YOLOX-PAI 论文解读
论文解读
前言
2021 年,旷视提出 YOLOX 算法,在速度和精度上构建了新的基线,组件灵活可部署,深受工业界的喜爱。
近日,阿里云机器学习平台团队 PAI 通过自研的 PAI-EasyCV 框架复现 YOLOX 算法。
一、YOLOX-PAI是什么?
YOLOX 是最著名的单阶段物体检测方法之一。
YOLOX-PAI是阿里在EasyCV中,利用PAI 的推理优化框架对YOLOX进行一系列优化得到的高效的预测器 api。
二、论文解读
0、摘要
我们开发了一个名为
EasyCV的多功能计算机视觉工具箱,以方便使用各种SOTA计算机视觉方法。最近,我们将YOLOX的改进版YOLOX-PAI添加到EasyCV中。通过消融研究以探讨某些检测方法对
YOLOX的影响。我们还为PAI-Blade提供了一个简单的用法,用于加速基于BladeDISC和TensorRT的推理过程。最后,在
COCO数据集上,单个 NVIDIA V100 GPU 上速度为1.0 毫秒,精度为42.8 mAP,这比YOLOv6快一点。
EasyCV中还设计了一个简单但高效的预测器 api 来进行端到端目标检测。
1、简介
YOLOX 是最著名的单阶段物体检测方法之一,已广泛应用于自动驾驶、缺陷检测等各个领域。它在 YOLO 系列中引入了解耦头和Anchor-free方式,并在 40 mAP 到 50 mAP 之间获得最先进的结果。
考虑到它的灵活性和效率,我们打算将 YOLOX 集成到 EasyCV 中,这是一种一体化的计算机视觉方法,即使是初学者也能轻松使用。此外,通过使用不同增强的检测Backbone、Neck和Head来研究YOLOX 的改进。用户可以根据自己的需求简单地设置不同的配置来获得适合自己的目标检测模型。
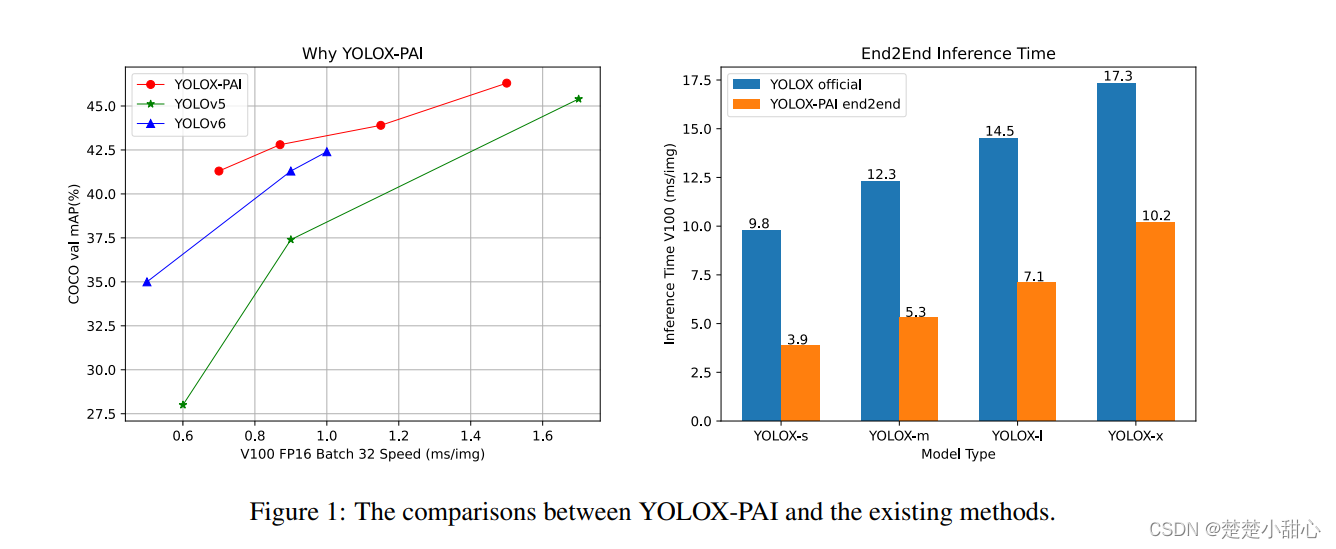
此外,基于 PAI-Blade(PAI 的推理优化框架),进一步加快了推理过程,并提供了一个简单的 api 来在 EasyCV 中使用 PAI-Blade。最后,设计了一个高效的预测器 api,以端到端的方式使用 YOLOX-PAI,大大加速了原始 YOLOX。YOLOX-PAI 与最先进的目标检测方法之间的比较如图 1 所示。
简而言之,我们的主要贡献如下:
- 在
EasyCV中发布YOLOX-PAI作为一个简单而高效的目标检测工具(包含docker镜像、模型训练、模型评估和模型部署的过程)。我们希望即使是初学者也可以使用YOLOX-PAI来完成他的目标检测任务。- 对现有的基于
YOLOX的目标检测方法进行了消融研究,其中仅使用一个配置文件来构建自行设计的YOLOX模型。随着架构的改进和PAI-Blade的效率,模型在单个 NVIDIA Tesla V100 GPU 上进行推理,耗时在1ms ,获得了 40 mAP 和 50 mAP 中最先进的目标检测结果。- 在
EasyCV中提供了一个灵活的预测器API,分别加速了预处理、推理和后处理过程。这样,用户可以更好地使用YOLOX-PAI进行端到端的目标检测任务。
2、方法
2.1、Backbone
最近,
YOLOv6和PP-YOLOE已经将CSPNet的Backbone替换为RepVGG。在RepVGG中,在推理过程中使用一个3x3的卷积块来代替多分支结构,这样既有利于节省推理时间,又有利于提高目标检测结果。 紧随YOLOv6其后,我们也使用基于RepVGG的Backbone。
2.2、neck
我们使用两种方法来提升
YOLOX在YOLOX-PAI的Neck的性能:
- 用于特征增强的自适应空间特征融合(
ASFF)及其变体(记为ASFF_Sim);- GSConv,一个轻量级的卷积块,以降低计算成本。
原始的
ASFF方法使用几个vanilla卷积块来首先统一不同特征图的维度。受YOLOv5中Focus层的启发,我们通过使用非参数的切片操作和均值操作来替换卷积块以获得统一的特征图(表示为ASFF_Sim)。具体来说,YOLOX输出的每个特征图的操作在图 2 中定义。
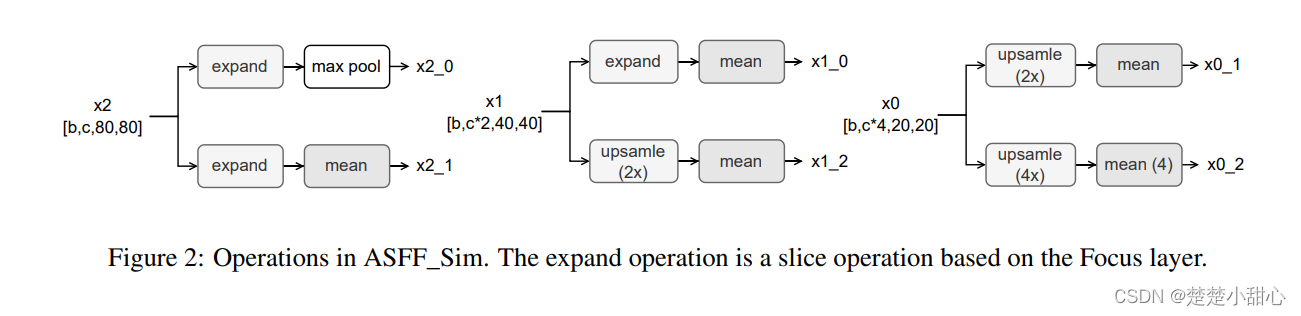
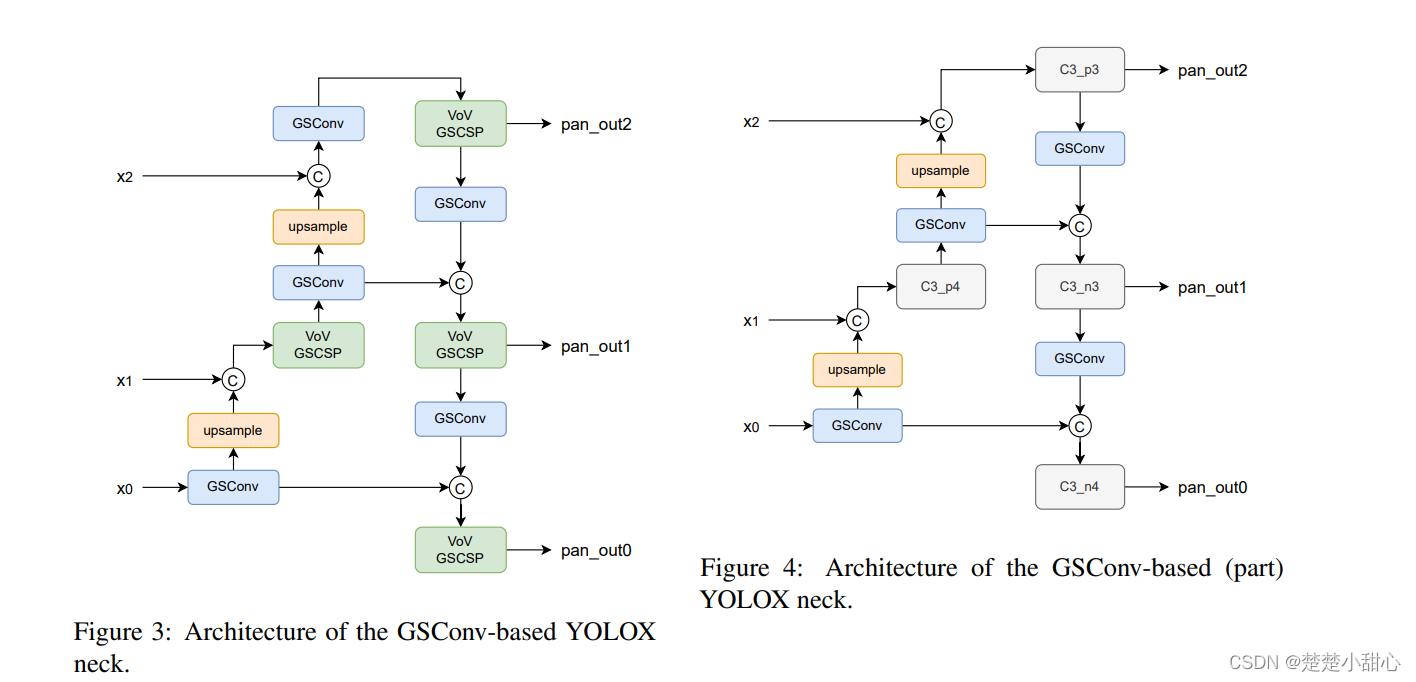
我们还使用2种基于
GSConv的Neck来优化YOLOX。使用的Neck架构如图3和图4所示。两种架构的区别在于是否将所有块替换为GSConv。正如作者所证明的那样,GSconv是专门为通道达到最大和尺寸达到最小的Neck设计的。
2.3、head
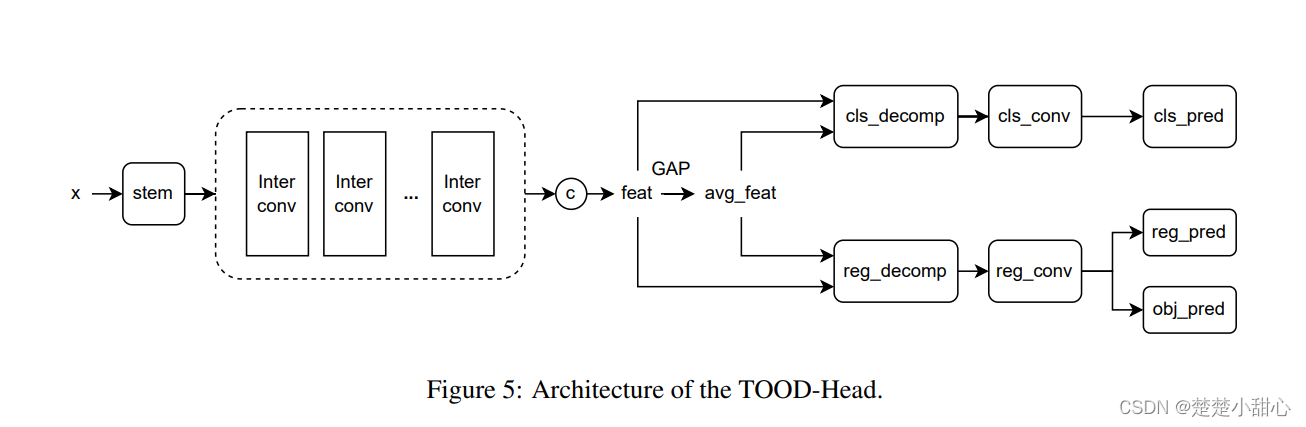
作者通过注意力机制增强了
YOLOX-Head,以协调目标检测和分类的任务(表示为TOOD-Head)。架构如图 5 所示。首先使用一个Stem层来进行通道压缩,接着通过堆叠卷积层得到中间的特征层。最后,根据不同的任务计算自适应权重。分别测试了在TOOD-Head中使用vanilla卷积和基于repvgg的卷积的结果。
2.4、PAI-Blade
PAI-Blade是一个用于模型加速的简单且强大的推理优化框架。它基于许多优化技术,如Blade Graph Optimizer、TensorRT、PAI-TAO(Tensor Accelerator and Optimizer)等。PAI-Blade将自动搜索优化输入模型的最佳方法。因此,没有模型部署专业知识的人也可以使用PAI-Blade来优化推理过程。作者在EasyCV中集成了PAI-Blade的使用,让用户只需更改导出配置即可获得高效的模型。
2.5、EasyCV Predictor
除了模型推断,预处理功能和后处理功能在端到端目标检测任务中也很重要,而现有的目标检测工具箱往往会忽略这些功能。在
EasyCV中,我们允许用户灵活选择是否使用预处理/后处理程序导出模型。然后,提供了一个预测器api来执行高效的端到端目标检测任务,整个过程只需几行代码。
3、实验
在本节中,我们将汇报上述方法在COCO数据集上的消融研究结果 ,并且和YOLOXPAI与SOTA对象检测方法进行比较。
3.1、SOTA对比
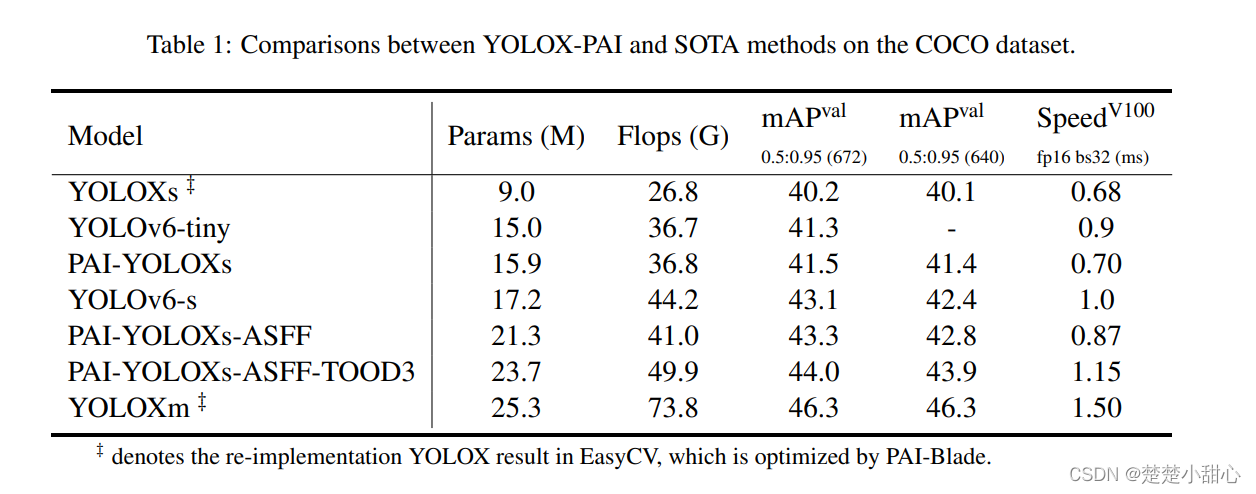
- 我们选择了在YOLOX-PAI中有用的改进,与SOTA YOLOv6方法在表1中进行了比较 。可以直观看出YOLOX-PAI 跟YOLOv6对应版本对比,快了很多。
- 具有更好的mAP(和YOLOv6-tiny相比0.2 mAP 和22%速度提升,与YOLOv6-s相比高了0.2 mAP和13%速度提升 )
3.2、消融研究
- backbone的影响
如表1所示:YOLOX用一个基于RepVGG的骨干实现更好的mAP,只牺牲一点点速度。它确实增加了更多的参数和计算量,需要更多的计算资源,但不需要额外的推理时间。考虑到性能,我们在EasyCV中将其作为灵活的配置设置。
- 颈部的影响。
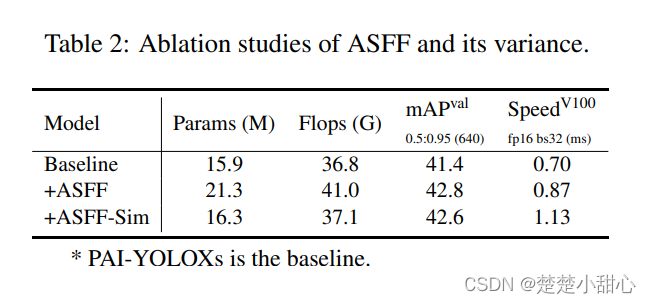
ASFF和ASFF_ Sim的影响如表2所示。
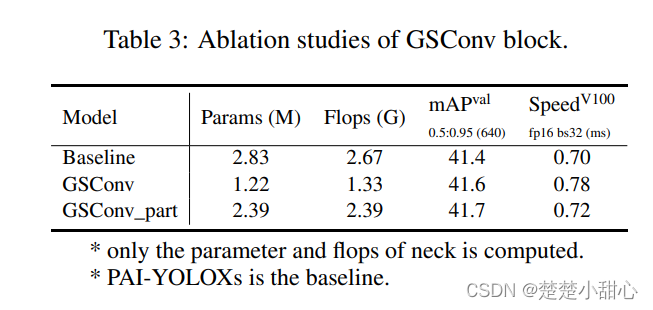
与ASFF相比,ASFF_Sim只需要增加一些参数和计算量就能提高检测结果。然而,在推理时间上会加大,我们将在未来实施CustomOP来优化它。影响GSConv的结果如表3所示,GSConv将带来0.3 mAP的提升,并减少3%的速度,在单个NVIDIA V100 GPU上。
- 头部的影响。
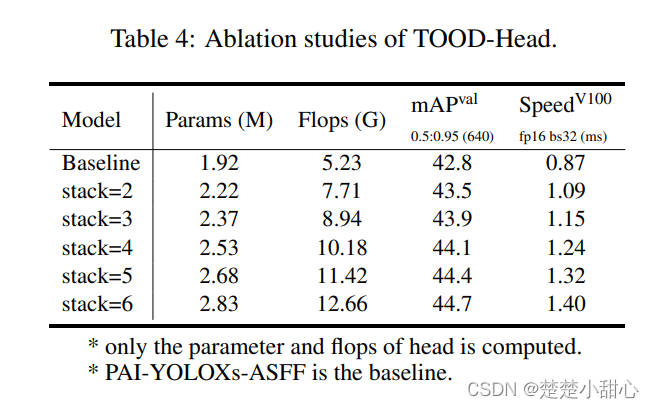
表4显示了TOODHead的影响。
我们研究了不同数量的内部卷积层对模型的影响。
研究表明,当添加额外的卷积层时,检测结果会变得更好。选择合适的超参数可以很好权衡的是速度和精度之间。我们发现,使用vanilla卷积替换基于repconv的卷积层时,结果会变得更糟。当堆叠的层数比较少的时候,使用基于Repconv的cls_conv/reg_conv层,可以稍微改善结果。
3.3、端到端结果
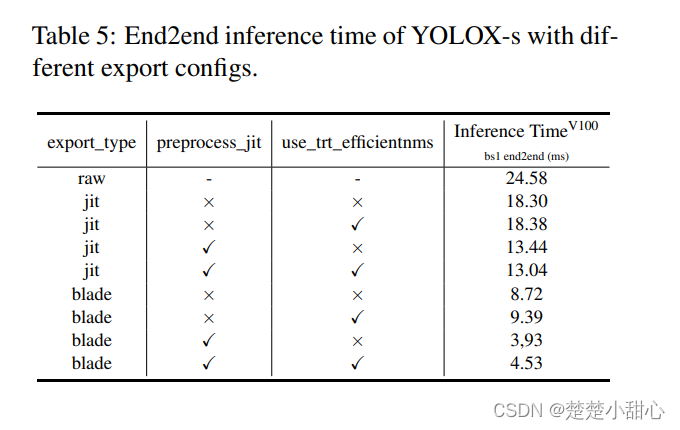
表5显示了具有不同导出配置的YOLOXs模型端到端预测结果。这个表中的关键字与EasyCV中的配置文件相同。很明显,blade优化有助于优化推理过程。此外,预处理过程可以通过导出的jit模型进行加速。至于后处理,我们仍在努力实现更好CustomOP,可以通过PAI Blade进行优化来获得更好的提升。在图1的右侧,可以看出,通过优化PAI-blade和EasyCV预测器,我们在可以在YOLOX上得到满意的端到端推理时间。
4、结论
- 在本文中,我们介绍了YOLOX-PAI,它是基于EasyCV的YOLOX的改进版本。
- 通过改进模型架构和PAI blade,它在40mAP到50mAP中取得了最先进的目标检测结果。
- 我们还提供了一个简单有效的预测api来执行端到端目标检测。
- EasyCV是一个专注于SOTA的多功能工具箱计算机视觉方法,特别是在自监督学习和视觉转换器。我们希望用户能够使用Easy CV来快速进行计算机视觉任务,爱上计算机视觉。
5、致谢
我们感谢所有在EasyCV中重新实现的算法的作者,以及他们在github社区的贡献。我们也感谢郭天佑、蒋娜娜、方海鹏、陈嘉宇和阿里巴巴PAI团队的许多其他成员他们的贡献,在建设YOLOX-PAI和EasyCV工具包上。