网站服务器(HTTPD)已经有很多版本,但是大部分对初学者都非常不友好。适合初学者学习的httpd服务器,最负盛名的当数tinyhttpd, 但是这个版本,是基于Linux系统的,而且配套的CGI也是使用perl语言写的,直接劝退了大部分想学后端开发的初学者。基于此,特意写了这个小项目,让只有C语言基础的初学者,就可以直接手写后端服务器,快速提升C语言和网络开发技能。
这个项目是基于tinyhttpd改写的,解决了以下问题:
1. 解决了tinyhttpd服务器只支持html纯文本的问题,添加了支持图片文件和JS脚本的问题,可以直接支持各种复杂的网页。
2. 使用C语言实现了CGI功能。tinyhttpd服务器的CGI是perl脚本实现的,对于C/C++初学者不友好,用C语言实现CGI功能,可以更加深刻的理解动态网站的实现原理和实现方法。
3. 解决和tineyhttpd服务器中文显示的问题,完美支持GET和POST的中文字符。
4. 本项目直接使用Window系统实现,C/C++初学者可以零障碍掌握学习。tinyhttpd服务器是基于Linux系统的,而大部分初学者对Linux系统并不熟悉。
5. 本项目在最后使用内网穿透,把自己的网站零成本的分享给自己的同学朋友。
项目效果点这里看本教程配套视频
项目准备
- Windows系统
- vs2019或者任意其它版本的vs
- 创建项目
创建项目
使用任意版本的VS或者VC++,创建一个空项目。
创建服务器端的套接字
基于网络的通信,需要先创建“套接字”。“套接字”这个专业术语,非常古怪,被很多人吐槽。我们不要深究它为什么叫这个名字,我们只需要了解“套接字”的作用即可。
套接字,就相当于一个“网络插座”,通过网络进行通信,就是通过这个“插座”收发信息的,相当于一个电话机的电话线插槽。

在创建服务器时,还必须要指定一个端口号。当一台服务器,同时对外提供多种服务时,比如WEB服务,远程登录服务等等,就需要使用“端口号”,对不同的服务进行区别。每个服务,都有自己唯一的端口号。
 但是,服务器端在网站访问服务之前,需要创建“套接字”。
但是,服务器端在网站访问服务之前,需要创建“套接字”。
#include <stdio.h>
// 初始化网络并创建服务端的套接字
int startup(unsigned short* port)
{
return 0;
}
int main(void)
{
//httpd默认的端口是80,这里指定了8000端口,也可以使用其它端口
unsigned short port = 8000;
// 初始化网络,并使用指定端口来创建服务端的套接字
int server_sock = startup(&port);
printf("httpd running on port %d\n", port);
return(0);
}以上代码,只是写了函数接口,还没有真正创建套接字。马上做详细的实现。
执行WEB服务前的准备工作
在接受浏览器前端的网页请求之前,服务器端需要做一些准备工作,流程如下:(详细详解可以参考本教程配套的分享视频)

代码实现如下:
#include <stdio.h>
#include <winsock2.h>
#pragma comment (lib, "WS2_32.lib")
void error_die(const char* sc)
{
perror(sc);
exit(1);
}
// 初始化网络并创建服务端的套接字
int startup(unsigned short* port)
{
// 网络协议初始化
WSADATA wsaData; // 网络通信相关的版本等信息
// 在windows系统使用网络通信,必须先进行网络协议初始化(Linux系统不需要)
int ret = WSAStartup( // WSAStartup 网络通信初始化,
MAKEWORD(1, 1), // 指定使用Windows Sockets规范的1.1版本
&wsaData); // 存储初始化后的版本等信息
if (ret != 0) {
return false;
}
int server_socket = socket(PF_INET, SOCK_STREAM, IPPROTO_TCP);
if (server_socket == -1) {
error_die("socket");
}
struct sockaddr_in server_addr;
memset(&server_addr, 0, sizeof(server_addr));
server_addr.sin_family = AF_INET;
server_addr.sin_port = htons(*port);
server_addr.sin_addr.s_addr = htonl(INADDR_ANY);
// 端口复用
int opt = 1;
ret = setsockopt(server_socket, SOL_SOCKET, SO_REUSEADDR, (const char*)&opt, sizeof(opt));
if (ret == -1) {
error_die("setsockopt");
}
if (bind(server_socket, (struct sockaddr*)&server_addr, sizeof(server_addr)) < 0) {
error_die("[bind]");
}
// 动态分配端口
if (*port == 0) {
int namelen = sizeof(server_addr);
if (getsockname(server_socket, (struct sockaddr*)&server_addr, &namelen) == -1) {
error_die("getsockname");
}
*port = ntohs(server_addr.sin_port);
}
if (listen(server_socket, 5) < 0) {
error_die("listen");
}
return(server_socket);
}接收浏览器的WEB请求
我们的httpd web服务器准备好以后,就可以接受来自前端浏览器的网页访问请求了。
我们先来看一下浏览器访问网站的完整流程:

处理浏览器请求的框架
因为可能有多个用户同时发起请求,为了更快的处理网页请求,这里使用多线程技术。流程如下:
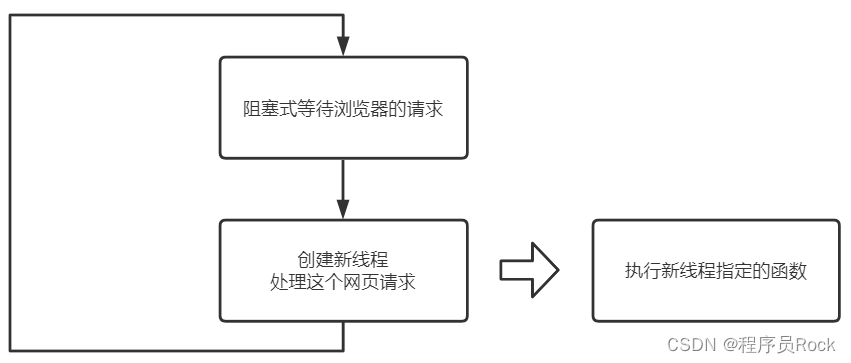
服务端收到浏览器的请求后,accept函数会返回一个“客户端套接字”,这个套接字对应于这个浏览器客户端。以后服务器就通过这个“客户端套接字”和对应的浏览器通信。此时,服务器端有两种套接字:
- 服务器端套接字:用来等待新的浏览器客户端的发起请求,收到请求后,返回一个客户端套接字。
- 客户端套接字:用来和对应的浏览器客户端通信。每个浏览器客户端连接到服务器后,都有一个对应的客户端套接字。
具体代码实现如下:
DWORD WINAPI accept_request(LPVOID arg) {
return 0;
}
int main(void)
{
//httpd默认的端口是80,这里指定了8000端口,也可以使用其它端口
unsigned short port = 8000;
// 初始化网络,并使用指定端口来创建服务端的套接字
int server_sock = startup(&port);
printf("httpd running on port %d\n", port);
while (1)
{
struct sockaddr_in client_addr;
int client_addr_len = sizeof(client_addr);
int client_sock = accept(server_sock, (struct sockaddr*)&client_addr, &client_addr_len);
if (client_sock == -1) {
error_die("accept"); //打印错误信息并结束
}
DWORD dwThreadID = 0;
HANDLE handleFirst = CreateThread(NULL, 0, accept_request, (void*)client_sock, 0, &dwThreadID);
}
return(0);
}处理浏览器的请求
在新线程中,单独处理对应浏览器客户端的请求。
GET请求报文的格式
浏览器发起新的访问时,将向服务器端发送一个请求报文。例如,在浏览器地址输入 127.0.0.1:8000 回车后,服务器端收到的完整报文如下:
GET / HTTP/1.1\n
Host: 127.0.0.1:8000\n
Connection: keep-alive\n
Cache-Control: max-age=0\n
Upgrade-Insecure-Requests: 1\n
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36\n
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9\n
Sec-Fetch-Site: none\n
Sec-Fetch-Mode: navigate\n
Sec-Fetch-User: ?1\n
Sec-Fetch-Dest: document\n
Accept-Encoding: gzip, deflate, br\n
Accept-Language: zh-CN,zh;q=0.9\n
\n请求报文由4四个部分组成:请求行、请求头部行、空行、请求数据。具体格式如下:
| 组成部分 | 说明 |
|---|---|
| 请求行 | 方法名+空格+URL+空格+版本+回车换行(\r\n) |
| 请求头部行1 | 关键字+":"+空格+值+回车换行(\r\n) |
| ...... | ...... |
| 请求头部行N | 关键字+":"+空格+值+回车换行(\r\n) |
| 空行 | 回车换行(\r\n) |
| 请求数据 | GET方法的请求报文没有请求数据; POST方法的请求数据就是填写的表单数据; 例如网页FORM表单中input字段输入的数据:color=red |
第一行报文详细说明
报文的第一行
报文的第一行是:GET / HTTP/1.1\n
GET表示请求方法(另外有POST方法)
1.1表示http的版本
GET和HTTP之间的"/"表示请求的资源。浏览器发起请求后的,第一次发送的请求报文中,这个位置都是"/",/表示服务器端的资源目录,这里表示不指定特定的资源。当服务器把网页文件(例如:index.html)发送给浏览器后,浏览器收到这个网页文件后,如果网页文件中含有图片,那么浏览器会自动再发起一个http请求报文,此时请求报文的第一行数据,就类似:
GET /images/head.png HTTP/1.1\n
响应报文的格式
服务器发送数据给浏览器时,发送的响应报文,由4个部分组成:
状态行、消息头部、空行和响应正文。格式如下:
| 组成部分 | 说明 |
|---|---|
| 状态行 | 版本+空格+状态码+空格+短语+回车换行 例如: HTTP/1.0 200 OK\r\n |
| 消息头部1 | 关键字 : 空格 + 值 + 回车换行 例如:Content-type:text/html\n |
| …… | …… |
| 消息头部N | 关键字 : 空格 + 值 + 回车换行 |
| 空行 | 回车换行(\r\n)例如: \n |
| 响应正文 | 例如: <html><body><h1>Rock</h1></body><html> |
常用的关键字有:
| 关键字 | 含义 |
|---|---|
| Content-Type | 返回消息的内容类型 |
| Content-Length | 返回内容的长度, 以字节为单位 |
| Date | 返回消息的时间 |
| Server | 服务器端的软件名称和它的版本号 例如:Server: RockHttpd/0.1\r\n |
POST请求报文的格式
浏览器发送的POST报文的格式,和GET报文格式其实是一致的,只是多了最后一部分内容“请求数据”,实例如下:
POST /color.cgi HTTP/1.1\n
Host: 127.0.0.1:8000\n
Connection: keep-alive\n
Content-Length: 9\n
Cache-Control: max-age=0\n
Upgrade-Insecure-Requests: 1\n
Origin: http://127.0.0.1:8000\n
Content-Type: application/x-www-form-urlencoded\n
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36\n
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9\n
Sec-Fetch-Site: same-origin\n
Sec-Fetch-Mode: navigate\n
Sec-Fetch-User: ?1\n
Sec-Fetch-Dest: document\n
Referer: http://127.0.0.1:8000/\n
Accept-Encoding: gzip, deflate, br\n
Accept-Language: zh-CN,zh;q=0.9\n
\n
color=red最后一行“color=red”就是网页提交的数据。
报文的解析(每行代码的详细说明,可参考本教程的分享视频)
#include <sys/stat.h> //访问文件的属性
#define ISspace(x) isspace((int)(x))
#define PRINTF(str) printf("[%s - %d] "#str" = %s\r\n",__func__,__LINE__,str);
DWORD WINAPI accept_request(LPVOID arg) {
char buf[1024];
int numchars;
char method[255];
char url[255];
char path[512];
size_t i, j;
struct stat st;
int cgi = 0; /* becomes true if server decides this is a CGI
* program */
int client = (SOCKET)arg;
char* query_string = NULL;
numchars = get_line(client, buf, sizeof(buf));
i = 0; j = 0;
while (!ISspace(buf[j]) && (i < sizeof(method) - 1))
{
method[i] = buf[j];
i++; j++;
}
method[i] = '\0'; //解析后, method的值:"GET"
PRINTF(method);
// method是指http请求的具体类型,例如:
// <FORM ACTION="color.cgi" METHOD="POST">
// HTTP的请求方法,一共有8种:GET,POST,HEAD,PUT,DELETE,TRACE,OPTIONS,CONNECT
// 主要使用GET和POST, 本服务器只实现GET和POST方法
if (stricmp(method, "GET") && stricmp(method, "POST"))
{
unimplemented(client);
return 0;
}
if (stricmp(method, "POST") == 0)
cgi = 1;
i = 0;
while (ISspace(buf[j]) && (j < sizeof(buf))) //跳过buff中的空格
j++;
while (!ISspace(buf[j]) && (i < sizeof(url) - 1) && (j < sizeof(buf))) //获得资源url 比如 / 或者 /images/head.png
{
url[i] = buf[j];
i++; j++;
}
url[i] = '\0';
PRINTF(url);
// 解析查询字符串
// 如果浏览器的访问地址是: http://127.0.0.1:8000?name=rock
// 那么服务器端第一次收到的报文头就是: buf = GET /?name=rock HTTP/1.1
// 通过如果解析,query_string的值就是 "name=rock"
if (stricmp(method, "GET") == 0)
{
query_string = url;
while ((*query_string != '?') && (*query_string != '\0'))
query_string++;
if (*query_string == '?')
{
cgi = 1;
*query_string = '\0';
query_string++;
}
}
sprintf(path, "htdocs%s", url);
// 如果浏览器的地址输入:http://127.0.0.1:8000/movies/
// 那么url就是 /movies/
// url的最后一个字符是路径分隔符/
// 表示默认访问的是:/movies/index.html
if (path[strlen(path) - 1] == '/')
strcat(path, "index.html");
PRINTF(path);
// 检查访问的资源是否存在
if (stat(path, &st) == -1) { //stat获取指定文件的属性信息
// 如果不能访问它的属性信息,那么这个文件就不存在
// 此时,就需要把这个请求报文,读完!虽然已经没有用了,但是也要把这个报文读完
while ((numchars > 0) && strcmp("\n", buf)) /* read & discard headers */
numchars = get_line(client, buf, sizeof(buf));
not_found(client);
}
else
{
// 如果浏览器的地址输入:http://127.0.0.1:8000/movies
// 如果movies是目录,就默认访问这个目录下的index.html
if ((st.st_mode & S_IFMT) == S_IFDIR)
strcat(path, "/index.html");
if (!cgi)
// 发送一个普通文件(path)给浏览器客户端
serve_file(client, path);
else
// 使用CGI来处理“动态请求”,例如在网页中,用户填写信息后点击提交按钮后,服务器端使用CGI来处理这个请求
execute_cgi(client, path, method, query_string);
}
closesocket(client); //关闭套接字
return 0;
}
// 向浏览器发送一个错误提示信息,表示请求的方法还没有实现(现在只实现了GET和POST)
void unimplemented(int client) {
}
void not_found(int client) {
}
void serve_file(int client, const char* filename) {
}
void execute_cgi(int client, const char* path, const char* method, const char* query_string) {
}
// 从浏览器客户端对应的套接字中,读取一行字符串
// 返回值:成功读取的字符个数
int get_line(int sock, char* buf, int size) {
return 0;
}发送错误请求的响应包
发送501未实现服务的响应包
HTTP 状态码分为 5 类,如下所示:
1xx 信息
2xx 成功
3xx 重定向
4xx 客户端错误
404 表示服务器找不到浏览器请求的资源(例如某个图片或某个文件)。
5xx 服务器错误
501 表示服务器现在还不能满足客户端请求的某个功能。
代码如下:
// 向浏览器发送一个错误提示信息,表示请求的方法还没有实现(现在只实现了GET和POST)
void unimplemented(int client) {
char buf[1024];
sprintf(buf, "HTTP/1.0 501 Method Not Implemented\r\n");
send(client, buf, strlen(buf), 0);
sprintf(buf, SERVER_STRING);
send(client, buf, strlen(buf), 0);
sprintf(buf, "Content-Type: text/html\r\n");
send(client, buf, strlen(buf), 0);
sprintf(buf, "\r\n");
send(client, buf, strlen(buf), 0);
sprintf(buf, "<HTML><HEAD><TITLE>Method Not Implemented\r\n");
send(client, buf, strlen(buf), 0);
sprintf(buf, "</TITLE></HEAD>\r\n");
send(client, buf, strlen(buf), 0);
sprintf(buf, "<BODY><P>HTTP request method not supported.\r\n");
send(client, buf, strlen(buf), 0);
sprintf(buf, "</BODY></HTML>\r\n");
send(client, buf, strlen(buf), 0);
}注意代码中的Server关键字,表示服务器端的软件名称和它的版本号。
发送404资源不存在的响应包
代码如下:
void not_found(int client) {
char buf[1024];
sprintf(buf, "HTTP/1.0 404 NOT FOUND\r\n");
send(client, buf, strlen(buf), 0);
sprintf(buf, SERVER_STRING);
send(client, buf, strlen(buf), 0);
sprintf(buf, "Content-Type: text/html\r\n");
send(client, buf, strlen(buf), 0);
sprintf(buf, "\r\n");
send(client, buf, strlen(buf), 0);
sprintf(buf, "<HTML><TITLE>Not Found</TITLE>\r\n");
send(client, buf, strlen(buf), 0);
sprintf(buf, "<BODY><P>The server could not fulfill\r\n");
send(client, buf, strlen(buf), 0);
sprintf(buf, "your request because the resource specified\r\n");
send(client, buf, strlen(buf), 0);
sprintf(buf, "is unavailable or nonexistent.\r\n");
send(client, buf, strlen(buf), 0);
sprintf(buf, "</BODY></HTML>\r\n");
send(client, buf, strlen(buf), 0);
}