文章目录
1 A/B实验
1.1 优点
- 通过流量细分可以同时追踪多个指标的变化趋势
- A/B测试的解释性更好,适用于获得各个版本的优劣的统计置信(statistical significance)。需要知道当前版本相对于base的各个指标如何变动、置信水平有多大、什么因素影响了指标变动。这些关于因素的分析可以用来指导后续的产品迭代
1.2 缺点
- 评估实验组与对照组的显著差异,用显著性假设检验,但是无法度量具体的因果效应
1.3 使用场景
- A/B测试适合测试一些周期较长的变化,且对结果分析获得的规律可以对后续工作产生指导
- 小流量实验可以避免直接上线效果不好造成损失。其次,实验迭代的过程中,决策都是有科学依据的,可以避免系统性的偏差。
- A/B 测试是可以持续不断进行的实验,即使一次实验提升的效果不大,但是长期下来复利效应的积累会产生很大的变化和回报。
参考:
A/B Test︱一轮完美的A/B Test 需要具备哪些要素
2 因果推断
2.1 优点
因果推断可以更加全面的了解问题:
- 关联问题:如果观察到因素X,因素Y会怎么样?
- 干预问题:如果改变了因素X,因素Y会怎么样?
- 反事实问题:假如因素X没有发生,会如何?
2.2 缺点
- 计算代价比较大,基于三大基础假设
2.3 使用场景
含有大量观测数据的情况下,可以使用各类合成A/B的方式,包括matching、合成控制等
- 评估干预因素的影响
- 需要反事实推理,评估一些决策因素异质性的场景
- 当实验对象不是个体粒度,而是一个特定的地理区域时,我们比较难找到同质的对照组,这时候需要用合成控制法来拟合出一个群体作为对照组
2.4 一些大厂方法论的总结
参考【因果推断笔记——数据科学领域因果推断案例集锦(九)】:
腾讯看点分享的【2-1观测数据因果推断应用-启动重置体验分析】文章中,比较明确的将实验、观测数据进行拆分,并在各自数据状态下,适用不同的方法:
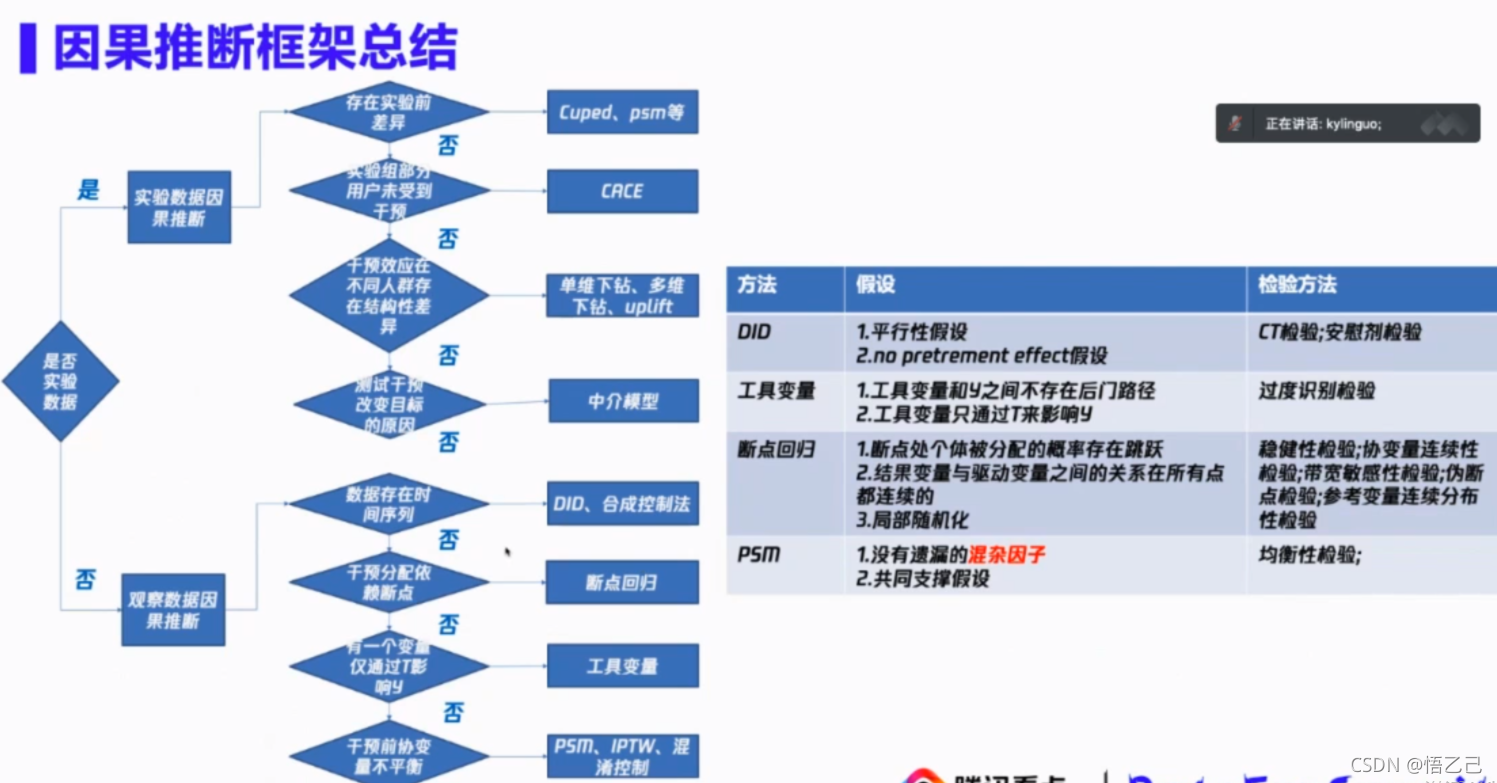
第二个版本目前解决各个分析场景的方法论框架:
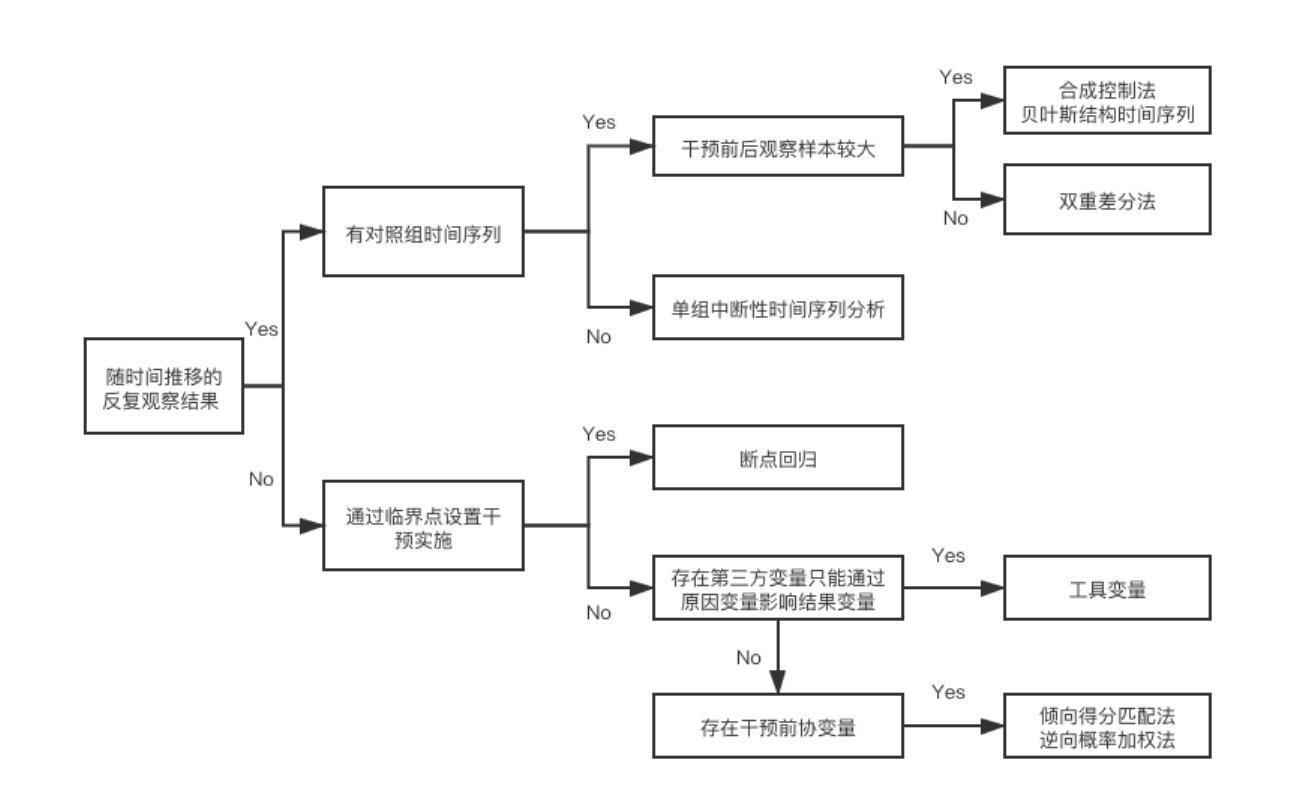
一些无法进行随机实验的场景下,会需要合成控制的方式
大部分运营和产品在评估效果时,最常用的方法就是effect = 上线后效果-上线前效果。这种方法最大的问题在于其关键假设,即上线的功能或者活动是唯一影响效果的变量。但是想想就知道这个假设是有多么不合理。
升级版的评估方案,可能会找到一个城市或者大盘来和上线的城市做对比,这种想法非常类似DID,但是这个里面也隐含着一个关键假设,即可以找到长期变化趋势高度同步的城市,这点对于有较强地域性的商业来说就非常困难。
还有一篇因果推断实战:淘宝3D化价值分析小结:
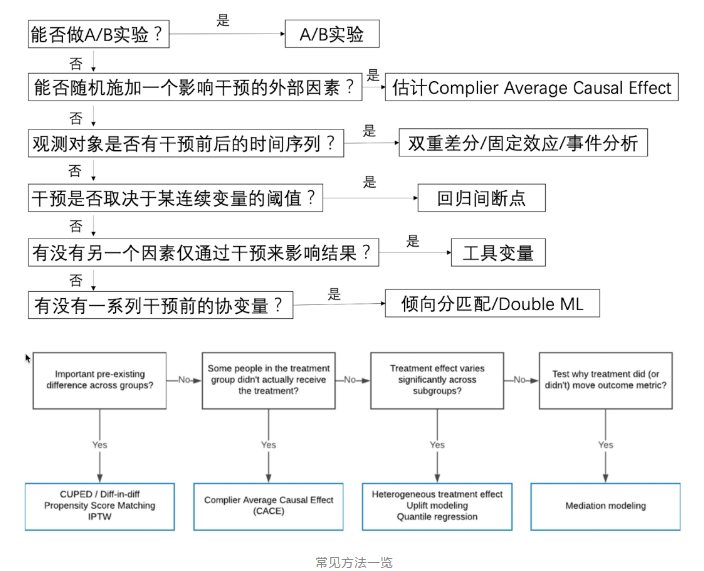
在datafun数据科学峰会中《5-1 数据+金融营销的思考与应用》提到的结合用户增长+因果推断:
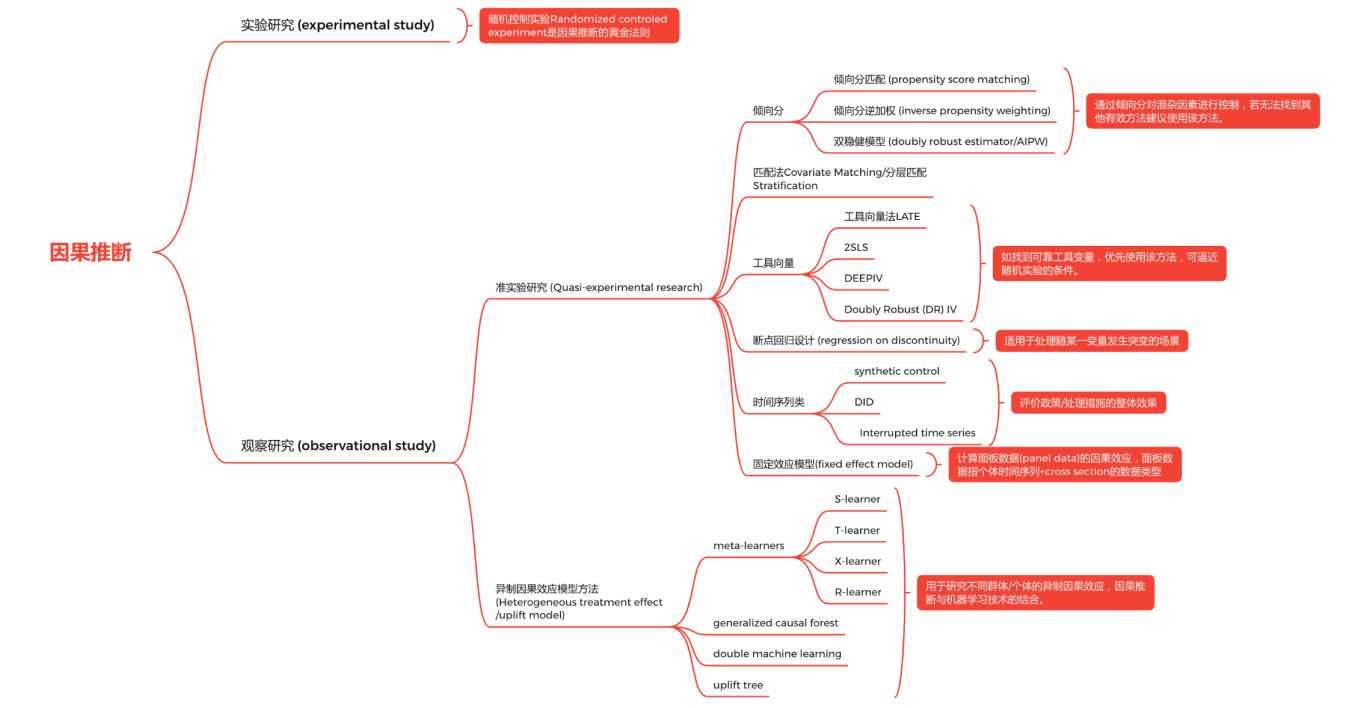
节选datafun数据科学峰会:《9-3 电商搜索场景下的数据科学实践》
京东内部的因果推断基础框架整理:

3 多臂老虎机Bandit
3.1 优点
- 根据用户实时反馈智能分配,并保障收益最大化,可以对大部分运营实验实现智能化
- bandit实验的主要优点是它相比A/B测试会提前终止,因为它需要更小的样本。
- bandit实验比A/B测试的错误更少。一个平衡的A/B测试总是将50%的流量发送给每个组。随着实验的进行,发送到失败的臂的流量越来越少。
3.2 缺点
- bandits只能对单一指标进行持续优化,虽然可以把多个指标叠加成为一个复合指标,但是bandits的优化目标只能是单一的一个指标。
- bandits的解释性较差,无法进行实验间的对比
- 更小的样本规模带来的便利是以更大的假阳性率为代价的
3.3 使用场景
bandits算法适合一些变化快周期短的优化场景,获得的知识不一定能够解释和泛化:
- 当关心的问题只是转化率、留存率等的单一指标,且不需要对数据结果进行解释和分析。
- 当你的运营活动只有短短的几天或者一天,并没有时间等到A/B测试达到统计置信(statistical significance)时。
- 如果有一些长期需要优化的指标,而这些指标经常发生变化,那么这个也是bandits的一个重要的应用场景。

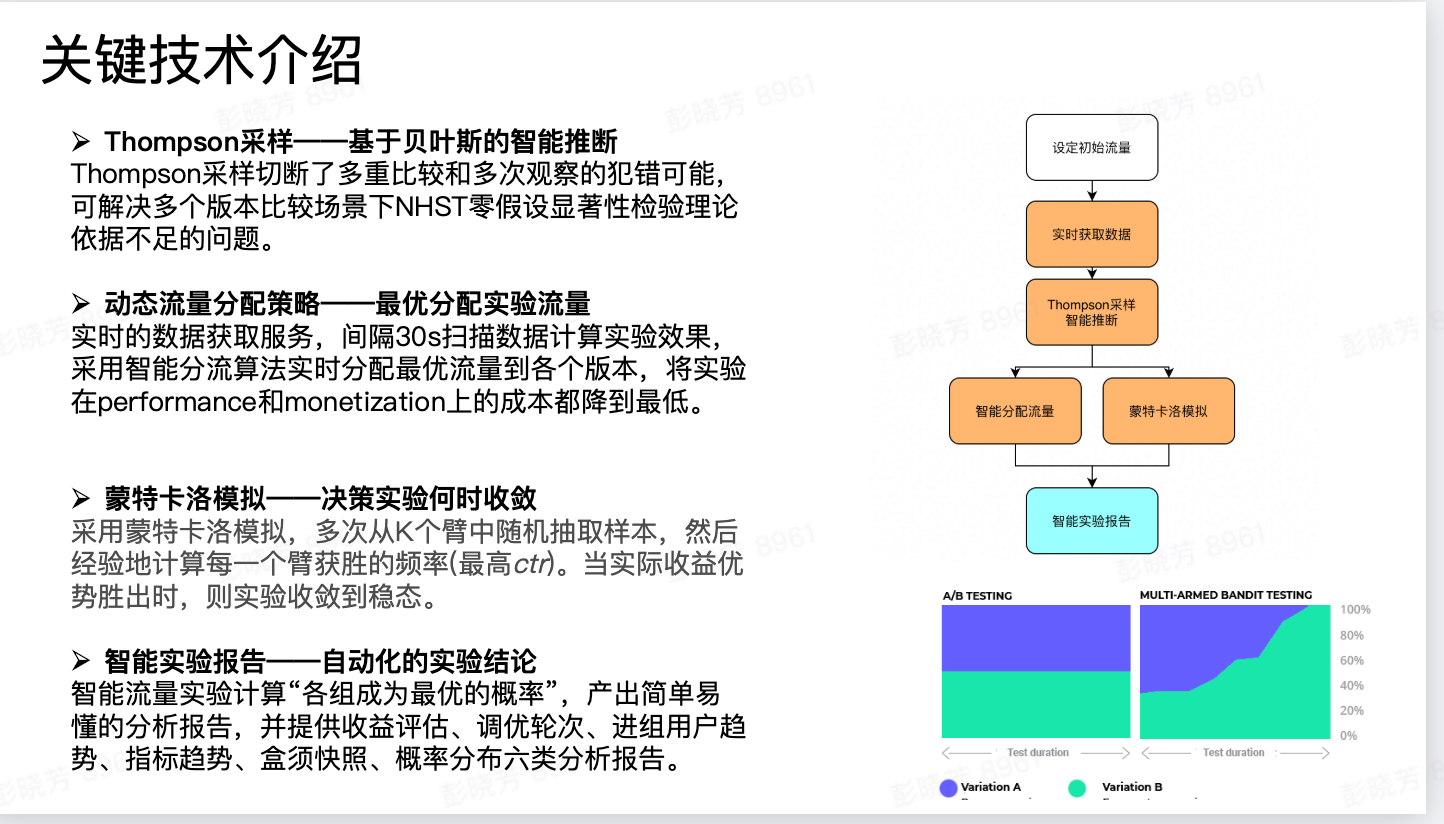
实验开启后无需操作和关注数据,abcd四组文案在每一次下发后都会实时收集反馈,自动根据上一轮的结果决定下一轮发什么,效果好的就加大流量效果差的就干掉,中规中矩的就给一少量流量留用观察,轮过几轮的循环推送,最终从均分,变成了绝大多数流量分给B和D脱颖而出并且旗鼓相当,A文案惨遭淘汰。最终效果相比均分,ctr提升9.2%,一定程度上实现了千人千面。
一旦实验增多,人力无法协调,智能动态调优实验就是一个解放人力的好方案。
参考文献:
多臂老虎机 学习笔记
不只是A/B测试:多臂老虎机赌徒实验
A/B测试增长实战
推荐系统︱基于bandit的主题冷启动在线学习策略
火山引擎:智能调优实验简介