Beautiful Soup库的安装
Beautiful Soup: We called him Tortoise because he taught us. (crummy.com)
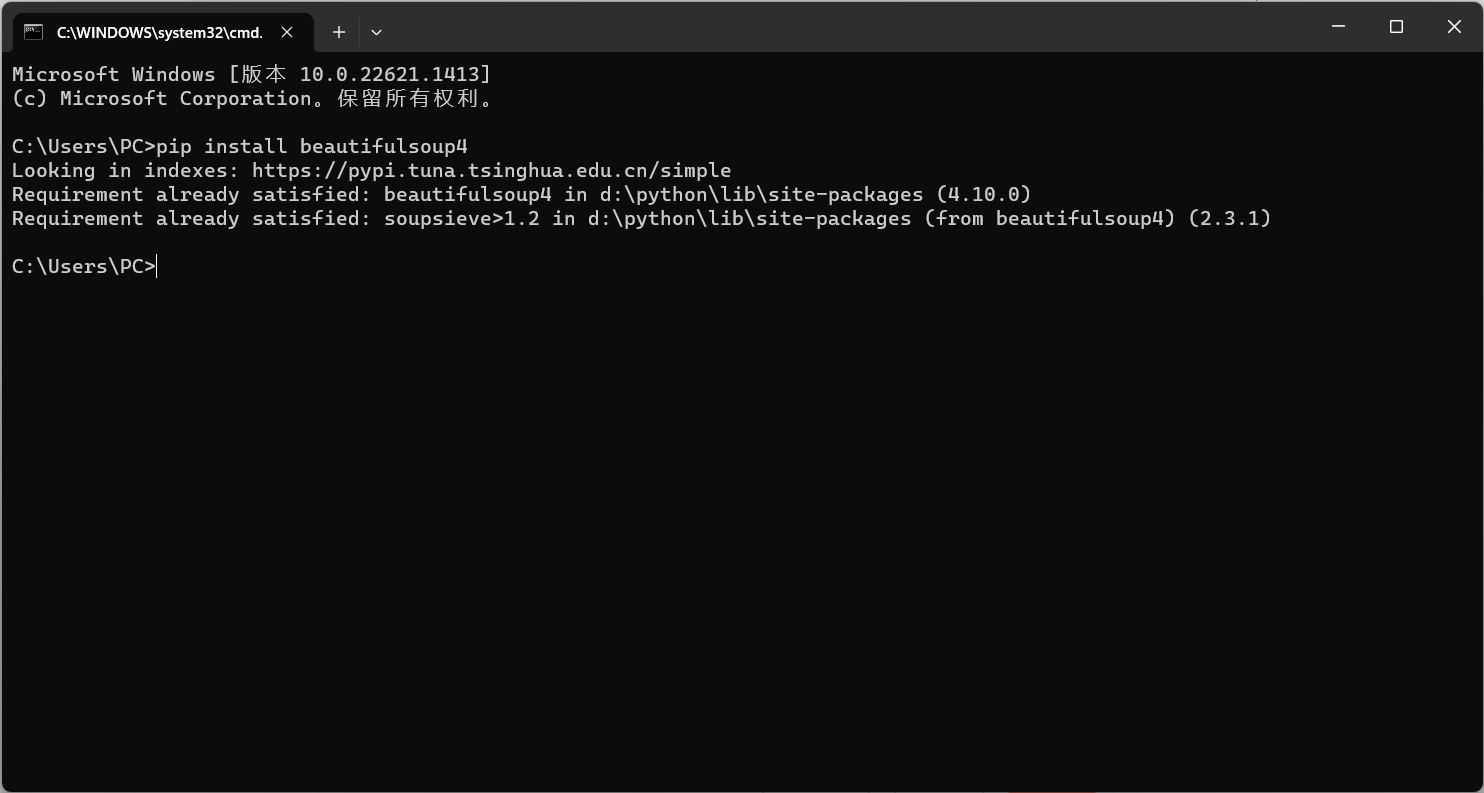
cmd打开终端输入
pip install beautifulsoup4
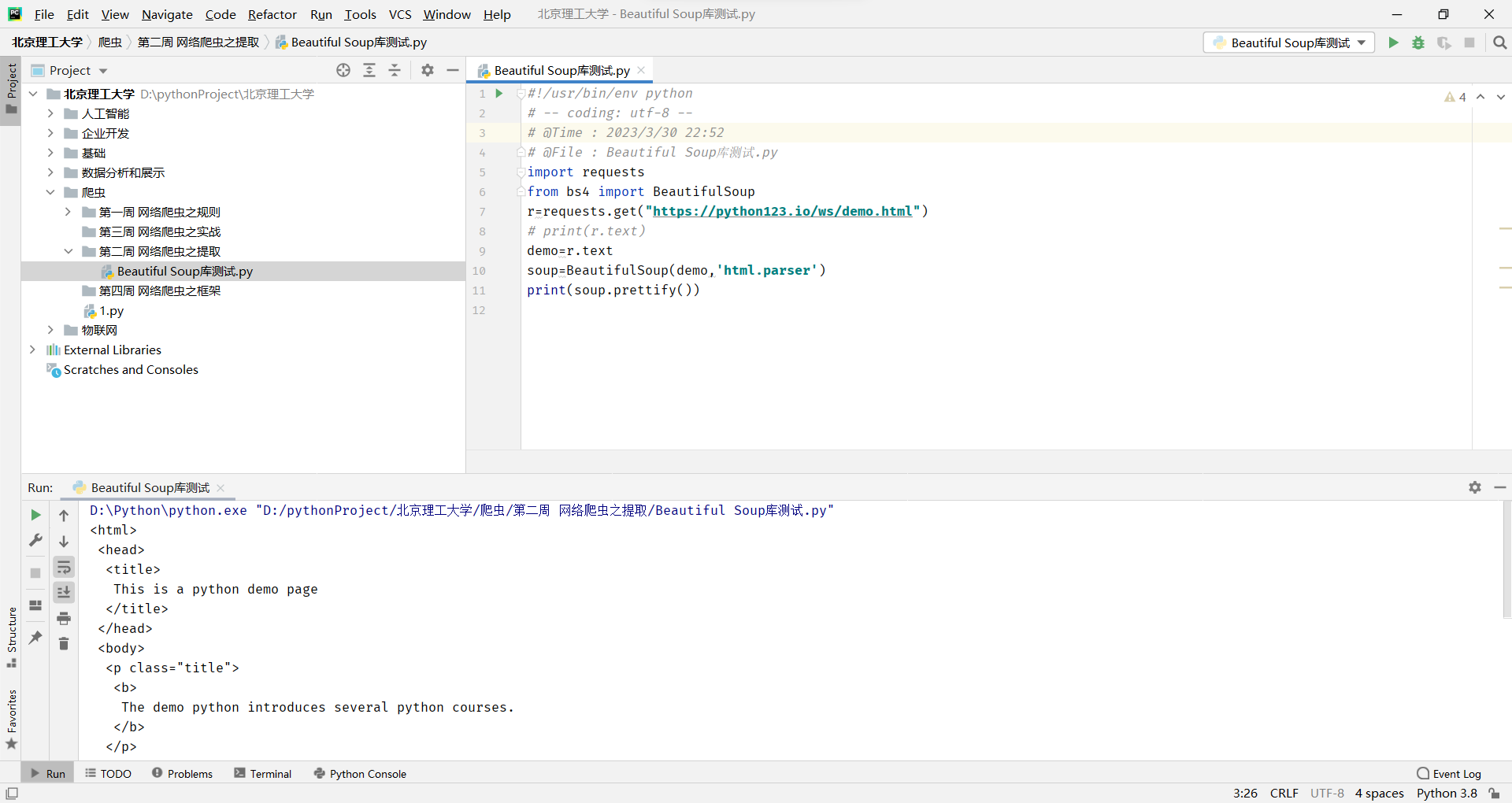
Beautiful Soup库的安装小测
测试路径This is a python demo page (python123.io)
安装成功
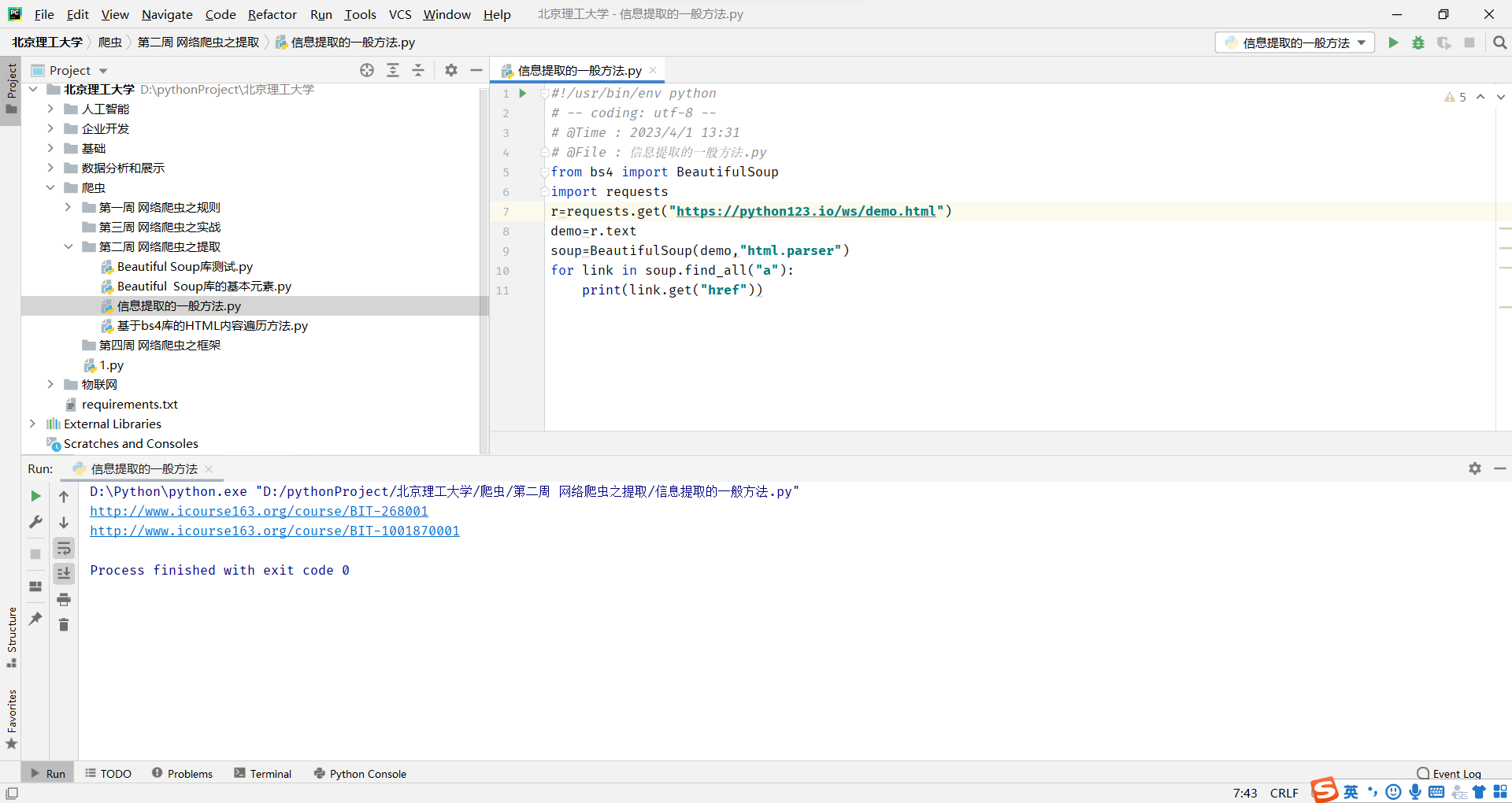
import requests
from bs4 import BeautifulSoup
r=requests.get("https://python123.io/ws/demo.html")
# print(r.text)
demo=r.text
soup=BeautifulSoup(demo,'html.parser')
print(soup.prettify())
Beautiful Soup库的基本元素
Beautiful Soup库是解析、遍历、维护“标签树”的功能库
Beautiful Soup库,也叫beautifulsoup4 或 bs4 约定引用方式如下,即主要是用BeautifulSoup 类
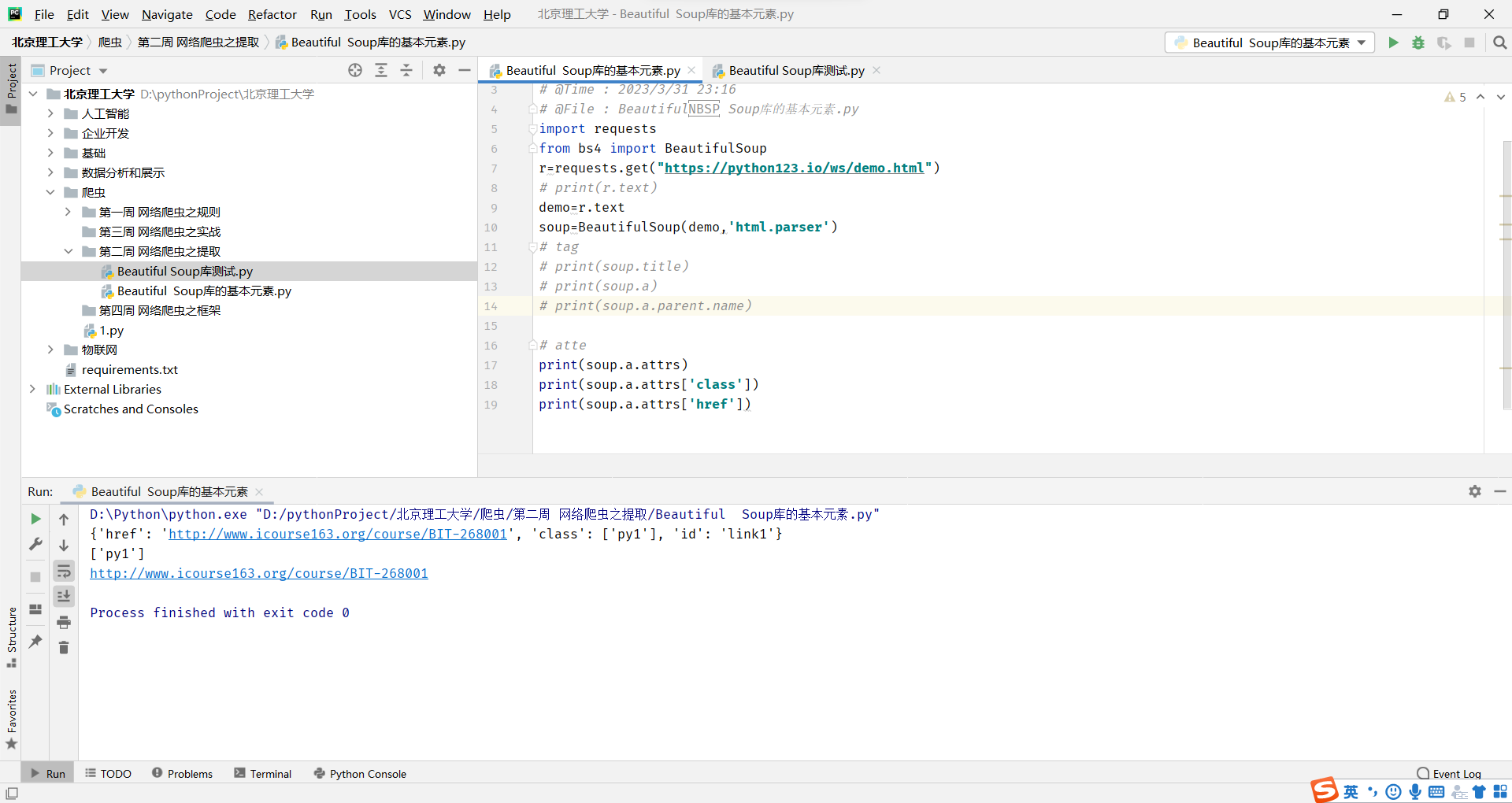
from bs4 import BeautifulSoup
import bs4
Beautiful Soup库解析器

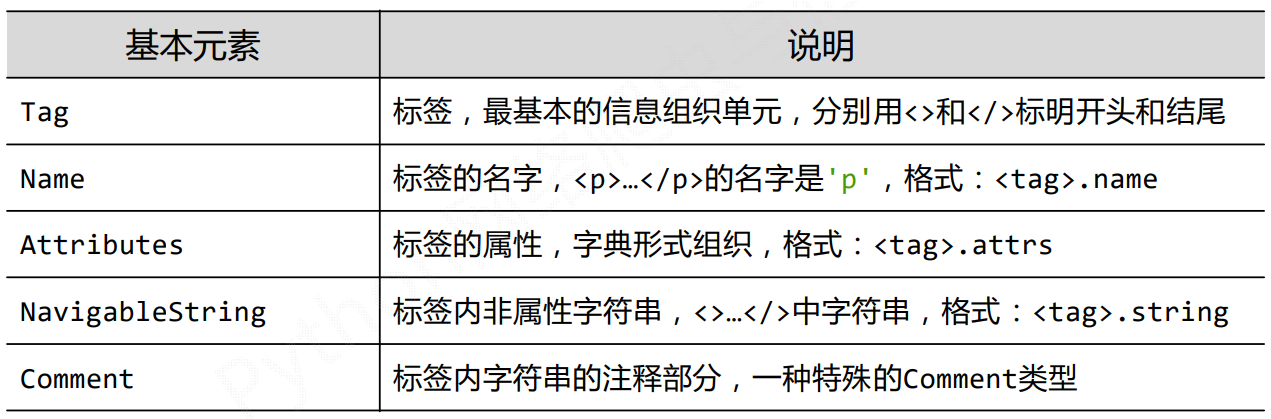
BeautifulSoup类的基本元素
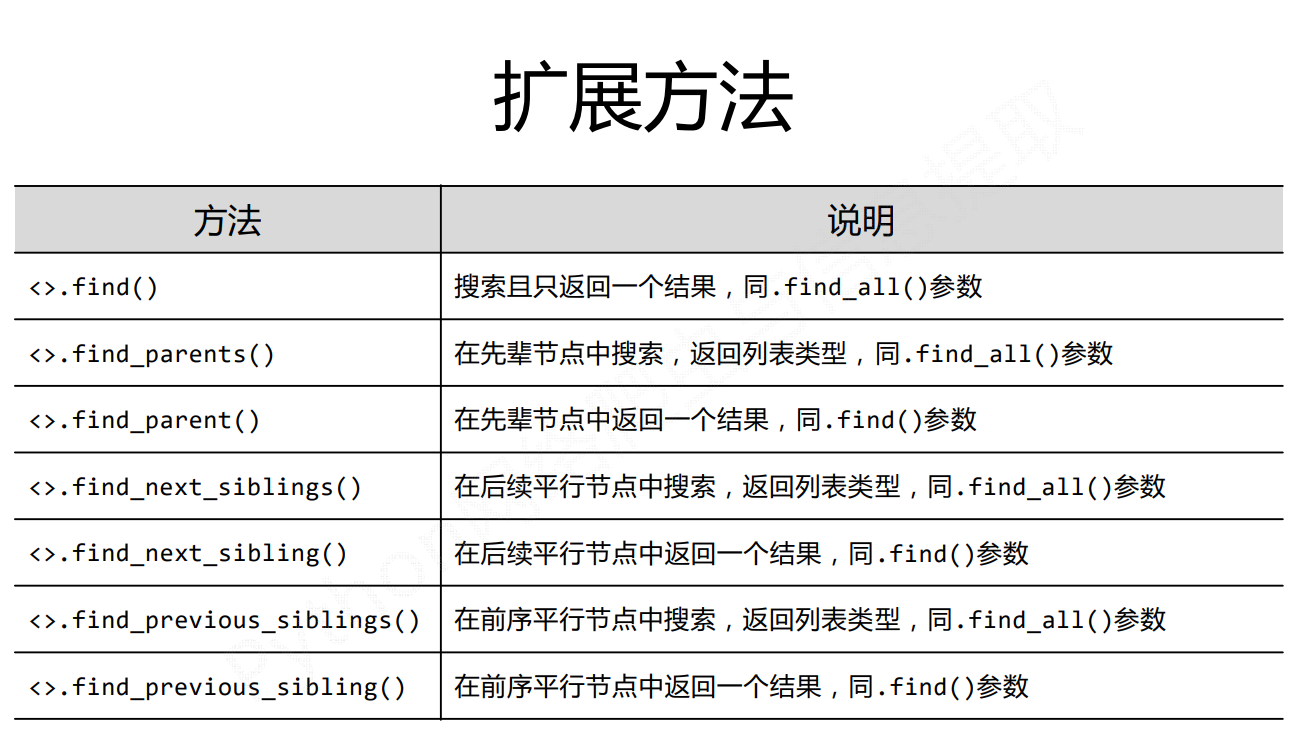
通过tag标签获取内容
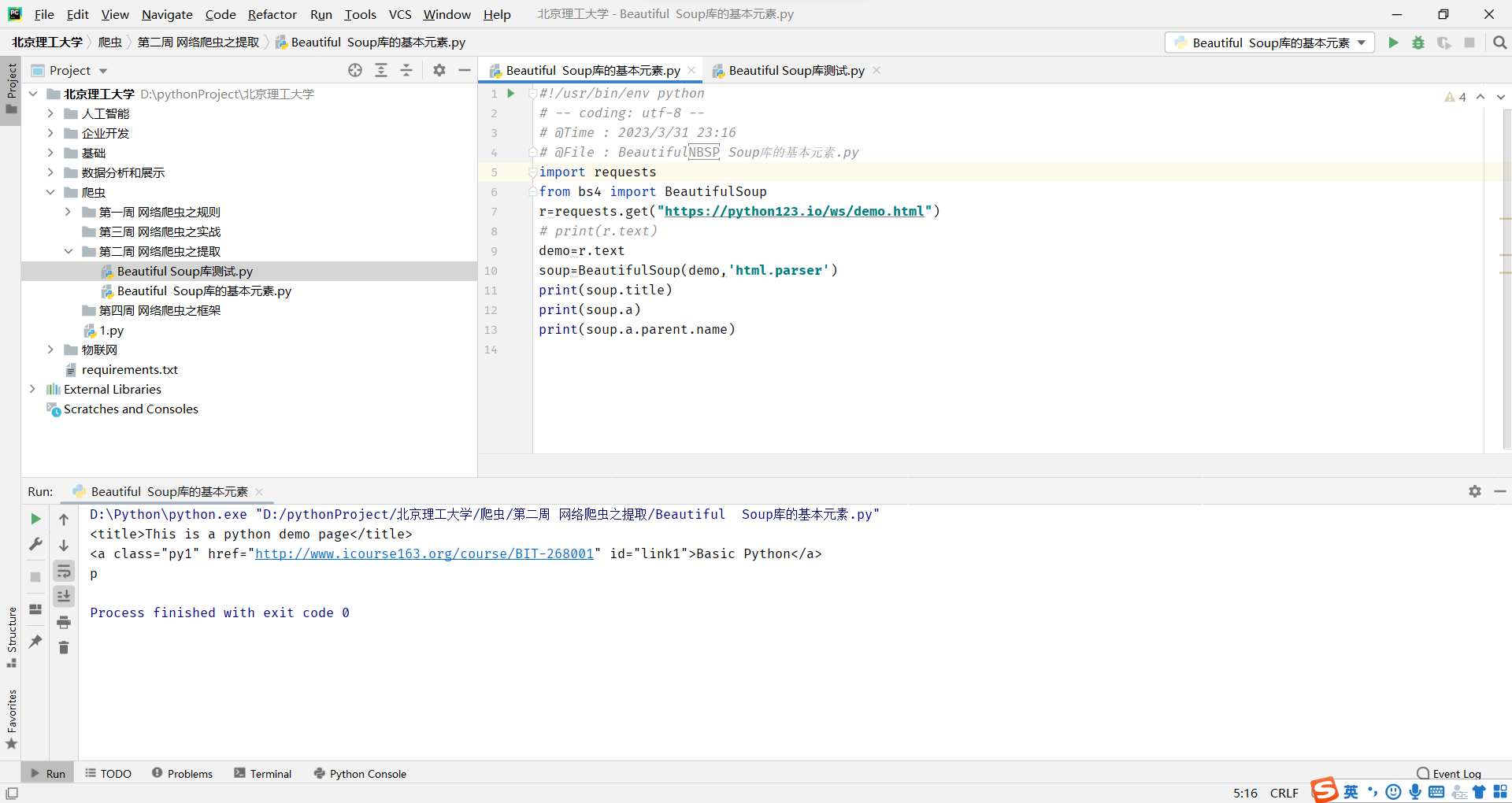
任何存在于HTML语法中的标签都可以用soup.访问获得 当HTML文档中存在多个相同对应内容时,soup.返回第一个
每个都有自己的名字,通过.name获取,字符串类型
通过Tag的attrs(属性)获取内容
一个<tag>可以有 0或多个属性,字典类型
Tag的NavigableString
就是俩个<></>之间的内容
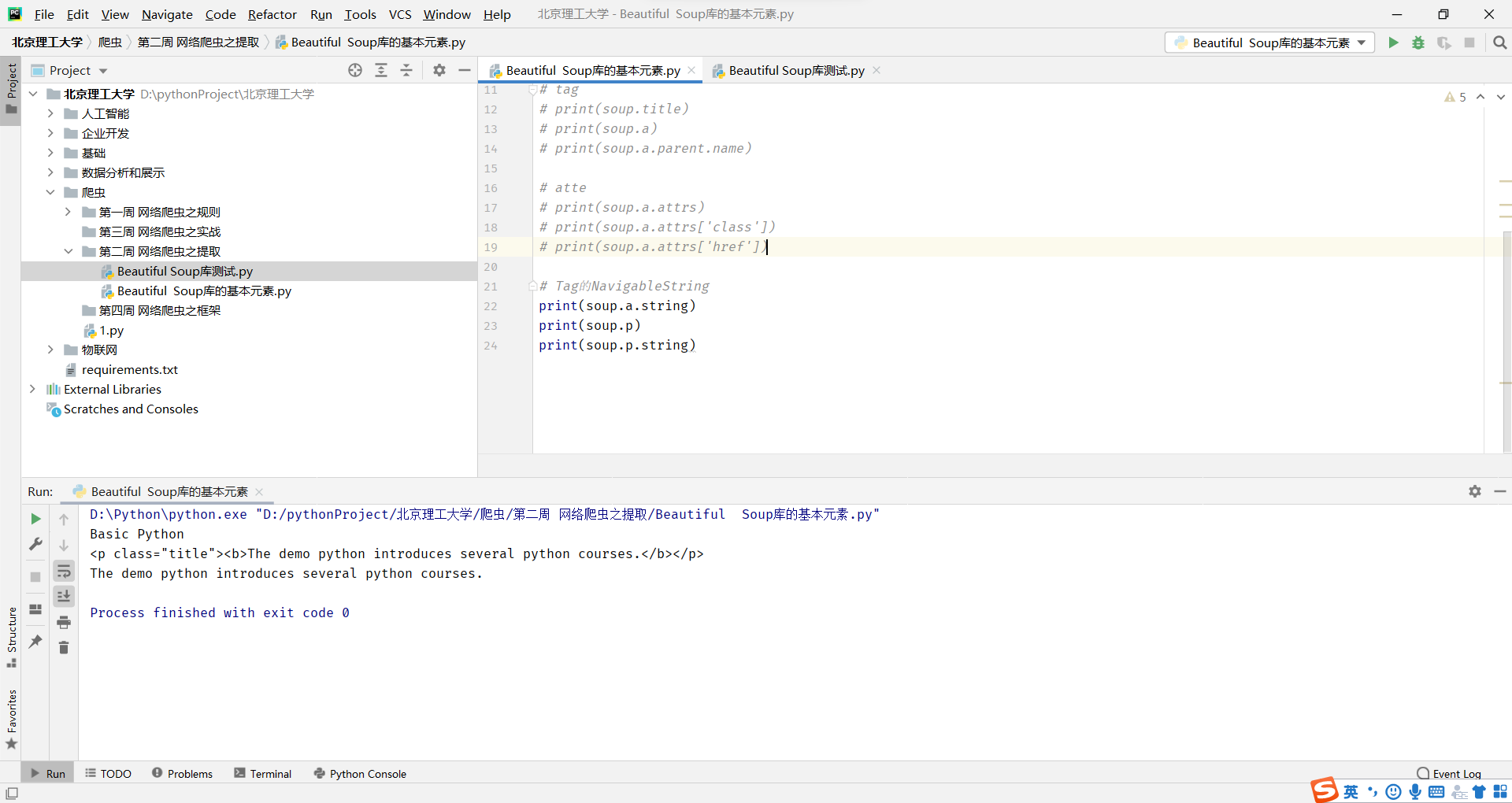
NavigableString可以跨越多个层次
Tag的Comment
Comment是一种特殊类型,指定是一个注释内容类型。了解即可
基于bs4库的HTML内容遍历方法
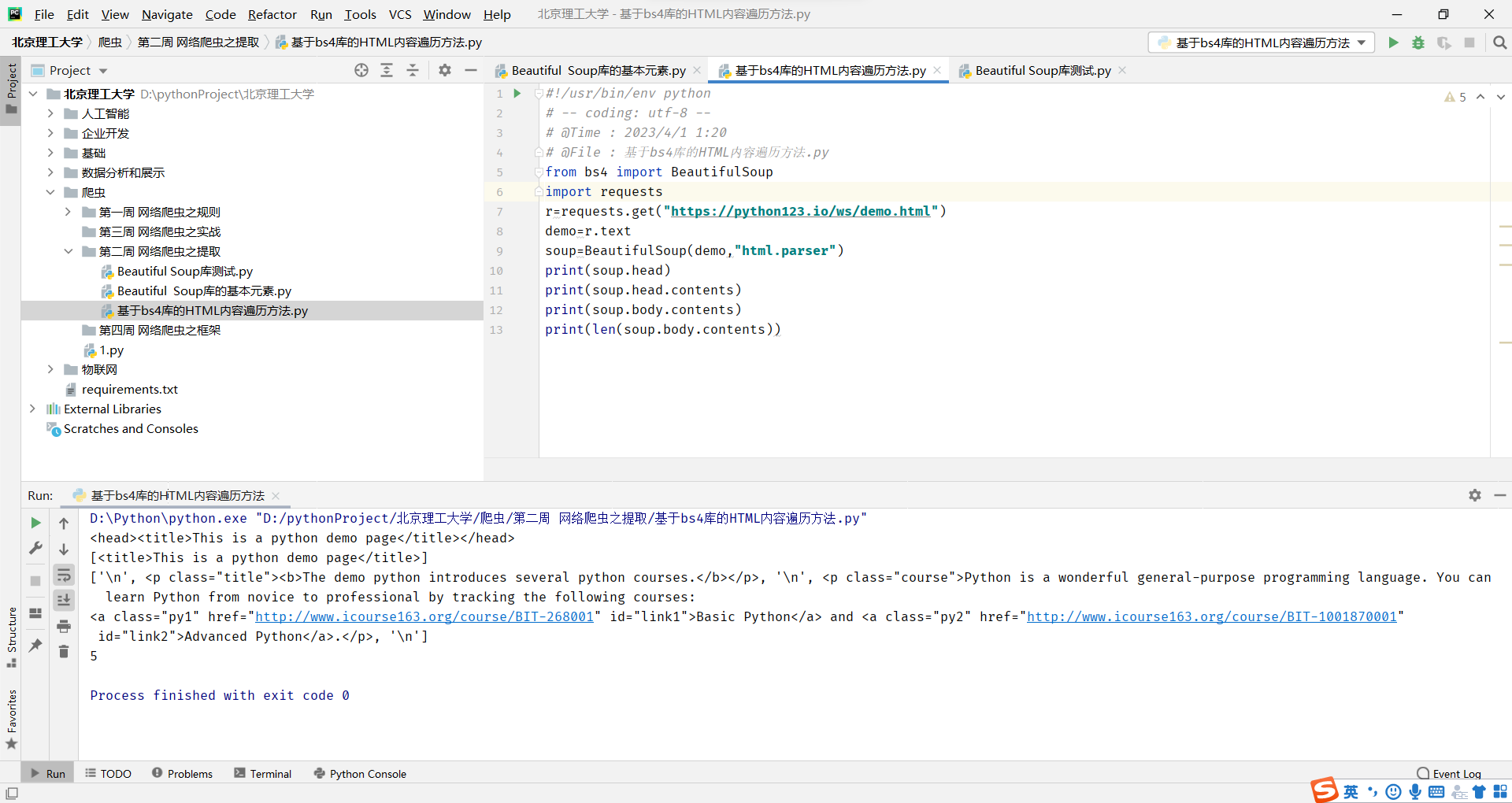


 遍历所有先辈节点,包括soup本身,所以要区别判断
遍历所有先辈节点,包括soup本身,所以要区别判断
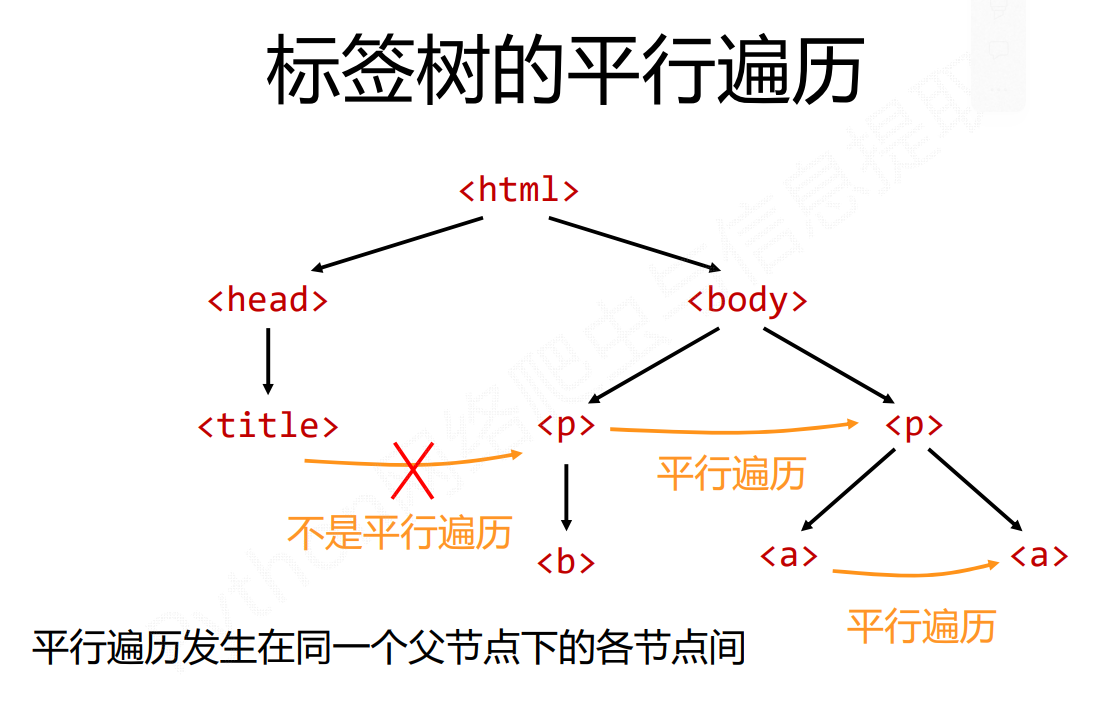 平行遍历必选要发生在同一个父节点下的
平行遍历必选要发生在同一个父节点下的
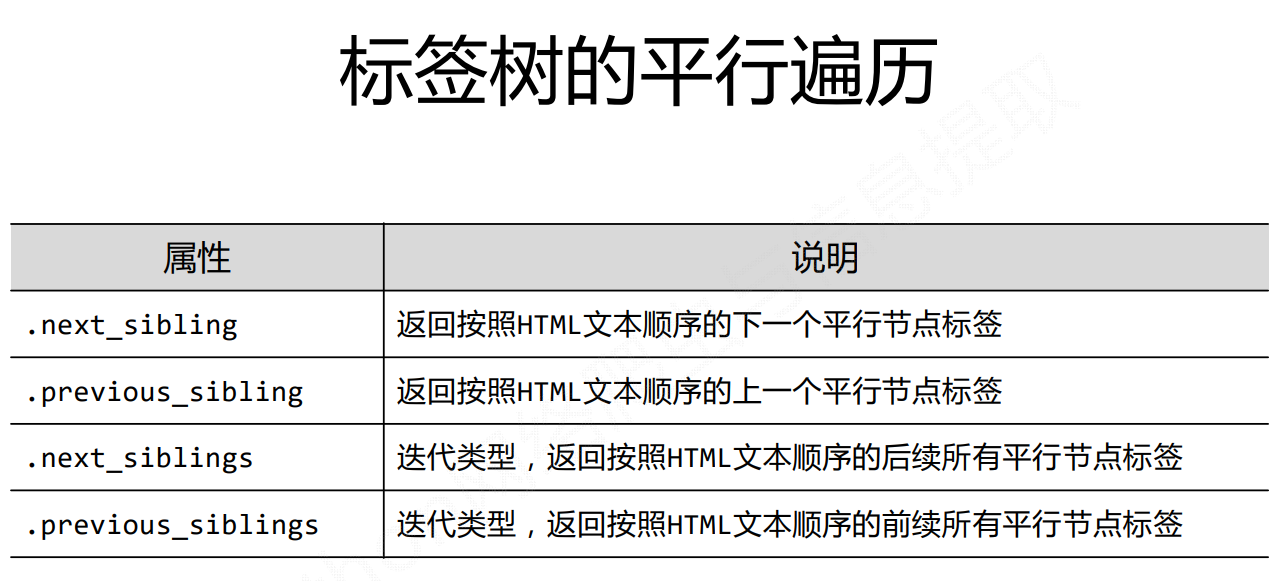
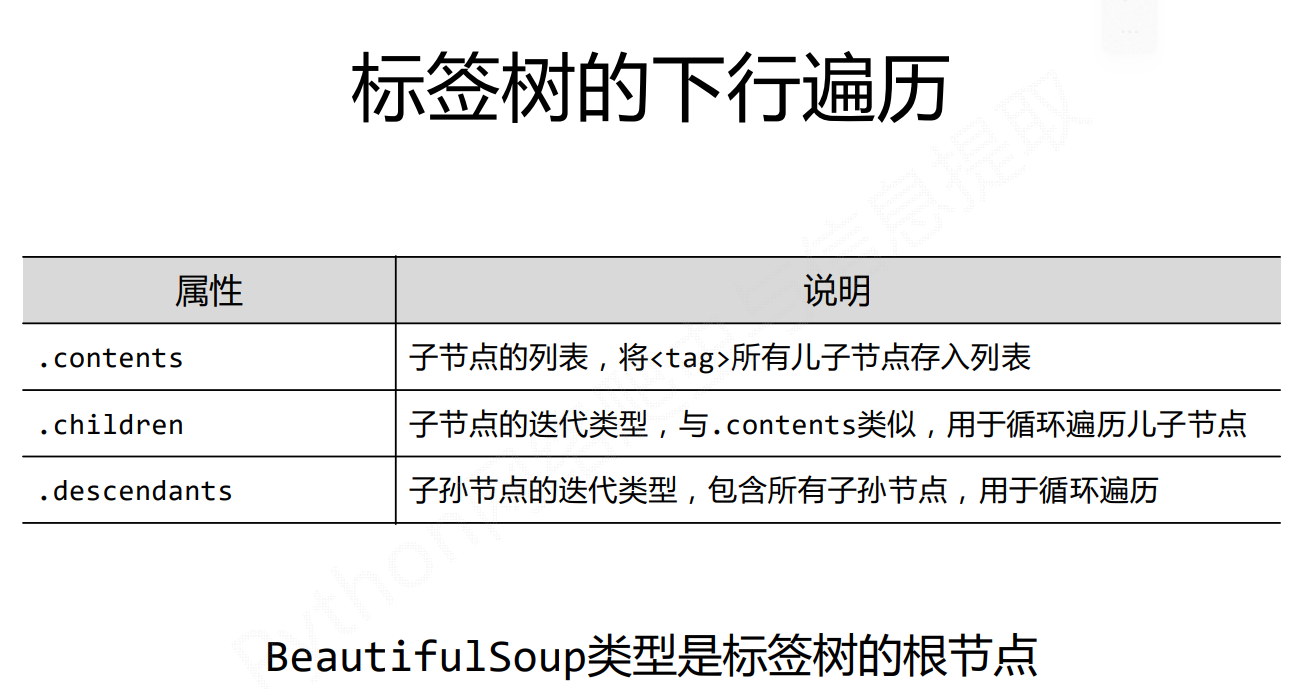
 注意加s的一个迭代类型,需要通过for循环,才能遍历节点中每个元素
注意加s的一个迭代类型,需要通过for循环,才能遍历节点中每个元素
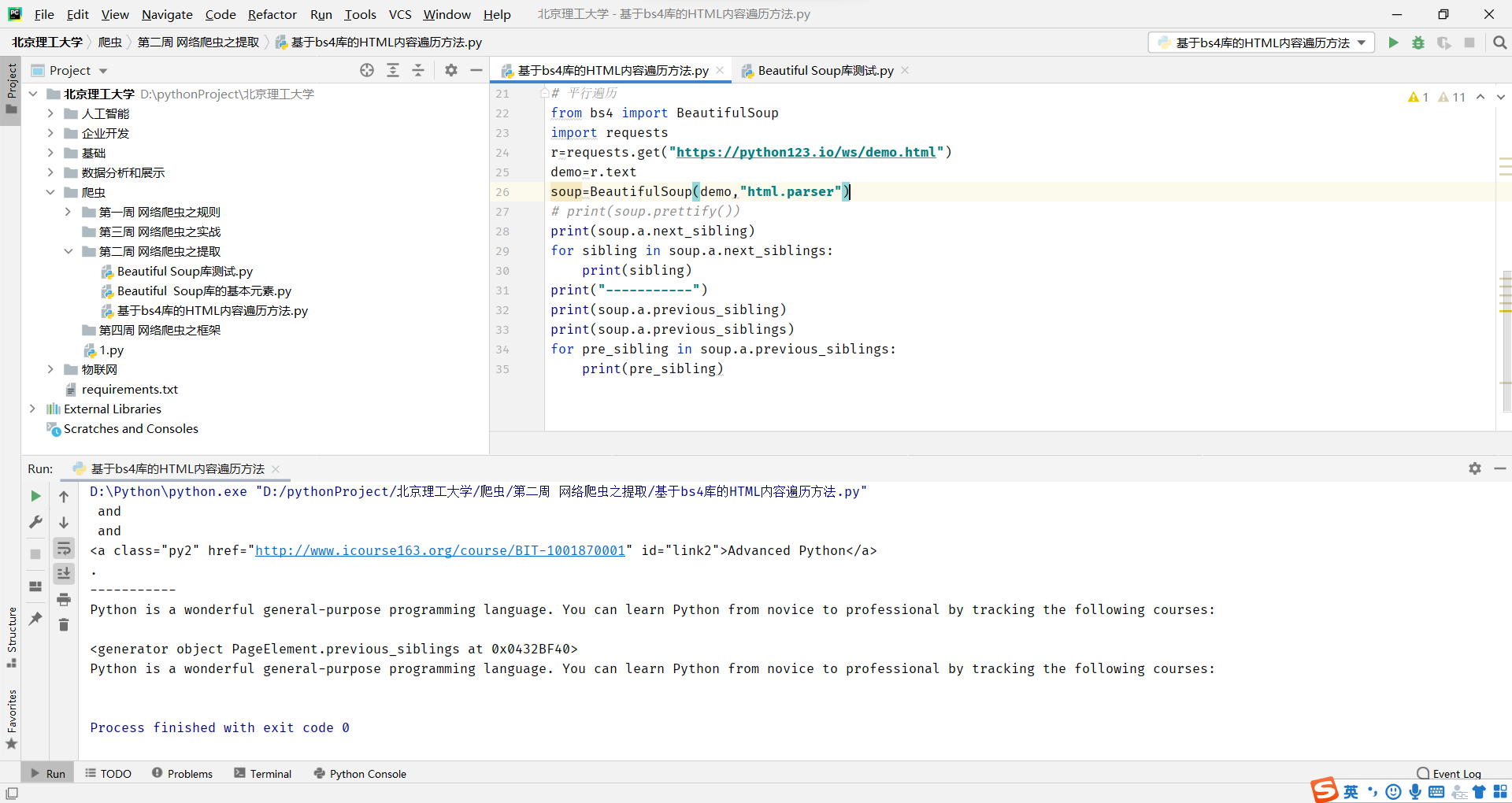
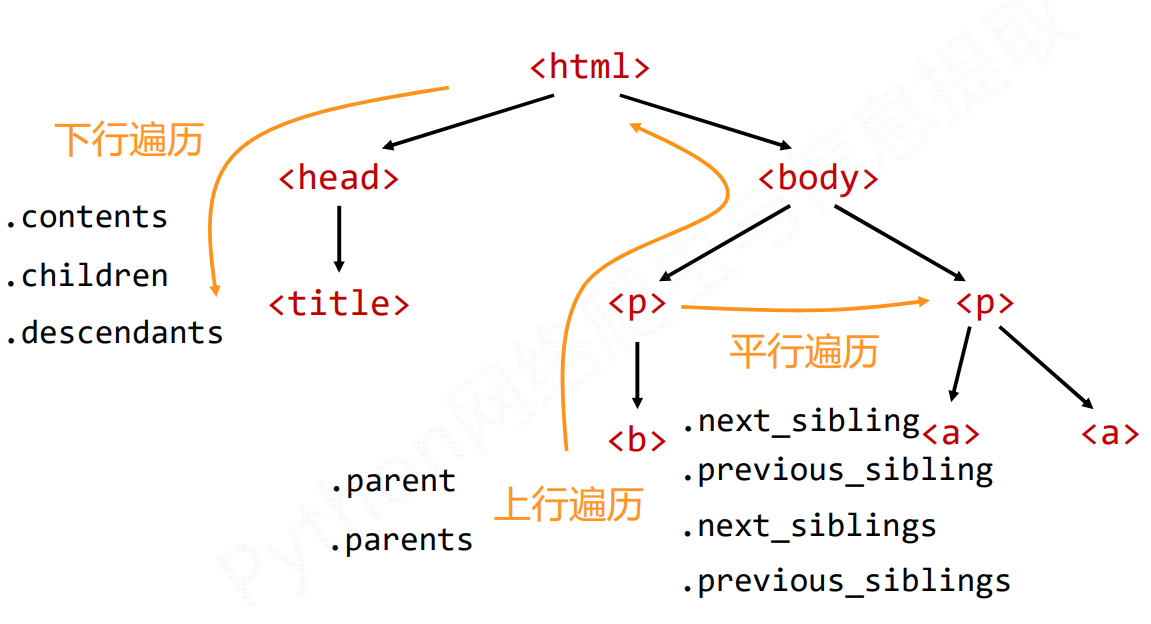
注意:.contents返回是的一个列表类型的,而下面俩个返回的是一个迭代类型的
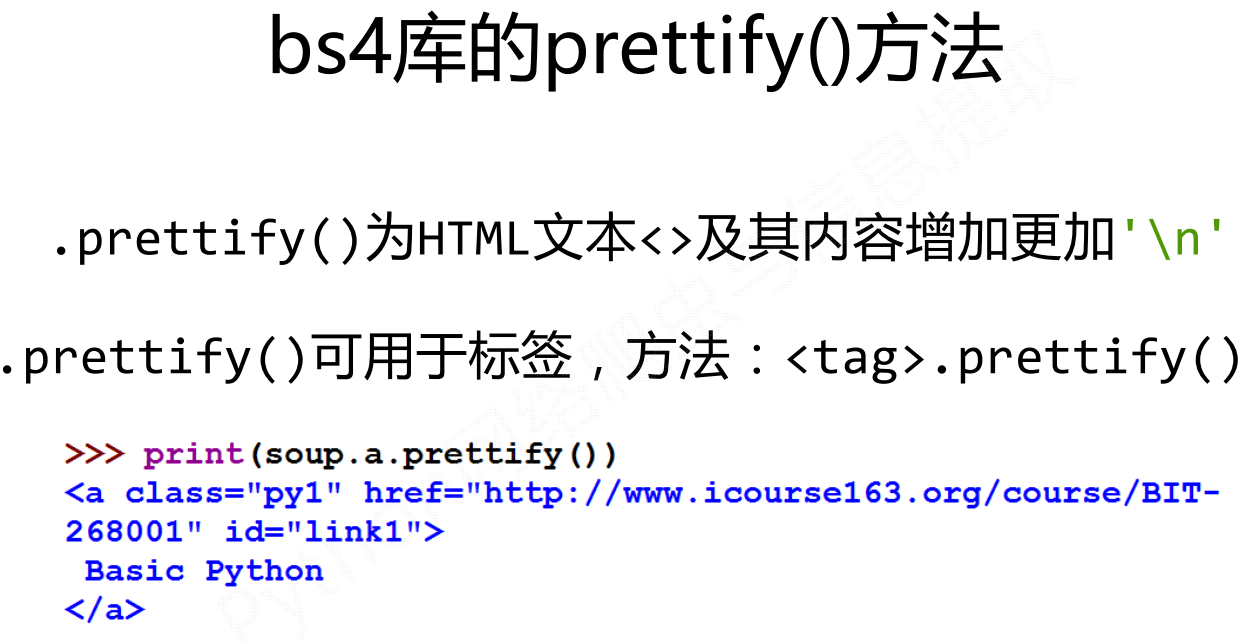
基于bs4库的HTML格式输出
 信息标记的三种形式
信息标记的三种形式
信息标记是指在文本中使用特定的标记符号或标记语言来标识某些信息或结构,以便于计算机程序或其他系统可以自动处理、理解和提取这些信息。常见的信息标记包括HTML、XML、JSON等。通过信息标记,可以使得文本数据更加结构化、规范化,从而方便进行数据分析、搜索、挖掘等操作。
信息标记的的三种形式
XMl

先有HTML,然后有了xml格式,因此可以说xml格式是基于HTML格式发展以来的一种通用的信息表达形式,简单说xml通过标签形式来构建所有的信息,当标签中有内容,我们用一对标签来表达这个信息,如果没有信息用一 对尖括号表达,同时可以增加注释
JSON

json是指有类型的键值对构建的信息表达方式
注意:在json类型中无论是键还是值都是必须要通过一个“”来表达
YAML

它也采用了键值对,但是是无类型的键值对来表示
通过缩进的方式来表达所属关系
可以用#表示注释,-表示并列的值信息,|表示整块内容
三种信息标记形式的比较

最早的通用信息标记语言,可扩展性好,但繁琐
 信息有类型,适合程序处理(js),较XML简洁
信息有类型,适合程序处理(js),较XML简洁
 信息无类型,文本信息比例最高,可读性好
信息无类型,文本信息比例最高,可读性好

信息提取的一般方法


 提取HTML中所有URL链接 思路:
提取HTML中所有URL链接 思路:
1) 搜索到所有标签
2)解析<a>标签格式,提取href后的链接
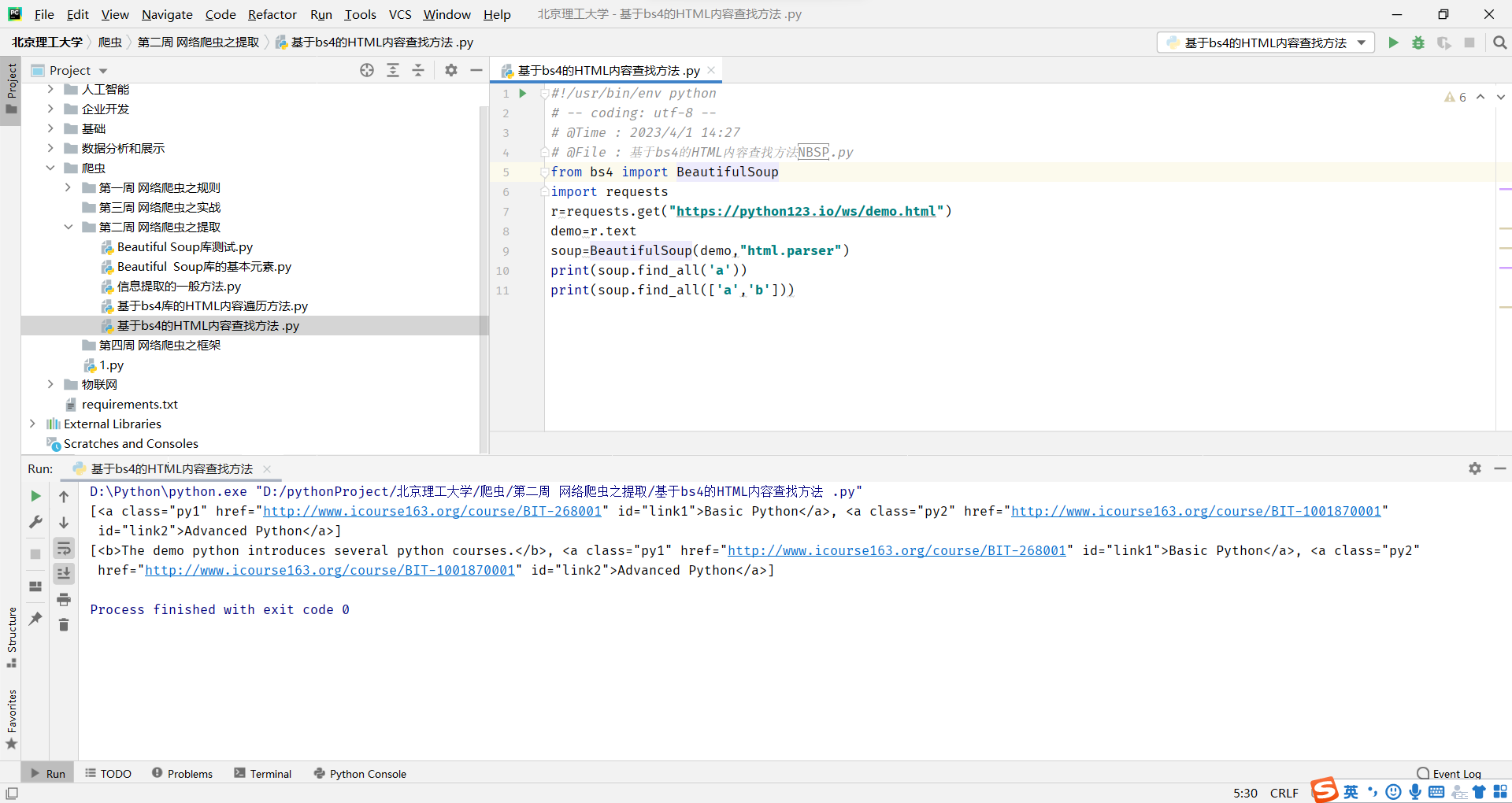
基于bs4的HTML内容查找方法

find_all方法有四个默认参数
分别进行使用
name
对标签名称的检索字符串
返回一个列表类型,存储查找的结果
attrs
对标签属性值的检索字符串,可标注属性检索
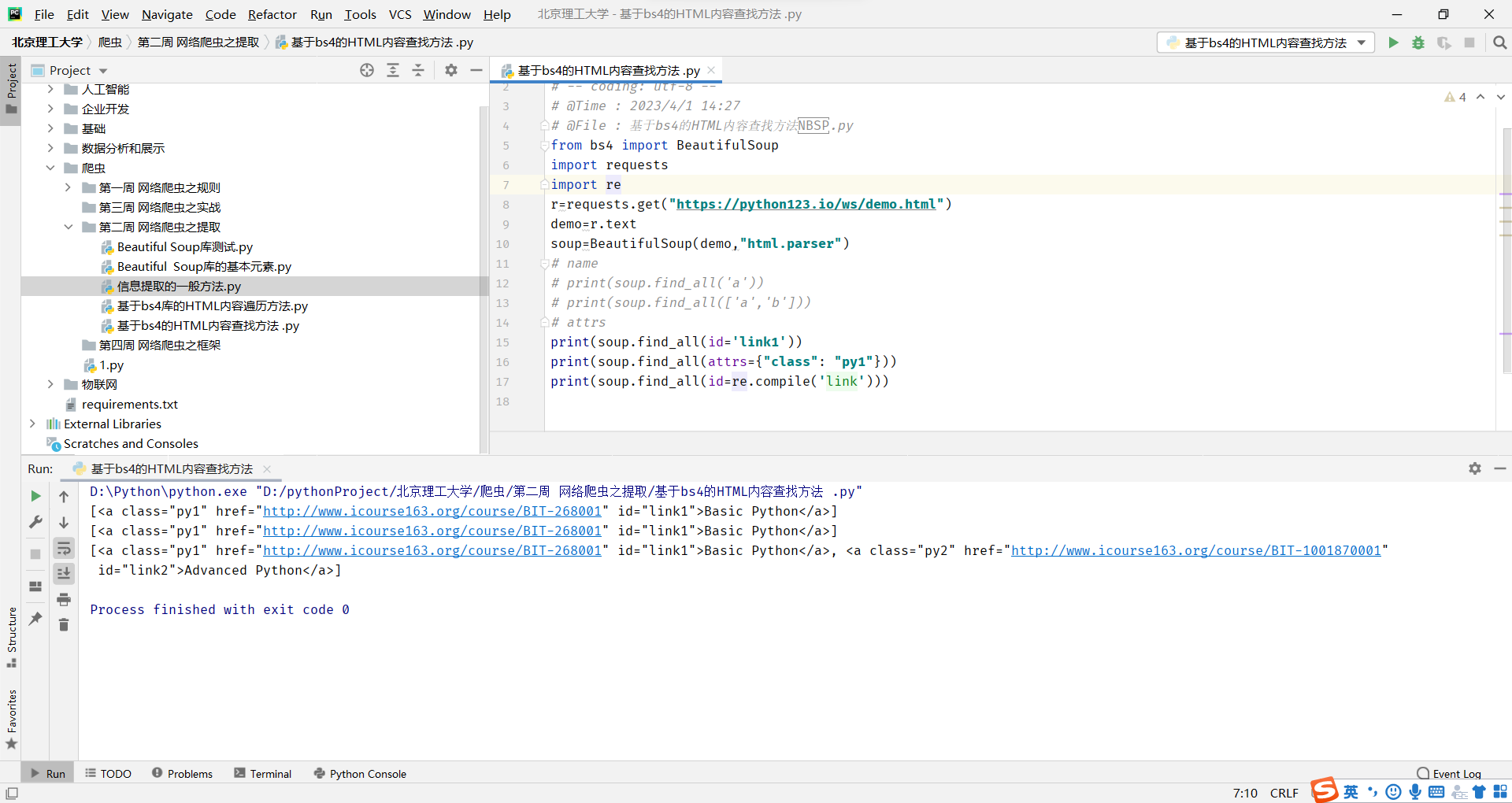
这里要注意一点的是这个class是要这么写的,否则会报错。因为,class 是 Python 的关键字,不能直接作为参数传递给 find_all() 函数
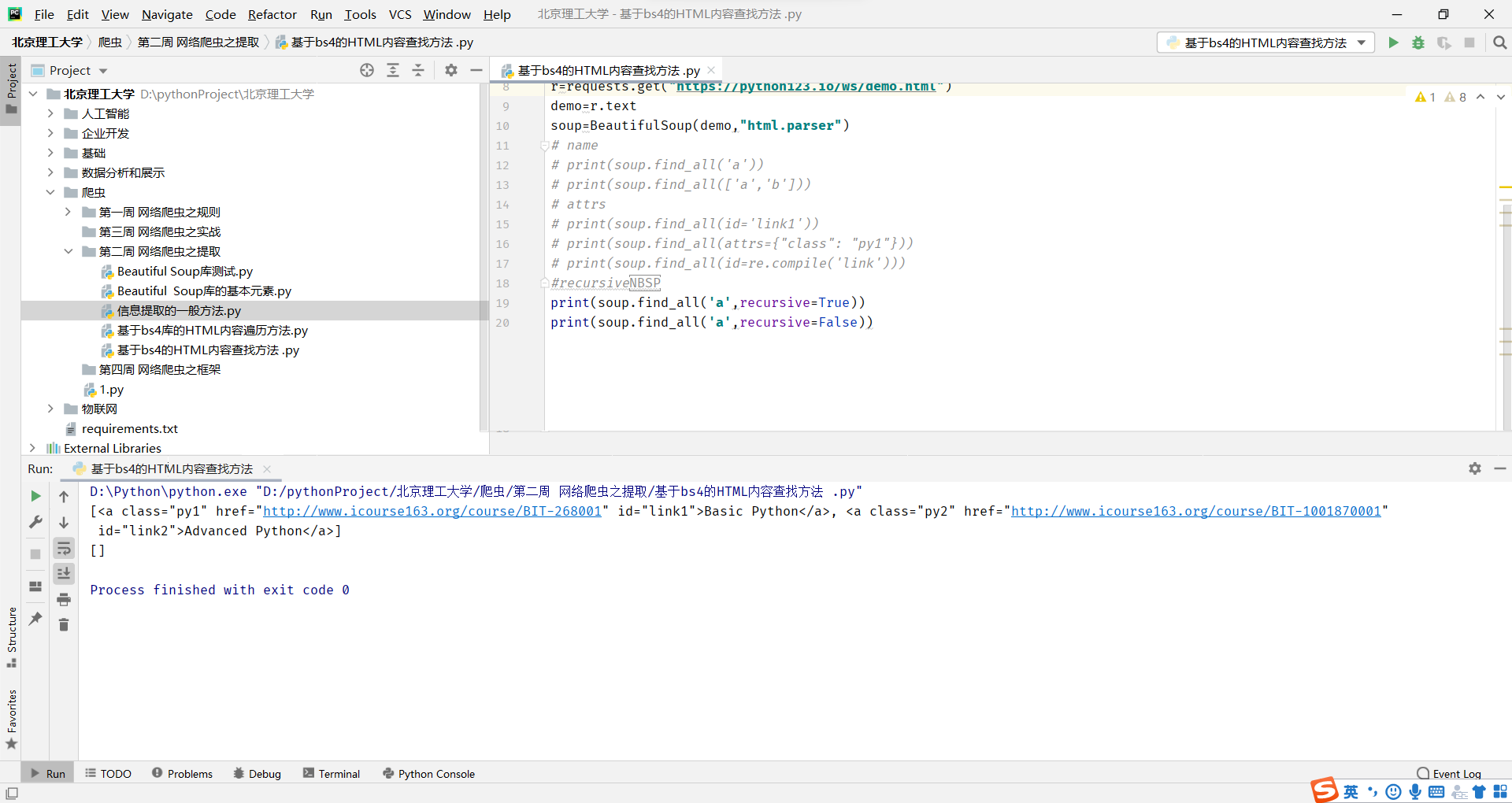
recursive
是否对子孙全部检索,默认True
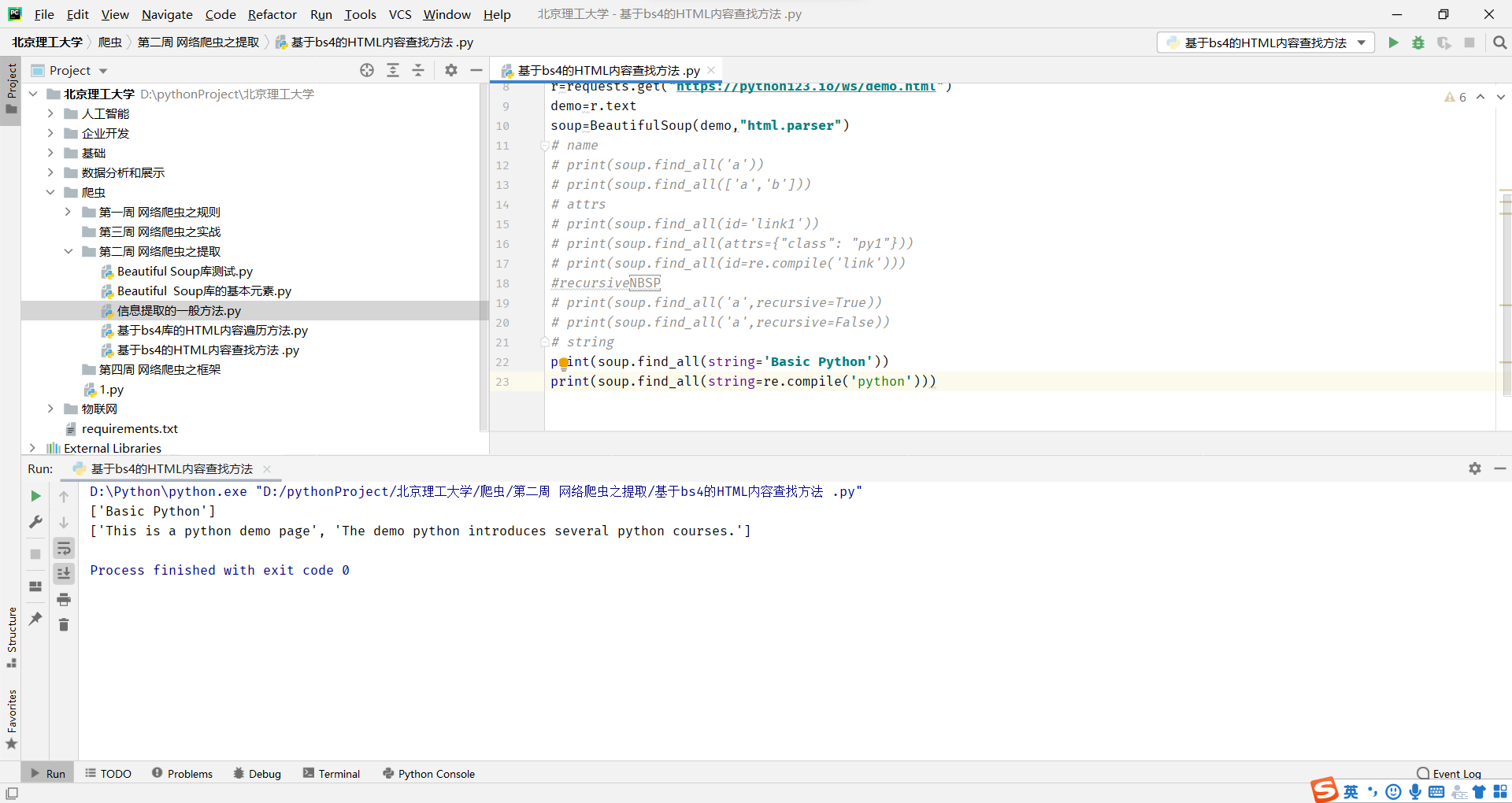
string
<>……</>.中字符串区域的检索字符串
因为在美味汤中经常使用find_all()方法,因此有简化


中国大学排名定向爬虫
2023浙江的大学排名 什么院校最厉害_高三网 (gaosan.com)
 结构分析
结构分析
import requests
from bs4 import BeautifulSoup
import openpyxl
url = 'http://www.gaosan.com/gaokao/571199.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'
}
response = requests.get(url,headers=headers)
response.encoding=response.apparent_encoding
soup = BeautifulSoup(response.text, 'html.parser')
# 获取省市序、学校名称、省市、类型前十名信息
table = soup.find('table', {'border': '1'})
rows = table.find_all('tr')
for row in rows[1:11]: # 取前十名
cols = row.find_all('td')
rank = cols[0].text.strip()
school_name = cols[1].text.strip()
province_city = cols[2].text.strip()
school_type = cols[3].text.strip()
# 输出信息
print(rank, school_name, province_city, school_type)
with open("1.txt",'a',encoding='utf-8') as data:
data.write(rank+' ')
data.write(school_name+' ')
data.write(province_city+' ')
data.write(school_type+' '+'\n')这段代码首先使用requests库和BeautifulSoup库爬取了指定URL的网页内容,并获取表格中前10名的省市序、学校名称、省市、类型信息,然后使用print函数将这些信息输出到控制台。
接着,使用open函数打开一个名为“1.txt”的文件,使用"a"模式,即在文件末尾追加内容,并指定编码为utf-8。然后使用with语句打开文件,将获取到的省市序、学校名称、省市、类型信息写入文件中。每个信息之间用空格分隔,每行信息以换行符结尾。
在循环结束后,文件会自动关闭。最终,该代码会将获取到的前10名的省市序、学校名称、省市、类型信息保存到名为“1.txt”的文件中。