性能问题因素图
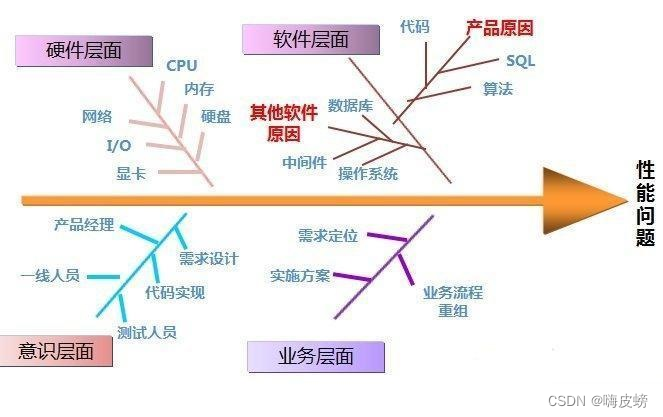
性能问题
1,需求问题及处理
问题:需求要求 innodb表(非myIsm)的千万级数据量的实时更新汇总,sql语句是:
select count(*) form 表
优化方案1:
创建统计表,每增加数据时统计表执行+1操作。弊端:数据库IO开销增加
优化方案2:
每日定时更新统计表的数据汇总。弊端:非实时更新数据汇总
优化方案3:
使用redis记录增加数据时统计字段执行+1操作,每日定时写入数据库
2,硬件问题
CPU1核、运行内存1G 压测并发能抗100
CPU8核、运行内存16G 压测并发能抗5000
3,数据库设计
a,冷热数据分离
b,text(64kb)、mediumtext(16MB)和longtext(4GB)字段切分使用varchar存储
c,innodb索引的添加和使用,优化sql语句where条件,使用explain语句进行索引命中率优化
4,架构设计
a,技术选项,如laravel可以使用swoole加速
b,数据库尽量不存储超文本数据和二进制多媒体文件(音频、视频、图片等)
c,使用缓存(客户端资源请求缓存(图片、js、css)、服务请求缓存(nginx)、服务逻辑缓存(php)、数据库请求缓存)
Linux性能查询命令以及管道
1,ps命令(查询进程)
进程CPU占用率倒叙前十进程:
ps -aux --sort=-%cpu|head -n11
进程运行内存占用率倒叙前十进程:
ps -aux --sort=-%mem|head -n11
进程运行内存占用倒叙前十进程:
ps -aux --sort=-rss|head -n11
查找MySQL的进程
ps -ef|grep mysqld
ps -ef|grep 3306

stat状态说明:
D //无法中断的休眠状态(通常 IO 的进程);
R //正在运行可中在队列中可过行的;
S //处于休眠状态;
T //停止或被追踪;
W //进入内存交换 (从内核2.6开始无效);
X //死掉的进程 (基本很少见);
Z //僵尸进程;
< //优先级高的进程
N //优先级较低的进程
L //有些页被锁进内存;
s //进程的领导者(在它之下有子进程);
l //多线程,克隆线程(使用 CLONE_THREAD, 类似 NPTL pthreads);
+ //位于后台的进程组;
2,top命令
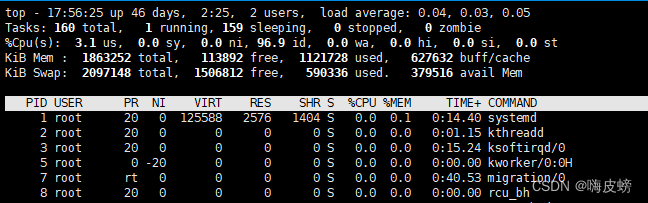
说明参考:linux top命令详解(看这一篇就够了)_Steven.1的博客-CSDN博客_linux top命令详解
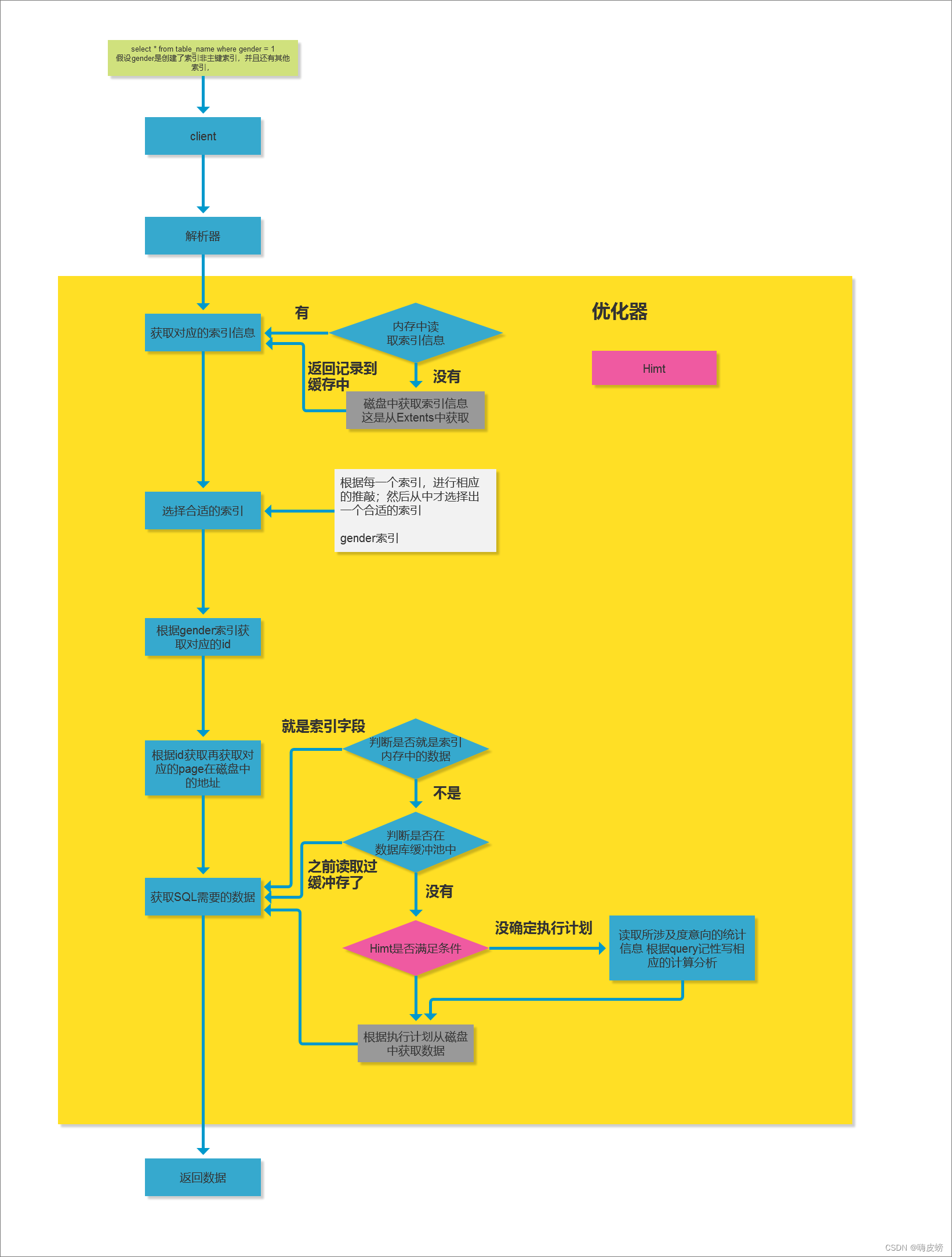
MySQL分页优化
问题:千万级的数据量表分页查询怎么优化?原本的语句:
select count(*) FROM 表 limit 9999999,10
方法1:通过主键子查询和主键搜索优化
select count(*) from 表 where id >= (select id FROM 表 limit 9999999,1) limit 10;
方法2:先查分页的id,再用in的查询
select count(*) from 表 where id in (select id FROM 表 limit 9999999,10);
如果报版本不支持的错误:This version of MySQL doesn't yet support 'LIMIT & IN/ALL/ANY/SOME subquery'
则改为
select * FROM 表 where id in (SELECT t.* FROM (select id FROM 表 limit 1) t);
方法3:增加查询字段的索引(针对单表优化)
索引类型:
btree索引(适合范围查询,【二叉树算法】,会降低数据写入速度,比hash索引还要慢一些)
hash索引(适合类别查询,【哈希算法】)
fulltext索引(适合长文本查询,【文本按字数拆分】,一般用es分布式搜索引擎代替)
R-tree索引
方法4:垂直(单表一百万的数据量)和水平分表(冷热数据拆分)
MySQL-IO的执行过程