这是一篇发在CCS 2019的研究区块链和联邦学习结合的short paper
摘要
联邦学习在支持协作学习方面很有前景,协作学习的应用涉及到大型数据集合、大规模分布的数据所有者、不可靠的网络连接。为了保护数据隐私,现有的联合学习方案采用(k,n)- threshold秘密共享机制,基于对客户的半诚实假设 来实现本地模型更新交换中的安全多方计算,以处理随机客户退出的问题。这个交换是以增加数据量为代价处理随机客户端退出的。因为采用半诚实假设,因此它们很容易受到而已客户的影响。在这项工作中,我们提出了一个基于区块链的隐私保护的联合学习框架即BC based PPFL。该框架利用区块链的不可篡改行和去中心化的信任特性来提供模型更新的证明。我们对于该框架的实验证明,它在联盟链中安全聚合本地模型的更新是有效的。
引言
联邦学习最开始是谷歌为了促进大规模的协作学习提出的,它不再需要将分布在多个设备上的数据样本传输到数据中心来训练或更新全局模型。在这个方法中,每个设备训练本地的模型,或者交换更新后的本地模型,以计算全局模型的更新。这和传统的集中式学习相比,联邦学习降低了把原始数据从客户端移动到数据中心的成本,而且利用了每个设备的计算资源。此外,由于本地数据没有离开设备,联邦学习提高了用户的隐私性。有了以上的理想属性,联邦学习支持大型数据集和大规模分布式数据所有者的协作学习应用是很乐观的。
早期的FL设计假定中间结果,如随机梯度下降的参数更新,包含的信息比原始训练数据少[6]。因此,短暂的更新往往被暴露出来。然而,这些梯度可能会泄露本地数据项的重要信息,特别是当数据结构等元数据可用时。**为了解决这个问题,最近提出了几种FL的安全聚合算法[2,3],利用秘密共享和差异化隐私技术。**然而,这些方法假定参与的客户端是一个松散的联盟,他们可能会在没有预谋的情况下加入或离开学习任务,因此受到随机客户端退出的影响。[3]提议采用(k,n)阈值秘密共享来提高对无计划加入或退出的稳健性。事实上,这些方案的安全保证植根于对客户的半诚实假设,即假设客户不会提交 "假 "份额,也不会相互勾结操纵学习过程或结果。这是一个很强的假设,特别是当更新的来源被认为是 “不被聚合算法所需要”,并且更新 “可以在没有识别元数据的情况下被传输”[6]。此外,几乎所有关于FL的现有工作都明确或隐含地采用了一个简单的激励模型,即假设客户自愿参与协作学习,以交换他们的本地模型更新和计算资源来换取一个改进的全局模型。这种扁平的激励模型忽略了这样一个事实:具有不同数据规模和计算能力的客户在全局优化任务中做出了不同的贡献,应该得到不同的奖励。
Note1:
一般的联邦学习存在三种问题:
1.采用半诚实假设,假设一半的客户端所上传的数据、训练的模型都是正确的,因此无法避免半数以上的客户端联手造假;
2.客户端可能在参与训练的过程中随机加入或者退出;
3.假设客户端都是愿意参与模型训练的,对于不同算力和贡献的用户,奖励机制应该要存在差异,才可以更好地促进协作学习。
我们提出了一个基于区块链的隐私保护的联合学习(BC-based PPFL)框架。
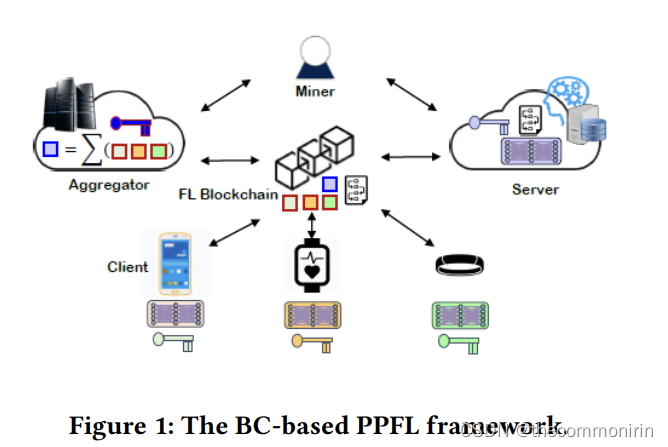
首先,区块链将联邦学习组件如服务器、客户端和聚合器等连接起来了。它使用分布式交易账本来记录各组件之间关于FL任务、参与的客户、本地和全局模型更新等的信息流。其次,不可变的账本通过跟踪每个FL任务中的数据流来支持数据出处,并提供一个良好的信任基础来建立现有FL方法所缺乏的验证机制。有了这样的验证机制,我们可以进一步将半诚实的客户假设扩展到更现实的恶意客户假设,在这种假设下,客户可以退出,提交虚假的本地更新,或与其他恶意客户勾结。此外,通过分布式账本,服务器以及FL任务中的其他相关实体(如客户和聚集者)可以跟踪每个客户对全局优化学习模型的贡献,这使得基于贡献的激励机制成为可能。在此基础上,我们可以进一步引入对改进模型所有权的溢价,并对矿工进行相应的奖励。
BC-BASED PPFL FRAMEWORK
联邦学习模型
联合学习的主要目标是在大量客户的所有数据上训练一个全局共享模型,其中每个客户安全地维护自己的数据。虽然已经为FL提出了不同的学习任务,但在这项工作中,我们采用了[6]中介绍的联合平均模型,其中一组固定的K个客户 支持nk个数据点,以固定的学习速率η计算其本地数据与当前模型wt的平均梯度。fi(wt )是对局部数据点的预测,因此每个客户端可以更新其本地模型,服务器将收到的本地模型更新汇总后来更新全局模型。
基于 BC 的 PPFL 的主要隐私目标是 (a) 通过不将本地数据点运出设备,保护本地数据点免受任何外部实体的影响;(b) 通过不将单个本地模型更新泄露给服务器,保护本地数据免受服务器的影响;以及© 保护本地和全局模型更新免受不相关的内部。
即保护本地和全局模型的更新不受内部(即聚集者、矿工)和外部实体的影响。同时,安全目标是确保来自承诺客户的本地模型更新的保密性和完整性和模型更新的来源。
Note2:
poster这个框架采用FL平均模型,主要是针对隐私问题做出了贡献:
1.不会把客户端的数据泄露出去;
2.本地模型的更新不会泄露给服务器(原文是protect local data from the server by never leaking individual local model updates to the server,根据上下文和框架图应该是本地模型训练参数通过blockchain(BC)给聚合器,然后聚合器进行全局更新事务);
3.在框架的耦合上,各模块分离,服务器,矿工(minier)不会影响其更新。
架构
BC-BASED PPFL FRAMEWORK组成元素如图1,对于FL任务,服务器首先公布任务规格,如应用类型(如按键或活动预测)、设备类型、训练数据的类型和格式(如陀螺仪或运动传感器数据、浮点格式)、学习模型的类型(如CNN)、计算要求(如学习率),以及任务设置(如聚合器、所需客户数)、所需的客户数量、批量大小等)的任务交易。愿意加入任务的客户向聚合器注册,聚合器为所有承诺的客户创建一个承诺交易。最后,矿工将所有的交易记录到账本中。
在FL任务中,服务器首先与所有承诺的客户共享初始模型。为了保护模型的隐私,这个初始模型是在 在受保护的模式下。然后,客户通过他们的本地训练数据计算本地模型更新,并将更新的模型参数上传到聚合器。聚合器在同一批次中收到的所有更新将被包裹在本地更新交易中,并在矿工的协助下记录到分类帐中。
创建区块
基于BC的PPFL依靠三个构件来提供FL中的数据隐私和来源。
同态加密和代理重新加密
现有的保护隐私的联合学习方法大多采用秘密共享方案来实现安全的多方计算(MPC),这些方案会受到随机客户端掉线的影响。为了解决这个问题,我们采用了由Cramer和Shoup[4]提出的带有两个陷阱门函数的Paillier密码系统的变体,在模型交换过程中保护本地模型。
在我们的设计中,服务器为每个任务生成一对公共和私人任务密钥,并将公共任务密钥包括在任务规范中,而参与任务的每个聚合器生成一对公共和私人批次密钥,并将公共批次密钥分配给每个承诺的客户端。任务密钥和批密钥的构造形式是,批密钥是对应任务密钥的转换密钥,以支持代理重新加密。因此,服务器不能直接恢复记录在账本上的单个本地更新,相反,它只能在聚合器聚合更新并以转换密钥重新加密后恢复聚合值。
Note3:
关于BC上具体有3种区块(原文relies on three building block)。
1.是同态加密和代理重新加密,简单来说是为每一次task生成一对密钥,使得服务器只拥有单个密钥是无法查看本地模型的更新;
2.采用POW,POS作为共识机制,对不同改进模型的客户端提供不同的奖励;
3.区块链的溯源机制可以回溯之前的聚合,排除恶意更新。
Note4:
这篇论文与委员会共识不同在于
1.在共识层上使用的POW,POS而不是PBFT;
2.区块链之外额外增加了服务器,如果改进的话可以改进成区块链同时充当服务器,聚合器;
3.在应用层上,采用PBFT共识是通过采用了委员会进行排除恶意节点
。
区块链
已经有一些关于使用区块链的提议来支持深度学习[7]和联合学习[5]的激励措施。虽然我们采用了区块链来证明和验证,但区块链网络的逻辑设计是相似的。矿工在物理上可以是任何具有足够计算资源的节点,以运行工作证明(PoW)或取证(PoS),并将任务、承诺和更新交易记录到任务区块中。区块链的使用也使得基于贡献的激励机制成为可能,据此,我们对服务器持有的改进模型的所有权引入溢价,并相应地奖励矿工。每个区块的大小与头和学习率η有关。同样值得注意的是,对于大型数据集上的大型模型更新,我们可以将加密的模型更新存储在分布式数据库中,如IPFS[1],并在区块链中只记录地址。
验证
区块链记录了加密模型更新的流量,这使得跟踪和验证客户对全局优化模型的贡献成为可能。特别是,验证者可以在一个批次中检索所有客户端的更新,生成排除可疑客户端输入的集合,并比较验证前后的全局模型的性能。在初步实验中,我们实现了基本的验证功能,其中服务器作为验证者,在每一轮中恢复总量后评估梯度。它使用损失函数将更新的全局模型的性能与该轮的初始模型进行比较。
Proof-of-Concept的实现和评估
我们在Python中开发了一个Paillier密码系统的变体,以实现同态加密和梯度聚合的代理再加密。我们在以太坊上建立了区块链,并使用Truffle套件控制链上操作,该套件是以太坊的开发和测试框架。最后,为了评估我们提出的框架的性能,我们采用了深度学习库PyTorch的nn包进行FL任务。
Settings
我们使用一个简单的两层神经网络建立了一个二元分类器,并使用UCI机器学习库的乳腺癌数据集作为训练数据。该数据集有569个样本和30个特征。对于我们框架中使用的所有三个密码系统,我们生成了默认长度为2048位的公共和私人密钥对。
我们在一个具有1GiB内存和3.3GHz英特尔可扩展处理器的亚马逊EC2 t2.micro实例上运行区块链。对于服务器、聚合器和客户端节点,我们采用了两种设置:在设置一中,我们在一台具有2GHz英特尔核心i5处理器和3GiB内存的笔记本电脑上运行所有三种类型的节点,从这里它们可以与亚马逊EC2上实现的区块链进行交互;在设置二中,我们也在亚马逊EC2实例上运行它们,这最大限度地减少了通信延迟,因为所有实例都在同一个云平台。在未来,我们将通过在多个云平台上部署不同的节点,进一步研究我们框架的可扩展性和通信延迟。
评估
为了评估我们方案的性能,我们为FL模型的训练做了一个相当小规模的实验。我们首先将训练数据随机分配给10个客户端,每个客户端有50个来自IID分区数据的例子。然后,我们测量了不同FL操作的执行时间(即模型加密、本地模型更新、聚合、本地更新的区块链写
和梯度平均,以及全局模型更新)。
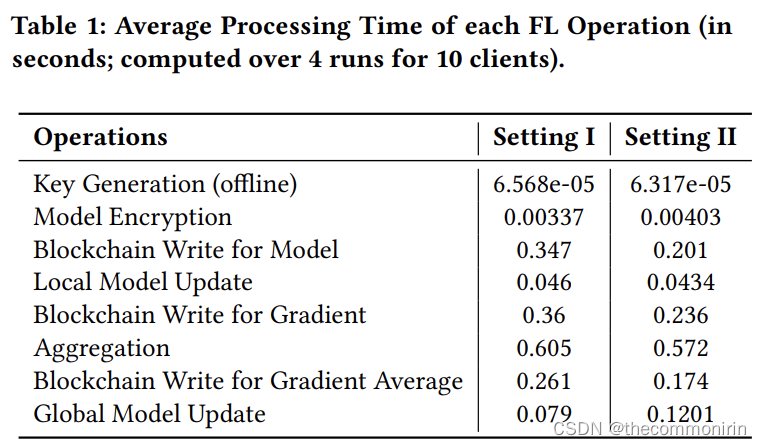
我们重复了四次模型训练,计算了一次迭代的平均执行时间,如表1所示。很明显,在两种设置下,聚合梯度和将结果写入区块链是所有FL操作中计算成本最高的操作。每个迭代的平均执行时间是所有FL操作的总和,在设置一和设置二中分别为1.62和1.27秒。两种设置之间的差异表明了对区块链的读写所引入的通信成本。所提方案的性能,特别是梯度聚合和区块链写入操作,与参与PPFL任务的客户端数量有关[6]。因此,我们将客户端的批量大小增加到20、30和40,并测量执行时间。平均执行时间从10个客户端的1.62秒分别增加到20、30和40个客户端的1.73、2.36和2.43秒。这表明,增加客户端的数量会导致协议执行时间的亚线性增加。
总结和未来工作
我们提出了一个保护隐私的联合学习框架的设计,该框架按照一个加密协议对私有数据进行梯度聚合。我们设计了一个Paillier密码系统的变体,以支持加法同态加密和代理再加密,从而使加密的本地模型更新可以被聚合并转化为可由服务器恢复的形式。在整个过程中,单个本地模型更新受到保护,不受服务器、聚合器和其他客户端的影响。而全局模型的更新则在参与的客户之间共享。
通过在PPFL过程中整合区块链,我们可以克服随机的客户端退出,因为他们的本地更新是异步写到区块链。此外,由于全局账本的不变性和数据出处属性,它提供了一个 识别和排除恶意客户端更新的手段。我们的初步实验结果显示,基于BC的PPFL支持的模型训练,并提供更好的透明度和可验证性,同时保护数据隐私。
在未来,我们将探索联合优化,在客户端的每个训练纪元中加入小批处理,并增加多客户端的并行性,以实现目标测试集的准确性。我们还将考虑非IID分区的数据,并研究激励方案,根据客户的贡献来奖励他们。