说明
至少用一种CPU优化方法和Cache优化方法,优化图像平滑函数,对于图像的每个long型像素点dst[i][j],执行如下操作(dst为平滑后的图像):
dst[i][j] = (src[i][j - 1] + src[i][j + 1] + src[i - 1][j] + src[i + 1][j]) / 4;
性能测试方法
这里利用C标准库中的clock()函数进行测算。
void testfunc(void (*flatten)()) {
clock_t t1 = clock();
int t = T;
while(t--) {
flatten();
}
clock_t t2 = clock();
printf("time cost: %d(ms)\n",(t2 - t1) * 1000 / CLOCKS_PER_SEC);//保证各平台的一致性
}
代码中,T为测试组数,默认为100;flatten为函数指针,指向平滑函数的不同版本。
原始版本
#define HEIGHT (1080)
#define WIDTH (1920)
typedef long img_size;
img_size src[HEIGHT][WIDTH], dst[HEIGHT][WIDTH];
void flatten1() {
int i, j;
for(i = 1; i < HEIGHT - 1; i++) {
for(j = 1; j < WIDTH - 1; j++) {
dst[i][j] = (src[i][j - 1] + src[i][j + 1] + src[i - 1][j] + src[i + 1][j]) / 4;
}
}
}
由于边界不是程序性能的瓶颈,写起来也很麻烦,直接省略了。
Cache优化
先用CPU-Z看一下L1 Cache的参数:
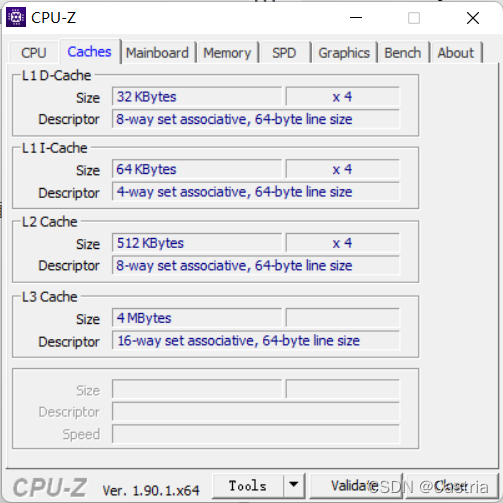
可以看到L1 D-Cache是8路相连的,每行64byte,每组正好可以存下一个8*8的矩阵(以long在linux 64位下为8字节计算)。因此取块大小为8*8,进行测试:
void flatten2() {
//gcc不加register可能会把某些变量放到栈里,加上可以把一些常用变量放到寄存器中,加快读写
register int i0, j0, i, j;
int K = 8;
//枚举每个8*8的小块
for(i0 = 1; i0 < HEIGHT - 1; i0 += K) {
for(j0 = 1; j0 < WIDTH - 1; j0 += K) {
//minn即min
//boundi,boundj即块内的每个元素
register int boundi = minn(HEIGHT - 1, i0 + K);
register int boundj = minn(WIDTH - 1, j0 + K);
for(i = i0; i < boundi; i++) {
for(j = j0; j < boundj; j++) {
dst[i][j] = (src[i][j - 1] + src[i][j + 1] + src[i - 1][j] + src[i + 1][j]) / 4;
}
}
}
}
}
//...
int main() {
testfunc(flatten1);
testfunc(flatten2);
return 0;
}
测试结果:
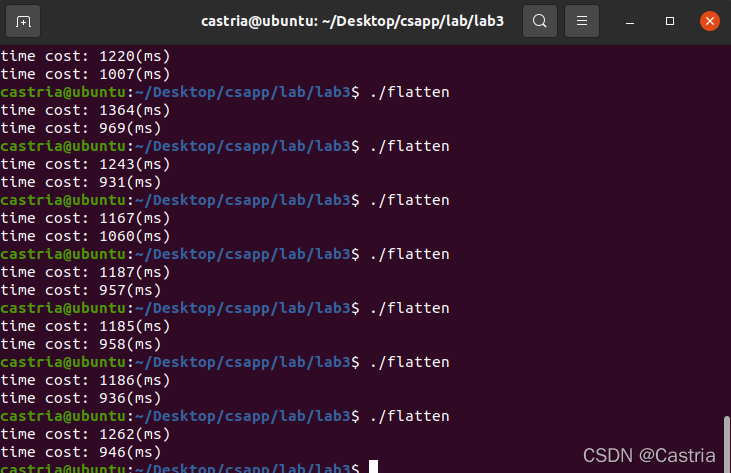
可以看到有很明显的加速。可以尝试将块放大成16*16:
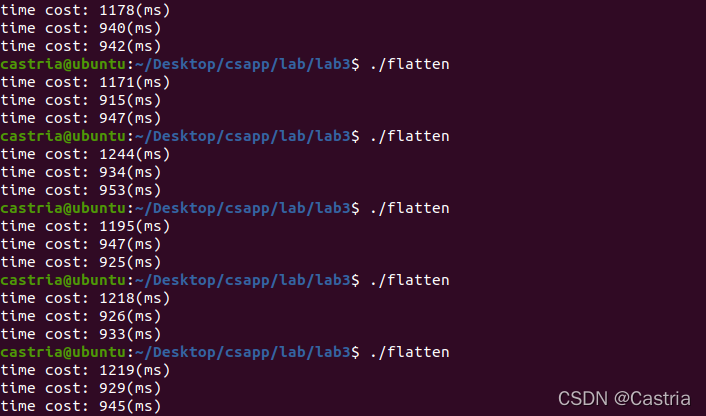
发现加速效果不大甚至起到反作用。
CPU优化
可以采用万能的循环展开:
void flatten2_1() {
register int i0, j0, i, j;
int K = 8;
for(i0 = 1; i0 < HEIGHT - 1; i0 += K) {
for(j0 = 1; j0 < WIDTH - 1; j0 += K) {
register int boundi = minn(HEIGHT - 1, i0 + K);
register int boundj = minn(WIDTH - 1, j0 + K);
for(i = i0; i < boundi; i++) {
for(j = j0; j < boundj - 3; j += 4) {
dst[i][j] = (src[i][j - 1] + src[i][j + 1] + src[i - 1][j] + src[i + 1][j]) / 4;
dst[i][j + 1] = (src[i][j] + src[i][j + 2] + src[i - 1][j + 1] + src[i + 1][j + 1]) / 4;
dst[i][j + 2] = (src[i][j + 1] + src[i][j + 3] + src[i - 1][j + 2] + src[i + 1][j + 2]) / 4;
dst[i][j + 3] = (src[i][j + 2] + src[i][j + 4] + src[i - 1][j + 3] + src[i + 1][j + 3]) / 4;
}
for(; j < boundj; j++) {
dst[i][j] = (src[i][j - 1] + src[i][j + 1] + src[i - 1][j] + src[i + 1][j]) / 4;
}
}
}
}
}
这里做展开因子为4的循环展开。
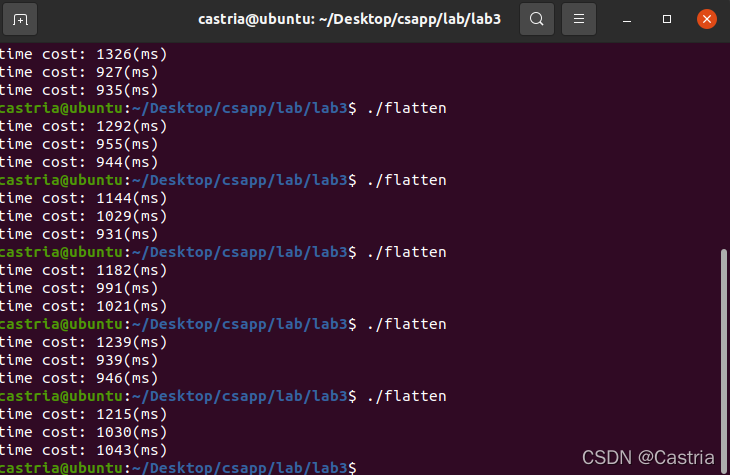
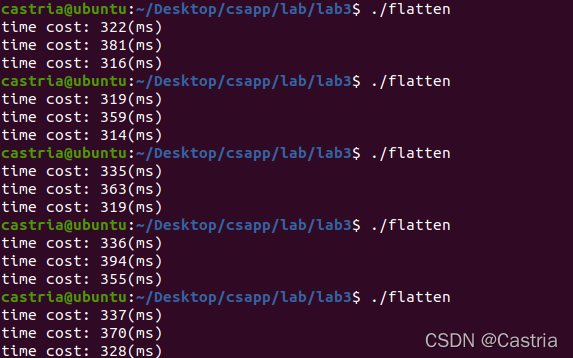
优化效果不是很明显,正常来分析的话,单个循环内有14次内存读(16个数中有2个是重复的),12次加法,CPU已经很难调出更多的资源了。即使在-O2优化下,优化也不是很明显,但是比仅有Cache优化的还是快了一点,我们保留这个优化。
注:-O2优化:在程序前加一行
#pragma GCC optimize(2)
多进程优化
可以尝试利用fork()把一部分独立工作交给子进程做。在本程序中,我们选择将矩阵的上半部分交给子进程:
void flatten3() {
register int i0, j0, i, j;
int K = 8;
int pid = fork();
if(pid == 0) {
for(i0 = 1; i0 < HEIGHT / 2; i0 += K) {
for(j0 = 1; j0 < WIDTH - 1; j0 += K) {
register int boundi = minn(HEIGHT / 2, i0 + K);
register int boundj = minn(WIDTH - 1, j0 + K);
for(i = i0; i < boundi; i++) {
for(j = j0; j < boundj; j++) {
dst[i][j] = (src[i][j - 1] + src[i][j + 1] + src[i - 1][j] + src[i + 1][j]) / 4;
}
}
}
}
exit(0);
}
else {
for(i0 = HEIGHT / 2; i0 < HEIGHT - 1; i0 += K) {
for(j0 = 1; j0 < WIDTH - 1; j0 += K) {
register int boundi = minn(HEIGHT - 1, i0 + K);
register int boundj = minn(WIDTH - 1, j0 + K);
for(i = i0; i < boundi; i++) {
for(j = j0; j < boundj; j++) {
dst[i][j] = (src[i][j - 1] + src[i][j + 1] + src[i - 1][j] + src[i + 1][j]) / 4;
}
}
}
}
}
}
测试结果(-O2):

用完fork()之后比不加还慢了一倍。在《操作系统概念》一书中提到,“进程创建所需的内存和资源分配非常昂贵,由于线程能够共共享它们所属进程的资源,所以创建和切换线程更加经济”(中文第九版,P113)。所以我们可以尝试多线程:
多线程优化
《操作系统概念》P118中也给出了多线程的示例程序。我们在linux下使用pthread.h库(编译时需要加-pthread选项):
gcc flatten.c -o flatten -pthread
初始化一个线程的基本方法如下:
pthread_t tid;//线程标识符
pthread_attr_t attr;//线程属性
pthread_attr_init(&attr);//设置线程缺省属性
pthread_create(&tid, &attr, runner, arg);
//runner为线程所调用的函数,原型为void *runner(void *param)
//arg为void型指针,传递参数用
pthread_join(tid, NULL);//等待线程完成
为了给线程传递(一个或多个)参数,需要定义一个结构体,把它的首地址传给pthread_create的第四个参数,这样线程就可以在其函数中访问到结构体的各个成员变量:
typedef struct para{
int l_bound;
int r_bound;
}p;
其中l_bound为该线程负责的起始行,r_bound为该线程负责的终止行。
以下为多线程的代码:
//传递每个线程参数用的结构体
typedef struct para{
int l_bound;
int r_bound;
}p;
void *sum(void *param) {
struct para *p = (struct para*)param;
int l_bound = p->l_bound, r_bound = p->r_bound;
register int i0, j0, i, j;
int K = 8;
for(i0 = l_bound; i0 < r_bound; i0 += K) {
for(j0 = 1; j0 < WIDTH - 1; j0 += K) {
register int boundi = minn(r_bound, i0 + K);
register int boundj = minn(WIDTH - 1, j0 + K);
for(i = i0; i < boundi; i++) {
for(j = j0; j < boundj - 3; j += 4) {
dst[i][j] = (src[i][j - 1] + src[i][j + 1] + src[i - 1][j] + src[i + 1][j]) / 4;
dst[i][j + 1] = (src[i][j] + src[i][j + 2] + src[i - 1][j + 1] + src[i + 1][j + 1]) / 4;
dst[i][j + 2] = (src[i][j + 1] + src[i][j + 3] + src[i - 1][j + 2] + src[i + 1][j + 2]) / 4;
dst[i][j + 3] = (src[i][j + 2] + src[i][j + 4] + src[i - 1][j + 3] + src[i + 1][j + 3]) / 4;
}
for(; j < boundj; j++) {
dst[i][j] = (src[i][j - 1] + src[i][j + 1] + src[i - 1][j] + src[i + 1][j]) / 4;
}
}
}
}
}
#define THREAD (2)
void flatten4() {
pthread_t tid[THREAD];
pthread_attr_t attr[THREAD];
struct para p[THREAD];
int i;
for(i = 0; i < THREAD; i++) {
//第i个线程负责第i个块,用max和min保证不越界
p[i].l_bound = maxn(1, i * HEIGHT / THREAD);
p[i].r_bound = minn(HEIGHT - 1, (i + 1) * HEIGHT / THREAD);
pthread_attr_init(&attr[i]);
pthread_create(&tid[i], &attr[i], sum, (void*)&p[i]);
}
for(i = 0; i < THREAD; i++) {
pthread_join(tid[i], NULL);
}
}
测试结果:
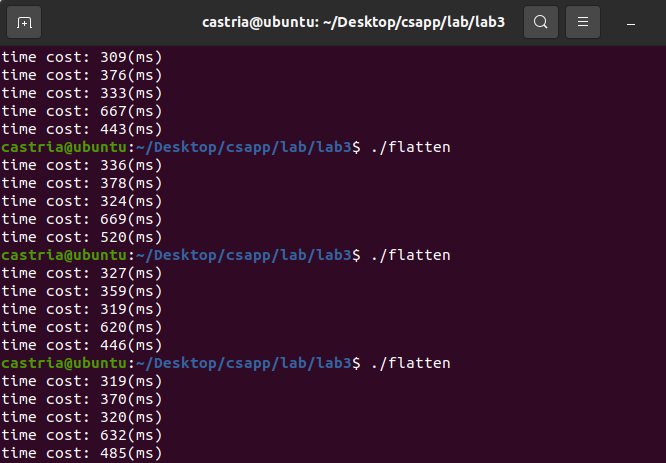
很遗憾,由于虚拟机资源的限制,虽然多线程比多进程快,但程序还是比不采用多进程慢。但是,我们可以在宿主机上测试(windows,采用pthread的windows兼容版本,线程数为8):
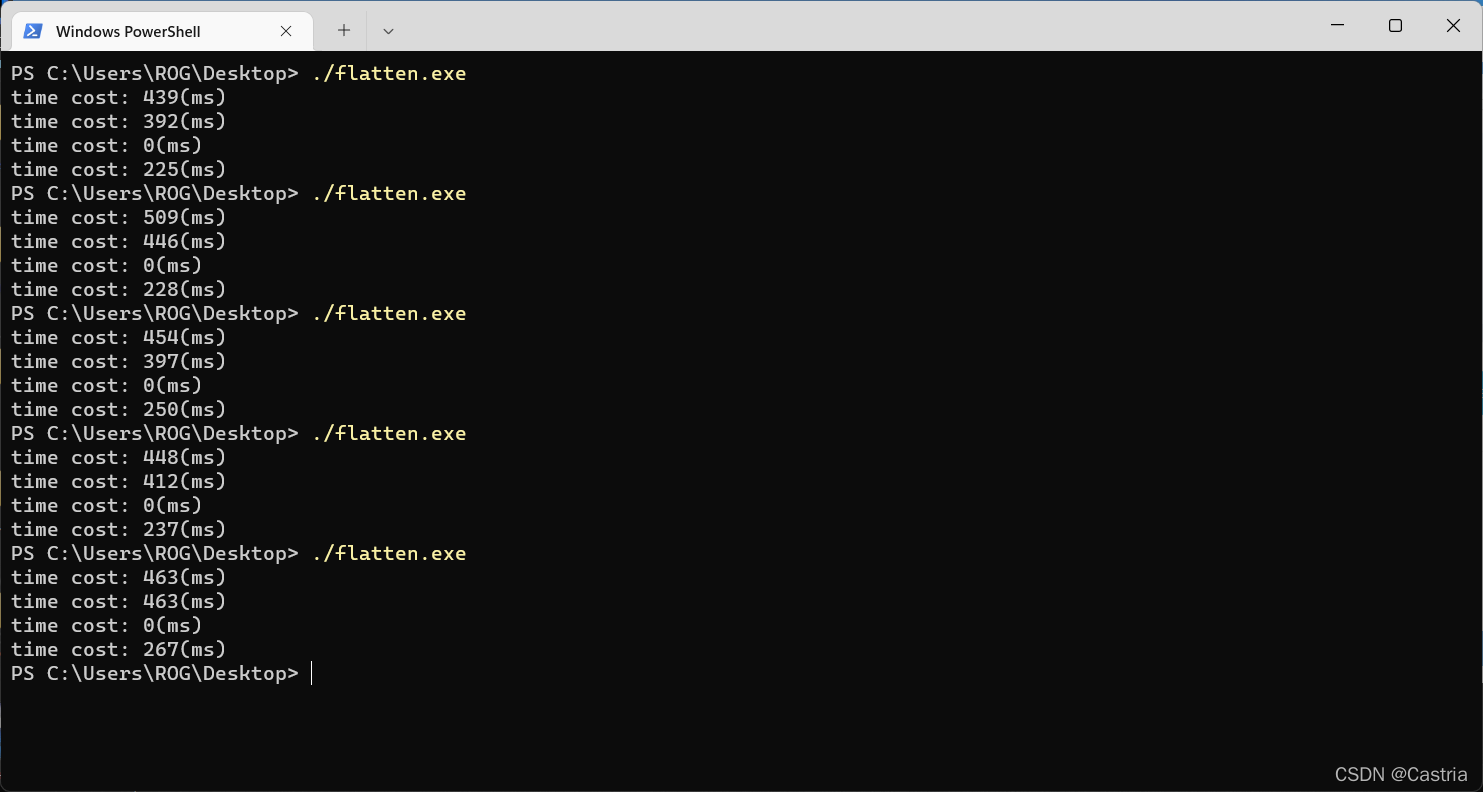
由于windows上没有fork,把多进程的版本注释掉了。
最终程序加速了70%~80%(采用分块,循环展开,-O2,多线程)。
最后补充一下windows下多线程的API:
typedef struct para{
int l_bound;
int r_bound;
}p;
//LPVOID即void*
DWORD WINAPI sum(LPVOID Param) {
register int i0, j0, i, j;
struct para *p = (struct para*)Param;
int l_bound = p->l_bound, r_bound = p->r_bound;
int K = 8;
for(i0 = l_bound; i0 < r_bound; i0 += K) {
for(j0 = 1; j0 < WIDTH - 1; j0 += K) {
register int boundi = min(r_bound, i0 + K);
register int boundj = min(WIDTH - 1, j0 + K);
for(i = i0; i < boundi; i++) {
for(j = j0; j < boundj - 3; j += 4) {
dst[i][j] = (src[i][j - 1] + src[i][j + 1] + src[i - 1][j] + src[i + 1][j]) / 4;
dst[i][j + 1] = (src[i][j] + src[i][j + 2] + src[i - 1][j + 1] + src[i + 1][j + 1]) / 4;
dst[i][j + 2] = (src[i][j + 1] + src[i][j + 3] + src[i - 1][j + 2] + src[i + 1][j + 2]) / 4;
dst[i][j + 3] = (src[i][j + 2] + src[i][j + 4] + src[i - 1][j + 3] + src[i + 1][j + 3]) / 4;
}
for(; j < boundj; j++) {
dst[i][j] = (src[i][j - 1] + src[i][j + 1] + src[i - 1][j] + src[i + 1][j]) / 4;
}
}
}
}
}
#define THREAD (8)
void flatten4() {
DWORD ThreadId[THREAD];
HANDLE ThreadHandle[THREAD];
struct para p[THREAD];
int i;
for(i = 0; i < THREAD; i++) {
p[i].l_bound = maxn(1, i * HEIGHT / THREAD);
p[i].r_bound = minn(HEIGHT - 1, (i + 1) * HEIGHT / THREAD);
//第三个参数为线程函数;第四个参数为给线程传递的参数
ThreadHandle[i] = CreateThread(NULL,0,sum, (LPVOID)&p[i],0,&ThreadId[i]);
}
//第一个参数为等待线程数
WaitForMultipleObjects(THREAD, ThreadHandle, TRUE, INFINITE);
}

同样是8个线程,要比pthread.h快一些。
完整代码
#include<time.h>
#include<stdio.h>
#include<unistd.h>
#include<pthread.h>
#pragma GCC optimize(2)
#define HEIGHT (1080)
#define WIDTH (1920)
int minn(int a, int b) {
return (a < b)? a: b;
}
int maxn(int a, int b) {
return (a > b)? a: b;
}
const int T = 100;
typedef long img_size;
img_size src[HEIGHT][WIDTH], dst[HEIGHT][WIDTH];
void flatten1() {
int i, j;
for(i = 1; i < HEIGHT - 1; i++) {
for(j = 1; j < WIDTH - 1; j++) {
dst[i][j] = (src[i][j - 1] + src[i][j + 1] + src[i - 1][j] + src[i + 1][j]) / 4;
}
}
}
void flatten2() {
register int i0, j0, i, j;
int K = 8;
for(i0 = 1; i0 < HEIGHT - 1; i0 += K) {
for(j0 = 1; j0 < WIDTH - 1; j0 += K) {
register int boundi = minn(HEIGHT - 1, i0 + K);
register int boundj = minn(WIDTH - 1, j0 + K);
for(i = i0; i < boundi; i++) {
for(j = j0; j < boundj; j++) {
dst[i][j] = (src[i][j - 1] + src[i][j + 1] + src[i - 1][j] + src[i + 1][j]) / 4;
}
}
}
}
}
void flatten2_1() {
register int i0, j0, i, j;
int K = 8;
for(i0 = 1; i0 < HEIGHT - 1; i0 += K) {
for(j0 = 1; j0 < WIDTH - 1; j0 += K) {
register int boundi = minn(HEIGHT - 1, i0 + K);
register int boundj = minn(WIDTH - 1, j0 + K);
for(i = i0; i < boundi; i++) {
for(j = j0; j < boundj - 3; j += 4) {
dst[i][j] = (src[i][j - 1] + src[i][j + 1] + src[i - 1][j] + src[i + 1][j]) / 4;
dst[i][j + 1] = (src[i][j] + src[i][j + 2] + src[i - 1][j + 1] + src[i + 1][j + 1]) / 4;
dst[i][j + 2] = (src[i][j + 1] + src[i][j + 3] + src[i - 1][j + 2] + src[i + 1][j + 2]) / 4;
dst[i][j + 3] = (src[i][j + 2] + src[i][j + 4] + src[i - 1][j + 3] + src[i + 1][j + 3]) / 4;
}
for(; j < boundj; j++) {
dst[i][j] = (src[i][j - 1] + src[i][j + 1] + src[i - 1][j] + src[i + 1][j]) / 4;
}
}
}
}
}
void flatten3() {
register int i0, j0, i, j;
int K = 8;
int pid = fork();
if(pid == 0) {
for(i0 = 1; i0 < HEIGHT / 2; i0 += K) {
for(j0 = 1; j0 < WIDTH - 1; j0 += K) {
register int boundi = minn(HEIGHT - 1, i0 + K);
register int boundj = minn(WIDTH - 1, j0 + K);
for(i = i0; i < boundi; i++) {
for(j = j0; j < boundj; j++) {
dst[i][j] = (src[i][j - 1] + src[i][j + 1] + src[i - 1][j] + src[i + 1][j]) / 4;
}
}
}
}
exit(0);
}
else {
for(i0 = HEIGHT / 2; i0 < HEIGHT - 1; i0 += K) {
for(j0 = 1; j0 < WIDTH - 1; j0 += K) {
register int boundi = minn(HEIGHT - 1, i0 + K);
register int boundj = minn(WIDTH - 1, j0 + K);
for(i = i0; i < boundi; i++) {
for(j = j0; j < boundj; j++) {
dst[i][j] = (src[i][j - 1] + src[i][j + 1] + src[i - 1][j] + src[i + 1][j]) / 4;
}
}
}
}
}
}
typedef struct para{
int l_bound;
int r_bound;
}p;
void *sum(void *param) {
struct para *p = (struct para*)param;
int l_bound = p->l_bound, r_bound = p->r_bound;
register int i0, j0, i, j;
int K1 = 8;
int K2 = 8;
for(i0 = l_bound; i0 < r_bound; i0 += K1) {
for(j0 = 1; j0 < WIDTH - 1; j0 += K2) {
register int boundi = minn(r_bound, i0 + K1);
register int boundj = minn(WIDTH - 1, j0 + K2);
for(i = i0; i < boundi; i++) {
for(j = j0; j < boundj - 3; j += 4) {
dst[i][j] = (src[i][j - 1] + src[i][j + 1] + src[i - 1][j] + src[i + 1][j]) / 4;
dst[i][j + 1] = (src[i][j] + src[i][j + 2] + src[i - 1][j + 1] + src[i + 1][j + 1]) / 4;
dst[i][j + 2] = (src[i][j + 1] + src[i][j + 3] + src[i - 1][j + 2] + src[i + 1][j + 2]) / 4;
dst[i][j + 3] = (src[i][j + 2] + src[i][j + 4] + src[i - 1][j + 3] + src[i + 1][j + 3]) / 4;
}
for(; j < boundj; j++) {
dst[i][j] = (src[i][j - 1] + src[i][j + 1] + src[i - 1][j] + src[i + 1][j]) / 4;
}
}
}
}
}
#define THREAD (8)
void flatten4() {
pthread_t tid[THREAD];
pthread_attr_t attr[THREAD];
struct para p[THREAD];
int i;
for(i = 0; i < THREAD; i++) {
p[i].l_bound = maxn(1, i * HEIGHT / THREAD);
p[i].r_bound = minn(HEIGHT - 1, (i + 1) * HEIGHT / THREAD);
pthread_attr_init(&attr[i]);
pthread_create(&tid[i], &attr[i], sum, (void*)&p[i]);
}
for(i = 0; i < THREAD; i++) {
pthread_join(tid[i], NULL);
}
}
void testfunc(void (*flatten)()) {
clock_t t1 = clock();
int t = T;
while(t--) {
flatten();
}
clock_t t2 = clock();
printf("time cost: %d(ms)\n",(t2 - t1) * 1000 / CLOCKS_PER_SEC);
}
int main() {
testfunc(flatten1);
testfunc(flatten2);
testfunc(flatten2_1);
testfunc(flatten3);
testfunc(flatten4);
return 0;
}
若文章有内容错误或代码bug,还请指出。