文章目录
1.查找
1.1 线性表查找
(1)顺序查找
public class SearchDemo1 {
public static void main(String[] args) {
// 给定分数数组
int[] scoreArr = {
89, 45, 78, 45, 100, 98, 86, 100, 65};
// 给定要查找的分数
int score = 100;
// 完成查找
int index = -1;
for (int i = 0; i < scoreArr.length; i++) {
if (scoreArr[i] == score){
index = i;
break;
} }
// 输出结果
if (index == -1) {
System.out.println("该分数不存在");
}else {
System.out.println(score+"的索引是"+index);
} } }
(2)折半查找:顺序结构、按照关键字有序
①非递归
public class SearchDemo2 {
public static void main(String[] args) {
// 给定数组
int[] arr = {
1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
//给定要查找的值
int key = 9;
// 进行折半二分查找
int index = binarySearch(arr, key);
// 输出结果
if (index == -1) {
System.out.println("该分数不存在");
} else {
System.out.println(key + "的索引是" + index);
} }
// 不使用递归
public static int binarySearch(int[] array, int key) {
// 指定low和high
int low = 0;
int high = array.length - 1;
// 折半查找
while (low <= high) {
// 求mid
int mid = (low + high) / 2;
// 判断是否等于
if (key == array[mid]) {
return mid;
} else if (key < array[mid]) {
high = mid - 1;
} else {
low = mid + 1;
}
}
return -1;
} }
②递归
public class SearchDemo3 {
public static void main(String[] args) {
// 给定数组
int[] arr = {
1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
//给定要查找的值
int key = 10;
// 进行折半二分查找
int index = binarySearch(arr, key);
// 输出结果
if (index == -1) {
System.out.println("该分数不存在");
} else {
System.out.println(key + "的索引是" + index);
}
}
// 使用递归
public static int binarySearch(int[] array, int key) {
//指定low和high
int low = 0;
int high = array.length - 1;
return binarySearch(array, key, low, high);
}
public static int binarySearch(int[] array, int key, int low, int high) {
// 递归结束的条件
if (low > high) {
return -1;
}
int mid = (low + high) / 2;
if (key == array[mid]) {
return mid;
} else if (key < array[mid]) {
return binarySearch(array, key, low, mid - 1);
} else {
return binarySearch(array, key, mid + 1, high);
} } }
1.2 查找树
1.2.1 二叉查找/搜索/排序树 BST
(1)或者是一棵空树
(2)或者是具有下列性质的二叉树
①若它的左子树不为空,则左子树上所有结点的值均小于它的根结点的值
②若它的右子树上所有结点的值均大于它的根结点的值
③它的左、右子树也分别为二叉排序树
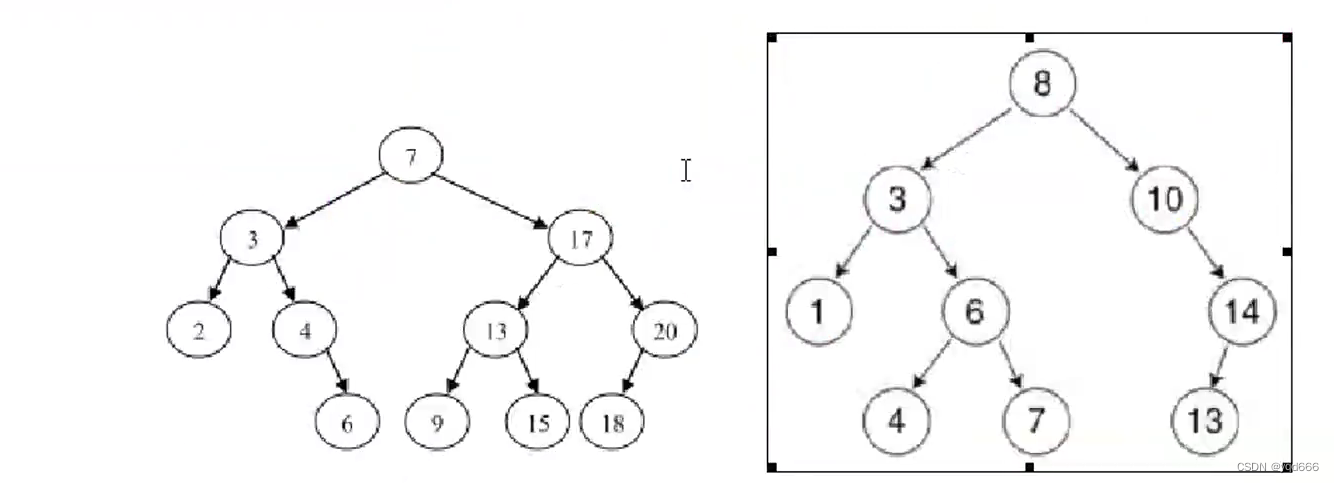 注意:对二叉查找树进行中序遍历,得到有序集合
注意:对二叉查找树进行中序遍历,得到有序集合
1.2.2 平衡二叉树
自平衡二叉查找树,又被称为AVL树(有别于AVL算法)
(1)它是一棵空树
(2)或它的左右两个子树的高度差(平衡因子)的绝对值不超过1,
并且左右两个子树都是一棵平衡二叉树,
同时,平衡二叉树必定是二叉搜索树,反之则不一定
①平衡因子:结点的平衡因子是结点的左子树的高度减去右子树的高度
②平衡二叉树:每个结点的平衡因子都为1、-1、0的二叉排序树。或者说每个结点的左右子树的高度
最多差1的二叉排序树。
(3)二叉树的目的是为了减少二叉查找树层次,提高查找速度
平衡二叉树的常用实现方法有AVL、红黑树、替罪羊树、Treap、伸展树等。
1.2.3 红黑树
R-B Tree,全称是Red-Black Tree,又称为“红黑树”,它是一种平衡二叉树。红黑树的每个结点上都有存储位表示结点的颜色,可以是红或黑。
红黑树的特性:
(1)每个结点或者是黑色,或者是红色。
(2)根结点是黑色
(3)每个叶子结点是黑色(注意:这里叶子结点,是指为空的叶子结点)
(4)如果一个结点是红色,则它的子节点必须是黑色的。
(5)从一个结点到该结点的子孙结点的所有路径上包含相同数目的黑结点。
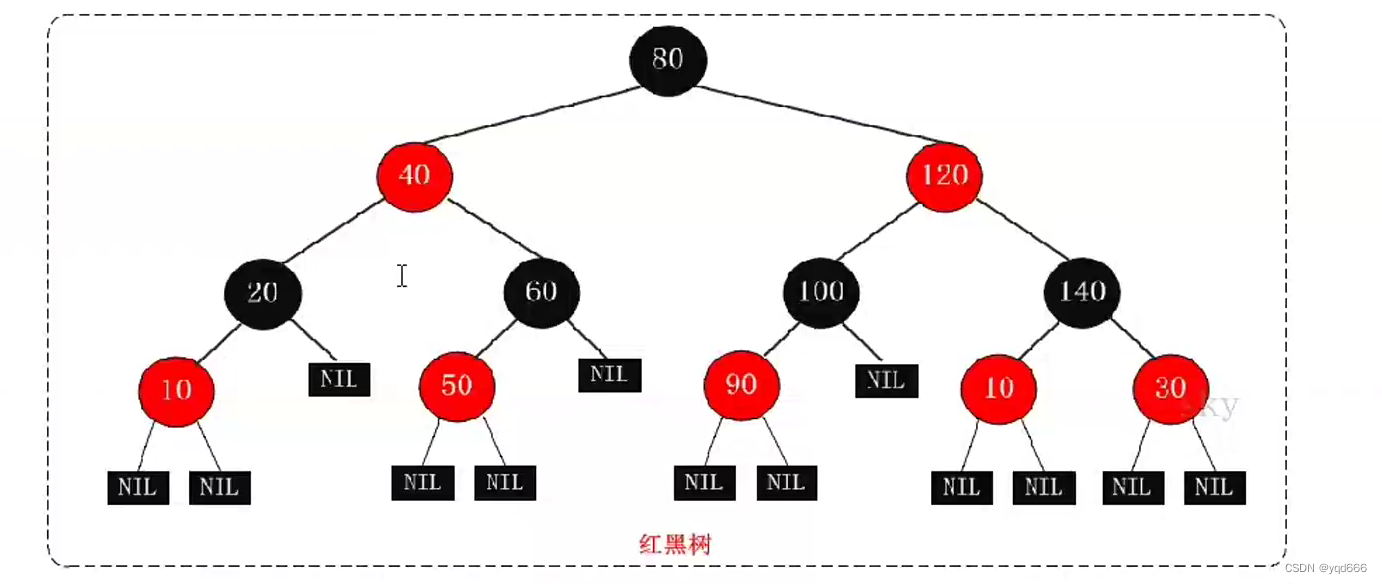
红黑树的应用比较广泛,主要用它来存储有序的数据,它的时间复杂度是O(logN),效率非常高。
例如,Java集合中的TreeSet和TreeMap
1.2.4 B树(平衡树)

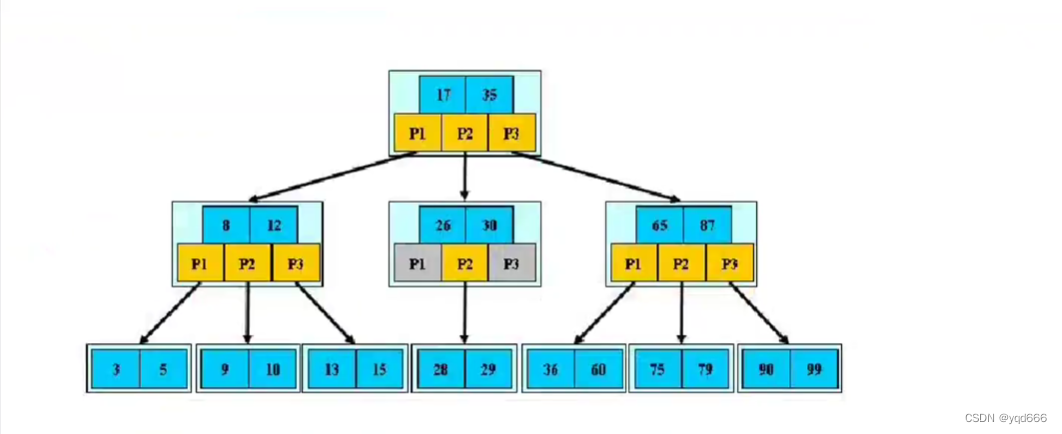
1.2.5 B+树
(1)所有的数据都在最下面一层
(2)在B-树(即B树)基础上,为叶子结点增加链表指针,所有关键字都在叶子结点中出现,非叶子结点作为叶子结点的索引;B+树总是到叶子结点才命中。
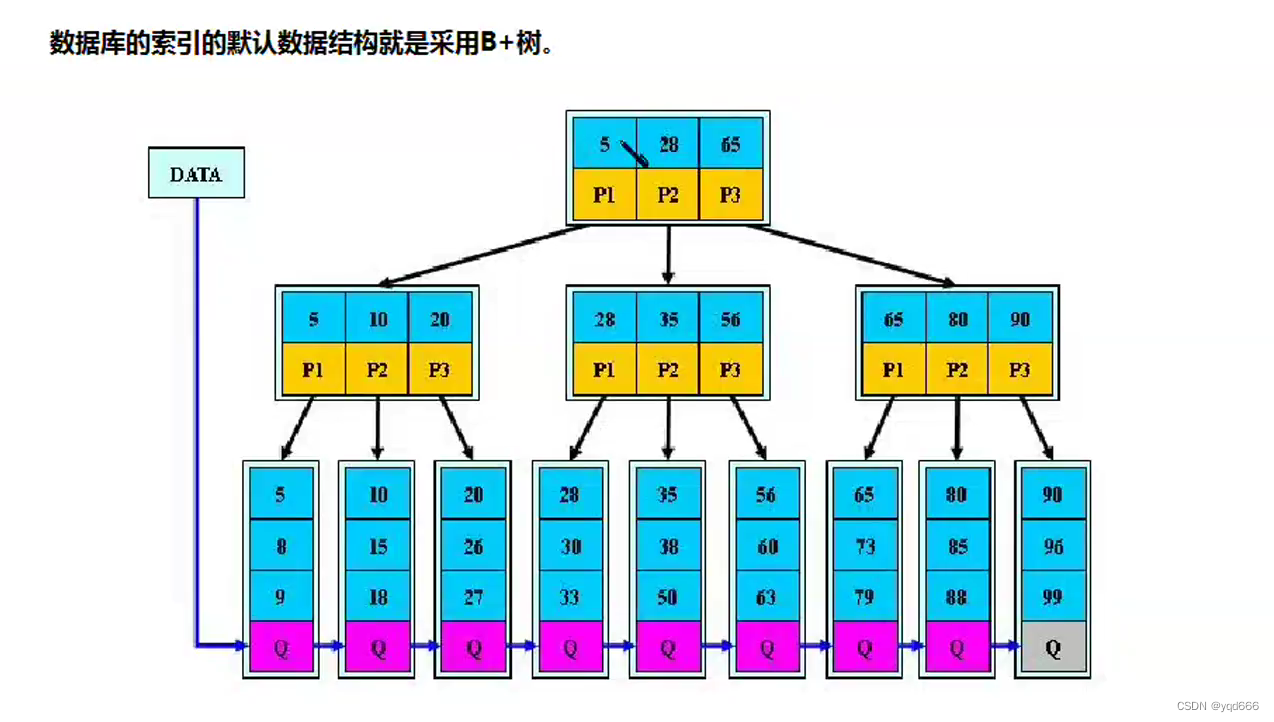
1.2.6 B*树
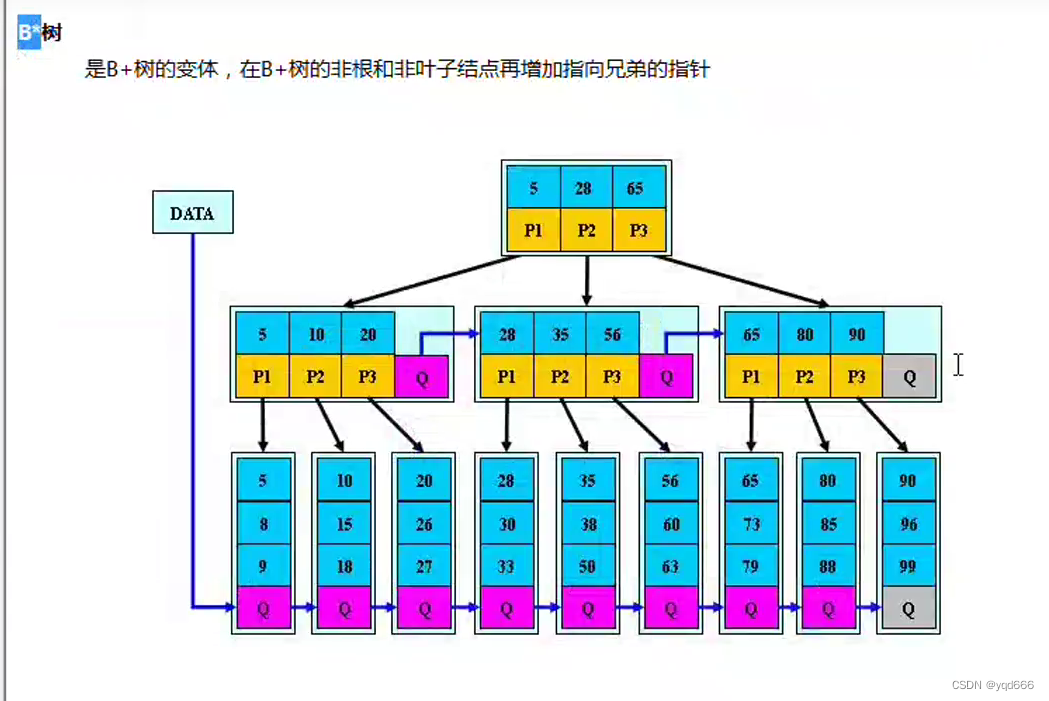
1.3 哈希表查找
1.3.1 哈希表的结构和特点
(1)hash table(哈希表) 也叫散列表
(2)特点:快
(3)结构有多种,
最流行、最容易理解的是:顺序表(主结构)+链表
(4)主结构:顺序表
(5)每个顺序表的结点再单独引出一个链表
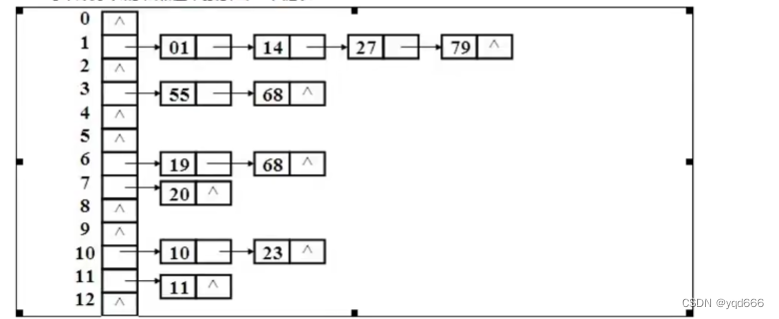
1.3.2 哈希表是如何添加数据的
(1)计算哈希码(调用hashCode(),结果是一个int值,整数的哈希码取自身即可)
(2)计算在哈希表中的存储位置(根据hashcode计算出hash值)
hashcode是一个整数,我们需要将它转化成[0, 数组长度-1]的范围。我们要求转化后的hash值尽量均匀地分布在[0,数组长度-1]这个区间,减少“hash冲突”
① 一种极端简单和低下的算法是:hash值 = hashcode/hashcode;
也就是说,hash值总是1。意味着,键值对对象都会存储到数组索引1位置,这样就形成一个非常长的链表。相当于每存储一个对象都会发生“hash冲突”,HashMap也退化成了一个“链表”。
②一种简单和常用的算法是(相除取余算法):hash值 = hashcode%数组长度
这种算法可以让hash值均匀的分布在[0,数组长度-1]的区间。 早期的HashTable就是采用这种算法。但是,这种算法由于使用了“除法”,效率低下。JDK后来改进了算法。首先约定数组长度必须为2的整数幂,这样采用位运算即可实现取余的效果:hash值 = hashcode&(数组长度-1)。
(3)存入哈希表:
情况一:一次添加成功
情况二:多次添加成功(出现了冲突[哈希表的存储位置相同],调用equals()和对应链表的元素进行比较,比较到最后,结果都是false,
创建新节点,存储数据,并加入链表末尾)
情况三:不添加(出现了冲突,调用equals()和对应链表的元素进行比较;经过一次或者多次比较后,结果都是true,表明重复,
不添加)
结论一:哈希表添加数据快(3步即可,不考虑冲突)
结论二:唯一
结论三:无序
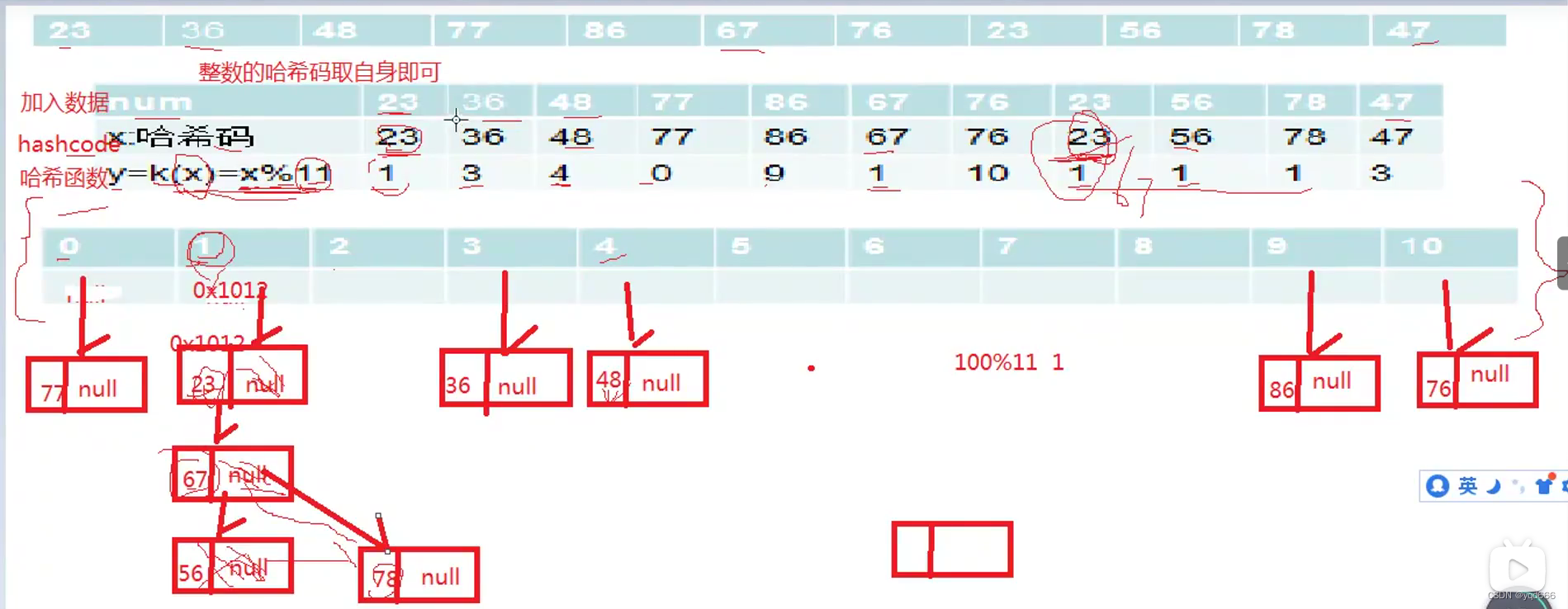
1.3.3 哈希表是如何查询数据的
和添加数据的过程是相同的
结论一:哈希表查询数据快
结论二:哈希表删除数据快
结论三:哈希表更新数据快(如果更新后影响到哈希码值,就比较麻烦了,要删除再添加了)
1.3.4 hashCode和equals的作用
(1)hashCode():用于计算哈希码,是一个整数,根据哈希码可以计算出数据在哈希表中的存储位置。
(2)equals():添加时出现了冲突,需要通过equals进行比较,判断是否相同
查询也需要使用equals进行比较,判断是否相等
1.3.5 各种类型数据的哈希码如何获取
(1)Integer
// int就是取自身
public static int hashCode(int value) {
return value;
}
(2)Double
public static int hashCode(double value) {
long bits = doubleToLongBits(value);
return (int)(bits ^ (bits >>> 32));
}
(3)String
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
2.排序
2.1 排序的介绍
(1)什么是排序
排序的功能是将一个数据元素的任意序列,重新排列成一个按关键字有序的序列
(2)内部排序和外部排序
①整个排序过程在内存储器中进行,称为内部排序
②待排序元素数量太大,以至于内存储器无法全部容纳全部数据,排序需要借助外部存储设备才能完成,这类
排序称为外部排序。
(3)稳定排序和不稳定排序
①假设Ri=Rj,若在排序之前Ri就在Rj之前,经过排序之后Ri仍在Rj之前,则称所用的排序方法是稳定的。
②否则,当相同关键字元素的前后关系在排序中发生变化,则称所用的排序方法是不稳定的
(在某些场合可能对排序有稳定性的要求,例如学生按成绩排序,分数相同时要求学号小的在前)
2.2 快速排序
快速排序采用了一种分治的策略,通常称其为分治法,该方法的基本思想是:
(1)先从数列中取出一个数作为基准数(简单起见可以取第一个数)
(2)分区过程,将比这个数大的数全部放到它的右边,小于或等于它的数全部放到它的左边(分区)
(3)再对左右区间重复第一步、第二步,直到各区间只有一个数(递归)