本文来源于:【精读AI论文】知识蒸馏_哔哩哔哩_bilibili
ReadPaper论文链接及论文十问解答:https://readpaper.com/paper/1821462560
OpenMMLab:https://openmmlab.com/
【OpenMMLab模型压缩工具箱】MMRazor:https://github.com/open-mmlab/MMRazor
【OpenMMLab模型转换与部署工具箱】MMDeploy:https://github.com/open-mmlab/MMDeploy
【12个SOTA知识蒸馏pytorch实现】RepDistill:https://github.com/HobbitLong/RepDistiller

https://arxiv.org/abs/2006.05525
一、知识蒸馏整体概括:
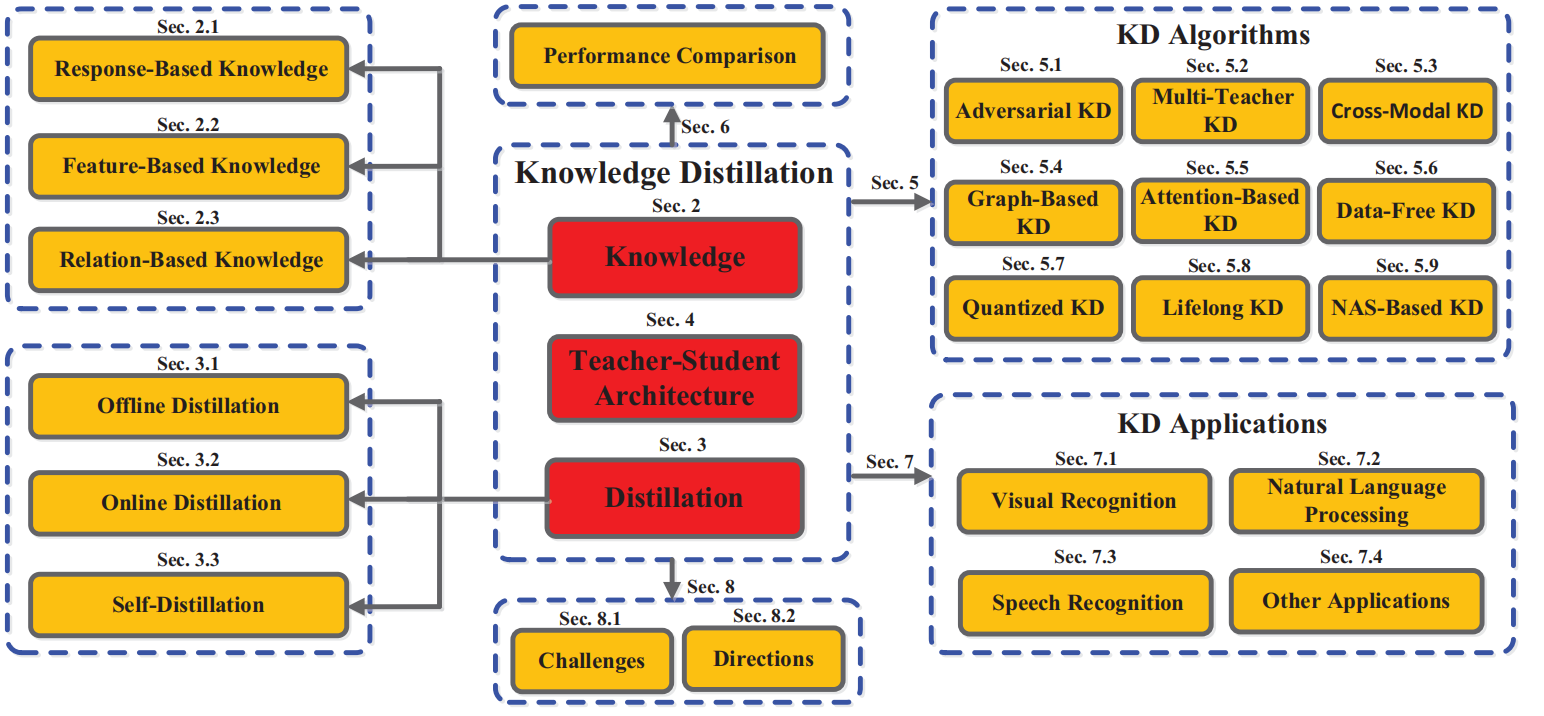
二、每种蒸馏方案又分为三种知识传递方式
蒸馏方案分为三种: Offline Distillation、Online Distillation、Self-Distillation,然后每种蒸馏方案又可以分为三种知识传递方式:
基于响应的知识(Response-Based Knowledge)
基于特征的知识(Feature-Based Knowledge)
基于关系的知识(Relation-Based Knowledge)
在原始或者说早期的知识蒸馏技术里,student学习的是teacher的logits(对于分类任务而言,一般将进softmax之前的scores叫做logits,softmax输出的概率分布叫soft labels,后者也有叫logits的)。后来为了改善知识蒸馏的效果,各路大佬开始花式开发各种特征用于学习,整体大致可以分为三类,response-based knowledge, feature-based knowledge and relation-based knowledge。
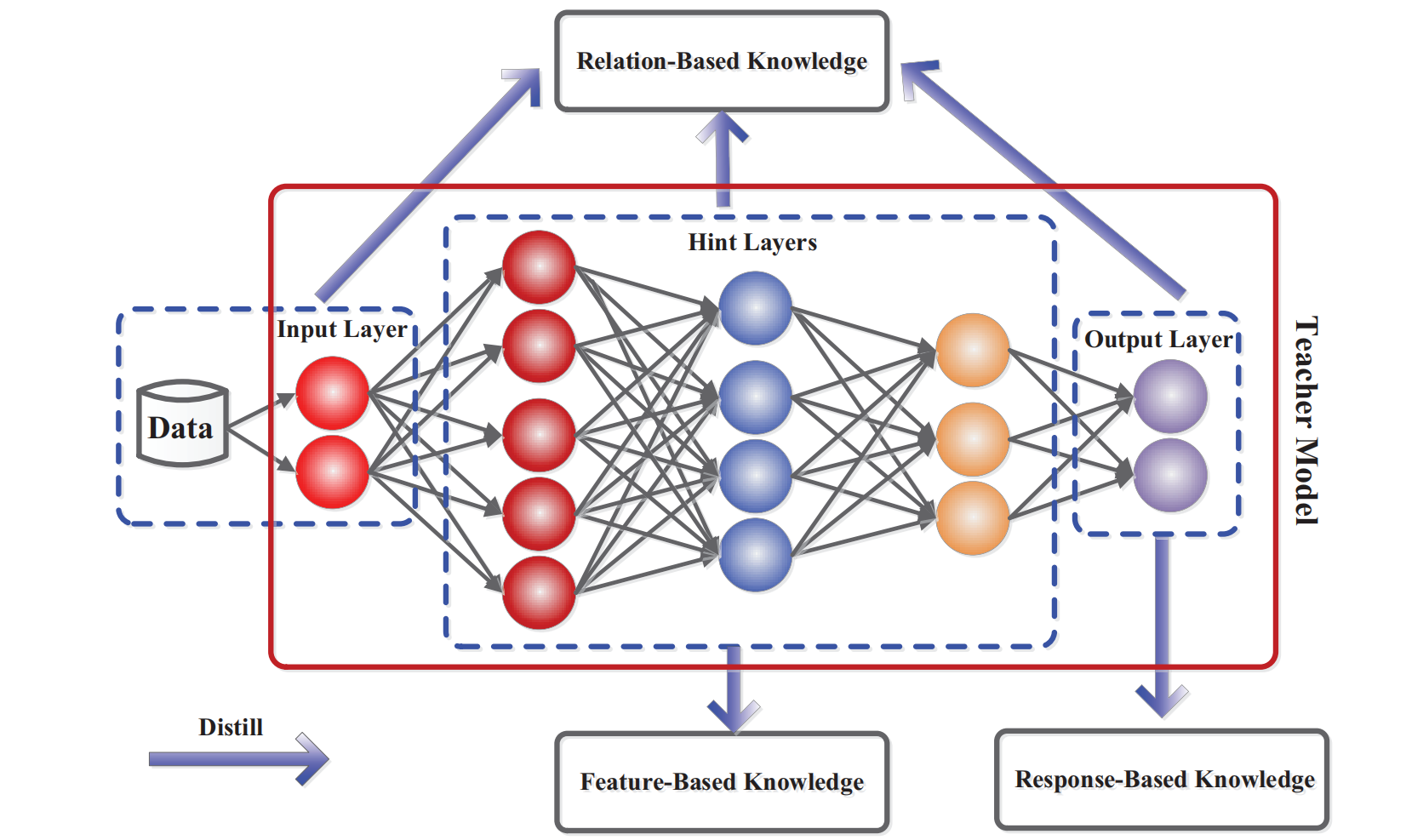
2.1 Response-Based Knowledge
用最后一层的输出用作知识来监督学生模型的训练

2.2 Feature-Based Knowledge
用中间层(不包含最后一层)的输出用作知识来监督学生模型的训练

深度神经网络善于学习多层次的特征表示,逐渐抽象化。这被称为表示学习(representation learning,Bengio等人,2013)。因此,最后一层的输出和中间层的输出,即特征图,都可以用作知识来监督学生模型的训练。具体来说,来自中间层的基于特征的知识是基于响应的知识的有益扩展,尤其适用于训练更薄、更深的神经网络
蒸馏的损失函数是:

-
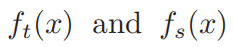 分别是教师网络和学生网络中间层的特征;
分别是教师网络和学生网络中间层的特征; 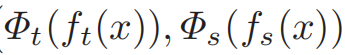 转换函数被用在教师网络和学生网络特征图不在一个维度(shape)的时候
转换函数被用在教师网络和学生网络特征图不在一个维度(shape)的时候-
 是计算教师网络和学生网络特征图的相似度函数
是计算教师网络和学生网络特征图的相似度函数
2.2.1 Feature-Based Knowledge Sources有哪些?
- Hint layer:指的是教师模型中的某个特定层,其输出被用作指导学生模型训练的参考知识。
- Multi-layer group:指的是一个由多个图层组成的图层组,可以将图层进行分组,以便于管理和操作
- Pre-ReLU:是指ReLU激活函数前面的部分。通常,这一部分包括输入层、隐藏层和权重矩阵等内容。
- Fully-connected layer:全连接层
- Penultimate layer:是神经网络中倒数第二个非输出层,通常用于提取高阶语义特征
2.2.1 Feature-Based Knowledge Types 有哪些?
Hint layer:
- Neuron selectivity patterns【指的是神经元对特定输入模式或刺激的选择性响应。例如,在视觉感知中,许多神经元对不同的视觉刺激,如边缘、方向、角度和颜色等,都有不同的选择性响应】
- Sharing parameters【是指在神经网络层之间共享一组参数。这种参数共享可以减少模型中可训练参数的数量,从而提高模型的效率和泛化能力。通常在卷积神经网络(CNN)中使用参数共享】
- Knowledge amalgamation【指的是将多个知识源或模型的输出结合起来以提高模型的准确性和性能】
- Feature representation【指的是将原始数据转换为高层次的特征表示形式的过程。通过学习从原始输入到高层特征的映射关系,可以提高模型的泛化能力和表达能力】
- Feature aggregation【是指把多个特征融合在一起以产生更有信息量的特征表示形式的过程。常用的特征融合方法包括加法、平均值、最大值、置信度加权等】
- Feature statistics【指的是对特征进行统计分析,提取其相关的统计属性,如均值、方差、协方差等,以便于模型进行分类、聚类等任务】
- Feature maps
- Attention maps
- Paraphraser【是一种自然语言处理工具,可以帮助用户快速编写文本。它使用先进的算法来自动重述英语句子、段落、论文或文章,以改善它们的表达方式并提高其质量】
- Parameters distribution
- Activation boundaries【是指在神经网络的空间中,将激活函数应用于输入后,在不同的输入位置或方向上的激活响应边界。Activation Atlas这篇博客提供了一个交互式的可视化工具,可以帮助人们更好地理解深度神经网络的工作方式和决策过程】
- Margin ReLU【是一种针对ReLU激活函数的改进版本,旨在通过抑制负值的输出来提高模型的表现。在训练期间,Margin ReLU会将负值直接设置为0,而不是保留原始负值。】
- Feature representation
Penultimate layer :
- Feature representation
虽然基于特征的知识传递为学生模型的学习提供了有利的信息,但如何有效地选择教师模型中的提示层(hint layers)和学生模型中的引导层(guided layers)仍需进一步研究(Romero等人,2015)。由于提示层和引导层的规模差异显著,因此如何正确匹配教师和学生的特征表示也需要探索?
提示层是指教师模型中的特征图映射,可以作为学生模型训练时的知识,用于指导学生模型的学习过程;
引导层则是学生模型中与提示层相对应的层,它的目标是通过在学生模型的训练过程中采取特定的优化策略,使学生模型的特征图更好地匹配教师模型的提示层。这样,学生模型可以更好地学习到教师模型中的知识,提高自己的性能和精度。
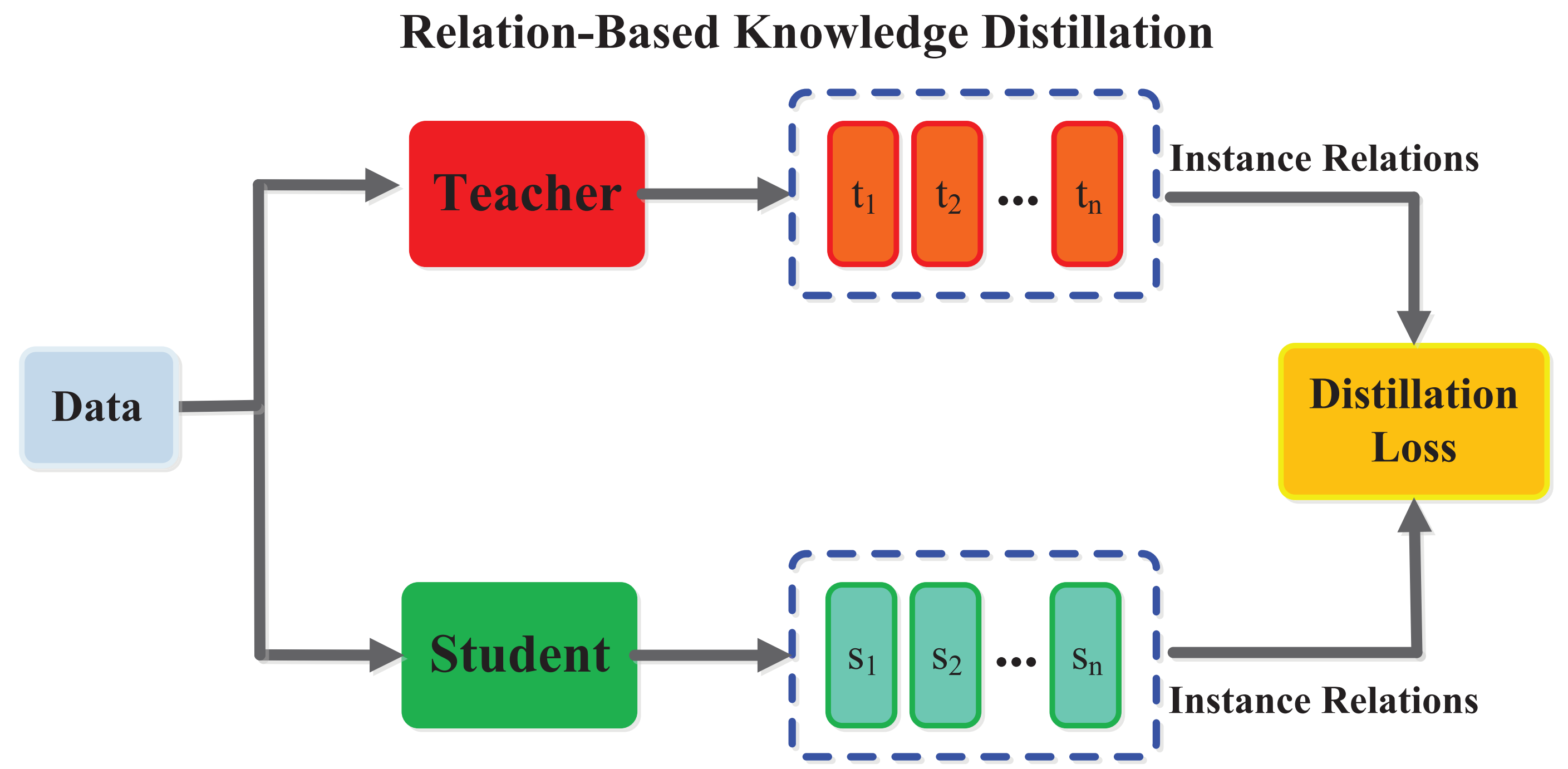
2.3 Relation-Based Knowledge
响应式知识和基于特征的知识都使用教师模型中特定层的输出。而关系型知识则进一步探索不同层之间或数据样本之间的关系
三、蒸馏的方案:
知识蒸馏一般可以分为离线蒸馏、在线蒸馏和自蒸馏三种架构。

3.1 Offline Distillation
工业界用的比较多的是离线蒸馏,学生向预先训练好的老师学习,简单易于实现。【只更新学生模型、教师网络无需更新】
知识从预训练的教师模型转移到学生模型。因此,整个训练过程分为两个阶段,即:
- 大教师模型首先在一组训练样本上进行训练,然后进行蒸馏;
- teacher模型用于提取logits或中间特征形式的知识,然后在蒸馏过程中用于指导student模型的训练。
离线蒸馏的主要关注点在知识的获取选择和损失函数的设计上。离线蒸馏的主要问题是大的teacher和小的student之间存在着model capacity gap,可能小的student就没有办法学得特别好,因为可能能力确实有限。这与人类的师生关系其实有本质的不同,人类的teacher和student只有闻道有先后的差别,没有human capacity gap。因此在人类的学习过程中,经常出现学生超过老师的情况,但在离线蒸馏中,学生往往很难超过老师。
3.2 Online Distillation
在线蒸馏是一种具有高效并行计算的单阶段端到端训练方案。为了克服离线蒸馏的局限性,提出了在线蒸馏来进一步提高学生模型的性能,特别是在没有大容量高性能教师模型的情况下。在线蒸馏时,【教师模型和学生模型同步更新,而整个知识蒸馏框架都是端到端可训练的】
近年来,有些比较有意思的在线蒸馏方面的工作,比如deep mutual learning,Co-distillation,Adversarial co-distillation等。
3.3 Self-Distillation
自蒸馏(self-distillation)【同一网络同时用作teacher和student、即网络本身既是教师模型又是学生模型】蒸馏通常在网络内部不同层之间进行。、
4.师生架构
教师和学生的模型设置几乎是预先固定的,大小和结构不变,容易产生模型容量上的差距。两者之间模型的设置主要有以下关系

深度神经网络的复杂性主要来自于深度和宽度这两个维度。通常需要将知识从更深、更宽的神经网络转移到更浅、更窄的神经网络。学生网络的结构通常有以下选择:
- 1)教师网络的简化版本,层数更少,每一层的通道数更少;
- 2)保留教师网络的结构,学生网络为其量化版本;
- 3)具有高效基本运算的小型网络;
- 4)具有优化全局网络结构的小网络;
- 5)与教师网络的结构相同。
大网络和小网络之间容量的差距会阻碍知识的迁移。为了有效地将知识迁移到学生网络中,许多方法被提出来控制降低模型的复杂性。
- 论文(Mirzadeh, S. I., Farajtabar, M., Li, A. & Ghasemzadeh, H. (2020). Improved knowledge distillation via teacher assistant. In AAAI.)引入了一个教师助手,来减少教师模型和学生模型之间的训练差距。
- 另一篇工作通过残差学习进一步缩小差距,利用辅助结构来学习残差。
- 还有其他一些方法关注减小教师模型与学生模型结构上的差异。例如将量化与知识蒸馏相结合,即学生模型是教师模型的量化版本。【这句话的意思是,除了知识蒸馏之外,还有一种方法可以减小教师模型和学生模型之间的结构差异,即将量化(Quantization)技术与知识蒸馏相结合。在这种情况下,学生模型被设计成教师模型的量化版本,即它们具有相同的网络结构,但学生模型的权重和激活值被限制为较小的固定精度来减少存储和计算开销。在这种情况下,知识从教师模型传递到学生模型时,不仅包括软标签信息,还包括量化后的权重和激活值。通过将量化和知识蒸馏结合使用,可以进一步提高学生模型的性能和效率,同时保持与教师模型相似的预测质量。】
- 通过替换基础组件也是有效的方法,例如将普通卷积替换为在移动和嵌入式设备上更高效的深度可分离卷积。受神经架构搜索的启发,通过搜索基于基础构建块的全局结构,小型神经网络的性能进一步提高。
- 此外,动态搜索知识迁移机制的想法也出现在知识蒸馏中,例如,使用强化学习以数据驱动的方式自动去除冗余层,并寻找给定教师网络的最优学生网络。
5.蒸馏算法
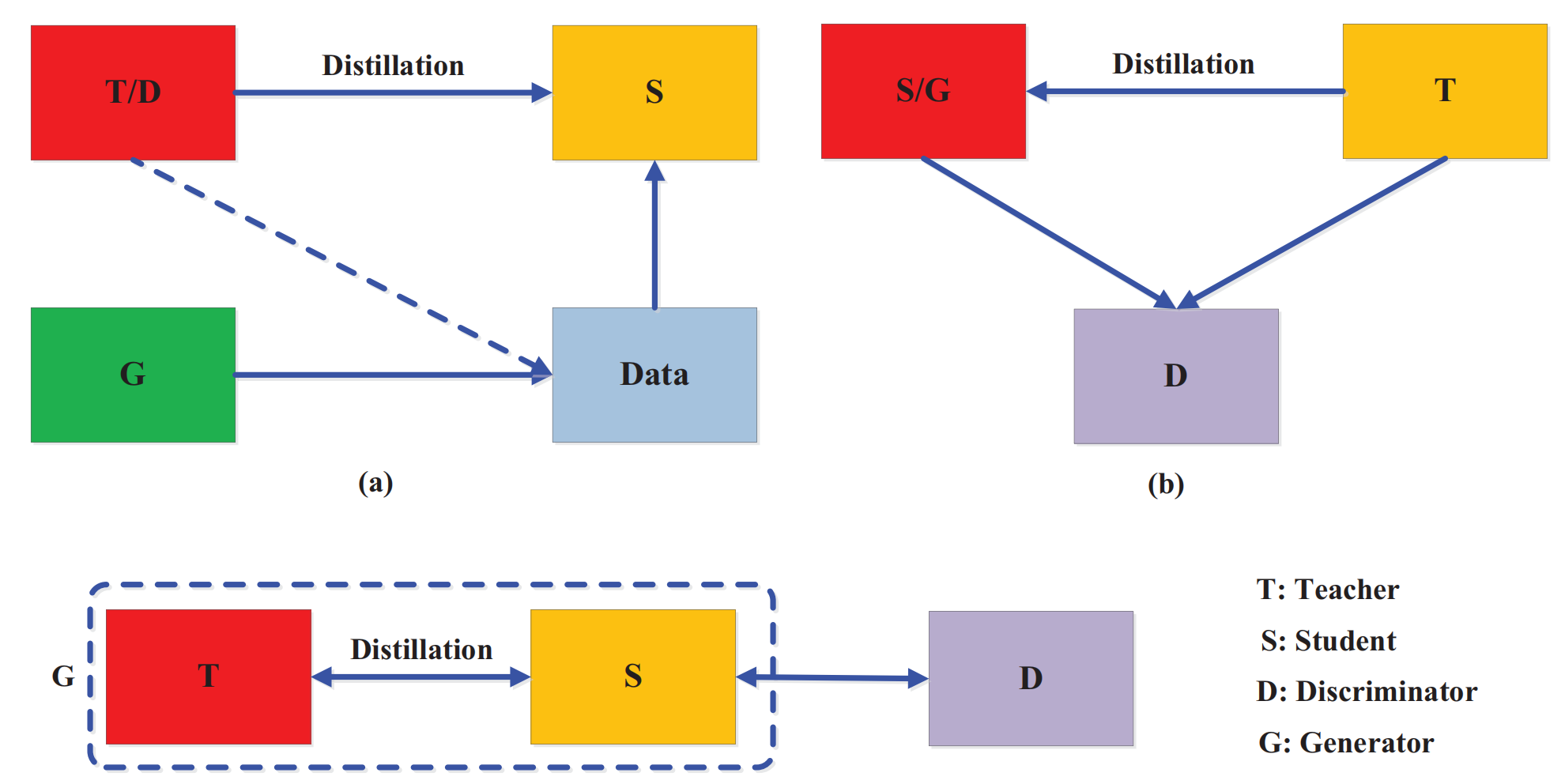
5.1 对抗性蒸馏(Adversarial Distillation)
生成对抗网络(GAN)中的鉴别器估计样本来自训练数据分布的概率,而生成器试图使用生成的数据样本欺骗鉴别器的概率预测。
5.2 多教师蒸馏(Multi-teacher Distillation)
多个教师那里转移知识,最简单的方法是使用所有教师的平均反应作为监督信号,
多教师知识蒸馏可以提供丰富的知识,并且由于来自不同教师的知识多样化,可以定制通用的学生模型。但是,如何有效整合多位教师的不同类型的知识还需要进一步研究。

5.3 跨模态蒸馏(Cross-Modal Distillation)
在训练或测试时一些模态的数据或标签可能不可用,因此需要在不同模态间知识迁移。在教师模型预先训练的一种模态(如RGB图像)上,有大量注释良好的数据样本,将知识从教师模型迁移到学生模型,使用新的未标记输入模态,如深度图像(depth image)和光流(optical flow)。
具体来说,所提出的方法依赖于涉及两种模态的未标记成对样本,即RGB和深度图像。然后将教师从RGB图像中获得的特征用于对学生的监督训练。成对样本背后的思想是通过成对样本迁移标注(annotation)或标签信息,并已广泛应用于跨模态应用。成对样本的示例还有
1)在人类动作识别模型中,RGB视频和骨骼序列;
2)在视觉问题回答方法中,将图像-问题-回答作为输入的三线性交互教师模型中的知识迁移到将图像-问题作为输入的双线性输入学生模型中。

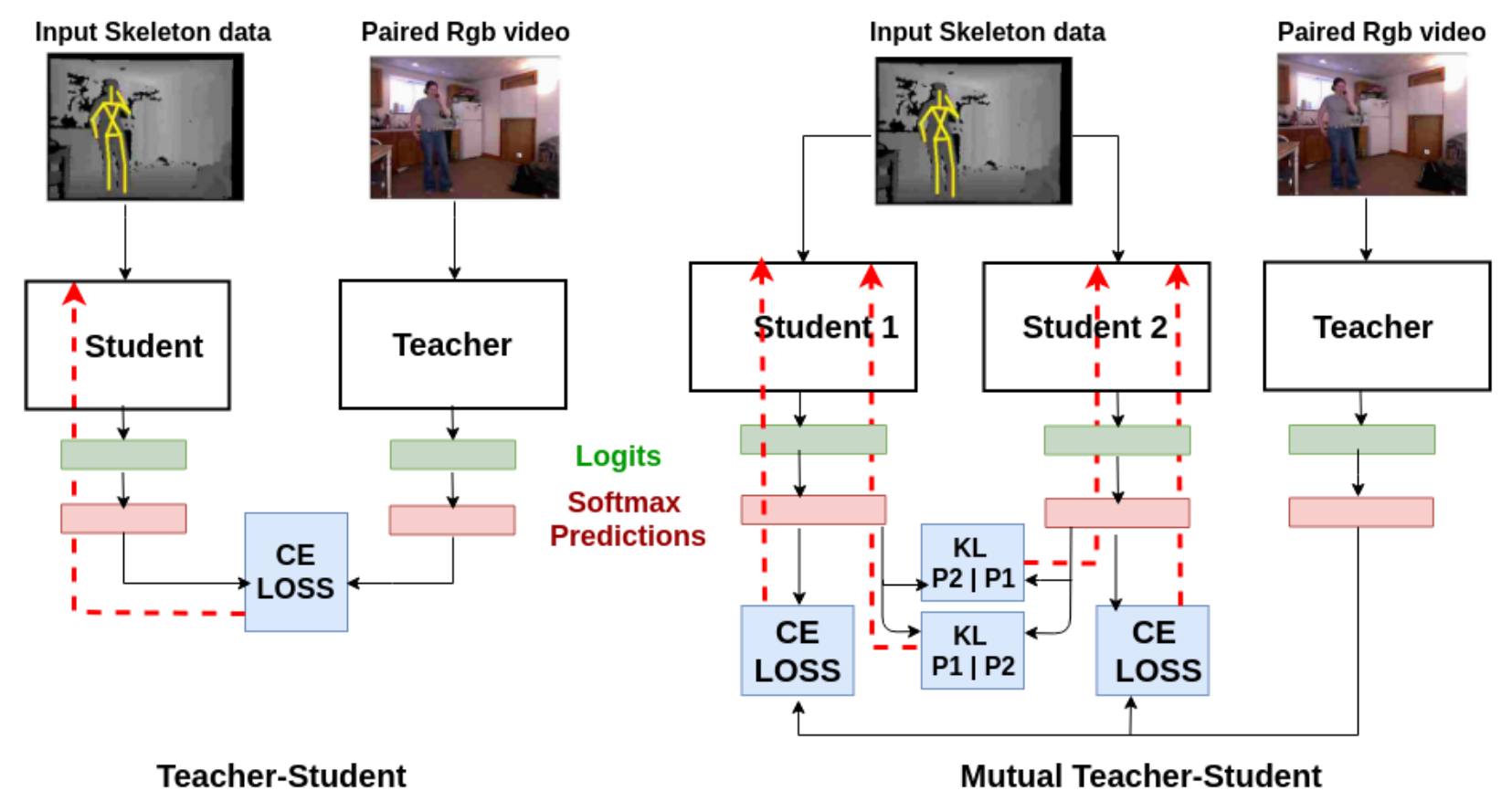
这里的多个学生模型好像是用到了协作学习(collaborative learning)
Fig. 1: (a) The teacher network, which has been previously trained for RGB videos, provides the supervision for the student network for skeleton data. For training the student network, unlabeled pairs for both modality and the cross-entropy loss are used.
(b) Instead of one student network, two or more student networks can be trained together using mutual learning such that each student learns from the supervision of the teacher as well as the other student. The red dashed lines denote back-propagation for the corresponding loss functions.
跨模态知识转移是一个具有挑战性的研究,例如不同模态之间有gap,不同模态之间缺乏成对样本。
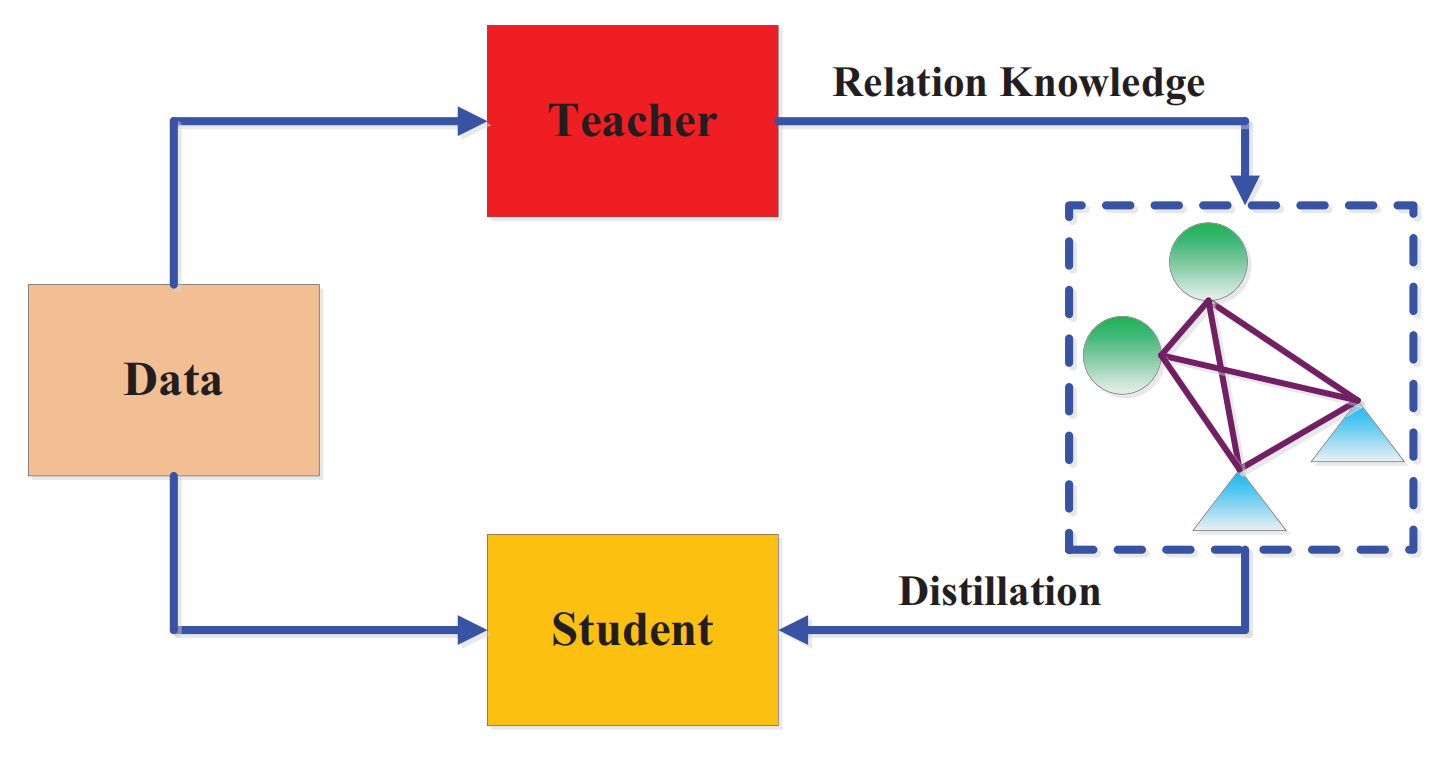
5.4 基于图的蒸馏(Graph-Based Distillation)
大多数知识蒸馏算法侧重于将个体实例知识从教师传递给学生,而最近提出了一些方法使用图来探索数据内关系。这些基于图的蒸馏方法的主要思想是:
1)使用图作为教师知识的载体【将教师变为一个图】;
2)使用图来控制教师知识的传递,基于图的知识可以归类为基于关系的知识【基于图的蒸馏全是基于关系的知识】。
5.5 基于注意力的蒸馏(Attention-Based Distilla)
由于注意力可以很好地反映卷积神经网络的神经元激活,因此利用注意力机制在知识蒸馏中提高学生网络的性能。注意力迁移的核心是定义特征嵌入到神经网络各层中的注意力映射。
5.6 无数据的蒸馏(Data-Free Distillation)
无数据蒸馏的方法提出的背景是克服由于隐私性、合法性、安全性和保密问题导致的数据缺失。“data free”表明并没有训练数据,数据是新生成或综合产生的。新生的数据可以利用GAN来产生。合成数据通常由预先训练过的教师模型的特征表示生成
5.7 量化蒸馏(Quantized Distillation)
通过将高精度转化为低精度网络,来降低神经网络的计算复杂度。知识蒸馏旨在训练一个小模型以产生与复杂模型相当的性能。
在这种情况下,学生模型被设计成教师模型的量化版本,即它们具有相同的网络结构,但学生模型的权重和激活值被限制为较小的固定精度来减少存储和计算开销。
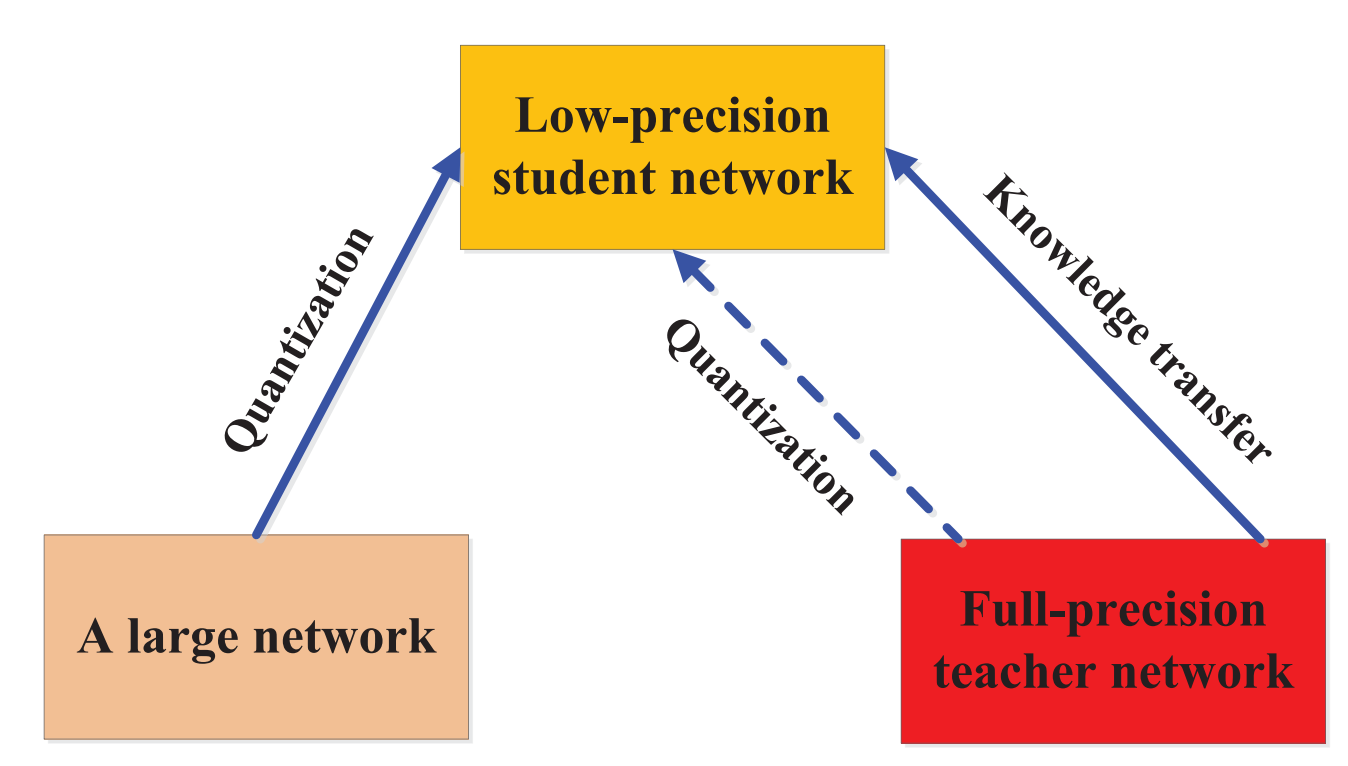
5.8 终身蒸馏(Lifelong Distillation)
终身学习,包括持续学习、持续学习和元学习,旨在以与人类相似的方式学习。它积累了以前学到的知识,并将学到的知识转移到未来的学习中
5.9 基于神经架构搜索的蒸馏(NAS-Based Distillation)
神经架构搜索 (NAS) 是最流行的自动机器学习(或 AutoML)技术之一,旨在自动识别深度神经模型并自适应地学习适当的深度神经结构。
6.性能比较
1.不同的深度模型都可以实现蒸馏
2.知识蒸馏可以实现深度模型的模型压缩
3.通过合作学习【collaborative learning】的在线蒸馏可以显著提升模型性能
4.自蒸馏可以有效提升模型性能
5.离线蒸馏常用基于特征的知识,在线蒸馏常用基于响应的知识
6.轻量化学生模型的性能可以通过高性能教师模型的知识来得到提升
8 Conclusion and Discussion
8.1 Challenges
知识的质量: 各种类型知识的作用以及如何互相影响,比如,基于响应的知识和label smoothing以及正则化有着相同的动机;基于特征的知识经常被用来模仿教师模型的中间结果;基于关系的知识用来捕获不同样本之间的关系。因此用一种统一的方式应用各种类型的知识仍然是个巨大的挑战。
蒸馏类型:一般来说大规模的复杂教师模型使用离线蒸馏,教师学生模型性能相当的使用在线蒸馏或者自蒸馏。因此模型复杂度与蒸馏类型之间的关系有待进一步研究。
教师学生架构:当前大多数研究集中在知识类型或者蒸馏损失函数的设计,而教师学生架构的研究相对较少。实际上,当存在gap时,学生模型几乎从教师模型那学不到多少东西。但是另一方面,一些早期的理论研究表明浅层的神经网络有能力学习到像深层网络一样的特征表示,因此如何设计高效的教师学生架构仍然是个具有挑战性的问题。
理论:尽管有很多关于知识蒸馏的方法和应用研究,但是关于知识蒸馏的理论解释和实验验证仍然相对较少。比如,知识蒸馏可以认为是带特权信息的学习。此外如何评价知识的质量和教师学生架构的好坏仍是个亟待解决的问题。
8.2 Future Directions
模型压缩和加速方法通常可分为以下四种类型:参数剪枝和共享、低秩分解、紧致卷积核和知识蒸馏。
只有为数不多的工作将知识蒸馏与其他模型压缩方法结合,如量化知识蒸馏。因此,混合压缩方法用于学习一个轻量化的模型非常必要,因为大部分模型压缩技术都有精细化调整的过程。更进一步,如何确定不同压缩方法的应用顺序,将是一个有趣的研究主题。
此外,知识蒸馏在数据隐私保护、对抗攻击、跨模态、灾难性遗忘、加速学习、NAS加速、自监督、数据增强等方面也可以有广泛应用。一个有趣的例子是用小的教师网络来监督大的学生网络可以加速学生网络的学习过程。从大模型中学到的无标签数据的特征表示也可以用来监督目标模型的学习。为此,知识蒸馏的其他拓展应用将是个有意义的研究方向。
知识蒸馏的学习过程和人类的学习过程类似,将其中的知识迁移过程推广到传统的机器学习方法是可行的。此外,知识蒸馏可以灵活地应用到其他的学习范式中,如对抗学习、元学习、标签噪声过滤、终生学习、强化学习等,这也是一些很有前景的研究方向。