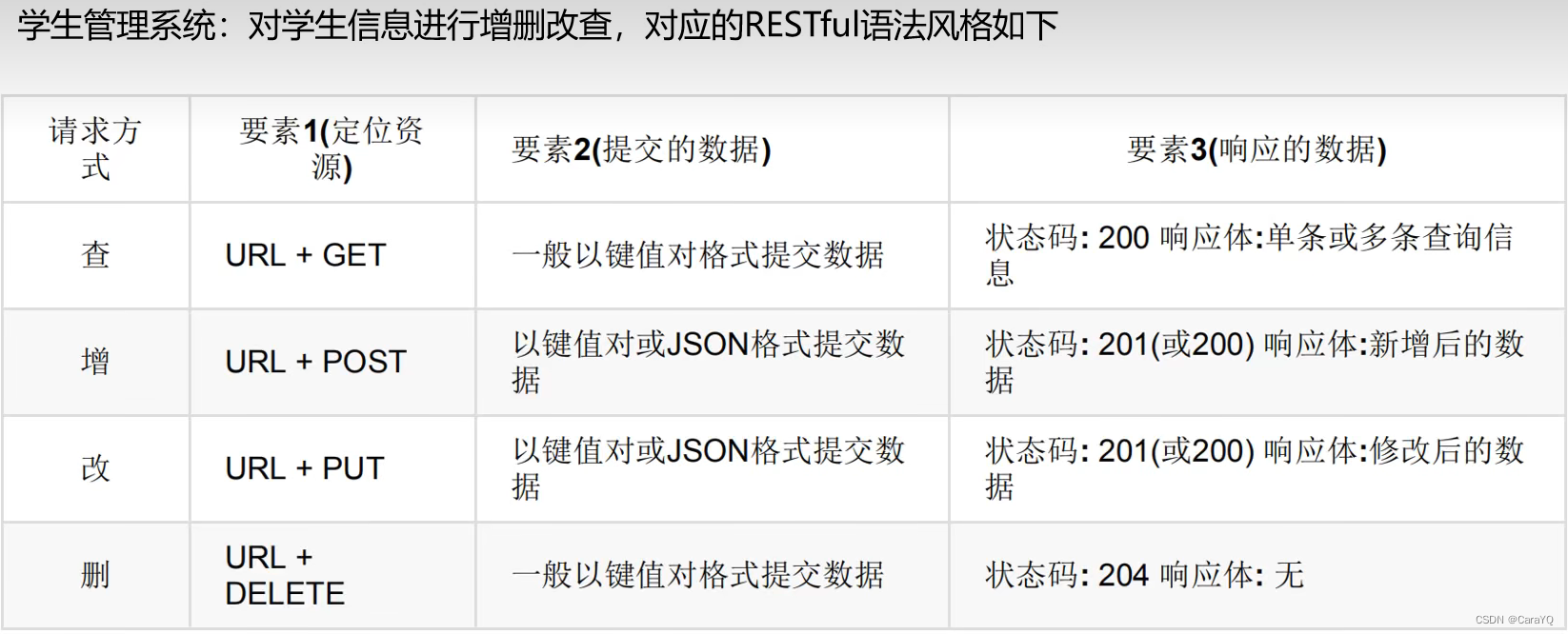
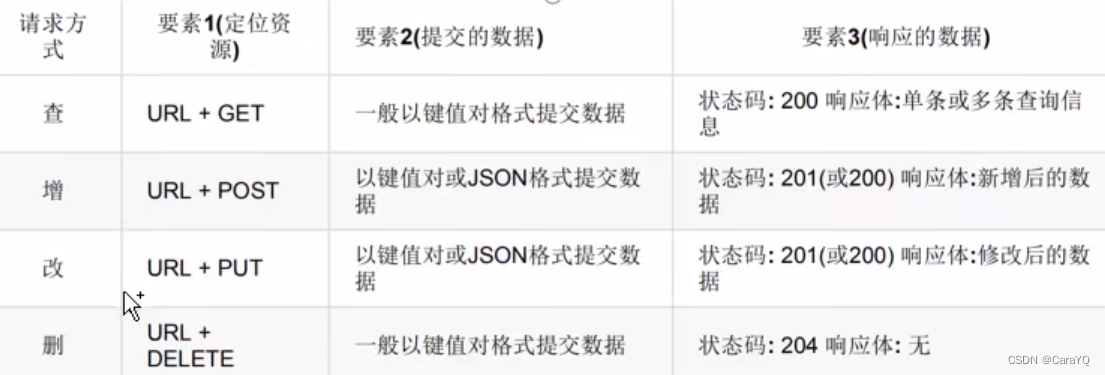
目录
环境配置
安装Java环境
安装jmeter
安装python环境
一、安装python环境 推荐python3.5版本
双击,一路next
- 将pip添加到环境变量中:python的安装目录scripts中有个pip.exe,将pip.exe的绝对位置添加到系统变量的path中(新增一条,复制粘贴进去)
- 将python添加到环境变量中:将python.exe的绝对位置添加到系统变量的path中(新增一条,复制粘贴进去)
二、在项目文件夹中cmd,安装依赖模块:pip install -r requirements.txt -i https://pypi.douban.com/simple
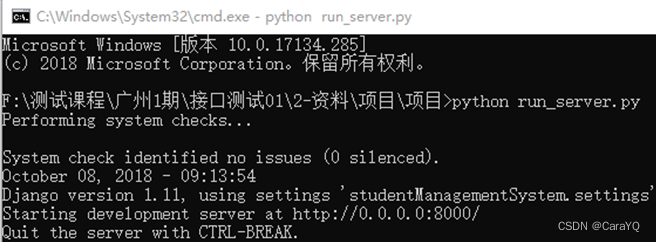
三、在项目文件夹中cmd,启动命令:python run_server.py,弹出下面窗口即可
数据库配置
双击运行(6小时自动化jmeter工具笔记资料\入门篇\入门篇资料\资料\sqlitestudio-3.1.1\SQLiteStudio中)
将下列文件(6小时自动化jmeter工具笔记资料\入门篇\入门篇资料\资料\项目\项目\studentManagementSystem中)
拖拽到:
线程组
一、进程:正在运行的程序
二、线程:是进程中的执行线索
三、线程组:进程中有许多线程,为了方便管理,可以对线程按照性质分组,分组的结果就是线程组
三者关系:一个进程可以包含多个线程组,一个线程组可以包含多个线程
例:迅雷下载电影
喜剧片:西虹市首富、大话西游、喜剧之王
恐怖片:贞子、咒怨、生化危机
迅雷是进程,喜剧片、恐怖片是进程,合在一起是进程组
四、并发执行:多个线程同时执行

右边的HTTP请求是并发执行
五、顺序执行:多个线程顺序执行
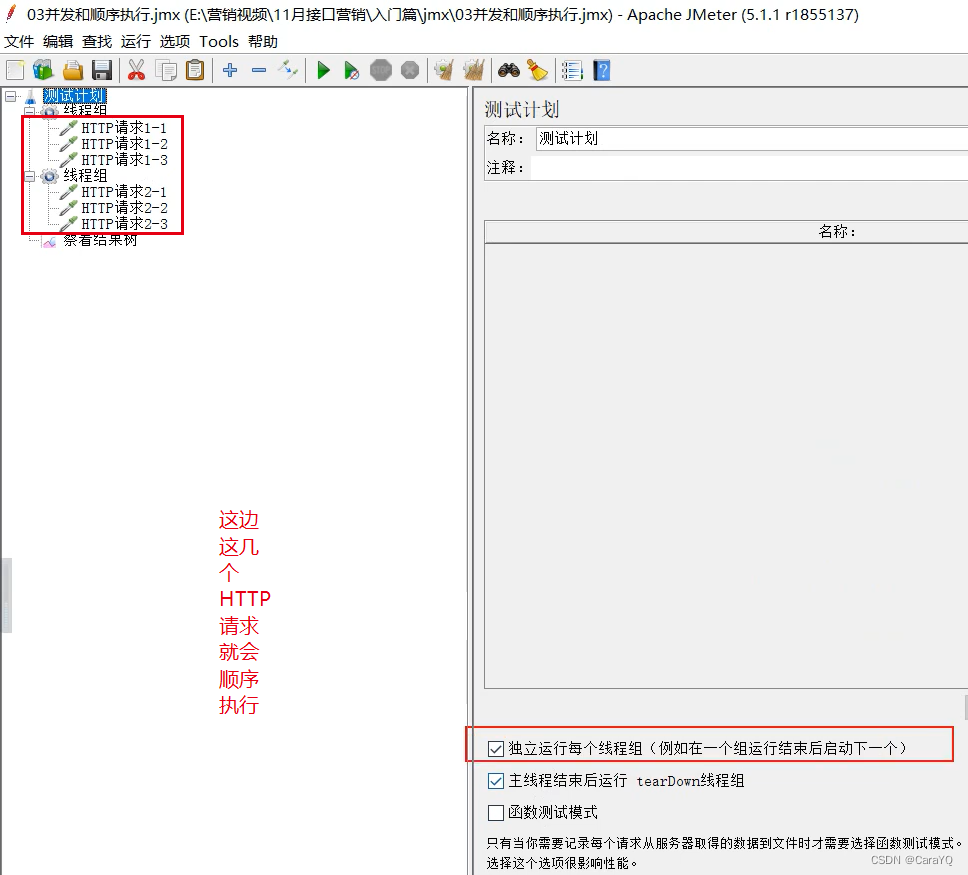
六、setUp线程组:最优先执行的线程组
七、tearDown线程组:最后执行的线程组
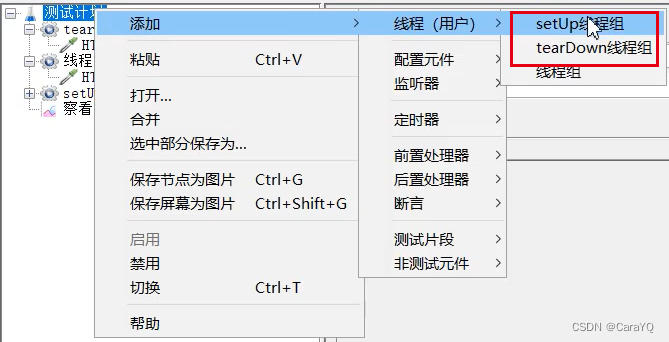
不管你勾不勾选【独立运行每个线程组】,setUp线程组始终是最优先执行的线程组,tearDown线程组是最后执行的线程组
八、线程组常用属性:
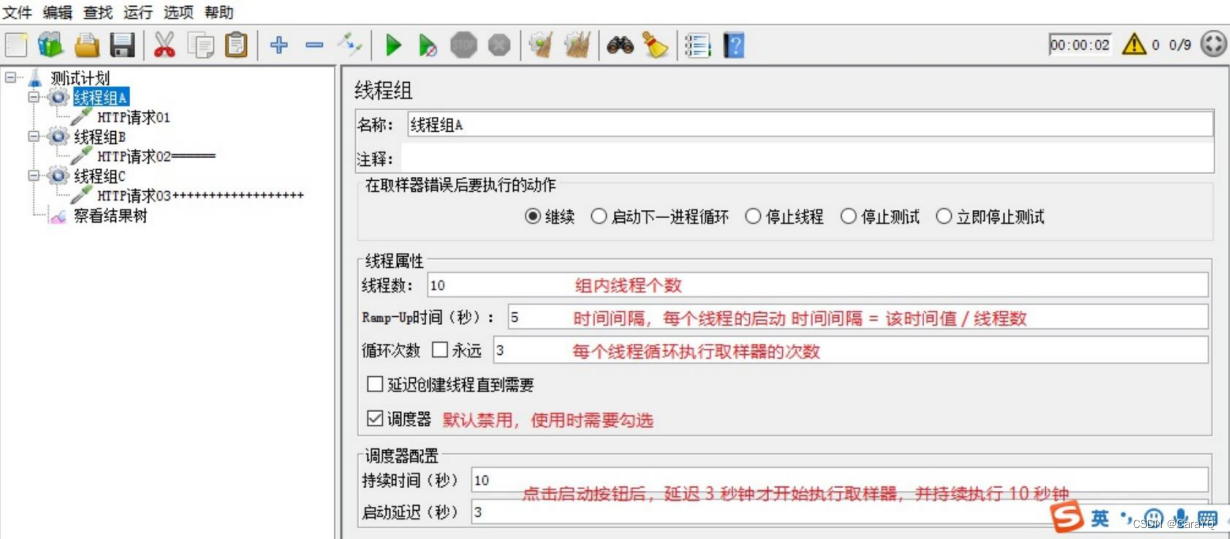
线程数:模拟的用户个数
Ramp-up period:给程序的准备时间
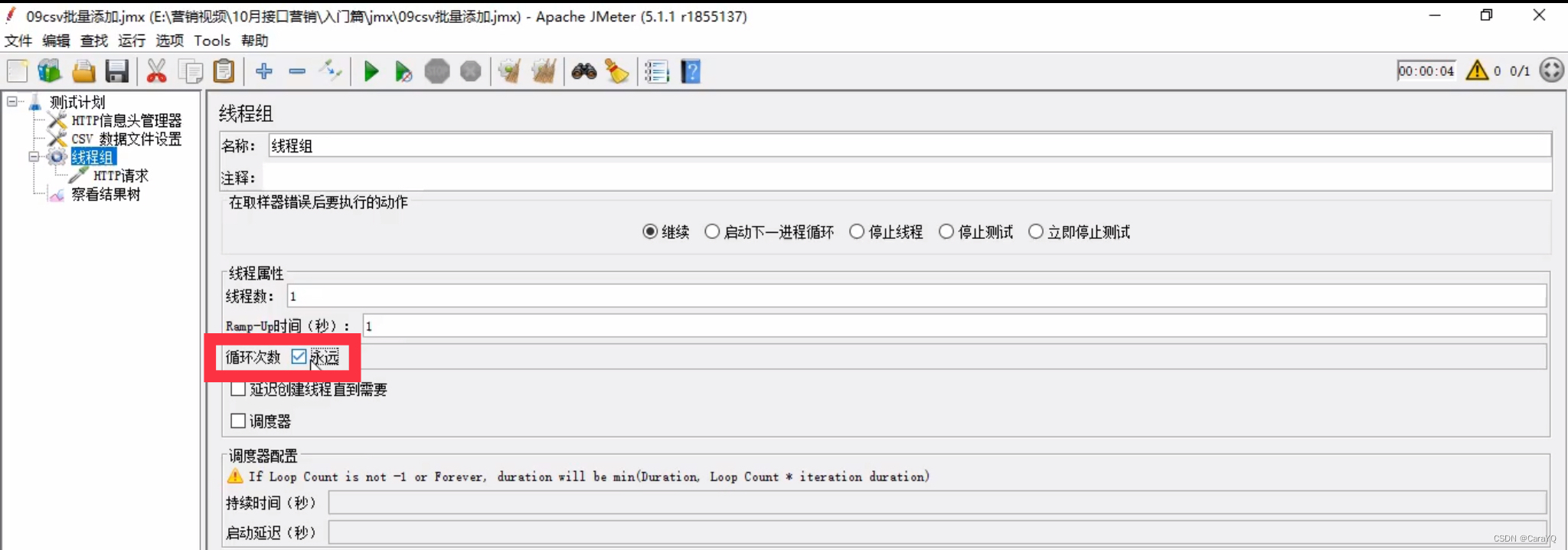
循环次数:每个用户执行的次数,如果线程数为3,循环次数为2,表示每个用户执行2次,一共3个用户,一共执行6次。永远代表一直执行下去
调度器:配合下面的持续时间、启动延迟使用。持续时间配合【永远】使用,在该持续时间内不停发请求。启动延迟:点击启动按钮后,延迟一段时间再启动
HTTP
HTTP请求默认值
查看我们请求的地址ip、端口号都是一样的:

我们每次在HTTP请求中都会设置一样的ip和端口号

太麻烦了,使用【HTTP请求默认值】优化一下,在测试计划中新增一个【HTTP请求默认值】:
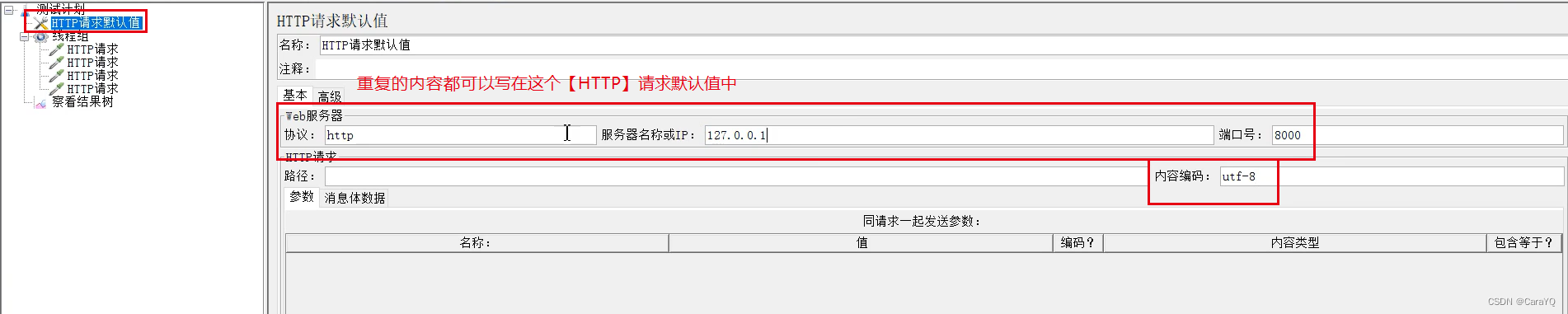
在该页面配置重复的内容
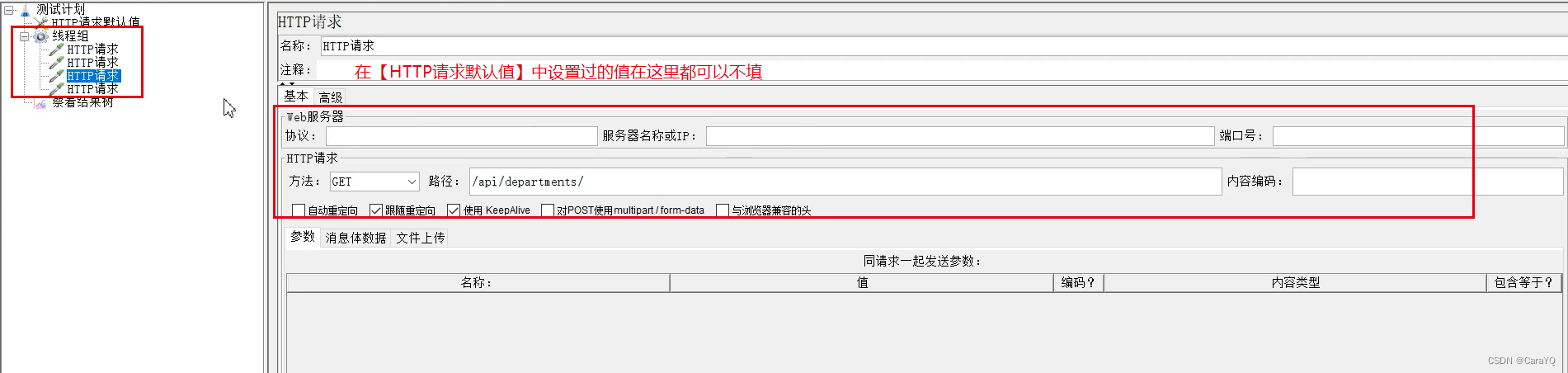
在具体的HTTP请求中填写其余内容
HTTP信息头管理器
如果要进行新增操作,需要使用HTTP信息头管理器,在HTTP信息头管理器中需要配置跟json数据有关的参数,因为新增操作需要传递一些json数据,需要json数据就必须设置HTTP信息头管理器,告诉浏览器你新增的数据是什么类型
- 添加HTTP信息头管理器
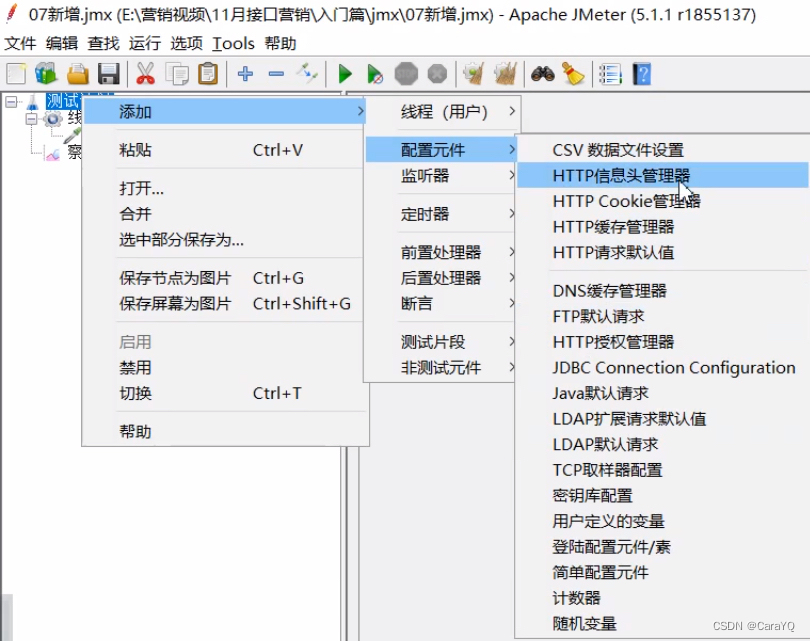
- 内容:

- 要添加的数据
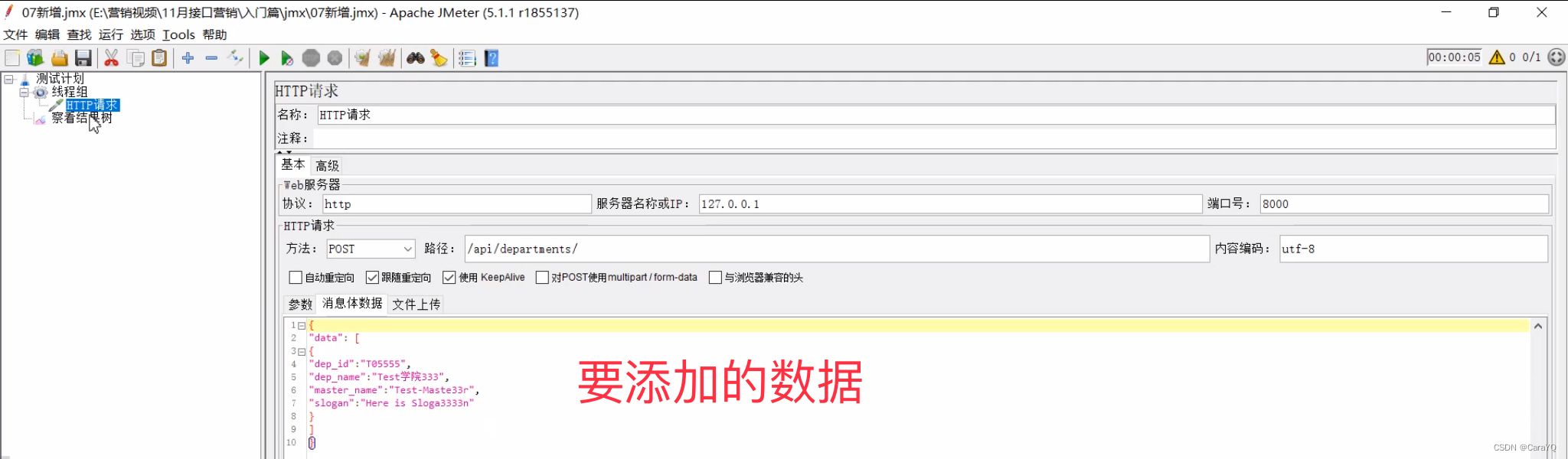
- 启动
参数化

用户定义的变量
- 添加用户定义的变量
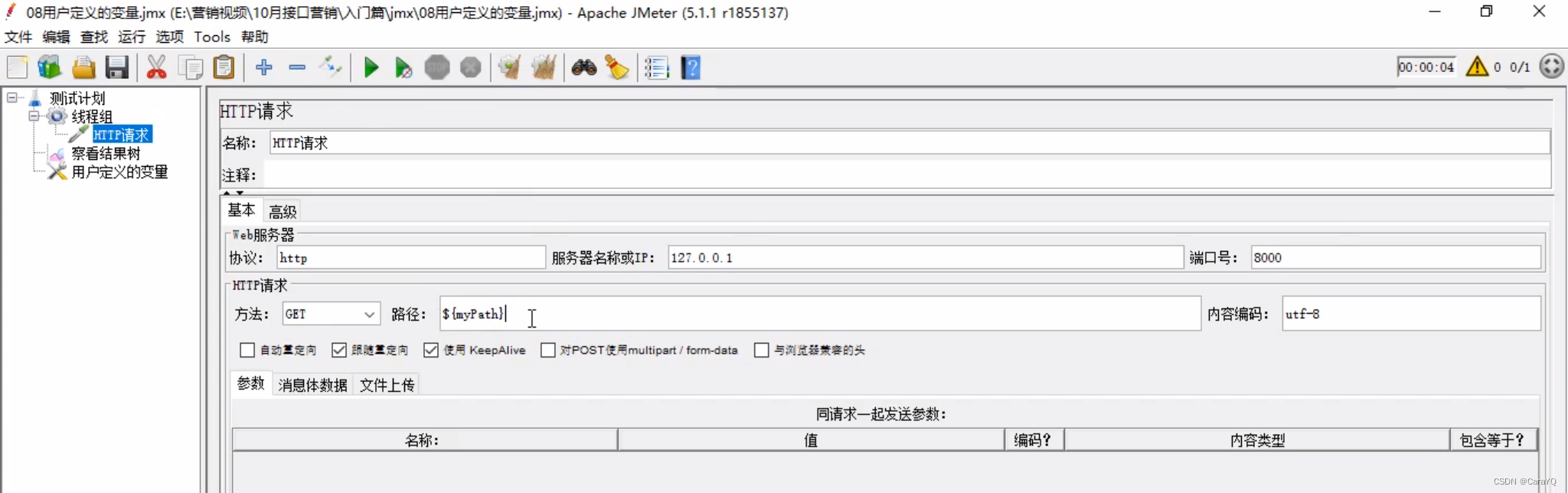
- 设置变量及要复用的内容

- 以后在http请求中想要使用变量里的内容,使用
${变量名}调用变量即可
csv数据文件设置
csv实现批量添加

- 新建csv.txt文件,在里面写你要存储的值,值和数据库中的字段是一一对应的,用逗号隔开
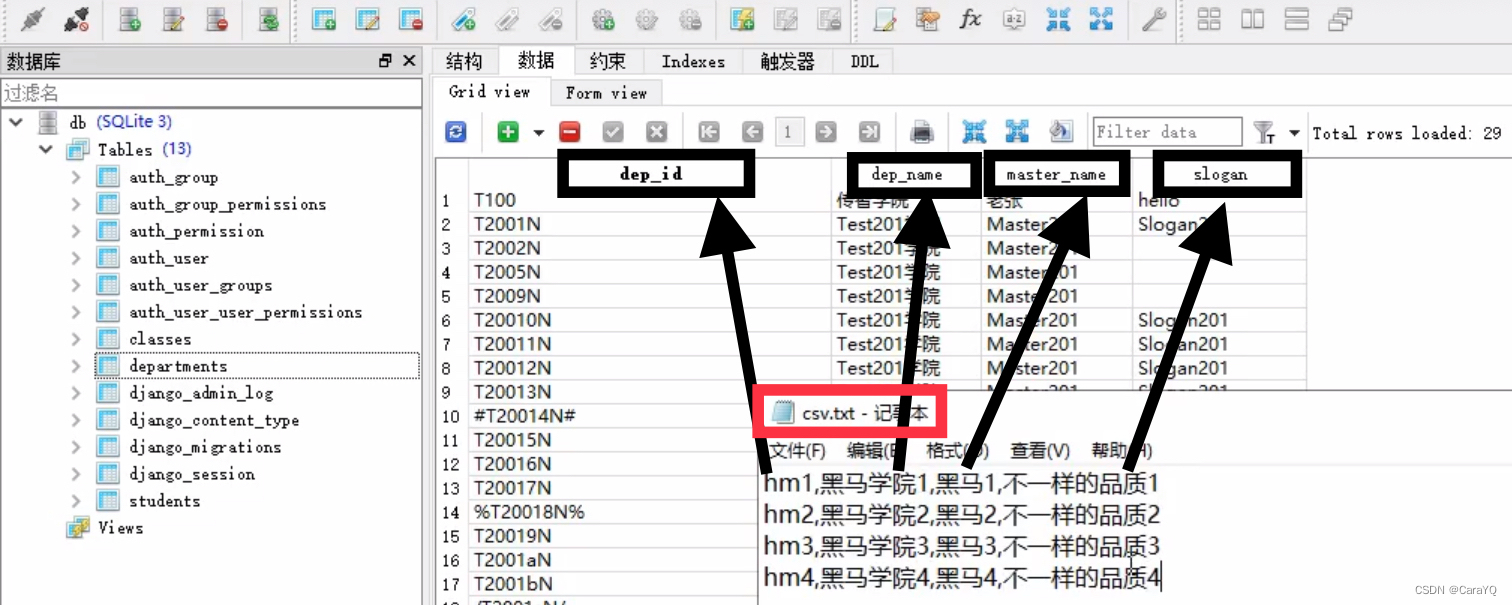
- 保存csv文件时注意一定要是utf-8
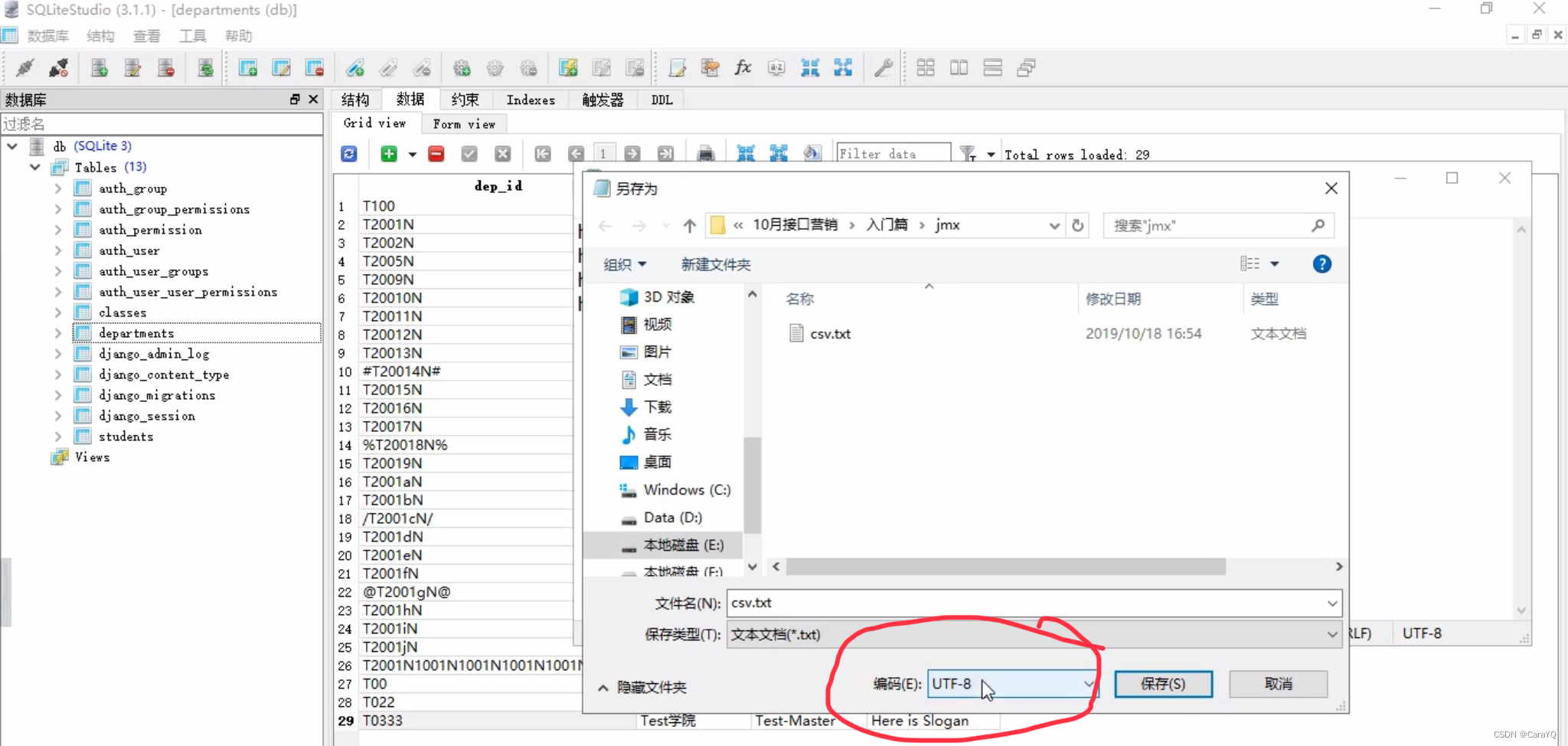
- 批量添加csv中的数据
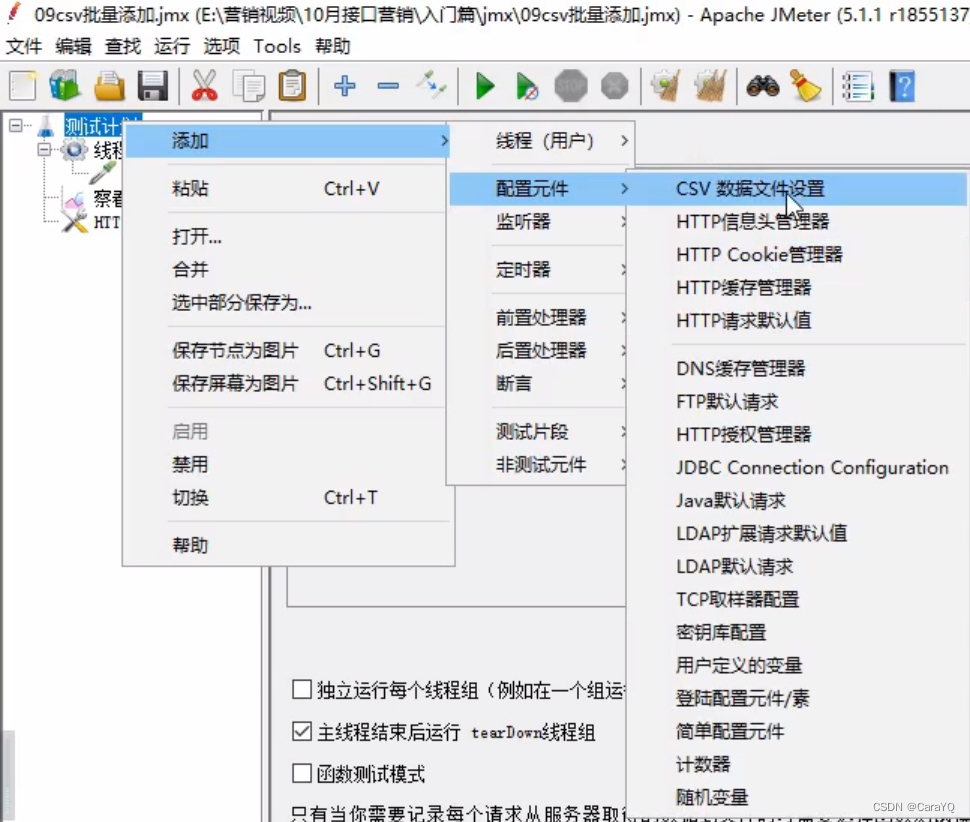
(1)添加csv数据文件设置
(2)填写内容:
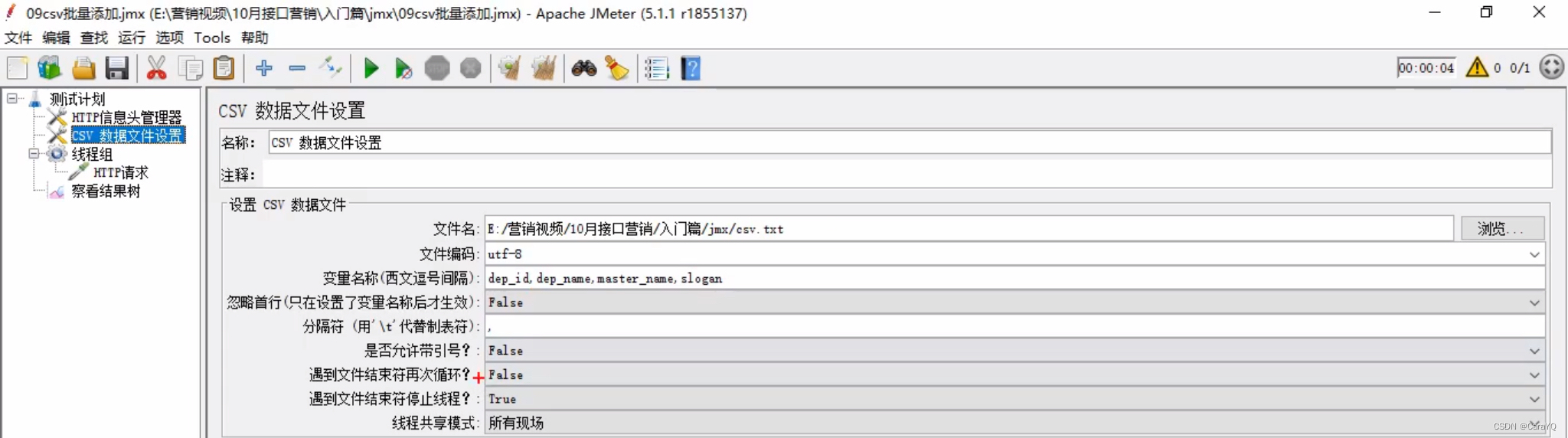
名称:csv.txt文件
文件编码:utf-8,也就是你保存csv.txt时的编码格式
变量名称:csv.txt文件中的数据对应的变量名
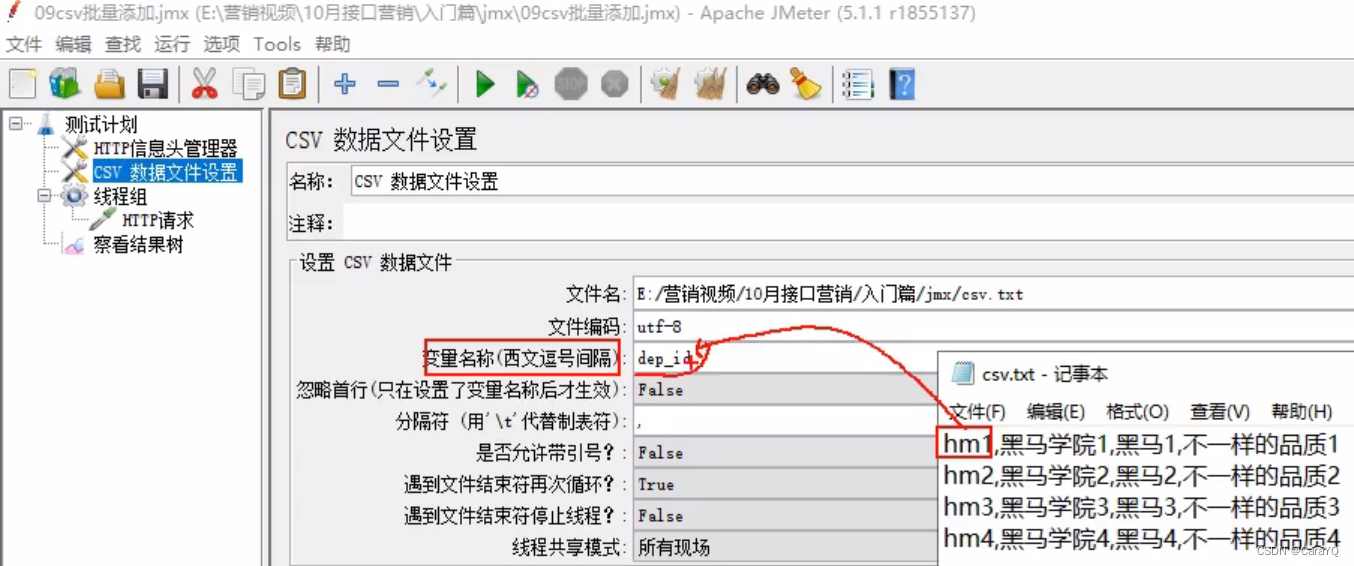
分隔符:csv.txt文件中数据的分隔符,此处是逗号
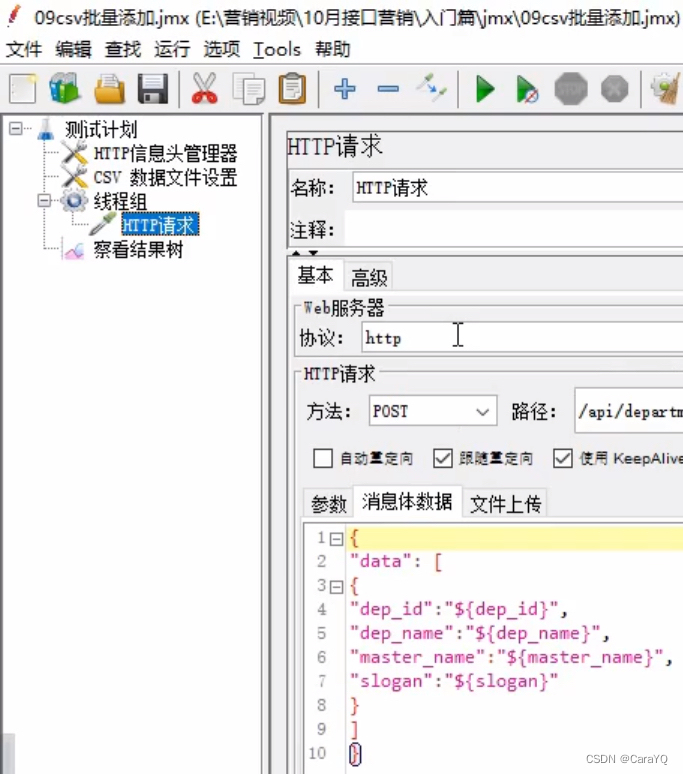
遇到文件结束符再次循环:整个csv.txt文档中的数据添加完了是否从头再次添加? - 在上传数据时,消息体数据以
${变量名}的方式将csv中的数据导入模板,变量名(右边的值)就是填写csv数据文件设置中的变量名
- 线程组循环次数勾选永远
用户参数
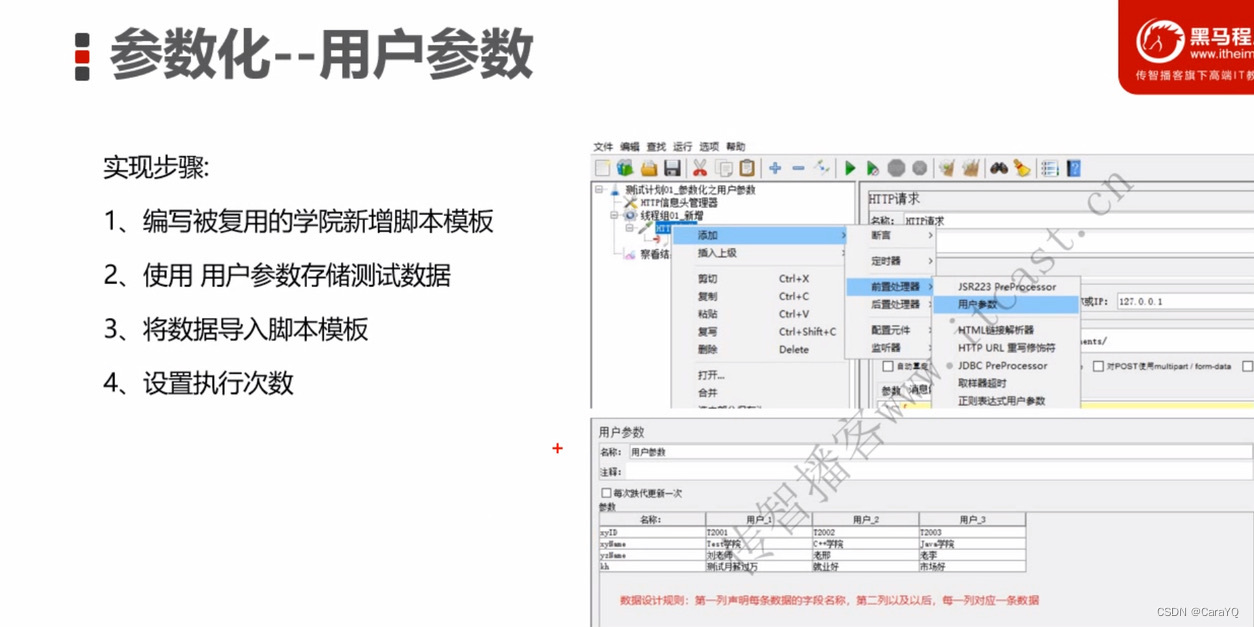
- 新增用户参数
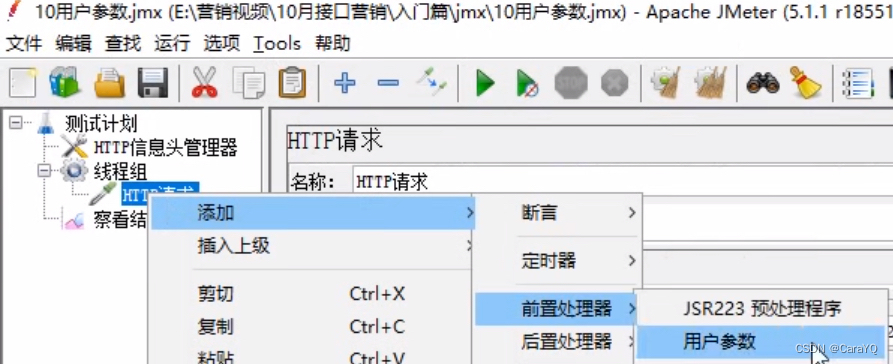
- 配置用户参数:添加变量是添加一列,添加用户是添加一行。
名称:数据库中的字段名
用户:数据
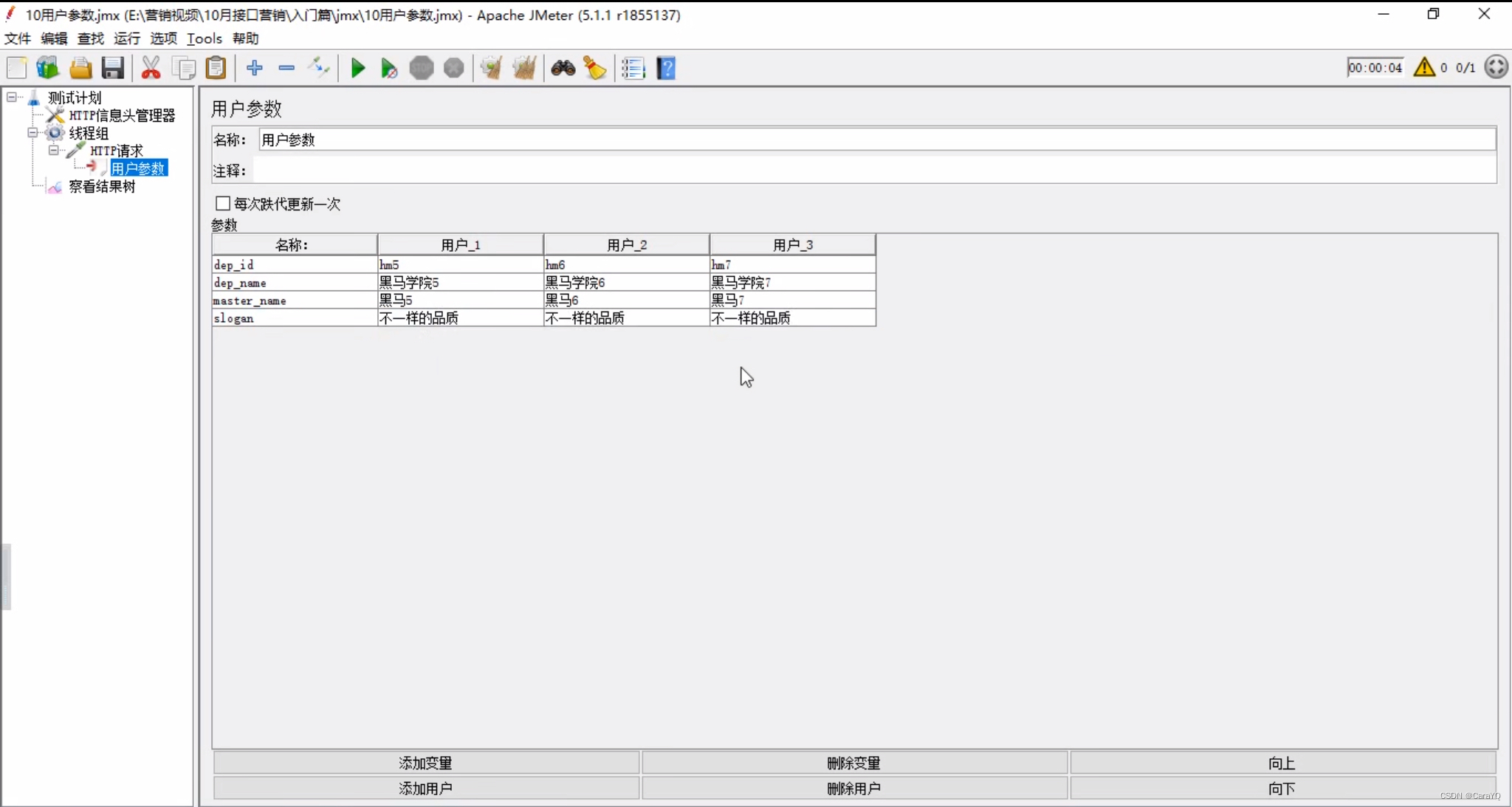
- 发送的数据中要引用你上面定义的名称
- 你在上面设置了多少个用户,就在线程组中设置多少个线程数
函数
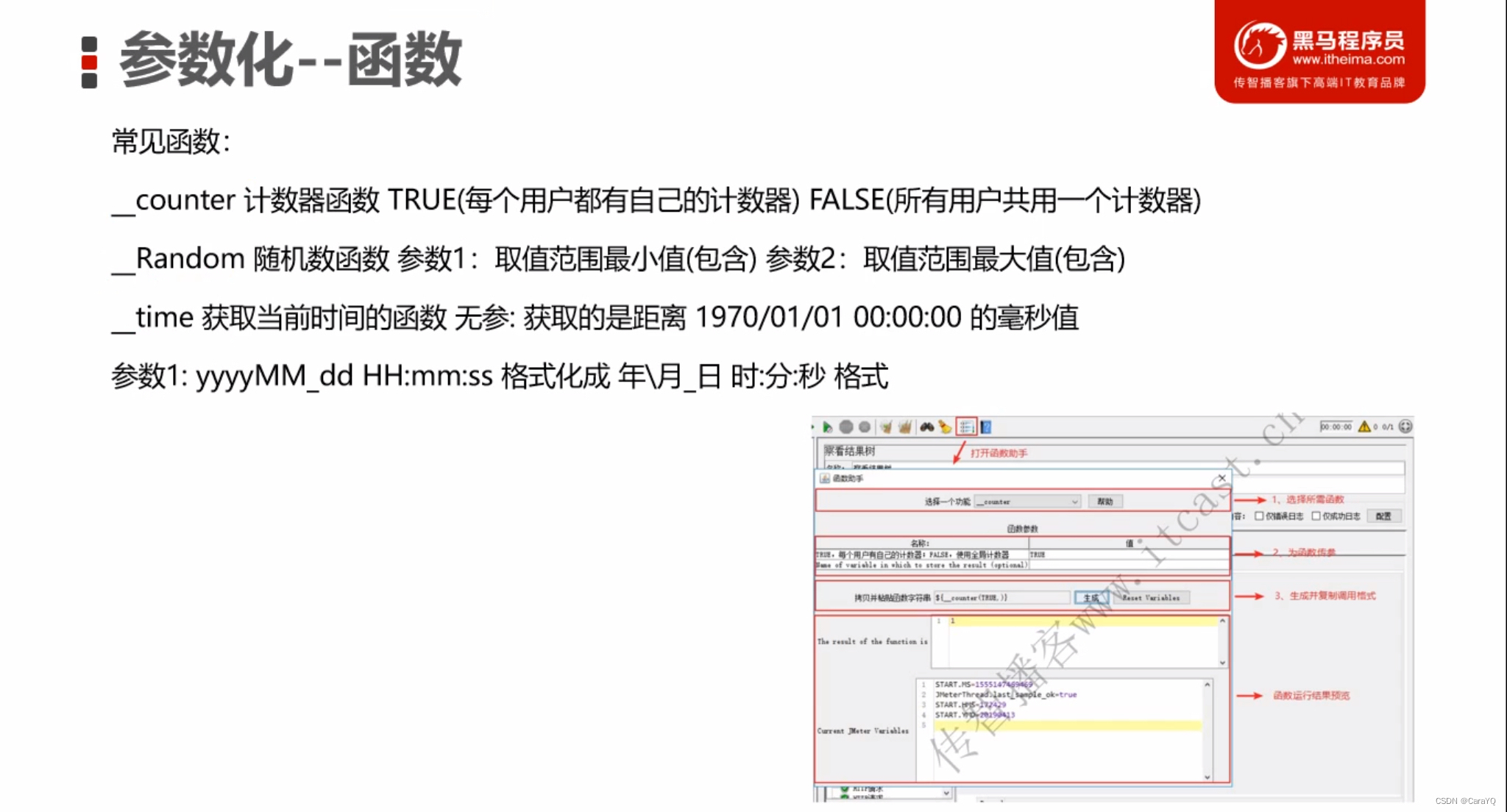
计数器函数
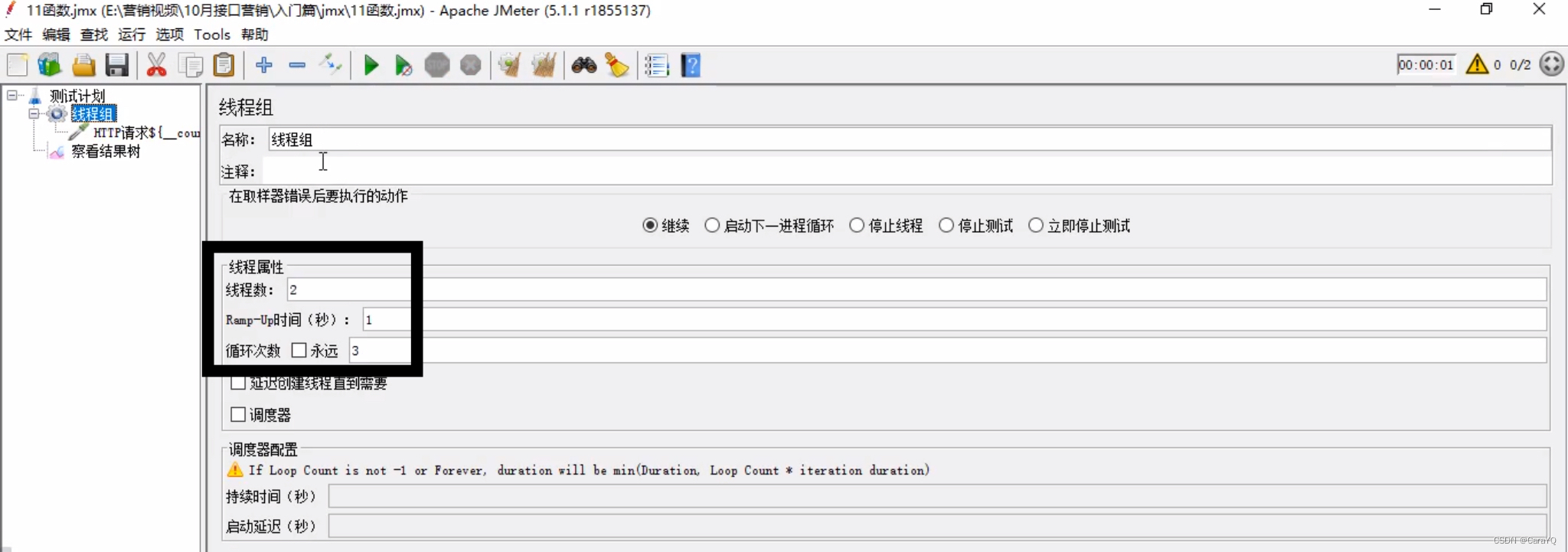
以上一共发6次请求,我希望察看结果树中每个请求都有编号,可以使用count函数来实现,点击函数助手,选择一个函数,下面先让每个用户有自己的计数器,然后点击生成,会生成一段代码
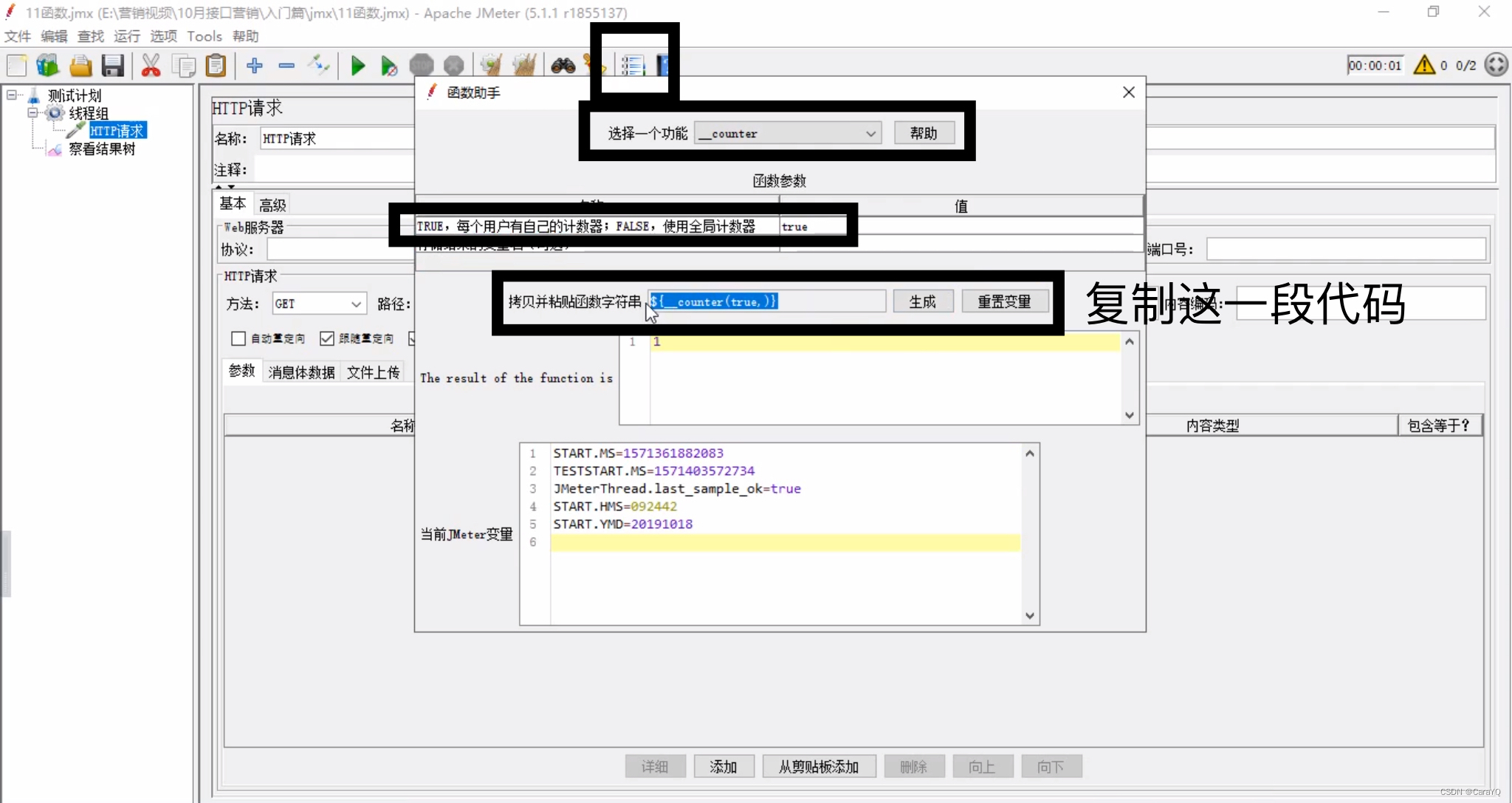
将这段代码复制到任何你想计数的地方
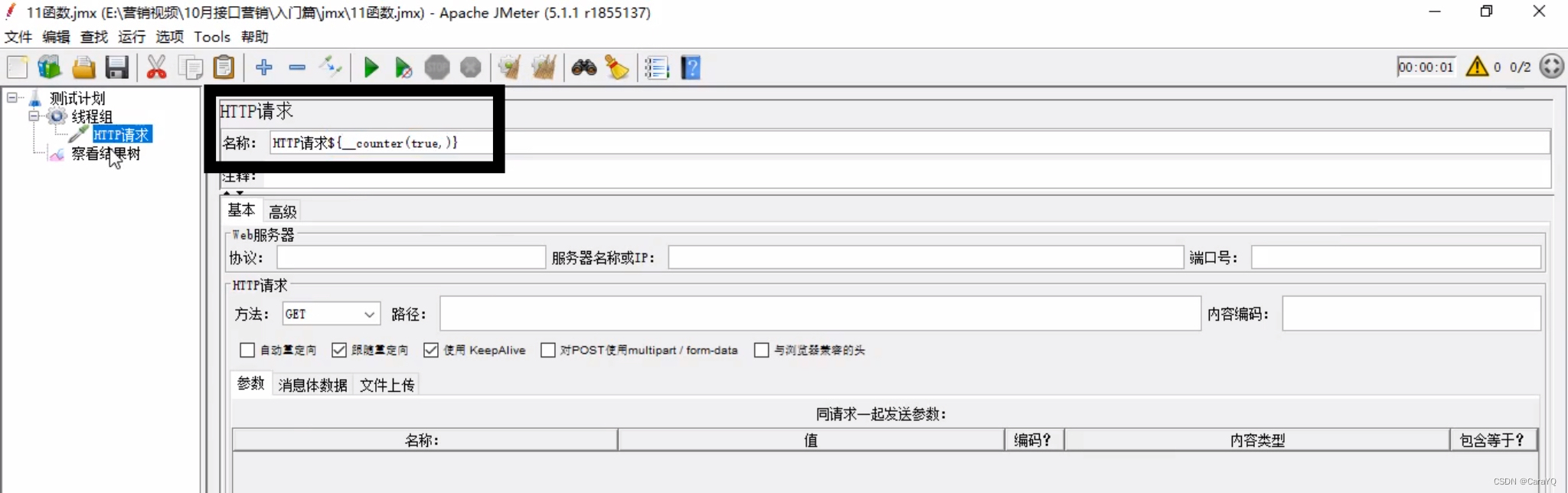
这样,并发的2个线程发的3次请求都有编号
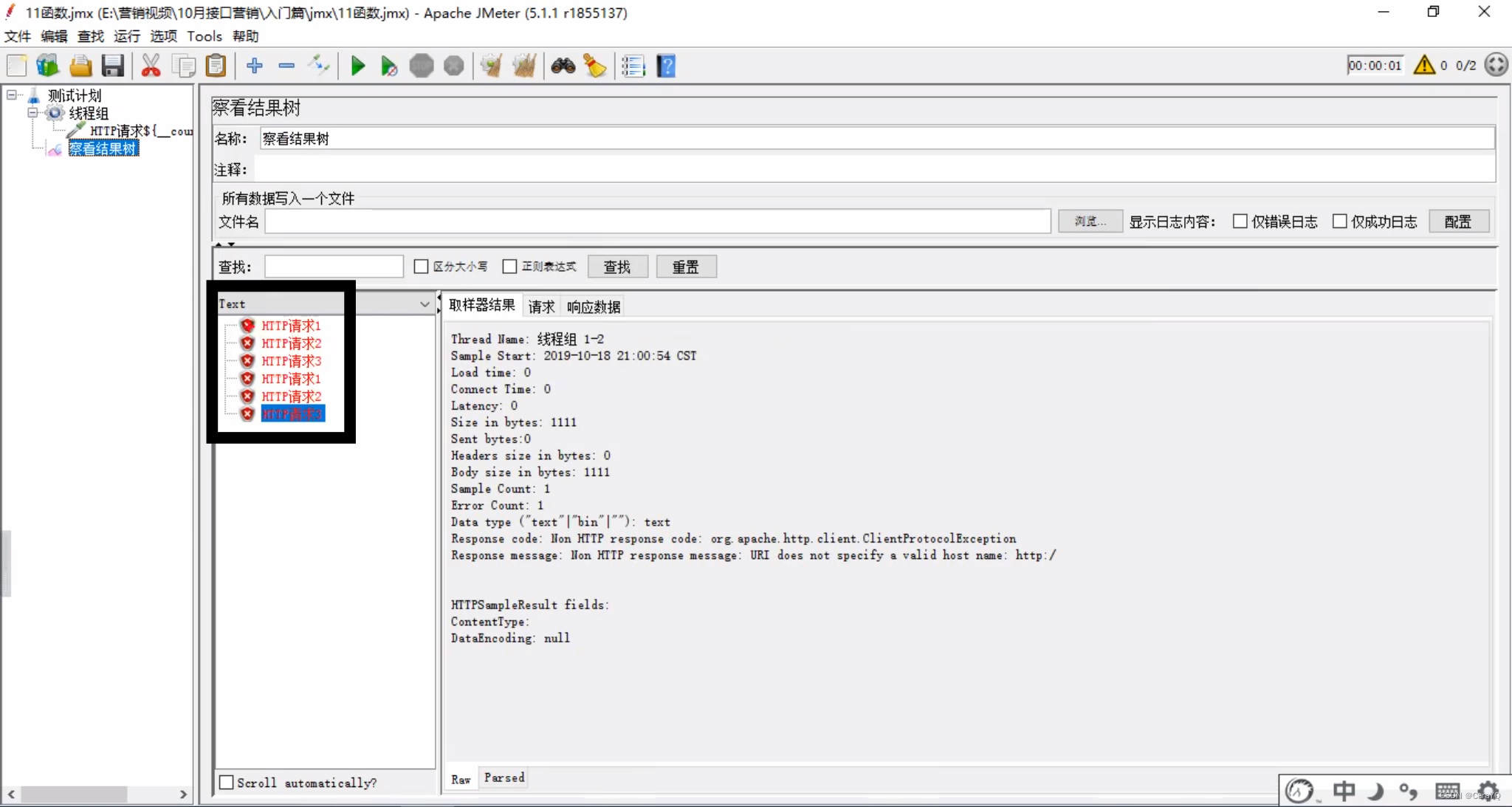
若当时选择使用全局计数器,运行结果
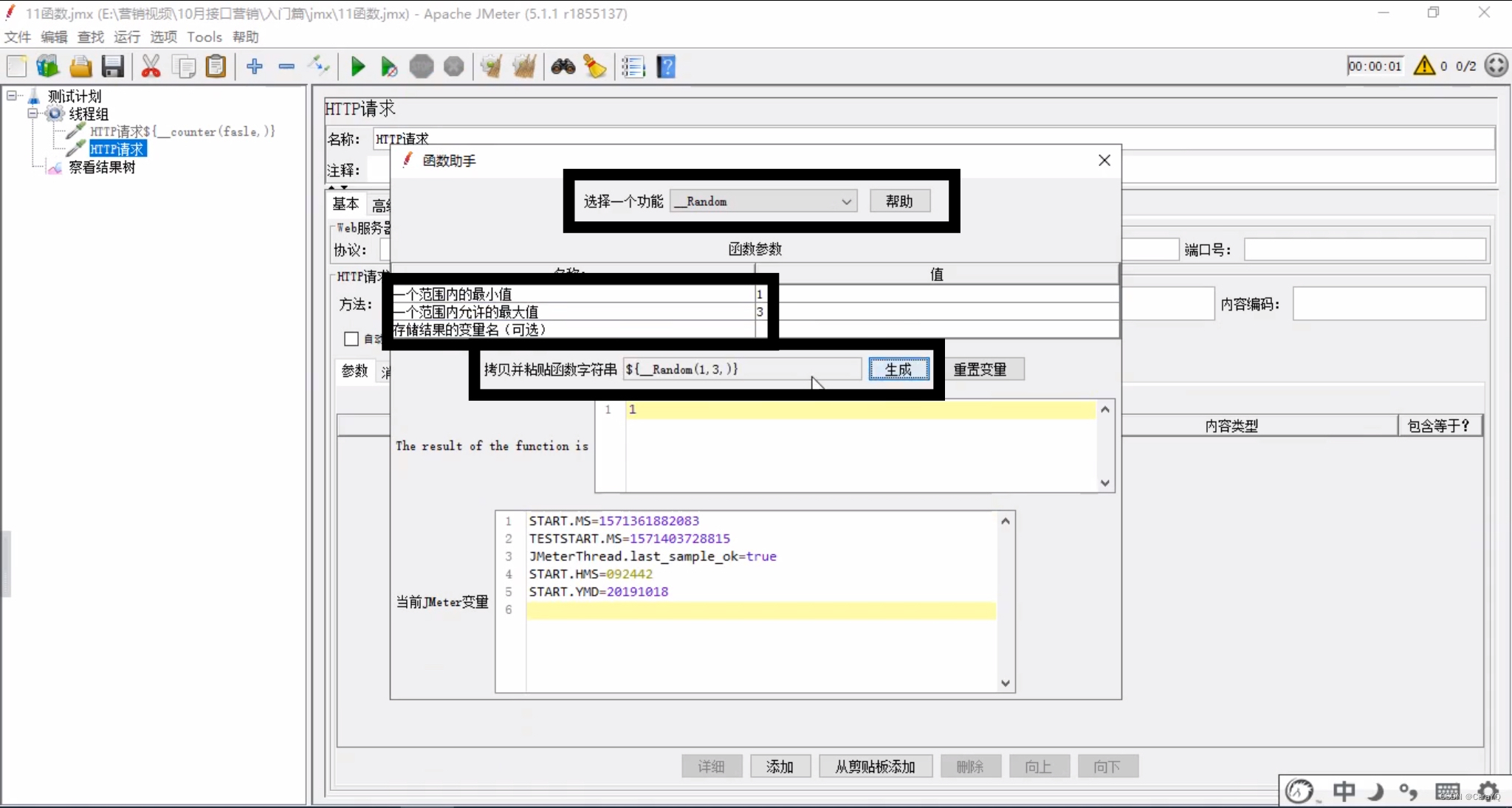
随机数函数
右击可以禁用掉一个请求
使用方法同count函数,这里是闭区间
将生成的代码粘贴到任何你要使用的地方
启动后
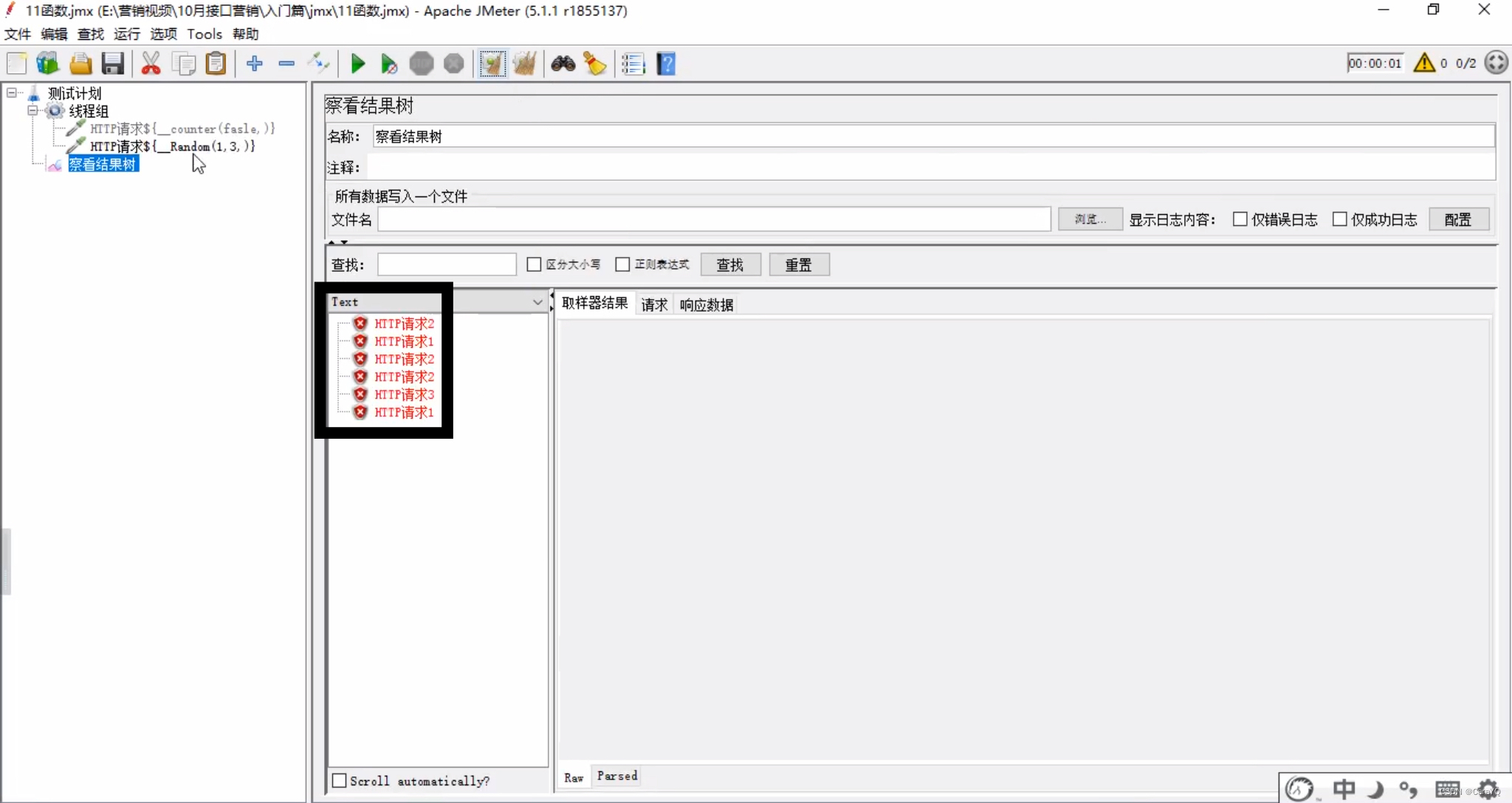
时间函数
使用方法同上
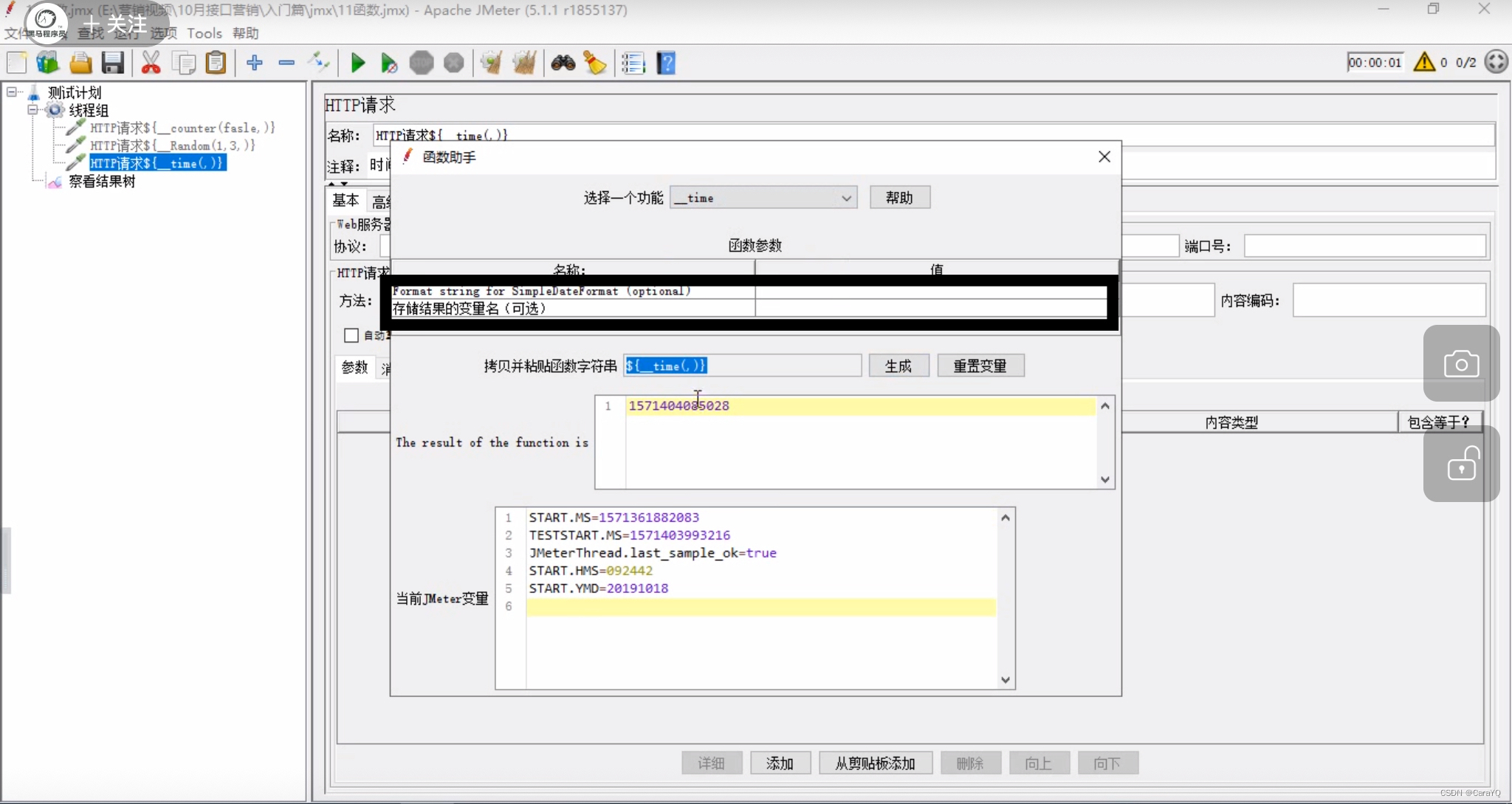
什么都不写,生成当前时间的时间戳
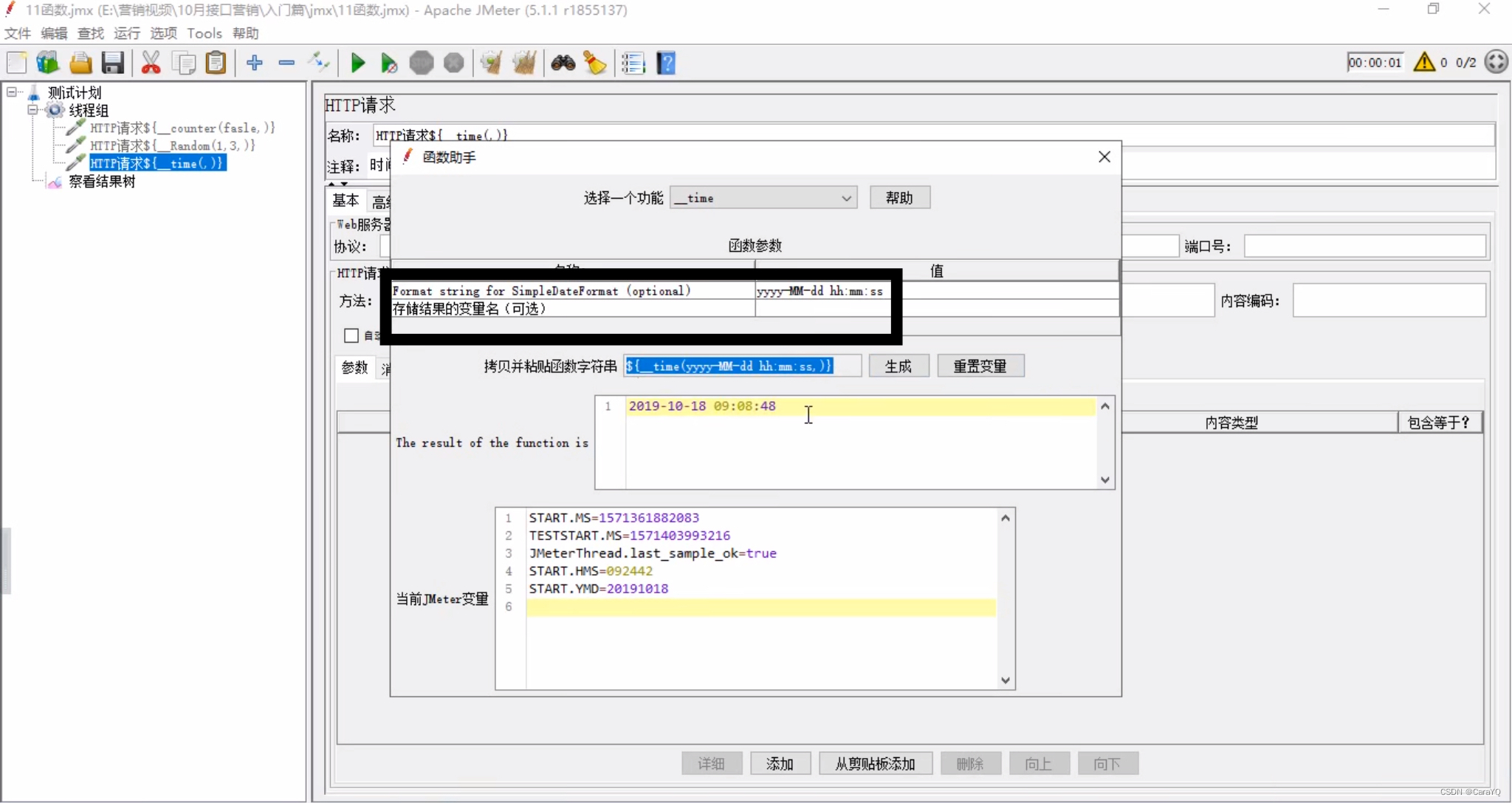
指定格式,生成当前时间的格式
直连数据库

- 添加第三方jar包:
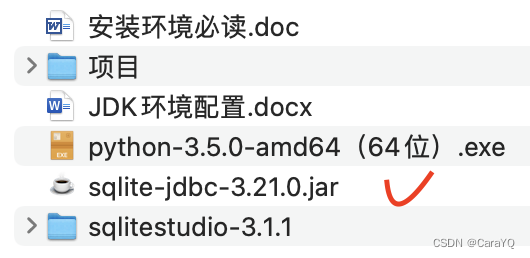
点击浏览,将上面这个jar包添加进来,如下所示:
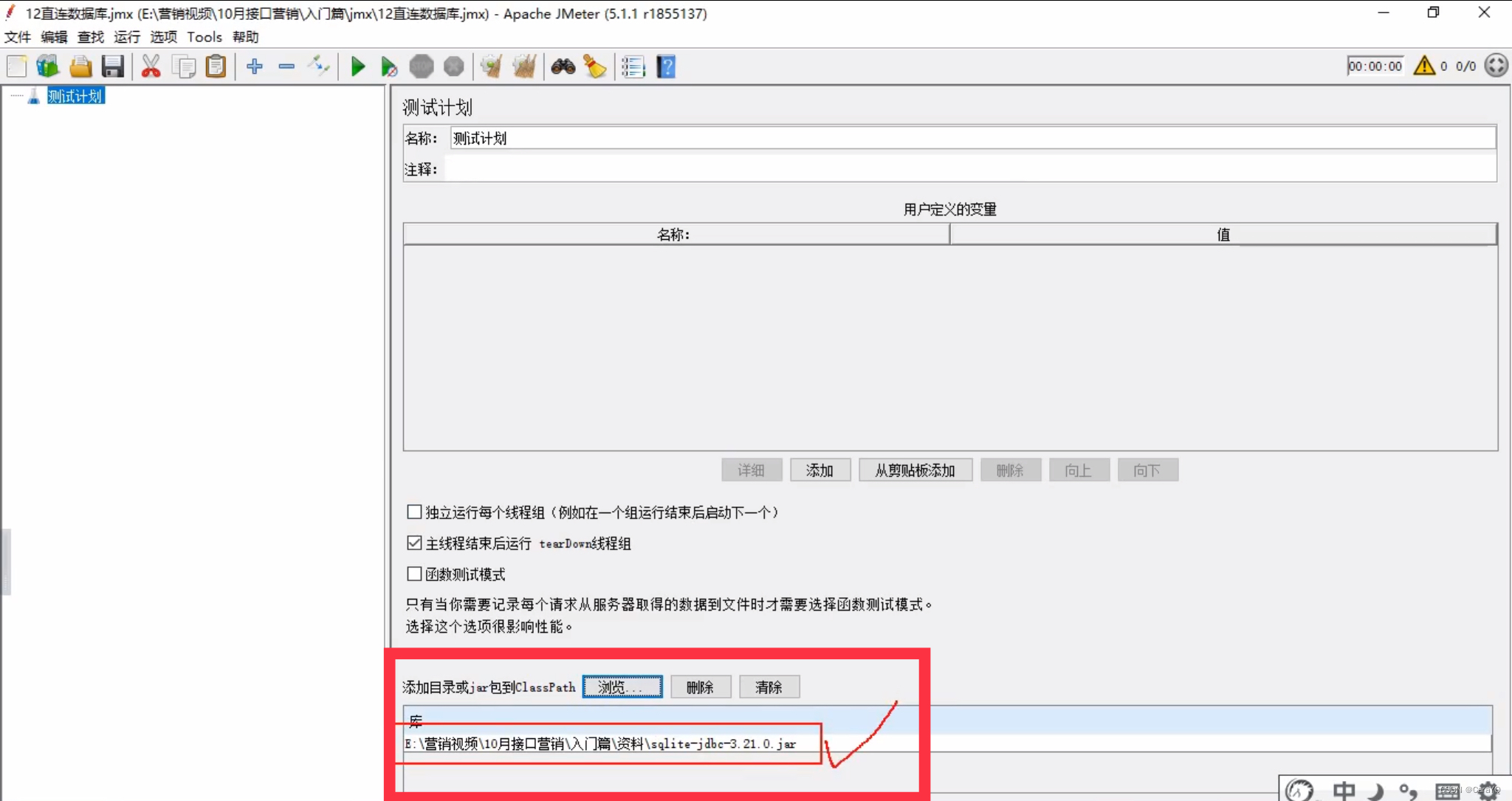
只要添加了这个jar包,jmeter就可以直连数据库了 - 在jdbc connection configuration中添加数据库连接所需配置:
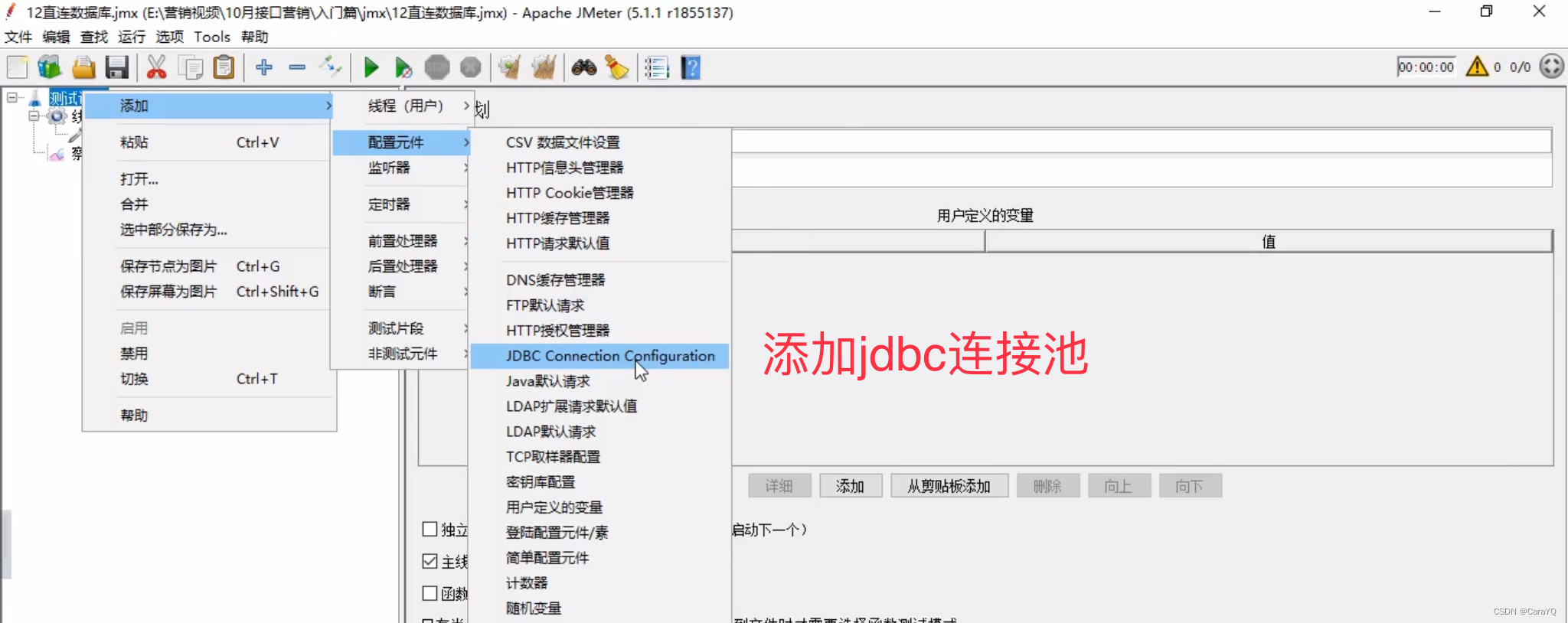
格式如下:
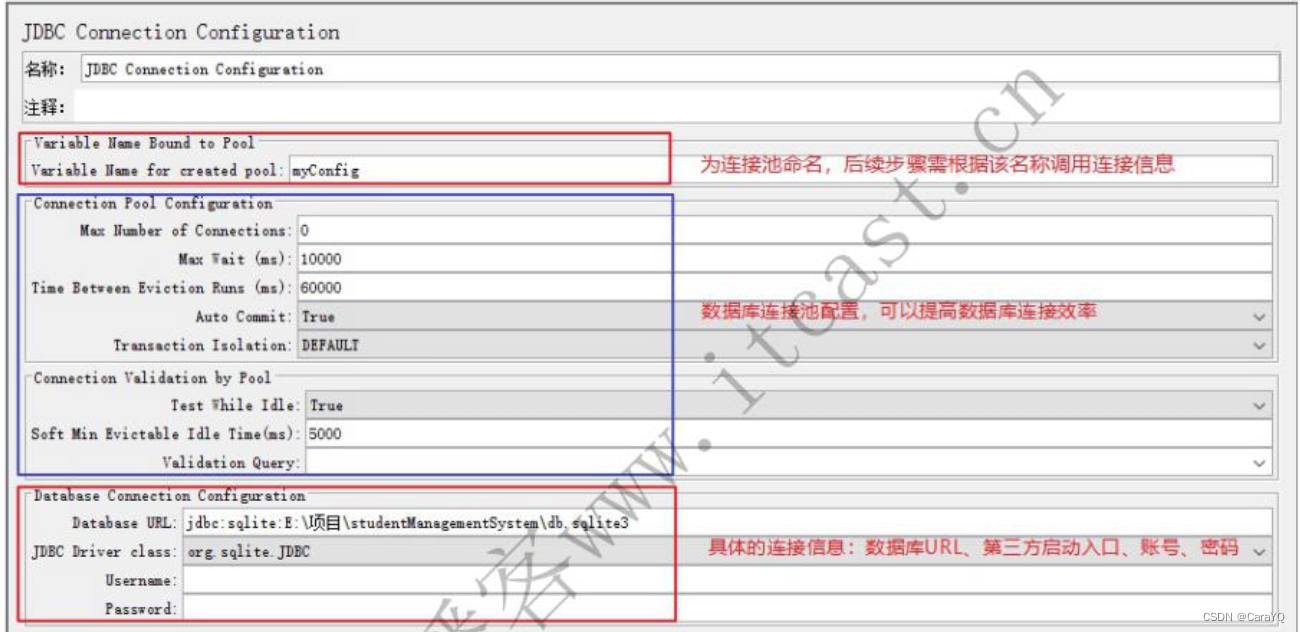
具体如下:
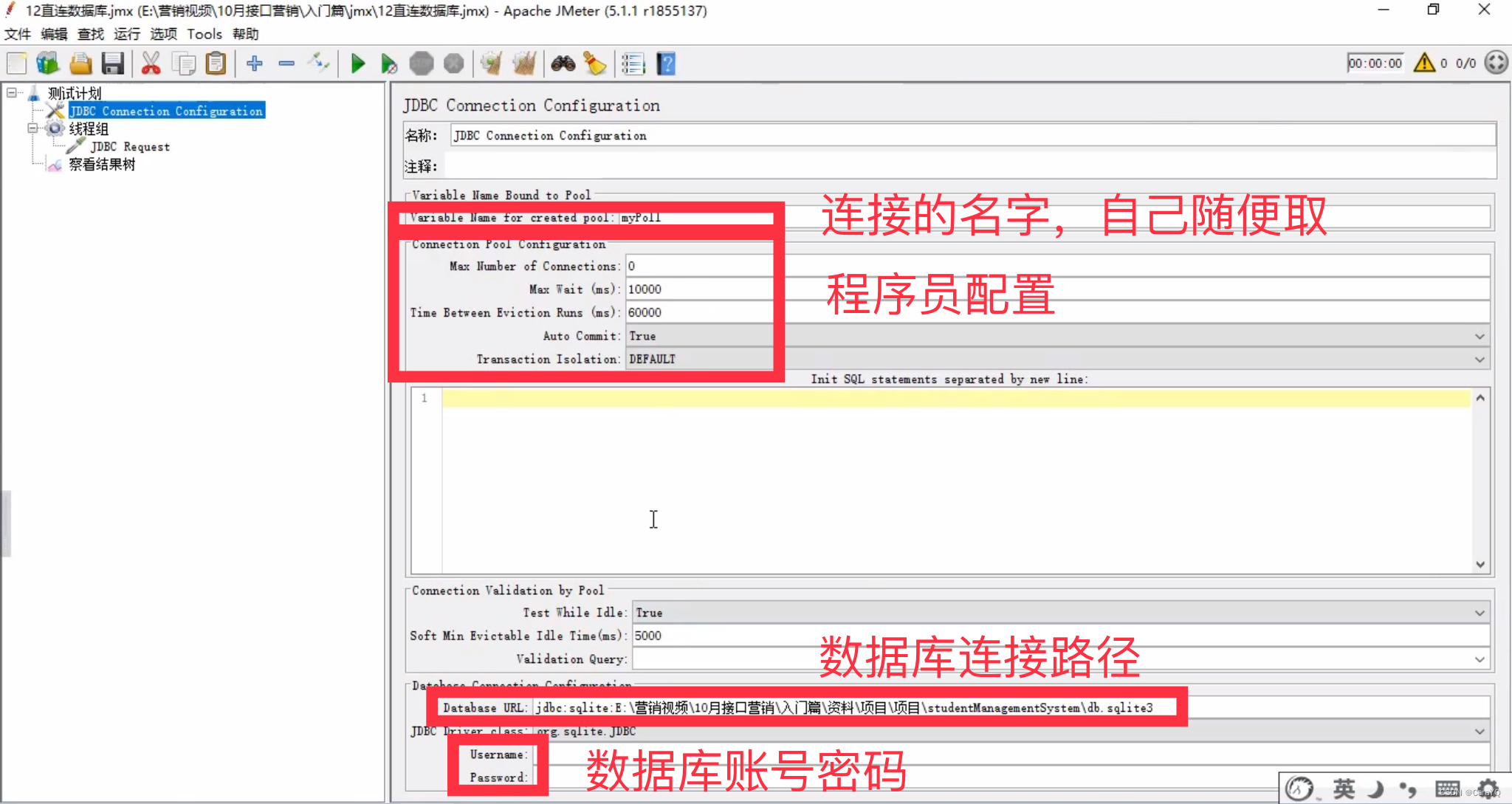
- 数据库连接路径需要写前缀:
jdbc:sqlite:- jdbc driver class中选择你使用的数据库
- 在线程组中添加的取样器就不再是http请求,而是jdbc request:
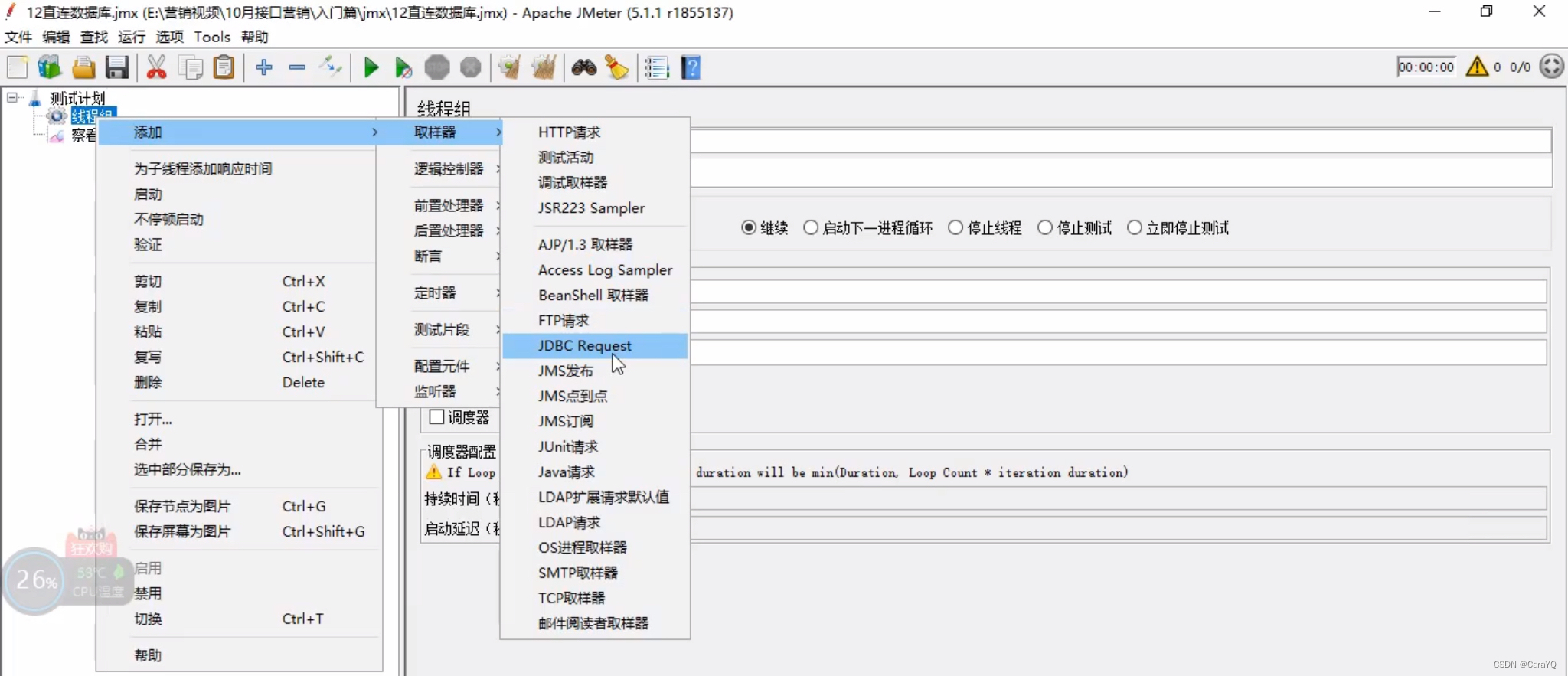
具体内容填写如下:
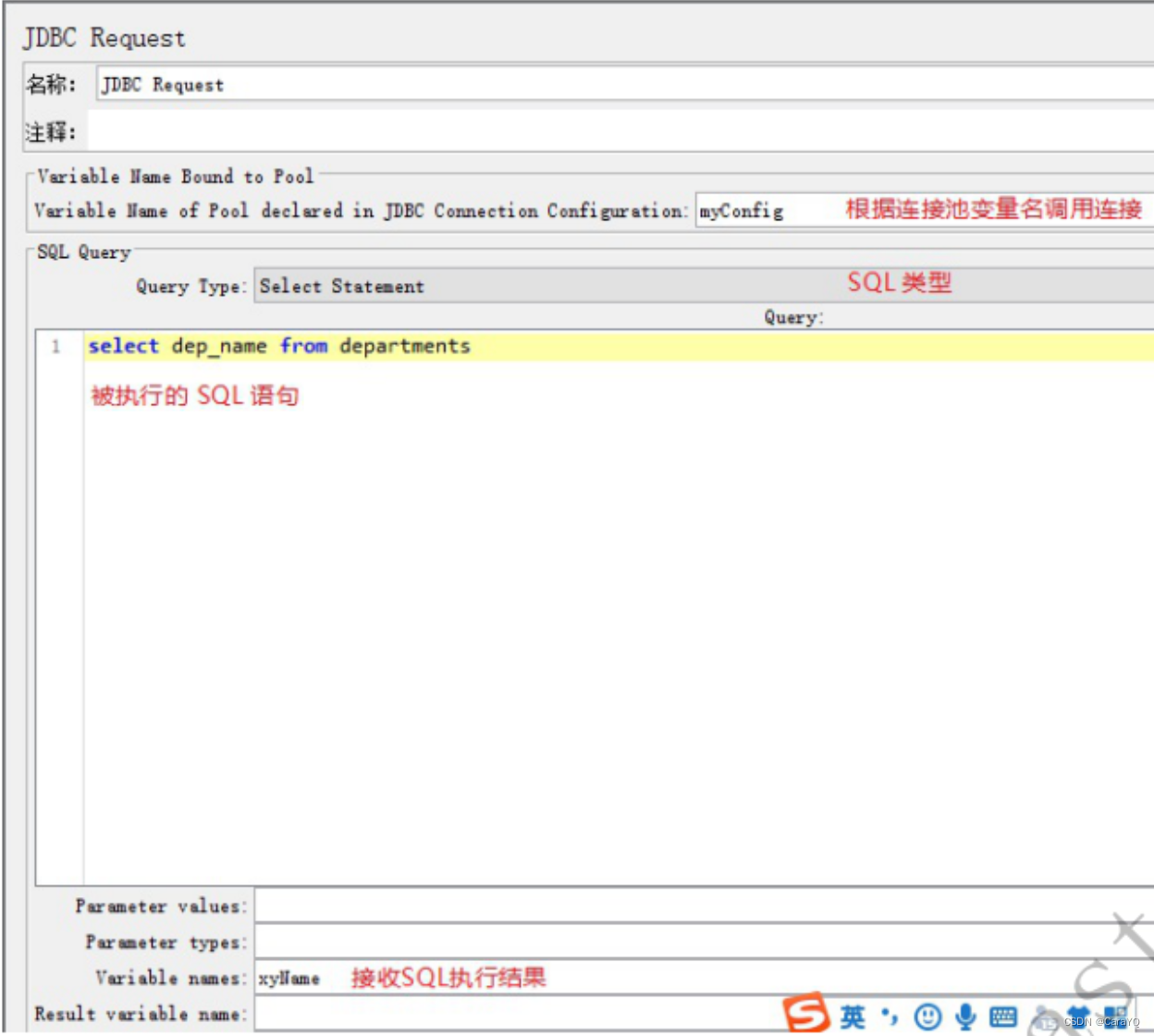
- variable name就是你在jdbc connection configuration中起的连接的名字
- query type说明:
(1)select:查询
(2)update:增删改
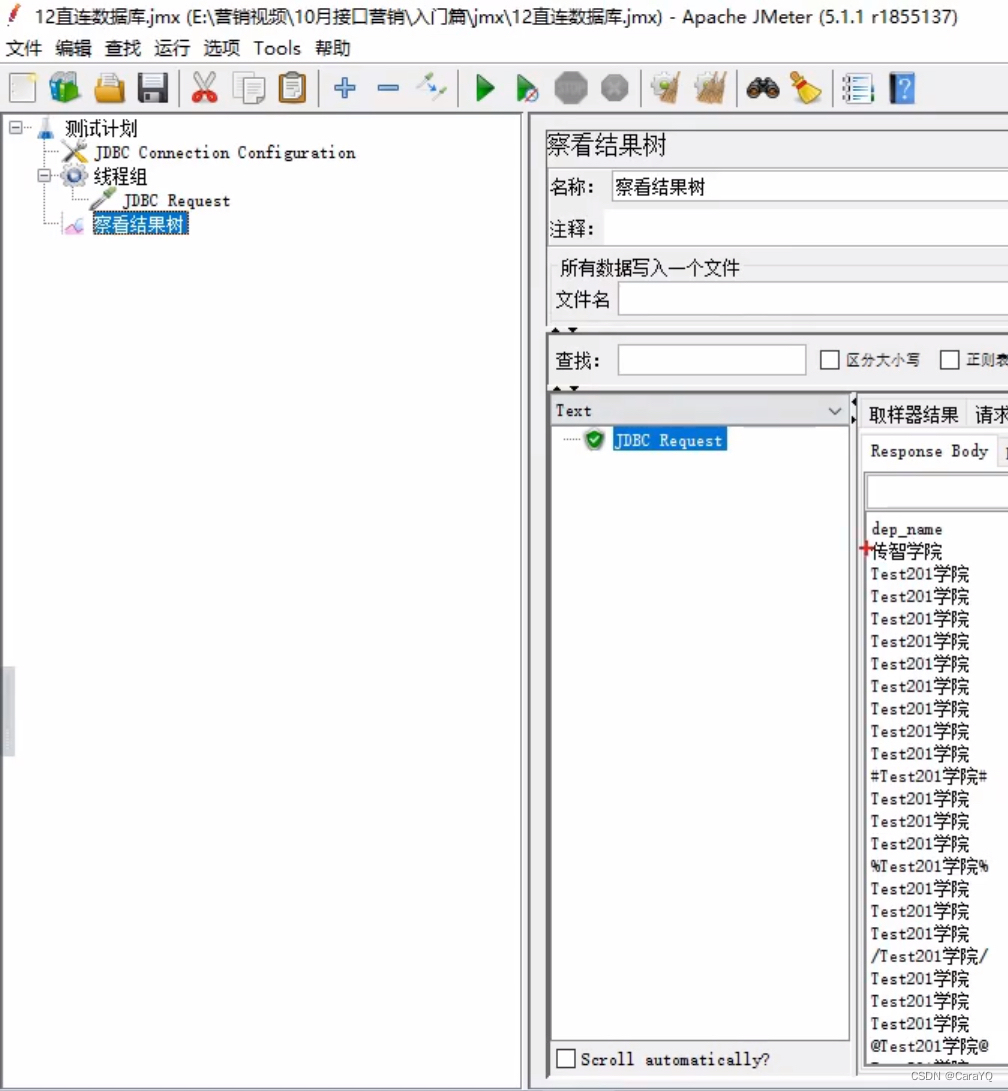
- 添加察看结果树,点击启动,就查询出来以下这么多结果,但是我只想把某一条结果放在百度上进行二次搜索
- 添加debug sampler组件查看数据怎么保存的,然后获取出来,放到百度上二次搜索
(1)
(2)
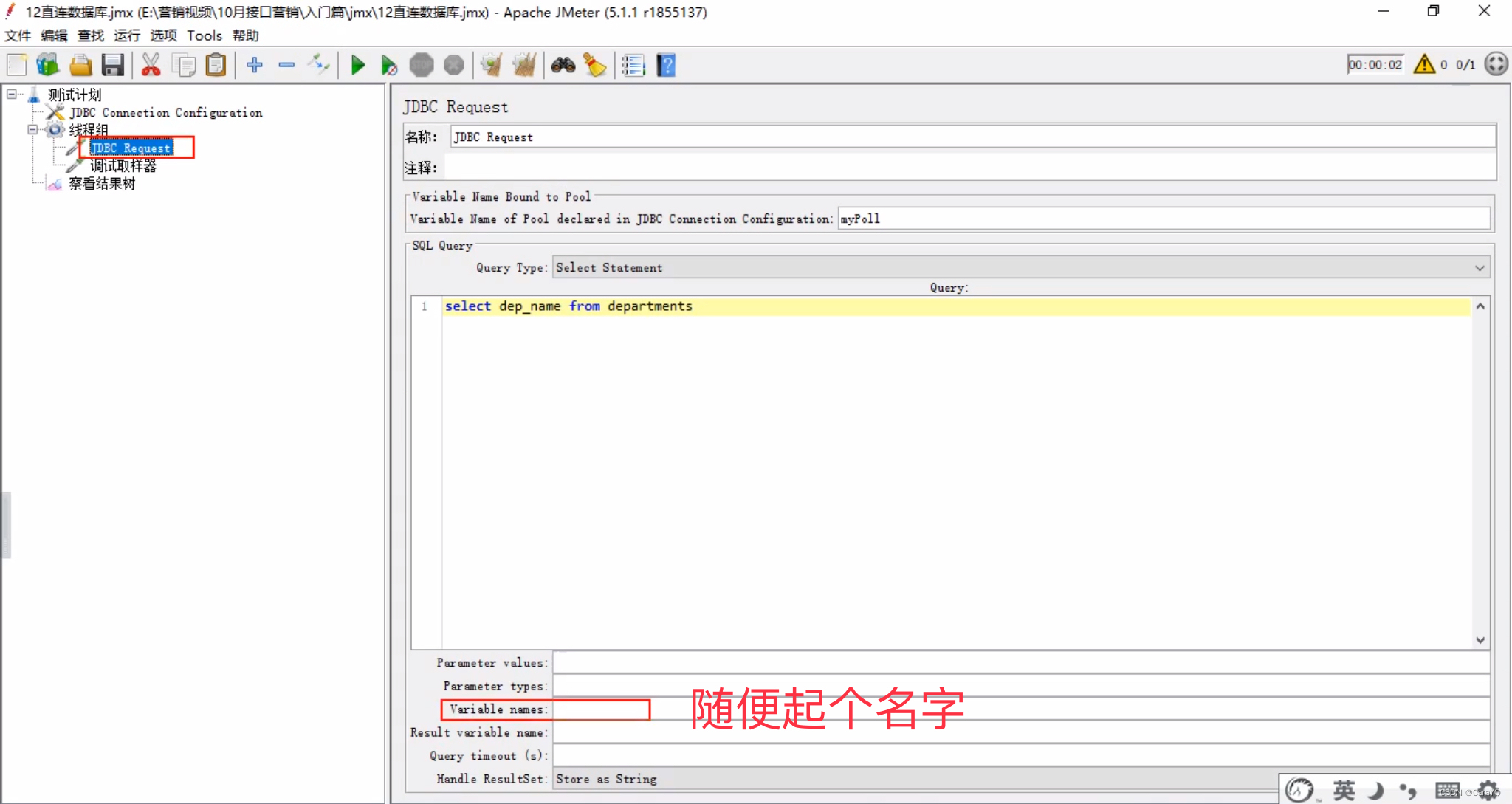
添加variable name的目的:让jdbc request获取到的结果都以variable name的值为前缀来保存:
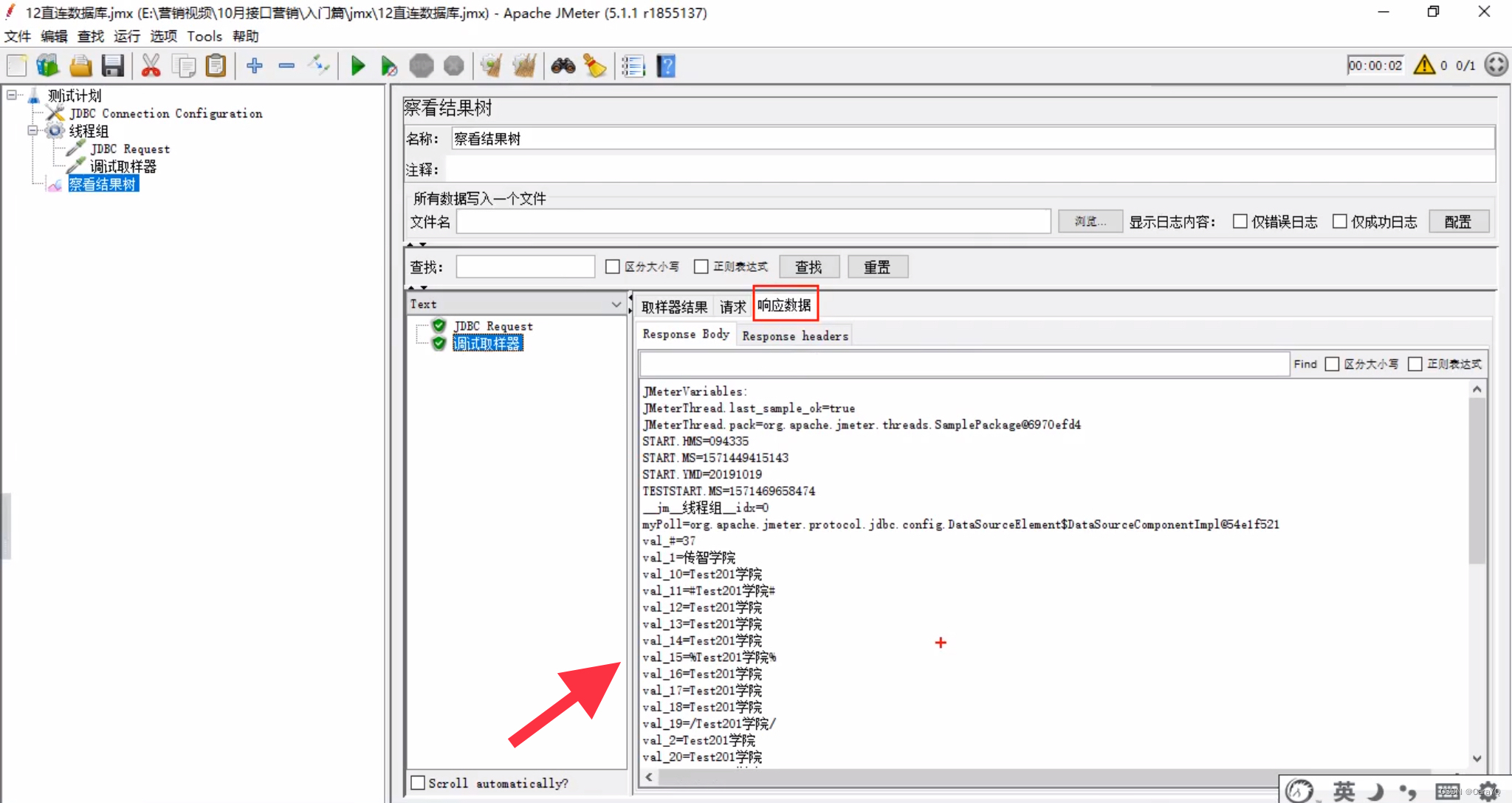
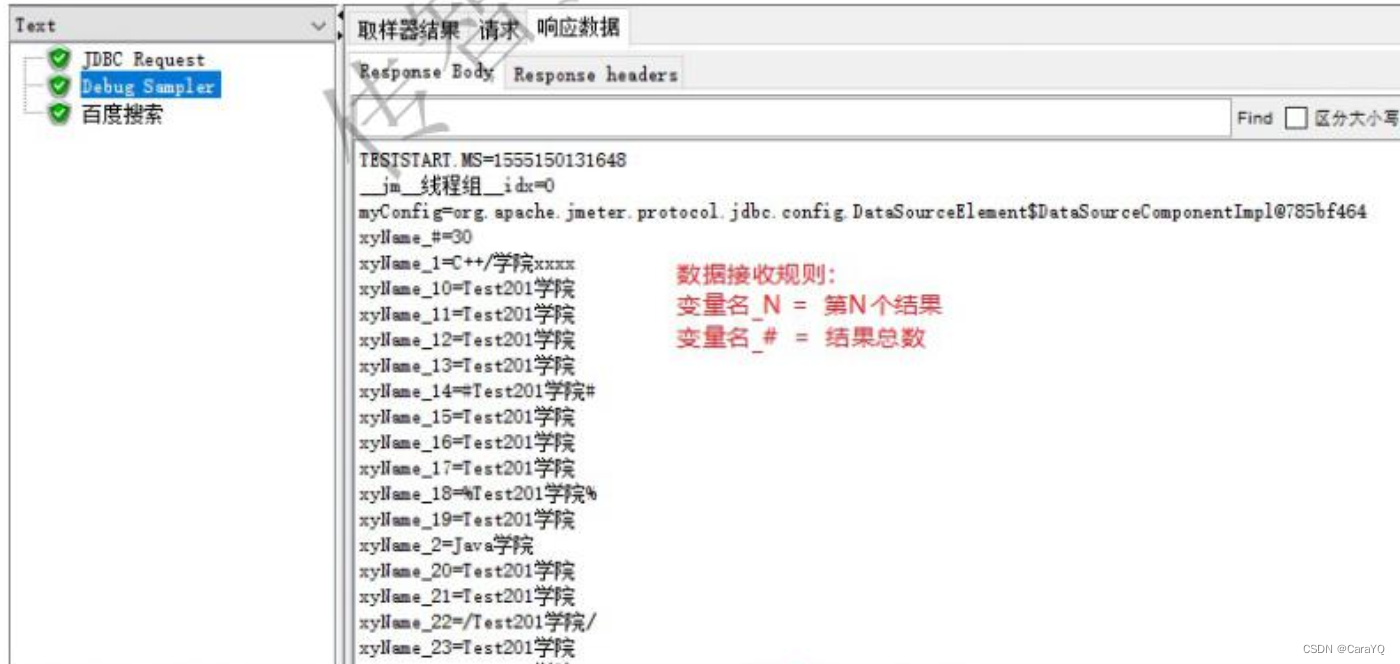
如果你想得到=右边的值,可以直接通过=左边的变量获取
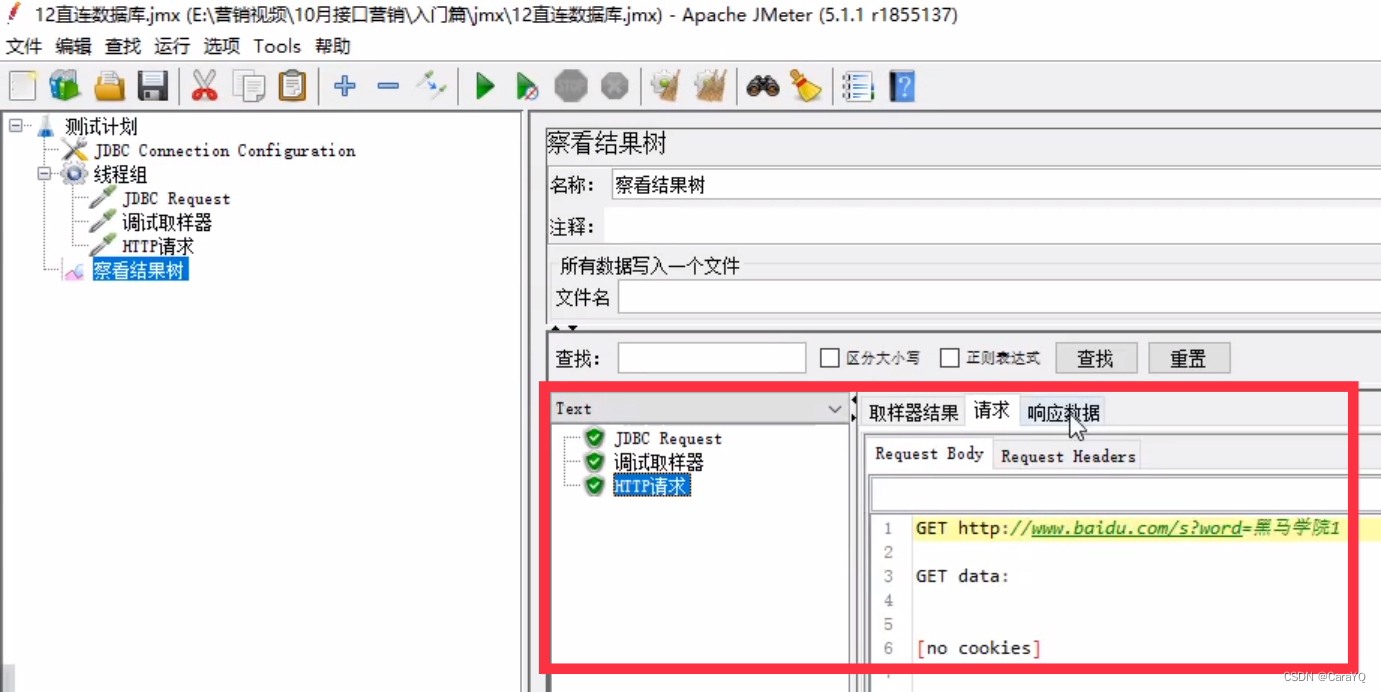
(3)添加一个http请求

内容如下:
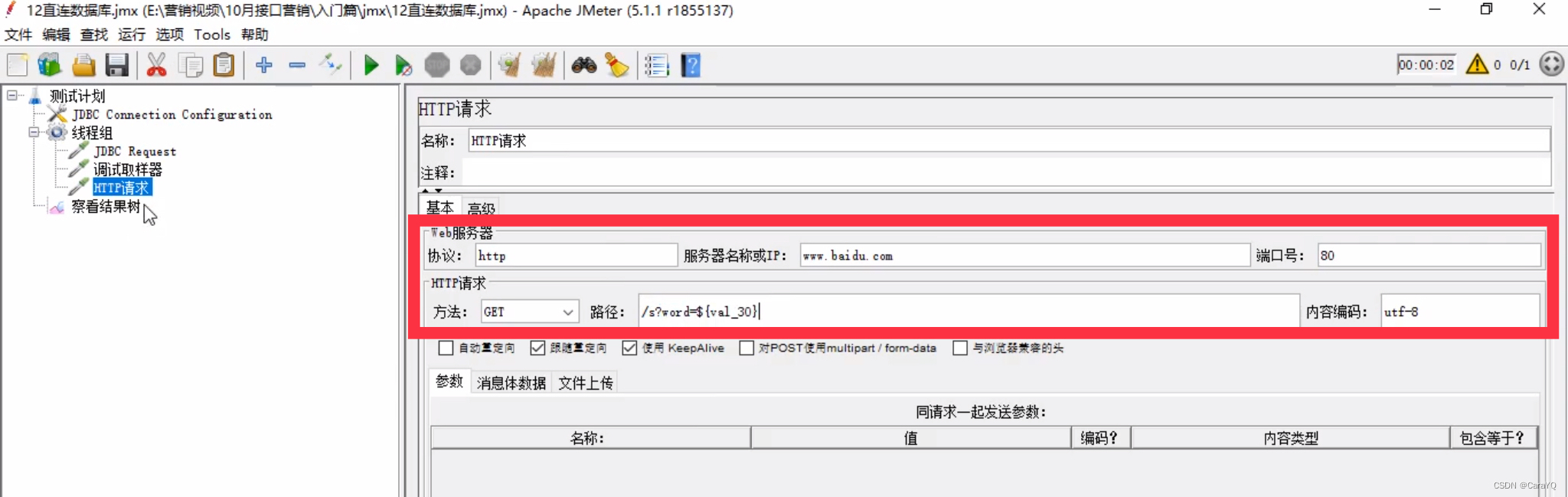
线上网站的端口号都是80,当我在百度中搜【黑马】时,百度其实访问的是/s页面,并在url中拼接了一个word,word的值为要搜索的内容,即黑马


现在我想把jdbc request获取到的某个结果展示出来,也就是说让百度搜索jdbc request获取到的某个结果,那么我可以写word=${val_30}
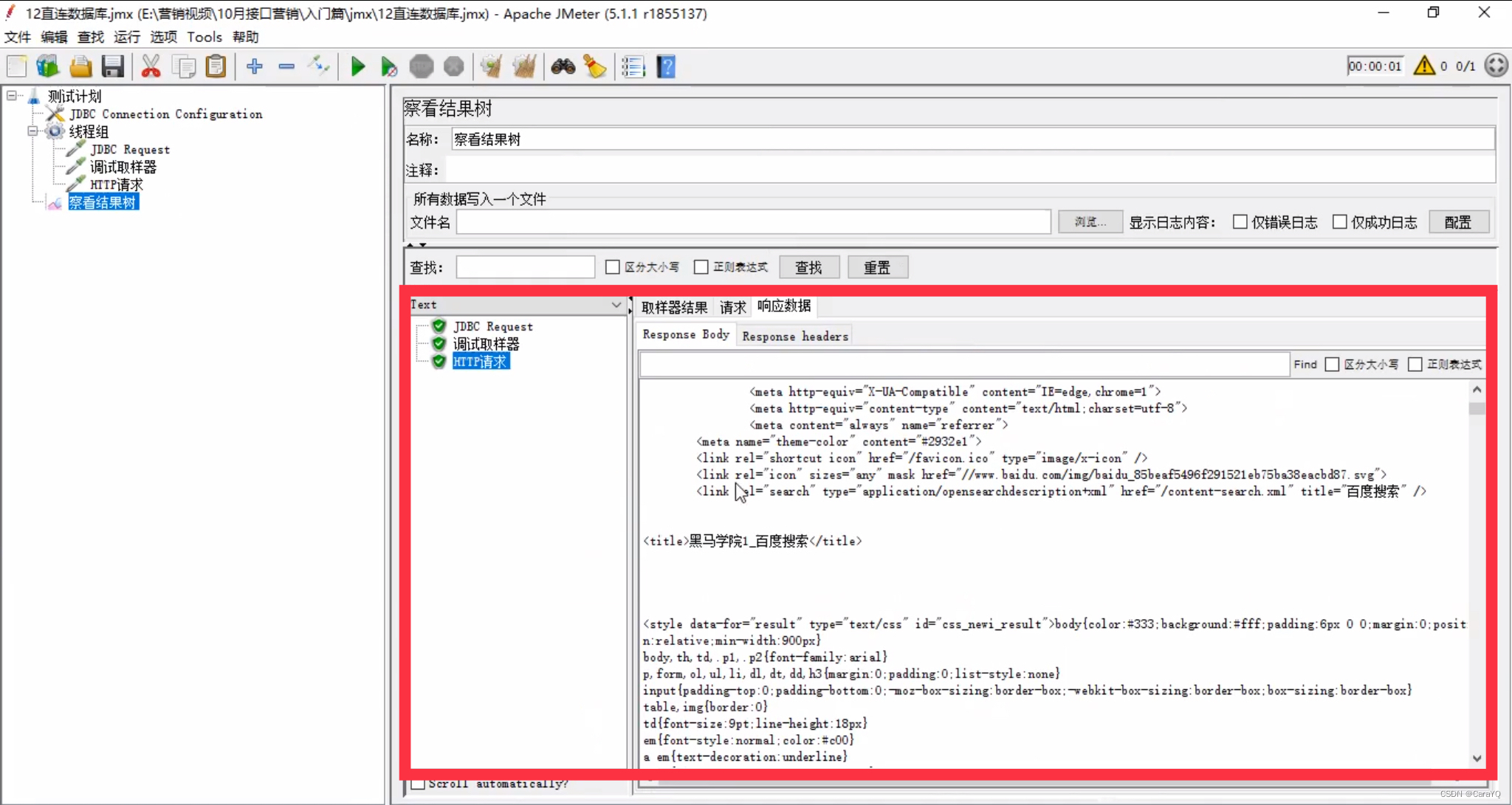
(4)启动后,
断言

响应断言
- 添加http请求
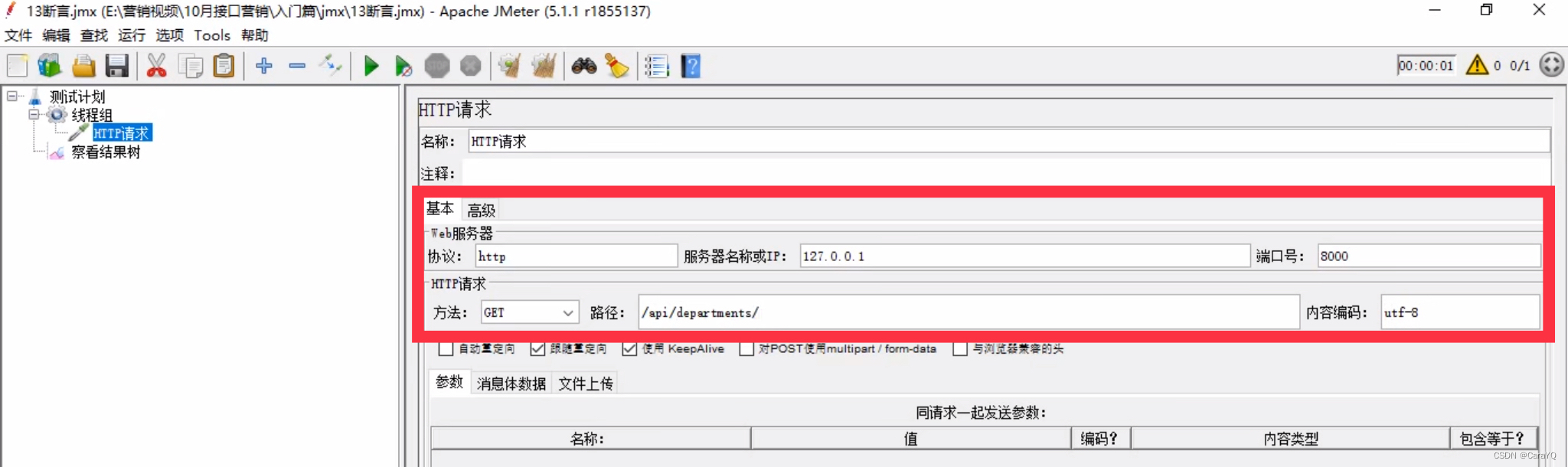
- 添加断言:
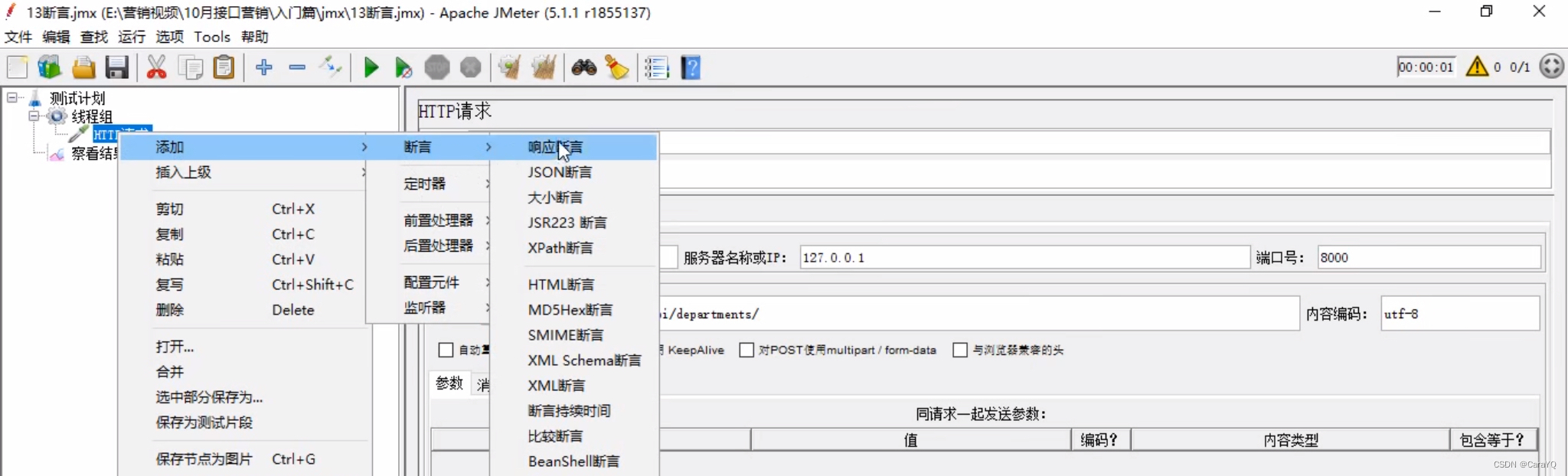
响应断言:从http请求中获取结果,对结果断言
具体内容:
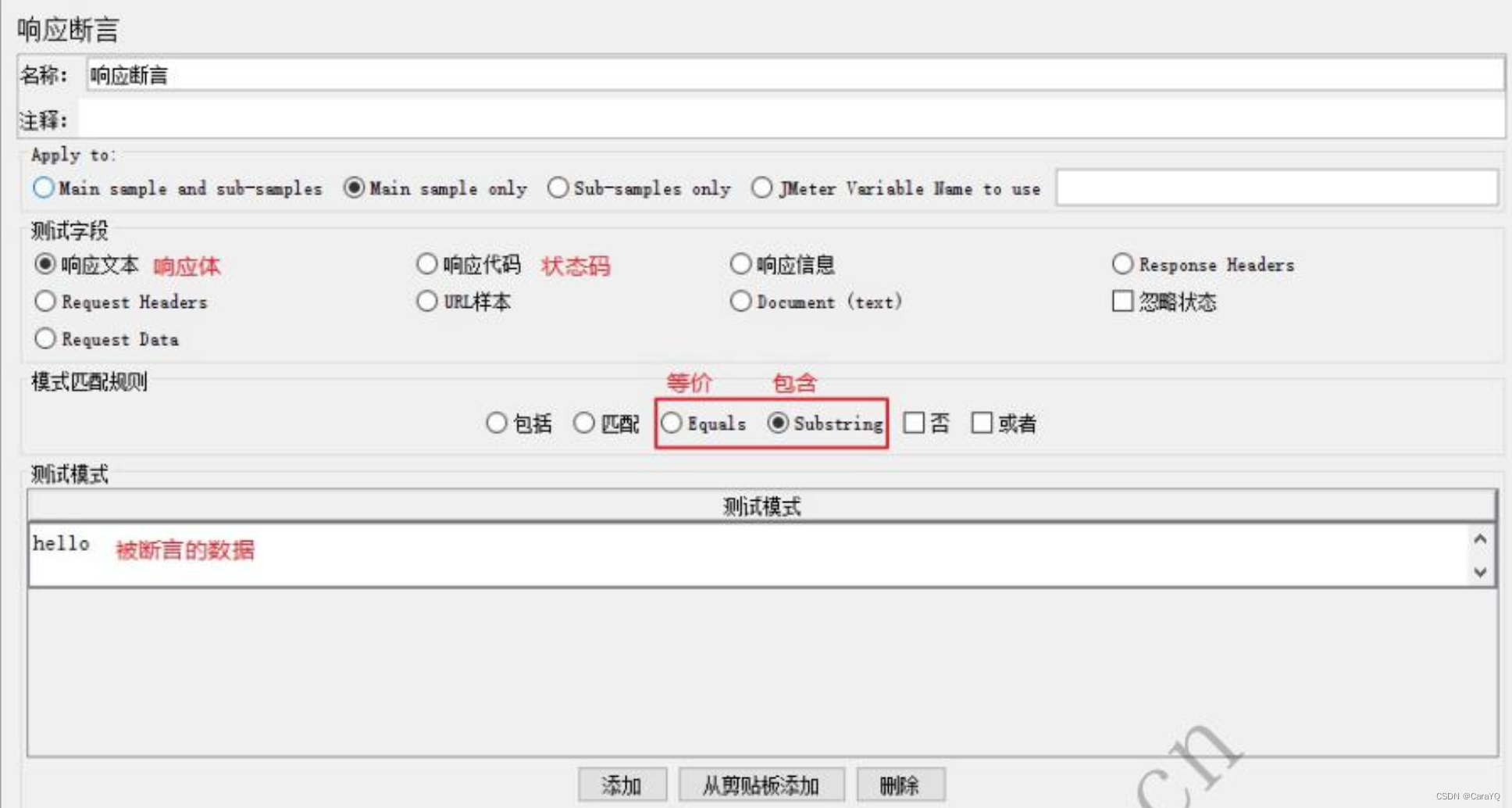
匹配:正则表达式
包含:响应体中是否包含测试模式中的内容
等价:响应体中是否等于测试模式中的内容
否:取反,响应体中是否不包含测试模式中的内容
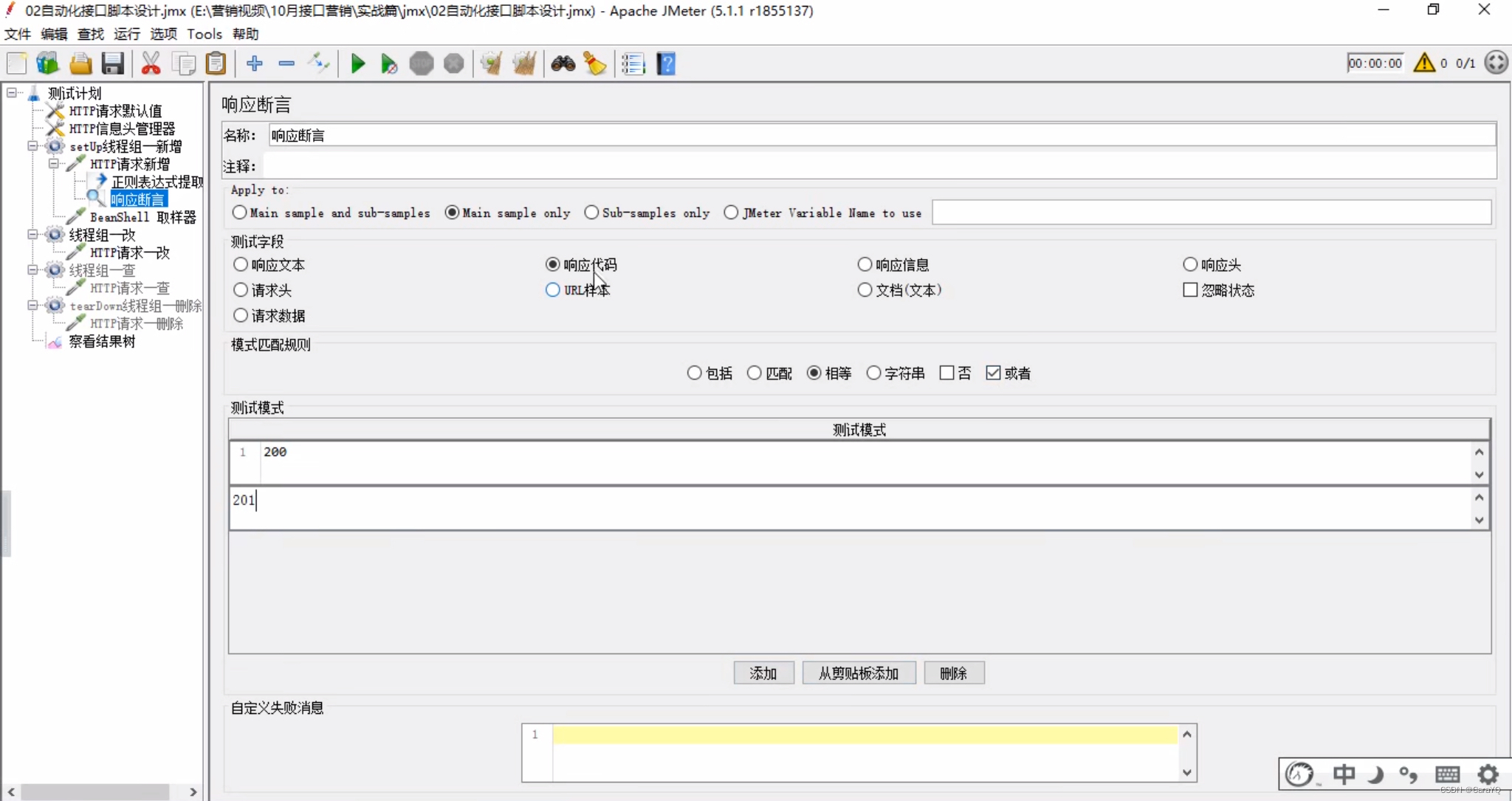
或者:配合响应代码使用,如下例,或者等于200或者等于201
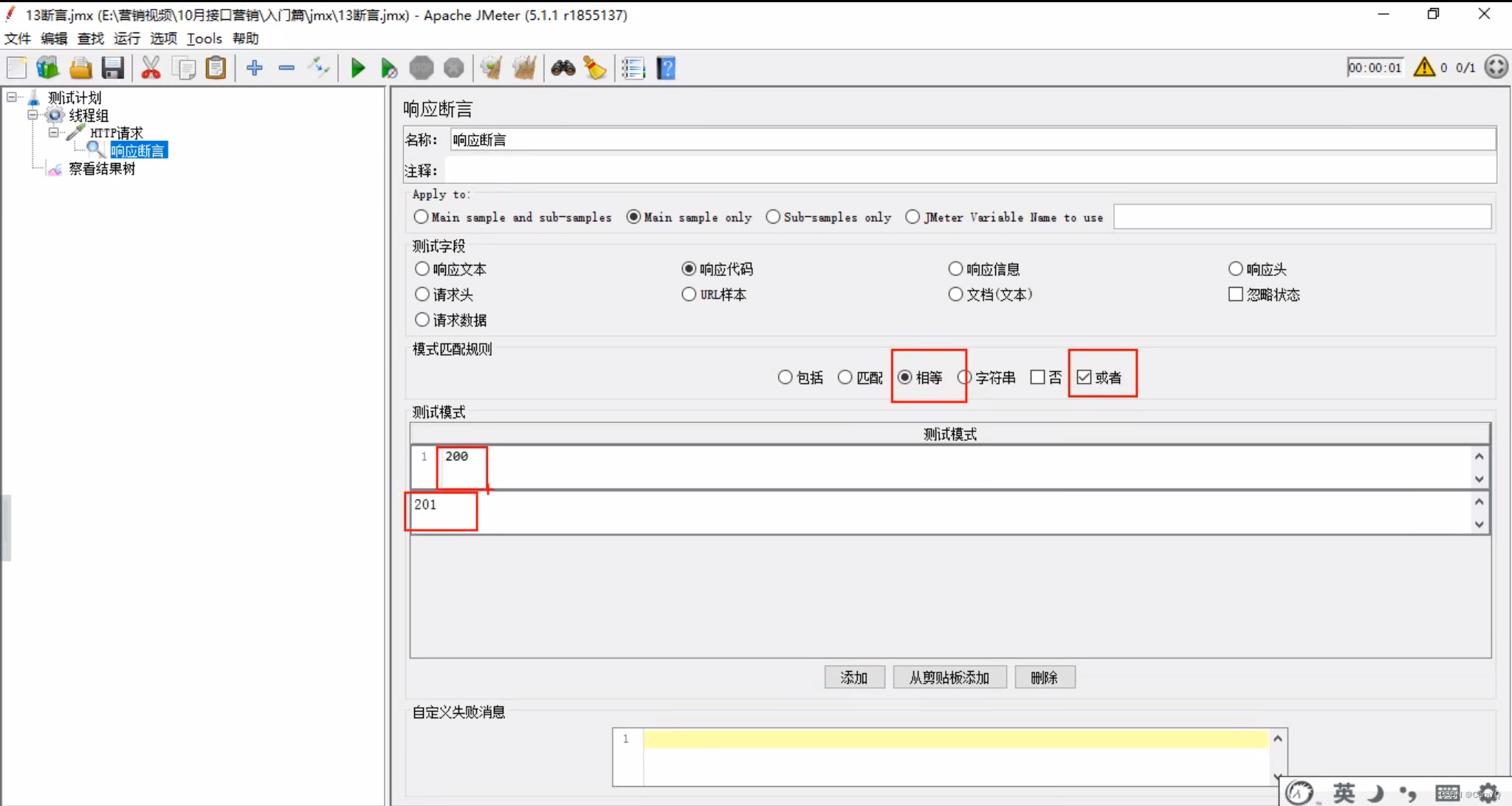
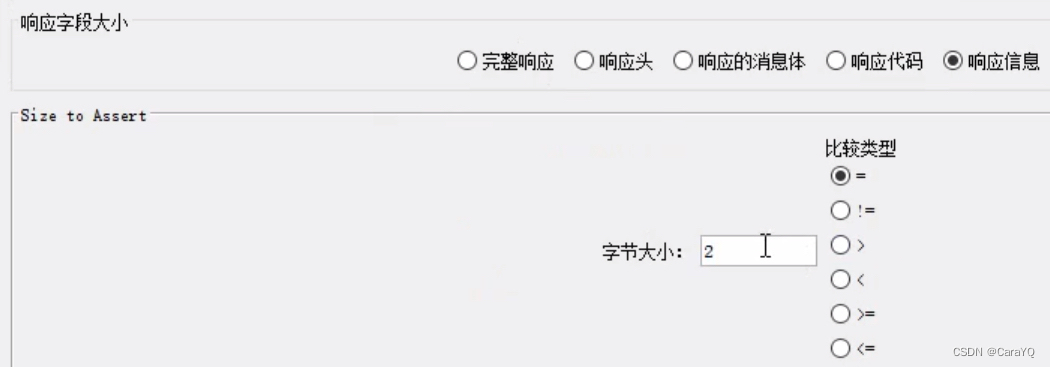
大小断言:判断字符串内容的长度。
添加断言

大小断言:用于判断你请求得到的结果,数据有多少。
具体内容:
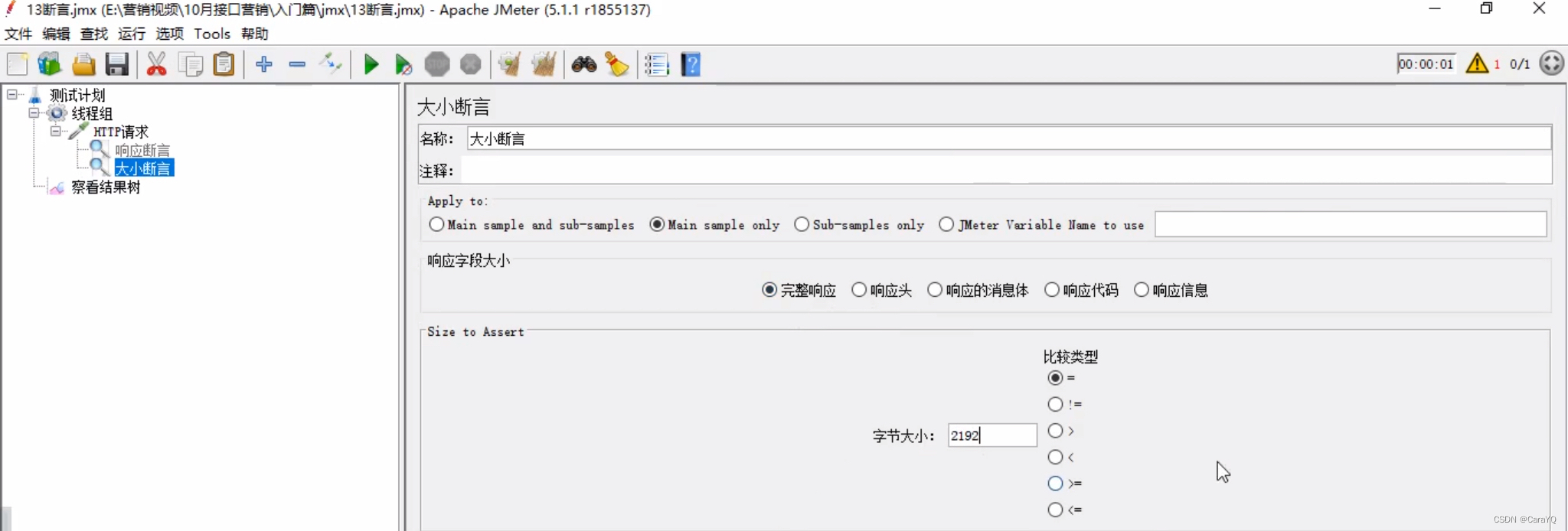
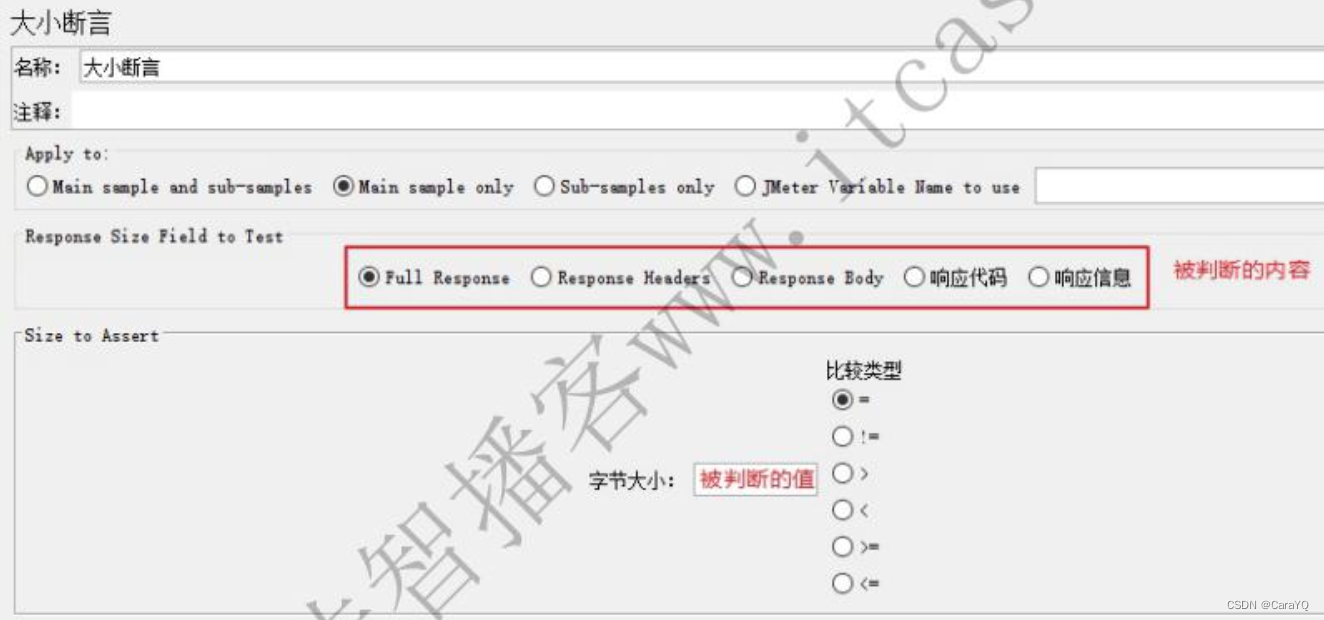
我们查看一下取样器结果,如下所示:
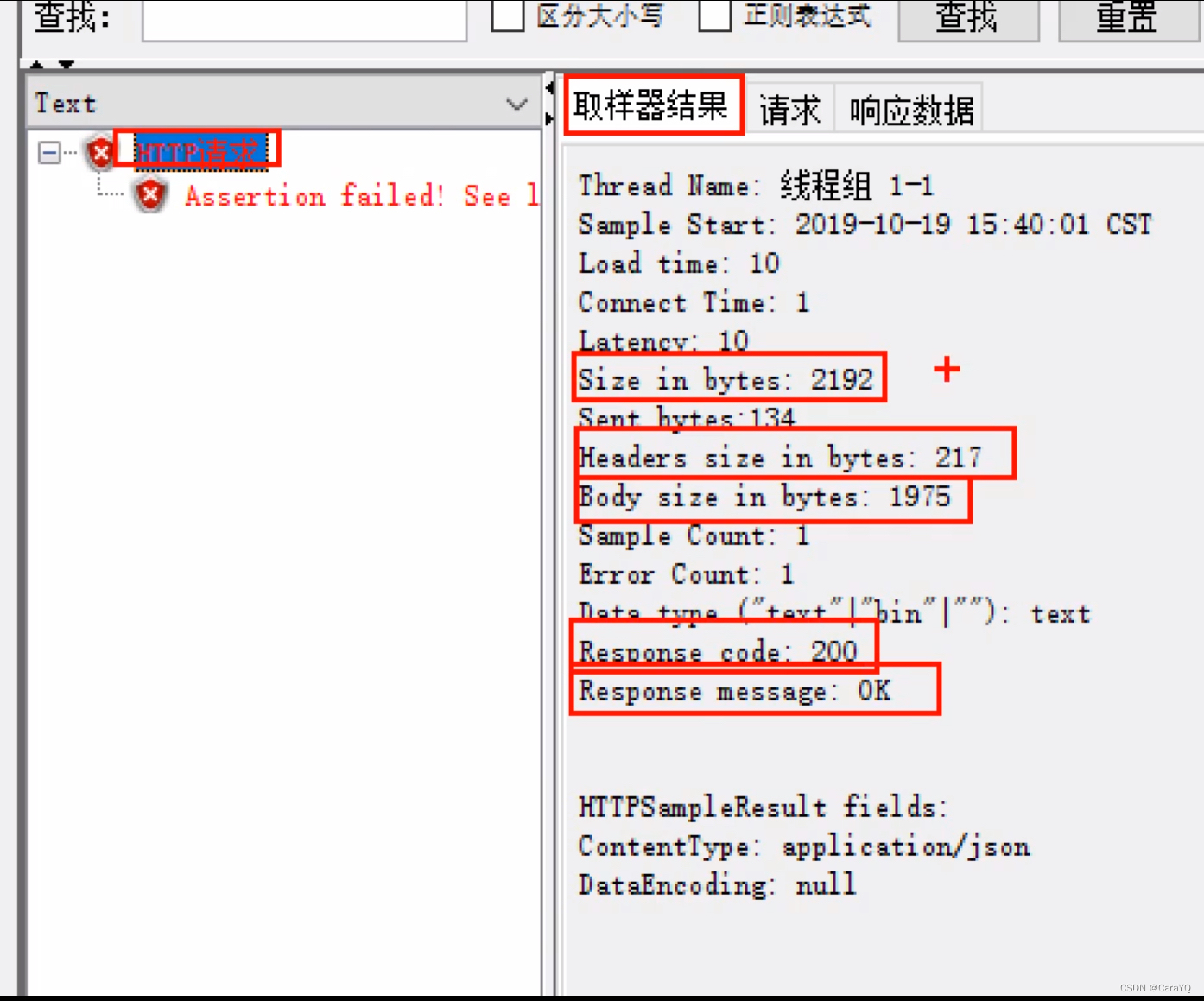
被判断的内容与取样器结果对应关系如下:
完整响应:size in bytes
响应的消息体:response message
响应代码:response code
响应头:header size in bytes
响应信息:body size in bytes
注意200代表3个字符,ok代表2个字符
断言持续时间
- 添加断言
具体内容:
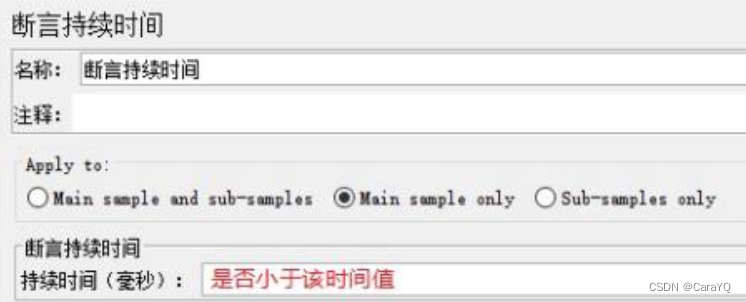
我当前请求到得到结果这一过程所耗时间是否小于我设定的这个持续时间
逻辑控制器和关联
通过前面讲的参数化可以实现单个接口的功能测试,而接口测试过程中,除了单个接口的功能测试之外,还会测试接口业务实现,所谓业务,就是一套完整的业务逻辑或流程,这就必须要使用到逻辑控制和关联。
逻辑控制器
一、if控制器:如果if条件成立,则执行请求,否则不执行
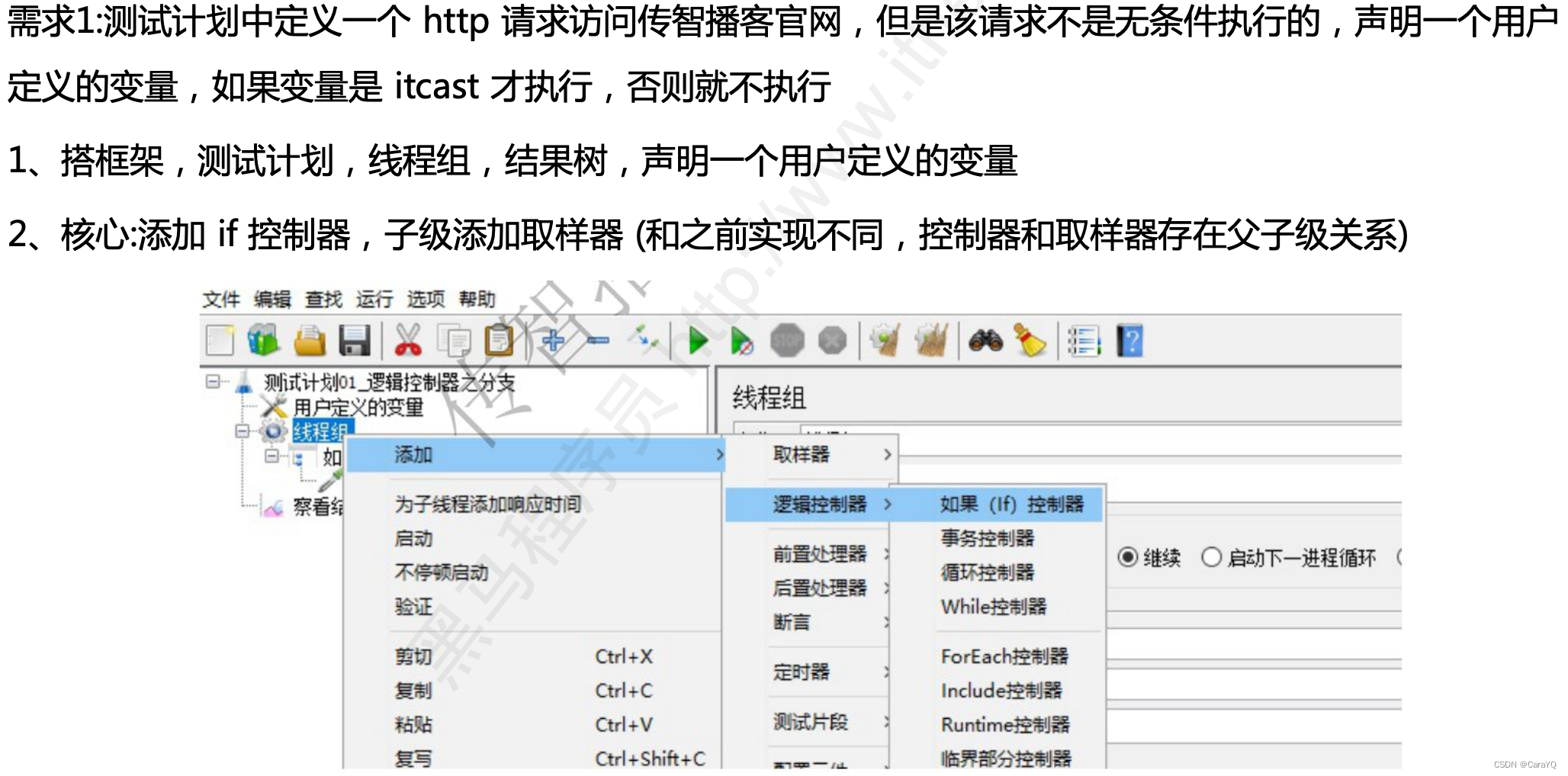
- 先在线程组上面添加一个if控制器
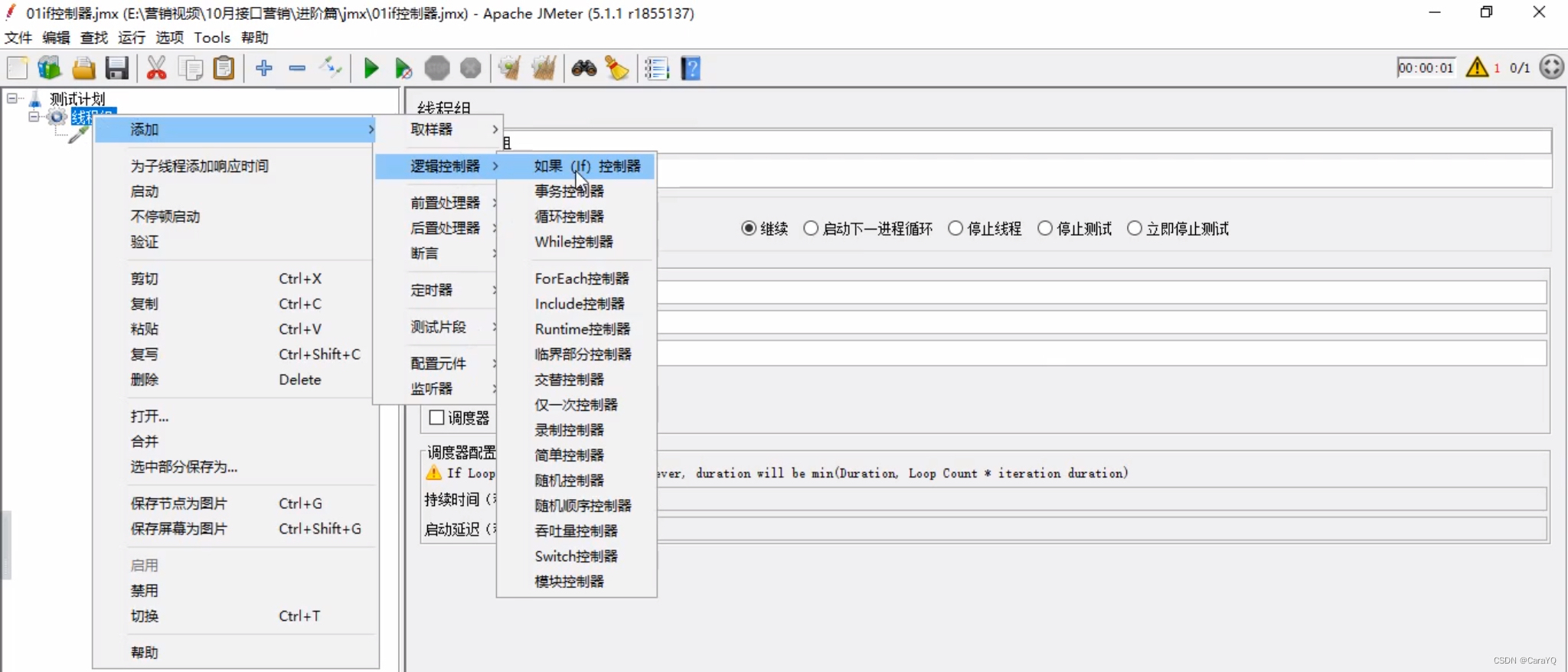
- 在线程组上添加一个http请求
- 将http请求拖拽到if控制器里面,相当于if控制器是http请求的父级,不知道可不可以在if控制器上直接添加http请求
- 然后添加用户定义的变量、察看结果树,如下图所示,且在用户定义的变量中定义一个变量

- 在if控制器中写你的判断语句,语法规则:
"变量" == "值",上面我们定义的变量为val,所以此处写:"${val}" == "itcast",如下:
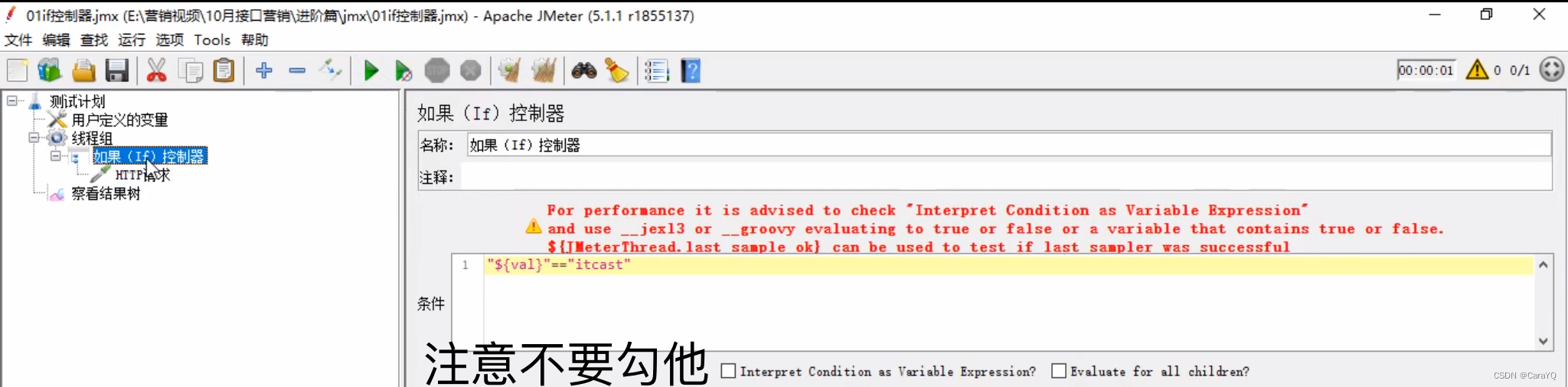
- 因为我们定义的变量就是itcast,所以在察看结果树中能看到请求执行成功,但是如果我们定义的是别的值,这个请求压根不会发出去,察看结果树中啥也没有
二、foreach控制器:把你所要实现的操作,一个个执行一遍
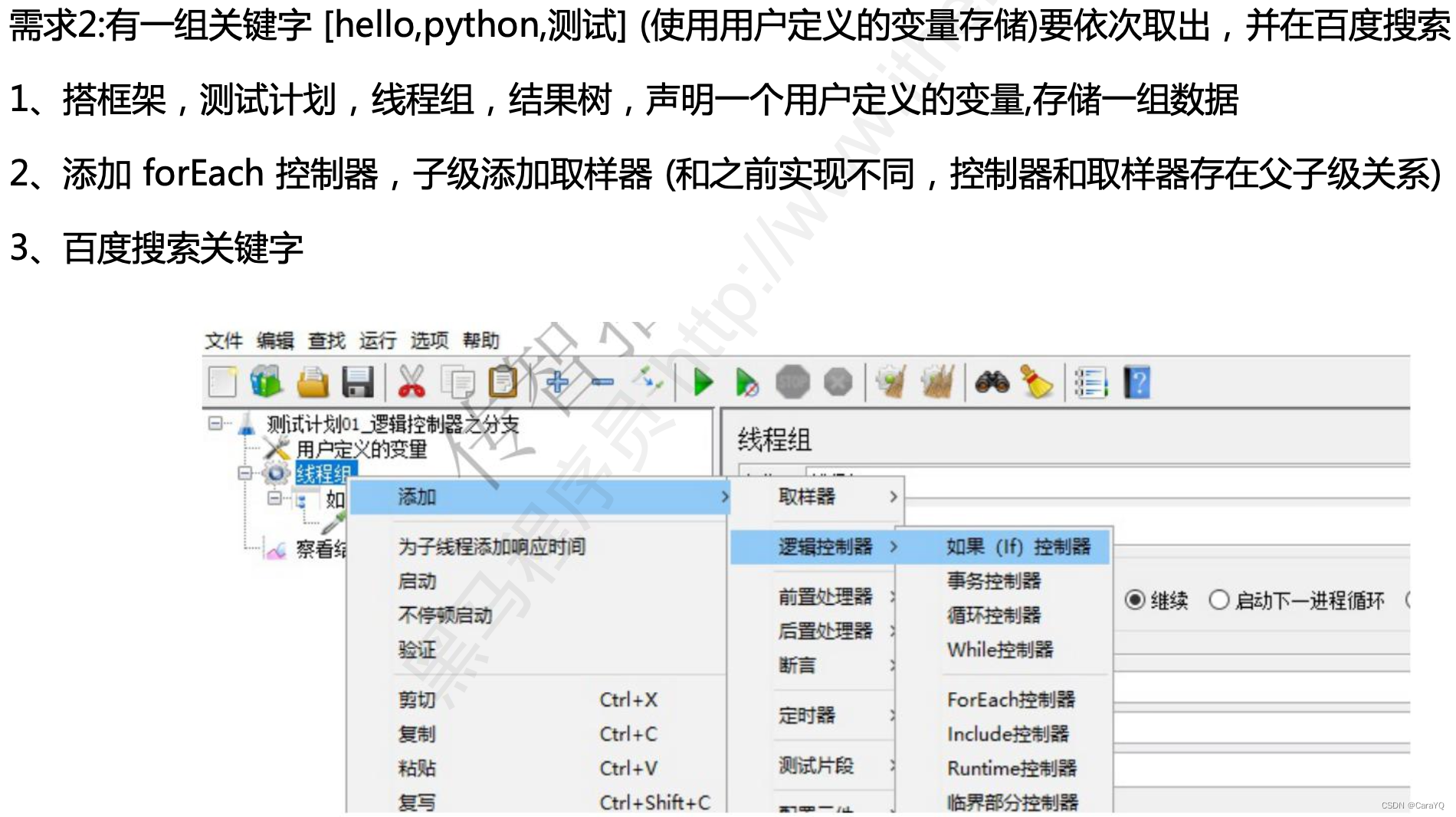
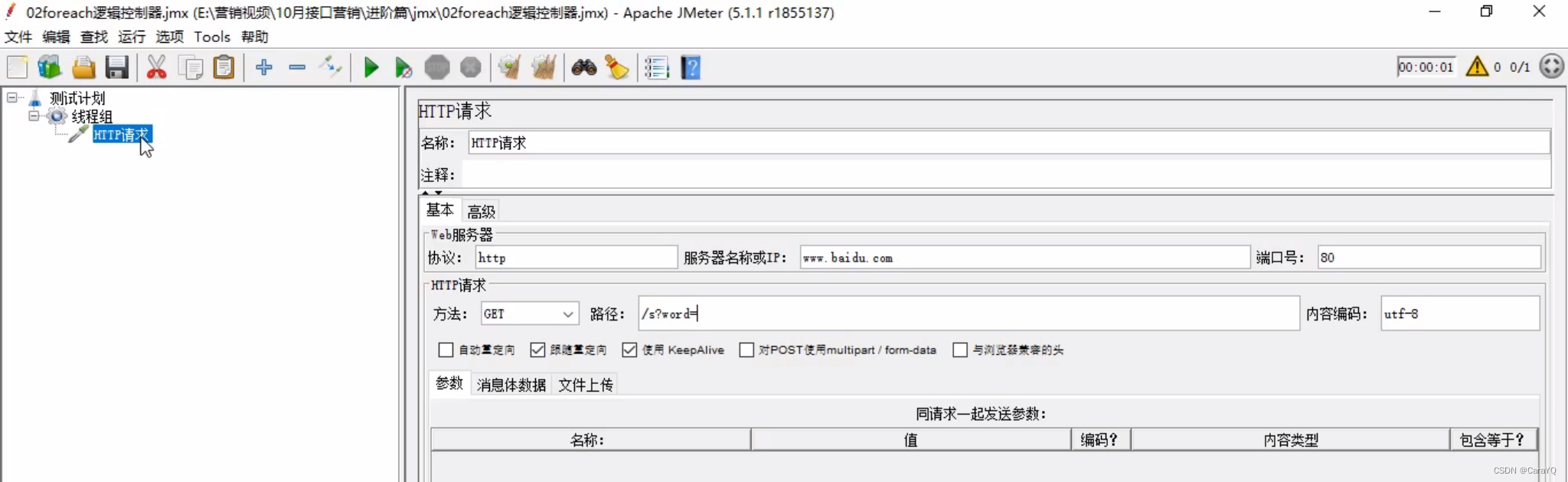
- 在线程组上添加http请求
- 在线程组上添加foreach控制器
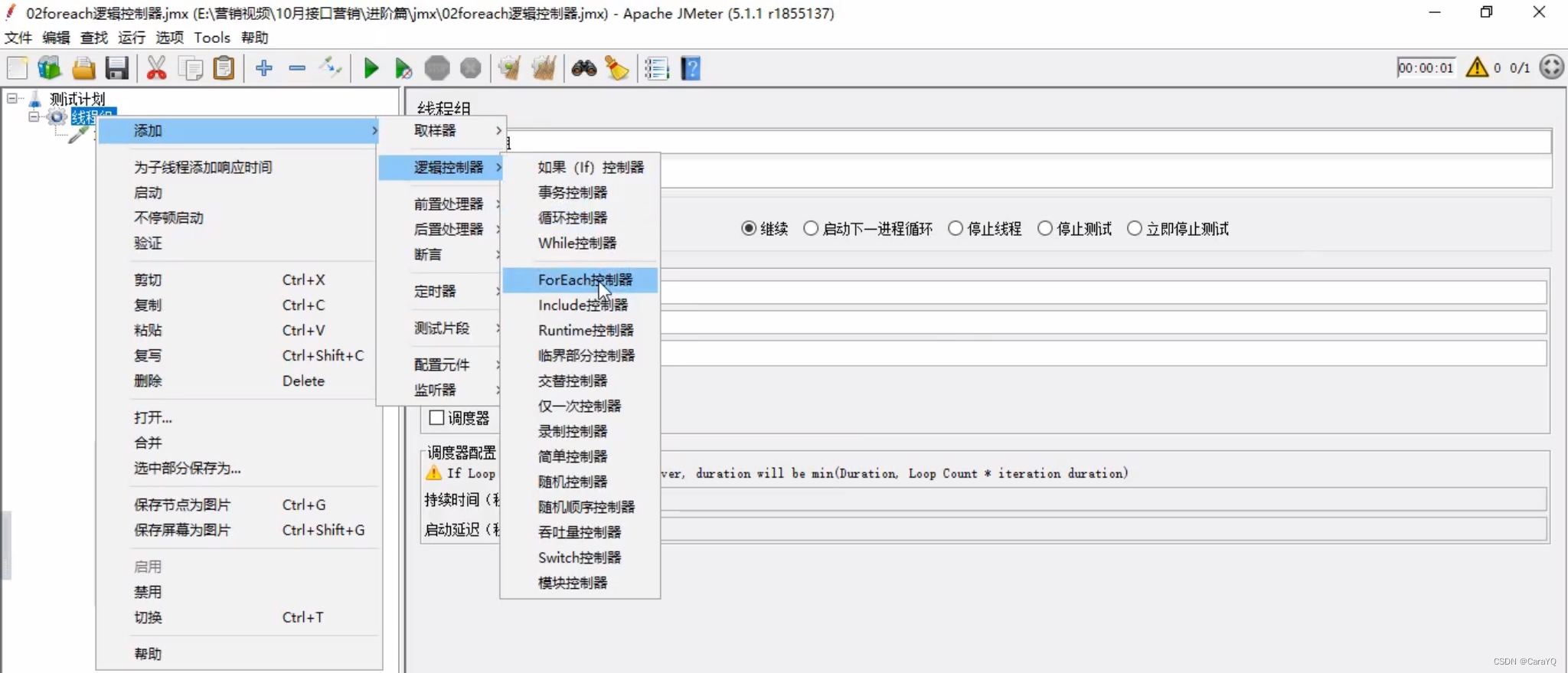
- 将http请求移到foreach控制器中,让控制器成为http请求的父级
- 添加用户定义的变量,内容如下

注意名称的规律:相同的前缀_不同的数字,如name_1
- foreach控制器内容如下:
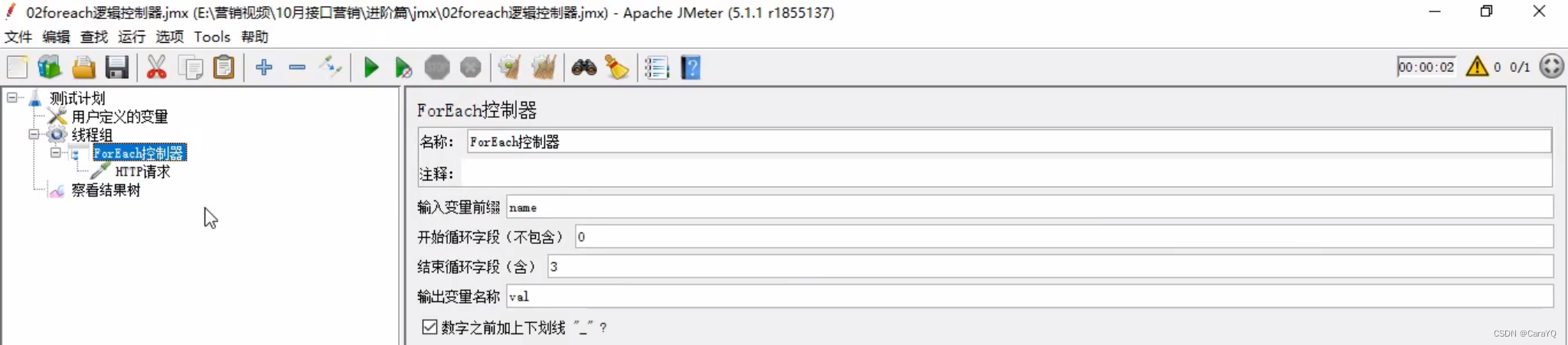
我们在用户定义的变量中添加的变量是name_1,name_2,name_3。所以【输入变量前缀】就是name_,但是由于勾选了【数字之前加上下划线】,所以_可省略,就填name就行了。开始循环字段应该是1,但是因为不包含1,所以应该填0。结束循环字段应该是3。输出变量随便定义,此处为val,但因为取出来的内容要作为查询字段拼在URL中,所以还需要在http请求中补充以下内容
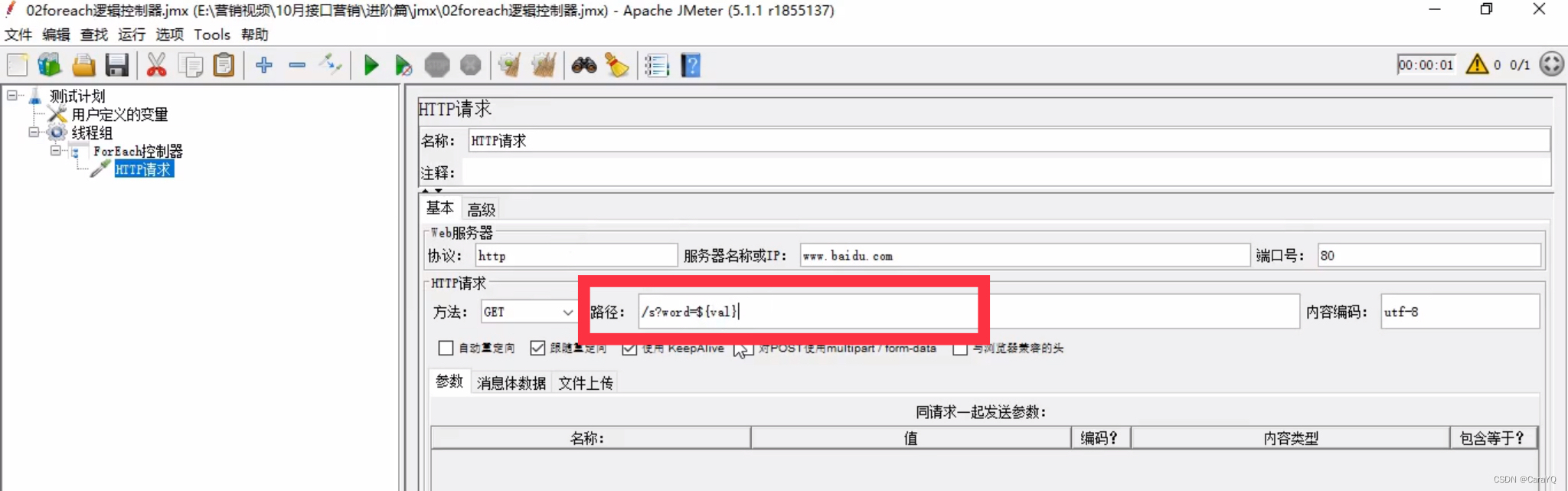
- 添加察看结果树
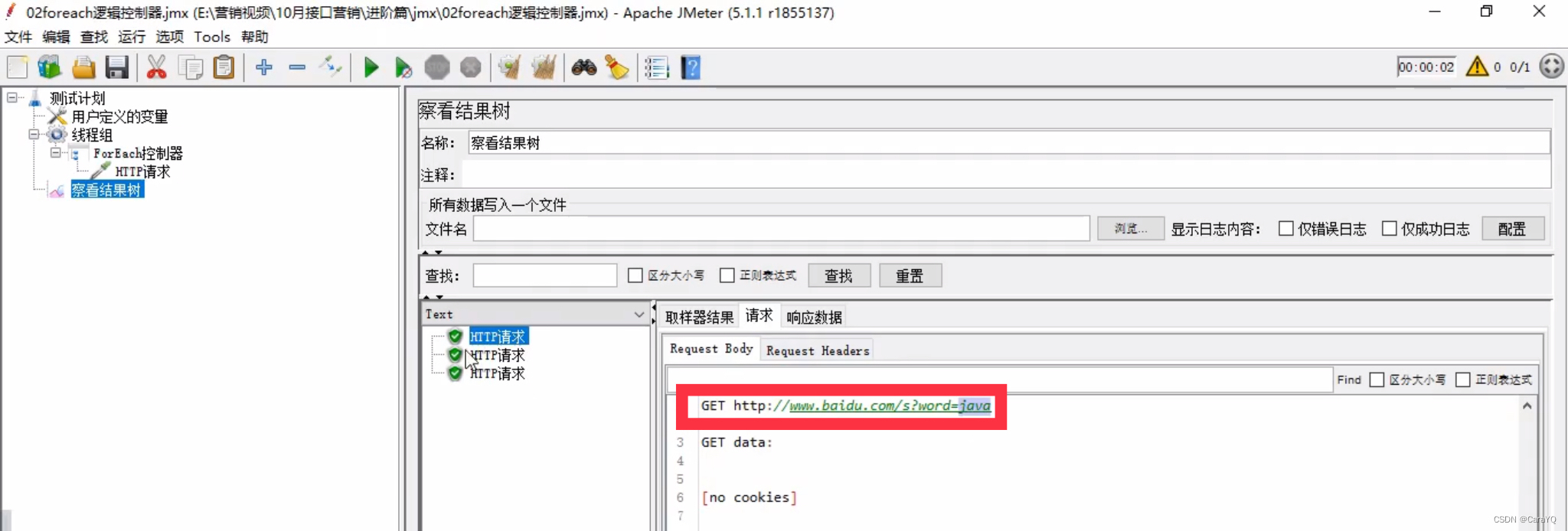
注意:foreach控制器已经把http请求循环执行3次了(你设置的开始循环字段0、结束循环字段3,共3次),你就没有必要在线程组中设置循环次数3了,如果你设置了,察看结果树中会输出9个执行结果
三、循环控制器

- 在线程组上添加http请求
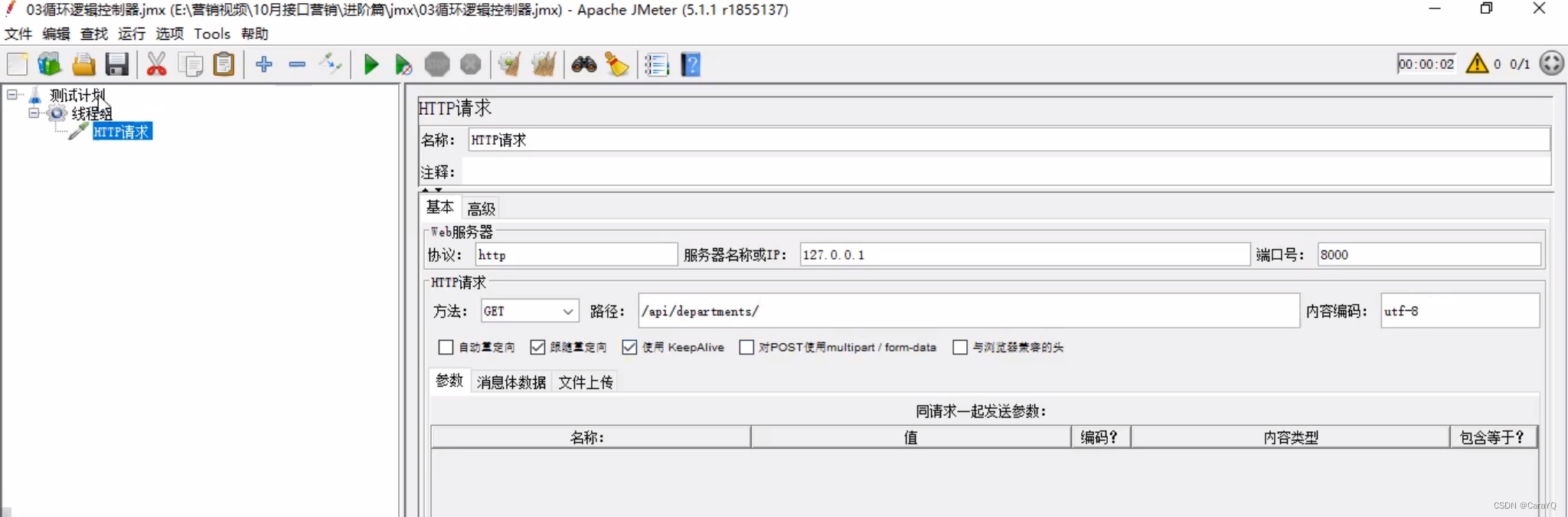
- 以前我们解决这个问题,会在线程组中设置循环次数为10
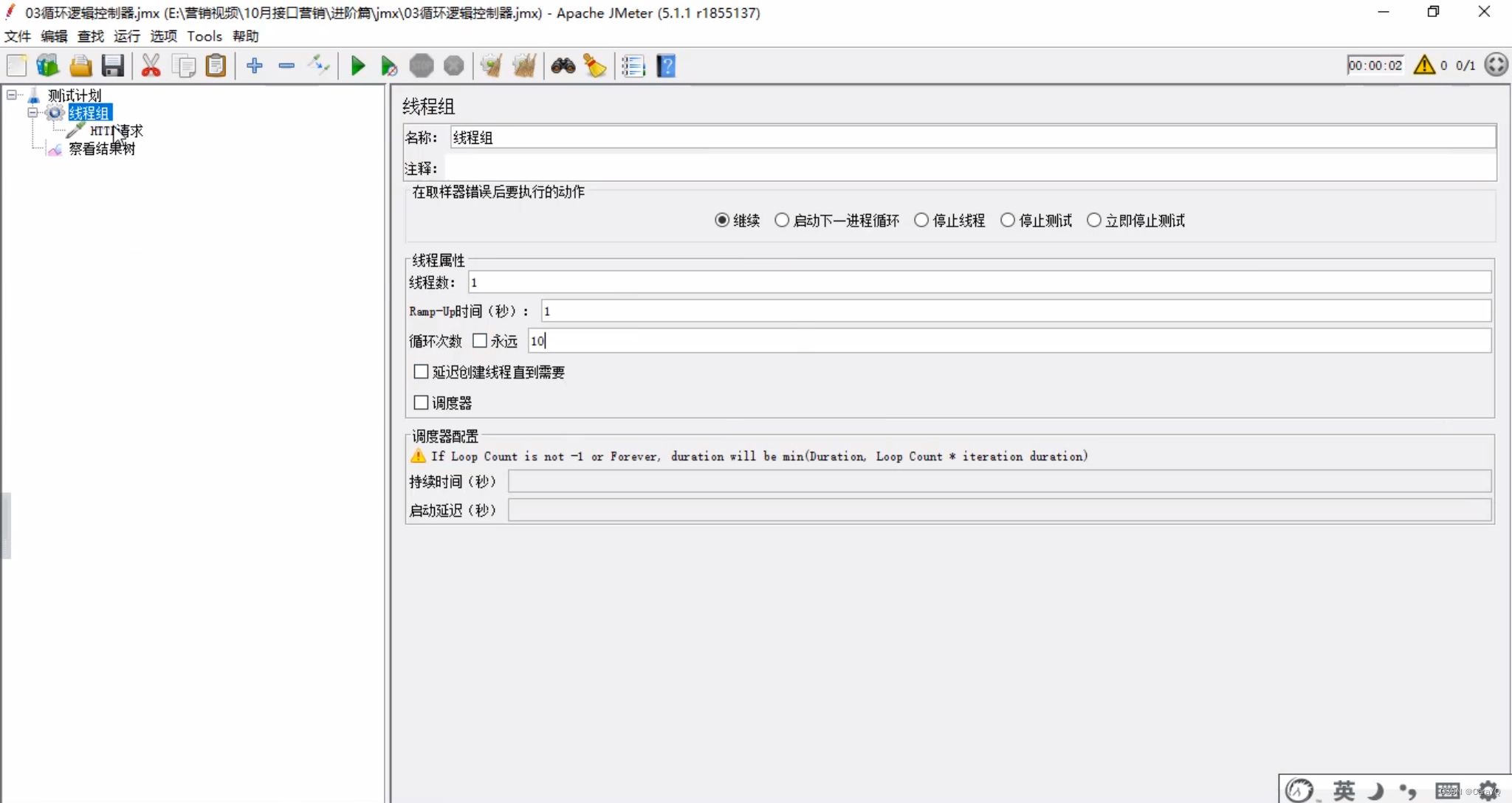
但是如果线程组上有两个http请求,一个需要执行10次,一个需要执行5次,那就没办法啦,只能两个http请求都执行10次,但我们循环控制器可以避免这个问题 - 线程组上添加循环控制器
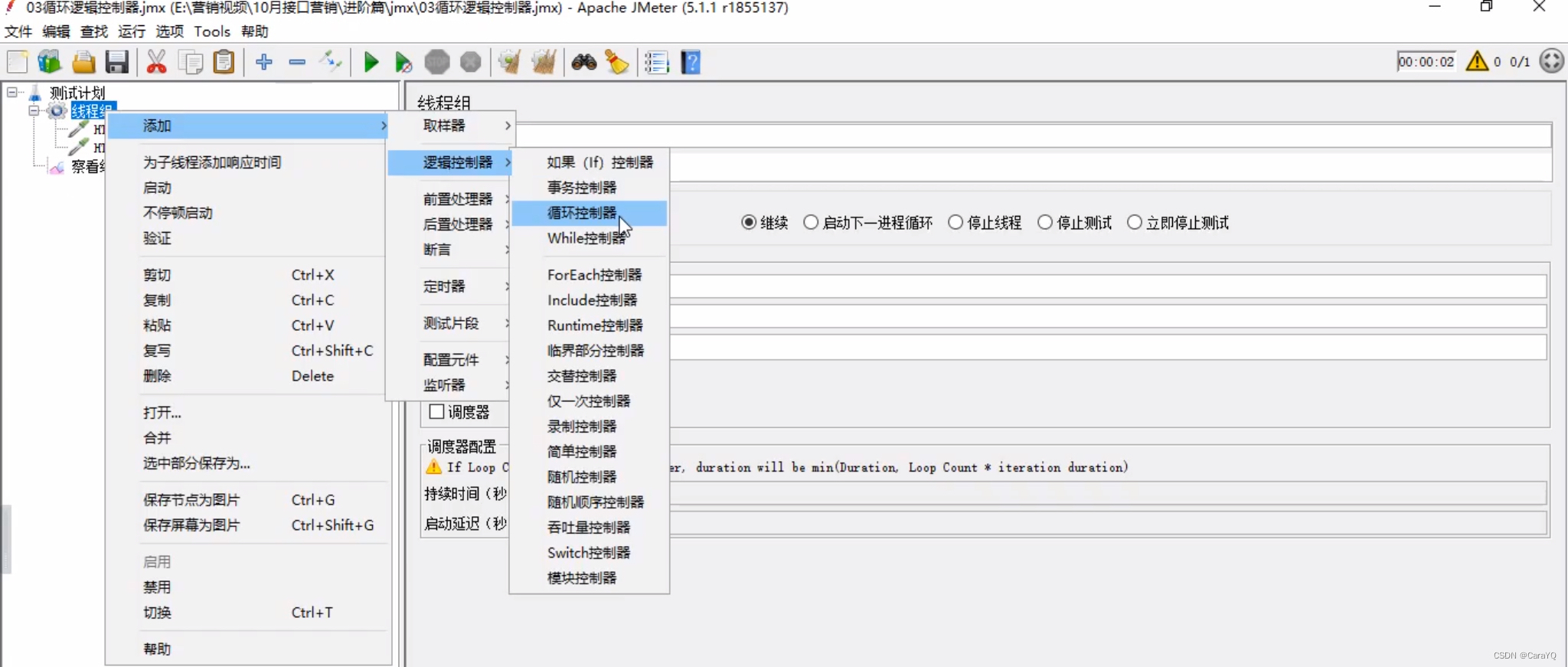
- 让循环控制器成为http请求的父级,你只要记住逻辑控制器只有是http请求的父级才能控制http请求,否则逻辑控制器无效
- 一个循环控制器的循环次数设置为10,一个设置为5即可

线程组的循环次数依旧是1 - 在线程组上添加察看结果树
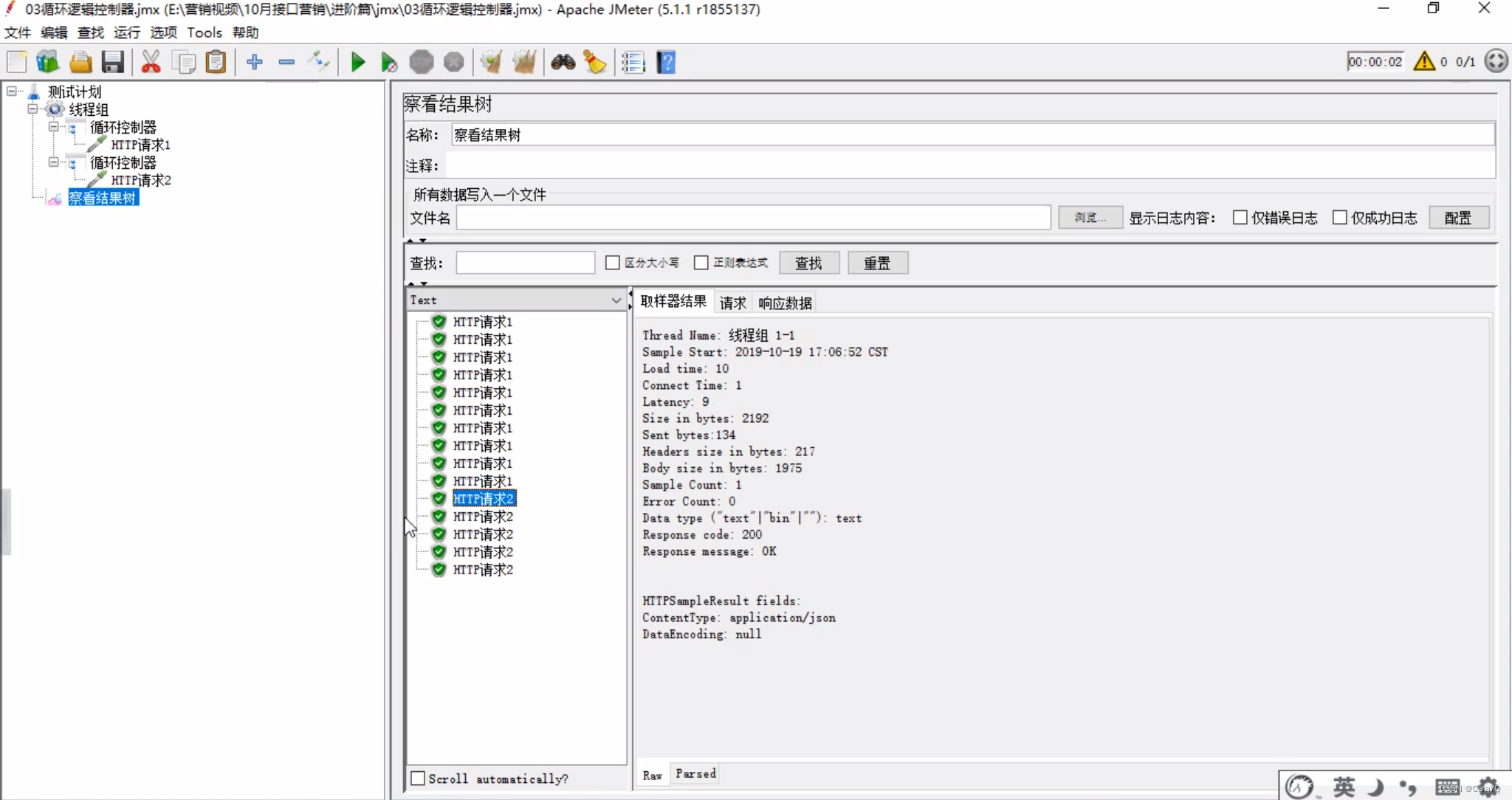
关联
一、关联: 上一个请求的响应结果和下一个请求的数据有关系,比如你查询出来了一批数据,接下来你可以对这些数据进行删除、查看、编辑等
二、xpath提取器:提取响应内容中标签的内容
- 在线程组中添加请求a:
及其察看结果树,并运行,得到如下结果
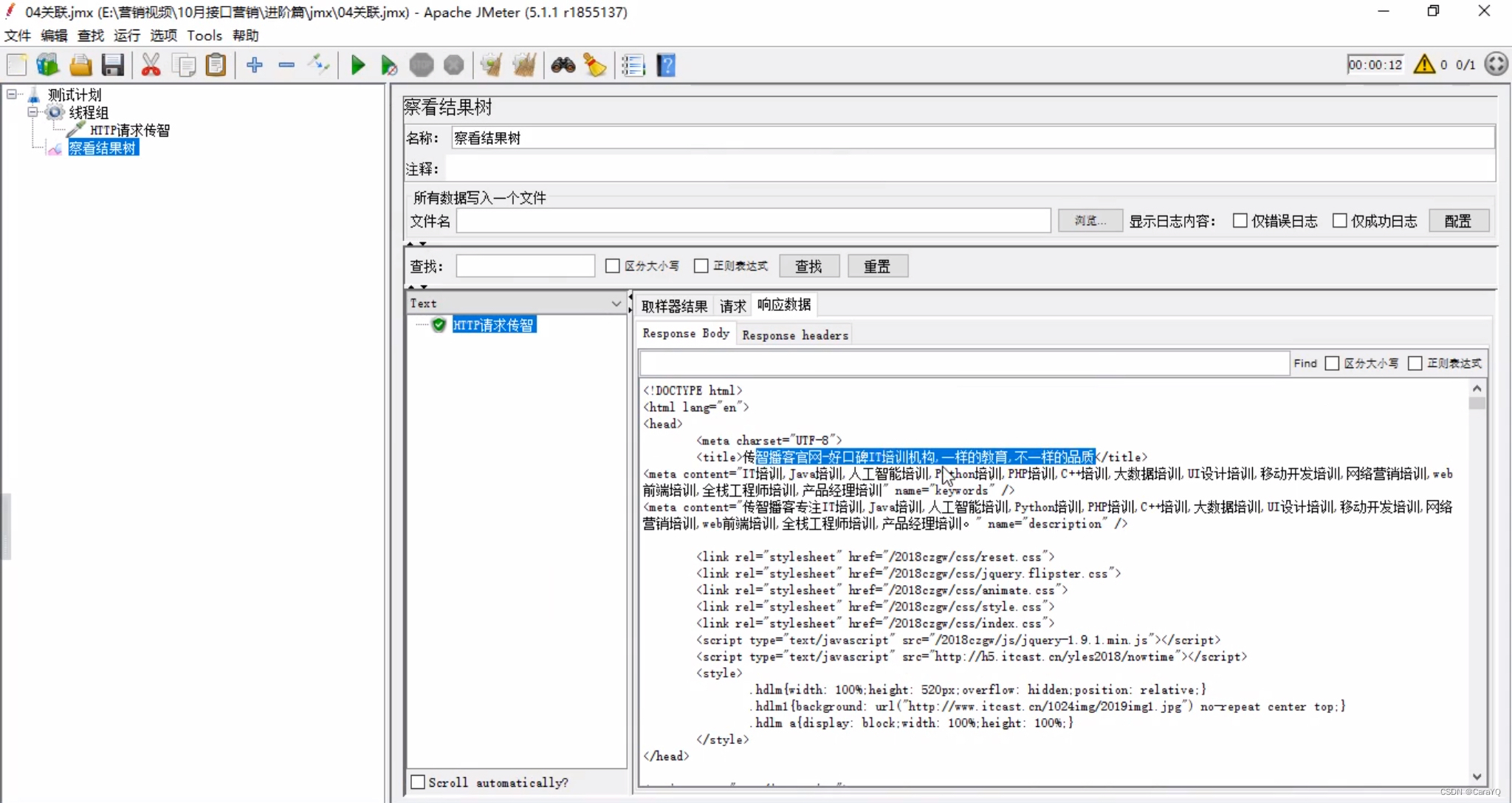
就是把响应内容的title标签的内容传给请求b,放在百度中搜索 - 把响应内容中title标签的内容取出来:在http请求上添加xpath提取器
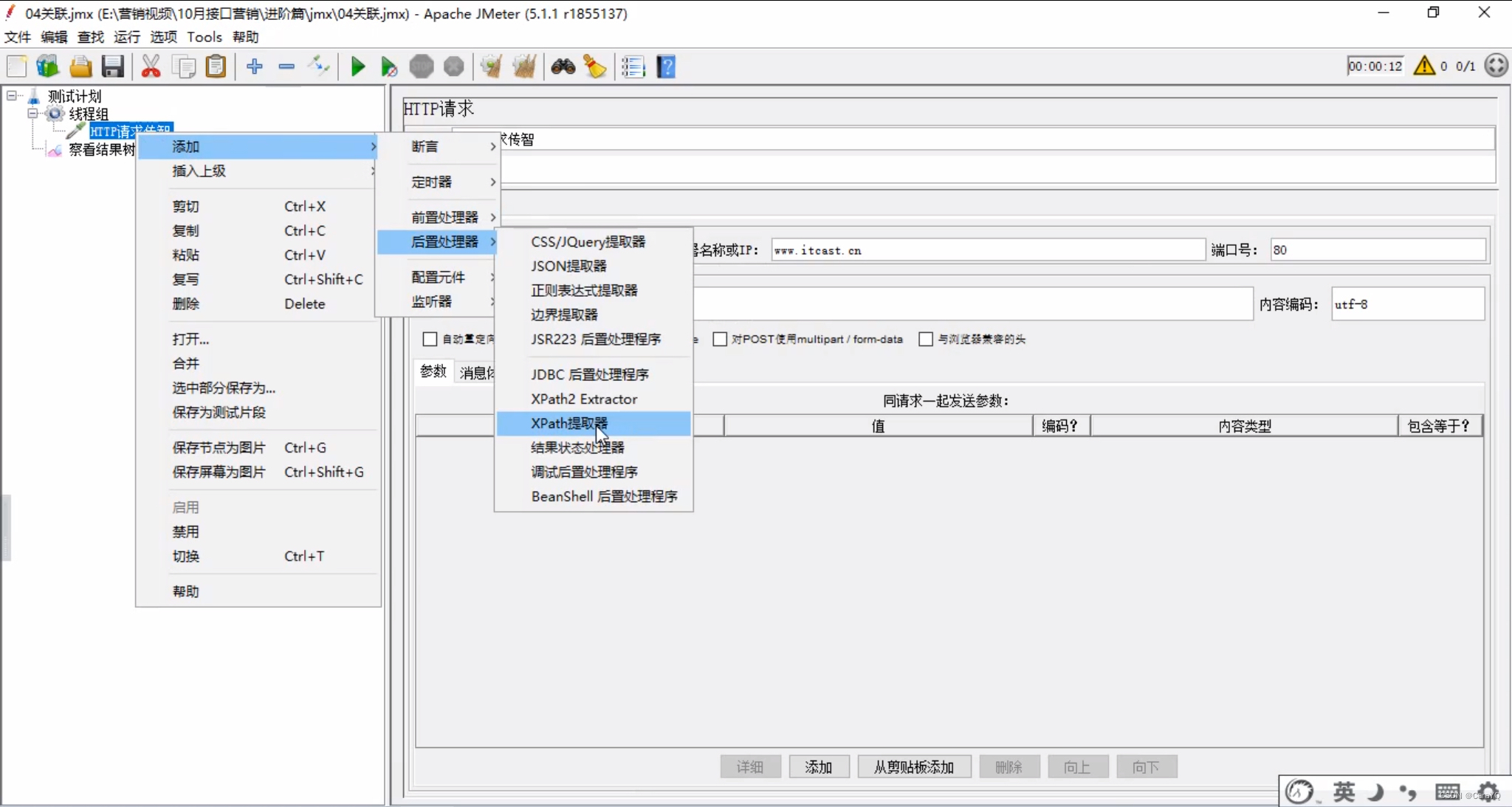
- xpath的内容如下:
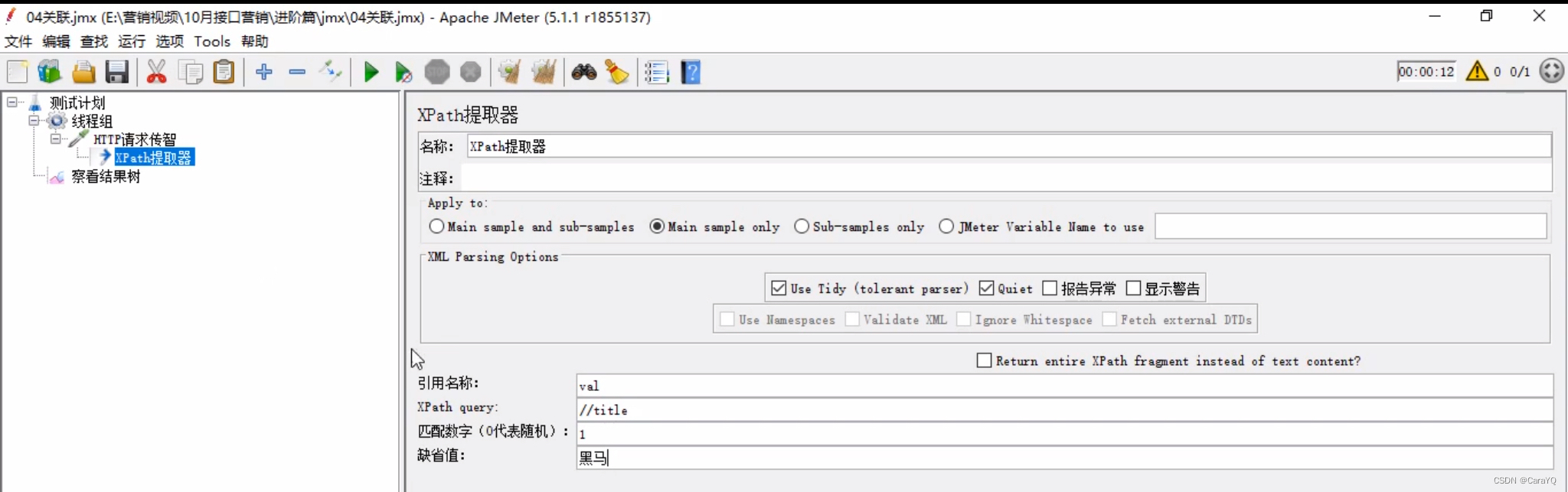
勾选use tidy(tolerant parser)表示提取标签中的内容
引用名称:随便取。取出来的内容会放在这个变量中
path query://你想获取哪个标签的内容
匹配数字:0代表随机,-1代表所有,其余数字代表获取响应内容中第几个path query的内容,在本例中就是获取响应内容中第几个title标签的内容
缺省值:如果没有找到,就是用缺省值的内容 - 在线程组上添加http请求b,内容如下:
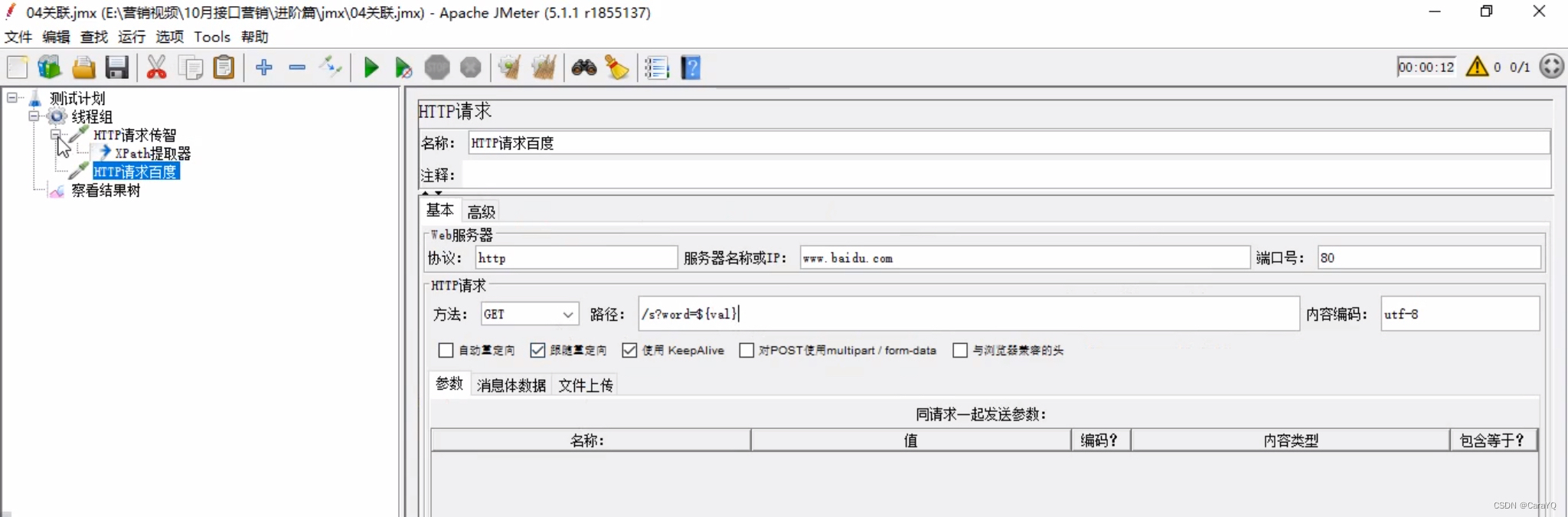
- 启动后察看结果树:
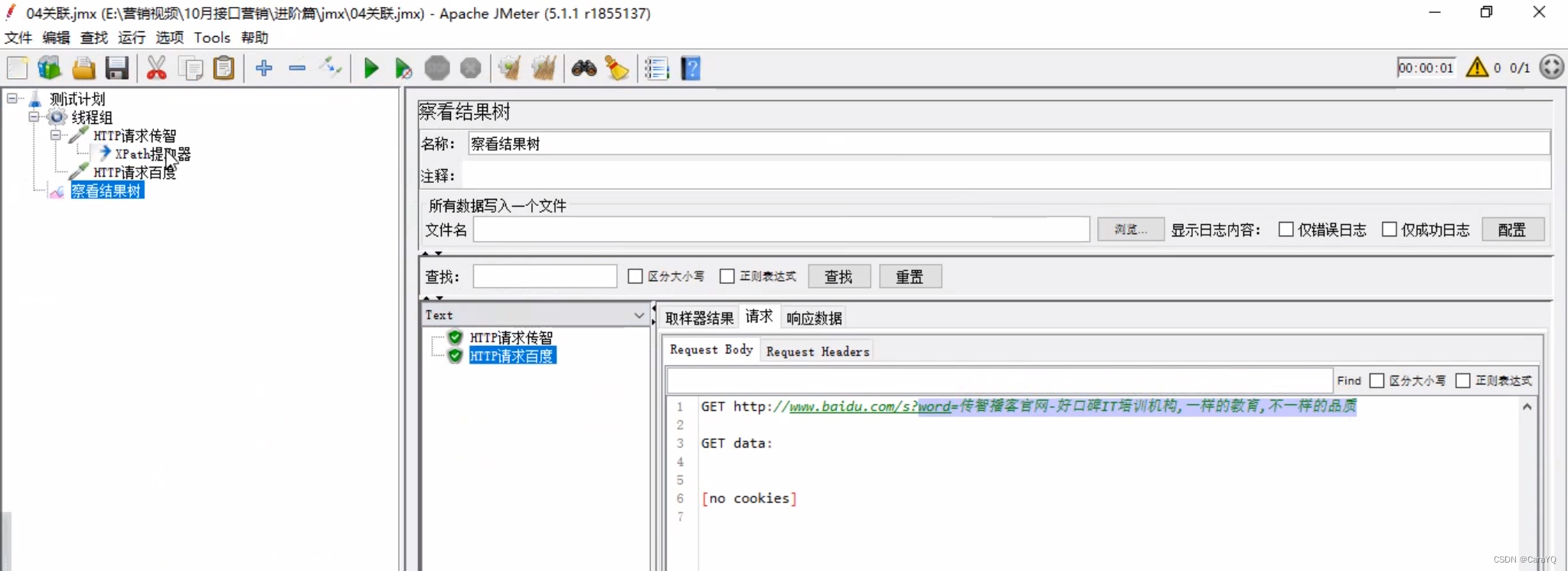
三、正则表达式提取器:如果响应内容是json数据,使用正则表达式提取器提取出来
- 在线程组上创建第一个http请求
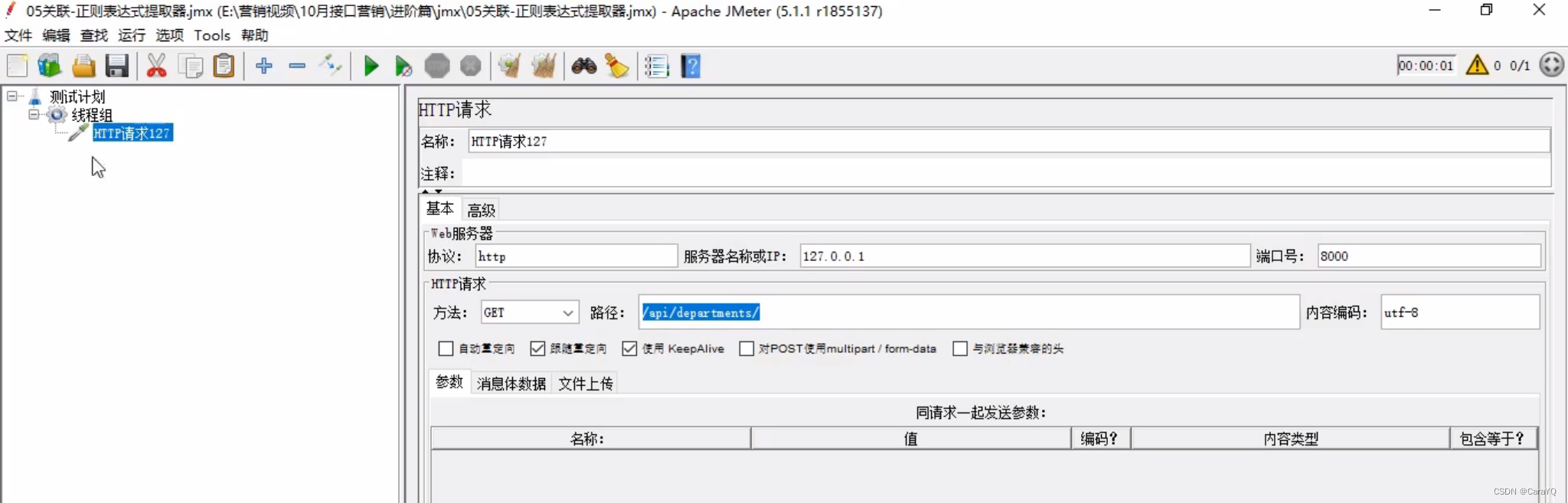
- 添加察看结果树,并启动,响应内容如下:
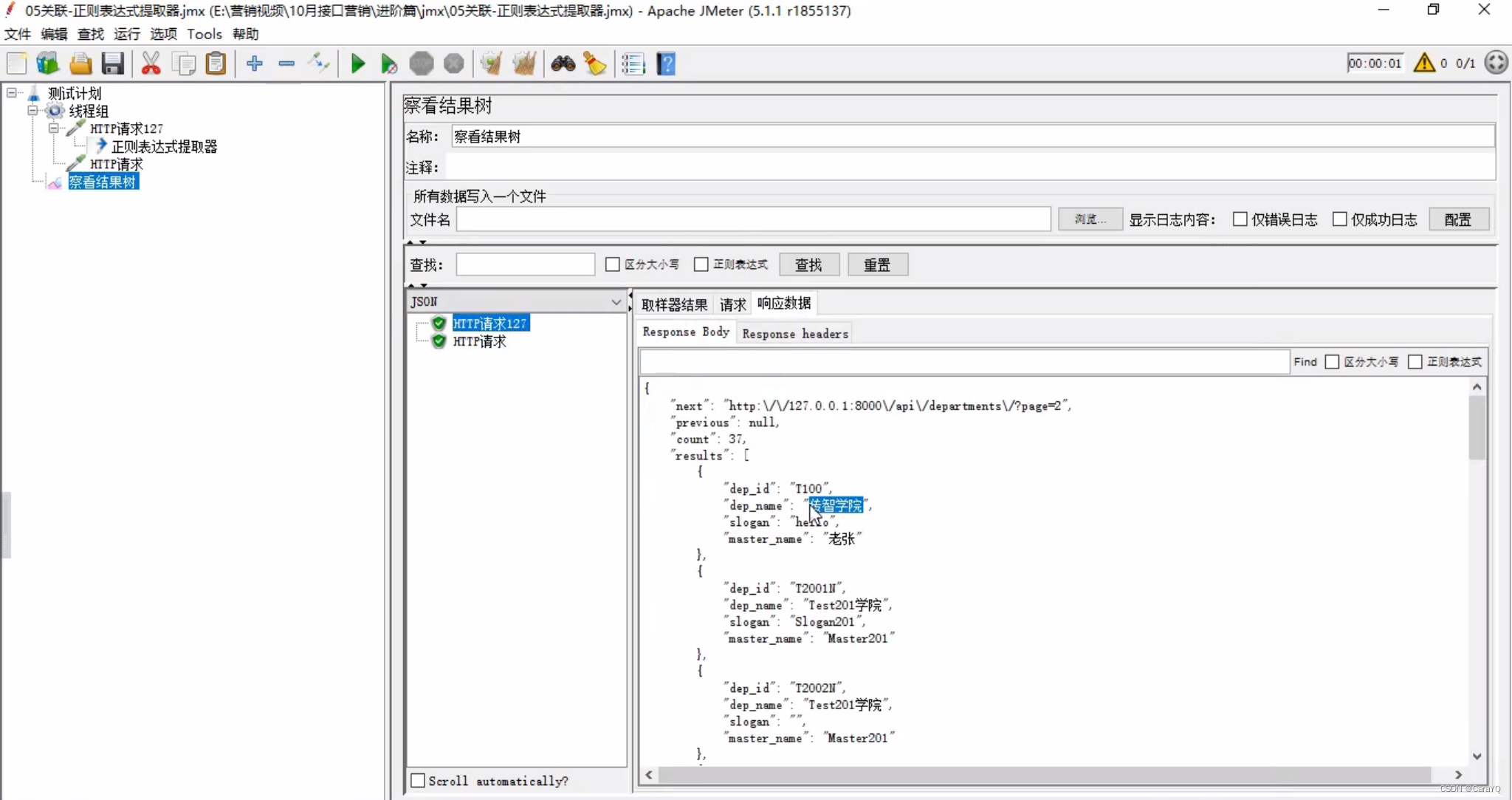
假如我们想提取响应内容中dep_name的值 - 在第一个http请求上添加正则表达式提取器
- 正则表达式提取器内容:
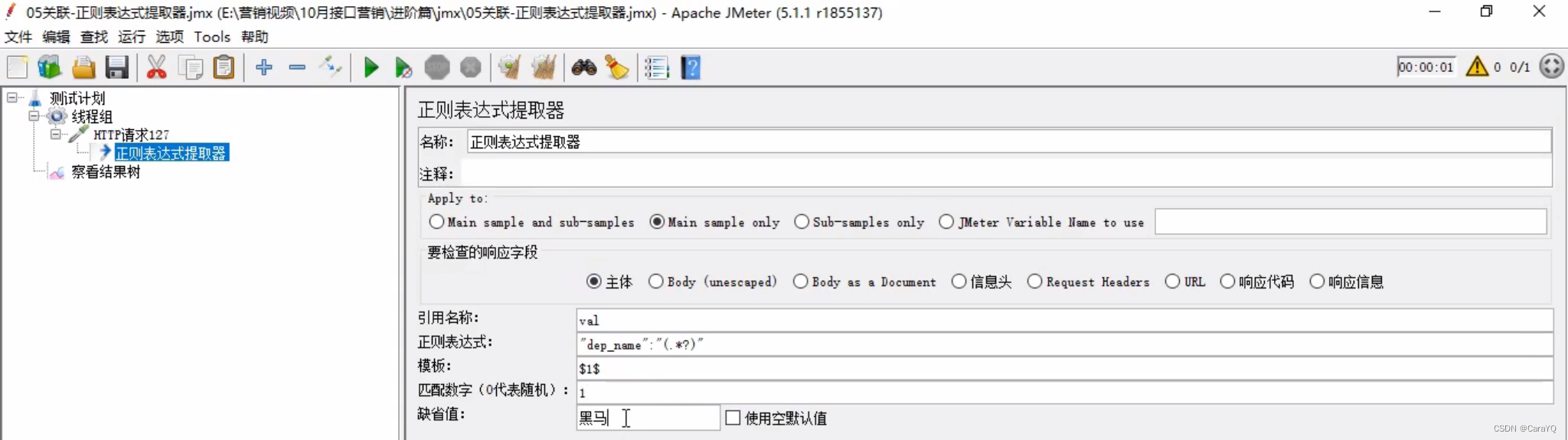
引用名称:随便取。取出来的内容会放在这个变量中
正则表达式:提取响应内容中dep_name的值的正则表达式为:"dep_name":"{.*?}",其中,.代表任意字符,*代表任意格式,?代表终止贪婪模式,即任意字符任意格式出现任意多次都行。如果不终止贪婪模式的话,即不写?,提取到的响应数据如下:
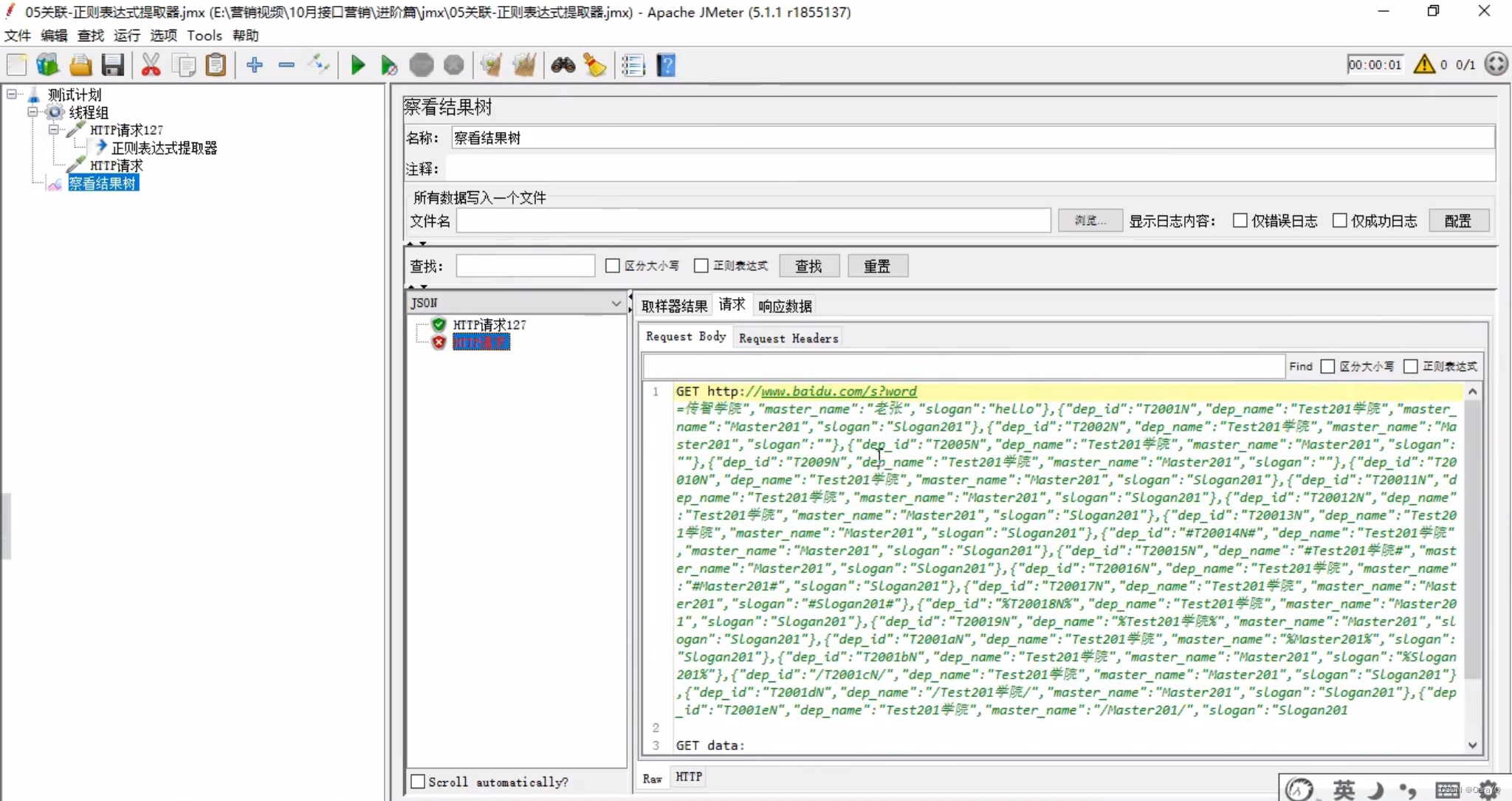
也就是说他找到你想要的内容后,会把后面所有的东西全提取出来,不会终止
模板:假如正则表达式写了很多个,模板中写$1$代表使用第一个,写$2$代表使用第二个,例如:
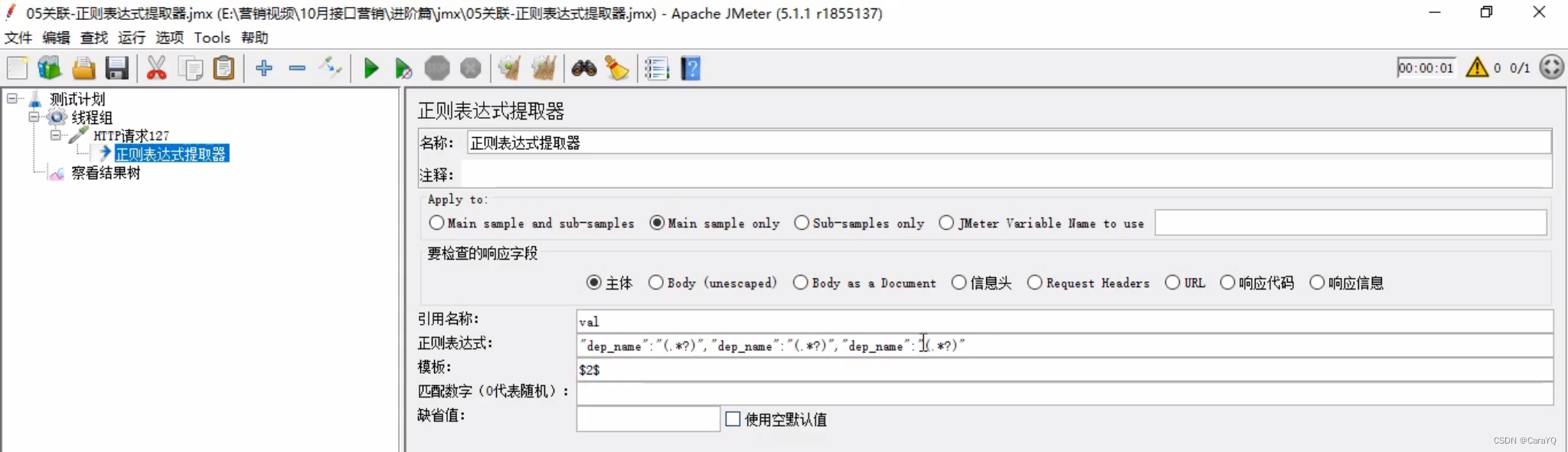
匹配数字:0代表随机,-1代表所有,其余数字代表获取响应内容中匹配到的第几个内容,在本例中就是获取响应内容中第几个dep_name的值
缺省值:如果没有找到,就是用缺省值的内容 - 新建第二个http请求:
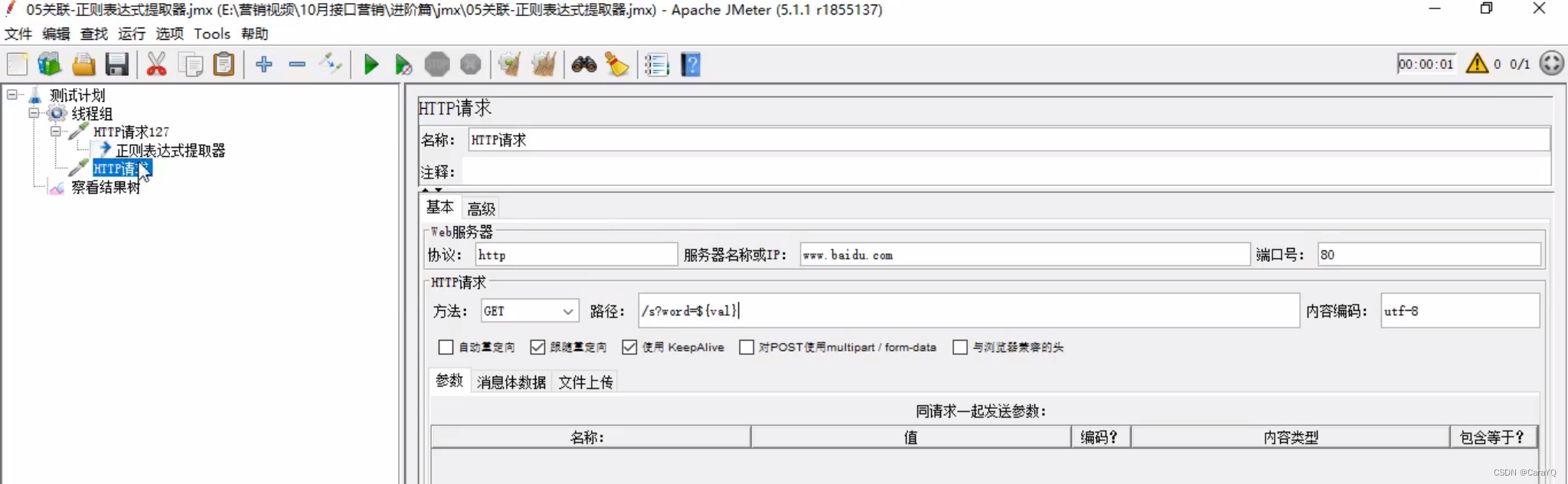
将从响应信息中获取到的数据val拼接在URL中 - 添加察看结果树,并观察其内容
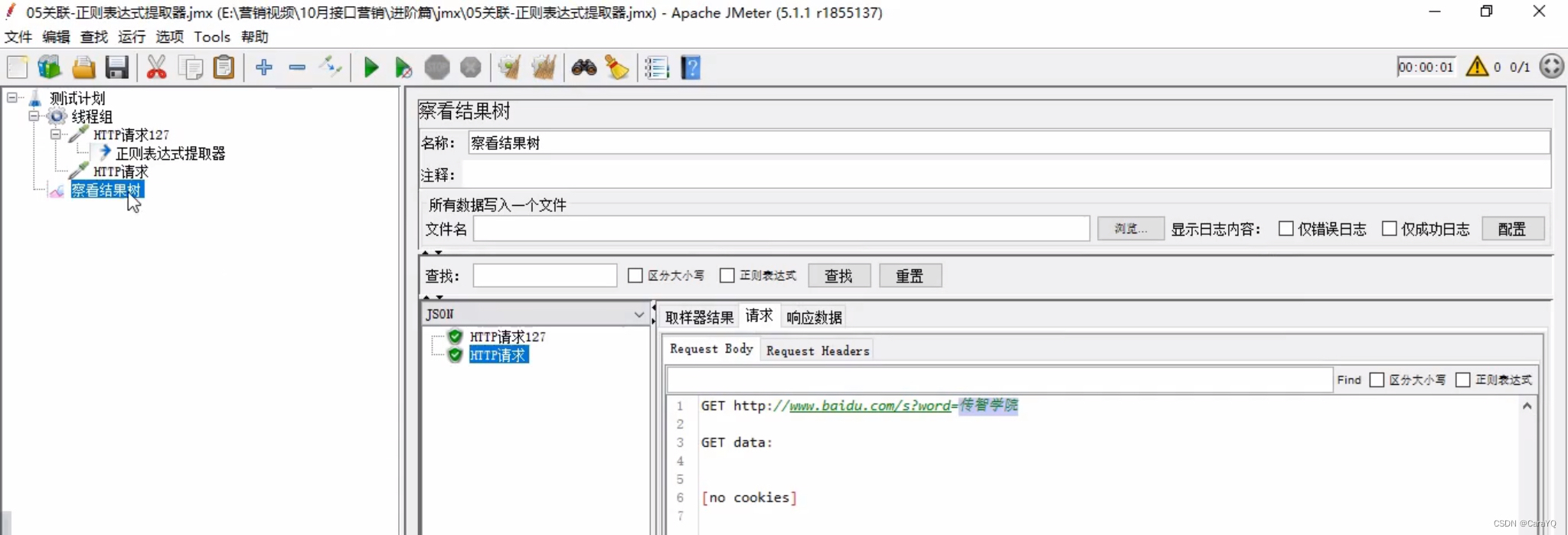
跨线程组关联
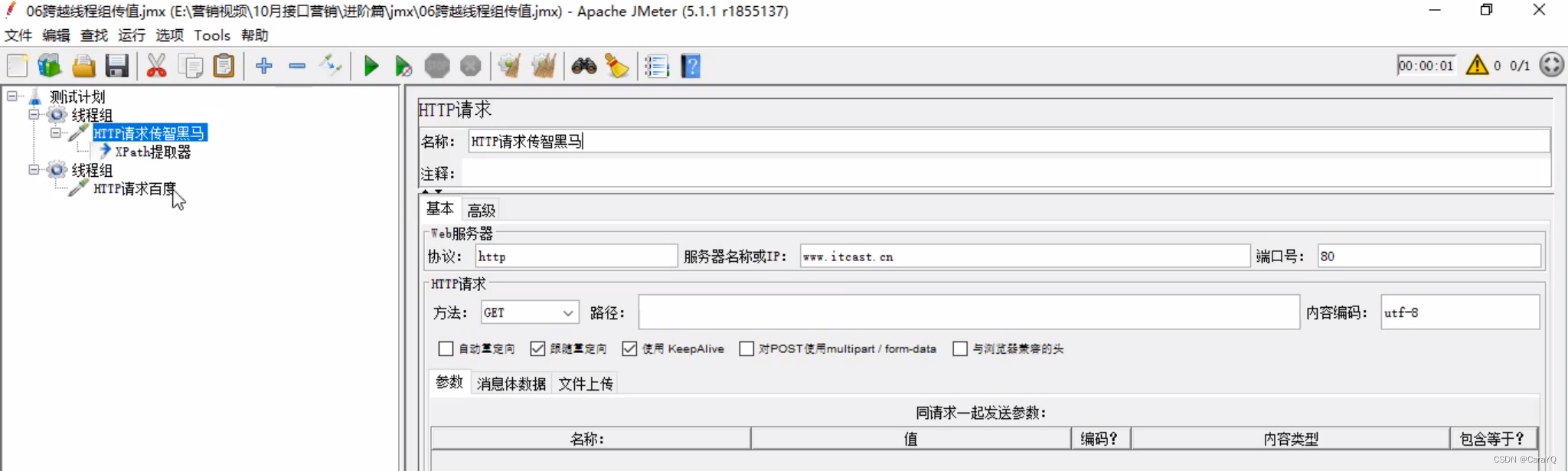
一、局部变量:某线程组中的变量只有该线程组能用,别的线程组不能用。正如前述,请求a的响应信息可以给请求b用,因为这两个请求属于同一个线程组,但是如果两个请求处在不同线程组呢?就要使用全局变量
二、变量作用域局限于当前线程组,其他线程组不可以直接调用。可以将请求A中提取的结果导出到公共空间 (可以被不同线程组共享),请求B再从公开空间调用该变量,相当于全局变量。
- 在线程组上新建http请求
- 给http请求添加后置处理器xpath
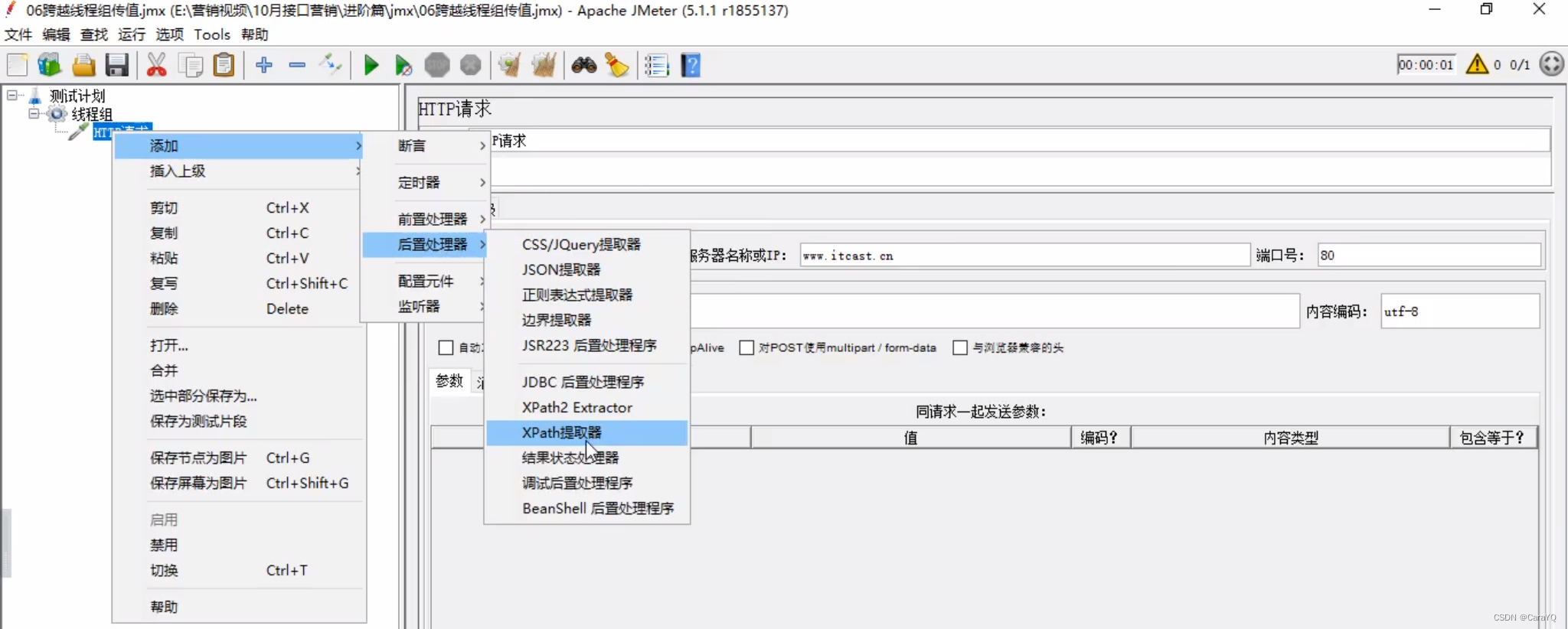
- xpath内容如下:
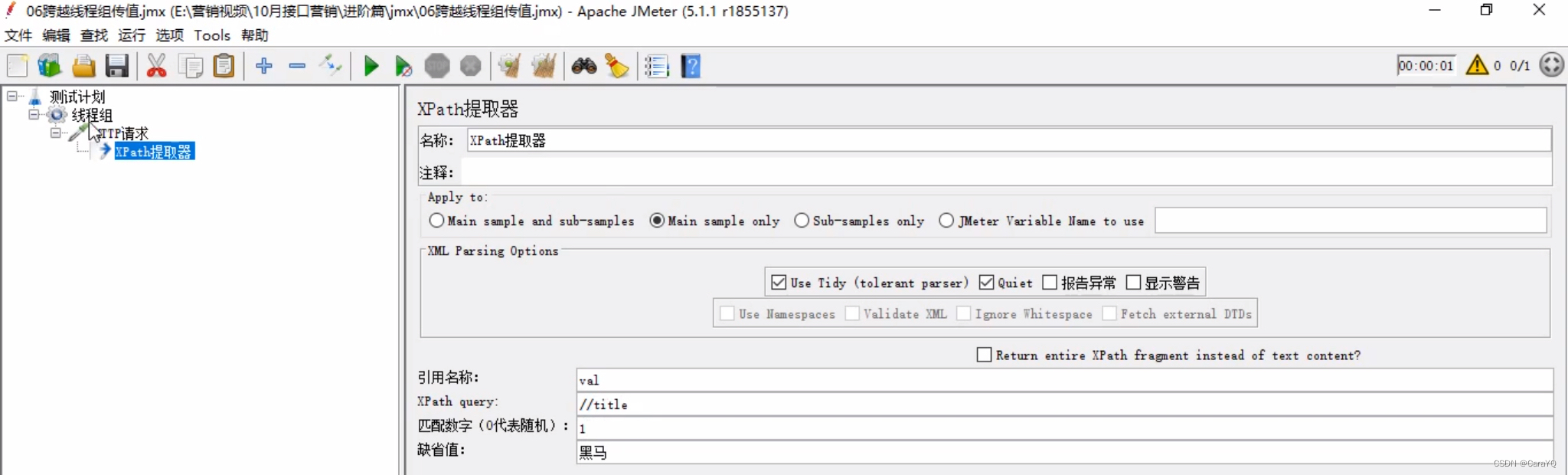
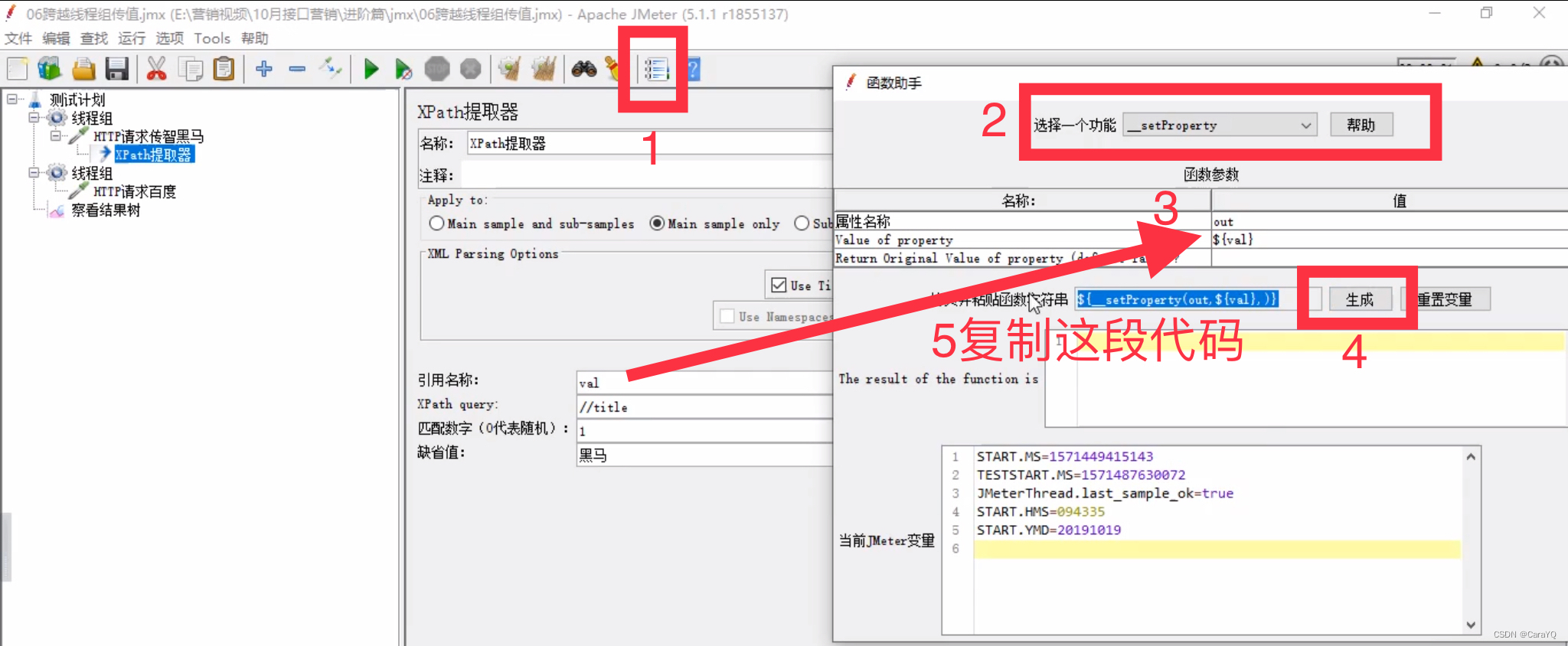
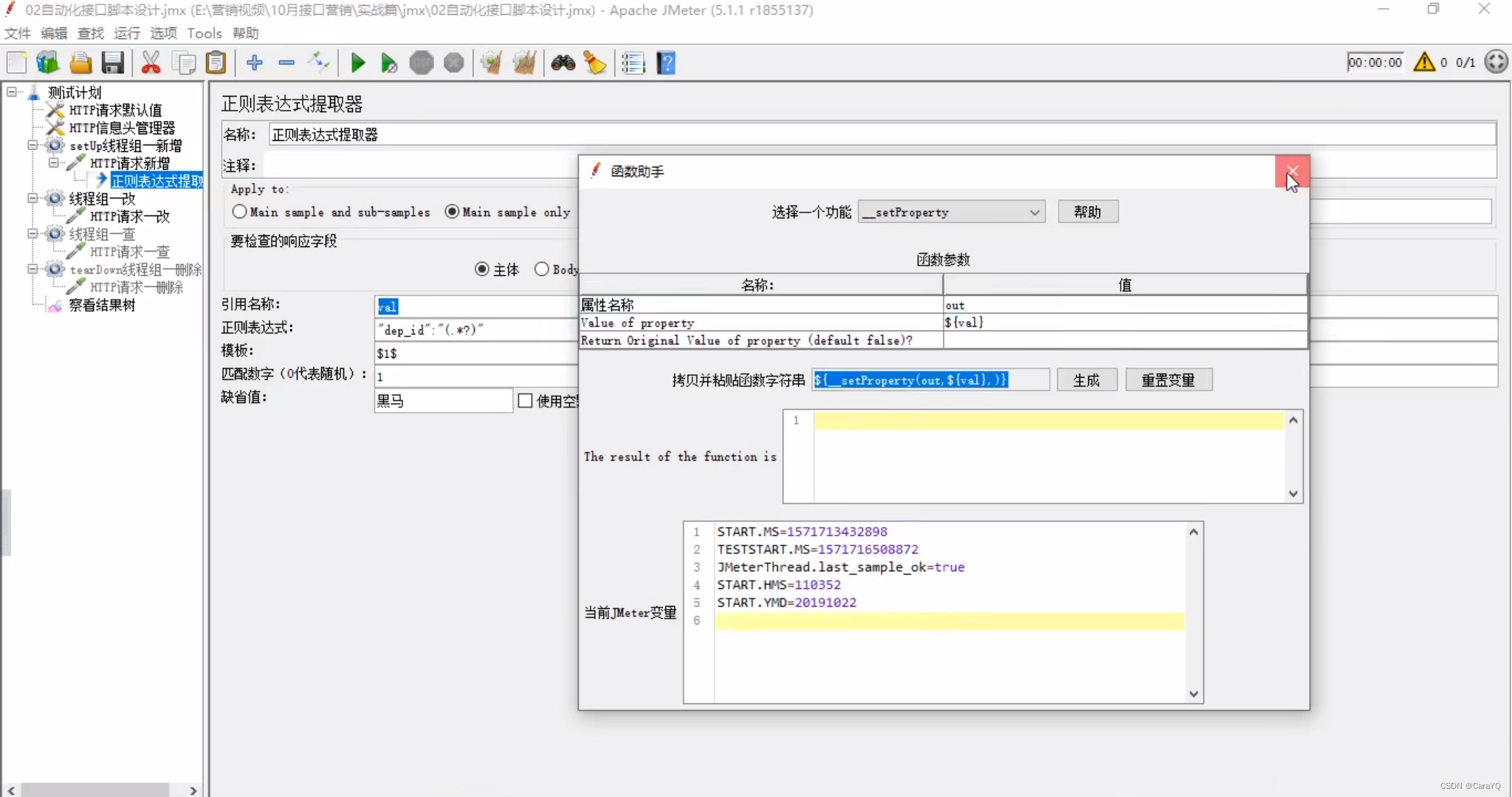
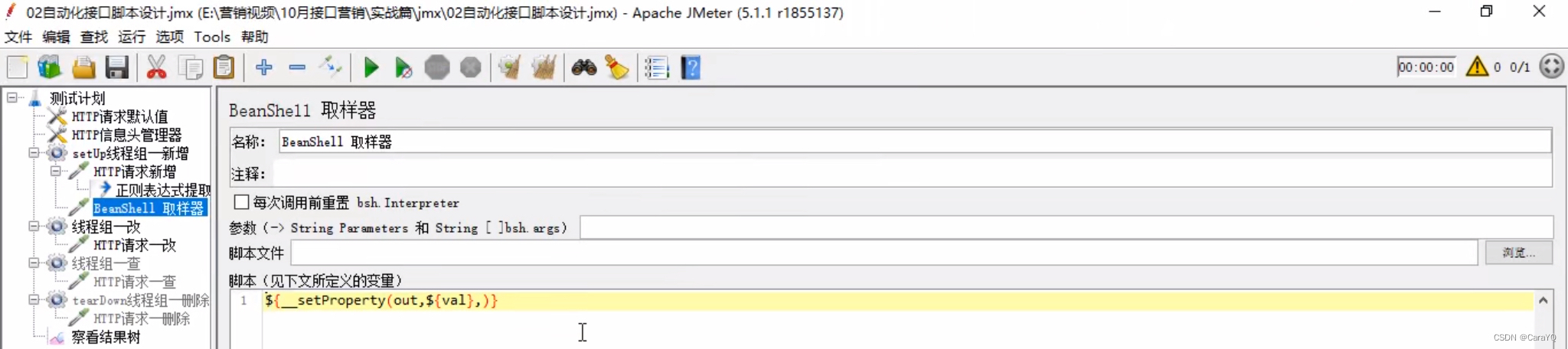
- 将第一个请求的数据导出到公共空间:在该请求中点击函数助手,选择
__setProperty,属性名称随便填,相当于你把这个数据导出到哪个变量里,属性值是要到处的数据,本例中我们是要把val中的内容导出(从响应内容中取出来的数据已经放在了val中),所以此处写${val},如果你写val,那么他会把val三个字母导出到out,而不会把val看作变量。接下来点击生成,复制选中的那句代码
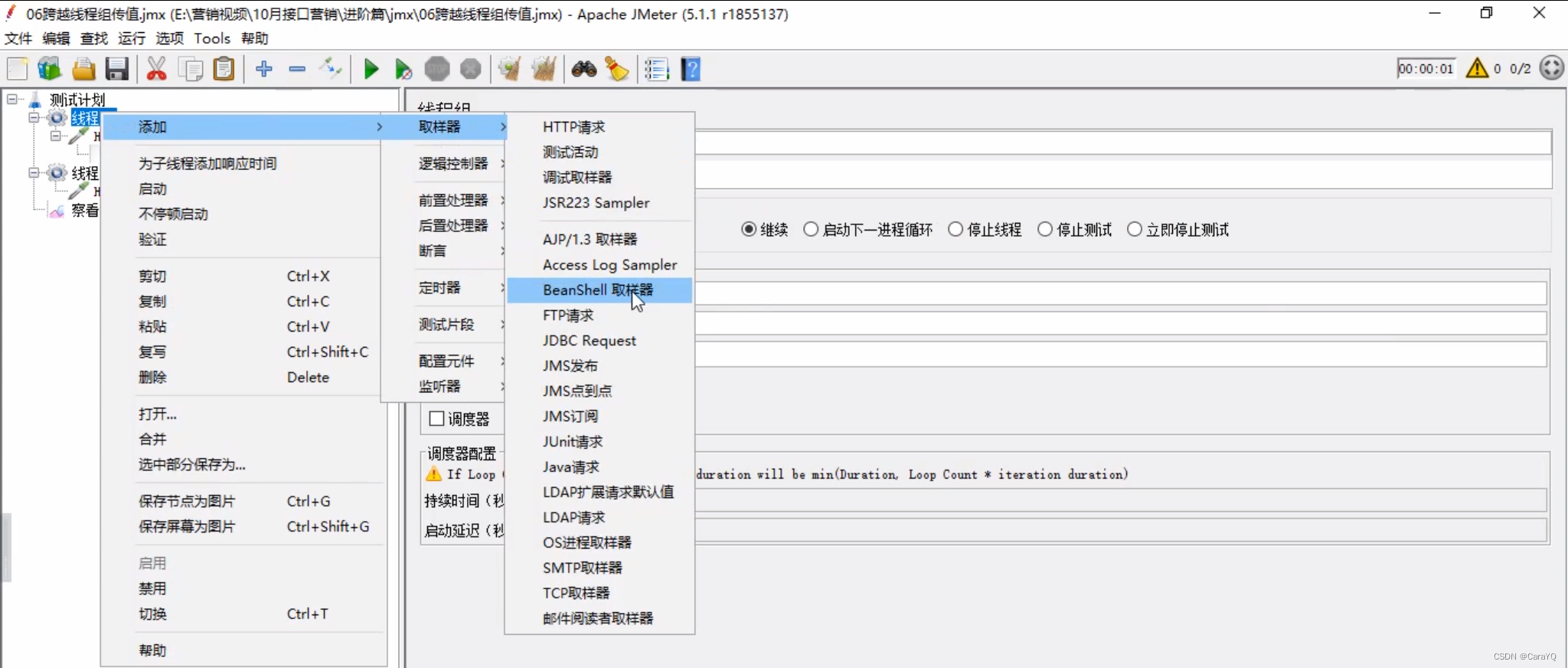
- 把代码放在beanshell取样器中:在线程组上添加beanshell取样器
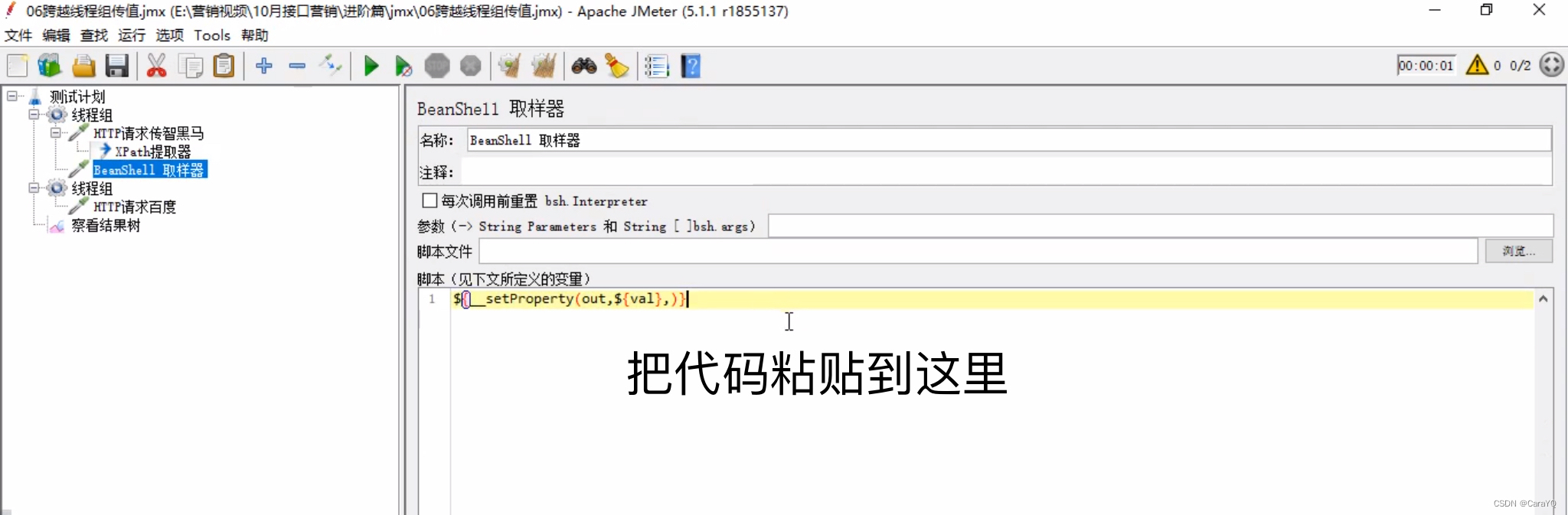
如此,就设置好了全局变量 - 在测试计划上新建一个线程组,在该线程组上新建一个http请求,该请求从公共空间调用数据 :在该请求中点击函数助手,选择
__property,注意属性名称是数据在共享空间的变量名,即out,一定要写out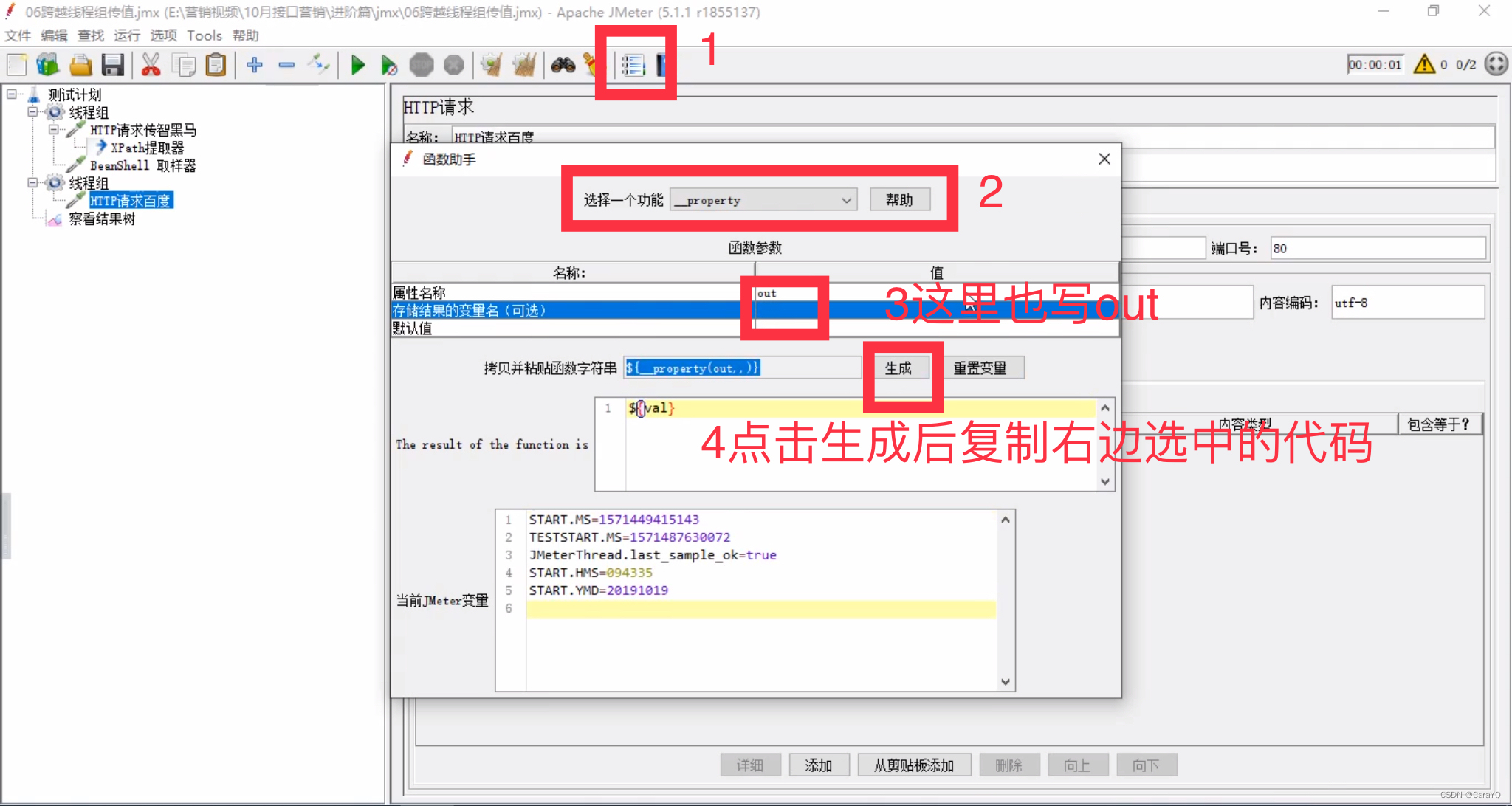
该http请求的内容如下:
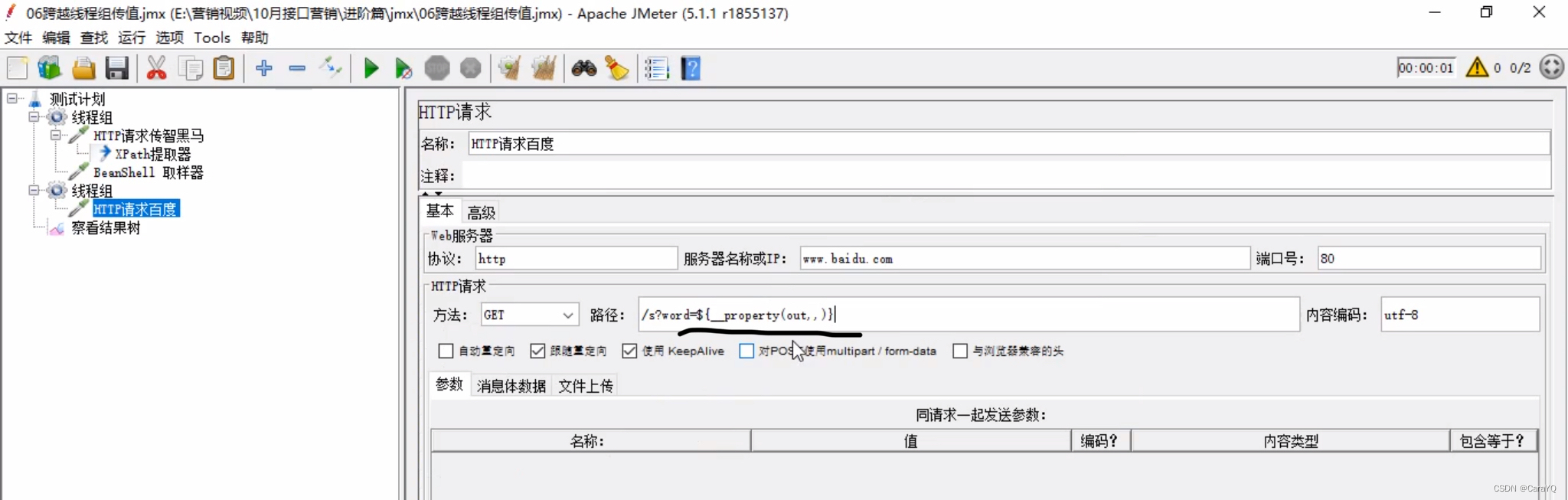
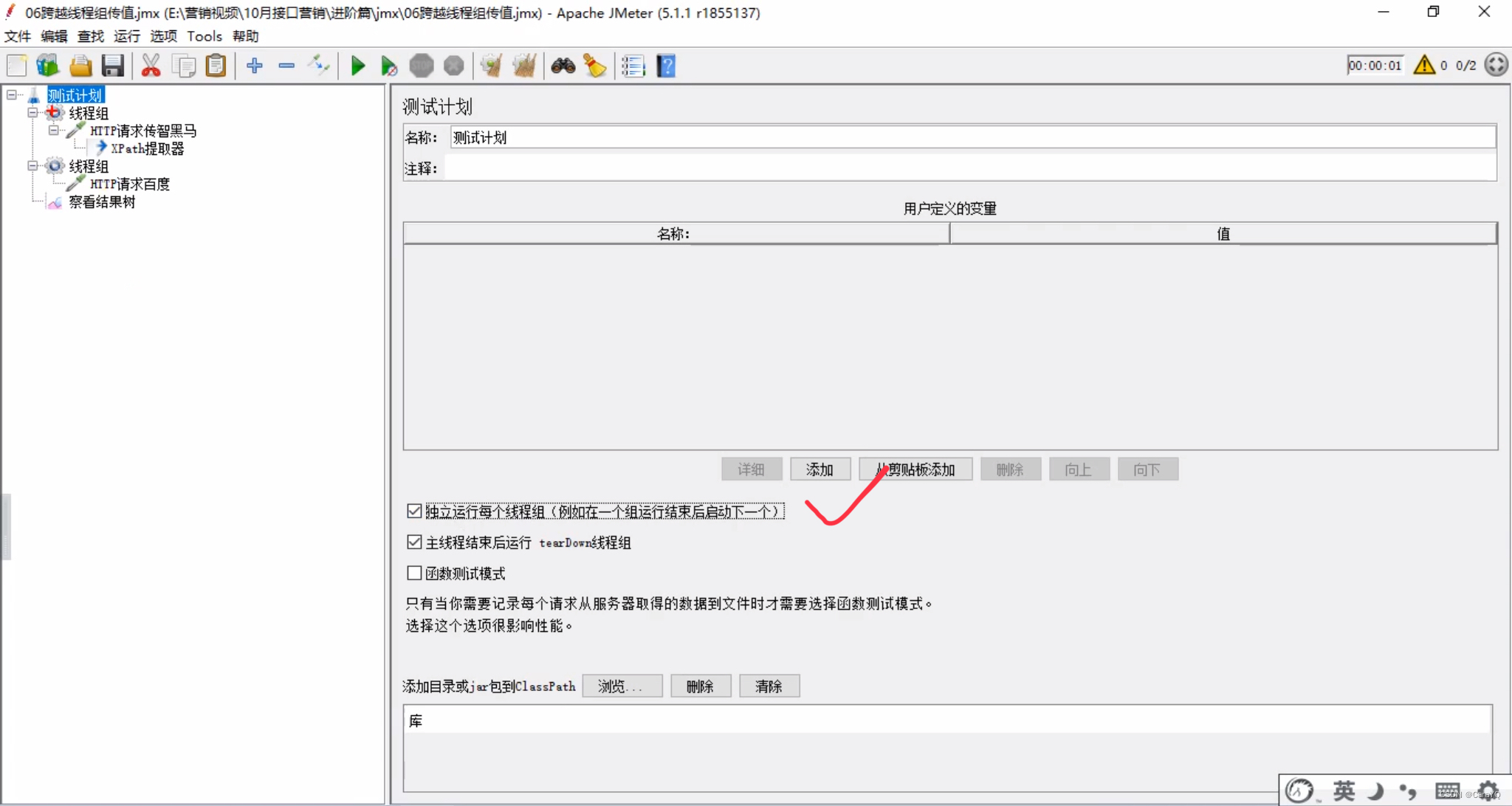
哪里要使用变量,就把复制的代码粘贴到哪里 - 在测试用例中选择【独立运行每个线程组】,否则两个线程组是并行关系
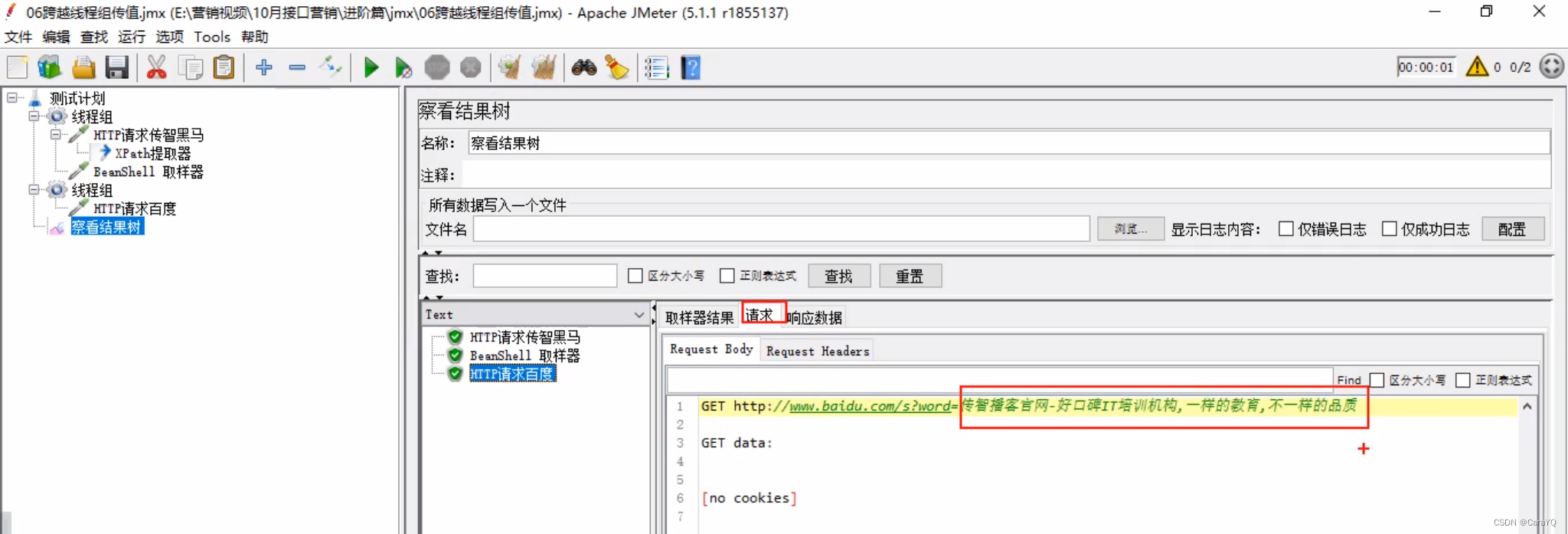
- 添加察看结果树,并启动
性能测试
性能测试:模拟各种正常的、峰值的测试环境,检测程序的各项性能指标是否能够达标
高并发
一、高并发(High Concurrency)是一种系统运行过程中遇到的一种“短时间内遇到大量操作请求”的情况,主要发生在web系统集中大量访问收到大量请求(例如:12306的抢票情况;天猫双十一活动)。该情况的发生会导致系统在这段时间内执行大量操作,例如对资源的请求,数据库的操作等。
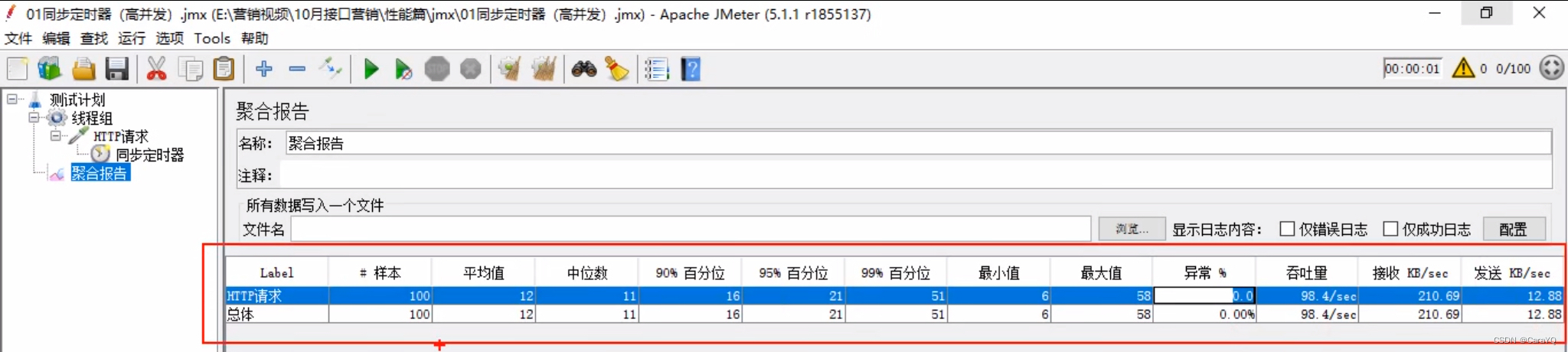
二、需求:看平均值、异常率等使用聚合报告更直观
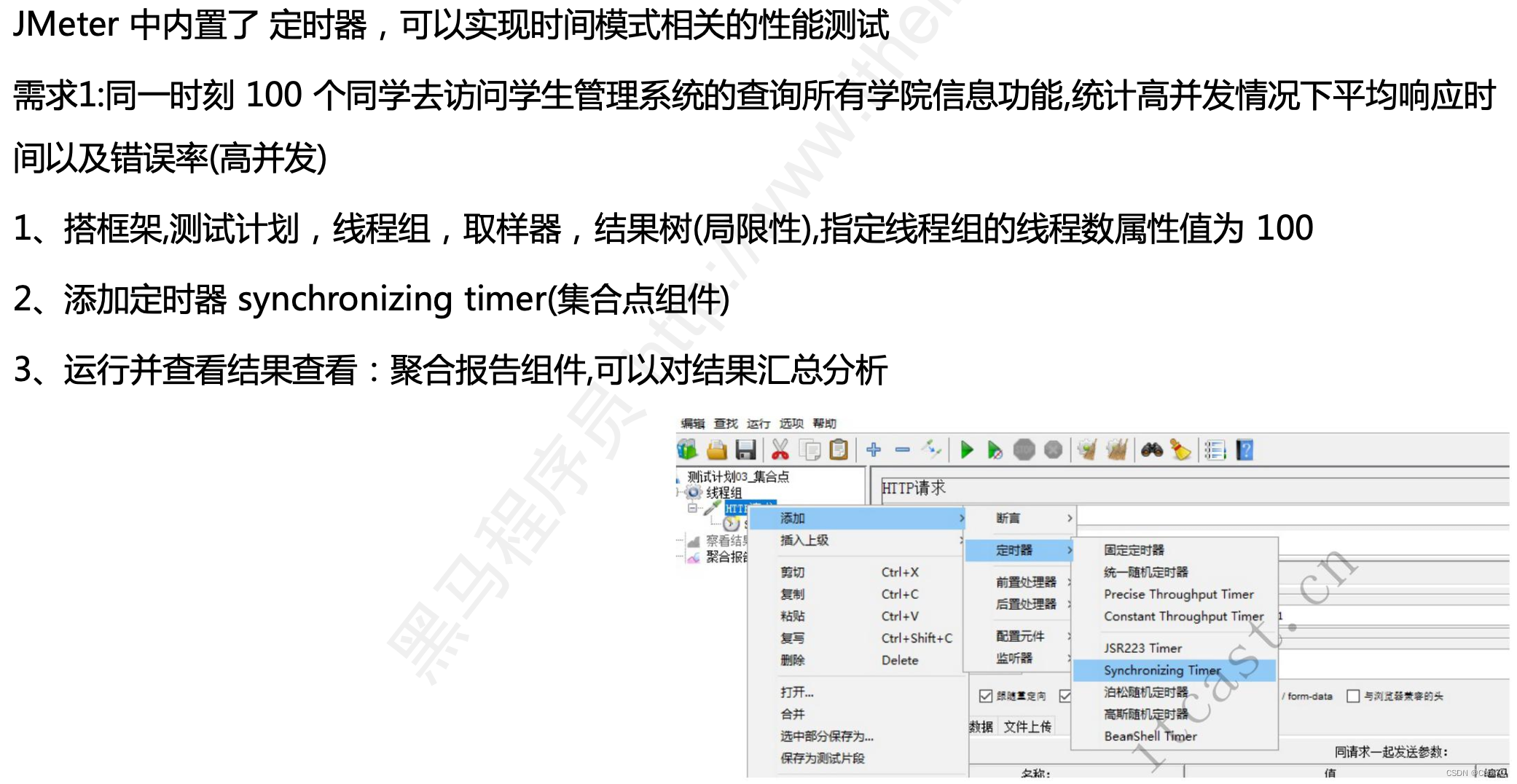
- 指定线程组的线程数为100,因为有100个同学来访问嘛,用户数就是100
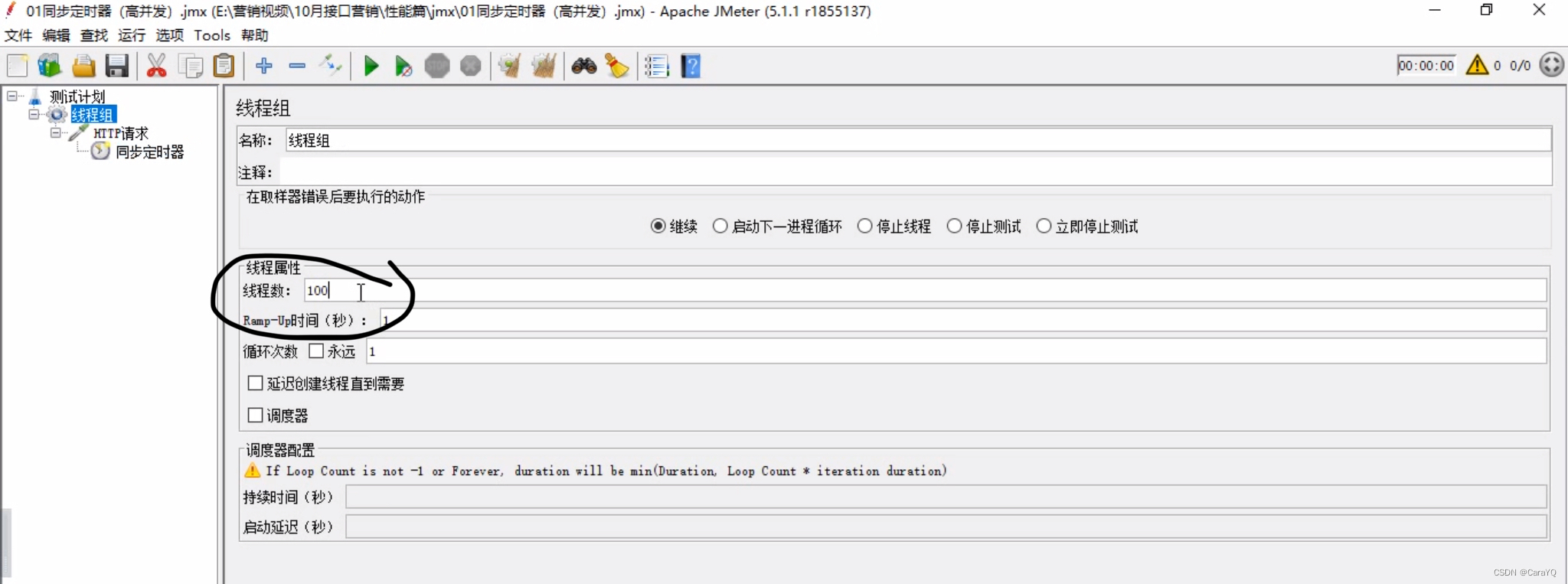
- 在线程组上新建一个http请求,内容如下:
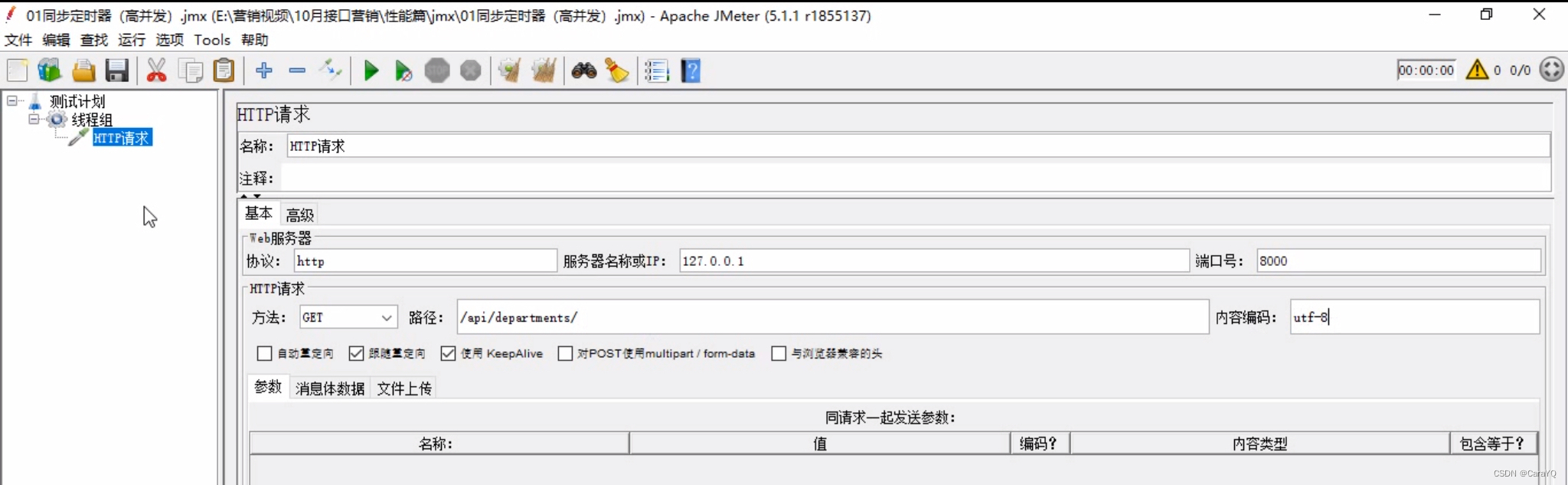
- 在http请求上添加同步定时器
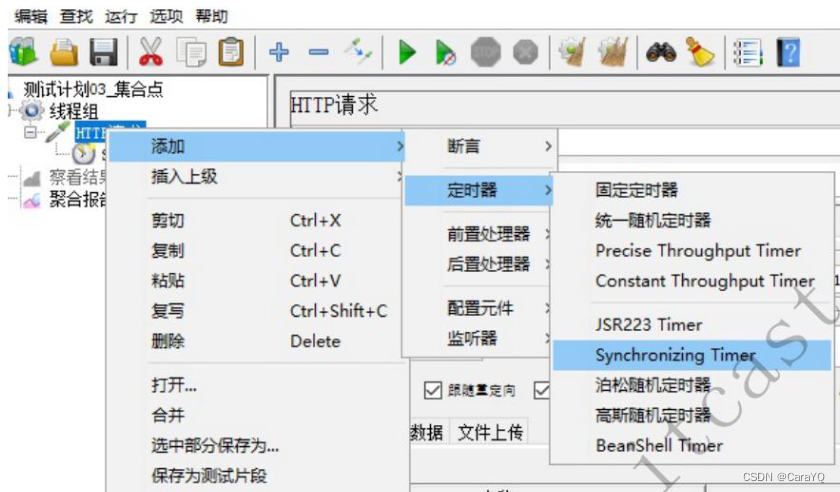
- 同步定时器内容如下:

模拟用户组的数量:即一组的数量,题目要求100个同学一起来访问,所以一组是100,如果题目要求,100人分两次访问,那么线程组的线程数为100,这里填50,每次访问50个人嘛(一组)
超时时间以毫秒为单位:如果线程组的线程数除以模拟用户组的数量除不尽,有余数,如果你又没有设置这个超时时间,那么http请求就会死等,比如线程组的线程数为100,模拟用户组的数量为30,你每一组执行30人,一共有100人,执行三组执行不完,第四组又还余20人,若超时时间为0,那么一组必须有30人他才会发送请求去执行,否则他会一直等在这里直到有30个用户,只要超时时间不为0,假如为10,难免程序等10ms管他有没有30个人都发送请求 - 在测试计划上添加聚合报告
- 启动后观察聚合报告
高频率
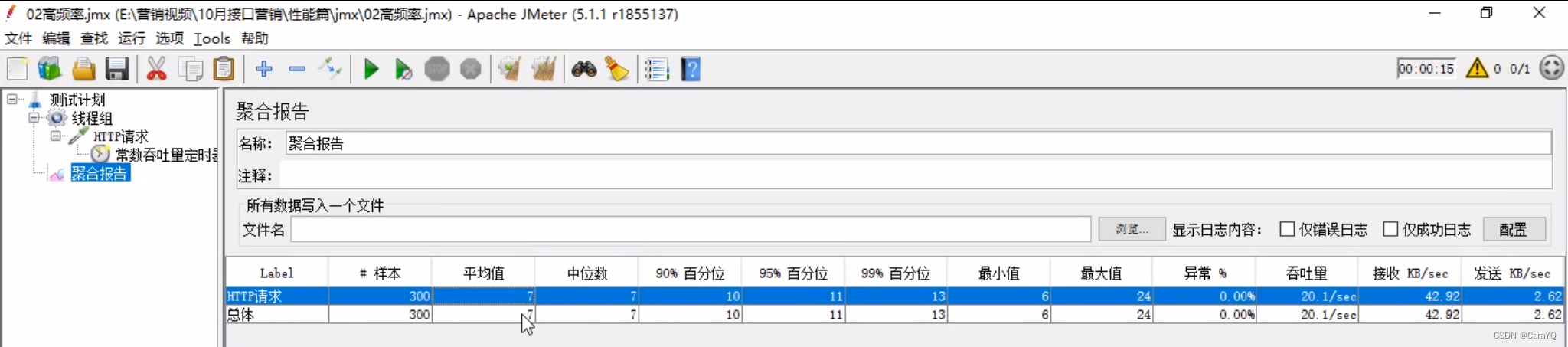
一、高频率:一秒钟访问多少多少次,持续多少秒,然后让你统计一个平均时间、错误率、正确率
二、

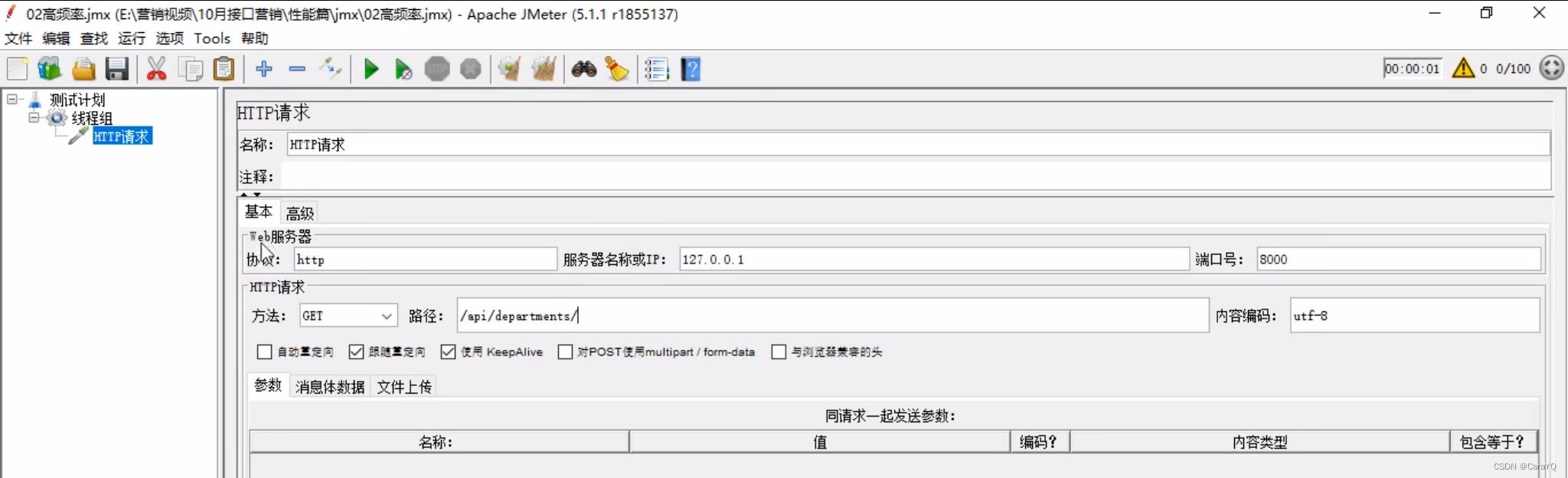
- 在线程组上添加一个http请求,内容如下:
- 在http请求上添加常数吞吐量定时器
- 常数吞吐量定时器的内容如下:

目标吞吐量(每分钟的样本量):每分钟能访问多少次,本例要求20次/s,所以一分钟访问20*60=1200次 - 本例中要求:一个用户以 20QPS ( == 20 次/s) 的频率访问学生管理系统服务器,持续15秒。那么线程组的线程数应该为1,因为只有一个用户,循环次数为300,因为20次/s,持续15s,所以一共执行300次
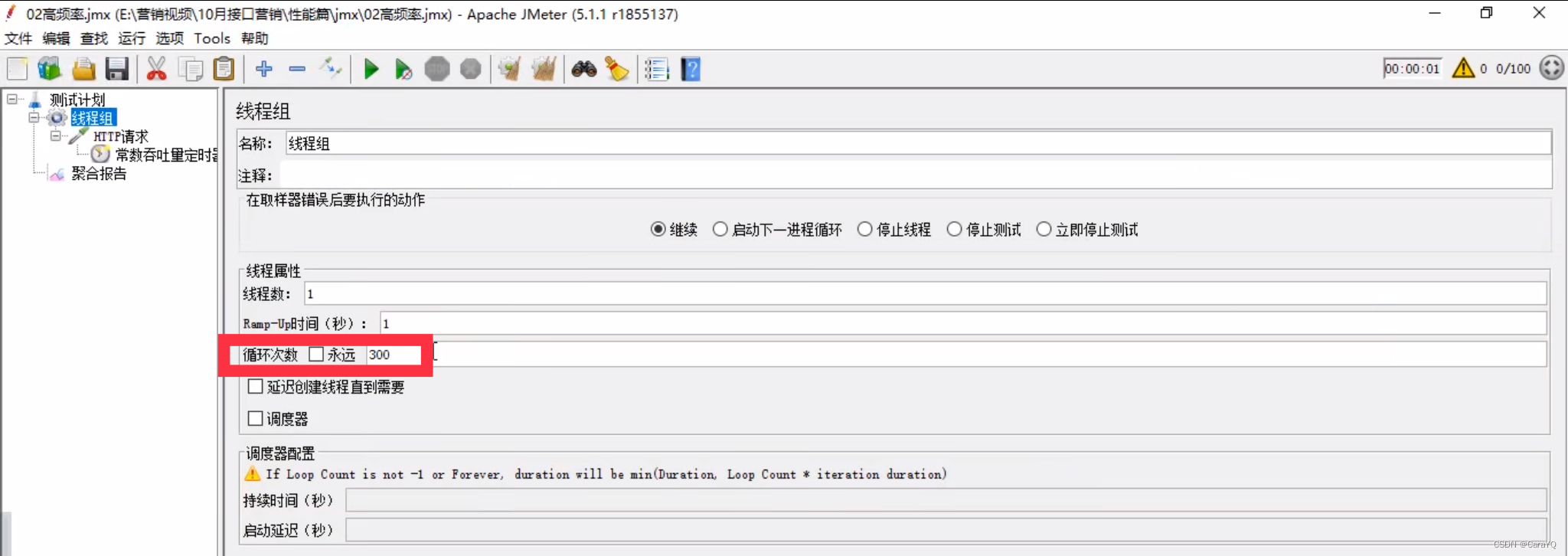
- 在测试计划上添加聚合报告,点击启动,观察聚合报告:
分布式
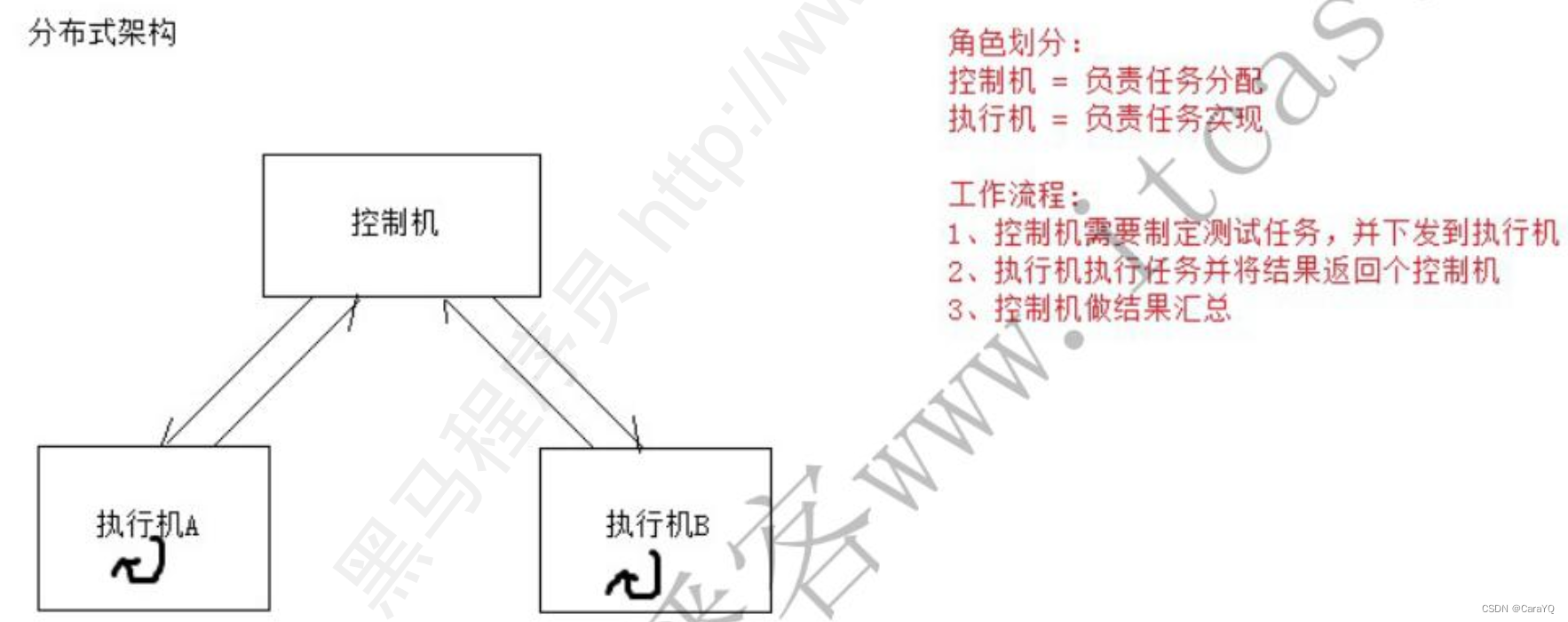
一、分布式:多台机协作,以集群的方式完成测试任务,可以提高测试效率。比如说有一个测试任务需要你访问10000次、100000次,如果你只有一台测试机,测试效率会很慢,如果你有两台测试机,那时间能减少一半,如果你有三台测试机,那测试时间只用1/3。做一件事,人越多,耗时越少,效率越高
二、分布式架构特点:你必须要有一台控制机,用于发布指令,接受任务返回的结果,还需要有若干台执行机,负干活
三、环境搭建:
- 不同的测试机上安装Jmeter
- 配置基础环境(统一操作系统、JDK、Jmeter … )
- 核心: 控制机如何与执行机通信? 关键点:端口号
- 控制机中设置执行机的IP,找到jmeter安装目录bin的jmeter.properties,即
%JMETER_HOME%/bin/jmeter.properties,设置remote_hosts=执行机A的IP:端口号, 执行机B的IP:端 口号, .....

并且控制机和执行机都得在该文件%JMETER_HOME%/bin/jmeter.properties中,设置远程访问相关属性:server.rmi.ssl.disable=true

四、启动执行机,点击执行机的jmeter.bat,每个执行机都要点
五、控制机脚本写好后,点击远程启动所有即可
接口测试流程
步骤:
- 制定测试计划,分配任务,你leader做
- 从 API 文档中提取接口清单:对API文档简化,提高测试效率,接口清单就是对API文档简化压缩主要提取三要素:请求地址、请求数据、请求方式
- 设计测试用例并参数化覆盖测试用例
- 编写脚本实现,并导入设计的测试数据;自动化接口脚本的设计:每次更新都要保证之前的代码没有收到影响,所以要把最基本的增删改查功能设计一套自动化执行的脚本,每次更新后执行这个脚本文件, 查看是否老接口有影响(此时程序已经在执行了,测试的数据不能对现有的数据进行污染)
- 测试结果汇总,BUG提交
测试数据准备
一、需求文档及书写测试用例思路
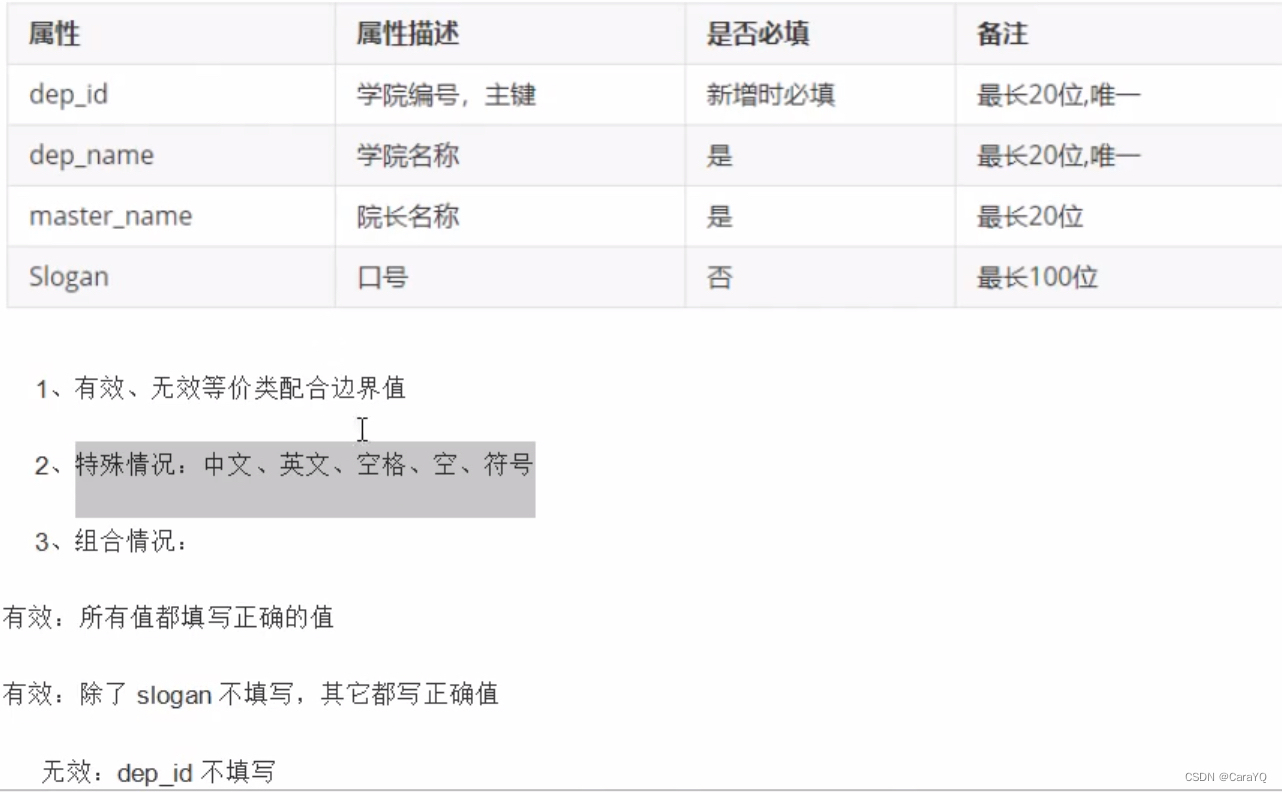
二、测试用例
T2001N,Test201学院,Master201,Slogan201,----全传正常数据
T2002N,Test201学院,Master201,----必填正常数据
T2001N,Test201学院,Master201,Slogan201,----dep_id已存在校验
123 T1,Test201学院,Master201,Slogan201,----id含空格
,Test201学院,Master201,Slogan201,----id为空
中文,Test201学院,Master201,Slogan201,----id含中文
!@we12,Test201学院,Master201,Slogan201,----id含特殊符号
t1212121212,Test201学院,Master201,Slogan201,----id10位
t12121212121,Test201学院,Master201,Slogan201,----id11位
t121345678,Test201学院,Master201,Slogan201,----id9位
t,Test201学院,Master201,Slogan201,----id1位
T2005N,Master201,Slogan201,----dep_name为空
T2006N,呵呵 学院,Master201,Slogan201,----dep_name含空格
T2007N,呵呵_学院,Master201,Slogan201,----dep_name含下划线
T2008N,呵呵-学院,Master201,Slogan201,----dep_name含中划线
T2009N,呵呵!学院,Master201,Slogan201,----dep_name含中划线
T2010N,大按键基督教就家世界基督教加建设大街就是,Master201,Slogan201,----dep_name20位
T2011N,大按键基督教就家世界基督教加建设大街就是的,Master201,Slogan201,----dep_name21位
T2011N,大按键基督教就家世界基督教加建设大街就,Master201,Slogan201,----dep_name19位
T2011N,大,Master201,Slogan201,----dep_name1位
T2105N,Master201,Slogan201,----master_name为空
T2206N,呵呵,Slogan201,----master_name含空格
T2207N,呵呵,呵呵_学院,Slogan201,----master_name含下划线
T2208N,呵呵,呵呵-学院,Slogan201,----master_name含中划线
T2309N,呵呵,呵呵!学院,Slogan201,----master_name含中划线
T2410N,呵呵,大按键基督教就家世界基督教加建设大街就是,Slogan201,----master_name位
T2511N,呵呵,大按键基督教就家世界基督教加建设大街就是的,Slogan201,----master_name位
T2611N,呵呵,大按键基督教就家世界基督教加建设大街就,Slogan201,----master_name位
T2411N,呵呵,大,Slogan201,----master_name位
T211101N,Test201学院,Master201,1111111111222222222211111111112222222222111111111122222222221111111111222222222211111111112222222222,----Slogan100位
T211101N,Test201学院,Master201,11111111112222222222111111111122222222221111111111222222222211111111112222222222111111111122222222223,----Slogan101位
T211101N,Test201学院,Master201,111111111122222222221111111111222222222211111111112222222222111111111122222222221111111111222222222,----Slogan99位
T211101N,Test201学院,Master201,1,----Slogan1位
编写脚本实现,并导入设计的测试数据
一、在线程组上添加http请求、察看结果树。
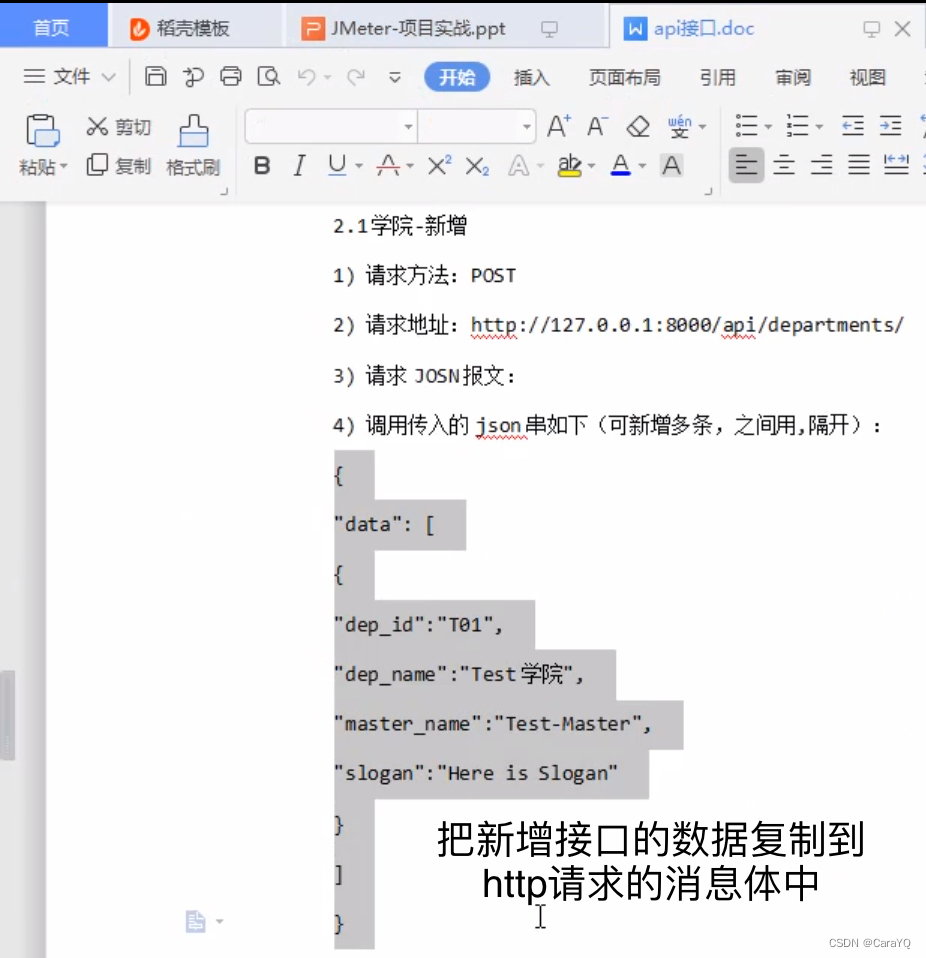
http请求的内容如下,注意方式应该是post,后面的图都写错了

二、因为我们是新增操作,所以必须有http信息头管理器,在测试计划上添加,http信息头管理器内容如下:

三、把我们刚才写的csv格式的测试用例导进来
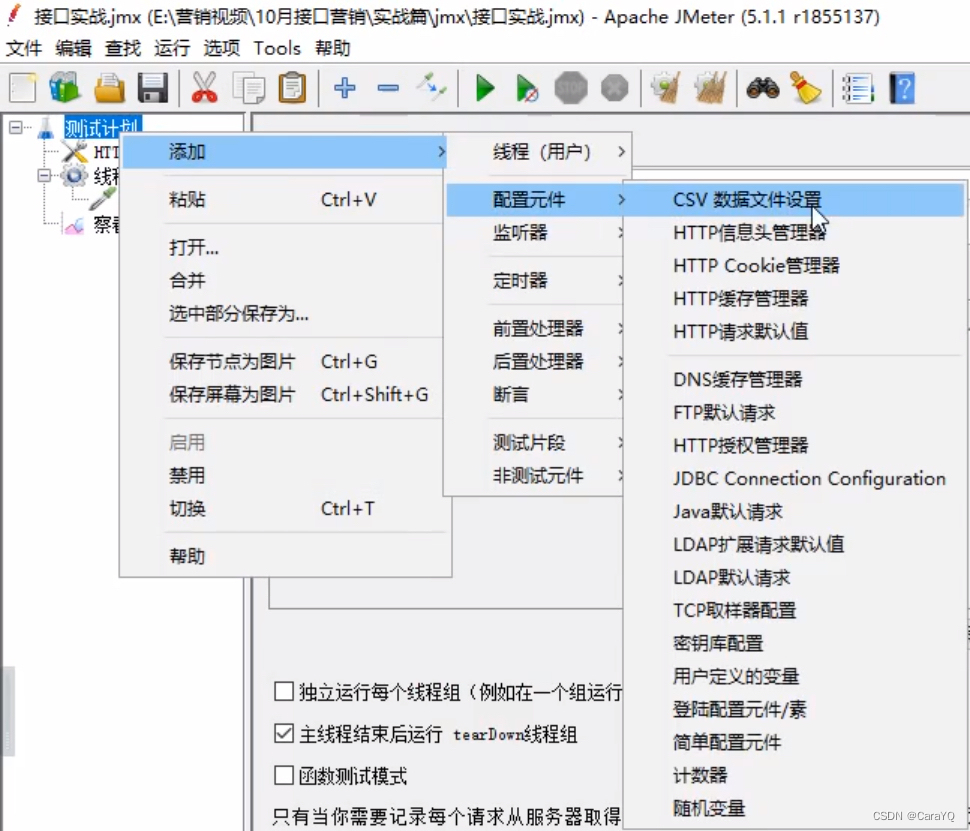
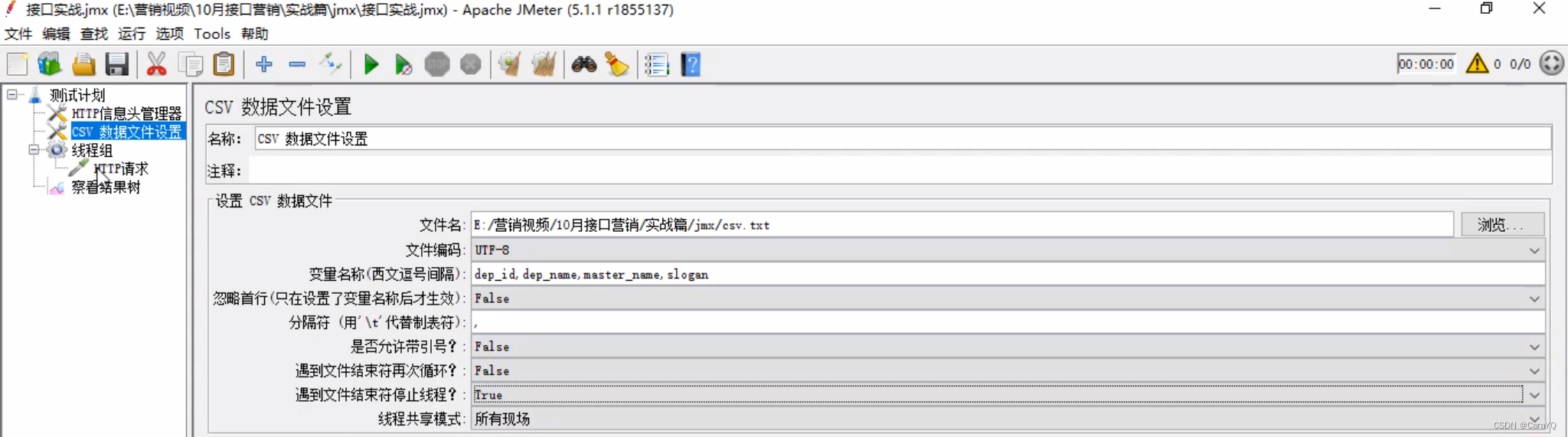
然后把http请求的消息体的属性值改成变量
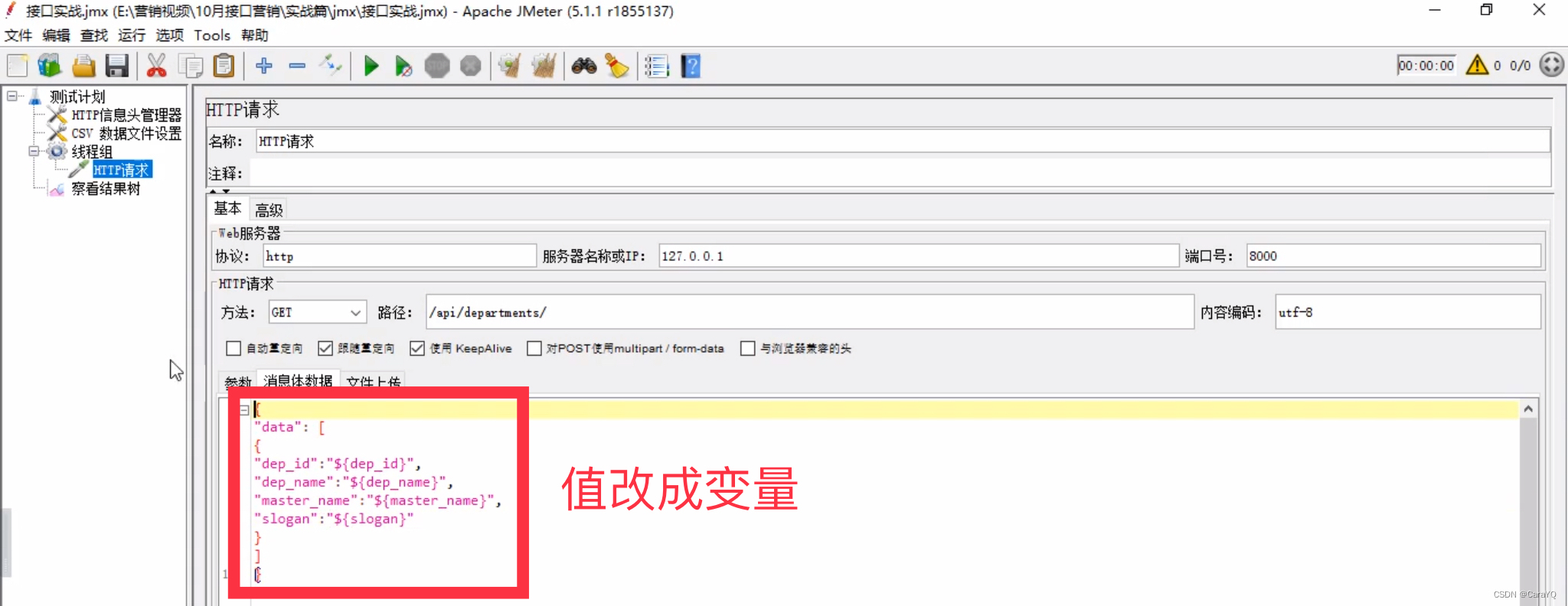
线程组的循环次数选永远
四、启动,将察看结果树的内容和测试用例一条条比对,并不是说察看结果树中是绿的就是正确的,有些你写的反例他就该是红的,所以你需要一条条比对,他到底应该是红的还是绿的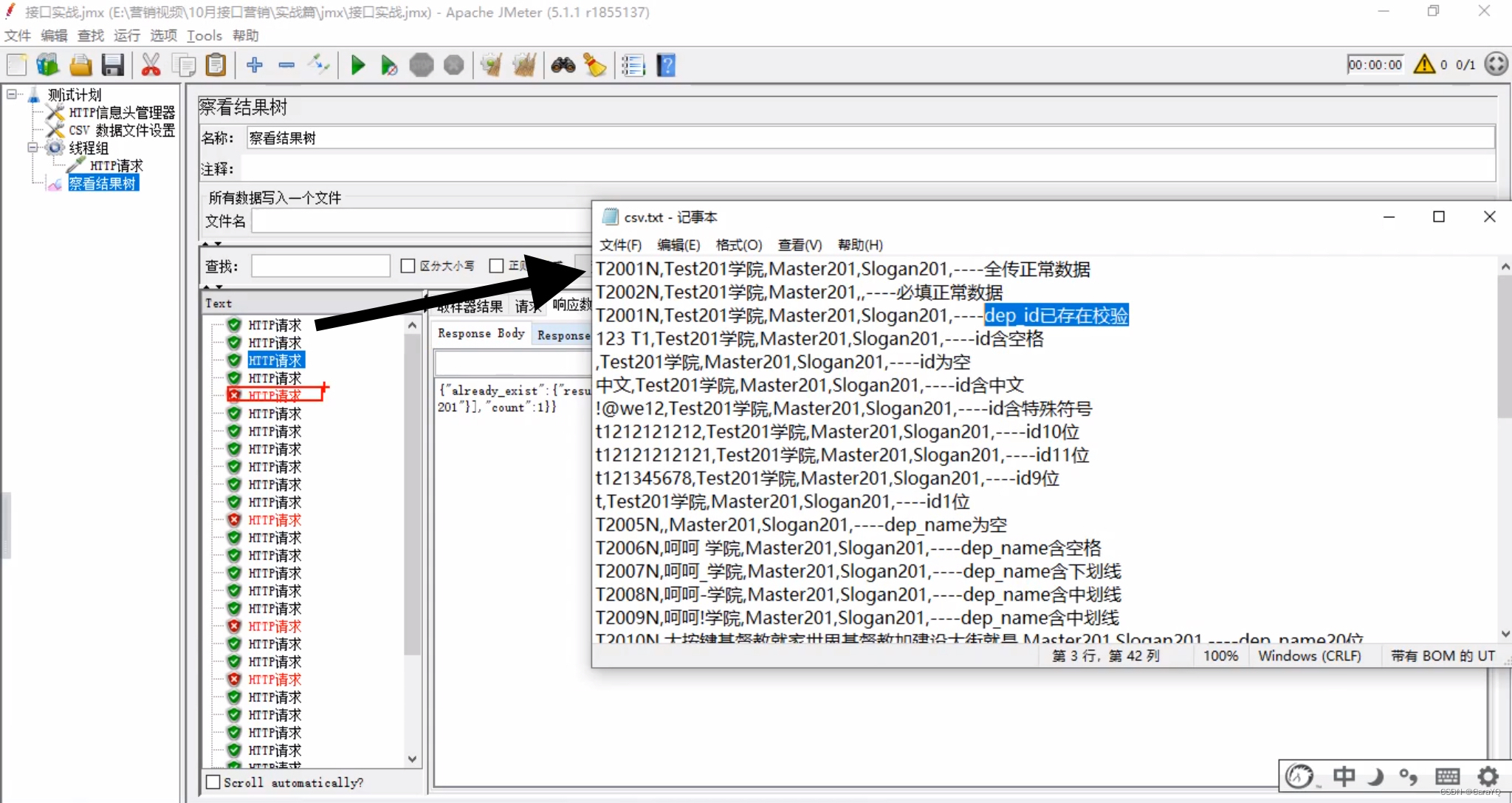
自动化测试
测试最怕开发加了新功能,导致老功能不能正常使用了,为了避免这个问题,我们要给增删改查各自准备一个自动化测试的接口脚本,注意此时程序已经在执行了,测试数据不能对现有的数据进行污染,那么我们可以新增一条,然后对这条进行改、查,最后删除这条
自动化测试基本框架搭建
注意我们目前只是搭建框架,后续才会填写具体内容
一、因为涉及新增,所以先在测试计划上新增一个http请求头管理器

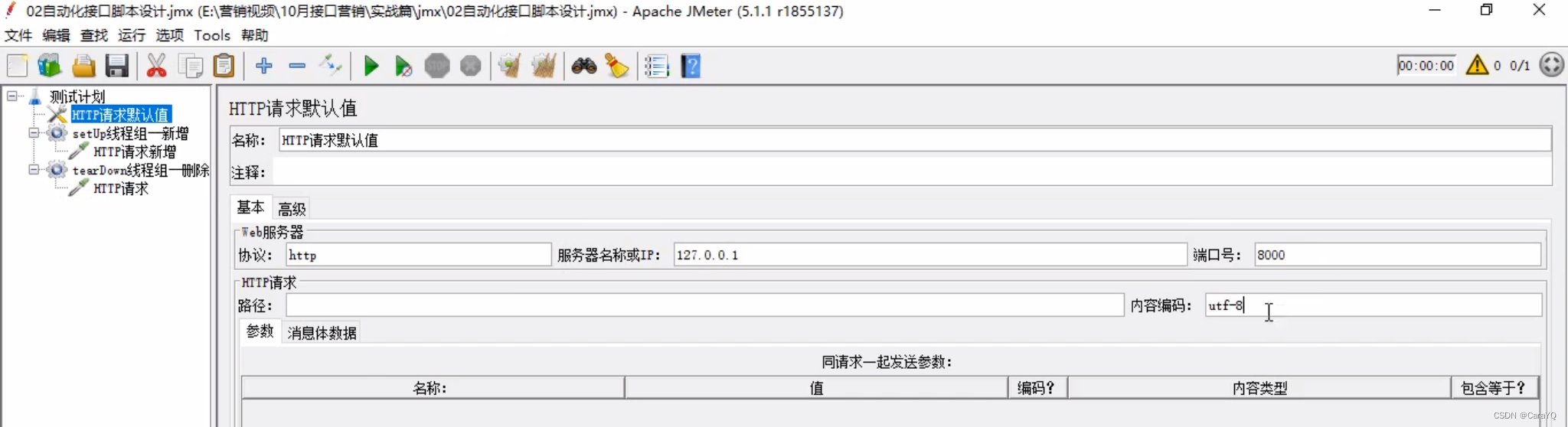
二、在测试计划上添加http请求默认值,将增删改查四个线程的公共内容保存在这里
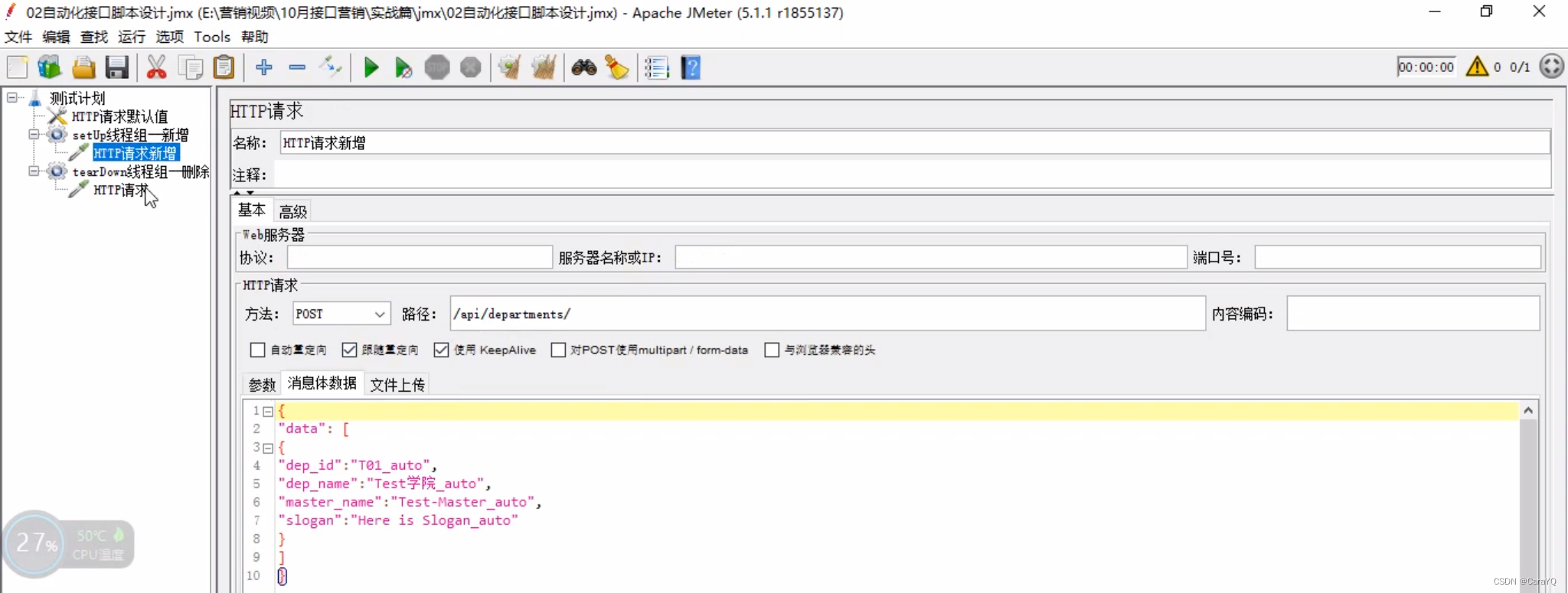
三、在测试计划上添加一个setUp线程组,用于新增,在该线程组上添加http请求
四、在测试计划上新增一个tearDown线程组,用于删除,在该线程组上添加http请求
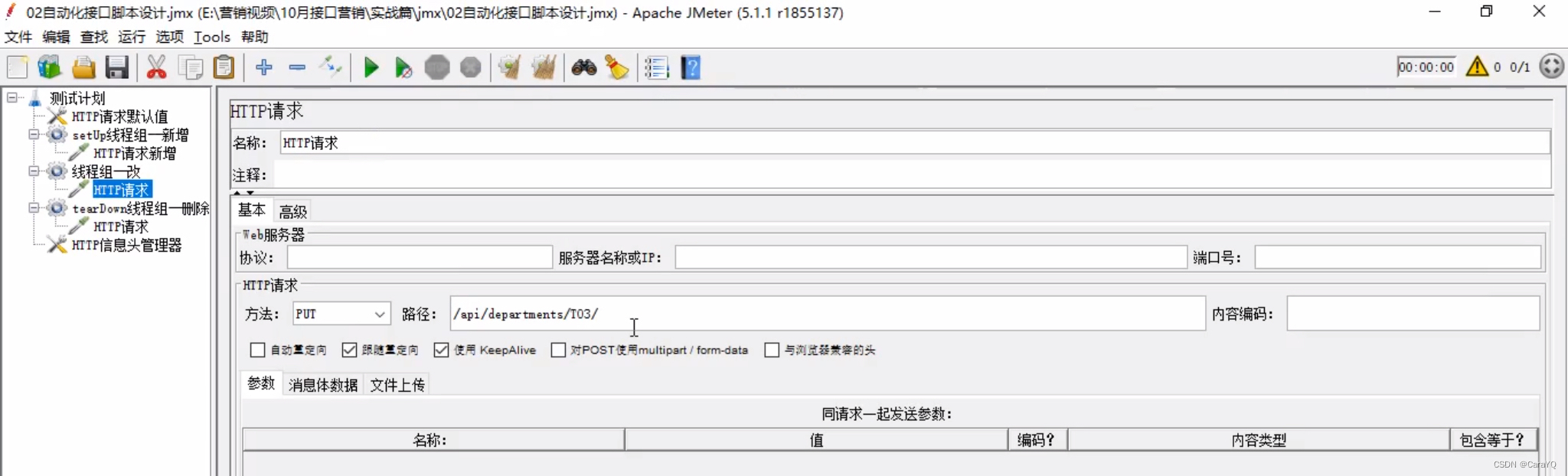
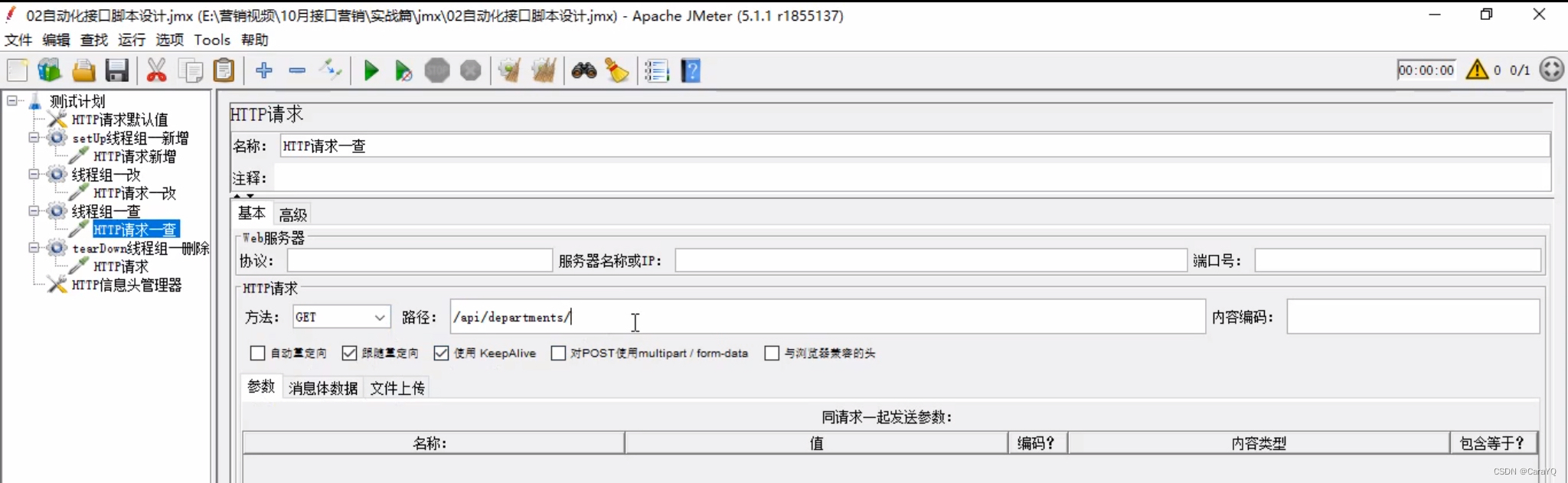
五、在测试计划上添加2个普通的线程组,分别用来改和查,我希望先改后查,所以需要勾选测试计划的【独立运行每个线程组】
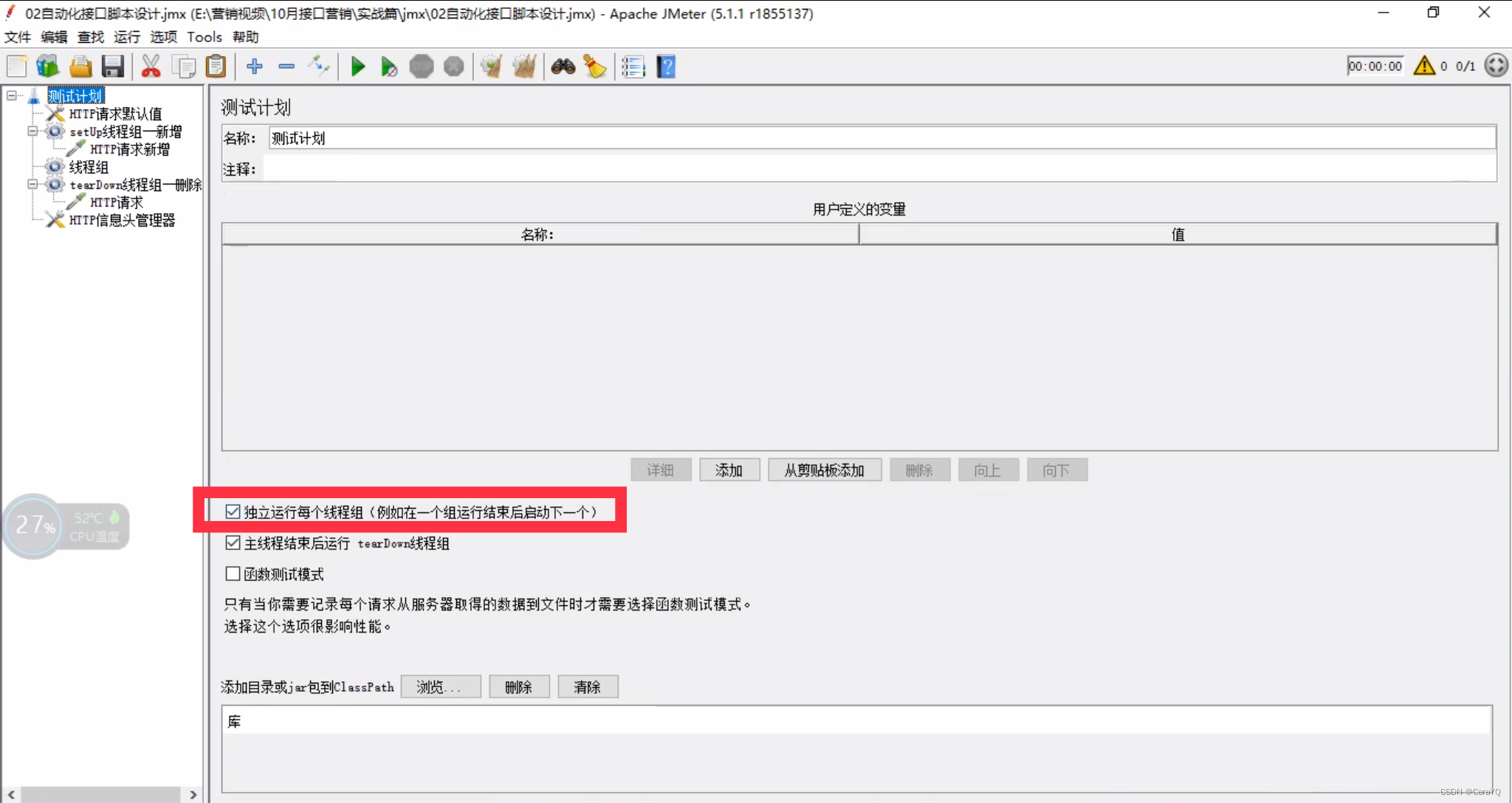
改和查两个线程组内容如下:
六、添加察看结果树
新增和修改
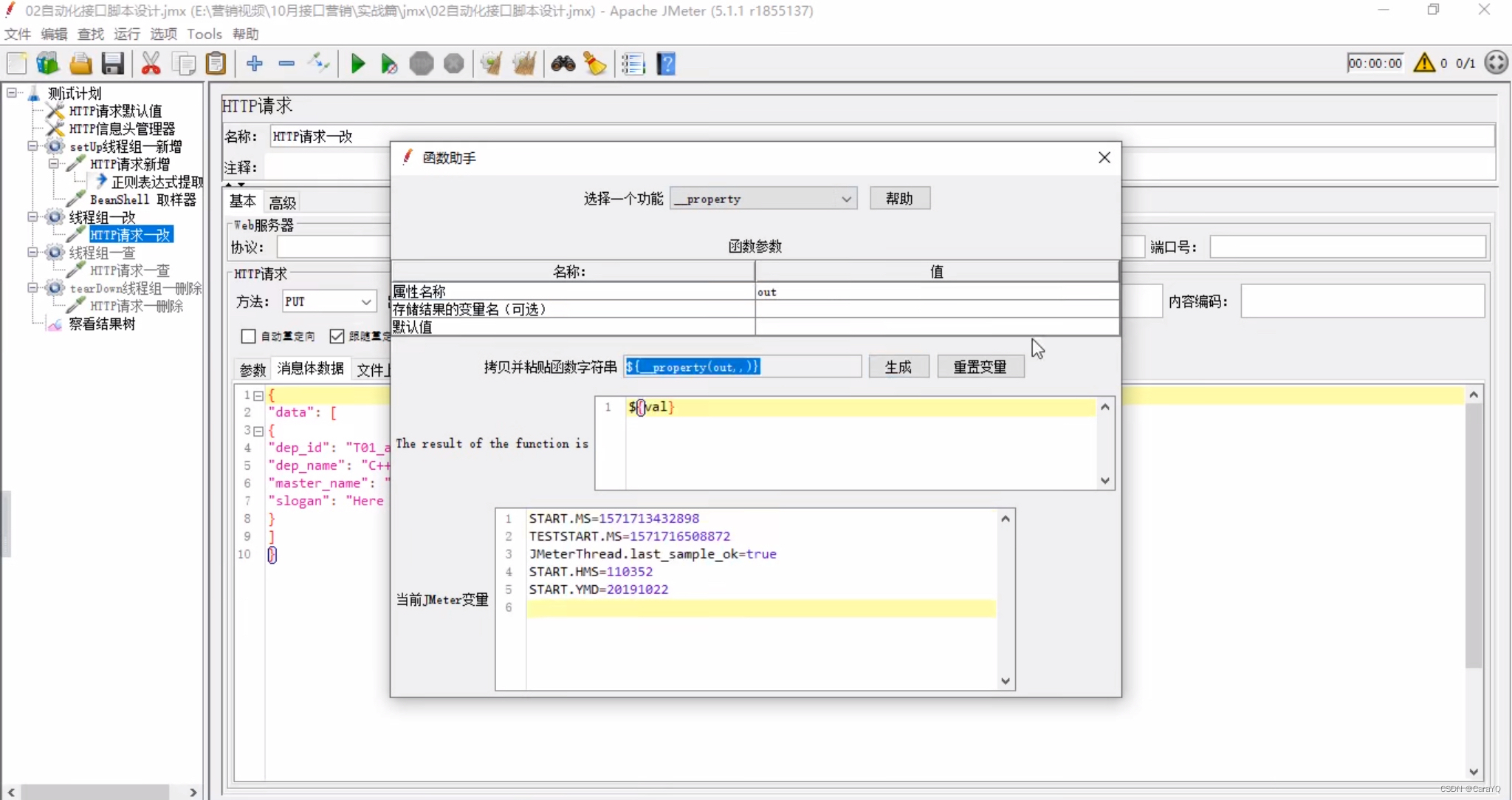
思路:新增一条数据,响应信息会返回你新增的这条数据,你从响应信息中把这条数据的id取出来,放在全局变量中,以后改、查、删都从全局变量中获取id,然后对数据进行操作,这样你以后新增的数据变了也不影响后续的操作
- 为http请求添加一个正则表达式提取器,内容如下:
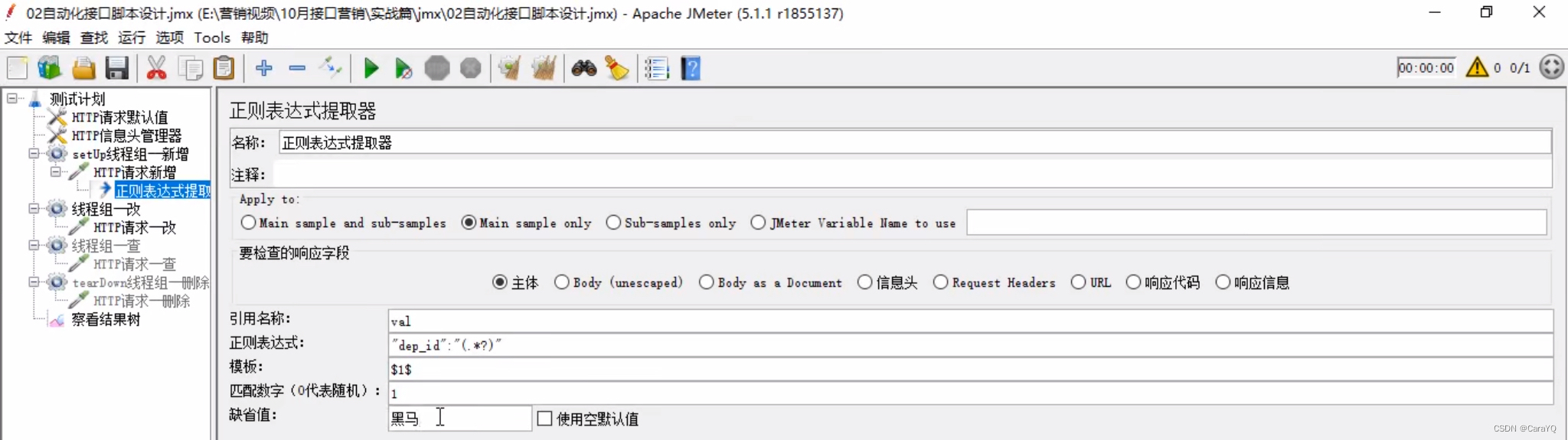
- 数据导出到全局变量中
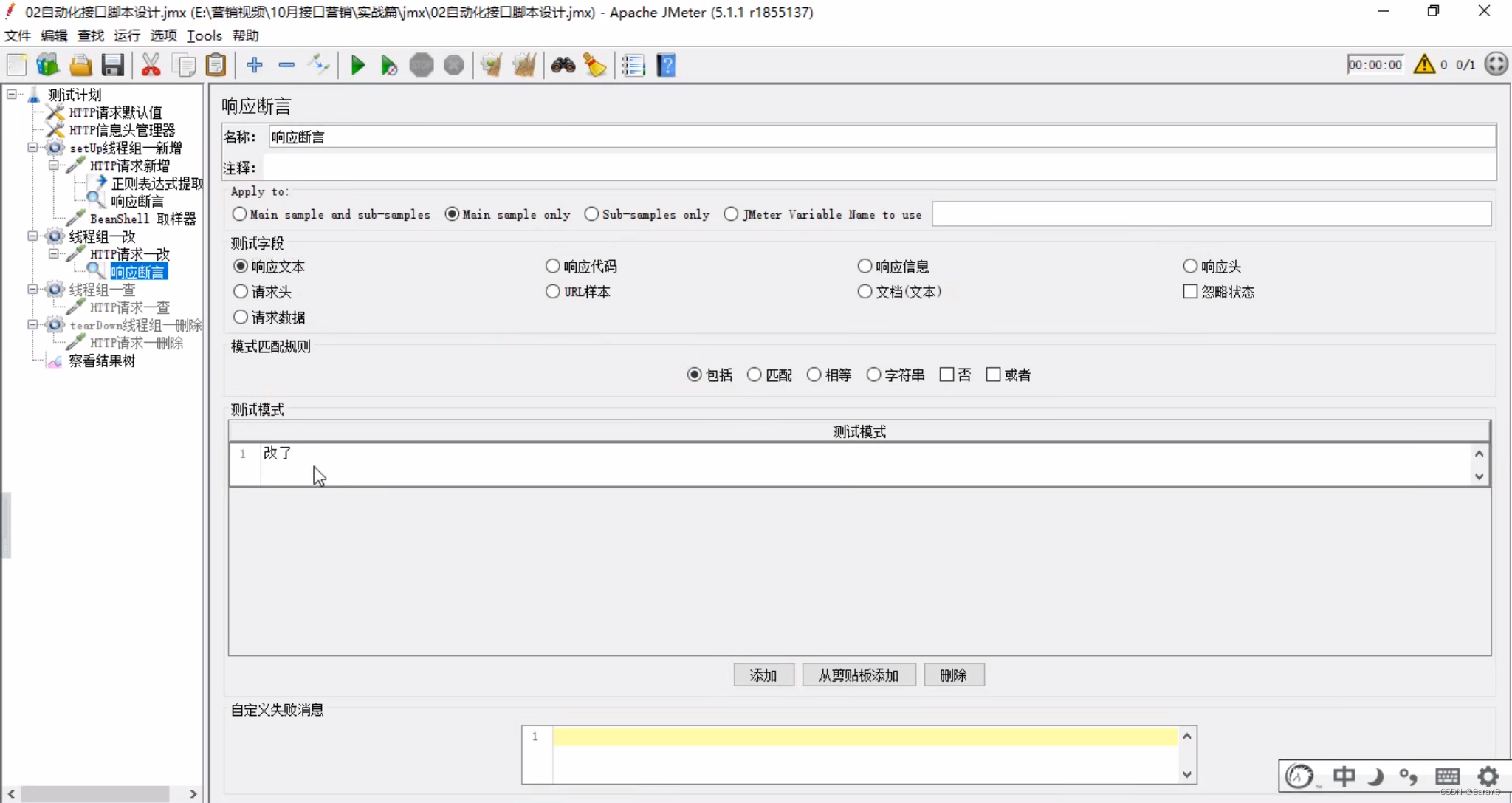
- 为新增线程组设置响应断言,有以下两种方式:
(1)根据响应文本进行断言:设置响应文本包括
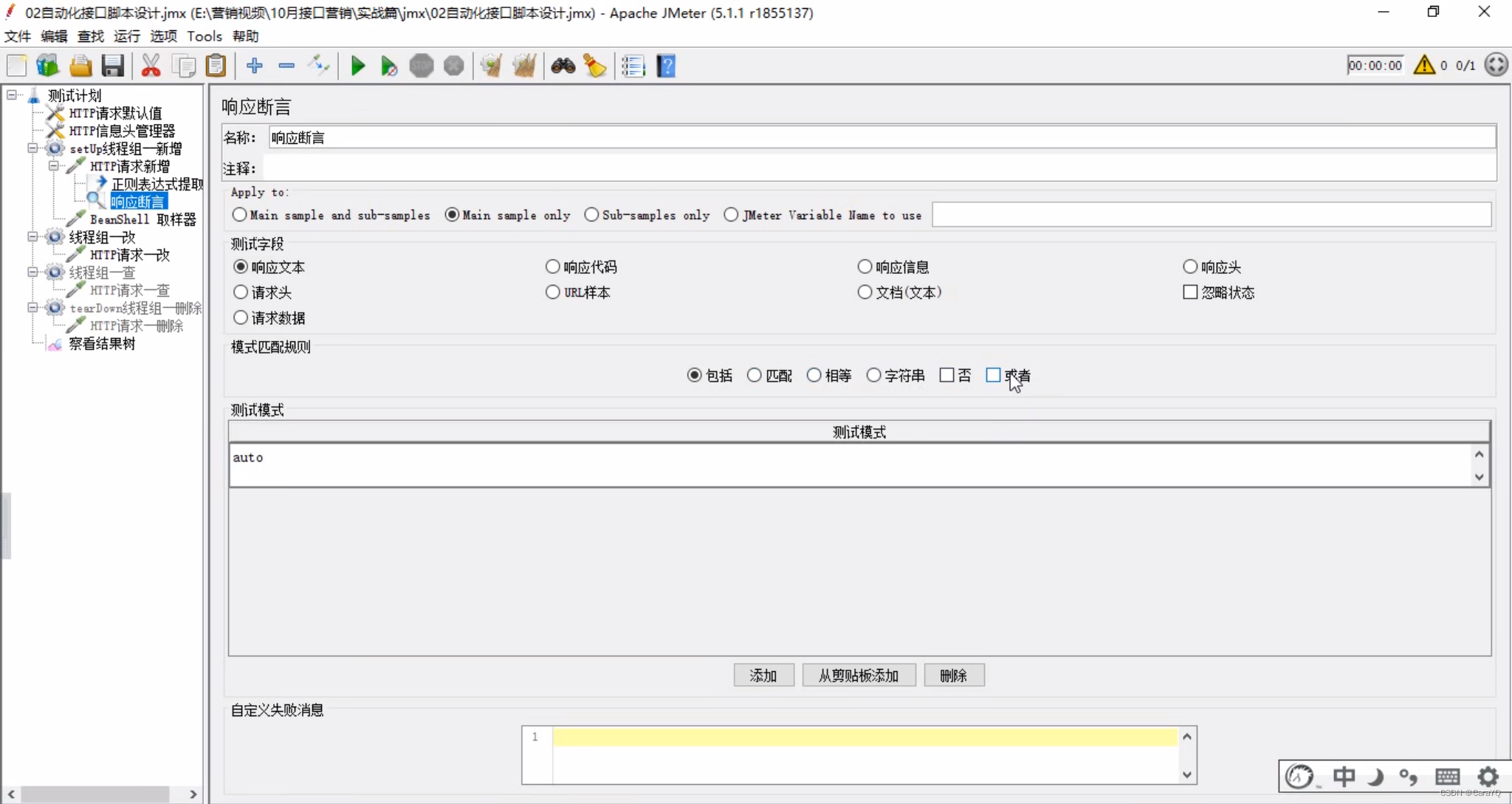
(2)根据响应码进行断言
- 改线程组取出数据并使用
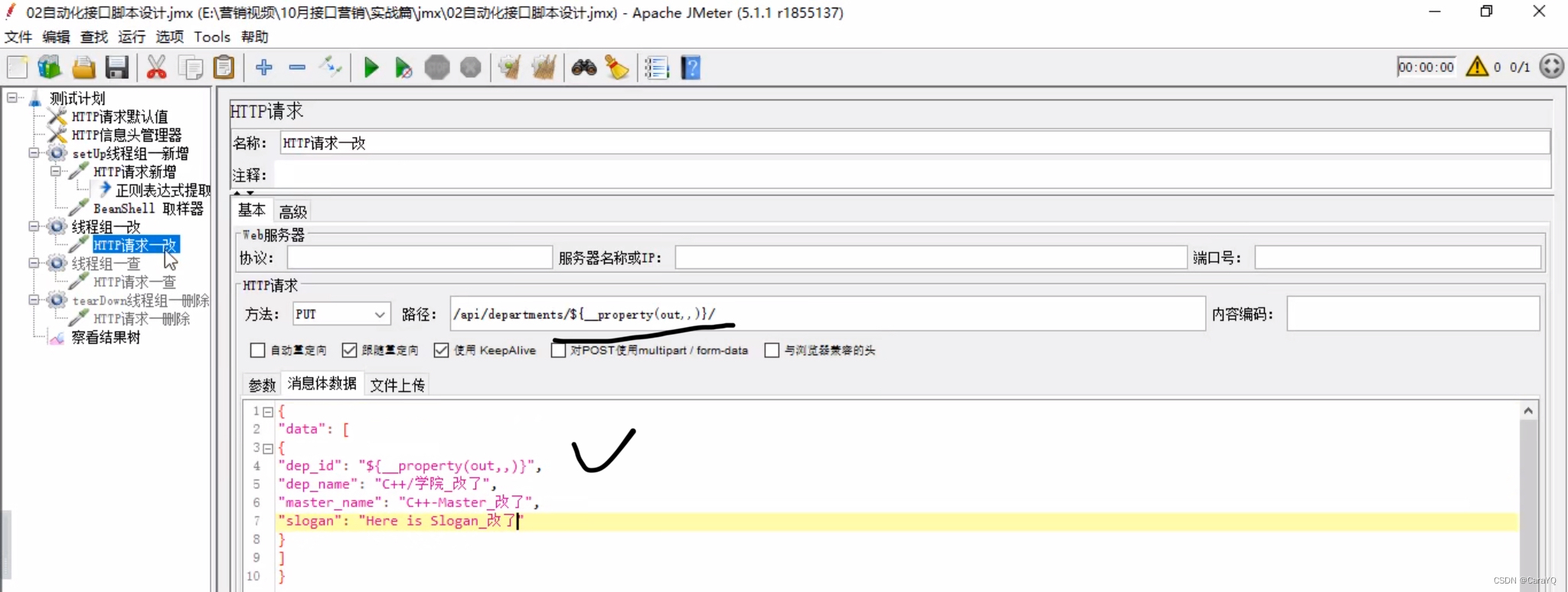
- 为改线程设置响应断言,设置方式依旧有两种,此处不在赘述,此处使用响应文本进行断言
- 察看结果树内容:
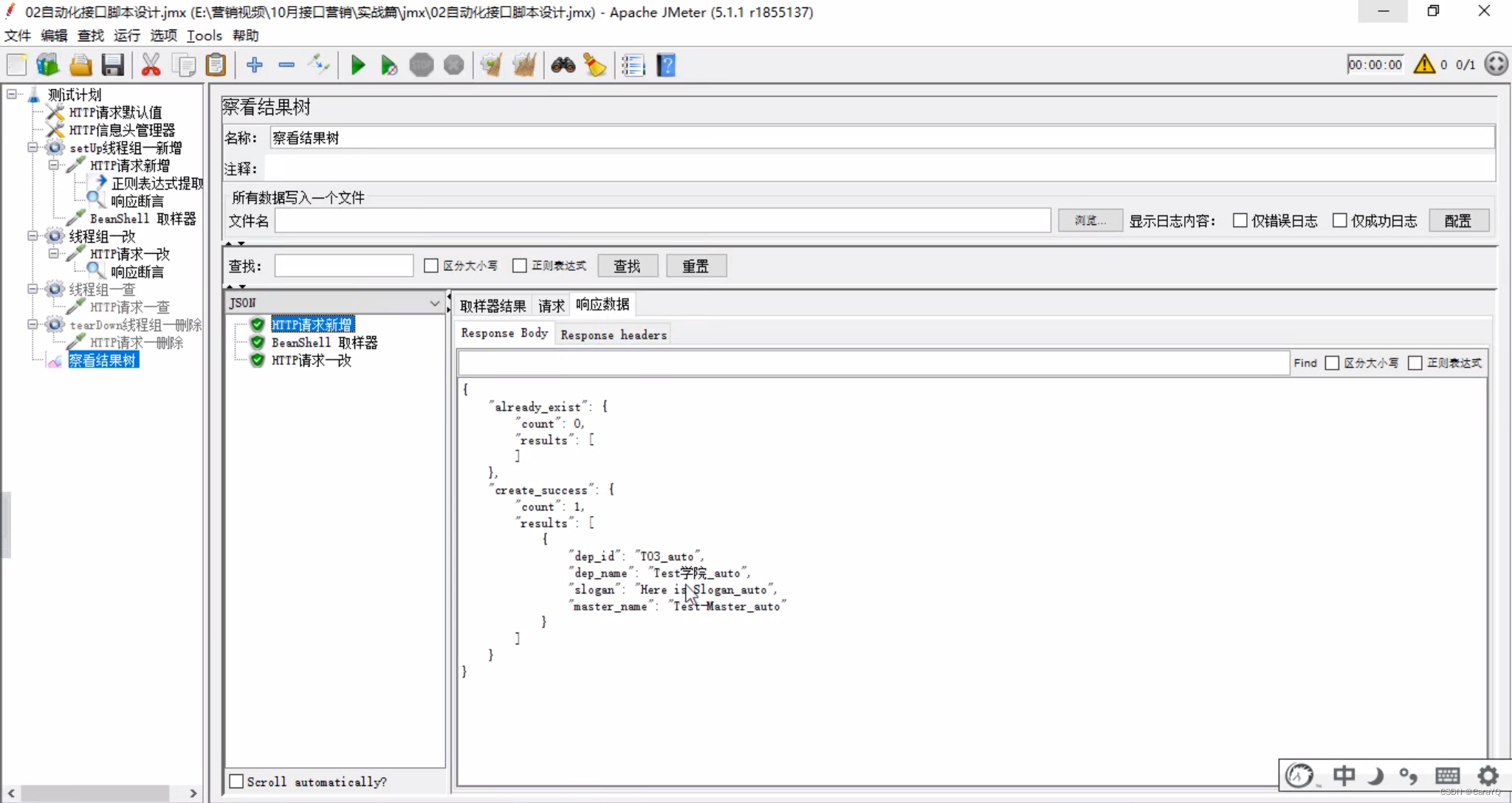
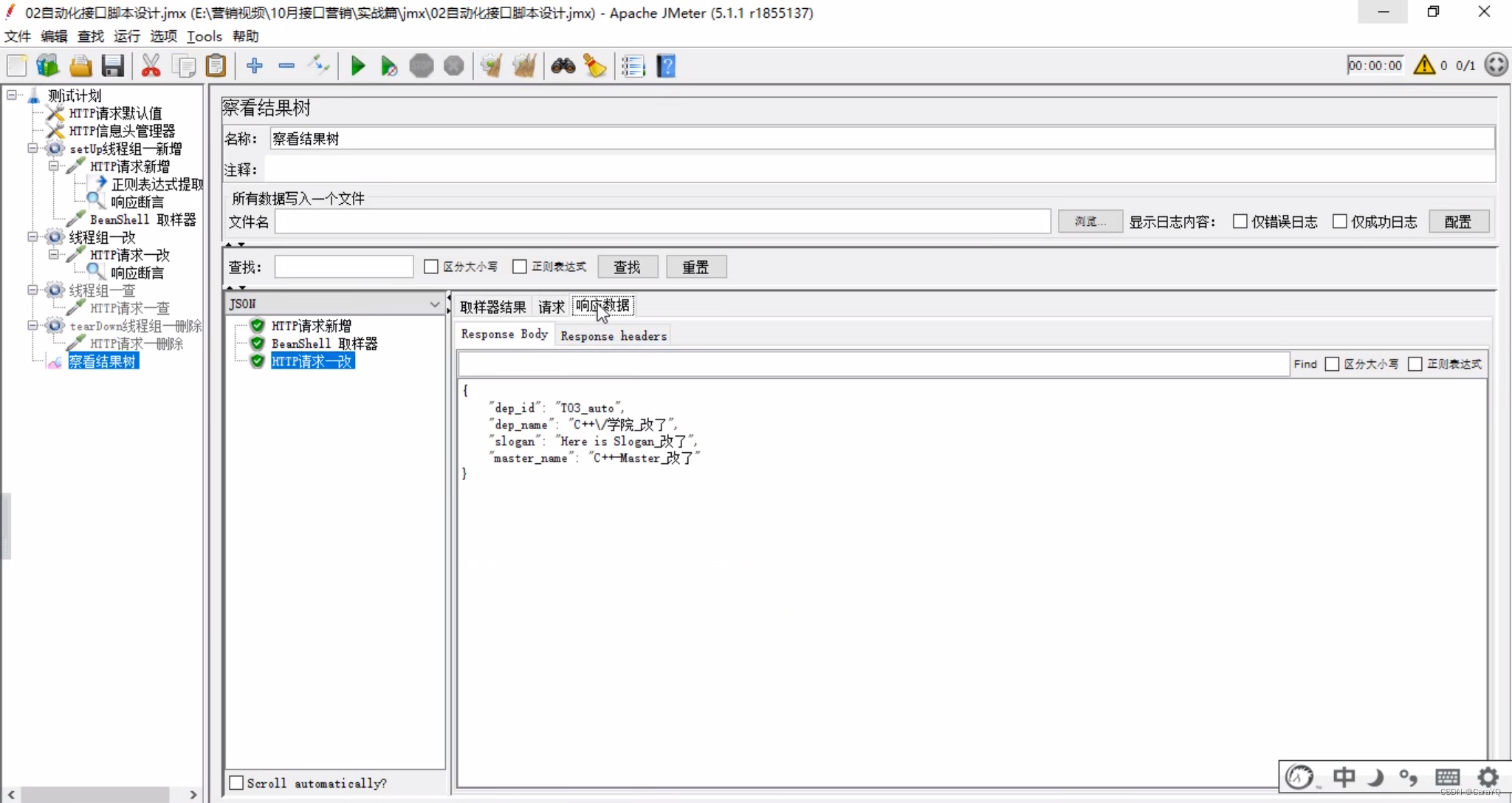
删除和查询
一、删除和查询只用将全局变量的代码复制到要使用数据的地方即可
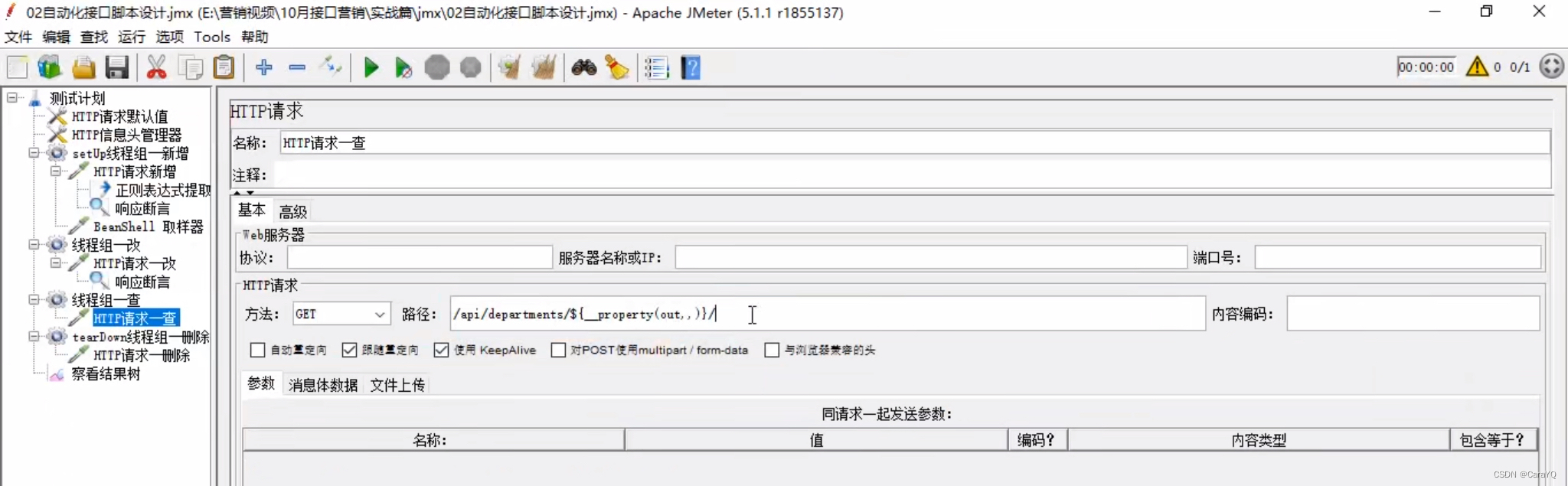
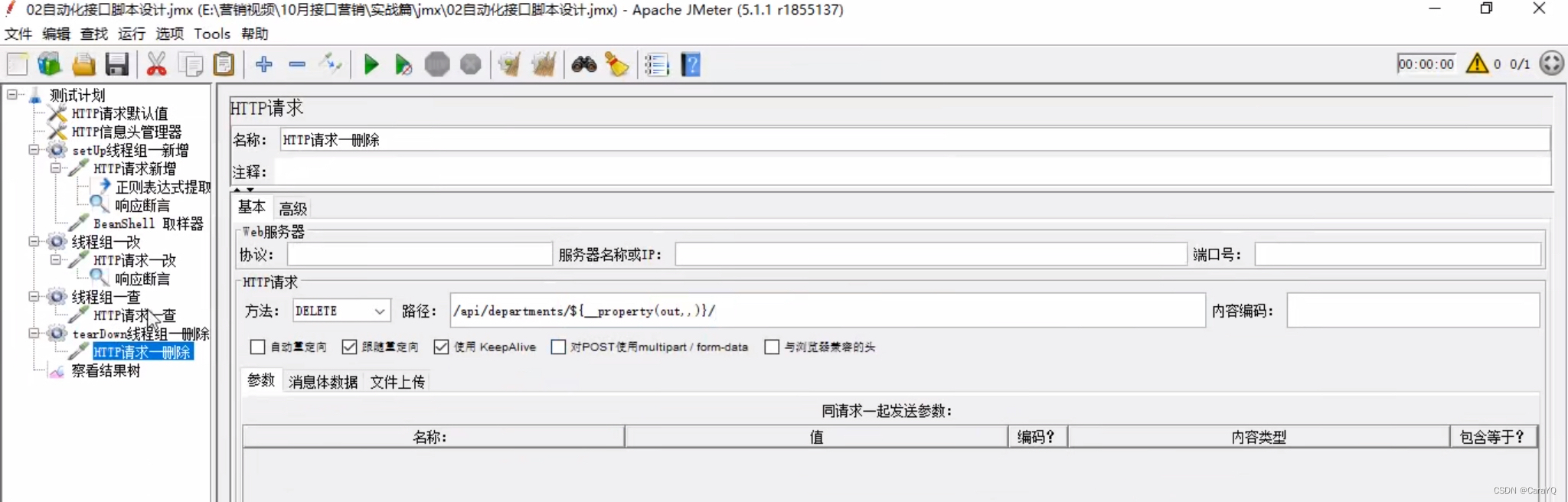
二、为删除和查询添加响应断言
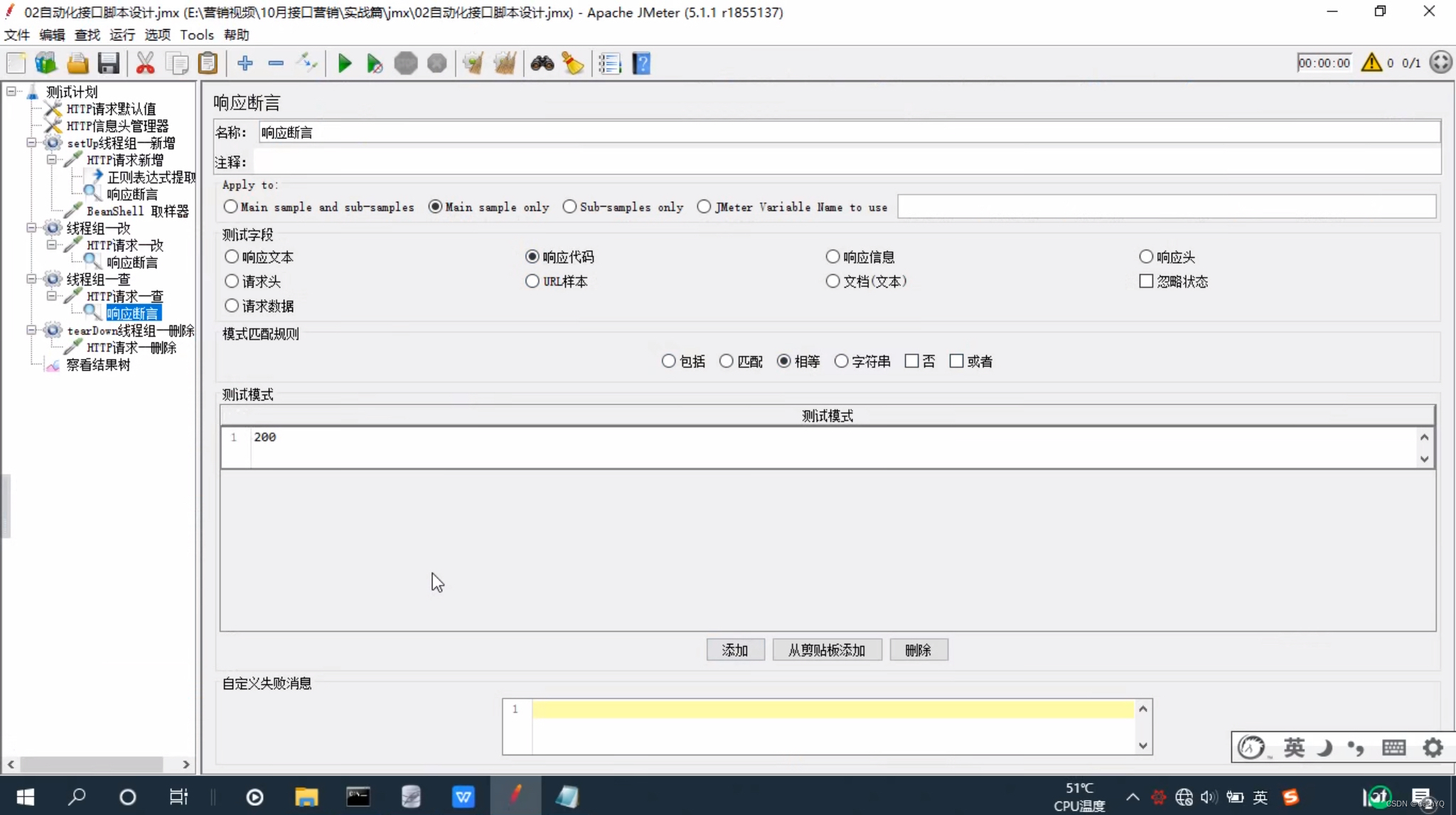
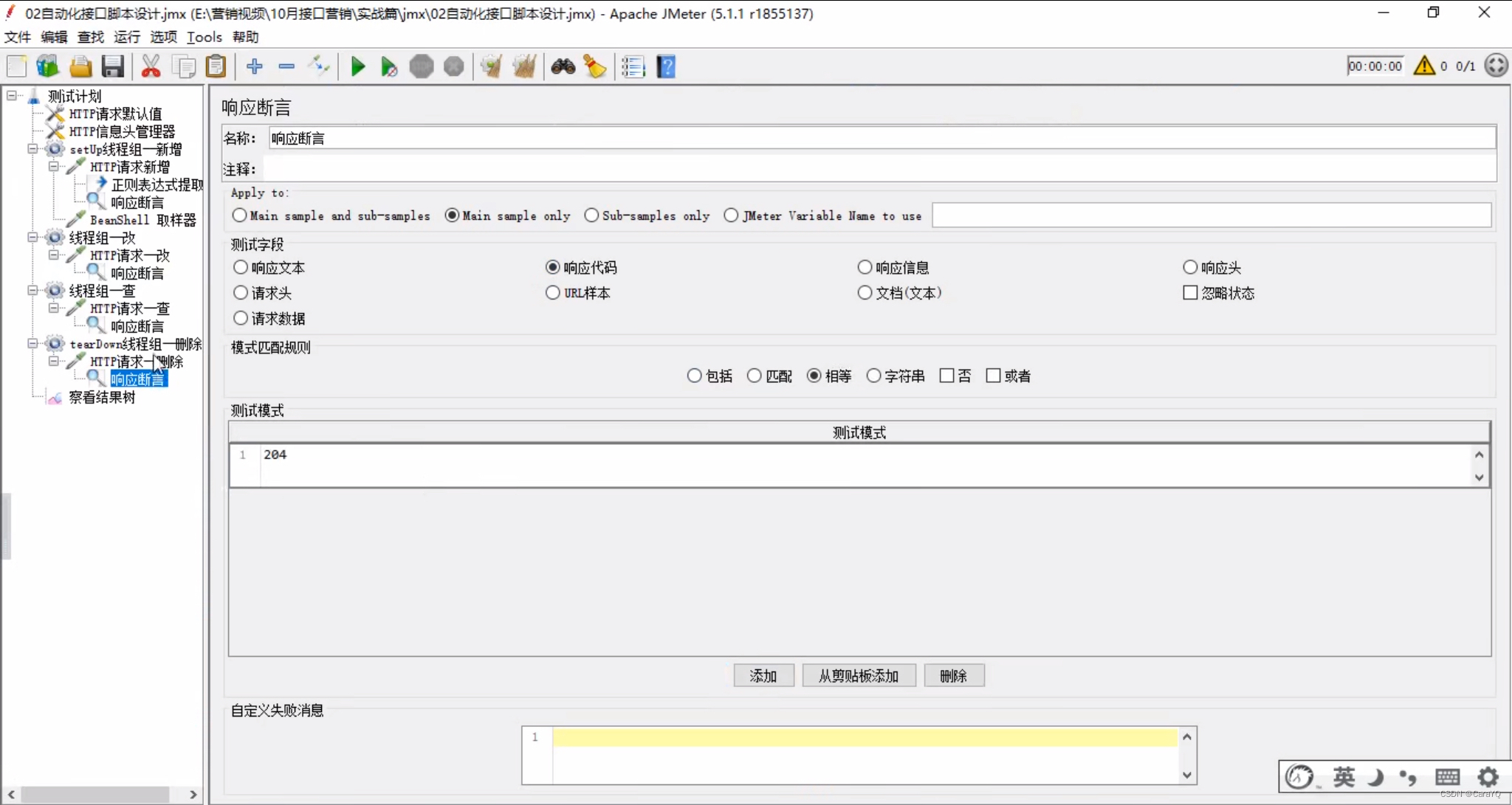
以后,如果开发跟你说我更新了一个功能,你再去测一下,你就可以拿出这个增删改查的自动化脚本,点击启动,查看察看结果树的内容,如果都是绿的,说明新功能没有影响老接口
接口弱压力测试
一、如果是大型项目,如京东、淘宝,还需要进行性能测试,如果是公司官网这种不会有很多人访问的页面,就不需要进行性能测试
二、如果要进行性能测试,从以下三个方面考虑:
- 场景1:模拟半小时之内1000个用户访问服务器资源,要求平均响应时间在3000ms内,且错误率为0 。具体实现如下:
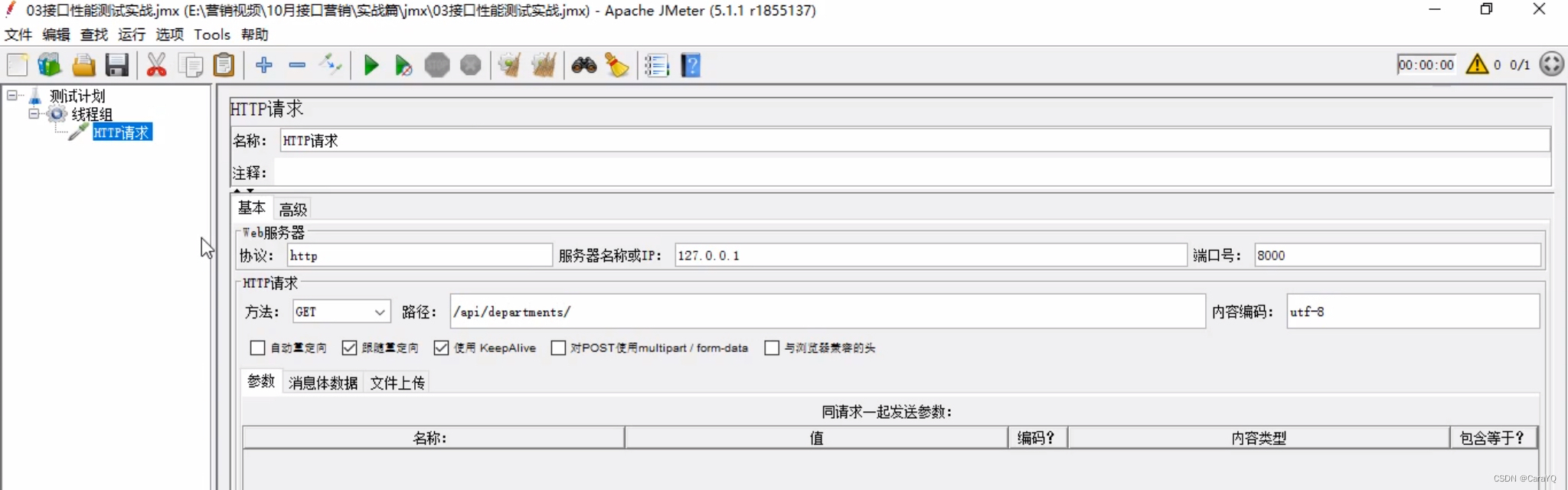
重点在这里:线程组的线程数应该为1000,因为有1000个用户嘛。ramp-up时间是程序的打开时间,应为ramp-up时间(秒)=30min*60s=1800s
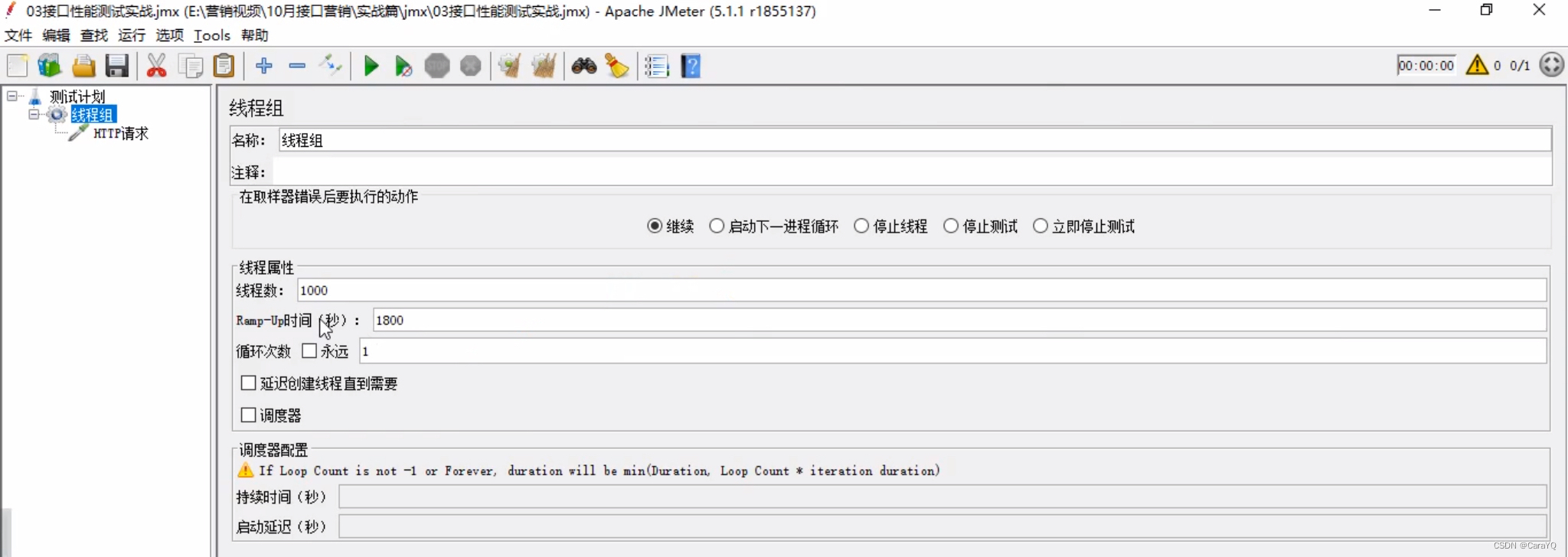
像这种不是在同一时刻1000个用户访问的场景就是弱压力测试,像学校选课,需要10000个学生在15:00-17:00时间段完成选课,就可以用到。
- 场景2:模拟100个用户同时访问服务器资源,要求平均响应时间在3000ms内,且错误率为0。具体实现如下:因为有100个用户所以线程数为100
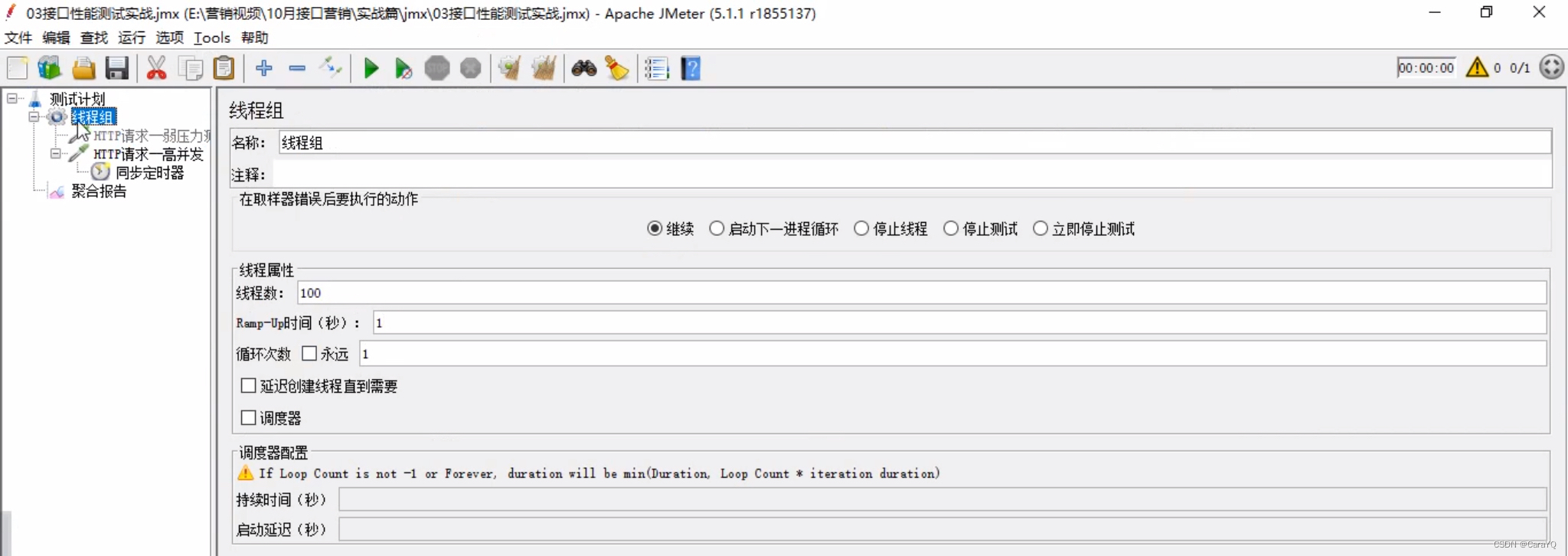

启动之后查看聚合报告
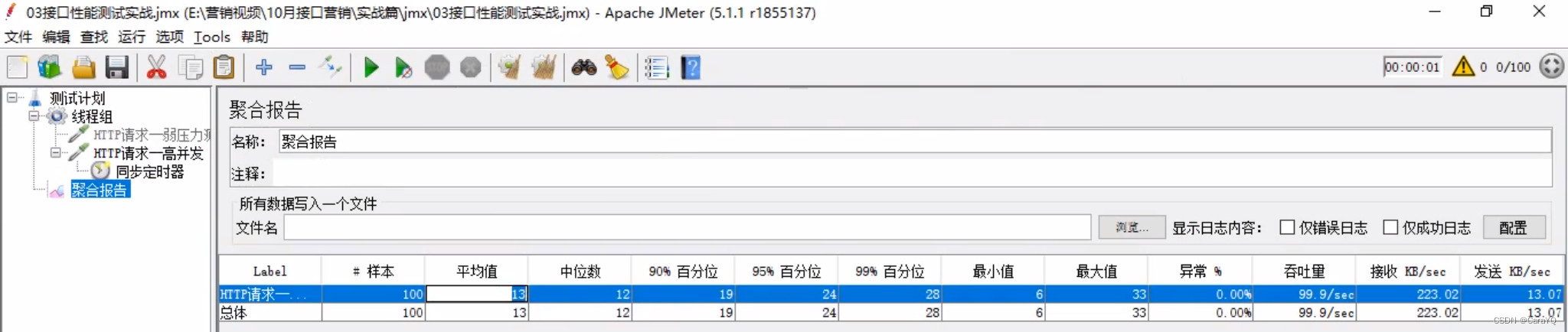
像这种100个用户同时访问就是高并发
- 场景3:模拟2个用户以20QPS的频率访问服务器资源持续10秒,要求平均响应时间在3000ms内,错误率为0。具体实现如下:
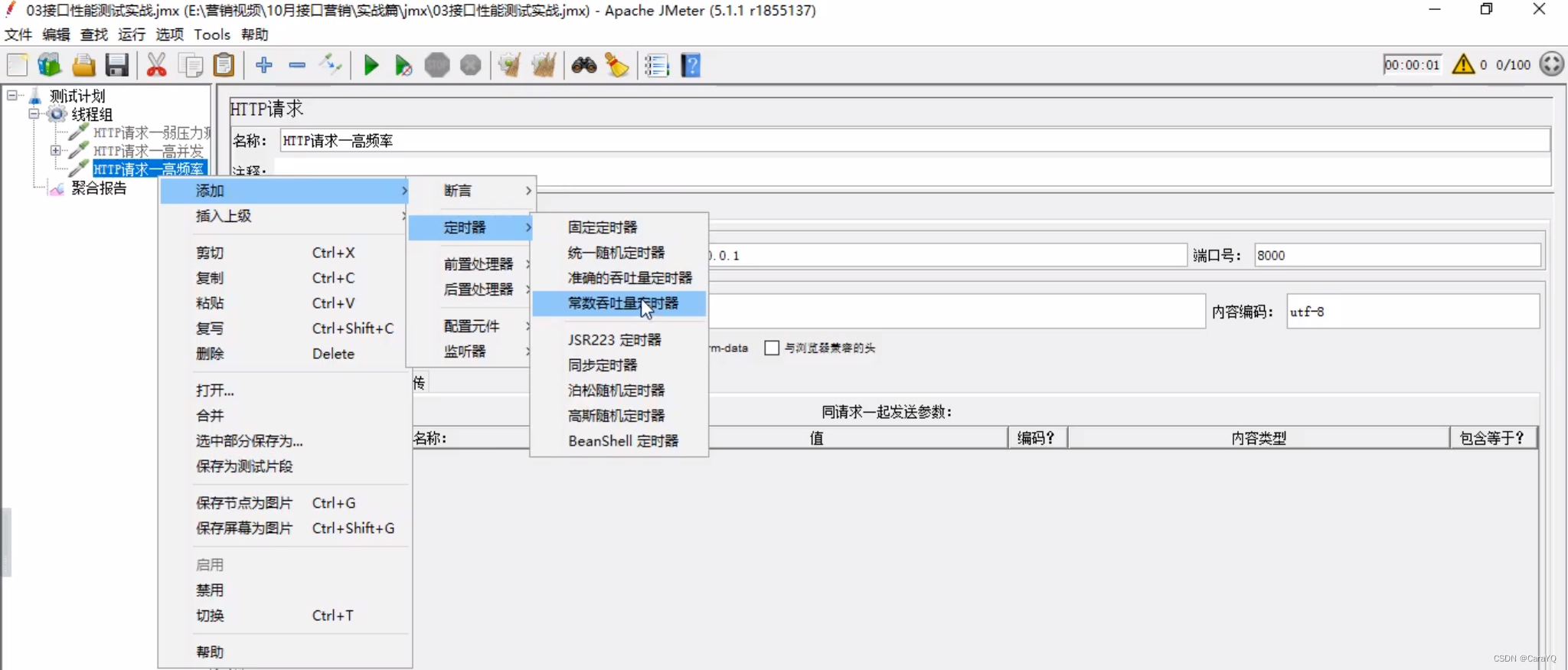
20qps即每秒执行20次,那每分钟就执行20*60=1200次

因为有两个用户所以线程数是2。20qps即每秒执行20次,共执行10s,那么一共执行200次,所以循环次数为200
启动之后查看聚合报告
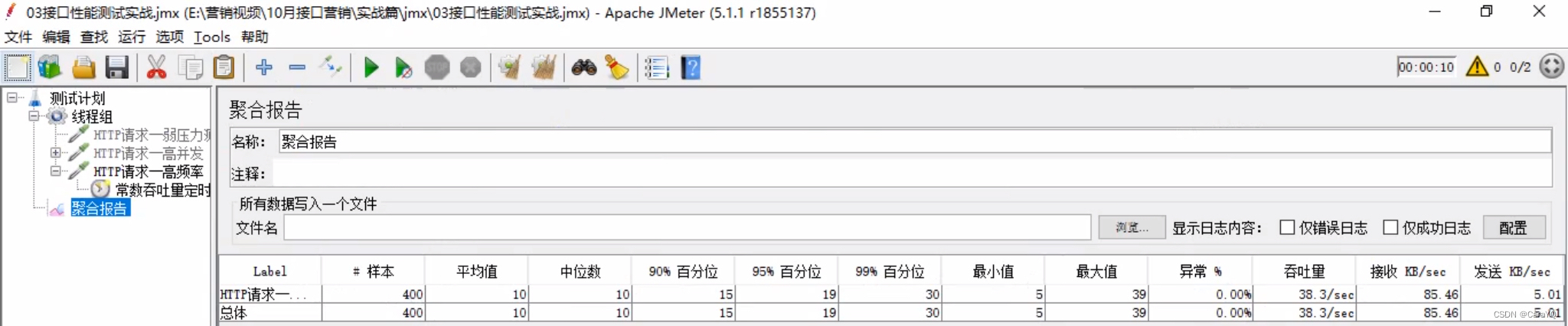
像这种有频率的就是高频率场景,需要使用高频率定时器
生成图形化测试报告
在JMeter中可以以图形化(饼状图、柱状图…)的方式显示脚本运行结果,较之于聚合报告或查看结果树组件实现更直观,用户体验更友好
- 将你想要生成图形化的那个jmx文件复制到jmeter安装文件的bin文件夹下
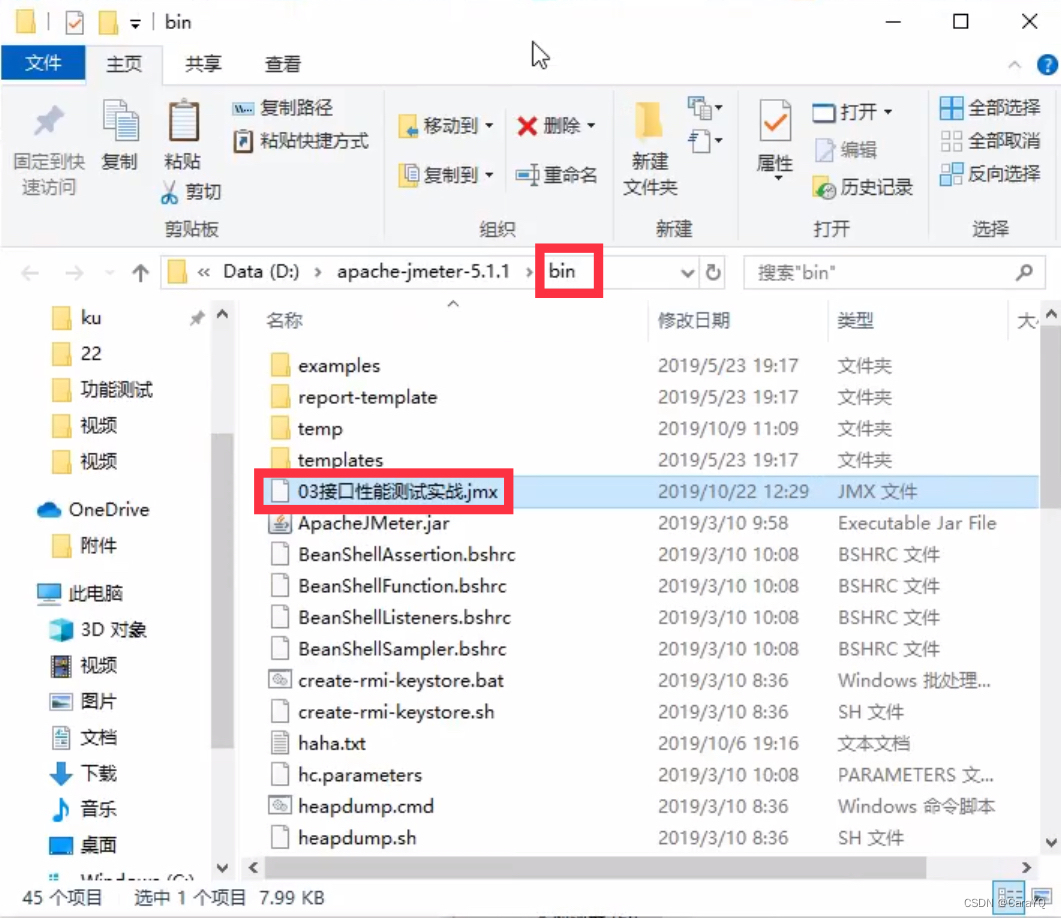
- 在当前bin目录下进入cmd

- 在cmd黑窗口中输入命令:
jmeter -n -t 脚本文件 -l 日志文件 -e -o 输出结果的目录
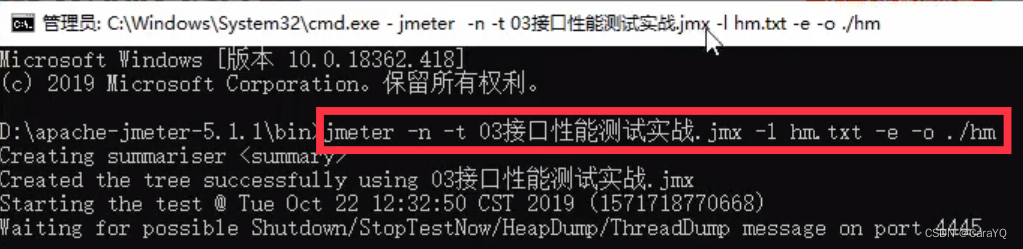
日志文件、输出结果的目录可以不存在,他会自动帮你创建,但是必须保证为空
-n 无图形化运行
-t 被运行的脚本
-l 将运行信息写入日志文件 -e 生成测试报告
-o 指定报告输出目录