作者:~小明学编程
文章专栏:MySQL
格言:目之所及皆为回忆,心之所想皆为过往

为什么需要索引?
前面给大家介绍了MySQL的一些增删改查,但是我们常用的需求就是查,既然说到了查询,那么查询的速度就很重要,当我么的数据量很大的时候我们在查询一个数据的时候就会很慢,这个时候就需要我们去引用索引。
当我们遇到一个生僻字的时候我们可能会尝试去查字典,查字典的话我们就要去翻前面的目录,找偏旁啥的,索引的作用就在于快速的让我们找到我们想要的数据。
索引要付出的代价
我们的索引可以让我们快速的找到我们所想要的数据,当然也要付出相应的代价,我么创建索引是要付出相应的时间和空间的代价,就像我们一本书的目录,目录可以让我们快速的找到指定的章节,当然我们也是需要消耗一定的纸张的。
索引背后的数据结构
我们索引的背后是一个B+树,至于为什么不去用二叉树是因为二叉树的高度过高的话也就是我们的查询速度会变慢,这个时候我们IO次数变多浪费时间。
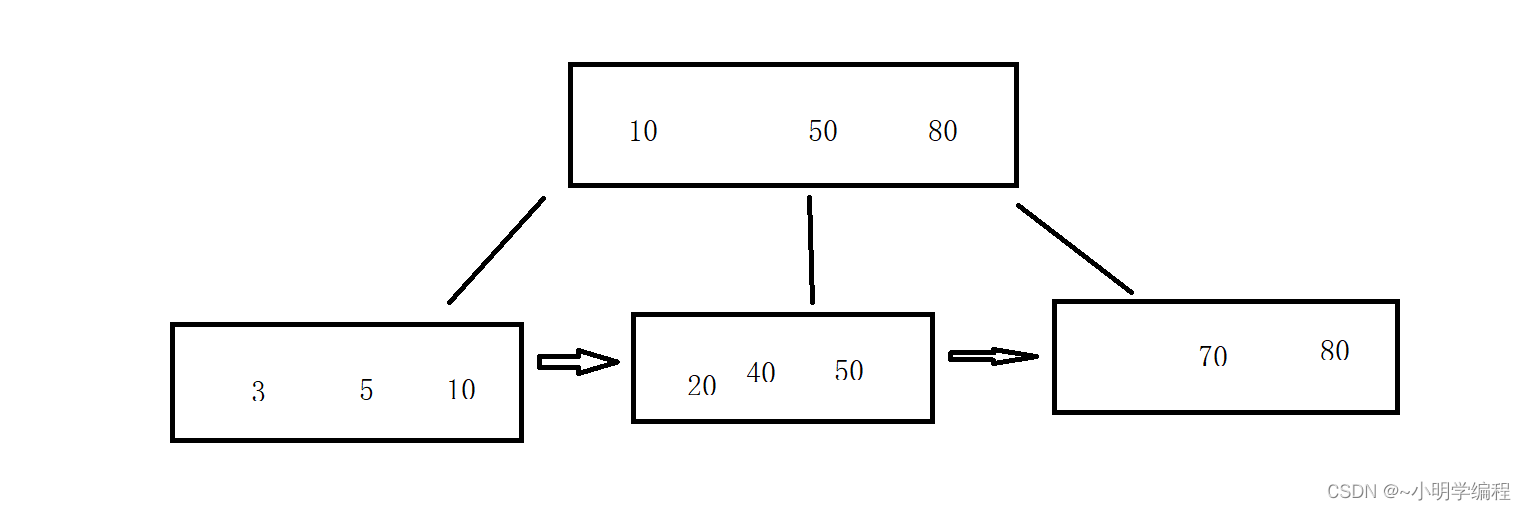
这是我们一棵简单的B+树,因为我们可以有很多的分支这样我们就不会因为高度过高IO次数过多而导致查询次数过慢了,虽然我们比较的次数还是不变但是我们每个节点的数据变多了,IO次数也变少了。
这里我们的最下面相当于是一个链表,这样的话当我们查找10~50的数据的话会很方便直接取到下面的两个边界就行了,此外我们所有的数据存储(负载)都是放在叶子节点上的,非叶子节点的话放key值就可以了,这样大大的节约课空间的开支。
索引的使用
在MySQL中我们可以利用相关的语句进行索引的相关操作:
查看索引:
show index from 表名;创建索引:
create index 索引名 on 表名(字段名);删除索引:
drop index 索引名 on 表名;