,在配置数据库连接池时,有几个可以说是和直觉背道而驰的原则需要明确。
为什么nginx只用4个线程发挥出的性能就大大超越了100个进程的Apache HTTPD?
即使是单核CPU的计算机也能“同时”运行数百个线程。但我们都[应该]知道这只不过是操作系统用时间分片玩的一个小把戏。一颗CPU核心同一时刻只能执行一个线程,然后操作系统切换上下文,核心开始执行另一个线程的代码,以此类推。给定一颗CPU核心,其顺序执行A和B永远比通过时间分片“同时”执行A和B要快,这是一条计算机科学的基本法则。一旦线程的数量超过了CPU核心的数量,再增加线程数系统就只会更慢,而不是更快。
1. 有限的资源
当我们寻找数据库的性能瓶颈时,总是可以将其归为三类:CPU、磁盘、网络。把内存加进来也没有错,但比起磁盘和网络,内存的带宽要高出好几个数量级,所以就先不加了。
如果我们无视磁盘和网络,那么结论就非常简单。在一个8核的服务器上,设定连接/线程数为8能够提供最优的性能,再增加连接数就会因上下文切换的损耗导致性能下降。数据库通常把数据存储在磁盘上,磁盘又通常是由一些旋转着的金属碟片和一个装在步进马达上的读写头组成的。读/写头同一时刻只能出现在一个地方,然后它必须“寻址”到另外一个位置来执行另一次读写操作。所以就有了寻址的耗时,此外还有旋回耗时,读写头需要等待碟片上的目标数据“旋转到位”才能进行操作。使用缓存当然是能够提升性能的,但上述原理仍然成立。
在这一时间段(即"I/O等待")内,线程是在“阻塞”着等待磁盘,此时操作系统可以将那个空闲的CPU核心用于服务其他线程。所以,由于线程总是在I/O上阻塞,我们可以让线程/连接数比CPU核心多一些,这样能够在同样的时间内完成更多的工作。
那么应该多多少呢?这要取决于磁盘。较新型的SSD不需要寻址,也没有旋转的碟片。可别想当然地认为“SSD速度更快,所以我们应该增加线程数”,恰恰相反,无需寻址和没有旋回耗时意味着更少的阻塞,所以更少的线程[更接近于CPU核心数]会发挥出更高的性能。只有当阻塞创造了更多的执行机会时,更多的线程数才能发挥出更好的性能。
网络和磁盘类似。通过以太网接口读写数据时也会形成阻塞,10G带宽会比1G带宽的阻塞少一些,1G带宽又会比100M带宽的阻塞少一些。不过网络通常是放在第三位考虑的,有些人会在性能计算中忽略它们。
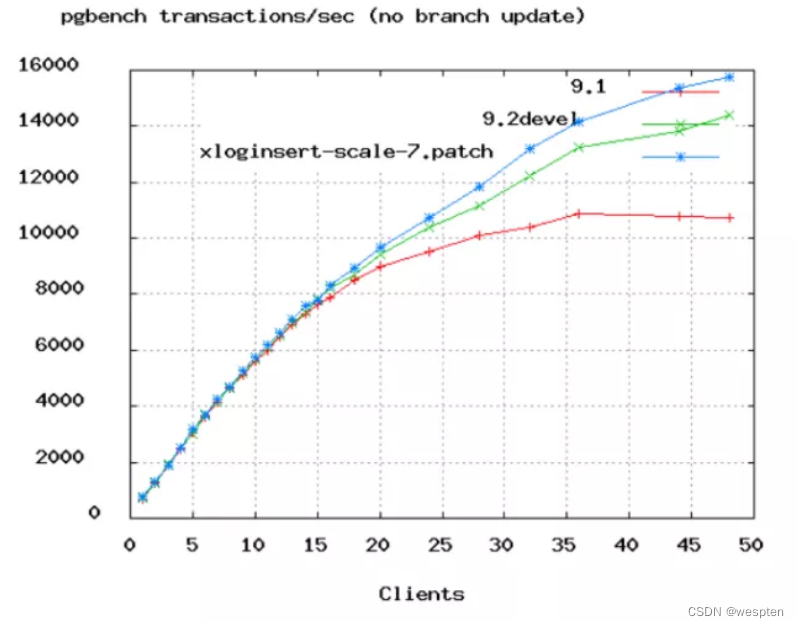
上图是PostgreSQL的benchmark数据,可以看到TPS增长率从50个连接数开始变缓。
2. 连接数值计算
下面的公式是由PostgreSQL提供的,不过我们认为可以广泛地应用于大多数数据库产品。你应该模拟预期的访问量,并从这一公式开始测试你的应用,寻找最合适的连接数值。
连接数 = ((核心数 * 2) + 有效磁盘数)
核心数不应包含超线程(hyper thread),即使打开了hyperthreading也是。如果活跃数据全部被缓存了,那么有效磁盘数是0,随着缓存命中率的下降,有效磁盘数逐渐趋近于实际的磁盘数。这一公式作用于SSD时的效果如何尚未有分析。
按这个公式,你的4核i7数据库服务器的连接池大小应该为((4 * 2) + 1) = 9。取个整就算是是10吧。是不是觉得太小了?跑个性能测试试一下,我们保证它能轻松搞定3000用户以6000TPS的速率并发执行简单查询的场景。如果连接池大小超过10,你会看到响应时长开始增加,TPS开始下降。
3. 数据库连接池调优案例
有一个网站,压力虽然还没到Facebook那个级别,但也有个1万上下的并发访问——也就是说差不多2万左右的TPS。那么这个网站的数据库连接池应该设置成多大呢?结果可能会让你惊讶,因为这个问题的正确问法是:
- “这个网站的数据库连接池应该设置成多小呢?”
Oracle数据库进行压力测试,9600并发线程进行数据库操作,每两次访问数据库的操作之间sleep 550ms,一开始设置的中间件线程池大小为2048:

初始的配置:
压测跑起来之后是这个样子的。

2048连接时的性能数据:
每个请求要在连接池队列里等待33ms,获得连接后执行SQL需要77ms,此时数据库的等待事件是这个熊样的。

各种buffer busy waits,数据库CPU在95%左右(这张图里没截到CPU)。
接下来,把中间件连接池减到1024(并发什么的都不变),性能数据变成了这样:

连接池降到1024后,获取链接等待时长没怎么变,但是执行SQL的耗时减少了。
下面这张图,上半部分是wait,下半部分是吞吐量:

wait和吞吐量:
能看到,中间件连接池从2048减半之后,吐吞量没变,但wait事件减少了一半。
接下来,把数据库连接池减到96,并发线程数仍然是9600不变。

96个连接时的性能数据:
队列平均等待1ms,执行SQL平均耗时2ms。

wait事件几乎没了,吞吐量上升。
没有调整任何其他东西,仅仅只是缩小了中间件层的数据库连接池,就把请求响应时间从100ms左右缩短到了3ms。
我们把连接数从2048降到了96,实际上96都太高了,除非服务器有16或32颗核心。
假如你有10000个并发用户,设置一个10000的连接池基本等于失了智。1000仍然很恐怖。即使100也太多了。你需要一个10来个连接的小连接池,然后让剩下的业务线程都在队列里等待。连接池中的连接数量应该等于你的数据库能够有效同时进行的查询任务数(通常不会高于2*CPU核心数)。
我们经常见到一些小规模的web应用,应付着大约十来个的并发用户,却使用着一个100连接数的连接池。这会对你的数据库造成极其不必要的负担。
总结:
连接池的大小最终与系统特性相关。
比如一个混合了长事务和短事务的系统,通常是任何连接池都难以进行调优的。最好的办法是创建两个连接池,一个服务于长事务,一个服务于短事务。
再例如一个系统执行一个任务队列,只允许一定数量的任务同时执行,此时并发任务数应该去适应连接池连接数,而不是反过来。
8、Tomcat 性能调优
1. Tomcat三种运行模式
1. bio模式
默认的模式,性能非常低下,没有经过任何优化处理和支持。
2. nio模式
利用java的异步io护理技术,noblocking IO技术。要想运行在该模式下,则直接修改server.xml里的Connector节点,修改protocol为如下配置。
protocol="org.apache.coyote.http11.Http11NioProtocol"重启Tomcat后,就可以生效。
3. apr模式
安装起来最困难,但是从操作系统级别来解决异步的IO问题,大幅度的提高性能。此种模式下,必须要安装apr和native,直接启动就支持apr。
如nio修改模式,修改protocol为 org.apache.coyote.http11.Http11AprProtocol,如下所示:
protocol="org.apache.coyote.http11.Http11AprProtocol"安装APR:
[root@binghe ~]# yum -y install apr apr-devel openssl-devel
[root@binghe ~]# tar zxvf tomcat-native.tar.gz
[root@binghe ~]# cd tomcat-native-1.1.24-src/jni/native
[root@binghe native]# ./configure --with-apr=/usr/bin/apr-1-config --with-ssl=/usr/include/openssl/
[root@binghe native]# make && make install安装完成之后,会出现如下提示信息:
Libraries have been installed in:
/usr/local/apr/lib安装成功后还需要对tomcat设置环境变量,方法是在catalina.sh文件中增加1行:

修改server.xml的配置,如下所示:
protocol=”org.apache.coyote.http11.Http11AprProtocol”启动tomcat之后,查看日志,如下所示:
more TOMCAT_HOME/logs/catalina.out
2020-04-17 22:34:56 org.apache.catalina.core.AprLifecycleListener init
INFO: Loaded APR based Apache Tomcat Native library 1.1.31 using APR version 1.3.9.
2020-04-17 22:34:56 org.apache.catalina.core.AprLifecycleListener init
INFO: APR capabilities: IPv6 [true], sendfile [true], accept filters [false], random [true].
2020-04-17 22:34:56 org.apache.catalina.core.AprLifecycleListener initializeSSL
INFO: OpenSSL successfully initialized (OpenSSL 1.0.1e 11 Feb 2013)
2020-04-17 22:34:58 AM org.apache.coyote.AbstractProtocol init
INFO: Initializing ProtocolHandler [“http-apr-8080”]
2020-04-17 22:34:58 AM org.apache.coyote.AbstractProtocol init
INFO: Initializing ProtocolHandler [“ajp-apr-8009”]
2020-04-17 22:34:58 AM org.apache.catalina.startup.Catalina load
INFO: Initialization processed in 1125 ms2. JVM 调优
在TOMCAT_HOME/bin/catalina.sh 增加如下语句,具体数值视情况而定。
添加到上面CATALINA_OPTS的后面即可,如下所示:
JAVA_OPTS=-Xms512m -Xmx1024m -XX:PermSize=512M -XX:MaxNewSize=1024m -XX:MaxPermSize=1024m参数详解
- -Xms:JVM初始化堆内存大小。
- -Xmx:JVM堆的最大内存。
- -Xss:线程栈大小。
- -XX:PermSize:JVM非堆区初始内存分配大小。
- -XX:MaxPermSize:JVM非堆区最大内存。
建议和注意事项:
-Xms和-Xmx选项设置为相同堆内存分配,以避免在每次GC 后调整堆的大小,堆内存建议占内存的60%~80%;非堆内存是不可回收内存,大小视项目而定;线程栈大小推荐256k。
32G内存配置如下:
JAVA_OPTS=-Xms20480m -Xmx20480m -Xss1024K -XX:PermSize=512m -XX:MaxPermSize=2048m3. 关闭DNS反向查询
在<Connector port=”8080″ 中加入如下参数:
enableLookups=”false”4. 优化 tomcat 参数
找到Tomcat根目录下的conf目录,修改server.xml文件的内容。对于这部分的调优,我所了解到的就是无非设置一下Tomcat服务器的最大并发数和Tomcat初始化时创建的线程数的设置,当然还有其他一些性能调优的设置,下图是我根据我机子的性能设置的一些参数值:
<Connector port=”8080″
protocol=”org.apache.coyote.http11.Http11AprProtocol”
connectionTimeout=”20000″ //链接超时时长
redirectPort=”8443″
maxThreads=”500″//设定处理客户请求的线程的最大数目,决定了服务器可以同时响应客户请求的数,默认200
minSpareThreads=”20″//初始化线程数,最小空闲线程数,默认为10
acceptCount=”1000″ //当所有可以使用的处理请求的线程数都被使用时,可以被放到处理队列中请求数,请求数超过这个数的请求将不予处理,默认100
enableLookups=”false”
URIEncoding=”UTF-8″ />参数说明:
1)URIEncoding=“UTF-8”:设置Tomcat的字符集。这种配置我们一般是不会设置的,因为关于乱码的转换我们会在具体项目中具体处理,直接修改Tomcat的字符集未免过于太死板。
2)maxThreads=“500”:设置当前Tomcat的最大并发数。Tomcat默认配置的最大请求数是150个,即同时能支持150个并发。但是在实际运用中,最大并发数与硬件性能和CPU数量都有很大关系的,更好的硬件、更高的处理器都会使Tomcat支持更多的并发数。如果一般在实际开发中,当某个应用拥有 250 个以上并发的时候,都会考虑到应用服务器的集群。
3)minSpareThreads=“20”:设置当前Tomcat初始化时创建的线程数,默认值为25。
4)acceptCount=“1000”:当同时连接的人数达到maxThreads参数设置的值时,还可以接收排队的连接数量,超过这个连接的则直接返回拒绝连接。指定当任何能够使用的处理请求的线程数都被使用时,能够放到处理队列中的请求数,超过这个数的请求将不予处理。默认值为100。在实际应用中,如果想加大Tomcat的并发数 ,应该同时加大acceptCount和maxThreads的值。整编:微信公众号,搜云库技术团队,ID:souyunku
5)enableLookups=“false”:是否开启域名反查,一般设置为false来提高处理能力,它的取值还有true,一般很少使用。
6)maxKeepAliveRequests=“1”:nginx动态的转给tomcat,nginx是不能keepalive的,而tomcat端默认开启了keepalive,会等待keepalive的timeout,默认不设置就是使用connectionTimeout。所以必须设置tomcat的超时时间,并关闭tomcat的keepalive。否则会产生大量tomcat的socket timewait。
maxKeepAliveRequests=”1”就可以避免tomcat产生大量的TIME_WAIT连接,从而从一定程度上避免tomcat假死。
9、JVM 性能调优
Tomcat本身还是运行在JVM上的,通过对JVM参数的调整我们可以使Tomcat拥有更好的性能。目前针对JVM的调优主要有两个方面:内存调优和垃圾回收策略调优。
1. 内存调优
找到Tomcat根目录下的bin目录,设置catalina.sh文件中JAVA_OPTS变量即可,因为后面的启动参数会把JAVA_OPTS作为JVM的启动参数来处理。再说Java虚拟机的内存结构是有点复杂的,相信很多人在理解上都是很抽象的,它主要分为堆、栈、方法区和垃圾回收系统等几个部分组成,下面是我从网上扒的内存结构图:

内存调优这块呢,无非就是通过修改它们各自的内存空间的大小,使应用能够更加合理的运用,下图是我根据我机子的性能设置的参数,给各位详细解释一下各个参数的含义吧:

参数说明:
1)-Xmx512m:设置Java虚拟机的堆的最大可用内存大小,单位:兆(m),整个堆大小=年轻代大小 + 年老代大小 + 持久代大小。持久代一般固定大小为64m。堆的不同分布情况,对系统会产生一定的影响。尽可能将对象预留在新生代,减少老年代GC的次数(通常老年回收起来比较慢)。
实际工作中,通常将堆的初始值和最大值设置相等,这样可以减少程序运行时进行的垃圾回收次数和空间扩展,从而提高程序性能。整编:微信公众号,搜云库技术团队,ID:souyunku
2)-Xms512m:设置Java虚拟机的堆的初始值内存大小,单位:兆(m),此值可以设置与-Xmx相同,以避免每次垃圾回收完成后JVM重新分配内存。
3)-Xmn170m:设置年轻代内存大小,单位:兆(m),此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8。一般在增大年轻代内存后,也会将会减小年老代大小。
4)-Xss128k:设置每个线程的栈大小。JDK5.0以后每个线程栈大小为1M,以前每个线程栈大小为256K。更具应用的线程所需内存大小进行调整。
在相同物理内存下,减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右。
5)-XX:NewRatio=4:设置年轻代(包括Eden和两个Survivor区)与年老代的比值(除去持久代)。设置为4,则年轻代与年老代所占比值为1:4,年轻代占整个堆栈的1/5 。
6)-XX:SurvivorRatio=4:设置年轻代中Eden区与Survivor区的大小比值。设置为4,则两个Survivor区与一个Eden区的比值为2:4,一个Survivor区占整个年轻代的1/6。
7)-XX:MaxPermSize=16m:设置持久代大小为16m,上面也说了,持久代一般固定的内存大小为64m。
8)-XX:MaxTenuringThreshold=0:设置垃圾最大年龄。
如果设置为0的话,则年轻代对象不经过Survivor区,直接进入年老代。对于年老代比较多的应用,可以提高效率。
如果将此值设置为一个较大值,则年轻代对象会在Survivor区进行多次复制,这样可以增加对象再年轻代的存活时间,增加在年轻代即被回收的概论。
2. 垃圾回收策略调优
找到Tomcat根目录下的bin目录,也是设置catalina.sh文件中JAVA_OPTS变量即可。我们都知道Java虚拟机都有默认的垃圾回收机制,但是不同的垃圾回收机制的效率是不同的,正是因为这点我们才经常对Java虚拟机的垃圾回收策略进行相应的调整。下面也是通过我的一些需求来配置的垃圾回收策略:

Java虚拟机的垃圾回收策略一般分为:串行收集器、并行收集器和并发收集器。
串行收集器:
1)-XX:+UseSerialGC:代表垃圾回收策略为串行收集器,即在整个扫描和复制过程采用单线程的方式来进行,适用于单CPU、新生代空间较小及对暂停时间要求不是非常高的应用上,是client级别默认的GC方式,主要在JDK1.5之前的垃圾回收方式。
并发收集器:
1)-XX:+UseParallelGC:代表垃圾回收策略为并行收集器(吞吐量优先),即在整个扫描和复制过程采用多线程的方式来进行,适用于多CPU、对暂停时间要求较短的应用上,是server级别默认采用的GC方式。此配置仅对年轻代有效。该配置只能让年轻代使用并发收集,而年老代仍旧使用串行收集。整编:微信公众号,搜云库技术团队,ID:souyunku
2)-XX:ParallelGCThreads=4:配置并行收集器的线程数,即:同时多少个线程一起进行垃圾回收。此值最好配置与处理器数目相等。
3)-XX:+UseParallelOldGC:配置年老代垃圾收集方式为并行收集。JDK6.0支持对年老代并行收集 。
4)-XX:MaxGCPauseMillis=100:设置每次年轻代垃圾回收的最长时间,如果无法满足此时间,JVM会自动调整年轻代大小,以满足此值。
5)-XX:+UseAdaptiveSizePolicy:设置此选项后,并行收集器会自动选择年轻代区大小和相应的Survivor区比例,以达到目标系统规定的最低相应时间或者收集频率等,此值建议使用并行收集器时,一直打开。
并发收集器:
1)-XX:+UseConcMarkSweepGC:代表垃圾回收策略为并发收集器。
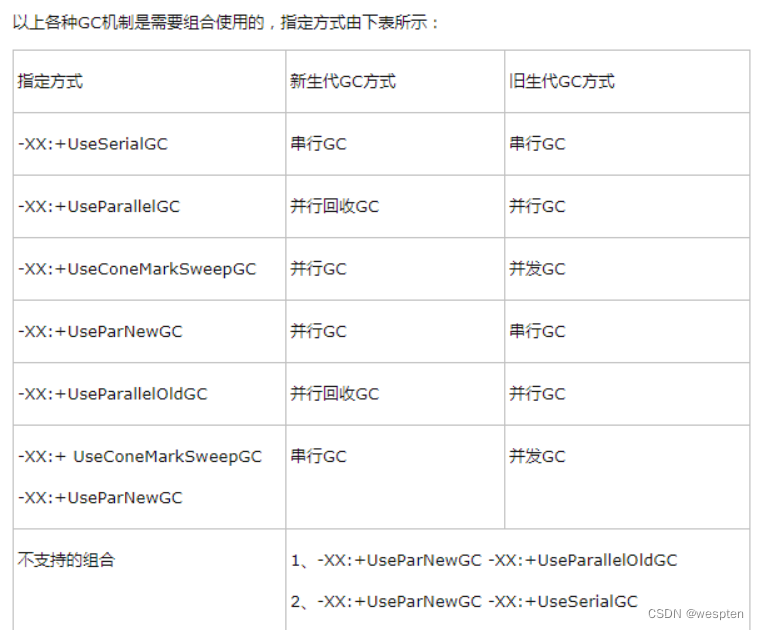
好了,到此我对虚拟机的垃圾回收策略总结就这么多,还是这句话:优化的学习一直在路上,下面还有一张从其他博客中偷到的图,据说以上三种GC机制是需要配合使用的。