文章目录
一、聚类分析
聚类分析作为一种定量方法,将从数据分析的角度,给出一个更准确、细致的分类工具。
1、聚类分析的度量
在聚类分析中,对于定量变量,最常用的是Minkowski距离:
d q ( x , y ) = [ ∑ i = 1 p ∣ x k − y k ∣ 1 / q ] , q > 0 d_q(x,y)=[\sum_{i=1}^p \lvert x_k-y_k\rvert ^{1/q}],q>0 dq(x,y)=[i=1∑p∣xk−yk∣1/q],q>0
当q=1,2或q→+∞时,分别得到:
- 【1】绝对值距离
d q ( x , y ) = [ ∑ i = 1 p ∣ x k − y k ∣ q ] 1 q , q > 0 d_q(x,y)=[\sum_{i=1}^p \lvert x_k-y_k\rvert ^{q}]^{\frac{1}{q}},q>0 dq(x,y)=[i=1∑p∣xk−yk∣q]q1,q>0 - 【2】欧式距离
d 2 ( x , y ) = [ ∑ i = 1 p ∣ x k − y k ∣ 2 ] 1 2 d_2(x,y)=[\sum_{i=1}^p \lvert x_k-y_k\rvert ^{2}]^{\frac{1}{2}} d2(x,y)=[i=1∑p∣xk−yk∣2]21 - 【3】Chebyshev距离
d ∞ ( x , y ) = m a x 1 ⩽ a ⩽ p ∣ x k − y k ∣ d_∞(x,y)= \underset{1\leqslant a\leqslant p}{max}\lvert x_k-y_k\rvert d∞(x,y)=1⩽a⩽pmax∣xk−yk∣
在Minkowski距离中,最常用的是欧氏距离,它的主要优点是当坐标轴进行正交旋转时,欧氏距离是保持不变的。因此,如果对原坐标系进行平移和旋转变换,则变换后样本点间的距离和变换前完全相同。
值得注意的是在采用Minkowski距离时,一定要采用相同量纲的变量。如果变量的量纲不同,测量值变异范围相差悬殊时,建议首先进行数据的标准化处理,然后再计算距离。在采用Minkowski距离时,还应尽可能地避免变量的多重相关性(multicollinearity)。多重相关性所造成的信息重叠,会片面强调某些变量的重要性。
2、系统聚类法
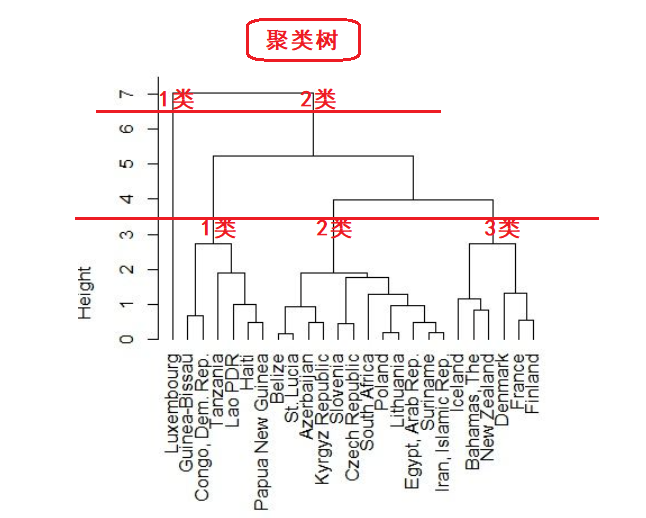
系统聚类法是聚类分析方法中最常用的一种方法。它的优点在于可以指出由粗到细的多种分类情况,典型的系统聚类结果可由一个聚类图展示出来。
聚类树:通过距离树的形式表现出来。
3、变量聚类法
在系统分析或评估过程中,为避免遗漏某些重要因素,往往在一开始选取指标时,尽可能多地考虑所有的相关因素。而这样做的结果,则是变量过多,变量间的相关度高,给系统分析与建模带来很大的不便。因此,人们常常希望能研究变量间的相似关系,按照变量的相似关系把它们聚合成若干类,进而找出影响系统的主要因素。
(1)变量相似性度量
在堆变量进行聚类分析时,首先要确定变量的相似性度量,常用的变量相似性度量有两种。
- 相关系数
- 夹角余弦
(2)变量聚类法
类似于样本集合聚类分析中最常用的最短距离法、最长距离法等,变量聚类法采用了与系统聚类法相同的思路和过程。在变量聚类问题中,常用的有最长距离法、最短距离法等。
4、Q型与R型聚类
聚类分析又称群分析,是对多个样本(或指标)进行定量分类的一种多元统计分析方法。对样本进行分类称为Q型聚类分析,对指标进行分类称为R型聚类分析。
例子:运用Q型和R型聚类分析方法对我国各地区普通高等教育的发展状况进行分析。
近年来,我国普通高等教育得到了迅速发展,为国家培养了大批人才。但由于我国各地区经济发展水平不均衡,加之高等院校原有布局使各地区高等教育发展的起点不一致,因而各地区普通高等教育的发展水平存在一定的差异,不同的地区具有不同的特点。对我国各地区普通高等教育的发展状况进行聚类分析,明确各类地区普通高等教育发展状况的差异与特点,有利于管理和决策部门从宏观上把握我国普通高等教育的整体发展现状,分类制定相关政策,更好的指导和规划我国高教事业的整体健康发展。
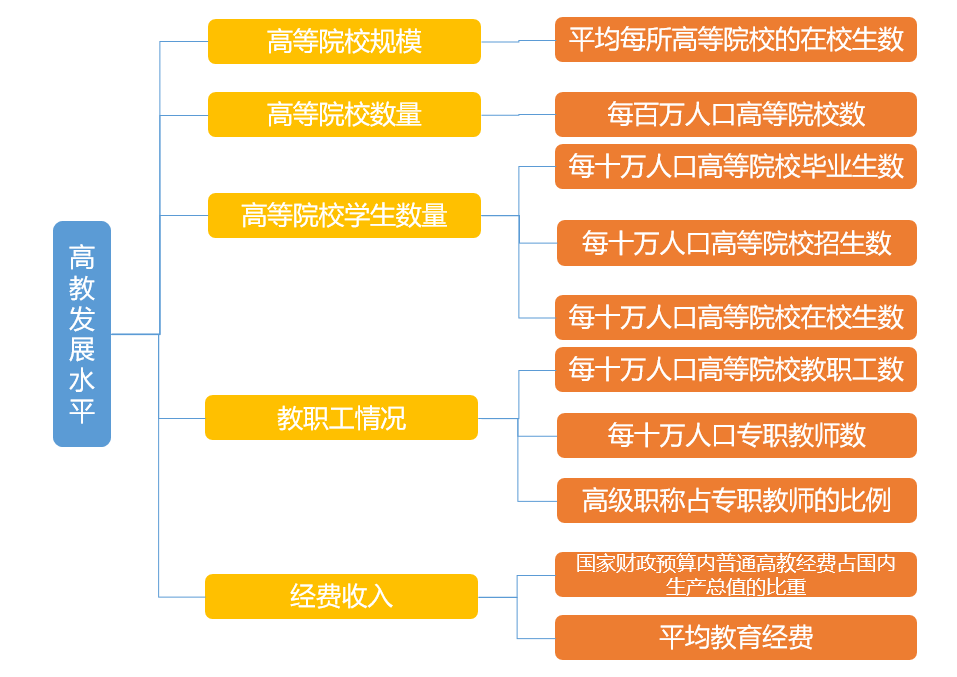
(1)建立综合评价指标体系
从高等教育的五个方面选取十项评价指标。
(2)数据资料
指标的原始数据取自《中国统计年鉴,1995》和《中国教育统计年鉴,1995》除以各地区相应的人口数得到十项指标值。
其中:
- x1:为每百万人口高等院校数
- x2:为每十万人口高等院校毕业生数
- x3:为每十万人口高等院校招生数
- x4:为每十万人口高等院校在校生数
- x5:为每十万人口高等院校教职工数
- x6:为每十万人口高等院校专职教师数
- x7:为高级职称占专职教师的比例
- x8:为平均每所高等院校的在校生数
- x9:为国家财政预算内普通高教经费占国内生产总值的比重
- x10:为平均教育经费
(3)R型聚类分析
相关系数矩阵(指标与指标之间)
可以看出某些指标之间确实存在很强的相关性,因此可以考虑从这些指标中选取几个有代表性的指标进行聚类分析。为此,把十个指标根据其相关性进行R型聚类,再从每个类中选取代表性的指标。首先对每个变量(指标)的数据分别进行标准化处理。变量间相近性度量采用相关系数,类间相近性度量的计算选用类平均法。
指标聚类树形图:
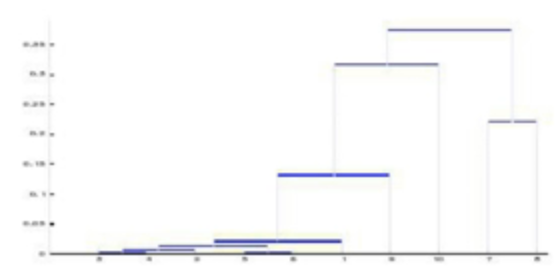
从聚类图中可以看出,每十万人口高等院校招生数、每十万人口高等院校在校生数、每十万人口高等院校教职工人数、每十万人口高等院校专职教师数、每十万人口高等院校毕业生数5个指标之间有较大的相关性,最先被聚到一起。如果将10个指标分为6类,其它5个指标各自为一类。这样就从十个指标中选定了六个分析指标:x1,x2,x7,x8,x8,x10,根据这六个指标对30个地区进行聚类分析。
(4)Q型聚类分析
根据这六个指标对30个地区进行聚类分析。首先对每个变量的数据分别进行标准化处理,样本间相似性采用欧氏距离度量,类间距离的计算选用类平均法。
各地区高等教育发展状况存在较大的差异,高教资源的地区分布很不均衡。
1、如果根据各地区高等教育发展状况把30个地区分为三类,结果为:
第一类:北京:第二类:西藏;第三类:其他地区。
2、如果根据各地区高等教育发展状况把3o个地区分为四类,结果为:
第一类:北京:第二类:西藏:第三类:上海,天津;第四类:其他地区。
3、如果根据各地区高等教育发展状况把3o个地区分为五类,结果为:
第一类:北京:第二类:西藏;第三类:上海,天津;第四类:宁夏、贵州、青海;第五类:其他地区。
二、主成分分析
主成分分析的主要目的是希望用较少的变量去解释原来资料中的大部分变异,将我们手中许多相关性很高的变量转化成彼此相互独立或不相关的变量。通常是选出比原始变量个数少,能解释大部分资料中的变异的几个新变量,即所谓主成分,并用以解释资料的综合性指标。由此可见,主成分分析实际上是一种降维方法。
1、主成分分析注意事项
(1)主成分分析的结果受量纲的影响,由于各变量的单位可能不一样,如果各自改变量纲,结果会不一样,这是主成分分析的最大问题,回归分析是不存在这种情况的,所以实际中可以先把各变量的数据标准化,然后使用协方差矩阵或相关系数矩阵进行分析。
(2)使方差达到最大的主成分分析不用转轴(由于统计软件常把主成分分析和因子分析放在一起,后者往往需要转轴,使用时应注意)。
(3)主成分的保留。用相关系数矩阵求主成分时,Kaiser主张将特征值小于1的主成分予以放弃(这也是SPSS软件的默认值)。
(4)在实际研究中,由于主成分的目的是为了降维,减少变量的个数,故一般选取少量的主成分(不超过5或6个),只要它们能解释变异的70%~80%(称累积贡献率)就行了。
2、主成分估计
主成分估计(principal component estimate)是Massy在1965年提出的,它是回归系数参数的一种线性有偏估计(biased estimate),同其它有偏估计,如岭估计(ridge estimate)等一样,是为了克服最小二乘(LS)估计在设计阵病态(即存在多重共线性)时表现出的不稳定性而提出的。
主成分估计采用的方法是将原来的回归自变量变换到另一组变量,即主成分,选择其中一部分重要的主成分作为新的自变量(此时丢弃了一部分影响不大的自变量,这实际达到了降维的目的),然后用最小二乘法对选取主成分后的模型参数进行估计,最后再变换回原来的模型求出参数的估计。
3、特征因子的筛选
主成分分析,将XTX的特征值按由大到小的次序排列之后,如何筛选这些特征值?一个实用的方法是删去入r+1,入r+2,…,入p,后,这些删去的特征值之和占整个特征值之和∑入i的15%以下,换句话说,余下的特征值所占的比重(定义为累积贡献率)将超过85%,当然这不是一种严格的规定。
单纯考虑累积贡献率有时是不够的,还需要考虑选择的主成分对原始变量的贡献值,我们用相关系数的平方和来表示,如果选取的主成分为z1,z2…,zr,则它们对原变量xj,的贡献值为
ρ i = ∑ j = 1 r r 2 ( z j , x i ) ρ_i=\sum_{j=1}^r r^2(z_j,x_i) ρi=j=1∑rr2(zj,xi)
其中, r ( z j , x i ) 表示 z j 与 x i 的相关系数 其中,r(z_j,x_i)表示z_j与x_i的相关系数 其中,r(zj,xi)表示zj与xi的相关系数
4、案例分析
案例分析—我国各地区普通高等教育发展水平综合评价
主成分分析试图在力保数据信息丢失最少的原则下,对多变量的截面数据表进行最佳综合简化,也就是说,对高维变量空间进行降维处理。本案例运用主成分分析方法综合评价我国各地区普通高等教育的发展水平。
(1)对原始数据进行标准化处理
假设进行主成分分析的指标变量有m个:x1,x2,…,xm,共有m个评价对象,第i个评价对象的第j个指标的取值为aij。将各指标值aij,转换成标准化指标 a i j ~ \widetilde{a_{ij}} aij ,
a i j ~ = a i j − u j s j ,( i = 1 , 2... , n ; j = 1 , 2... m ) \widetilde{a_{ij}}=\frac{a_{ij}-u_j}{s_j},(i=1,2...,n ;j=1,2...m) aij
=sjaij−uj,(i=1,2...,n;j=1,2...m)
其中uj,sj 为第j个指标的样本均值和样本标准差。对应地,称 x i ~ = x i − u j s j \widetilde{x_{i}}=\frac{x_{i}-u_j}{s_j} xi
=sjxi−uj为标准化变量。
(2)计算相关系数矩阵
(3)计算特征值和特征向量
(4)选择p(p<m)个主成分,计算综合评价值
①计算特征值λj (j=1,2,…m)的信息贡献率bj和累计贡献率ap。当ap接近于1时,则选择前p个指标变量y1,y2…yp,作为p个主成分,代替原来m个指标变量,从而可对p个主成分进行综合分析。
②计算综合得分
Z = ∑ j = 1 p b j y j Z=\sum_{j=1}^p b_jy_j Z=j=1∑pbjyj
其中bj为第j个主成分的信息贡献率,根据综合得分值就可以进行评价。
定性考察反映高等教育发展状况的五个方面十项评价指标,可以看出,某些指标之间可能存在较强的相关性。比如每十万人口高等院校毕业生数、每十万人口高等院校招生数与每十万人口高等院校在校生数之间可能存在较强的相关性,每十万人口高等院校教职工数和每十万人口高等院校专职教师数之间可能存在较强的相关性。为了验证这种想法,计算十个指标之间的相关系数。
可以看出某些指标之间确实存在很强的相关性,如果直接用这些指标进行综合评价,必然造成信息的重叠,影响评价结果的客观性。主成分分析方法可以把多个指标转化为少数几个不相关的综合指标,因此,可以考虑利用主成分进行综合评价。
利用MATLAB软件对十个评价指标进行主成分分析,相关系数矩阵的前几个特征根及其贡献率如下表。
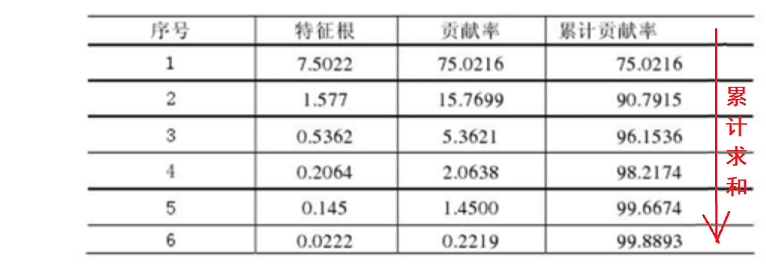
可以看出,前两个特征根的累计贡献率就达到90%以上,主成分分析效果很好。下面选取前四个主成分(累计贡献率就达到98%)进行综合评价。
从主成分的系数可以看出:
第一主成分:主要反映了前六个指标(学校数、学生数和教师数方面)的信息。
第二主成分:主要反映了高校规模和教师中高级职称的比例。
第三主成分:主要反映了生均教育经费。
第四主成分:主要反映了国家则政预算内普通高教经费占国内生产总值的比重。
把各地区原始十个指标的标准化数据代入四个主成分的表达式,就可以得到各地区的四个主成分值。
分别以四个主成分的贡献率为权重,构建主成分综合评价模型:
Z = 0.7502 y 1 + 0.1577 y 2 + 0.0536 y 3 + 0.0206 y 4 Z=0.7502y_1+0.1577y_2+0.0536y_3+0.0206y_4 Z=0.7502y1+0.1577y2+0.0536y3+0.0206y4
(四个主成分相加,前面的系数是λ,即贡献率的百分比,λ之和是0.98)
5、小结
主成分分析: 将原来具有相关关系的多个指标简化为少数几个新的综合指标的多元统计方法。
主成分: 由原始指标综合形成的几个新指标。依据主成分所含信息量的大小成为第一主成分,第二主成分等等。
主成分与原始变量之间的关系:
(1)主成分保留了原始变量绝大多数信息。
(2)主成分的个数大大少于原始变量的数目。
(3)各个主成分之间互不相关。
(4)每个主成分都是原始变量的线性组合。
1、如何进行主成分分析?(主成分分析的方法)
基于相关系数矩阵还是基于协方差矩阵做主成分分析。当分析中所选择的经济变量具有不同的量纲,变量水平差异很大,应该选择基于相关系数矩阵的主成分分析。
2、如何确定主成分个数?
主成分分析的目的是简化变量,一般情况下主成分的个数应该小于原始变量的个数。关于保留几个主成分,应该权衡主成分个数和保留的信息。
三、因子分析
因子分析可以看成主成分分析的推广,它也是多元统计分析中常用的一种降维方式,因子分析所涉及的计算与主成分分析也很类似,但差别也是很明显的:
(1)主成分分析把方差划分为不同的正交成分,而因子分析则把方差划归为不同的起因因子。
(2)因子分析中特征值的计算只能从相关系数矩阵出发,且必须将主成分转换成因子。
举例理解:
(1)诊断时,医生检测了病人的五个生理指标:收缩压、舒张压、心跳间隔、呼吸间隔和舌下温度,但依据生理学知识,这五个指标是受植物神经支配的,植物神经又分为交感神经和副交感神经,因此这五个指标可用交感神经和副交感神经两个公共因子来确定,从而也构成了因子模型。 五个指标直接受两个公共因子的影响。
(2)Holjinger和Swineford在芝加哥郊区对145名七、八年级学生进行了24个心理测验,通过因子分析,这24个心理指标被归结为4个公共因子,即词语因子、速度因子、推理因子和记忆因子。
这里的因子和试验设计里面的因子(因素)不同,这里的因子往往无法单独测量,需要进行抽象和概括。
1、因子分析与其他分析的区别
因子分析(factor analysis)是一种数据简化的技术。它通过研究众多变量之间的内部依赖关系,探求观测数据中的基本结构,并用少数几个假想变量来表示其基本的数据结构。这几个假想变量能够反映原来众多变量的主要信息。原始的变量是可观测的显在变量,而假想变量是不可观测的潜在变量,称为因子。
因子分析与回归分析不同,因子分析中的因子是一个比较抽象的概念,而回归因子有非常明确的实际意义。
主成分分析与因子分析也有不同,主成分分析仅仅是变量变换而因子分析需要构造因子模型。
2、因子分析模型
设p个变量Xi(i=1,2,…p),如果表示为Xi=ui +ai1F1+aimFm +ξi,(m ⩽ \leqslant ⩽ p)
或表示为:
X − u = A F + ξ X-u =AF+ξ X−u=AF+ξ
其中
X = [ X 1 X 2 . . . X p ] X=\left[ \begin{matrix} X_1 \\ X_2 \\ ...\\ X_p \\ \end{matrix} \right] X=⎣
⎡X1X2...Xp⎦
⎤
u = [ u 1 u 2 . . . u p ] u=\left[ \begin{matrix} u_1 \\ u_2 \\ ...\\ u_p \\ \end{matrix} \right] u=⎣ ⎡u1u2...up⎦ ⎤
A = [ a 11 a 12 ⋯ a 1 m a 21 a 22 ⋯ a 2 m ⋮ ⋮ ⋱ ⋮ a p 1 a p 2 ⋯ a p m ] A=\left[ \begin{matrix} a_{11} & a_{12} & \cdots & a_{1m} \\ a_{21} & a_{22} & \cdots & a_{2m} \\ \vdots & \vdots & \ddots & \vdots \\ a_{p1} & a_{p2} & \cdots & a_{pm} \\ \end{matrix} \right] A=⎣ ⎡a11a21⋮ap1a12a22⋮ap2⋯⋯⋱⋯a1ma2m⋮apm⎦ ⎤
ξ = [ ξ 1 ξ 2 . . . ξ p ] ξ=\left[ \begin{matrix} ξ_1 \\ ξ_2 \\ ...\\ ξ_p \\ \end{matrix} \right] ξ=⎣ ⎡ξ1ξ2...ξp⎦ ⎤
3、因子分析的步骤
(1)选择分析的变量
用定性分析和定量分析的方法选择变量,因子分析的前提条件是观测变量间有较强的相关性,因为如果变量之间无相关性或相关性较小的话,他们不会有共享因子,所以原始变量间应该有较强的相关性。
(2)计算所选原始变量的相关系数矩阵
相关系数矩阵描述了原始变量之间的相关关系。可以帮助判断原始变量之间是否存在相关关系,这对因子分析是非常重要的,因为如果所选变量之间无关系,做因子分析是不恰当的。并且相关系数矩阵是估计因子结构的基础。
(3)提出公共因子
这一步要确定因子求解的方法和因子的个数。需要根据研究者的设计方案或有关的经验或知识事先确定。因子个数的确定可以根据因子方差的大小。只取方差大于1(或特征值大于1)的那些因子,因为方差小于1的因了其贡献可能很小;按照因子的累计方差贡献率来确定,一般认为要达到60%才能符合要求。
(4)因子旋转
通过坐标变换使每个原始变量在尽可能少的因子之间有密切的关系,这样因子解的实际意义更容易解释,并为每个潜在因子赋子有实际意义的名字。
(5)计算因子得分
求出各样本的因子得分,有了因子得分值,则可以在许多分析中使用这些因子,例如以因子的得分做聚类分析的变量,做回归分析中的回归因子。
4、案例
实例——我国上市公司盈利能力与资本结构的实证分析根据上市公司的数据,试用因子分析法对上述企业进行综合评价
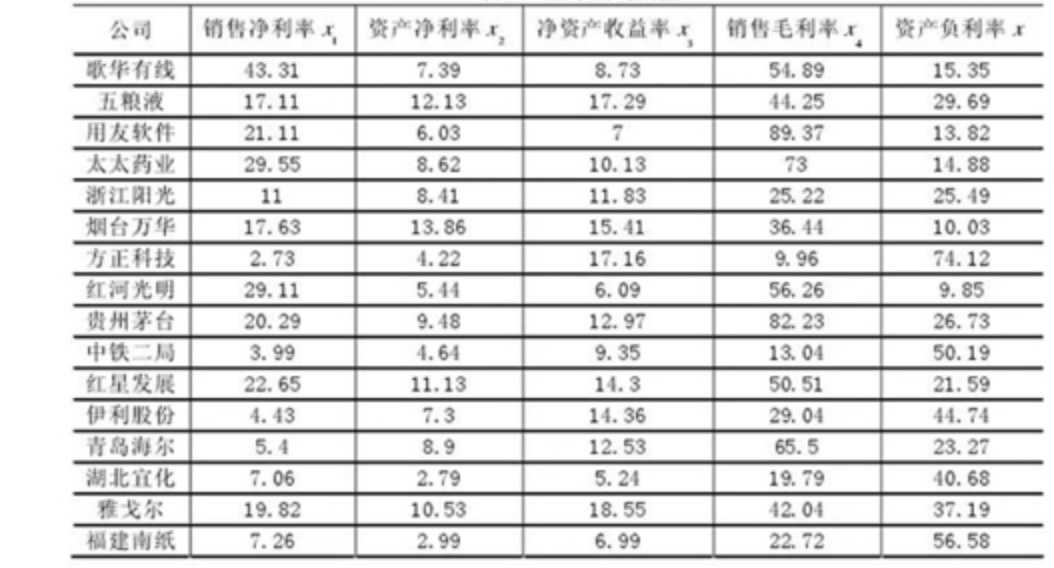
(1)对原始数据进行标准化处理
(2)计算相关系数矩阵R
(3)计算初等载荷矩阵
(4)选择m(m<p)个主因子,进行因子旋转
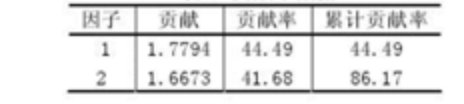
本例中,我们选取两个主因子,利用MATLAB程序计算得旋转后的因子贡献以及贡献率如下表:
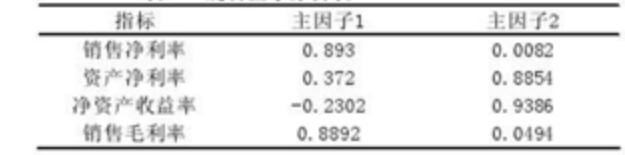
因子载荷阵如下:
(5)计算因子得分,进行综合评价