环境准备
- Python
- 谷歌浏览器或其他浏览器的Driver驱动,最好设置下环境变量(全局驱动),或者使用局部的驱动也可以
- 安装 selenium库
实现
- 打开浏览器
- 定位元素
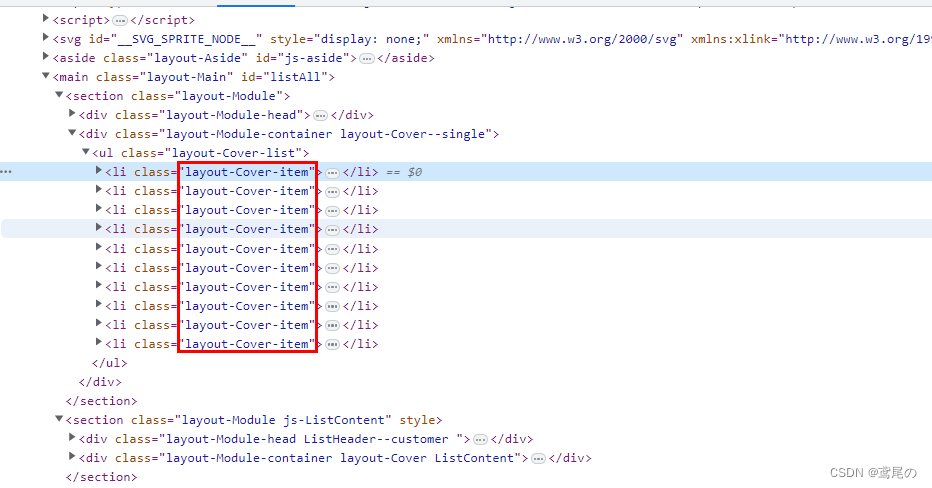
打开页面调试,即可发现每个直播框都是很多的li元素,class都是layout-Cover-item,我们直接获取所有的这种li元素集合就行。
- 操作元素
获取完毕后,我们还需要提取每个直播间的标题、用户、热度等等数据。
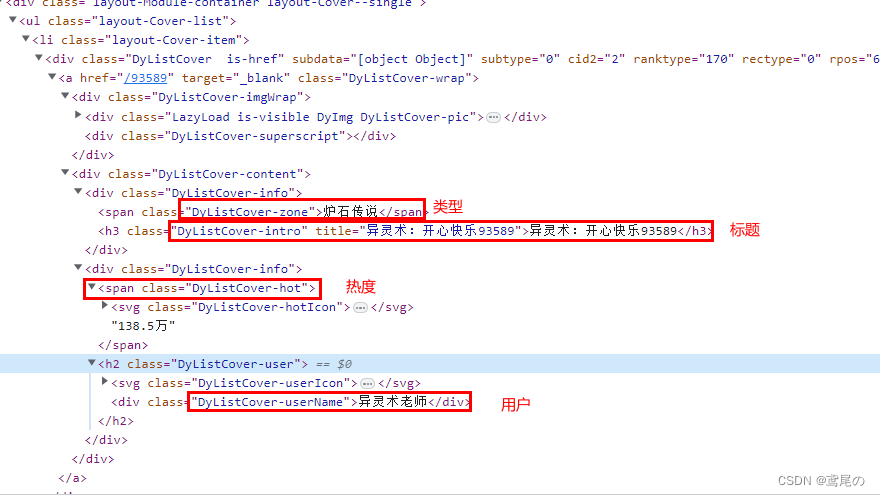
数据都可以获取到,需要注意的是,我们需要遍历的是获取到的li集合中的web元素。
- 获取元素信息
# @creator by wlh
# @date 2023/3/16 14:01
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
url = "https://www.douyu.com/directory/all"
driver.get(url)
# 最大化
driver.maximize_window()
time.sleep(1)
n = 1
# 模拟获取10页
while n < 11:
# 滑动到底部
driver.execute_script("window.scrollTo(0, 10000)")
# 等待加载元素
time.sleep(2)
# 获取所有的元素列表
lst = driver.find_elements(By.CLASS_NAME, "layout-Cover-item")
# 遍历所有的 li 标签
for li in lst:
item = {
}
# 每次从 li 元素里面找到需要的数据
item["title"] = li.find_element(By.CLASS_NAME, "DyListCover-intro").text
item["types"] = li.find_element(By.CLASS_NAME, "DyListCover-zone").text
item["name"] = li.find_element(By.CLASS_NAME, "DyListCover-userName").text
item["hot"] = li.find_element(By.CLASS_NAME, "DyListCover-hot").text
print(item)
# 获取下一页
next = driver.find_element(By.XPATH, "//*[@title='下一页']")
if next.is_enabled():
next.click()
n += 1
time.sleep(1)
time.sleep(5)
driver.quit()