目录
一、垃圾回收算法
截至目前,Java的垃圾回收算法只有3种。
标记-清除(Mark-Sweep)、标记-整理(Mark-Compact)、复制算法(Copying)。
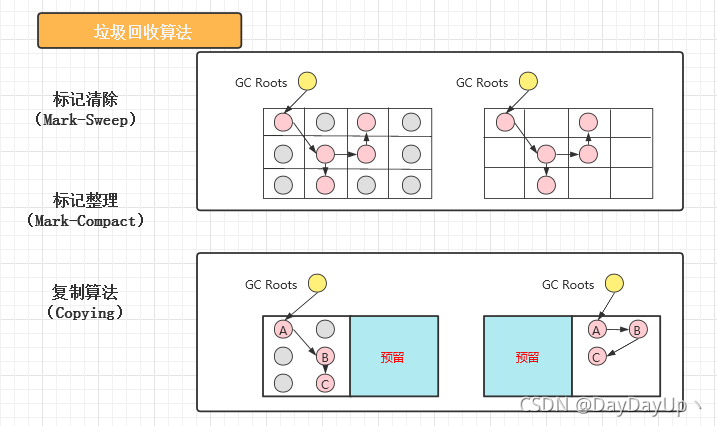
1.1、标记-清除
如上图,先标记再清除,会有碎片,导致内存不连续,可能无法分配大对象,因为大对象所需的是连续内存。
1.2、标记-整理
标记后,将所有存活对象向一端移动整理在一起,避免碎片,但需移动对象导致效率低。
1.3、复制算法
如上图,预留一半内存,没有内存碎片,但仅有一半内存空间可用。一般用于年轻代的Minor GC。
二、垃圾回收器
截至目前,Java官方的垃圾回收器有10种左右,是基于3种垃圾回收算法以及分代/分区模型发展而来。
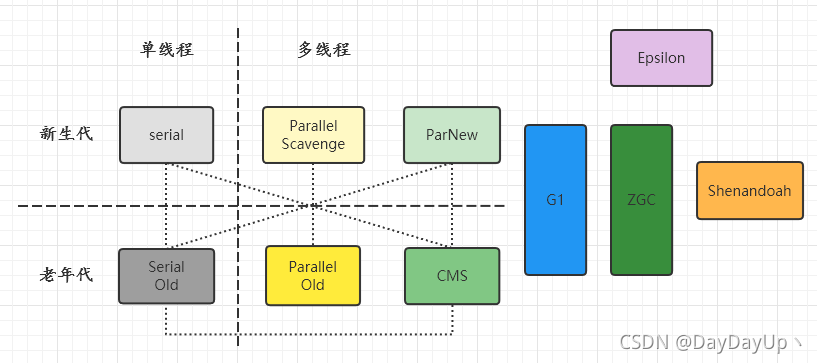
如上图,根据GC单线程或多线程、新生代或老年代、分代模型或分区模型划分,垃圾回收器之间又通过连线反映出它们可以搭配使用。
2.1、Serial串行回收器
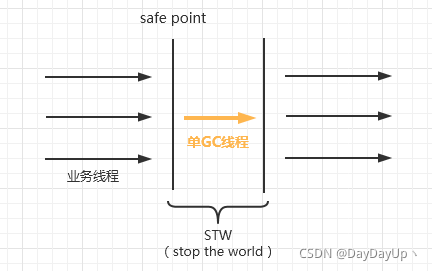
如上图,只有一个GC线程,回收效率较低,不适用于服务端,可适用于单机客户端。
2.2、Parallel并行回收器
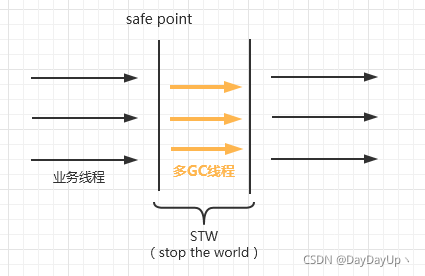
如上图,多个GC线程回收,相比Serial回收器的STW时间缩短,效率相对高一些。PS回收器吞吐量优先,而ParNew回收器响应时间优先,可以与CMS回收器搭配使用。
2.3、CMS并发标记回收器
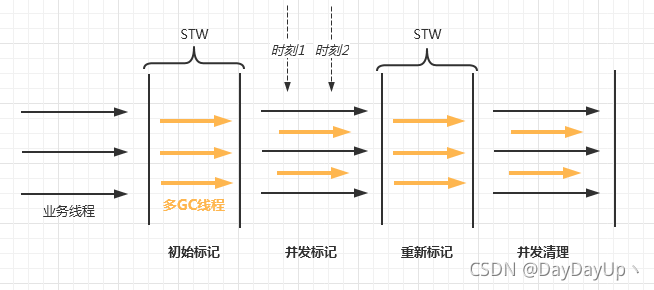
CMS(Concurrent Mark Sweep),“并发”意为GC线程会在标记-清除过程中与业务线程一起执行。过程如下图。
主要步骤:
- 初始标记,需要在线程安全点(Safe Point)处STW,不过它只会标记与GC Roots直连的对象。
- 并发标记,多GC线程一边为初始标记对象开始标记下面的引用的对象,业务线程一边执行,这个过程是没有STW的,所以可能时刻1进行标记后,时刻2的引用状态又发生了改变。为记录并发标记这个过程或状态,用到了三色标记法。
- 重新标记,对三色标记的缺陷进行补偿处理。
- 并发清理,针对前面三次标记的结果进行清理。
2.3.1、三色标记法
三色标记原则:
- 黑色,代表根对象,或对象本身以及它直连引用的对象已被GC线程扫过;
- 灰色,中间状态,代表对象本身已被GC线程扫过,但其引用对象未被扫过;
- 白色,代表对象本身(当然包括其引用对象)未被扫过。
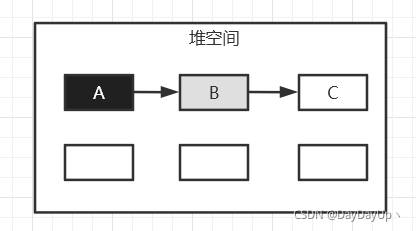
比如时刻1的GC线程只扫了A和B,却尚未扫B的引用,此时A被置为黑色,B被置为灰色;到了时刻2,继续扫到了B的引用C,则B才会被置为黑色。这样就可以反映出并发标记这一片段的时刻状态,多个GC线程才可以随时协同。
但是三色标记是有缺陷的,在并发标记中的时刻2,可能业务线程将B到C的引用删了,等到清理时,黑色的C对象不会被认为是要清理的垃圾,C对象会变成浮动垃圾,需要等到下一次GC才有可能清理掉。而浮动垃圾对象需要被另外存下来。

2.3.2、CMS对浮动垃圾的解决方案
要在内存空间90%的时候触发GC,另外10%空间存放浮动垃圾。若100%才触发GC,则浮动垃圾会没有新空间进行保存。
三色标记还有另外的缺陷——漏标。

如上图,并发标记的时刻2,引用状态发生改变,业务线程删除了B对C的引用,又将A新增引用到C。
此时B已经不再引用C,所以B变为黑色,由于A已经被置为黑色,代表A下的引用都被扫完,所以不会再去由A扫到C,导致C被漏标,被当做垃圾。
2.3.3、CMS对漏标的解决方案
增量更新(Incremental Update),类似于数据库的触发器,在监测到A到C新增引用后,触发自动标记将A置灰,这样就需要下一次STW进行重新标记,从灰A重新扫一次扫到C。
但是由于CMS的多线程GC实际上是更复杂的,加上GC线程本身就是多线程,存在线程同步线程安全的问题,不会为了线程安全的最可靠性,而牺牲GC效率,所以CMS仍旧可能存在漏标等问题。
2.4、G1回收器
科技时代在发展,机器内存越来越大,Java的垃圾回收器也在跟着发展。分区模型在面对大内存时代的优势体现出来。
G1回收器(Garbage First,垃圾优先)自jdk1.8引入,也是在CMS回收器的基础上进行改进,划分堆内存,也是并发回收,适用于堆内存大的场景。具有以下特点:
- 标记阶段跟CMS类似(对漏标处理方式不同)
- 筛选回收(分区模型的优势)
- 复制+标记整理算法(没有内存碎片)
主要步骤:
- 初始标记
- 并发标记
- 最终标记
- 筛选回收
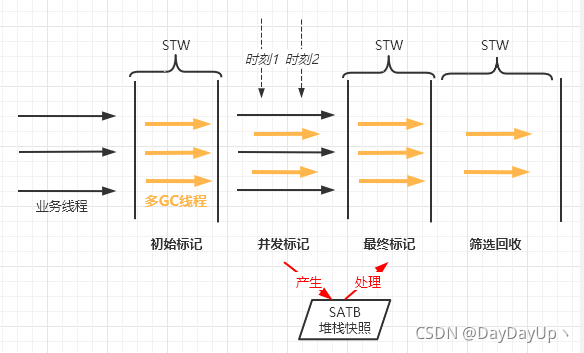
2.4.1、G1对漏标的解决方案
堆栈快照SATB(snapshot-at-the-begining),同样假设并发标记的时刻2,引用状态发生改变,业务线程删除了B对C的引用,又将A新增引用到C。
在B到C的引用删除时,会在GC线程的堆栈中快照记录下B到C的引用改变,时刻2之后,在堆栈快照中找到C并处理C,这一步作为G1的最终标记步骤。
2.4.2、G1的分区模型
将堆内存按照默认的优化策略划分为多种地址连续的小块,内存小块又被标记或区分为不同的用途,如下图,E代表Eden,S代表Survivor,O代表Old,H代表Humongous,几块H区相连,专门用来存放大对象等。
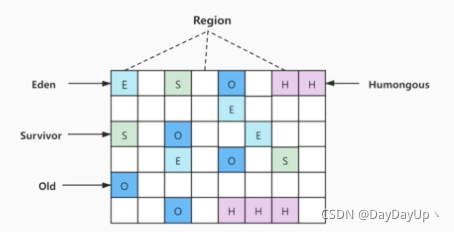
分区模型的优势在于,面对越来越大的内存空间,一般的标记清理算法可能在清理整块内存时会越来越慢,就比如从前是一个人扫一条街不算吃力,后来街区越来越大扫起来会相对地变慢,这会直接导致STW时间变长,严重影响效率。
所以筛选回收就很灵活,它可以不用扫所有的大街,指哪打哪,定点打击,可以优先去处理指定的Old区等真正的垃圾区(Garbage First,垃圾优先),清理价值更高。