Python爬取视频在上一章已经实现,如果爬取数据的时候发现不止一页数据,而是很多页数据的时候,我们就需要爬虫自行翻页操作继续获取另一页的数据。那么如何实现的翻页操作是本章主要描述内容。
该文章爬取数据例子网址
1、翻页操作的原理
翻页操作基本原理实际就是打开另一页的网址(该文章描述的是换页网址会发生变化的类型,换页时地址没变化的不适用该文章描述方法),知道原理后,我们想翻页操作时,只需要找到翻页后的网络地址并打开即可爬取翻页后的数据内容。
2、如何实现翻页
比如爬取数据是如下图这种翻页模式的

那么我们只需要在打开该网址后,打开开发者工具,搜索关键字 “下一章” ,点击搜索到的信息,会看到有需要的下一章网址(如下图所示)
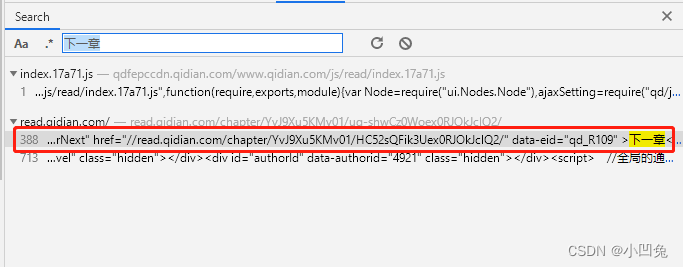
留意记住红框框柱的内容,这是我们想要的点击下一章后刷新的网络地址,只要获取该网络地址并对该网址进行网络请求即可获取下一章的内容,从而实现自动翻页操作
3、代码实现
import requests
import re
url = 'https://read.qidian.com/chapter/YvJ9Xu5KMv01/uq-shwCz0Woex0RJOkJclQ2/'
headers={
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36 SE 2.X MetaSr 1.0"}
response = requests.get(url=url, headers=headers)
next_url = re.findall('href="(.*?)" data-eid="qd_R109" >下一章', response.text)[0]
print("自动获取下一章的网址: %s"%("https:" + next_url))
4、结果
执行完上面代码可看到结果:

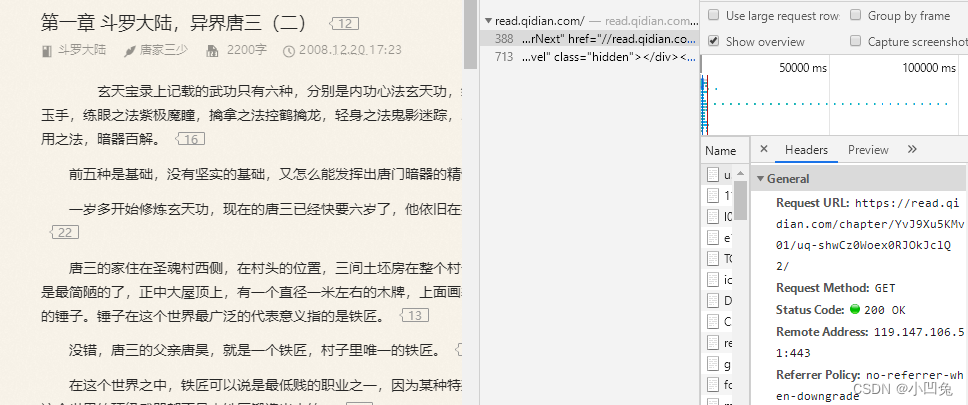
我们将自动获取出来的网络地址复制粘贴到浏览器并打开与未翻页的页面对比观看是否实现了下一章的跳转:
跳转前页面:
下一章跳转后页面:
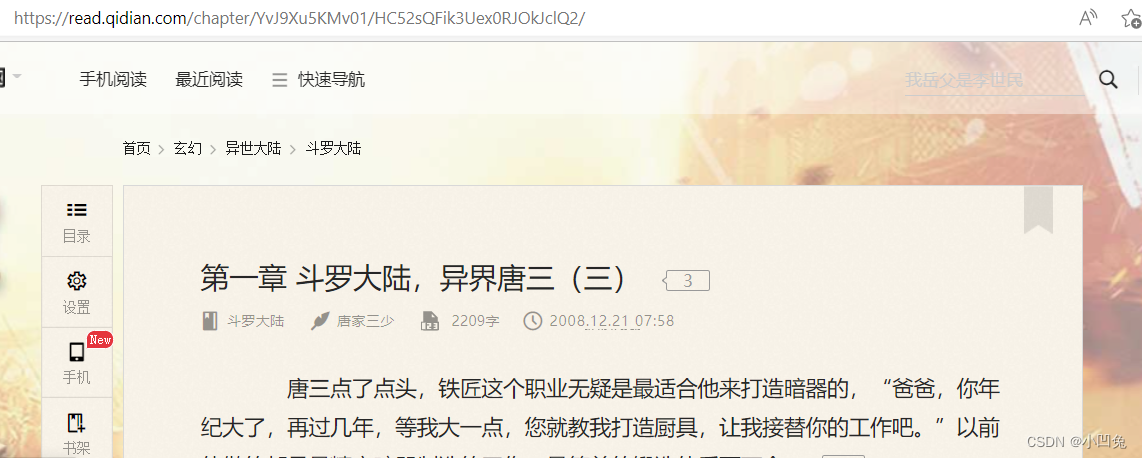
通过两个页面对比,可以看出是正确自动捕获到了翻页后的网址,成功实现了爬虫翻页操作。
希望该文章对你有所帮助,作者能力有限,如有不足请多多包涵。
如果你觉得该文章不错请点个免费的赞吧!