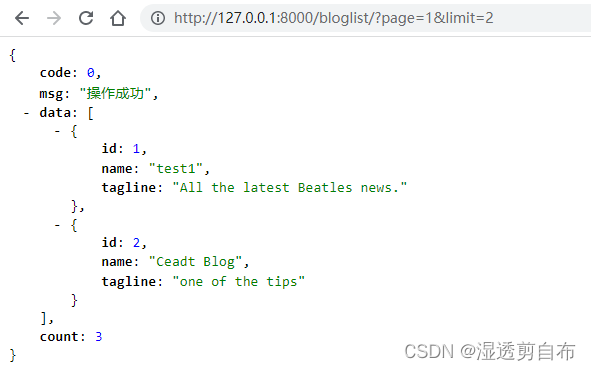
参考原链接:https://blog.csdn.net/qq_37605109/article/details/124514037
这里添加了keyword参数,可以在分页的基础上继续过滤
views.py
from django.forms import model_to_dict
from django.core.paginator import Paginator
from django.views import View
from django.http import JsonResponse
from .models import Blog
class BlogListView(View):
def get(self, request):
page = request.GET.get('page', 1) # 获取第几页
limit = request.GET.get('limit', 2) # 每页有多少条数据
keyword = request.GET.get('keyword', "")
all_count = Blog.objects.filter(name__icontains=keyword)
paginator = Paginator(all_count, limit)
page_1 = paginator.get_page(page)
data_list = []
for i in page_1:
mode_to = model_to_dict(i, exclude='img') # exclude这个是转字典的时候去掉,哪个字段,就是不给哪个字段转成字典
data_list.append(mode_to)
data = {'code': 0, "msg": '操作成功', "data": data_list, 'count': paginator.count}
return JsonResponse(data)urls.py
from django.urls import path, include
from . import views
urlpatterns = [
path('bloglist/', views.BlogListView.as_view())
]浏览器请三种请求返回结果: