数据结构
1. 数据结构(算法)介绍
数据结构是一门研究算法的学科,好的数据结构可以编写出更加漂亮、更加有效率的代码。算法是程序的灵魂。数据结构来源于现实问题。
2. 稀疏数组sparse array
问题引出:
编写五子棋程序中,存在存盘退出和续上盘的功能。
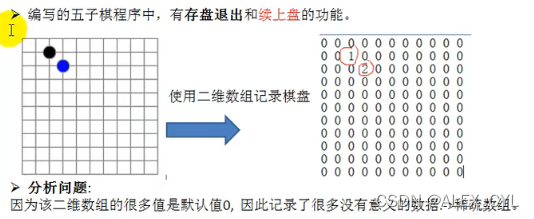
按照原始的二维数组方式记录,很多重复数据(0)没有意义,浪费空间和操作时间
基本介绍:
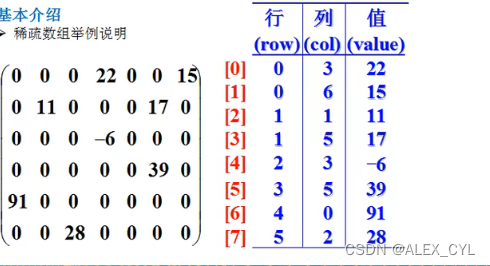
当一个数组中大部分元素为0,或者为同一个值的数组时,可以使用稀疏数组来保存该数组。
稀疏数组的处理方法是:
1.记录原数组几行几列及共性值,与有多少个不同的值
2. 把具有不同值得元素行列及值记录在一个小规模的数组中,从而压缩数据,缩小程序的规模

应用实例
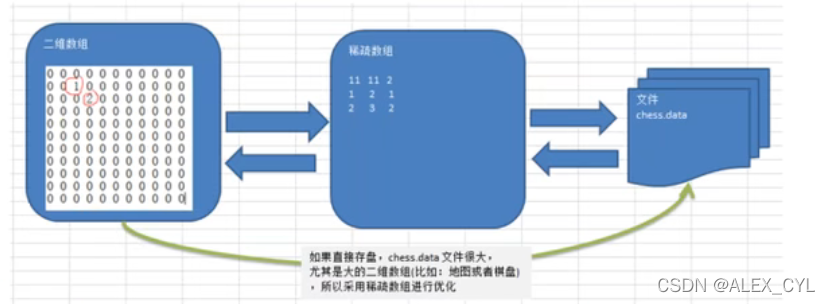
1.使用稀疏数组,来保留类似前面二维数组(棋盘、地图等等)
2.把稀疏数组存盘,并可以重新恢复原来的二维数组
3.整体思路分析
4.代码实现
package main
import (
"bufio"
"fmt"
"io"
"io/ioutil"
"log"
"os"
"strconv"
"strings"
)
type ValNode struct {
row int
col int
val interface{
}
}
func main() {
// 1.先创建一个原始数组
var chessMap [11][11]int
chessMap[1][2] = 1 //黑子
chessMap[2][3] = 2 //白子
// 2.输出原始的数组
for _, v := range chessMap {
for _, v1 := range v {
fmt.Printf("%d\t", v1)
}
fmt.Println()
}
// 3.转成稀疏数组(在golang中,使用切片形式+结构体实现)
//思路
// 1.由于Golang中数组是明确固定大小的的,为达到稀疏数组的效果需使用动态数组切片
// 2.遍历原数组,当发现有元素的值不为零时,创建一个值节点记录行列、值信息
// 3.再将值节点放入切片中
var sparseArray []ValNode
// 标准的稀疏数组,首行需记录员对应二维数组的规模(行列数、以及默认值)
valNode := ValNode{
row: len(chessMap),
col: len(chessMap[0]),
val: 0,
}
sparseArray = append(sparseArray, valNode)
for i, v := range chessMap {
for j, v1 := range v {
if v1 != 0 {
valNode := ValNode{
row: i,
col: j,
val: v1,
}
sparseArray = append(sparseArray, valNode)
}
}
}
//输出稀疏数组
for i, valNode := range sparseArray {
fmt.Printf("index %d:%d %d %d\n", i, valNode.row, valNode.col, valNode.val.(int))
}
//4.将这个稀疏数组,存盘
// 将数据写入文件中 src\go_code\chapter20\sparsearray\chessMap.data
filepath := "E:\\goproject\\src\\go_code\\chapter20\\sparsearray\\chessMap.data"
file, err := os.OpenFile(filepath, os.O_RDWR|os.O_CREATE, 0666)
if err != nil {
log.Fatal(err)
}
// 要及时关闭file句柄
defer file.Close()
writer := bufio.NewWriter(file)
for _, valNode := range sparseArray {
str := fmt.Sprintf("%d %d %d", valNode.row, valNode.col, valNode.val.(int))
writer.WriteString(str + "\r\n")
// writer.WriteString(str)
}
// 因为writer是带缓存的,WriteString方法时
// 写入的数据存放在writer(*bufio.Writer)的缓存切片中
// 因此还需调用Flush方法,将缓冲中的数据写入下层的io.Writer接口
// 实现写的操作
writer.Flush() //如没有此操作,文件将不会更新写入内容
// 查看文件内容
content, err := ioutil.ReadFile(filepath)
if err != nil {
log.Fatal(err)
}
fmt.Printf("文件chessMap.data内容:\n%s", content)
// 5.恢复原数组
// 5.1从文件中取出数据 =>恢复原始数组
file, err = os.Open("E:\\goproject\\src\\go_code\\chapter20\\sparsearray\\chessMap.data")
if err != nil {
fmt.Println("open file err :", err)
}
// 开一个文件,一般后直接使用defer方法,当函数退出后及时关闭文件
defer func() {
err = file.Close()
if err != nil {
fmt.Println("close file err :", err)
} else {
fmt.Println("file closes successfully")
}
}() //使用defer+匿名函数方法及时关闭file句柄,否则会有内存泄漏
var newChessMap [][]int
reader1 := bufio.NewReader(file)
for {
str, err := reader1.ReadString('\n') //读取到换行符时结束
if err == io.EOF {
fmt.Println("`````") //io.EOF表示文件的末尾
break
}
str = strings.Trim(str, "\r\n")
strslice := strings.Split(str, " ")
row1, _ := strconv.ParseInt(strslice[0], 10, 64)
col1, _ := strconv.ParseInt(strslice[1], 10, 64)
val1, _ := strconv.ParseInt(strslice[2], 10, 64)
if val1 == 0 {
for i := 0; i < int(row1); i++ {
var rowslice []int
for j := 0; j < int(col1); j++ {
rowslice = append(rowslice, 0)
}
newChessMap = append(newChessMap, rowslice)
}
continue
}
newChessMap[int(row1)][int(col1)] = int(val1)
}
for _, v := range newChessMap {
for _, v1 := range v {
fmt.Printf("%d\t", v1)
}
fmt.Println()
}
}
3. 队列 queue
场景引出:
银行排队系统
队列介绍:
- 队列是一个有序列表,可以用环形数组或是链表来实现
- 遵循先入先出的原则
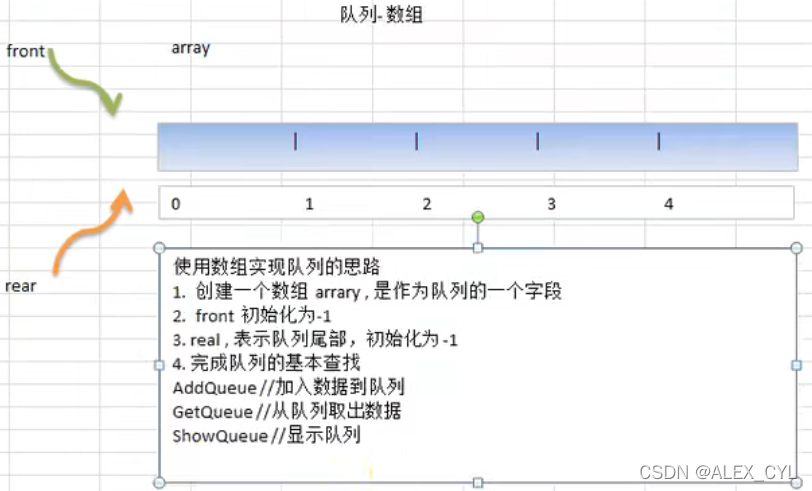
3.1 数组模拟队列思路
- 队列本身是有序列表,若使用数组的结构来储存队列的数据,则队列数组的声明如下,其中
MaxSize是该队列的最大容量。 - 由于队列的输出和输入分别是从前后端来处理,因此需要两个变量
front和rear分别记录队列的前后端的下标,front会随着数据的输出而改变,rear则是随着输入而改变。当front == rear时表示该队列为空。(front指向头部但不包含头部数据)

先完成一个非环形的队列: - 当数据存入队列时被称为
addqueue,addqueue的处理需要两个步骤:
1) 将尾指针往后移:rear+1,
2) 若尾指针rear小于或等于队列的最大下标MaxSize-1,则表示数据存放成功,且存入在rear所指的数组元素中,否责无法存入数据。当rear==MaxSize-1时,表示队列满。
思路分析:
代码实现:
package main
import (
"errors"
"fmt"
"os"
)
// 使用一个结构体管理队列
type Queue struct {
maxSize int //队列最大容量
array [5]int //数组=> 模拟队列
front int //表示指向队首 初始为-1 指向队首但不包含队首的元素
rear int //表示指向队尾 初始为-1 是指向队尾含有最后一个元素
}
//为Queue结构体绑定方法实现,队列功能
//1.添加数据
func (queue *Queue) AddQueue(val int) error {
// 先判断队列是否已经满了
if queue.rear == queue.maxSize-1 {
//重要提示,rear是指向队尾(并且含有最后一个元素)
return errors.New("queue full")
}
// 能添加数据,则尾部指针rear往后移一位
queue.rear++
queue.array[queue.rear] = val
return nil
}
//1.环形数组 添加数据
func (queue *Queue) NewAddQueue(val int) error {
// 先判断队列是否已经满了
//队列容量是确定的,即尾部指针和首部指针的差为该队列当前含有的元素个数
if queue.rear-queue.front == queue.maxSize {
return errors.New("queue full")
}
// 能添加数据,则尾部指针rear往后移一位
queue.rear++
index := queue.rear % queue.maxSize //循环使用数组
queue.array[index] = val
return nil
}
// 2. 显示队列,找到队首,然后遍历到队尾
func (queue *Queue) ShowQueue() {
// front 在此设计中指向队首但不包含队首的元素
fmt.Println("队列当前情况是:")
for i := queue.front + 1; i <= queue.rear; i++ {
fmt.Printf("array[%d]=%d\n", i, queue.array[i])
}
}
// 2.循环数组 显示队列,找到队首,然后遍历到队尾
func (queue *Queue) NewShowQueue() {
// front 在此设计中指向队首但不包含队首的元素
fmt.Println("队列当前情况是:")
for i := queue.front + 1; i <= queue.rear; i++ {
fmt.Printf("array[%d]=%d\n", i%queue.maxSize, queue.array[i%queue.maxSize])
}
}
// 3.从队列取出数据
func (queue *Queue) GetQueue() (int, error) {
// 先判断队列是否为空
if queue.front == queue.rear {
return -1, errors.New("queue empty")
}
queue.front++
val := queue.array[queue.front]
// fmt.Println("推出数据val=", val)
return val, nil
}
// 3.循环数组从队列取出数据
func (queue *Queue) NewGetQueue() (int, error) {
// 先判断队列是否为空
if queue.front == queue.rear {
return -1, errors.New("queue empty")
}
queue.front++
index := queue.front % queue.maxSize
val := queue.array[index]
// fmt.Println("推出数据val=", val)
return val, nil
}
func main() {
queue := &Queue{
maxSize: 5,
front: -1,
rear: -1,
}
var (
key string
val int
)
for {
fmt.Println("1. 输入add表示添加数据到队列")
fmt.Println("2. 输入get表示从队列获取数据")
fmt.Println("3. 输入show表示显示队列")
fmt.Println("4. 输入exit表示退出")
fmt.Scanln(&key)
switch key {
case "add":
fmt.Println("输入入队元素值")
fmt.Scanln(&val)
err := queue.NewAddQueue(val)
if err != nil {
fmt.Println(err.Error())
} else {
fmt.Println("加入队列成功")
}
case "get":
val, err := queue.NewGetQueue()
if err != nil {
fmt.Println(err.Error())
} else {
fmt.Println("推出数据val=", val)
}
case "show":
queue.NewShowQueue()
case "exit":
os.Exit(0)
}
}
}
环形结构:
package main
import (
"errors"
"fmt"
"os"
)
// 使用一个结构体管理环形队列
type CircleQueue struct {
maxSize int
arrary [5]int //数组
head int //指向队列首 初始值为0 指向并包含队首元素
tail int //指向队尾 初始值为0 指向但不包含队尾巴元素
}
// 入队列
func (cq *CircleQueue) Push(val int) error {
if cq.IsFull() {
return errors.New("queue full")
}
cq.arrary[cq.tail] = val
cq.tail = (cq.tail + 1) % cq.maxSize //tail 在队尾但不包含最后的元素
return nil
}
// 出队列
func (cq *CircleQueue) Pop() (int, error) {
if cq.IsEmpty() {
return -1, errors.New("queue EMPTY")
}
val := cq.arrary[cq.head]
cq.head = (cq.head + 1) % cq.maxSize
return val, nil
}
// 判断环形队列为满
func (cq *CircleQueue) IsFull() bool {
return (cq.tail+1)%cq.maxSize == cq.head
}
// 判断环形队列空
func (cq *CircleQueue) IsEmpty() bool {
return cq.tail == cq.head
}
// 取出环形列表有多少个元素
func (cq *CircleQueue) Size() int {
// 关键点
return (cq.tail + cq.maxSize - cq.head) % cq.maxSize
}
// 显示队列信息
func (cq *CircleQueue) Show() {
// 取出当前队列有多少个元素
size := cq.Size()
if size == 0 {
fmt.Println("队列为空")
}
fmt.Println("队列当前信息:")
for i := cq.head; i < size; i++ {
index := i % cq.maxSize
fmt.Printf("arr[%d]=%d\n", index, cq.arrary[index])
}
}
func main() {
queue := &CircleQueue{
maxSize: 5,
head: 0,
tail: 0,
}
var (
key string
val int
)
for {
fmt.Println("1. 输入add表示添加数据到队列")
fmt.Println("2. 输入get表示从队列获取数据")
fmt.Println("3. 输入show表示显示队列")
fmt.Println("4. 输入exit表示退出")
fmt.Scanln(&key)
switch key {
case "add":
fmt.Println("输入入队元素值")
fmt.Scanln(&val)
err := queue.Push(val)
if err != nil {
fmt.Println(err.Error())
} else {
fmt.Println("加入队列成功")
}
case "get":
val, err := queue.Pop()
if err != nil {
fmt.Println(err.Error())
} else {
fmt.Println("推出数据val=", val)
}
case "show":
queue.Show()
case "exit":
os.Exit(0)
}
}
}
4. 链表
链表的基本介绍
链表是有序的列表,其存储的元素的地址可以是无序的,因为其明确的下一个元素的地址指向。
相较而言,数组的存储的元素,地址是连续的,这是由于数组的数据查询,基于头地址(第一个元素的地址)根据数据类型占字节大小,递增寻找下一个元元素的地址。
链表在内存中的存储如下:
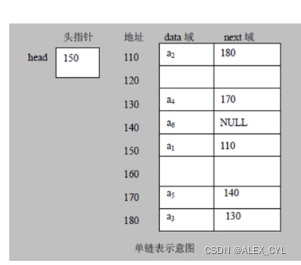
1. 单向链表的介绍
单链表示意图

在Go中,结构体是值类型,故链表元素间的传递,中间会先指向“地址”,再指向“地址”所指向的值空间。
一般情况下,为了较好的对单链表进行增删改查的操作,都会设计头节点。
头节点的主用:用来表示链表的头,本身该节点不存放数据。
代码实现:
package main
import "fmt"
// 创建一个结构体管理链表
type HeroNode struct {
no int //第几个节点
name string //节点内容
nicname string //节点内容
next *HeroNode //指向下一个节点
}
// 给链表插入一个节点
// 编写第一种插入方法,在单链表的最后插入
func InsertHeroNode(head, newHeroNode *HeroNode) {
// 思路
// 1,先找到该链表的最后节点
// 2.由于头节点十分重要,轻易不要动用,故创建一个辅助节点【跑龙套,帮忙】
temp := head
for {
if temp.next == nil {
//链表到最后节点了
// 将新的节点加入到链表的最后
temp.next = newHeroNode
break
}
temp = temp.next
}
}
// 编写第二种插入方法,根据节点的no字段大小顺序插入
func InsertHeroNodeByno(head, newHeroNode *HeroNode) {
// 创建辅助节点
temp := head
for {
if temp.next == nil {
//节点到最后了
break
} else if temp.next.no <= newHeroNode.no {
//节点按照no降序排序,
// 相同大小的no节点后插入的,排在前面
//从顺序排序 则temp.next.no >= newHeroNode.no,
break
}
temp = temp.next
}
newHeroNode.next = temp.next
temp.next = newHeroNode
}
//删除某个节点
func deleteHeroNode(head *HeroNode, no int) {
temp := head
for {
if temp.next == nil {
fmt.Println("该节点不存在")
return
}
if temp.next.no == no {
break
}
temp = temp.next
}
temp.next = temp.next.next
}
// 从链表中获取信息
func getHeroNode(head *HeroNode) {
temp := head
heroNode := HeroNode{
}
if temp.next == nil {
fmt.Println("链表为空")
return
}
heroNode = *temp.next
//并删除链表中的该节点
deleteHeroNode(head, heroNode.no)
}
func ListHeroNode(head *HeroNode) {
// 1.仍然创建一个辅助节点
temp := head
// 先判断链表是否为空
if temp.next == nil {
fmt.Println("链表为空")
return
}
for {
temp = temp.next
fmt.Printf("[%d,%s,%s] ==>", temp.no, temp.name, temp.nicname)
if temp.next == nil {
break
}
}
}
func main() {
// 1.先创建一个头节点
head := HeroNode{
}
head1 := HeroNode{
}
// 2.链表中创建新的节点
Hero1 := HeroNode{
no: 1,
name: "宋江",
nicname: "及时雨",
}
Hero2 := HeroNode{
no: 2,
name: "吴庸",
nicname: "智多星",
}
Hero3 := HeroNode{
no: 3,
name: "林聪",
nicname: "豹子头",
}
Hero4 := HeroNode{
no: 3,
name: "卢俊义",
nicname: "九纹龙",
}
//3.添加
InsertHeroNode(&head, &Hero1)
InsertHeroNode(&head, &Hero2)
InsertHeroNode(&head, &Hero3)
InsertHeroNodeByno(&head1, &Hero2)
InsertHeroNodeByno(&head1, &Hero3)
InsertHeroNodeByno(&head1, &Hero1)
InsertHeroNodeByno(&head1, &Hero4)
// 4.显示
ListHeroNode(&head)
fmt.Println()
ListHeroNode(&head1)
fmt.Println()
// [1,宋江,及时雨] ==>
// [3,卢俊义,九纹龙] ==>[3,林聪,豹子头] ==>[2,吴庸,智多星] ==>[1,宋江,及时雨] ==>
// 由于节点含有的next为引用类型,且HeroNode绑定的方法全是指针类型,
// 故对链表内容(元素next字段)的修改会直接修改到链表中元素的实际内容
// 5.删除
deleteHeroNode(&head1, 1)
deleteHeroNode(&head1, 3)
ListHeroNode(&head1)
// [3,林聪,豹子头] ==>[2,吴庸,智多星] ==>
}
2. 链表构成队列结构:
使用上述构建的getHeroNode()和InsertHeroNode()方法即可以实现队列结构的功能。
3. 双向链表介绍
1)单向链表,查找的方向只能是从单向的(从头到尾),双向链表则是可以从前或者从后查找
2)单向链表不能自我删除,需要靠辅助节点找到相应的待删除的节点;双向链表可以实现自我删除。
代码实现:
package main
import "fmt"
type HeroNode struct {
no int //第几个节点
name string //节点内容
nicname string //节点内容
next *HeroNode //指向下一个节点
pre *HeroNode //指向前一个节点
}
//给双向链表插入一个节点
//编写第一种插入方法,在双向链表尾巴加入
func InsertHeroNode(head, newHeroNode *HeroNode) {
temp := head
// 找到最后的节点
for {
if temp.next == nil {
temp.next = newHeroNode
newHeroNode.pre = temp
break
}
temp = temp.next
}
}
// 编写第二种插入方法,根据节点的no字段大小顺序插入
func InsertHeroNodeByno(head, newHeroNode *HeroNode) {
// 创建辅助节点
temp := head
for {
if temp.next == nil {
//节点到最后了
break
} else if temp.next.no <= newHeroNode.no {
//节点按照no降序排序,
// 相同大小的no节点后插入的,排在前面
//从顺序排序 则temp.next.no >= newHeroNode.no,
break
}
temp = temp.next
}
newHeroNode.next = temp.next
newHeroNode.pre = temp
temp.next = newHeroNode
if temp.next != nil {
//在最后增加
temp.next.pre = newHeroNode
}
}
//删除某个节点
func deleteHeroNode(head *HeroNode, no int) {
temp := head
for {
if temp.next == nil {
fmt.Println("该节点不存在")
return
}
if temp.no == no {
break
}
temp = temp.next
}
temp.pre.next = temp.next
if temp.next != nil {
//删除最后一个节点
temp.next.pre = temp.pre
}
}
//从前往后显示
func ListHeroNode(head *HeroNode) {
// 1.仍然创建一个辅助节点
temp := head
// 先判断链表是否为空
if temp.next == nil {
fmt.Println("链表为空")
return
}
for {
temp = temp.next
fmt.Printf("[%d,%s,%s] ==>", temp.no, temp.name, temp.nicname)
if temp.next == nil {
break
}
}
}
//从后往前显示
func ListHeroNode1(head *HeroNode) {
// 1.仍然创建一个辅助节点
temp := head
// 先判断链表是否为空
if temp.next == nil {
fmt.Println("链表为空")
return
}
for {
temp = temp.next
if temp.next == nil {
break
}
}
for {
fmt.Printf("[%d,%s,%s] ==>", temp.no, temp.name, temp.nicname)
temp = temp.pre
if temp.pre == nil {
break
}
}
}
func main() {
head := &HeroNode{
}
Hero1 := &HeroNode{
no: 1,
name: "宋江",
nicname: "及时雨",
}
Hero2 := &HeroNode{
no: 2,
name: "吴庸",
nicname: "智多星",
}
Hero3 := &HeroNode{
no: 3,
name: "林聪",
nicname: "豹子头",
}
Hero4 := &HeroNode{
no: 3,
name: "卢俊义",
nicname: "九纹龙",
}
InsertHeroNode(head, Hero1)
InsertHeroNode(head, Hero2)
InsertHeroNode(head, Hero3)
InsertHeroNode(head, Hero4)
// 从后往前显示
ListHeroNode1(head)
fmt.Println()
deleteHeroNode(head, 3)
ListHeroNode(head)
}
4. 环形链表
创建单方向环形链表时,为了便于管理,仍采用head头部的概念,但该head本身也存储数据。
由于环形列表实际上没有头部的概念,为了便于管理增加head指代。与单链表的head不包含内容不会被删除不同,循环链表的任何节点都是可以被删除的。因此,在实现删除环形链表中某个值节点时,需特别注意该节点是否为指定的head,若是需要返回新的head指代节点,负责main栈中的head还是指向被删除的值节点,往后不能再通过main栈中的head对循环链表实现CRUD操作了。
示意图
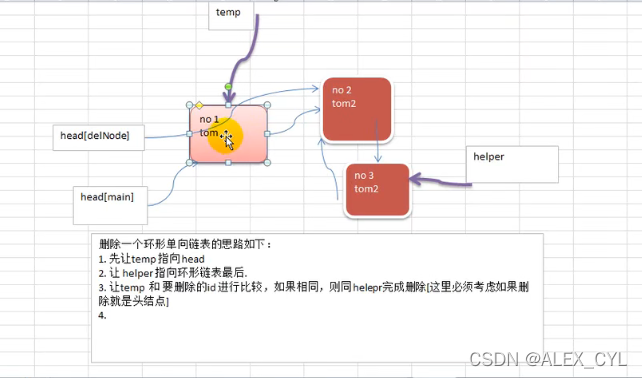
package main
import (
"errors"
"fmt"
)
type catNode struct {
no int
name string
next *catNode
}
func InsertcatNode(head, newcatNode *catNode) {
//与单链表带头方式不同处:
// 单链表的头部不存放数据,只是next 指向下一个 值节点的地址空间
// 循环列表实则上没有头部的概念,因为处处都可以为头,但为了初始化(创建和管理的需求)
// 使用头节点的思想,但在循环列表中头节点也等价于值节点,即头节点也存放数据
//先判断该循环链表是否为空
if head.next == nil {
head.no = newcatNode.no
head.name = newcatNode.name
head.next = head //构建循环
return
}
temp := head
for {
// 找到最后的节点
if temp.next == head {
break
}
temp = temp.next
}
temp.next = newcatNode
newcatNode.next = head //形成循环
}
func ListCircleLink(head *catNode) {
fmt.Println("循环列表情况如下:")
temp := head
if temp.next == nil {
fmt.Println("该循环列表为空")
return
}
for {
fmt.Printf("cat的信息为=[no:%d name:%s] ->", temp.no, temp.name)
if temp.next == head {
fmt.Printf("cat的信息为=[no:%d name:%s]\n", head.no, head.name)
break
}
temp = temp.next
}
}
//删除
func DelcatNode(head *catNode, id int) (*catNode, error) {
//创建两个辅助节点
temp := head
helper := head
// helper指向最后的节点
for {
if helper.next == head {
break
}
helper = helper.next
}
// helper指向最后节点 和 temp指向头节点 便于单循环连边的删除操作
// 判断是否为空链表
if temp.next == nil {
return head, errors.New("head 没指向一个链表")
}
//如果只有一个节点
if temp.next == head {
if temp.no == id {
temp.next = nil
}
return head, nil
}
//如果含有多个节点
for {
if temp.no == id {
if temp == head {
head = temp.next
}
helper.next = temp.next
return head, nil
}
if temp.next == head {
//达到最后节点
return head, errors.New("del failed ")
}
temp = temp.next
helper = helper.next
}
}
func main() {
head := &catNode{
}
catNode1 := &catNode{
no: 1,
name: "tom",
}
catNode2 := &catNode{
no: 2,
name: "jarry",
}
catNode3 := &catNode{
no: 3,
name: "curry",
}
InsertcatNode(head, catNode1)
InsertcatNode(head, catNode2)
InsertcatNode(head, catNode3)
ListCircleLink(head)
// ListCircleLink(catNode2)
// head, err := DelcatNode(head, 1)
// head, err := DelcatNode(head, 2)
head, err := DelcatNode(head, 10)
ListCircleLink(head)
fmt.Println("err=", err)
}
Josephu问题:
设编号为1,2,… n的n个人围坐一圈,约定编号为k (1<=k<=n)的人从1开始报数,数到m的那个人出列,它的下一位又从1开始报数,数到m的那个人又出列,依次类推,直到所有人出列为止,由此产生一个出队编号的序列。
提示:
用一个不带头结点的循环链表来处理Josephu问题,先构成一个有n个结点的单循环链表,然后由k结点起从1开始计数,计到m时,对应结点从链表中删除,然后再从被删除结点的下一个结点又从1开始计数,直到最后一个结点从链表中删除算法结束。
package main
import "fmt"
//值节点结构体
type ValNode struct {
no int //编号
next *ValNode //指向下一个值节点的指针
}
// 构建单循环环形链表
func constructorCricleLink(n int) *ValNode {
//链表的值节点个数,返回循环链表的一个指代头节点
head := &ValNode{
}
for i := 1; i <= n; i++ {
newValNote := &ValNode{
no: i,
}
addVlaNote(head, newValNote)
}
return head
}
// 添加环形链表的值节点
func addVlaNote(head, newValNote *ValNode) {
if head.next == nil {
head.no = newValNote.no
head.next = head //构建循环
return
}
temp := head
for {
if temp.next == head {
break
}
temp = temp.next
}
temp.next = newValNote
newValNote.next = head
}
//删除环形链表中的值
func pushNote(head *ValNode, n, m int) []int {
intSort := make([]int, 0)
temp := head
helper := head
for {
if helper.next == head {
break
}
helper = helper.next
}
//n==0
if temp.next == nil {
fmt.Println("链表为空")
return intSort
}
//n==1
if temp.next == head {
temp.next = nil
intSort = append(intSort, temp.no)
return intSort
}
// n >=2
for {
if temp.next == temp {
intSort = append(intSort, temp.no)
temp.next = nil
break
}
// if i%n != 0 {
// continue
// }
for j := 1; j < m; j++ {
temp = temp.next
helper = helper.next
}
intSort = append(intSort, temp.no)
helper.next = temp.next
temp = temp.next
}
return intSort
}
//暴力法
func JosePhu(m, n int) []int {
numSort := make([]int, 0) //m =5 n=2
for i := n; i <= m*n; {
//
if i%n == 0 {
index := (i - 1) % m
numSort = append(numSort, index+1)
// head = delValNote(head, index)
}
i += n
}
return numSort
}
func ListCircleLink(head *ValNode) {
fmt.Println("循环列表情况如下:")
temp := head
if temp.next == nil {
fmt.Println("该循环列表为空")
return
}
for {
fmt.Printf("cat的信息为=[no:%d] ->", temp.no)
if temp.next == head {
fmt.Printf("cat的信息为=[no:%d]\n", head.no)
break
}
temp = temp.next
}
}
func main() {
// 输入n=5 间隔m=2
head := constructorCricleLink(5) //输入n=5
ListCircleLink(head)
s := pushNote(head, 5, 2)
fmt.Println(s)
// numSort := make([]int, 5)
// for i := 1; i <= 10; i++ {
// if i%2 == 0 {
// index := i % 5
// numSort = append(numSort, index)
// head = delValNote(head, index)
// }
// }
}
5. 排序
排序介绍
排序是将一组数据,依指定的顺序进行排列的过程。
排序的分类:
1)内部排序:
将所需要处理的所有数据都加载到内部存储器中进行排序。包括:交换式排序法、选择式排序法和插入式排序法
2)外部排序:
数据量过大时,无法全部加载到内存中,需要借助外部存储器进行排序。有:合并排序法 和 直接合并排序法
交换式排序法
运用数据比较后,以判断规则对数据位置进行交换,以达到排序的目的。
交换式排序法又可分为:
1)冒泡排序法(Bubble sort)
2)快速排序法(Quick sort)
排序速度:冒泡<选择<插入<快速
- 1.冒泡排序
- 2.选择排序
- 3.插入排序
- 4.快速排序
1.冒泡排序
冒泡排序:
1)通过对待排序序列从后向前(从下标较大的元素开始),一次比较相邻元素的排序码,若发现逆序则交换,是排序码较小的元素从后部向前部(从下标较大的单元移向下标较小的单元),就像水底的下的气泡一样逐渐向上冒。
2)排序的过程中,各元素不断接近自己的位置,如果一趟比较下来没有进行过交换,说明序列有序,因此要在排序过程中设置一个标识flag判断元素是否进行过交换。从而减少不必要的比较。(优化)
//冒泡法:分为轮次和每轮的交换次数,两者的关系为 第几轮+该轮交换次数 = 数组长度
//从后往前
func bubbleSort(slice []int) {
for i := 1; i < len(slice); i++ {
//总轮数= 数组长度-1
temp := 0
flag := 0
for j := len(slice) - 1; j >= i; j-- {
//表示第i论时的j次交换 i + j = 5
if slice[j] < slice[j-1] {
temp = slice[j]
slice[j] = slice[j-1]
slice[j-1] = temp
flag++
}
}
if flag == 0 {
switch i {
case 1:
fmt.Println("本身有序")
default:
fmt.Printf("第%v轮完成排序\n", i-1)
}
break
}
}
fmt.Println("排序后:", slice)
}
//从前往后
func bubbleSort1(slice []int) {
for i := 1; i < len(slice); i++ {
//总轮数= 数组长度-1
temp := 0
flag := 0
for j := 0; j < len(slice)-i; j++ {
//表示第i论时的j次交换 i + j = 5
if slice[j] > slice[j+1] {
temp = slice[j]
slice[j] = slice[j+1]
slice[j+1] = temp
flag++
}
}
if flag == 0 {
switch i {
case 1:
fmt.Println("本身有序")
default:
fmt.Printf("第%v轮完成排序\n", i-1)
}
break
}
}
fmt.Println("从前向后~排序后:", slice)
}
func main() {
intArr := [5]int{
1, 15, 29, 8, 16}
slice := intArr[:]
fmt.Println("slice排序前:", slice) //slice排序前: [1 15 29 8 16]
bubbleSort(slice) //排序后: [1 8 15 16 29]
fmt.Println("-------------")
bubbleSort1(slice) //本身有序 从前向后~排序后: [1 8 15 16 29]
fmt.Println("intArr排序后:", intArr) //intArr排序后: [1 8 15 16 29]
}
Output
slice排序前: [1 15 29 8 16]
第2轮完成排序
排序后: [1 8 15 16 29]
本身有序
从前向后~排序后: [1 8 15 16 29]
intArr排序后: [1 8 15 16 29]
2.选择排序
选择排序(select sorting):
基本思想:按指定的规则选取数组中某一元素(一般选取数组中最小值/最大值),经过和其他元素重整,再依原则交换位置后达到排序的目的。一般经过n-1次交换即可得到有序序列。

package main
import "fmt"
// selectsort
//从小到大
func SelectSort(arr []int) {
for i := 0; i < len(arr)-1; i++ {
//交换轮次 len(arr)-1 每轮换一次
regular := arr[i]
regularIndex := i
for j := i + 1; j < len(arr); j++ {
if regular > arr[j] {
regularIndex = j
regular = arr[j]
}
}
if regularIndex == i {
//比较比交换操作时间更短
continue //表示当前值即为此轮的最小值
}
arr[regularIndex] = arr[i]
arr[i] = regular
}
}
func main() {
arr := []int{
10, 21, 13, 4, 55}
SelectSort(arr)
fmt.Println(arr)
}
3.插入排序
插入排序(insert sorting):
基本思想:把n个待排序的元素看成为一个有序表和无序表,开始是有序表中中包含一个元素,无无序表中包含n-1个元素,排序过程中每次从无序表中取出一个元素,把它的排序码依次与有序表的排序码进行比较,将它插入到合适的位置,使之成为有序表。
package main
import "fmt"
func insertSort(intslice []int) {
for i := 1; i < len(intslice); i++ {
// 第二个元素开始比较,一共len(n-1)轮
insertVal := intslice[i]
insertIndex := i - 1 //首先要比较的是要插入的前一个元素
for insertIndex >= 0 && intslice[insertIndex] > insertVal {
//从小到大排序
intslice[insertIndex+1] = intslice[insertIndex] //数据往右(后)移
insertIndex--
}
// 插入
if insertIndex+1 != i {
//加快效率,应对插入值本身是在该index+1处的情况
intslice[insertIndex+1] = insertVal
}
fmt.Printf("第%d次插入后%v\n", i, intslice)
}
}
func main() {
intslice := []int{
50, 12, 64, 1, 34, 27}
insertSort(intslice)
fmt.Println("main():")
fmt.Println("intslice=", intslice)
}
OutPut
第1次插入后[12 50 64 1 34 27]
第2次插入后[12 50 64 1 34 27]
第3次插入后[1 12 50 64 34 27]
第4次插入后[1 12 34 50 64 27]
第5次插入后[1 12 27 34 50 64]
main():
intslice= [1 12 27 34 50 64]
4.快速排序
快速排序(quick sorting):
基本思想:通过一趟排序将要排序的数据划分成独立的两个部分,其中一部分的所有数据都比另外一部分的都要小或者大,然后按照此方法对这两部分的数据分别进行排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
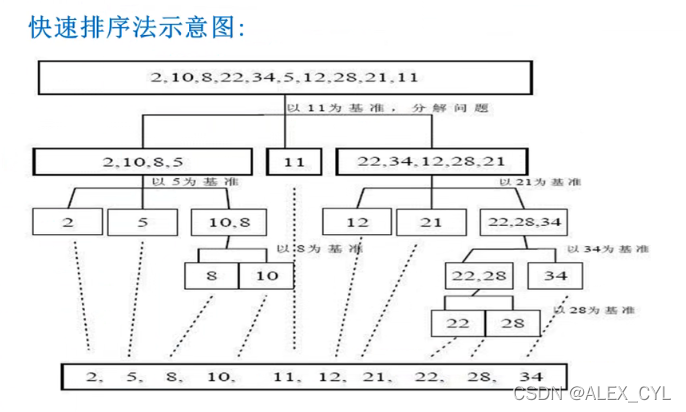
package main
import "fmt"
func QuickSort(left, right int, intslice []int) {
l := left
r := right
// pivot 是中轴,支点
pivot := intslice[(l+r)/2]
temp := 0
// for循环的目的是
// 将比pivot小的数放到左边
// 将比pivot大的数放到右边
for l < r {
//二分法的应用
//从 pivot的左边找到一个比它大的数
for intslice[l] < pivot {
l++
}
// 再从pivot的右边找到一个比它小的数
for intslice[r] > pivot {
r--
}
//交换
// 如果此时切片中刚好pivot值的前面元素都小于它自己
// pivot值的前面元素都大于它自己,则不需交换
if l >= r {
break
}
temp = intslice[l]
intslice[l] = intslice[r]
intslice[r] = temp
if intslice[l] == pivot {
r--
}
if intslice[r] == pivot {
l++
}
fmt.Println(intslice)
}
if l == r {
l++
r--
}
if left < r {
QuickSort(left, r, intslice)
}
if right > l {
QuickSort(l, right, intslice)
}
}
func main() {
intslice := []int{
0, 14, 2, 13, 15, 3, 1}
QuickSort(0, len(intslice)-1, intslice)
}
5.堆排序
最快的效率找到最大值
但用于数组排序速度和冒泡效率相似
使用完全二叉树的理论,将数组元素的序号按照二叉树的模式排列,当知道其中一个节点的索引下标,即可知道其左右子节点的下标(关系:节点a[n],左子节点a[2*n+1],右节点a[2*n+2]);三者中选取最大值,再同理向根节点推送,最后得到最大值。
func HeapSort(s []int) []int {
length := len(s)
for i := 0; i < length-1; i++ {
PerLength := length - i
depth := PerLength/2 - 1
for j := depth; j >= 0; j-- {
topmaxid := j
leftchild := 2*j + 1
rightchild := 2*j + 2
if leftchild < PerLength && s[leftchild] > s[topmaxid] {
topmaxid = leftchild
}
if rightchild < PerLength && s[rightchild] > s[topmaxid] {
topmaxid = rightchild
}
if topmaxid != j {
s[j], s[topmaxid] = s[topmaxid], s[j]
}
}
s[0], s[PerLength-1] = s[PerLength-1], s[0]
}
return s
}
package main
import "fmt"
func HeapSort(s []int) []int {
length := len(s)
for i := 0; i < length-1; i++ {
lastmesslen := length - i // 每次截取一段
HeapSortMax(s, lastmesslen)
fmt.Println(s)
s[0], s[lastmesslen-1] = s[lastmesslen-1], s[0] //将每轮的最大值放在每轮的最后处
fmt.Println("ex", s)
}
return s
}
func HeapSortMax(s []int, length int) []int {
if length <= 1 {
return s
} else {
depth := length/2 - 1 //深度(最后一个三节点组的节点下标=所有的三节点组的数量+1),
// n ,左子节点2*n+1 ,右2*n+2
for i := depth; i >= 0; i-- {
//循环所有的三节点
topmaxid := i //假定最大值在i的位置
leftchild := 2*i + 1
rightchild := 2*i + 2
//防止越界,记录最大值
if leftchild < length && s[leftchild] > s[topmaxid] {
topmaxid = leftchild
}
if rightchild < length && s[rightchild] > s[topmaxid] {
topmaxid = rightchild
}
if topmaxid != i {
// 比较耗时小于交换
s[i], s[topmaxid] = s[topmaxid], s[i]
}
}
}
return s
}
func main() {
s := []int{
1, 0, 3, 5, 2, 7, 4, 8, 6, 9, 10}
HeapSort1(s)
fmt.Println("heapsort:", s)
}
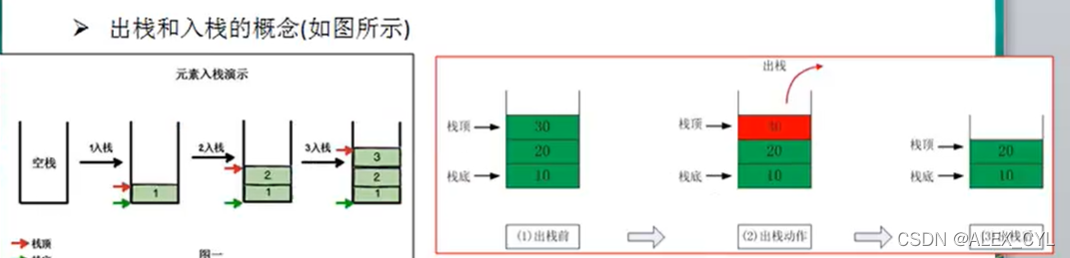
6. 栈
- 栈(stack)是FILO(first in last out)先入后出的有序列表。
- 栈是限制线性表,插入和删除某一元素都只能在同一端进行,该端即为栈顶(top),另一端为固定的一段,称为栈底(bottom)
- 栈底index为-1时,即为空栈
栈底示意图:
栈的应用场景:
- 子程序的调用:在跳往子程序前,会将下一个指令的地址存到堆栈中,直到子程序执行完后再将地址取出,以回到原来的程序
2)处理递归调用:和子程序调用类似,不同处在于,除了储存下一个指令的地址外,也将参数、区域变量等数据存入堆栈中
3)表达式的转换与求值
4)二叉树的遍历
5)图形的深度优化(depth-first)搜素法
栈的案例:
- 动态数组(切片)模拟栈:
package main
import (
"errors"
"fmt"
"strconv"
"strings"
)
// 使用数组模拟一个栈的使用
// 链表也可以模拟栈,链表更为灵活
type Stack struct {
MaxTop int //表示栈最大可以存放的个数
Top int //表示栈顶,栈底是固定的,初始时为 -1 表示空栈
arr []interface{
} //(动态数组)切片模拟栈
}
//入栈
func (s *Stack) Push(val interface{
}) error {
//先判断栈是否满了
if s.Top == s.MaxTop-1 {
fmt.Println("stack full")
return errors.New("stack full")
}
s.Top++
s.arr[s.Top] = val
return nil
}
//遍历栈,需从栈顶开始遍历
func (s *Stack) List() error {
fmt.Println("栈的情况:")
//先判断栈是否为空
if s.Top == -1 {
fmt.Println("stack empty")
return errors.New("stack empty")
}
for i := s.Top; i >= 0; i-- {
fmt.Printf("arr[%d]=%d\n", i, s.arr[i])
}
return nil
}
// 出栈
func (s *Stack) Pop() (val interface{
}, err error) {
// 先判断是否为空栈
if s.Top == -1 {
fmt.Println("stcak empty")
return 0, errors.New("stack empty")
}
val = s.arr[s.Top]
s.Top--
return val, err
}
//判断一个字符是不是一个运算符[+,-,*,/]
// 采用ASCII码值进行判断
func (s *Stack) IsOper(val int) bool {
if val == 42 || val == 43 || val == 45 || val == 47 {
return true
} else {
return false
}
}
// 运算方法
func (s *Stack) Cal1(oper int) float64 {
n1, _ := s.Pop()
n2, _ := s.Pop()
num1 := n1.(float64)
num2 := n2.(float64)
res := 0.0
switch oper {
case 42:
res = num2 * num1
case 43:
res = num2 + num1
case 45:
res = num2 - num1
case 47:
res = num2 / num1
default:
fmt.Println("运算符有误")
}
return res
}
func (s *Stack) Cal(num1, num2, oper int) int {
res := 0
switch oper {
case 42:
res = num2 * num1
case 43:
res = num2 + num1
case 45:
res = num2 - num1
case 47:
res = num2 / num1
default:
fmt.Println("运算符有误")
}
return res
}
//运算优先级设计
func (s *Stack) Priority(oper int) int {
if oper == 42 || oper == 47 {
//[* /] -> 1
return 1
} else if oper == 43 || oper == 45 {
//[+ -] -> 0
return 0
} else {
return -1
}
}
//整数计算
func IntCal(numStack, operStack *Stack, exp string) {
// 用于拼接的变量
keepnum := ""
for index, v := range exp {
if operStack.IsOper(int(v)) {
//是符号
//如果符号位栈是空栈直接入栈
if operStack.Top == -1 {
operStack.Push(int(v))
} else {
if operStack.Priority(operStack.arr[operStack.Top].(int)) >=
operStack.Priority(int(v)) {
num1, _ := numStack.Pop()
num2, _ := numStack.Pop()
oper, _ := operStack.Pop()
res := operStack.Cal(num1.(int), num2.(int), oper.(int))
//将计算结果重新入数栈
numStack.Push(res)
//当前的符号压入符号栈
operStack.Push(int(v))
} else {
operStack.Push(int(v))
}
}
} else {
//是数.
keepnum += string(v)
if index == len(exp)-1 || operStack.IsOper(int(exp[index+1])) {
//到达最后一个字符了 或者后一个字符不是运算符
val, _ := strconv.Atoi(keepnum)
numStack.Push(val)
keepnum = ""
}
}
}
//如果扫描表达式 完毕,依次从符号栈取出符号,然后从数栈取出两个数,
//运算后的结果,入数栈,直到符号栈为空
for {
if operStack.Top == -1 {
break //退出条件
}
num1, _ := numStack.Pop()
num2, _ := numStack.Pop()
oper, _ := operStack.Pop()
res := operStack.Cal(num1.(int), num2.(int), oper.(int))
//将计算结果重新入数栈
numStack.Push(res)
}
}
//浮点数计算
func Float64Cal(numStack, operStack *Stack, exp string) {
// 用于拼接的变量
keepnum := ""
for index, v := range exp {
if operStack.IsOper(int(v)) {
//是符号
//如果符号位栈是空栈直接入栈
if operStack.Top == -1 {
operStack.Push(int(v))
} else {
if operStack.Priority(operStack.arr[operStack.Top].(int)) >=
operStack.Priority(int(v)) {
oper, _ := operStack.Pop()
res := numStack.Cal1(oper.(int))
//将计算结果重新入数栈
numStack.Push(res)
//当前的符号压入符号栈
operStack.Push(int(v))
} else {
operStack.Push(int(v))
}
}
} else {
//是数.
keepnum += string(v)
if index == len(exp)-1 || operStack.IsOper(int(exp[index+1])) {
//到达最后一个字符了 或者后一个字符不是运算符
val, _ := strconv.ParseFloat(keepnum, 64)
numStack.Push(val)
keepnum = ""
}
}
}
//如果扫描表达式 完毕,依次从符号栈取出符号,然后从数栈取出两个数,
//运算后的结果,入数栈,直到符号栈为空
for {
if operStack.Top == -1 {
break //退出条件
}
oper, _ := operStack.Pop()
res := numStack.Cal1(oper.(int))
//将计算结果重新入数栈
numStack.Push(res)
}
}
func main() {
//数栈
numStack := &Stack{
MaxTop: 20,
Top: -1,
arr: make([]interface{
}, 20),
}
// 字符栈
operStack := &Stack{
MaxTop: 20,
Top: -1,
arr: make([]interface{
}, 20),
}
exp := "300+4*6-20"
if strings.Contains(exp, ".") {
//浮点数运算
Float64Cal(numStack, operStack, exp)
} else {
IntCal(numStack, operStack, exp)
}
//如果算法没有问题,表达式也是正确的,则结果就是numStack最后数
res, _ := numStack.Pop()
fmt.Printf("表达式%s = %v\n", exp, res)
}
7. 递归
递归:函数、方法自己调用自己,每次传入不同的变量,有助于解决复杂的问题并同时简化代码。
经典应用场景:迷宫\回溯问题、皇后问题、汉诺塔、阶乘问题、球和篮子
递归遵循的原则:
1)执行一个函数时,就创建一个新的受保护的独立空间(新函数栈)
2)函数的局部变量是独立的,不会互相影响
3) 递归必须向退出递归条件逼近
4)当一个函数执行完毕或者遇到return就会返回,遵守谁调用就将结果返回给谁,同时当函数执行完毕或者返回时,该函数也会被系统销毁
递归每次调用,都是开辟新的堆栈:
简单实例:
打印问题: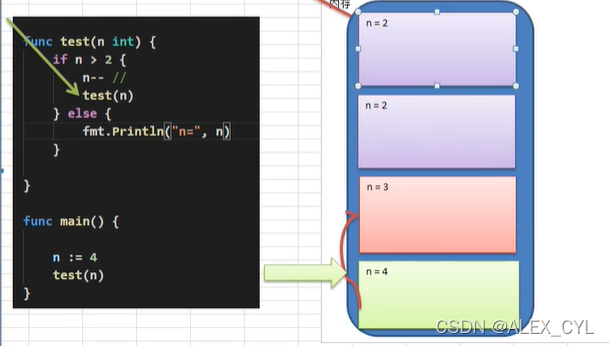
package main
import "fmt"
func test(n int) {
if n > 2 {
n-- //需有跳出递归的限制条件
test(n)
}
fmt.Println("n=", n)
}
func main() {
test(4)
}
Output:
n= 2
n= 2
n= 3
迷宫:
package main
import "fmt"
func setWay(myMap *[8][7]int, i, j int) bool {
//(i,j)表示起始点
// 终点为[6,5]
// 判断条件为
if myMap[6][5] == 2 {
return true
}
if myMap[i][j] == 0 {
myMap[i][j] = 2
// 该点的下右上左规则顺序探点
if setWay(myMap, i+1, j) {
return true
} else if setWay(myMap, i, j+1) {
return true
} else if setWay(myMap, i-1, j) {
return true
} else if setWay(myMap, i, j-1) {
return true
} else {
myMap[i][j] = 3
return false
}
} else {
return false
}
}
func main() {
//创建一个二维数组,模拟迷宫
// 规则
// 1.如果元素的值为0,表示为没有走过的点
// 1.1如果元素的值为2,是一个通路
// 1.2如果元素的值为3,是走过的点,但走不通,需要退回的点
// 2.如果元素的值为1,就是墙
var myMap [8][7]int
// 先把地图的最上和最下边设置为1 墙
for i := 0; i < len(myMap[0]); i++ {
myMap[0][i] = 1
myMap[7][i] = 1
}
// 先把地图的最左和最右边设置为1 墙
for i := 0; i < len(myMap); i++ {
myMap[i][0] = 1
myMap[i][6] = 1
}
//加墙点
myMap[3][1] = 1
myMap[3][2] = 1
// myMap[1][2] = 1
myMap[2][2] = 1
// 输出地图
for _, val := range myMap {
for _, v := range val {
fmt.Printf("%d\t", v)
}
fmt.Println("")
}
fmt.Println("")
fmt.Println("")
setWay(&myMap, 1, 1)
for _, val := range myMap {
for _, v := range val {
fmt.Printf("%d\t", v)
}
fmt.Println("")
}
}
8.哈希表(散列)
哈希表(散列表,hash table),根据关键码值(Key-Value)而直接进行访问的数据结构。即,它通过把关键码值映射到表中的一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组或链表叫做散列表。

案例
使用hashtable来实现一个雇员的管理系统【增删改查】
雇员的信息有id,性别,年龄,住址…,当输入id时即可查找到该雇员的所有信息
要求:
1)不使用数据库,尽量节省内存,速度越快越好=>哈希表(散列表)
2)添加时,保证按照雇员的id从低到高插入
思路分析:
1)使用链表来实现哈希表,该链表不带表头
2)示意图
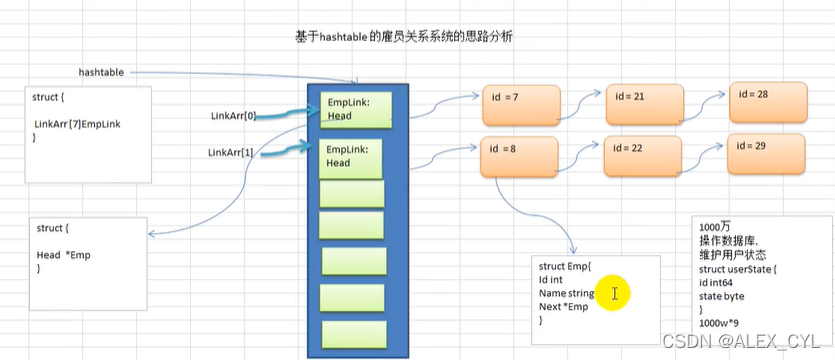
3)代码实现(CRUD 显示所有员工,按id查询)
package main
import (
"fmt"
"os"
)
// 定义雇员节点
type EmpNode struct {
Id int
Name string
Next *EmpNode
}
//方法待定..
func (en *EmpNode) ShowMe() {
fmt.Printf("链表%d 找到该雇员 %d\n", en.Id%7, en.Id)
}
//定义EmpLink
//我们这里的EmpLink 不带表头,即第一个结点就存放雇员
type EmpLink struct {
Head *EmpNode
}
//方法待定..
//1. 添加员工的方法, 保证添加时,编号从小到大
func (el *EmpLink) Insert(emp *EmpNode) {
cur := el.Head // 这是辅助指针
// var pre *EmpNode = nil // 这是一个辅助指针 pre 在cur前面
pre := el.Head
//如果当前的EmpLink就是一个空链表
if cur == nil {
el.Head = emp //完成
return
}
//如果不是一个空链表,给emp找到对应的位置并插入
//思路是 让 cur 和 emp 比较,然后让pre 保持在 cur 前面
for {
if cur != nil {
//比较
if cur.Id > emp.Id {
//找到位置
break
}
pre = cur //保证同步
cur = cur.Next
} else {
break
}
}
//退出时,我们看下是否将emp添加到链表最后
if pre == emp {
//表示添加位置为头节点时
emp.Next = cur
el.Head = emp
}
pre.Next = emp
emp.Next = cur
}
//显示链表的信息
func (el *EmpLink) ShowLink(no int) {
if el.Head == nil {
fmt.Printf("链表%d 为空\n", no)
return
}
//变量当前的链表,并显示数据
cur := el.Head // 辅助的指针
for {
if cur != nil {
fmt.Printf("链表%d 雇员id=%d 名字=%s ->", no, cur.Id, cur.Name)
cur = cur.Next
} else {
break
}
}
fmt.Println() //换行处理
}
//根据id查找对应的雇员,如果没有就返回nil
func (el *EmpLink) FindById(id int) *EmpNode {
cur := el.Head
for {
if cur != nil && cur.Id == id {
return cur
} else if cur == nil {
break
}
cur = cur.Next
}
return nil
}
//定义hashtable ,含有一个链表数组
type HashTable struct {
LinkArr [7]EmpLink
}
//给HashTable 编写Insert 雇员的方法.
func (ht *HashTable) Insert(emp *EmpNode) {
//使用散列函数,确定将该雇员添加到哪个链表
linkNo := ht.HashFun(emp.Id)
//使用对应的链表添加
ht.LinkArr[linkNo].Insert(emp) //
}
//编写方法,显示hashtable的所有雇员
func (ht *HashTable) ShowAll() {
for i := 0; i < len(ht.LinkArr); i++ {
ht.LinkArr[i].ShowLink(i)
}
}
//编写一个散列方法
func (ht *HashTable) HashFun(id int) int {
return id % 7 //得到一个值,就是对于的链表的下标
}
//编写一个方法,完成查找
func (ht *HashTable) FindById(id int) *EmpNode {
//使用散列函数,确定将该雇员应该在哪个链表
linkNo := ht.HashFun(id)
return ht.LinkArr[linkNo].FindById(id)
}
func main() {
key := ""
id := 0
name := ""
var hashtable HashTable
for {
fmt.Println("===============雇员系统菜单============")
fmt.Println("input 表示添加雇员")
fmt.Println("show 表示显示雇员")
fmt.Println("find 表示查找雇员")
fmt.Println("exit 表示退出系统")
fmt.Println("请输入你的选择")
fmt.Scanln(&key)
switch key {
case "input":
fmt.Println("输入雇员id")
fmt.Scanln(&id)
fmt.Println("输入雇员name")
fmt.Scanln(&name)
emp := &EmpNode{
Id: id,
Name: name,
}
hashtable.Insert(emp)
case "show":
hashtable.ShowAll()
// case "find":
// fmt.Println("请输入id号:")
// fmt.Scanln(&id)
// emp := hashtable.FindById(id)
// if emp == nil {
// fmt.Printf("id=%d 的雇员不存在\n", id)
// } else {
// //编写一个方法,显示雇员信息
// emp.ShowMe()
// }
case "exit":
os.Exit(0)
default:
fmt.Println("输入错误")
}
}
}
二叉树
树的每个节点最多只能有两个节点称为二叉树
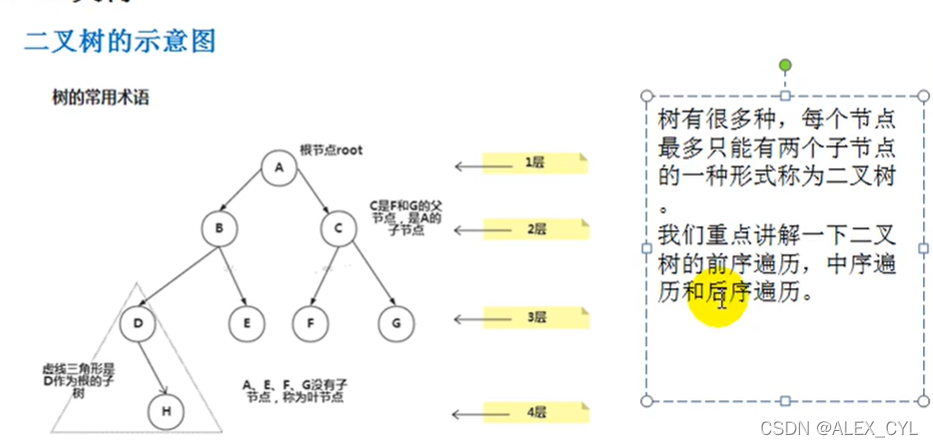
1)前序遍历 PreOrder
先输出root节点,然后再输出左子树,最后再输出右子树
2)中序遍历 InfixOrder
先输出root的左子树,再输出root节点,最后输出右子树
3)后序遍历PostOrder
先输出root的左子树,再输出右子树节点,最后输出root节点
package main
import "fmt"
type heronode struct {
id int
name string
left *heronode
right *heronode
}
// 1)前序遍历 PreOrder
// 先输出root节点,然后再输出左子树,最后再输出右子树
func PreOrder(node *heronode) {
if node == nil {
return
}
fmt.Printf("id:%d name:%s\n", node.id, node.name)
PreOrder(node.left)
PreOrder(node.right)
}
// 2)中序遍历 InfixOrder
// 先输出root的左子树,再输出root节点,最后输出右子树
func InfixOrder(node *heronode) {
if node == nil {
return
}
InfixOrder(node.left)
fmt.Printf("id:%d name:%s\n", node.id, node.name)
InfixOrder(node.right)
}
// 3)后序遍历
// 先输出root的左子树,再输出右子树节点,最后输出root节点
func PostOrder(node *heronode) {
if node == nil {
return
}
PostOrder(node.left)
PostOrder(node.right)
fmt.Printf("id:%d name:%s\n", node.id, node.name)
}
func main() {
hero1 := &heronode{
id: 1,
name: "宋江",
}
hero2 := &heronode{
id: 2,
name: "吴用",
}
hero3 := &heronode{
id: 3,
name: "卢俊义",
}
hero4 := &heronode{
id: 4,
name: "林冲",
}
hero5 := &heronode{
id: 10,
}
hero6 := &heronode{
id: 12,
}
//建立二叉树
root := hero1
root.left = hero2
root.right = hero3
hero2.left = hero5
hero2.right = hero6
hero3.right = hero4
// 前序遍历
PreOrder(root)
fmt.Println("")
// 中序遍历
InfixOrder(root)
fmt.Println("")
// 后序遍历
PostOrder(root)
}