问:Spring对Bean的生命周期管理?
答:普通Java对象和Spring所管理的Bean实例化的过程是有些区别的
在普通Java环境下创建对象简要的步骤可以分为:
- java源码被编译为被编译为class文件
- 等到类需要被初始化时(比如说new、反射等)
- class文件被虚拟机通过类加载器加载到JVM
- 初始化对象供我们使用
而是Spring管理的Bean不同,除了Class对象外,还会使用BeanDefinition的实例来描述对象;
可以理解为:Class只描述了类的信息,而BeanDefinition描述了对象的信息

- Spring在启动的时候需要「扫描」在XML/注解/JavaConfig 中需要被Spring管理的Bean信息
- 会将这些信息封装成BeanDefinition,最后会把这些信息放到一个beanDefinitionMap中
- Map的key应该是beanName,value则是BeanDefinition对象
可以说上述就是扫描加收集半成品,并没有实例化对象 - 接着会遍历这个beanDefinitionMap,执行BeanFactoryPostProcessor这个Bean工厂后置处理器的逻辑
BeanFactoryPostProcessor:读取bean 配置元数据,并可进行修改。例如增加bean的属性和值,重新设置bean是否作为自动装配的侯选者,重设bean的依赖项 - 在Spring里边是通过反射来实现的,一般情况下会通过反射选择合适的构造器来把对象实例化
- 这里把对象实例化 ,只是把对象给创建出来,而对象具体的属性是还没注入的。
- 相关属性注入完之后,往下接着就是初始化的工作了
- 首先判断该Bean是否实现了Aware相关的接口,如果存在则填充相关的资源
- 初始化完成,即可使用相应的对象了;
- 销毁的时候就看有没有配置相关的destroy方法,执行就完事了

问:Spring是怎么解决循环依赖的吗?
答:
- 首先A对象实例化,然后对属性进行注入,发现依赖B对象
- B对象此时还没创建出来,所以转头去实例化B对象
- B对象实例化之后,发现需要依赖A对象,那A对象已经实例化了嘛,所以B对象最终能完成创建
- B对象返回到A对象的属性注入的方法上,A对象最终完成创建
原理:
三级缓存其实就是三个Map
- singletonObjects(一级,日常实际获取Bean的地方);
- earlySingletonObjects(二级,还没进行属性注入,由三级缓存放进来);
- singletonFactories(三级,Value是一个对象工厂);
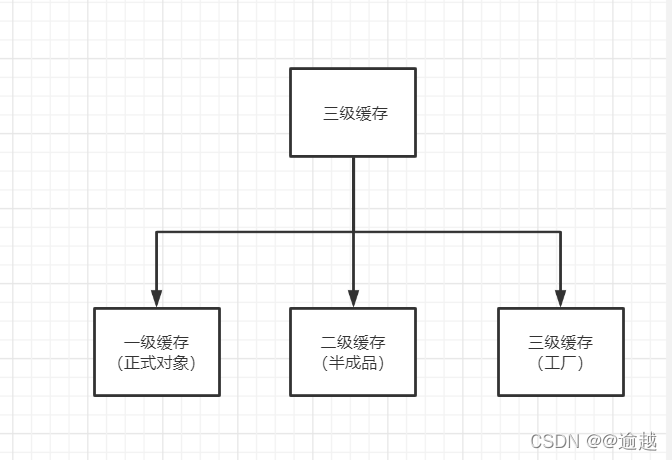
- A对象实例化之后,属性注入之前,其实会把A对象放入三级缓存中
- key是BeanName,Value是ObjectFactory
- 等到A对象属性注入时,发现依赖B,又去实例化B时
- B属性注入需要去获取A对象,这里就是从三级缓存里拿出ObjectFactory,从ObjectFactory得到对应的Bean(就是对象A)
- 把三级缓存的A记录给干掉,然后放到二级缓存中
- 二级缓存存储的key是BeanName,value就是Bean(这里的Bean还没做完属性注入相关的工作)
- 等到完全初始化之后,就会把二级缓存给remove掉,塞到一级缓存中
- 我们自己去getBean的时候,实际上拿到的是一级缓存的
第三级缓存考虑的是代理
第二级缓存考虑的是性能
参考博客:https://www.zhihu.com/question/438247718/answer/1730527725