1.简介
本文根据2022年8月字节跳动的《Next-ViT: Next Generation Vision Transformer for Effificient Deployment in Realistic Industrial Scenarios 》翻译总结的。
ViT 运行速度慢。为此我们提出了Next-ViT。Next-ViT不仅准率高高于ViT,而且速度也快。
ViT可以参考以前翻译的文章:https://blog.csdn.net/zephyr_wang/article/details/127162110。
Next-ViT是一个CNN-Transformer混合架构。从名字看,Next-ViT名字起的有点大。
Next-ViT:1)引入Next Convolution Block (NCB),其主要捕获视觉数据的短期(局部)依赖信息,采用的Multi-Head Convolutional Attention (MHCA)。 2)建立Next Transformer Block (NTB),其捕获长期(全局)依赖,同时作为一个轻量的从高到低频率信号的混合器来增强模型能力。3)设计了Next Hybrid Strategy (NHS),在每一步来堆叠NCB和NTB,减少了transformer的比例,但保留transformer的高准确率。
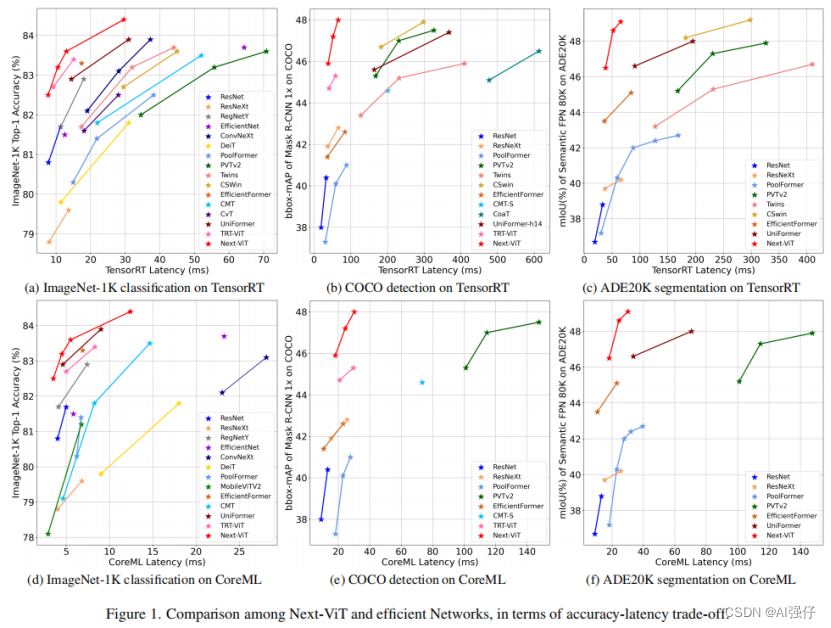
从下图可以看出来,Next-ViT(红色的线),不仅低延迟还准确率高。
2.方法
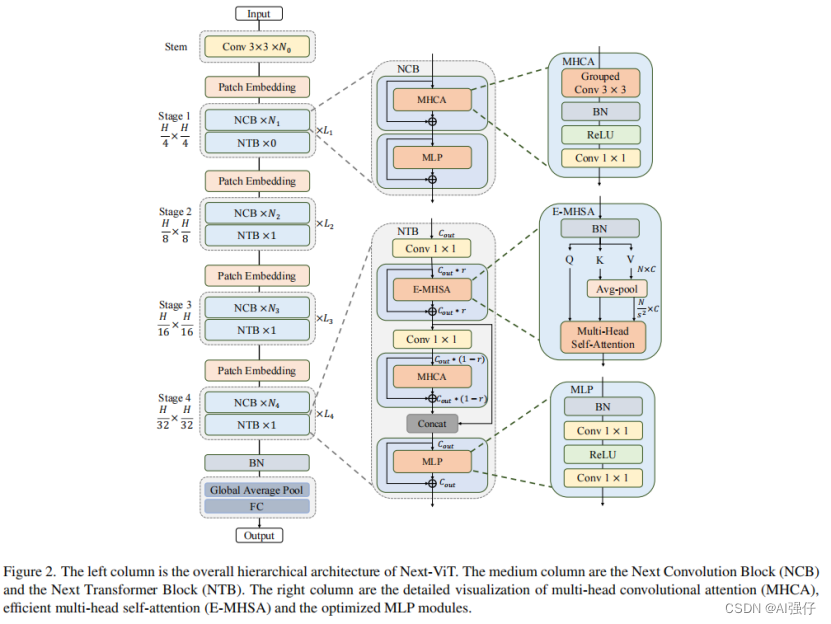
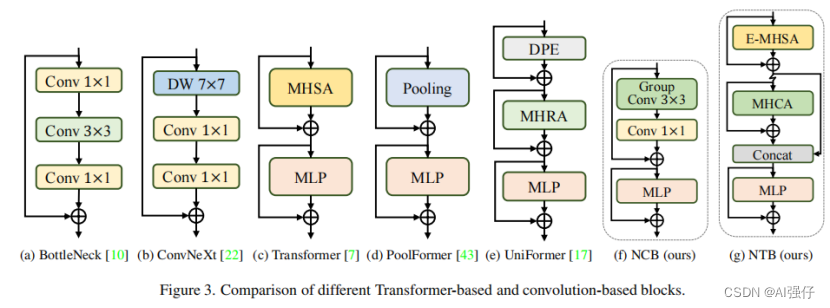
如下图,最左边是Next-ViT的整体架构。同ViT一样,图像经过patch embedding层,输入CNN或者transformer模块。
2.1.Next Convolution Block (NCB)
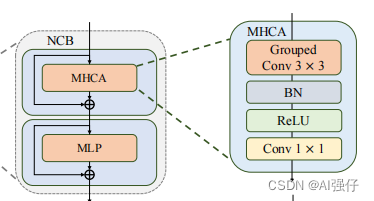
NCB由MHCA 和MLP组成,如下图,其中NCB中的MHCA ,由group convolution (multi-head convolution) 和a point-wise convolution构成,MHCA 详见下节:
公式如下:
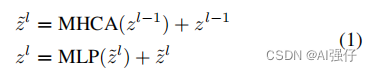
2.1.1.Multi-Head Convolutional Attention (MHCA)
NCB中的MHCA ,由group convolution (multi-head convolution) 和a point-wise convolution构成,如下面的图f。
NCB中使用的BatchNorm (BN) and ReLU activation function ,而不是传统transformer的LayerNorm (LN) and GELU ,以提供计算速度。
公式为:
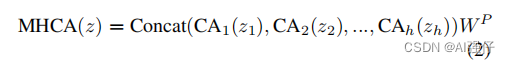
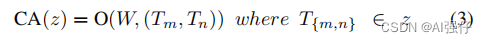

2.2.Next Transformer Block (NTB)
transformer模块可以捕获低频率的信号,其提供全局(global)信息;不过有研究表明transformer模块也许会损坏高频信号,影响local信息。
NTB首先使用Effificient Multi-Head Self Attention(E-MHSA)捕获低频信息,然后使用MHCA捕获高频等信息,接着将E-MHSA和MHCA的信息连接起来,混合高低频信息。
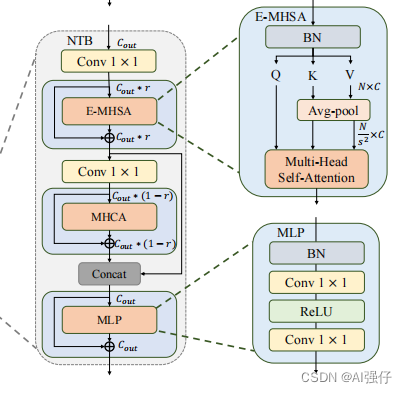
公式如下:

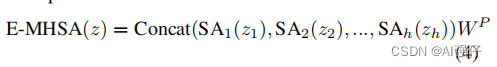
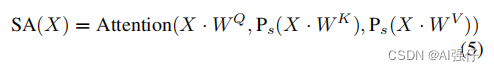
其中,Proj是 point-wise convolution 层。
2.3.Next Hybrid Strategy (NHS)
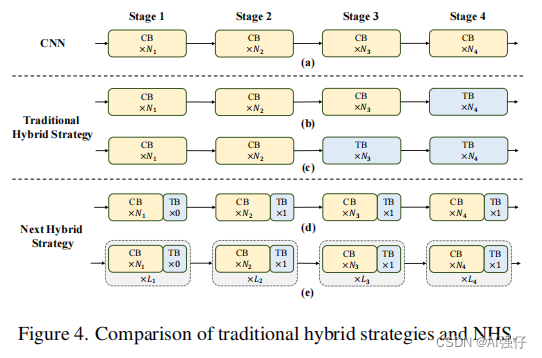
NHS采用NCN * N +NTB * 1 格式,如上图第3个部分d,CB(卷积)和TB(transformer)模块交互使用。
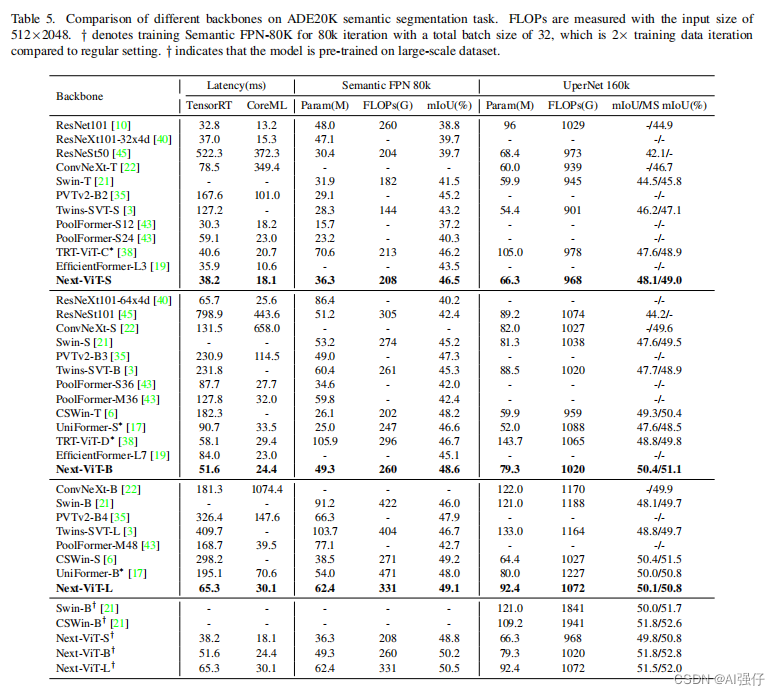
3.实验结果
Next-ViT不仅低延迟还准确率高。
4.Ablation Study
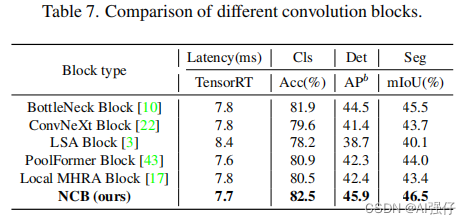
1.研究了NCB和各模块的比较,如下表。
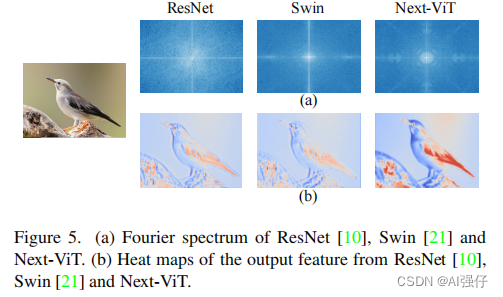
2.如下图,ResNet倾向于捕获高频信号,而对低频信号较困难。ViT(Swin)倾向于捕获低频信号,忽略高频信号。而Next-ViT同时捕获高低频。