目录
一,常用查询
1,order by按关键字排序
使用select语句可以将需要的数据从 mysql数据库中查询出来,如果对查询的结果进行排序,可以使用order by语句来对语句实现排序,并最终将排序后的结果返回给用户,这个语句的排序不光可以针对某一个字段,也可以针对多个字段。
语法
select 字段1,字段2....from 表名 order by 字段1,字段2.......[asc]
#查询结构以升序方式显示,asc可以省略
select 字段1.字段2....from 表名 order by 字段1,字段2........desc
#查询结构以降序的方式显示
- ASC是按照升序进行排序,是默认的排序方式,即ASC可以省略
- select语句中如果没有指定具体的排序方式,则默认按ASC进行排序
- desc是安装降序方式进行排序
- order by 前面也可以使用where子句对查询结果进一步过滤
1.1 升序排序
mysql> select id,nba,age from ky21 order by id asc;
#查询id,nba,age。字段的记录,并且以id进行升序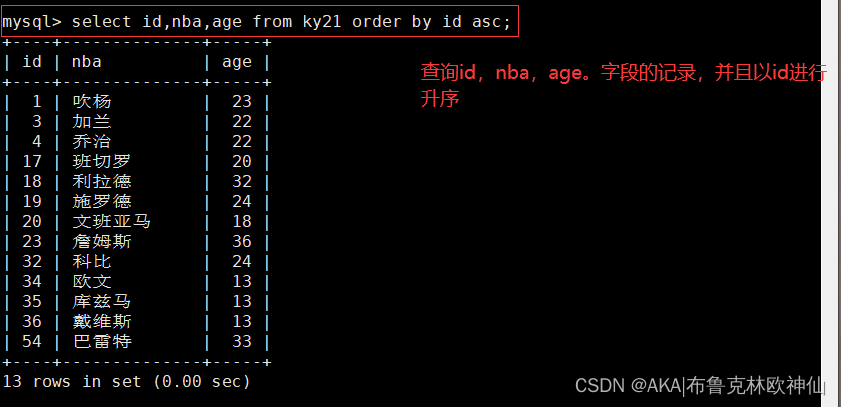
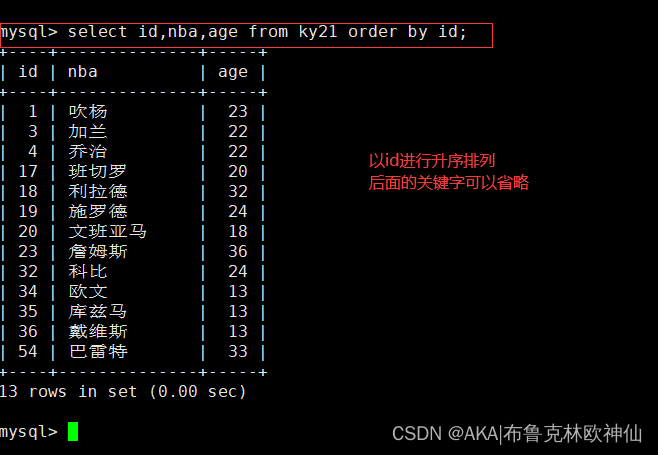
1.2 降序排序
mysql> select id,nba,age from ky21 order by id desc;
查找id,nba,age字段,以id进行降序排序
desc(降序)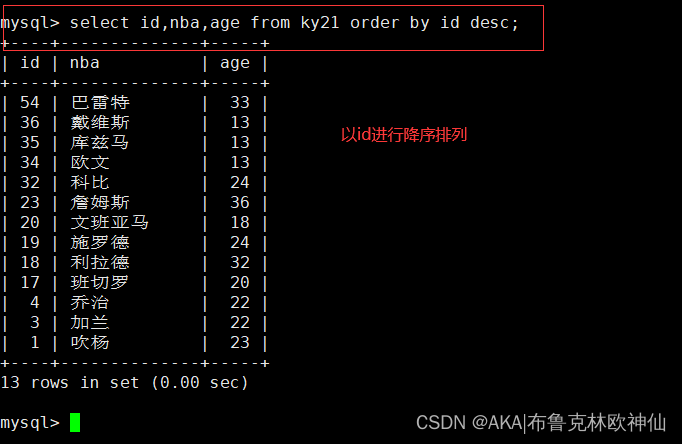
1.3 结合where进行条件过滤再排序
mysql> select id,nba,score,addres from ky21 where addres='洛杉矶' order by score desc;
#查询,id,nab,score,address字段,再进行过滤出address=洛杉矶的字段,在进行score字段进行降序排序
1.4多字段排序
order by 语句也可以使用多个字段来进行排序,当排序的第一个字段相同的记录有多条的情况下,这些多条的记录再安装第二个字段进行排序,order by后面跟多个字段时,字段直接使用英文逗号隔开,优先级是安装优先级顺序而定,但是order by 之后的第一个参数只有在出现相同值的时候,第二个字段才有意义。
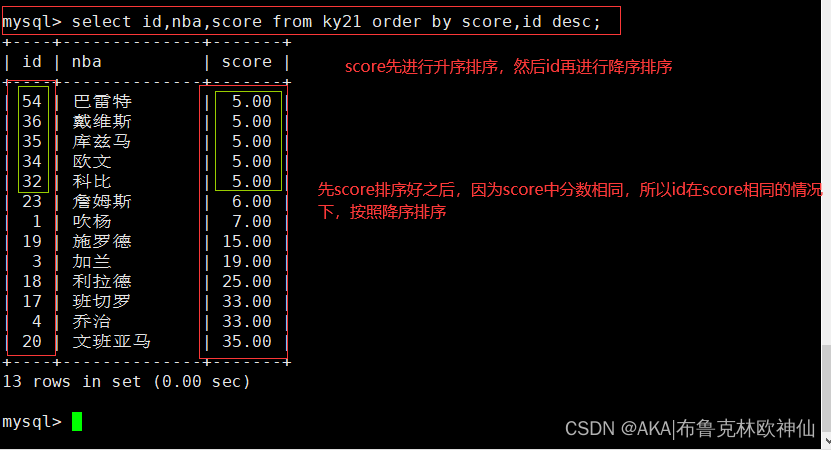
mysql> select id,nba,score from ky21 order by score,id desc;
此处做的实验是先升序排序再降序排序,也可以都降序排序或者都升序排序,这里就不做过多的例子了
2,and和or判断
在大型数据库中,有事查询数据需要数据符合某些特点,“and”和“or” 表示“且”和“或”。
2.1 and和or的使用
mysql> select id,nba,age from ky21 where id>20;
查找id大于20的记录,并且只显示id,age,nba
mysql> select id,nba,age from ky21 where id>10 and id<30;
查找id大于10的记录并且小于30的记录
mysql> select id,nba,age from ky21 where id>1 or id<30;
查找id大于1 或者小于30的记录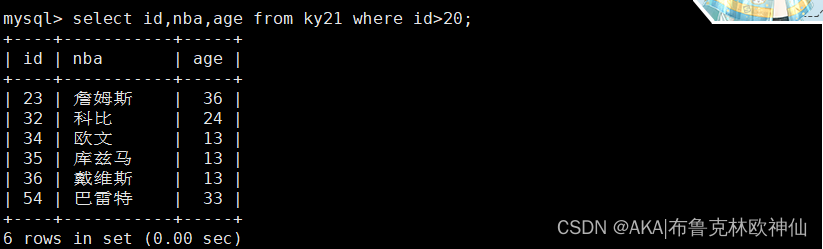

2.2 嵌套,多条件使用
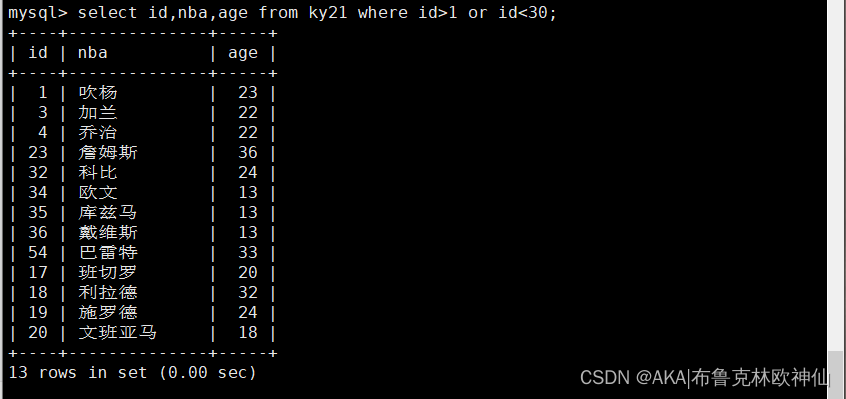
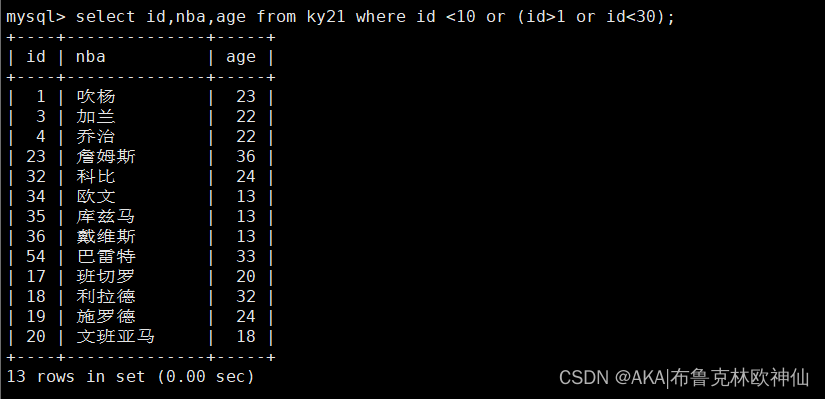
mysql> select id,nba,age from ky21 where id <10 or (id>1 or id<30);
查找id小于10或者大于1和小于30之间的
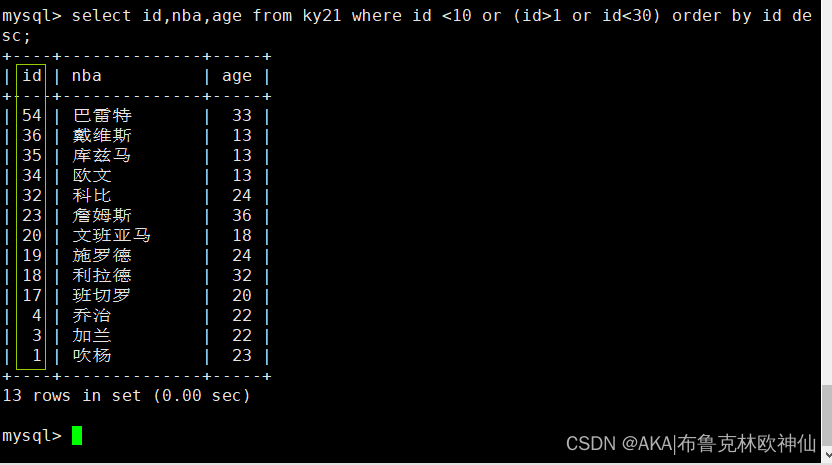
mysql> select id,nba,age from ky21 where id <10 or (id>1 or id<30) order by id desc;
查找id小于10或者大于1和小于30之间的,并且以id进行降序排序
3,distinct 查询不重复记录
select distinct 字段 from 表名;
- distinct 必须放在最开头
- distinct 只能使用需要去重的字段进行操作
- distinct 去重多个字段时,含义是:几个字段同时重复时才能会过滤,会默认按左边第一个字段为依据。
mysql> select distinct age from ky21;
#使用distinct查询不重复记录,(相当于去重)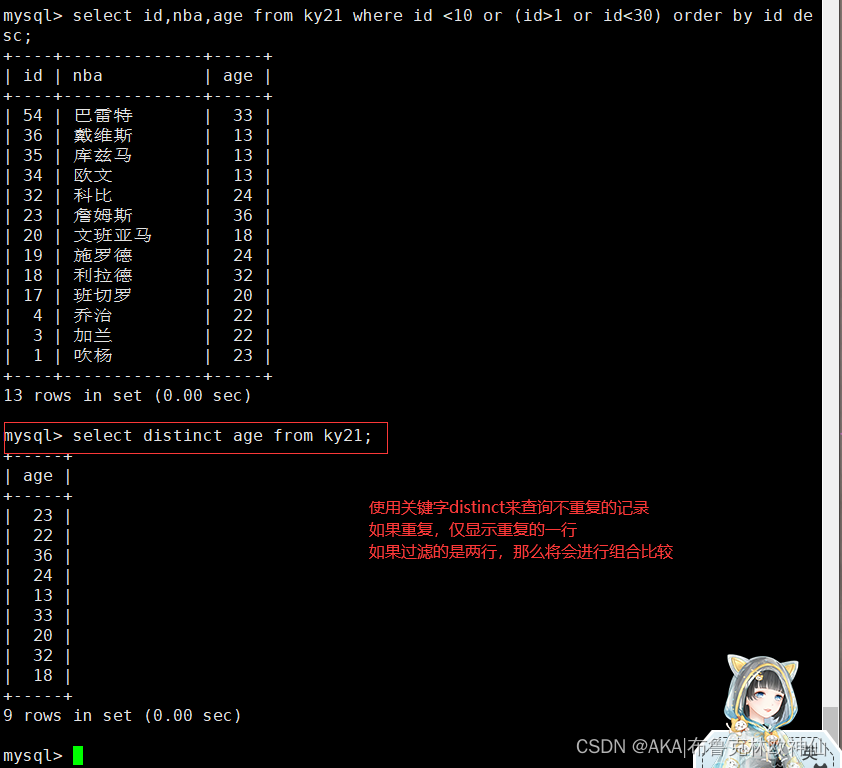
4,group by 对结果进行分组
通过sql查询出来的结果,还可以对其进行分组,使用group by语句来实现,group by通常都是结合集合函数来一起实现的。
常用的聚合函数包括:计数(count)、求和(sum)、求平均数(avg)、最大值(max)、最小值(min),group by 分组的时候可以按一个或多个字段对结果进行分组处理。、
- 对于group by后面的字段的查询结果进行汇总分组,通常结合聚合函数一起使用的
- group by 有一个原则,就是select 后面的所以列中,没有聚合函数的列必须出现在group by的后面
select 字段,聚合函数(字段) from 表名【where 字段 (匹配) 数值】group by 字段名;
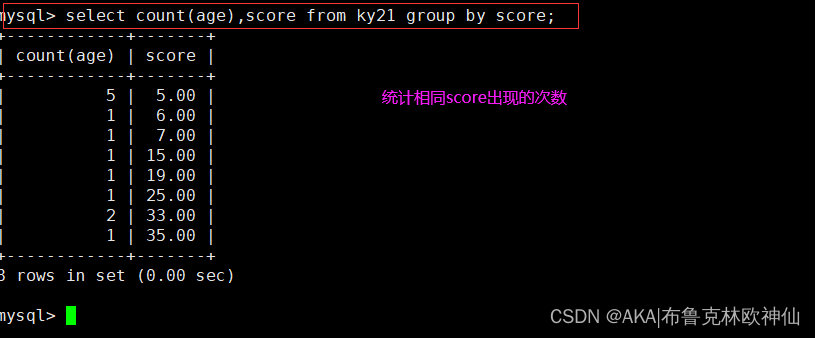
mysql> select count(age),score from ky21 group by score;
#count(age): 记录age字段的数据出现的次数
group by score; 按照score相同的分数进行分组,
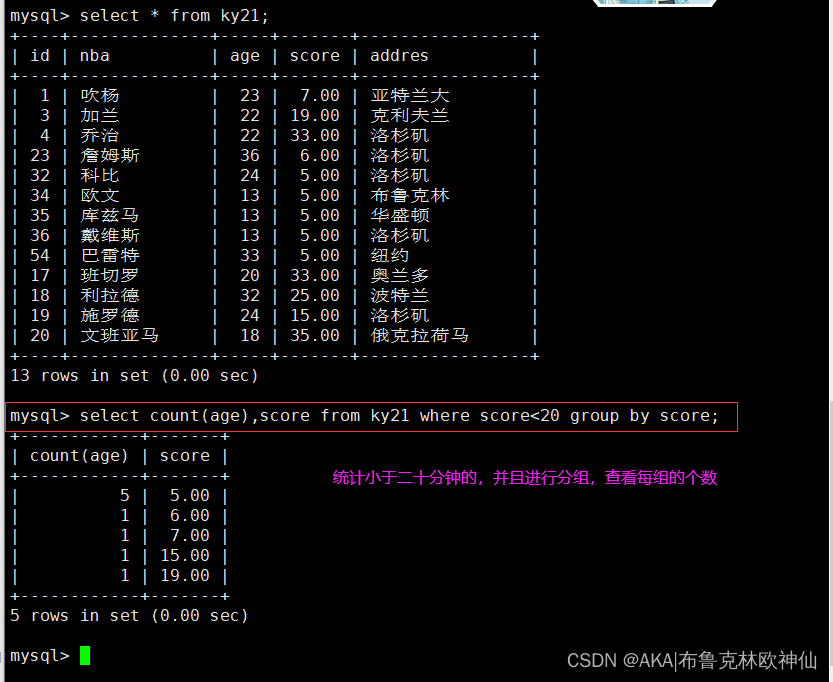
mysql> select count(age),score from ky21 where score<20 group by score;
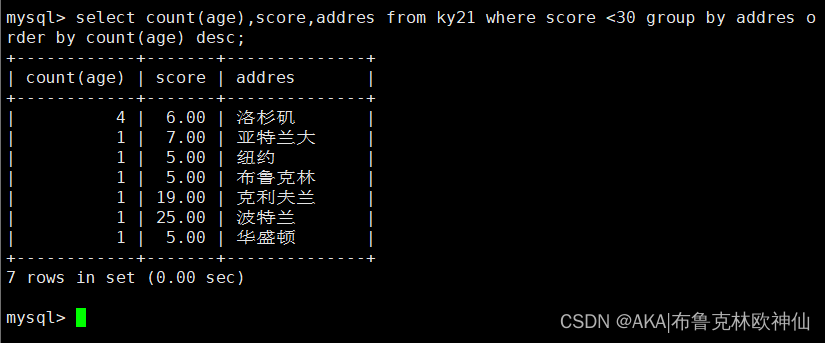
mysql> select count(age),score,addres from ky21 where score <30 group by addres order by count(age) desc;

5,limit限制结果输出条目
limit限制输出的结果
在使用mysql select 语句进行查询时,结果集返回的是所以匹配的记录(行)
,有时候仅需返回第一行或者前几行,这时候就需要用到limit子句
语法:select 字段 from 表名 limint [offset] number
- limit的第一个参数是位置偏移量(可选参数),设置mysql从哪一行开始,如果不设定第一个参数,将会从表中的第一条记录开始显示。第一条偏移量是0,将会从表中的第一条记录开始开始
- 第一条偏移量是0,第二条为1
- offset :为索引下标
- number:为索引下标后的几位
查询所以信息显示的前四行记录
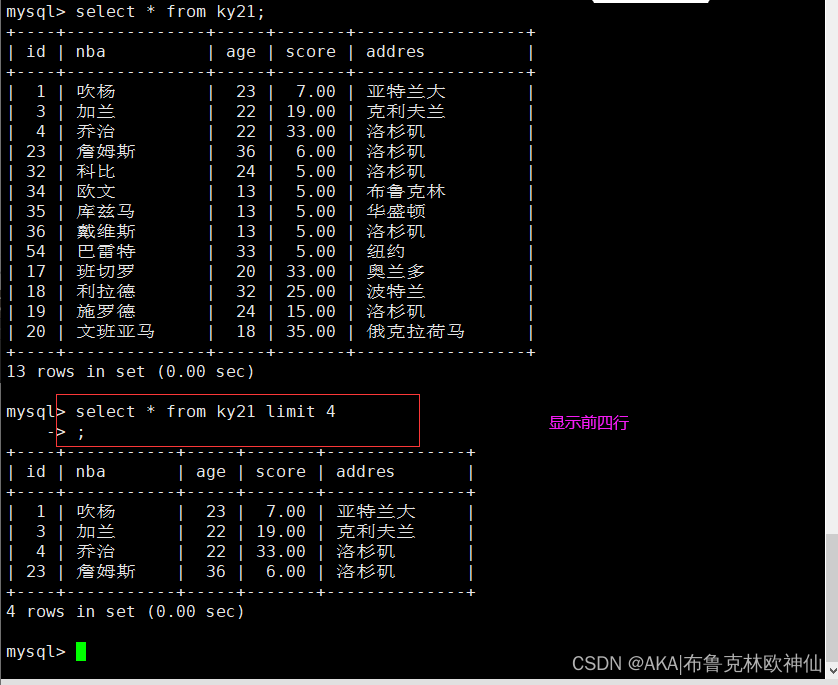
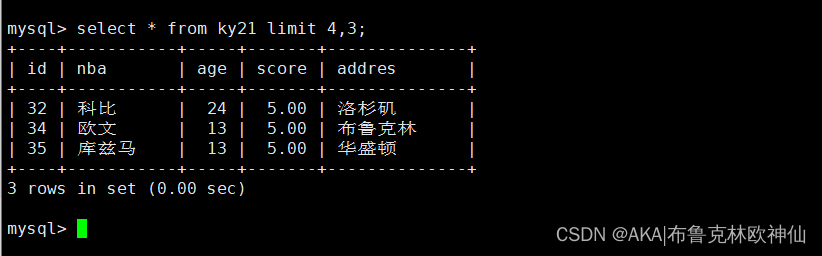
从第四行开始,显示后3行的内容
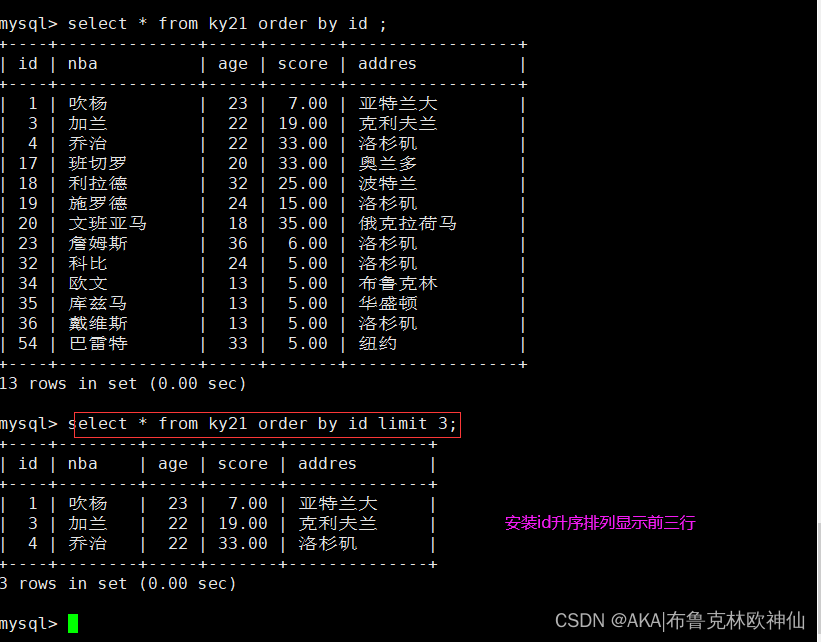
结合order by 来显示按照id的大小升序排列显示前三行
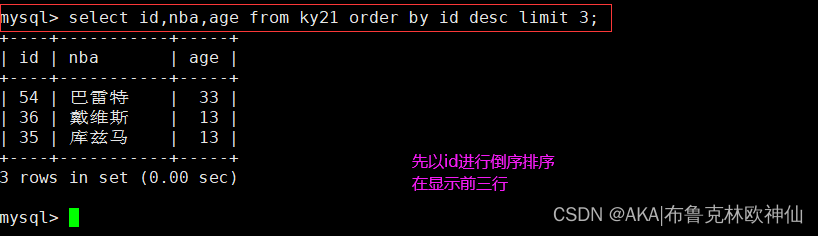
怎么输出最后三行
6,设置别名(alias-as)
当在mysql查询时,当表的名字比较长或者表内的某些字段比较长时,为了方便书写或者多次使用相同的表,可以给字段列或者表设置别名,使用的时候直接使用别名,简单明了,增强可读性
语法:对应列的别名:select 字段 as 字段别名 表名:
:对于表的别名:select 别名.字段 from 表名 as 别名;
使用场景
- 对复杂的表进行查询的时候,别名可以缩短查询语句的长度
- 多表相连查询的时候(通俗易懂,减短sql语句)
6.1列别名设置示例:
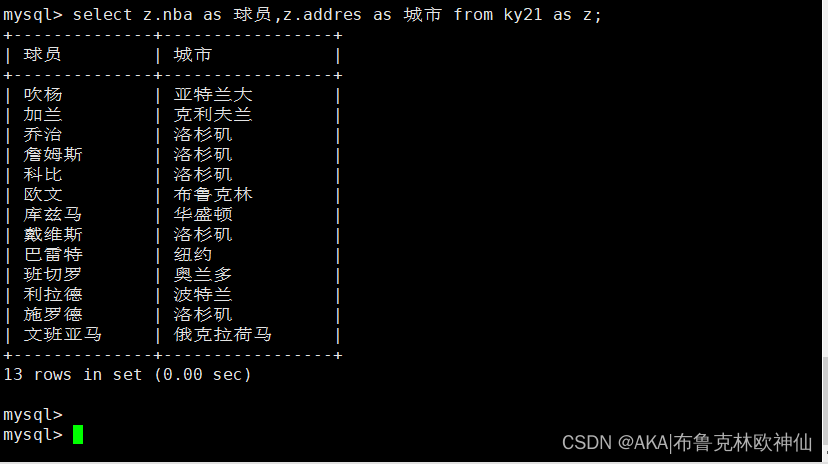
mysql> select nba as 球员,addres as 城市 from ky21;

表,别名设置示例
6.2 查询表的记录数量,以别名显示
mysql> select addres,count(*)as 城市 from ky21 group by addres;
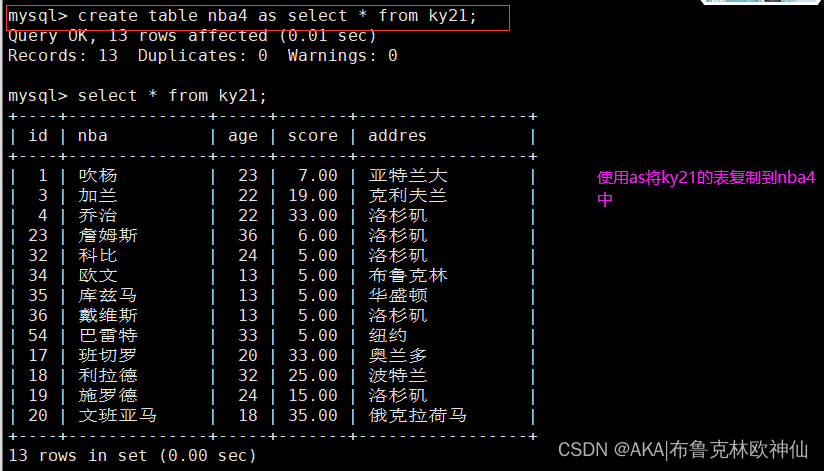
6.3 利用as,将查询的数据导入到另一个表内
此处as起到的作用
- 创建了一个新表,并定义表结构,插入表数据
- 但是“约束”没有被完成复制过来,但是如果原表设置了主键,那么附表的:default字段会默认设置一个0
- as可以省略
mysql> create table nba4 as select * from ky21;
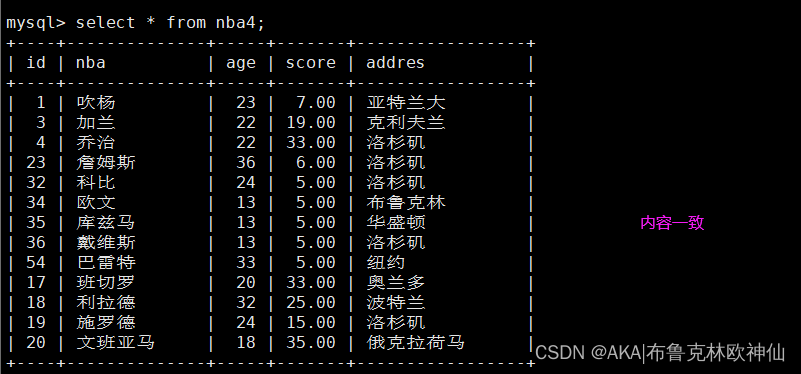
mysql> select * from nba4;
mysql> select * from ky21;
7,通配符查询
- 通配符主要用于替换字符串的部分字符,通过部分字符的匹配将相关结构查询出来
- 通常通配符都是跟like一起使用的,并协同where
- 子句共同来完成查询任务,常用的通配符有两个,分别是:“%” 和 “_”。
%:百分号表示0个、1个、或多个字符
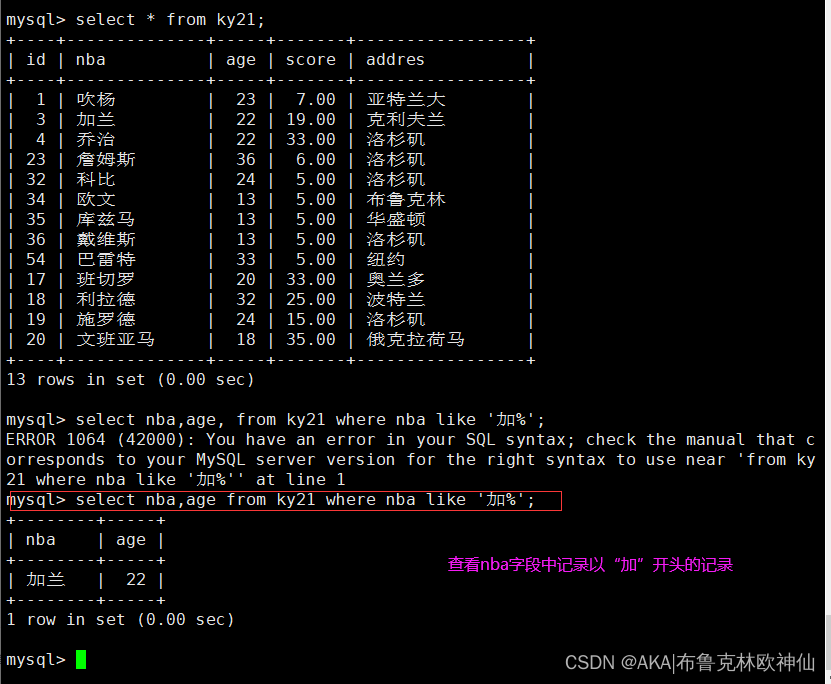
_:下划线表示单个字符mysql> select nba,age from ky21 where nba like '加%';
#查询名称以“加”开头开头的记录
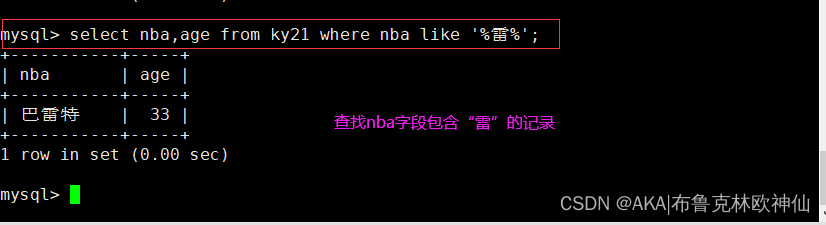
mysql> select nba,age from ky21 where nba like '%雷%';
#查询包含字符“雷”的nba的记录
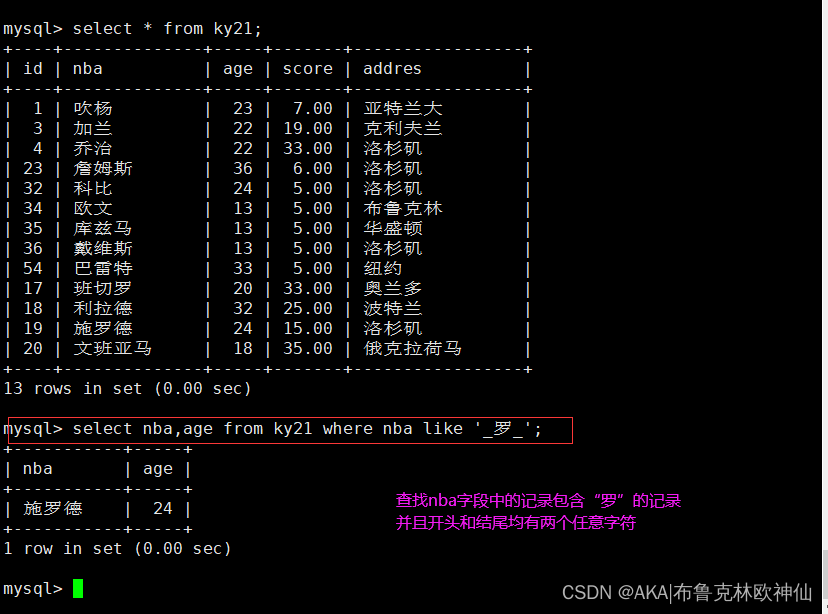
mysql> select nba,age from ky21 where nba like '_罗_';
二,子查询
子查询也被称为内查询或者嵌套查询,是指在一个查询语句里面还嵌套者另一个查询语句
子查询语句是先于主查询语句被执行,且结果作为外层的条件返回给主查询进行下一步查询
在查询中可以与主语句相同的表,也可以是不同的表
1,select 查询
子语句可以与主语句所查询的表相同,也可以使不同的表
语法格式
select 字段1,字段2 from 表名1 where 字段 in (select 字段 from 表名 where 条件);
- 主语句:select 字段1,字段2 from 表名1 where 字段;
- in:将主表和字表关联/连接的语法
- 子语句(集合):select 字段 from 表名 where 条件;
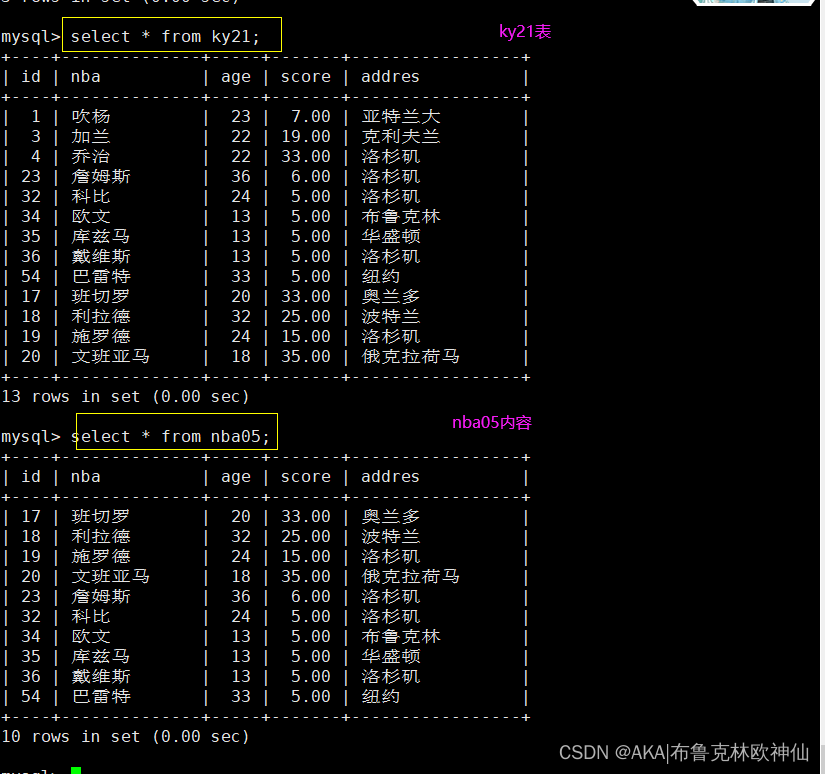
1.1 相同表查询
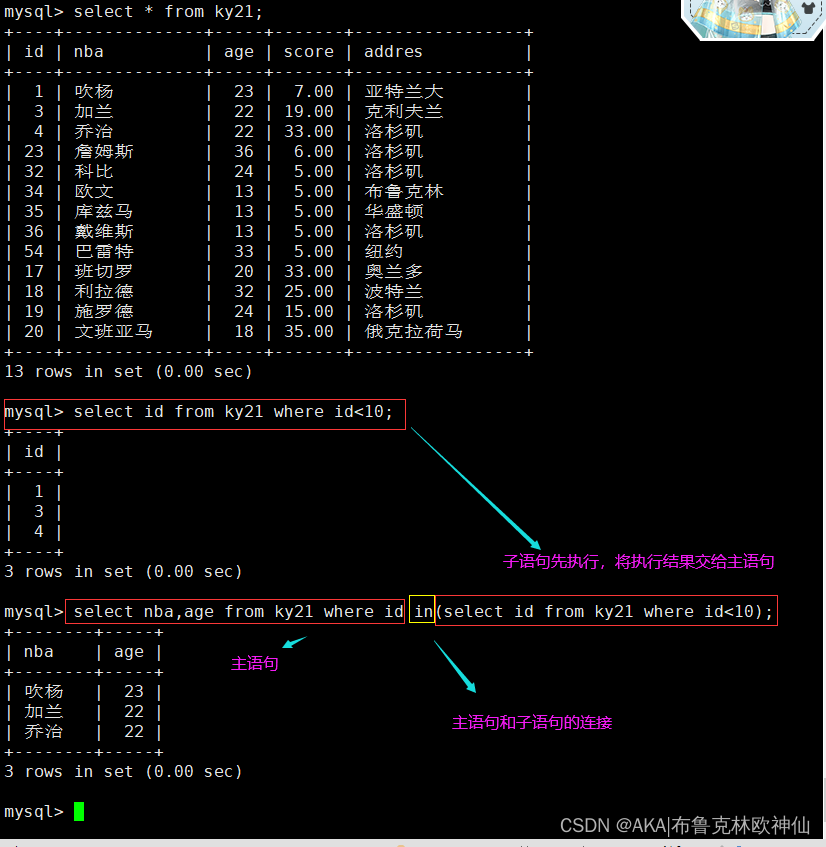
mysql> select nba,age from ky21 where id in(select id from ky21 where id<10);
1.2 多表查询
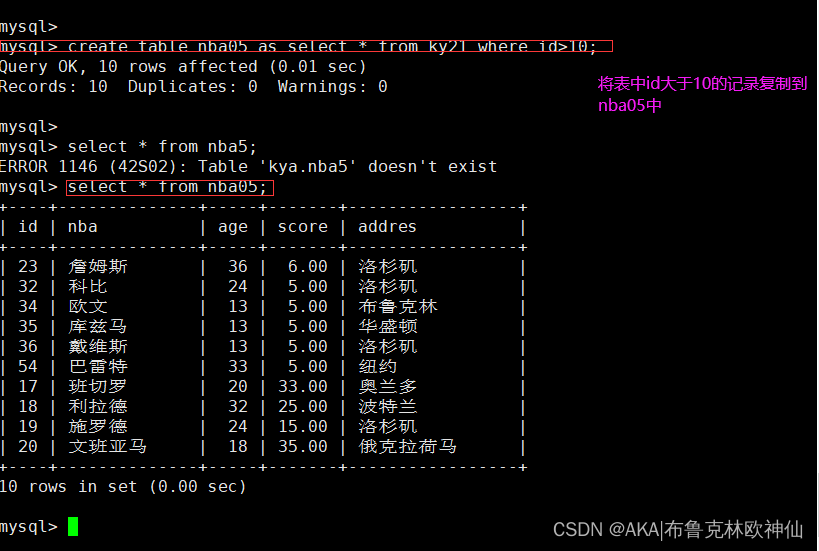
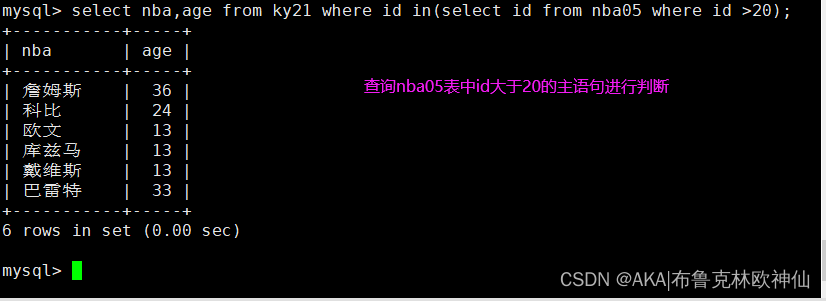
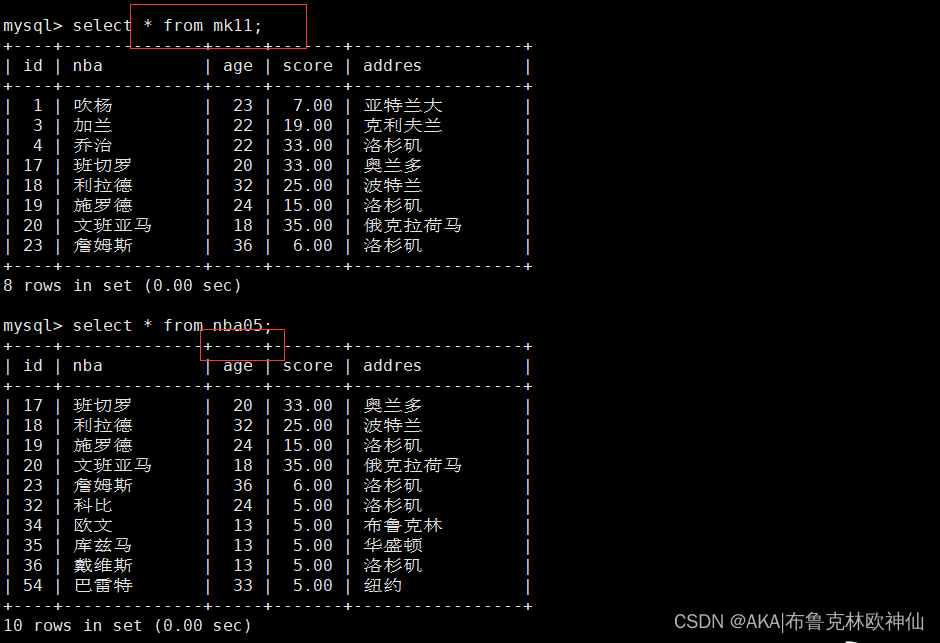
mysql> select nba,age from ky21 where id in(select id from nba05 where id >20);
1.3 not取反,将子查询的结果,进行取反操作
mysql> select nba,age from ky21 where id not in(select id from nba05 where id >20););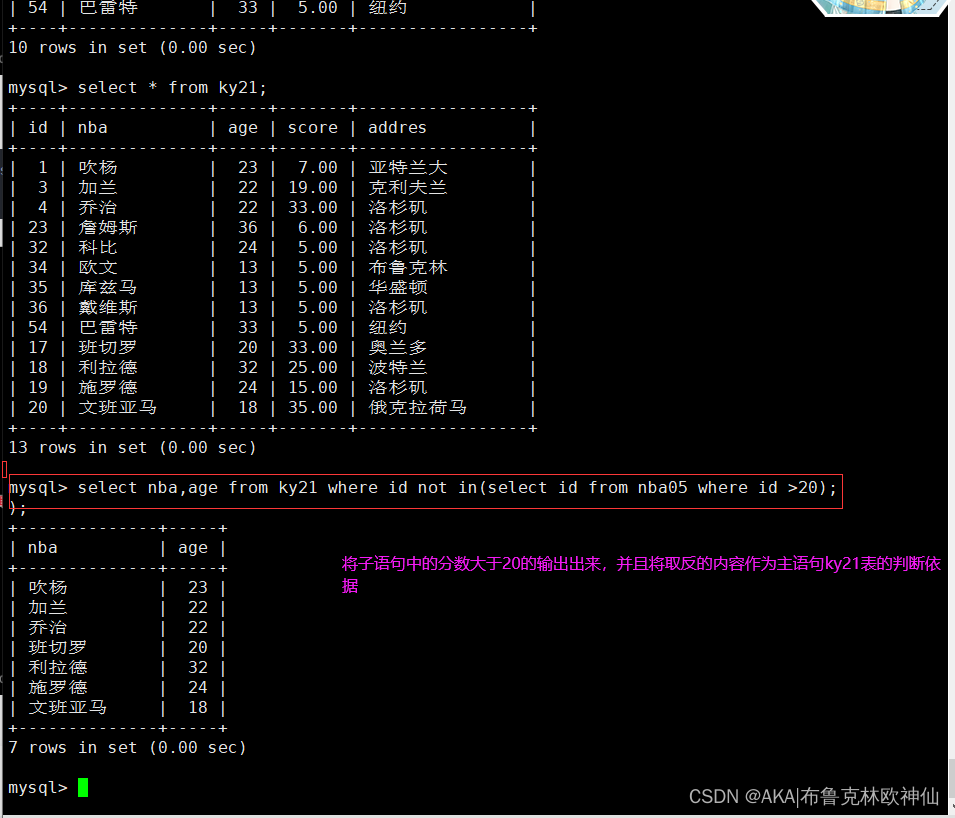
1.4 结合as别名进行子查询
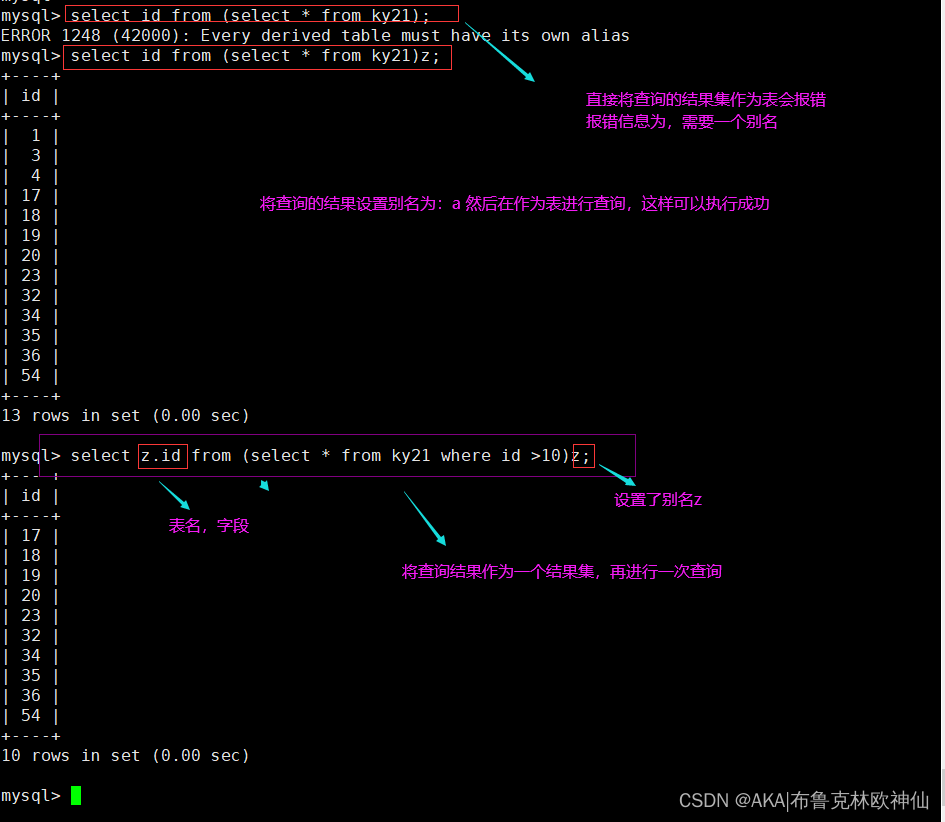
当我们将一个查询的结果集作为一个新表再进行查询时。直接使用会进行报错,我们需要使用到别名
- 如果直接使用select id from (select id,name from info); 此时会报错,因为select * from 表名 ,此格式为标准格式,而以上的查询的语句, “表名”的位置其实是一个完整结果集,mysql并不能直接识别,而此时给与结果集设置一个别名,
- 所以可以使用select a.id from (select id,name from info) a;
select id from (select * from ky21;
#此条报错
select id from (select * from ky21)a;
#设置了别名,然后再作为表
select a.id from (select * from ky21 where id >80)a;
#将查询结果集设置别名,然后将结果集作为表进行查询,
2,insert 插入
子查询还可以用在insert语句中,子查询的结果集可以通过insert语句插入到其它表中
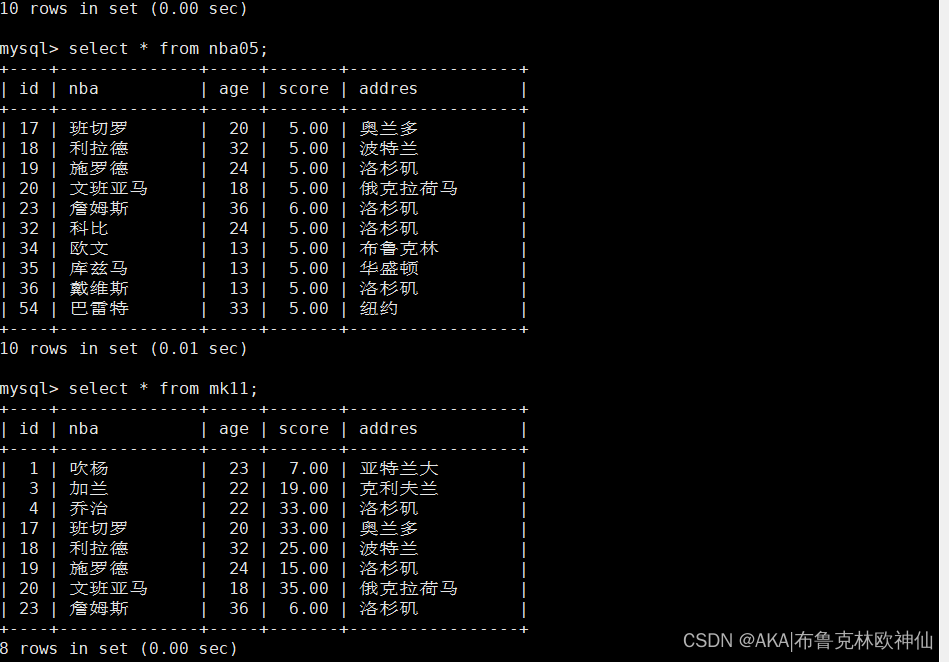
mysql> create table mk11 like ky21;
mysql> desc mk11;
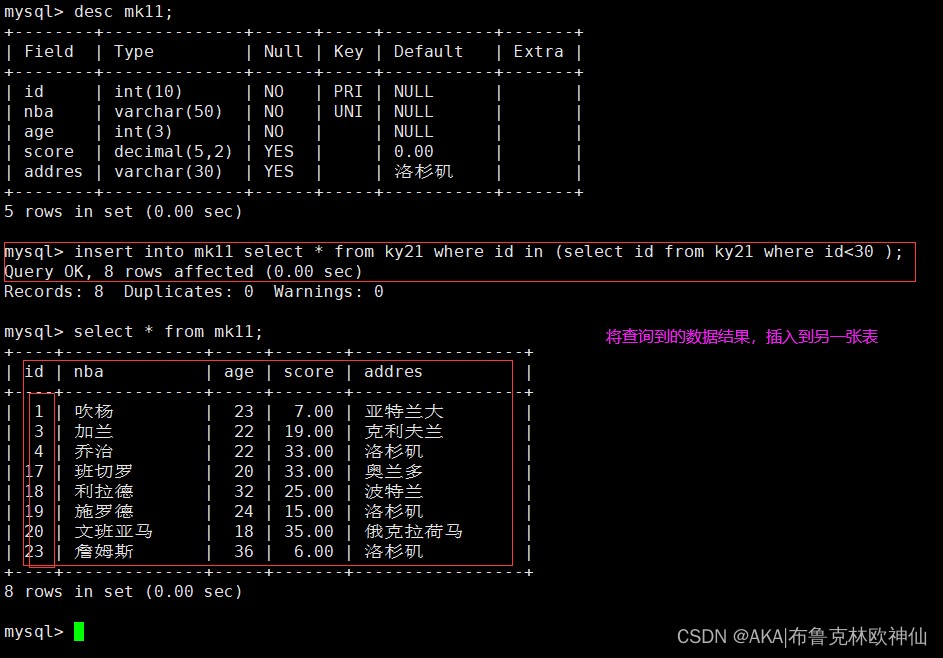
mysql> insert into mk11 select * from ky21 where id in (select id from ky21 where id<30 );
mysql> select * from mk11;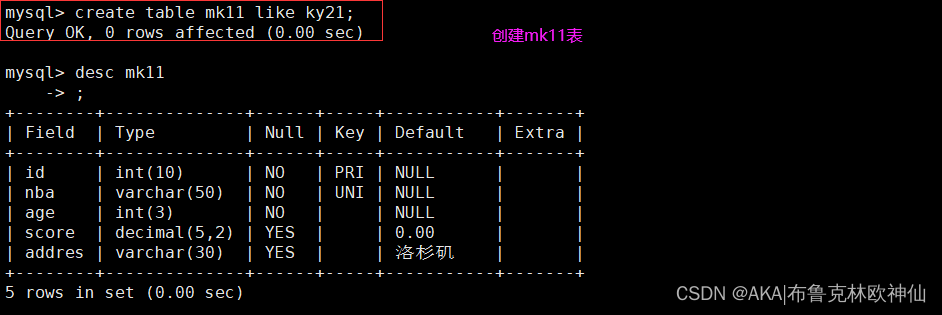
3,update更新
update语句也可以使用子查询,update内的子查询,在set更新内容时,可是单独一列,也可以是多列。
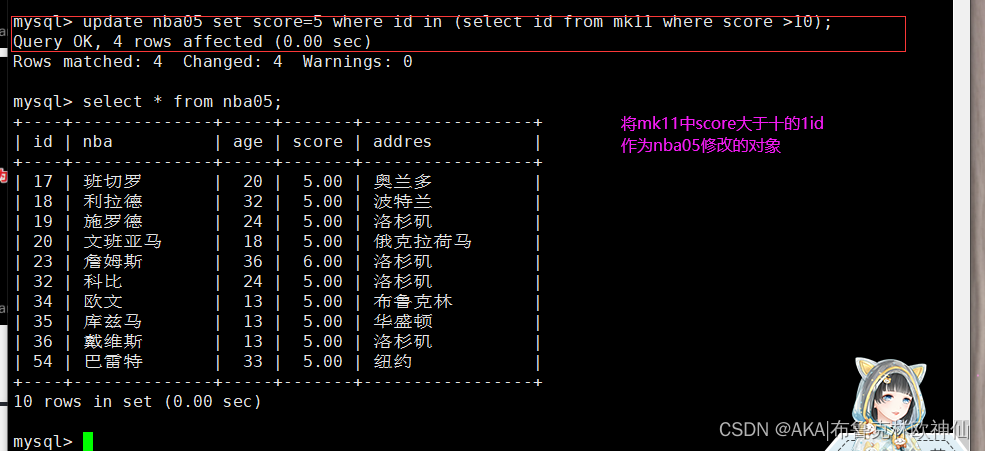
mysql> update nba05 set score=5 where id in (select id from mk11 where score >10);
4,delete删除

5,exists布尔输出
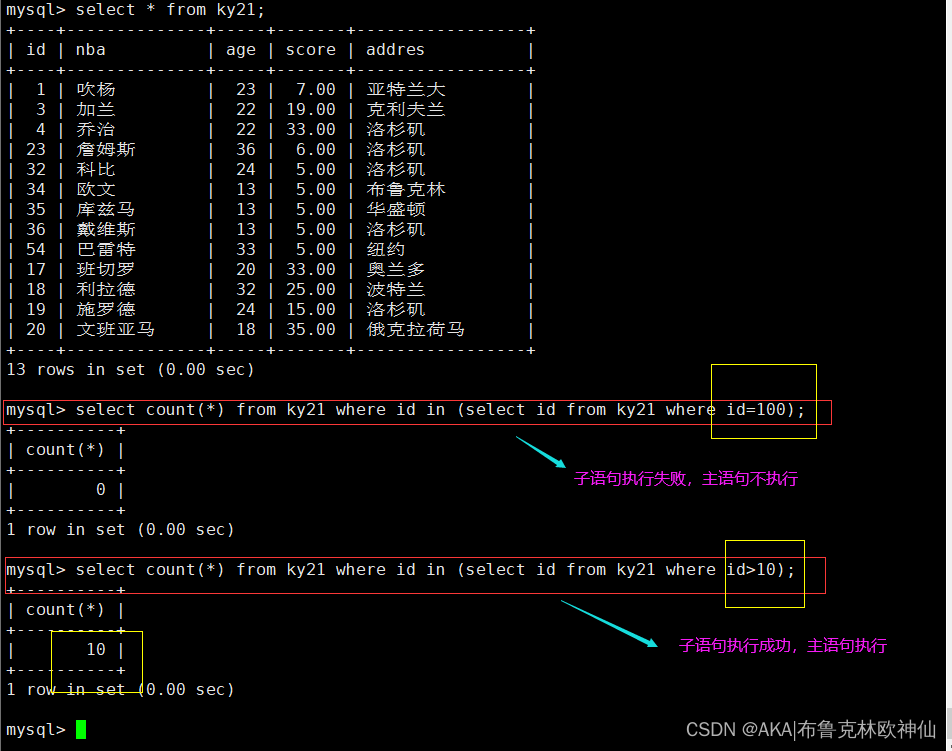
exists 关键字在子查询时,主要用于判断子查询的结果集是否为空,如果不为空。则返回true,反之返回false。
注意: 在使用exists时,当子查询有结果时,不关心子查询的内容,执行主查询操作,当子查询没有结果时,则不执行主查询操作。子查询只是作为布尔的输出
mysql> select count(*) from ky21 where id in (select id from ky21 where id=100);
#子语句执行失败,输出为false,那么主语句不会进行执行,默认输出0
mysql> select count(*) from ky21 where id in (select id from ky21 where id>10);
#子语句执行成功,输出为true,那么主语句会执行,输出info表的行数
三,mysql视图
1,什么是视图
视图:优化操作+安全方案
数据库中的虚拟表,这张虚拟表不包含真实数据。只是做了真实数据的映射。
视图可以理解为镜花水月倒影,动态保存结果集
作用场景:针对不同的人(不同权限),提供不同的结果集的表(以表格的形式展示)
功能
- 简化查询结果集,灵活查询,可以针对不同用户呈现不同的结果集,相对有更高的安全性
- 本质而言,视图是一种select(结果集的呈现)
注意
视图适合于多表连接浏览时使用,不适合增,删,改,
而存储过程适合于使用较频繁的sql语句,这样可以提供执行效率
2,视图和表的区别与联系
区别
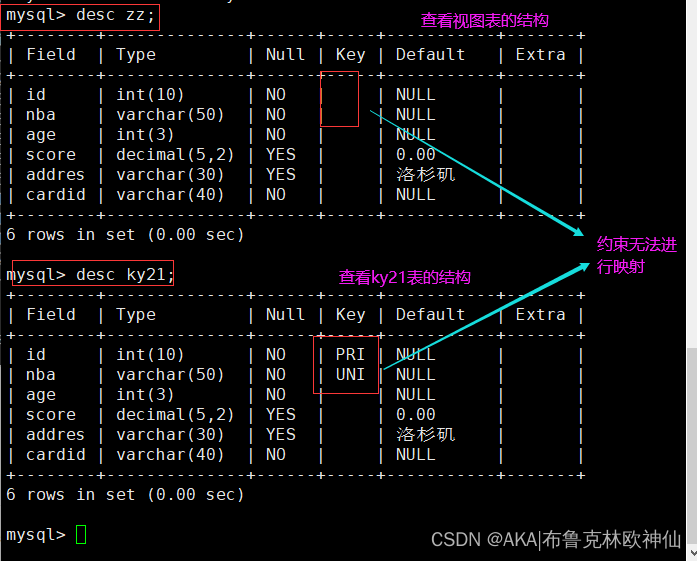
- 视图是已编译好的sql语句,而表不是
- 视图没有实际的物理空间,而表有
- 表示只用物理空间,而视图不占物理空间,视图只是逻辑概念的存在,表可以及时对他进行修改,mysql5.7 通过更改视图也可以直接更改表数据
- 视图是查看数据表的一种方法,可以查询数据表中某些字段构成的数据,只是一些sql语句的集合。从安全角度来说,视图可以不给用户接触数据表,从而不知道结构。
- 表属于全局模式中的表,是实表,视图属于局部模式的表,是虚表。
联系
- 视图(view)是在基本表之上建立的表,它的结构(即所定义的列)和内容(即所有数据行)都是来自基本表,它依据基本表存在而存在。一个视图可以对应一个基本表,也可以对应多个基本表。视图是基本表的抽象和在逻辑意义上建立的新关系。
3,单标创建视图
语法格式:create view 视图表名 as select * from 表名 where 条件;
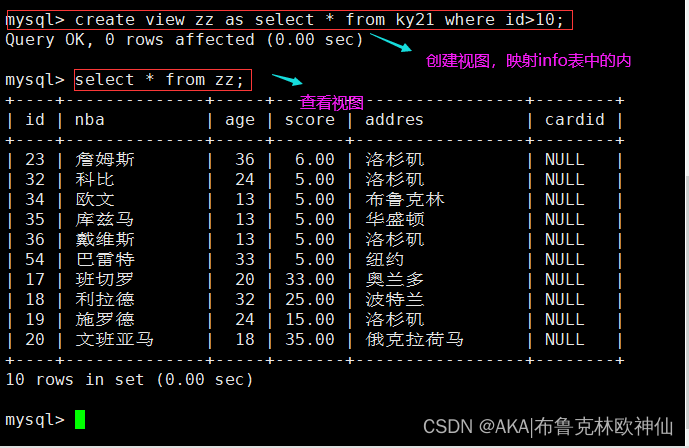
4,多表创建视图
现在有两个表,需要频繁查看其中数据,那就可以使用视图的方式将要看的内容生成一个视图,要查看时,直接查看视图内容即可。
五,NULL值
在 SQL 语句使用过程中,经常会碰到 NULL 这几个字符。通常使用 NULL 来表示缺失的值,也就是在表中该字段是没有值的。如果在创建表时,限制某些字段不为空,则可以使用 NOT NULL 关键字,不使用则默认可以为空。在向表内插入记录或者更新记录时,如果该字段没有 NOT NULL 并且没有值,这时候新记录的该字段将被保存为 NULL。需要注意 的是,NULL 值与数字 0 或者空白(spaces)的字段是不同的,值为 NULL 的字段是没有 值的。在 SQL 语句中,使用 IS NULL 可以判断表内的某个字段是不是 NULL 值,相反的用 IS NOT NULL 可以判断不是NULL值
1,NULL值与空值区别
- NULL值长度为null,占用空间,空值长度为0,不占空间
- is null 无法判断空值
- 控制使用“ = ” 或者 “<>”来处理(!=)
- count()计算时,NULL会忽略,空值会加入计算
六,总结
常用查询,
可以使用order by进行针对某一个字段进行排序,使用asc为升序,可默认不写,使用desc为降序。如果同一条语句中写了两条排序字段,则默认按照第一个进行排序,等出现相同字段才会去使用第二个字段排序。
使用and和or可以过来判断条件,常用在查询语句中筛选一些条件,使用在where条件后面
distinct 为查询不重复记录,在查询语句时,定义字段前面加上distinct就可以输出该字段的所有记录,重复的记录只输出一遍。
group by,表示分组,用来指定以哪个字段进行分组,其中还可以使用count(*)来表示统计行数,经常搭配使用。
limit表示限制,可以选定只显示前几行,或者从第几行开始的后几行内容。
是指别名as,表示在对于表名或字段名较长的时候,使用as设置别名,可以方便降低复杂度。还可使用as来获取另一个表的内容,相当于克隆表的内容数据。as可以省略。
通配符查询,有%表示任意长度的只读,_表示单个任意字符,查询时,经常配合like来进行模糊查询。
子查询
子查询,就是当进行多个表进行查询时,可以使用子查询的结构作为主查询的判断条件进行。总的来说就是,将子查询的结果作为一个集合交给主查询。
写法有两种,一种是在定义判断条件时,使用where in (子查询内容),或者将子查询结果直接作为主查询的表来实现,这样实现需要使用as将子查询的结果设置别名,不然报错。
子查询还可以进行insert、update、delect、exists布尔判断,来设置。
视图
视图就是将表的不同的内容加载到内存中,用来展现给不同的人看,视图可以理解为时一个快捷方式,加载速度快,不消耗磁盘资源,不影响数据库的资源,查询自己需要查询的内容非常方便快捷。