lambda表达式
lambda表达式概念
lambda表达式是一个匿名函数,恰当使用lambda表达式可以让代码变得简洁,并且可以提高代码的可读性。
举个例子
商品类Goods的定义如下:
struct Goods
{
string _name; //名字
double _price; //价格
int _num; //数量
};
现在要对若干商品分别按照价格和数量进行升序、降序排序。
- 要对一个数据集合中的元素进行排序,可以使用sort函数,但由于这里待排序的元素为自定义类型,因此需要用户自行定义排序时的比较规则。
- 要控制sort函数的比较方式常见的有两种方法,一种是对商品类的的
()运算符进行重载,另一种是通过仿函数来指定比较的方式。 - 显然通过重载商品类的
()运算符是不可行的,因为这里要求分别按照价格和数量进行升序、降序排序,每次排序就去修改一下比较方式是很笨的做法。
所以这里选择传入仿函数来指定排序时的比较方式。比如:
struct ComparePriceLess
{
bool operator()(const Goods& g1, const Goods& g2)
{
return g1._price < g2._price;
}
};
struct ComparePriceGreater
{
bool operator()(const Goods& g1, const Goods& g2)
{
return g1._price > g2._price;
}
};
struct CompareNumLess
{
bool operator()(const Goods& g1, const Goods& g2)
{
return g1._num < g2._num;
}
};
struct CompareNumGreater
{
bool operator()(const Goods& g1, const Goods& g2)
{
return g1._num > g2._num;
}
};
int main()
{
vector<Goods> v = {
{
"苹果", 2.1, 300 }, {
"香蕉", 3.3, 100 }, {
"橙子", 2.2, 1000 }, {
"菠萝", 1.5, 1 } };
sort(v.begin(), v.end(), ComparePriceLess()); //按价格升序排序
sort(v.begin(), v.end(), ComparePriceGreater()); //按价格降序排序
sort(v.begin(), v.end(), CompareNumLess()); //按数量升序排序
sort(v.begin(), v.end(), CompareNumGreater()); //按数量降序排序
return 0;
}
仿函数确实能够解决这里的问题,但可能仿函数的定义位置可能和使用仿函数的地方隔得比较远,这就要求仿函数的命名必须要通俗易懂,否则会降低代码的可读性。
对于这种场景就比较适合使用lambda表达式。比如:
int main()
{
vector<Goods> v = {
{
"苹果", 2.1, 300 }, {
"香蕉", 3.3, 100 }, {
"橙子", 2.2, 1000 }, {
"菠萝", 1.5, 1 } };
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2)
{
return g1._price < g2._price;
}); //按价格升序排序
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2)
{
return g1._price > g2._price;
}); //按价格降序排序
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2)
{
return g1._num < g2._num;
}); //按数量升序排序
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2)
{
return g1._num > g2._num;
}); //按数量降序排序
return 0;
}
这样一来,每次调用sort函数时只需要传入一个lambda表达式指明比较方式即可,阅读代码的人一看到lambda表达式就知道本次排序的比较方式是怎样的,提高了代码的可读性。
lambda表达式语法
lambda表达式书写格式:[capture-list](parameters)mutable->return-type{statement}
lambda表达式各部分说明
[capture-list]:捕捉列表。该列表总是出现在lambda函数的开始位置,编译器根据[]来判断接下来的代码是否为lambda函数,捕捉列表能够捕捉上下文中的变量供lambda函数使用。(parameters):参数列表。与普通函数的参数列表一致,如果不需要参数传递,则可以连同()一起省略。mutable:默认情况下,lambda函数总是一个const函数,mutable可以取消其常量性。使用该修饰符时,参数列表不可省略(即使参数为空)。->return-type:返回值类型。用追踪返回类型形式声明函数的返回值类型,没有返回值时此部分可以省略。返回值类型明确情况下,也可省略,由编译器对返回类型进行推导。{statement}:函数体。在该函数体内,除了可以使用其参数外,还可以使用所有捕获到的变量。
lambda函数的参数列表和返回值类型都是可选部分,但捕捉列表和函数体是不可省略的,因此最简单的lambda函数如下:
int main()
{
[]{
}; //最简单的lambda表达式
return 0;
}
该lambda函数不能做任何事情。
捕获列表说明
捕获列表描述了上下文中哪些数据可以被lambda函数使用,以及使用的方式是传值还是传引用。
[var]:表示值传递方式捕捉变量var。[=]:表示值传递方式捕获所有父作用域中的变量(成员函数包括this指针)。[&var]:表示引用传递捕捉变量var。[&]:表示引用传递捕捉所有父作用域中的变量(成员函数包括this指针)。[this]:表示值传递方式捕捉当前的this指针。
说明一下:
- 父作用域指的是包含lambda函数的语句块。
- 语法上捕捉列表可由多个捕捉项组成,并以逗号分割。比如
[=, &a, &b]。 - 捕捉列表不允许变量重复传递,否则会导致编译错误。比如
[=, a]重复传递了变量a。 - 在块作用域以外的lambda函数捕捉列表必须为空,即全局lambda函数的捕捉列表必须为空。
- 在块作用域中的lambda函数仅能捕捉父作用域中的局部变量,捕捉任何非此作用域或者非局部变量都会导致编译报错。
- lambda表达式之间不能相互赋值,即使看起来类型相同。
lambda表达式交换两个数
如果要用lambda表达式交换两个数,可以有以下几种写法:
标准写法
参数列表中包含两个形参,表示需要交换的两个数,注意需要以引用的方式传递。比如:
int main()
{
int a = 10, b = 20;
auto Swap = [](int& x, int& y)->void
{
int tmp = x;
x = y;
y = tmp;
};
Swap(a, b); //交换a和b
return 0;
}
说明一下:
- lambda表达式是一个匿名函数,该函数无法直接调用,如果想要直接调用,可借助auto将其赋值给一个变量,此时这个变量就可以像普通函数一样使用。
- lambda表达式的函数体在格式上并不是必须写成一行,如果函数体太长可以进行换行,但换行后不要忘了函数体最后还有一个分号。
利用捕捉列表进行捕捉
以引用的方式捕捉所有父作用域中的变量,省略参数列表和返回值类型。比如:
int main()
{
int a = 10, b = 20;
auto Swap = [&]
{
int tmp = a;
a = b;
b = tmp;
};
Swap(); //交换a和b
return 0;
}
这样一来,调用lambda表达式时就不用传入参数了,但实际我们只需要用到变量a和变量b,没有必要把父作用域中的所有变量都进行捕捉,因此也可以只对父作用域中的a、b变量进行捕捉。比如:
int main()
{
int a = 10, b = 20;
auto Swap = [&a, &b]
{
int tmp = a;
a = b;
b = tmp;
};
Swap(); //交换a和b
return 0;
}
说明一下: 实际当我们以[&]或[=]的方式捕获变量时,编译器也不一定会把父作用域中所有的变量捕获进来,编译器可能只会对lambda表达式中用到的变量进行捕获,没有必要把用不到的变量也捕获进来,这个主要看编译器的具体实现。
传值方式捕捉?
如果以传值方式进行捕捉,那么首先编译不会通过,因为传值捕获到的变量默认是不可修改的,如果要取消其常量性,就需要在lambda表达式中加上mutable,并且此时参数列表不可省略。比如:
int main()
{
int a = 10, b = 20;
auto Swap = [a, b]()mutable
{
int tmp = a;
a = b;
b = tmp;
};
Swap(); //交换a和b?
return 0;
}
但由于这里是传值捕捉,lambda函数中对a和b的修改不会影响外面的a、b变量,与函数的传值传参是一个道理,因此这种方法无法完成两个数的交换。
lambda表达式底层原理
lambda表达式的底层原理
实际编译器在底层对于lambda表达式的处理方式,完全就是按照函数对象的方式处理的。函数对象就是我们平常所说的仿函数,就是在类中对()运算符进行了重载的类对象。
下面编写了一个Add类,该类对()运算符进行了重载,因此Add类实例化出的add1对象就叫做函数对象,add1可以像函数一样使用。然后我们编写了一个lambda表达式,并借助auto将其赋值给add2对象,这时add1和add2都可以像普通函数一样使用。比如:
class Add
{
public:
Add(int base)
:_base(base)
{
}
int operator()(int num)
{
return _base + num;
}
private:
int _base;
};
int main()
{
int base = 1;
//函数对象
Add add1(base);
add1(1000);
//lambda表达式
auto add2 = [base](int num)->int
{
return base + num;
};
add2(1000);
return 0;
}
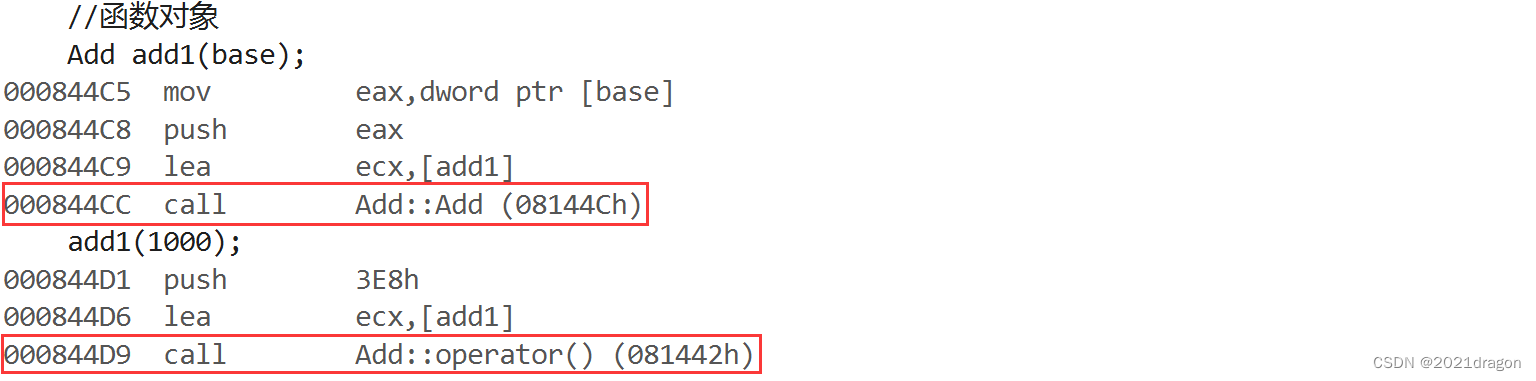
调试代码并转到反汇编,可以看到:
- 在创建函数对象add1时,会调用Add类的构造函数。
- 在使用函数对象add1时,会调用Add类的
()运算符重载函数。
如下图:
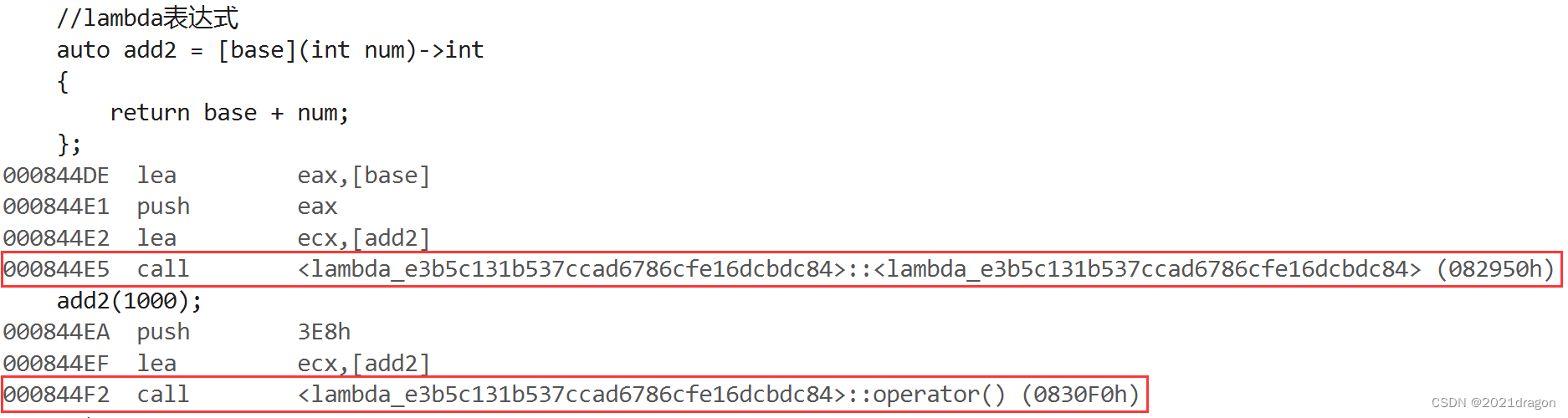
观察lambda表达式时,也能看到类似的代码:
- 借助auto将lambda表达式赋值给add2对象时,会调用
<lambda_uuid>类的构造函数。 - 在使用add2对象时,会调用
<lambda_uuid>类的()运算符重载函数。
如下图:
本质就是因为lambda表达式在底层被转换成了仿函数。
- 当我们定义一个lambda表达式后,编译器会自动生成一个类,在该类中对
()运算符进行重载,实际lambda函数体的实现就是这个仿函数的operator()的实现。 - 在调用lambda表达式时,参数列表和捕获列表的参数,最终都传递给了仿函数的
operator()。
lambda表达式和范围for是类似的,它们在语法层面上看起来都很神奇,但实际范围for底层就是通过迭代器实现的,lambda表达式底层的处理方式和函数对象是一样的。
lambda表达式之间不能相互赋值
lambda表达式之间不能相互赋值,就算是两个一模一样的lambda表达式。
- 因为lambda表达式底层的处理方式和仿函数是一样的,在VS下,lambda表达式在底层会被处理为函数对象,该函数对象对应的类名叫做
<lambda_uuid>。 - 类名中的uuid叫做通用唯一识别码(Universally Unique Identifier),简单来说,uuid就是通过算法生成一串字符串,保证在当前程序当中每次生成的uuid都不会重复。
- lambda表达式底层的类名包含uuid,这样就能保证每个lambda表达式底层类名都是唯一的。
因此每个lambda表达式的类型都是不同的,这也就是lambda表达式之间不能相互赋值的原因,我们可以通过typeid(变量名).name()的方式来获取lambda表达式的类型。比如:
int main()
{
int a = 10, b = 20;
auto Swap1 = [](int& x, int& y)->void
{
int tmp = x;
x = y;
y = tmp;
};
auto Swap2 = [](int& x, int& y)->void
{
int tmp = x;
x = y;
y = tmp;
};
cout << typeid(Swap1).name() << endl; //class <lambda_797a0f7342ee38a60521450c0863d41f>
cout << typeid(Swap2).name() << endl; //class <lambda_f7574cd5b805c37a13a7dc214d824b1f>
return 0;
}
可以看到,就算是两个一模一样的lambda表达式,它们的类型都是不同的。
说明一下: 编译器只需要保证每个lambda表达式底层对应类的类名不同即可,并不是每个编译器都会将lambda表达式底层对应类的类名处理成<lambda_uuid>,这里只是以VS为例。