作者:计算机视觉工坊
编辑:3D视觉开发者社区
论文链接:
https://xueshu.baidu.com/usercenter/paper/show?paperid=1e090pe0h36k0m002a7q06d0at215203&site=xueshu_se
1、摘要
在三维人脸对齐领域,大多数研究者都集中在提高算法的预测精度上,而忽视了算法的可移植性。为此,本研究提出了一种实时三维人脸对齐方法,该方法使用一个具有高效反卷积层的编解码器网络。编码和解码特征的融合为该网络增加了更丰富的特征,同时加强了编解码阶段不同分辨率之间信息的传递。在解码阶段,一个高效的反卷积层应用L1范数选择具有代表性的特征通道,并通过线性运算生成更加丰富的特征从而缩短卷积运算耗时。在标准的AFLW2000-3D和AFLW-LFPA数据集上的实验结果表明,该算法在保持较低的预测误差的同时能够达到实时的性能。
2、介绍
人脸对齐指的是一种预测面部特征点的方法,用于人脸识别[1,2]、面部美化和头部姿势估计等应用。传统的人脸对齐算法使用二维图像来输出二维人脸标志。然而,这种方法在大姿态人脸对齐中不稳定,鲁棒性差。因此,三维人脸对齐逐渐引起了研究者的兴趣。本研究的主要目的是提出一种实用的实时三维人脸对齐方法。
论文的研究贡献如下:
(1)提出了一种称为EDNet的编解码网络,它利用特征增强和特征融合来增加网络编码和解码区域之间的信息传输。
(2)提出了一种转置卷积层,利用L1范数选择和过滤原始输入特征,利用线性变换生成丰富的特征,使得网络是轻量级的同时具有不错的非线性表达能力。
(3)提出了一种CPU实时三维人脸特征点定位方法,该方法能够实现精度和速度的平衡,更适用于实际应用。
3、概述
(1)提出的网络结构
论文提出的方法的结构如图1所示。将人脸的二维图像输入到所提出的EDNet中。输出是UV位置图[9,5],它表示人脸的三维信息。最后,利用UV图对三维人脸进行重建,并对地标坐标进行预测。
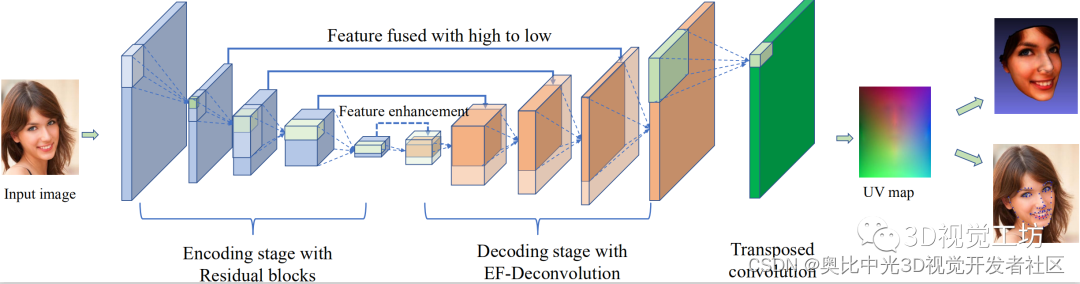
在编码阶段,第一层是标准卷积层,具有八个滤波器,接着是一系列残差块[23],信道逐渐增加。解码模块的每个步骤都包括特征图的上采样,该特征图经过了所提出的高效反卷积(EF-deconv)层。该层通过线性变换,可以过滤出更具代表性的特征,并生成具有相似特征分布的特征通道,最后对所获得的特征映射与编码模块对应输出的特征映射相结合。
在第一层EF-deconv中,从编码模块中添加了相同大小的特征。这相当于特征增强;接下来的三个EF-deconv层执行级联操作,以增加特征的多层次细粒度。在网络的最后三层中,论文不使用EF-deconv层,因为这些网络层用于使用UV位置图恢复三维面部顶点。因此,如果在网络最后三层使用EF-deconv层时,训练过程中网络的特征通道会出现紊乱,这使得网络难以达到收敛效果。因此,在网络的末尾,仍然使用一个通用的转置卷积层进行训练。
(2)反卷积层的实现
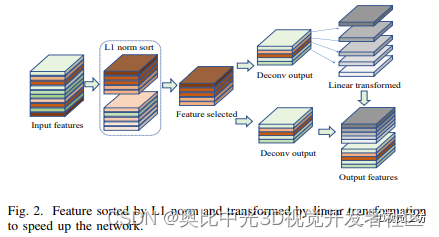
EF-deconv层的内部实现方式如下:
首先,使用L1正则化将所有特征通道的得分从高到低排序。然后,选择前半部分得分较高的特征通道输入到普通的转置卷积层,也即得分较低的通道的权重置为0。转置卷积层的输出特性保持不变,再通过线性变换对转置卷积层的输出特征进行扩展,从而在保持网络非线性表达能力的同时缩短该层的计算耗时,最后将二者的特征通道进行结合作为最终输出特征。L1正则化通常用于一些特征选择研究[7,8]。式(1)表示具体操作:
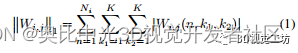
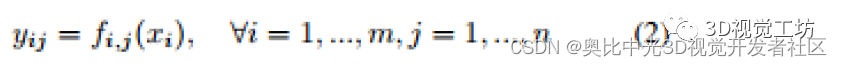
其中Wi,j是第i层反卷积中第j个特征图的得分,Ni是第i层中特征图的数目。K是来自过滤器的输出特征映射的大小。用于产生其它特征映射的线性变换的操作可以公式化如下:
这里,xi是第i个输入特征图,Yij是第i个输入特征的第j个输出,而f(I,j)是产生第j个特征的第j个线性运算,Yij。m是输入特征映射的数量,n是一个输入特征映射产生的特征的数量。该模块中的线性变换可以用几种不同的线性运算来实现,在实验部分作者采用1×1和3×3的线性核来比较结果。
(3)3D 人脸表示
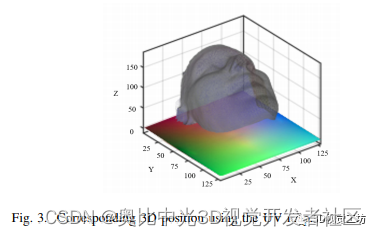
UV空间是从3D空间参数化的2D图像平面,如参考文献[9,5]所提出的. 它可以用来表达三维人脸信息。UV空间用于存储三维面模型中点的三维坐标。因此,x、y和z坐标用于替换纹理贴图中的红色、绿色和蓝色值。因此,位置图可以表示为pos()=(Xi,Yi,Zi),其中i表示面部的第i点的UV坐标,(Xi,Yi,Zi)表示相应的3D位置,如图3所示。建立了基于3DMM[10]的UV坐标系,利用300W-LP[3]提供的3DMM参数的图像,从二维图像到三维信息进行端到端的训练。数据集的3DMM参数基于Basel face model(BFM)[10]。根据BFM提供的顶点数据,选择UV位置图的大小为128*128。因此,可以记录包含语义信息的3D面部顶点集的UV位置图,以端到端的方式训练网络,并且使用固定的面部索引获得3D面部特征点坐标。
4、实验
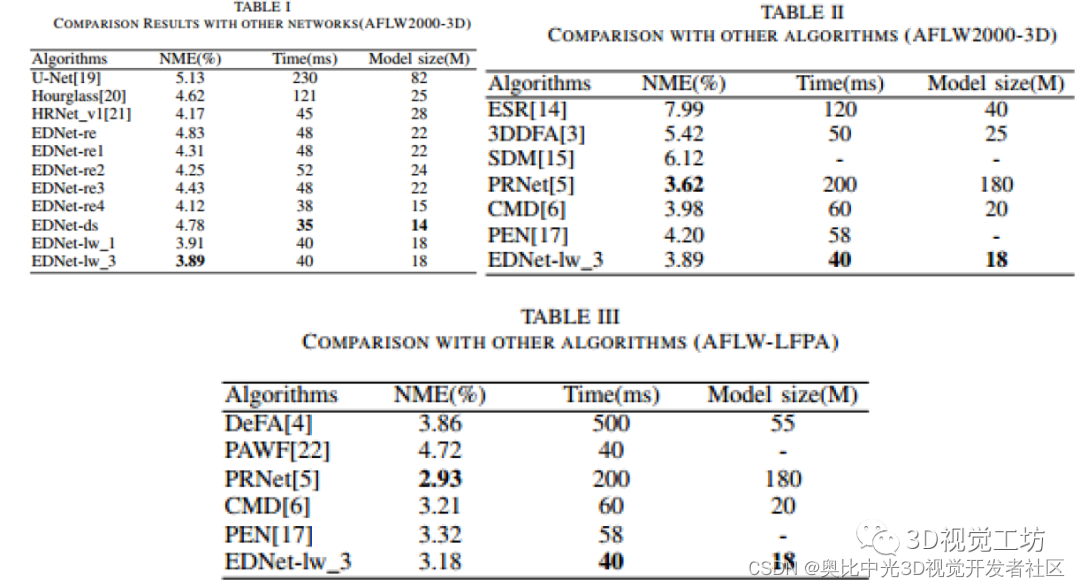
表二显示,与ESR[14]、3DDFA[3]、SDM[15]和CMD[6]相比,该方法在精度和时间消耗方面具有明显的优势。例如,与最新版本的CMD相比,论文的算法将时间消耗提高了30%,并且模型更小。同时,定位精度略高于CMD。与PRNet[5]相比,该算法的平均下降了8%,但是时间消耗缩短了5倍,模型大小减小了10倍。论文的网络使用较小的图像输入尺寸和较少的通道;此外,论文的EF-deconv层使用特征选择,从而让参数数量减少了一半。因此,该算法实现了预测精度和时间消耗之间的平衡。
图5在预测精度和时间消耗方面更直观地示出了不同算法的性能之间的比较。更精确、更快的算法更接近原点。与3DDFA[3]、PEN[17]和CMD[6]相比,本文提出的方法在这两个参数上都具有优势。与PRNet[5]和DAMDNet[19]相比,论文的方法的时间消耗更低,并且可以在CPU上实时运行。
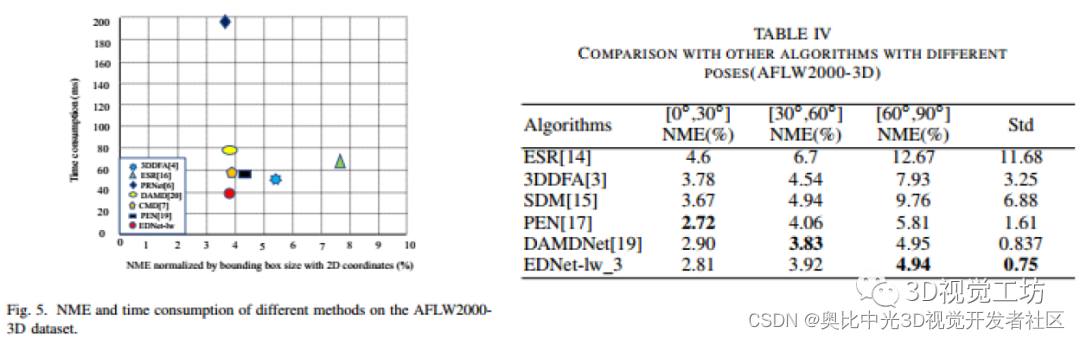
表四列出了不同面部姿势的AFLW2000-3D[3]数据集上不同算法的结果。与PEN[19]相比,该方法对[30°、60°]和[60°、90°]更为准确,误差降低了13-17%。与早期提出的方法(如ESR[14]、SDM[15]和3DDFA[3])相比,该算法在不同的头部姿态下表现出更好的性能。与最近提出的方法(如PEN[17]和DAMDNet[19])相比,该算法具有较小的方差。图4显示了所提出算法的最终预测和人脸重建结果。对不同姿势、表情、阴影和其他因素的测试结果可以清楚地看到,该方法对不同角度的人脸姿态具有较强的鲁棒性。综上所述,该方法可以在CPU上实时运行,实现了快速的三维人脸对齐,能够满足实际应用的要求。

5、结论
该文提出了一种可在CPU上实时运行的三维人脸对齐方法,该方法采用了一种轻量级编解码网络EDNet。在特征解码阶段,通过特征融合和高效的反卷积,实现了网络预测精度和时间消耗的完美平衡,更适用于实际产品中的部署和应用。
作者:宁欣1,2,3,段鹏飞2,3,李卫军1,2,3,张少林2,3 单位信息:
1.中国科学院半导体研究所 高速电路与神经网络实验室;
2.威富集团认知计算技术联合实验室;
3.深圳市威富视界有限公司 文章信息:X. Ning, P. Duan, W. Li and S. Zhang, “Real-Time 3D Face Alignment Using an Encoder-Decoder Network With an Efficient
Deconvolution Layer,” in IEEE Signal Processing Letters, vol. 27, pp.
1944-1948, 2020, doi: 10.1109/LSP.2020.3032277.
本文仅做学术分享,版权归原作者所有,若涉及侵权内容请联系删文。
3D视觉开发者社区是由奥比中光给所有开发者打造的分享与交流平台,旨在将3D视觉技术开放给开发者。平台为开发者提供3D视觉领域免费课程、奥比中光独家资源与专业技术支持。
加入【3D视觉开发者社区】学习行业前沿知识,赋能开发者技能提升!
加入【3D视觉AI开放平台】体验AI算法能力,助力开发者视觉算法落地!
往期推荐:
1、开发者社区「运营官」招募启动啦!_奥比中光3D视觉开发者社区的博客-CSDN博客