python爬虫逆向js反爬实例教程
前言:
网上关于js逆向的教程还是比较少的,我觉得这对想入门的初级爬虫们非常不友好,所以我这次来分享我的学习经验,希望相关资源能多一点。本次教程有借鉴公众号咸鱼学python的资源,但是由于公众号只提供了思路和解密方法,很多小白还不是很清楚如何运用起来进行爬虫。教程讲述了如何解密以及运用进爬虫的方法。代码写的不是很规范,仅是用来实现功能的版本。如有不足,请大佬们指出。
这是本次网址链接: aHR0cHM6Ly93d3cuemRheWUuY29tL0ZyZWVJUExpc3QuaHRtbA==
(提示:这是一串加密)
一、分析

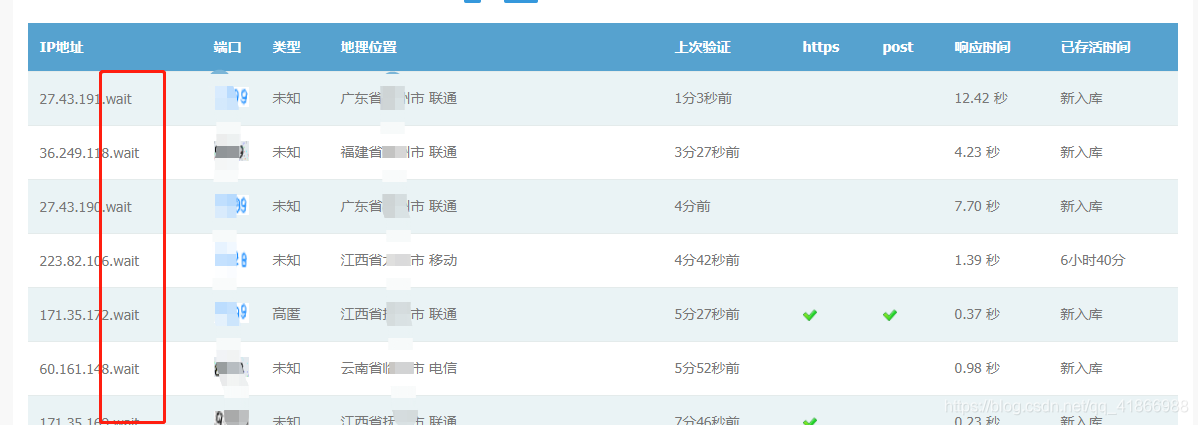
打开网页后找到这个ip地址,我们爬取的需要的就是这个,当然你直接请求这个网站,是肯定请求不到的,不然我写的也没有意义啦,你直接请求的话,遇到的会是这个画面。

明显遇到了阻碍,这个wait,把地址最后的部分给隐藏了,我们现在需要去找到这个wait,是怎么出现的,因为在网页中,ip是正常显示的。
像这种情况,我们先禁用js看看是不是js反爬。
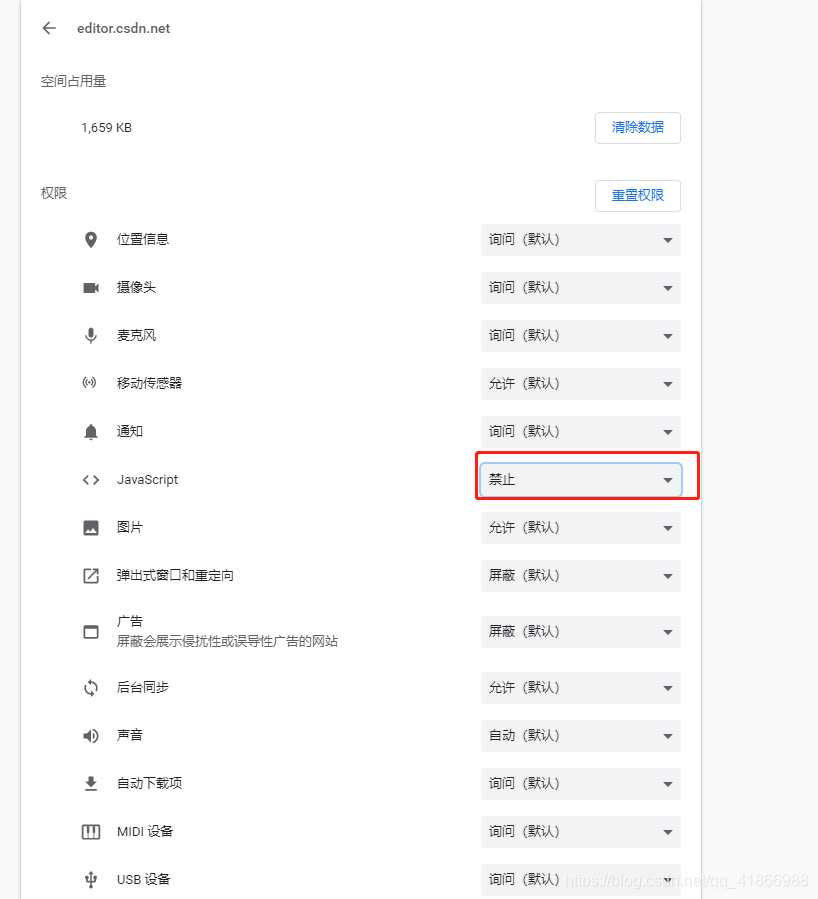
然后重新加载页面,发现wait出来了,可以判断是js控制的。
现在需要定位这个 js 逻辑的位置,打开F12页面,刷新搜索一下wait看看能不能找到有关的内容(记得恢复网页js的允许使用)
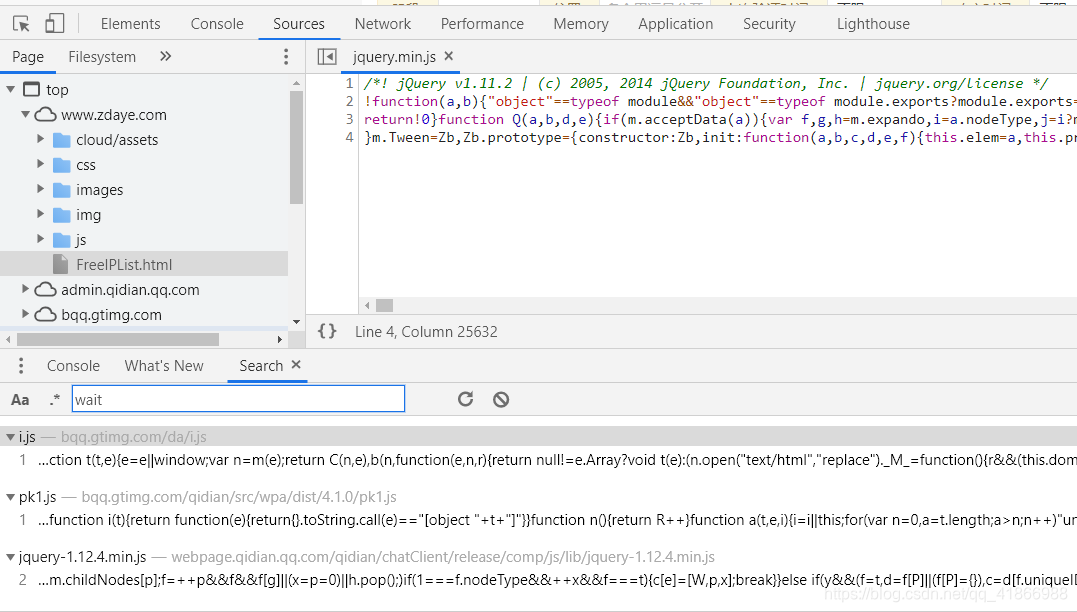
太多不相干的js了,如果有实在找不到其他办法,再回来看看这个吧。

肯定有人想通过这个v来定位,可以重复一下上面的操作,你会发现,检索的结果不尽人意,没有什么有用的信息,想通过这个方法去找到加密的直接可以放弃了。
我们接着回到抓包的页面Network。
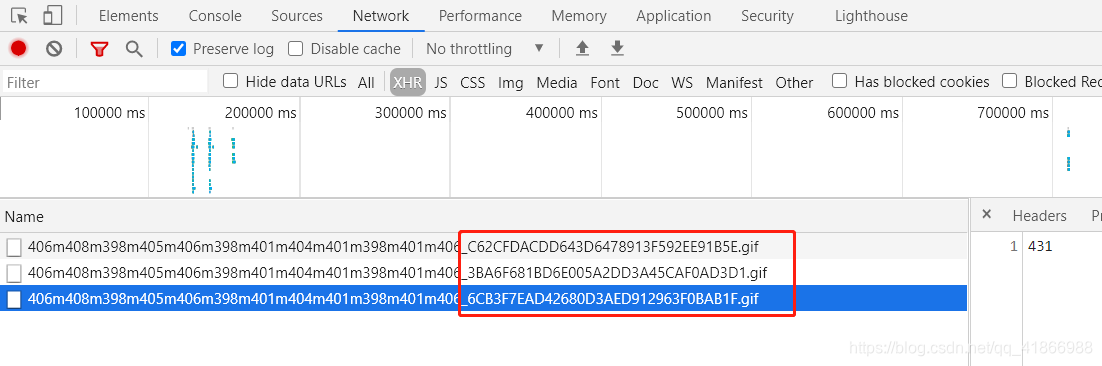
你会发现这几个请求很奇怪,后面红框部分的地方每条还不一样,应该是加密了,返回回来的也是不知道什么意义的数字,但是他是随着页面的加载出来的,所以也算是有研究价值的。
我们现在给它打上断点,红框后面是会变化的部分,我是没有办法给它断点的只能断点这个不变的网址。
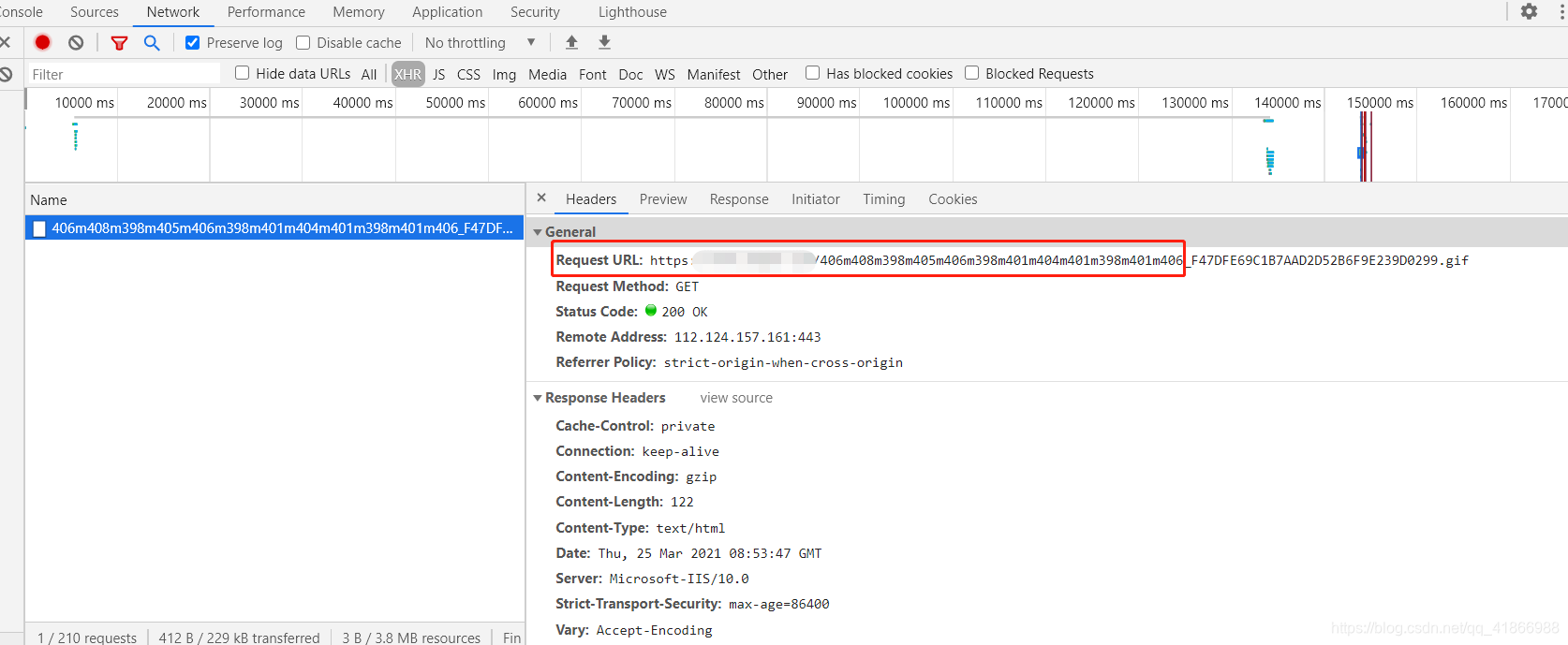
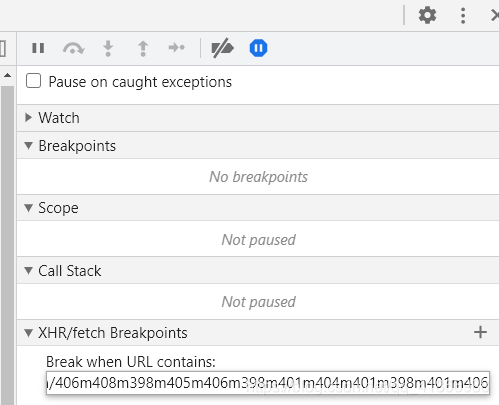
打上断点后刷新页面即可进入调试功能,出现红色框里的就是进入了,然后点击黄色框里的进行格式化,更方便的看代码。
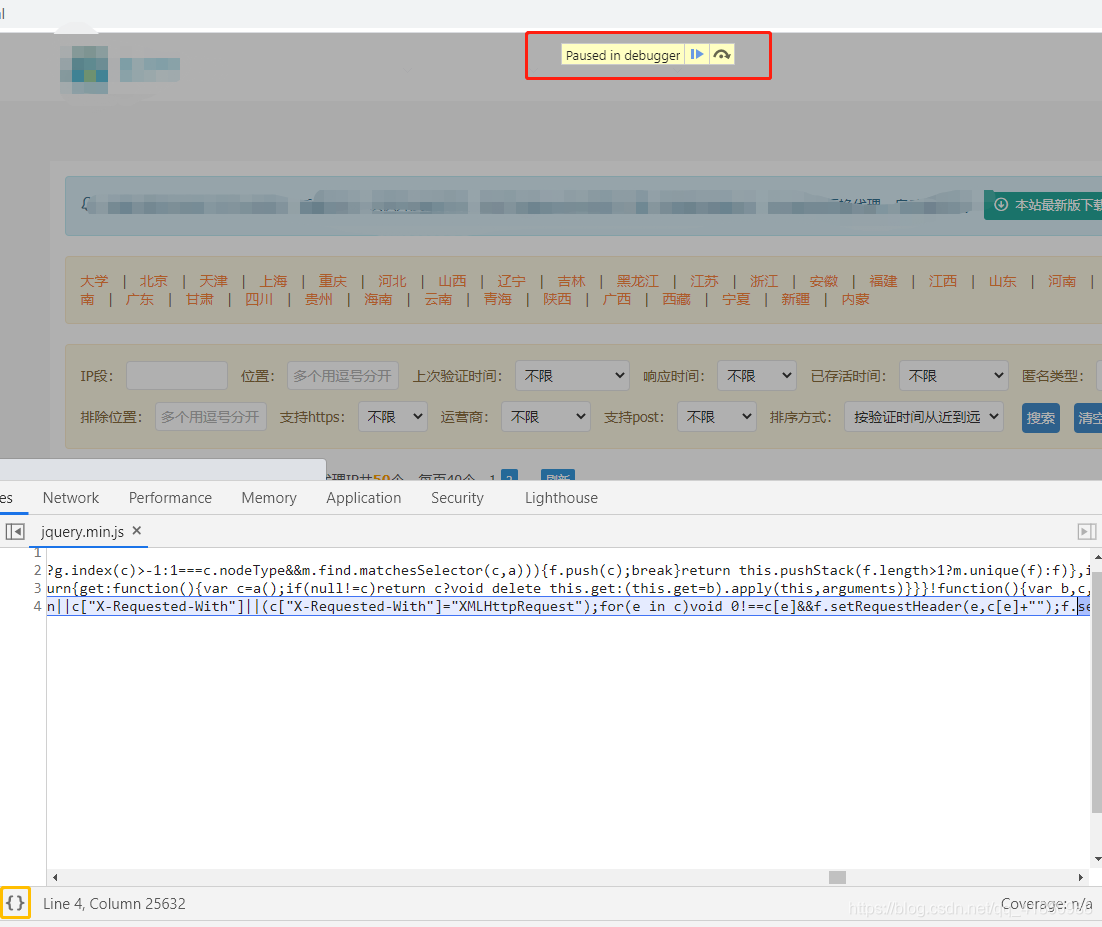
然后到这个Call Stack部分,往上

可以看到在ajax的时候,url已经出来了,明显不是我们想要的继续往上。
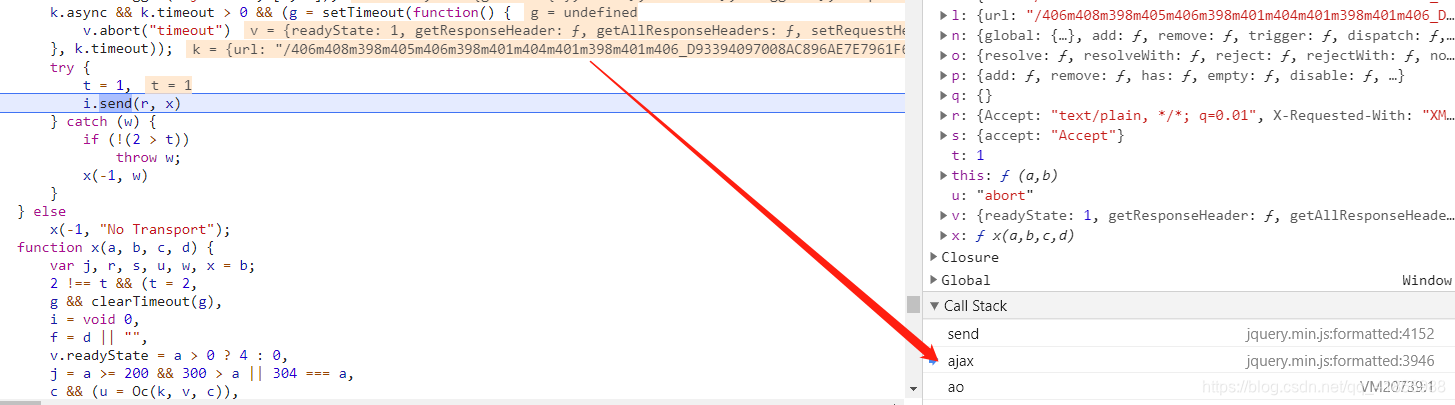
是不是很熟悉这个红框里的东西,没错,这是我们要找的url组成公式。

二话不说先打上一个断点,然后释放掉XHR断点,重新刷新一次页面进入这个断点调试。

进入后,把Url部分用鼠标拉起来,可以显示出当前元素的结果,明显是一个Url。

接着在下面继续打一个断点,接下来我们F8也就是单步执行到下一个断点,看看得到了这个Url后,会做些什么。
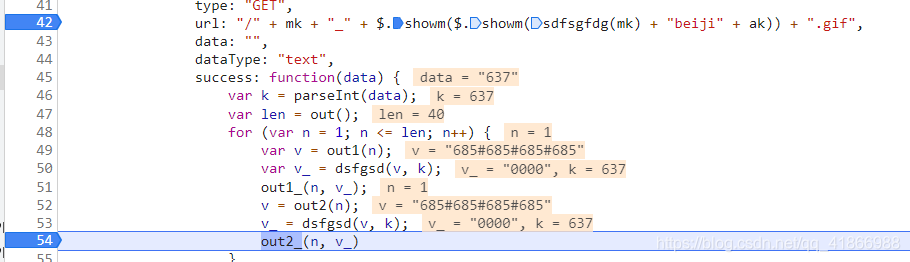
从上图我们看到了这个data,是不是很熟悉,和我们要请求那个一长串的网站反映出来的数值好像很像,就假设他们有关系吧,既然有假设,接下来我们就需要去验证一下,是否有关系了,重新刷新一次,然后F10单步调试,一步步慢慢来,我们会看到有一个参数是这样的。
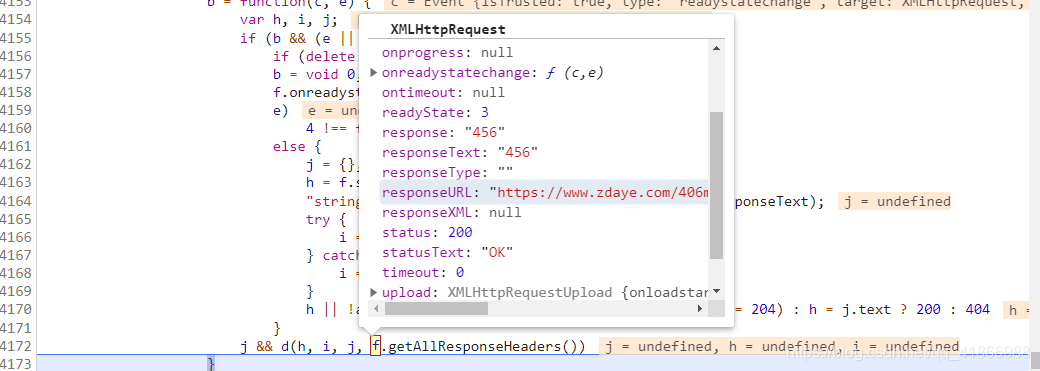
这个response和response是不是特别眼熟,没错了,在这一步我们基本上确定,这个data就是这个网页请求的值了。接下来将断点打在这个位置,目的是直接跳过Url调用showm的这个方法,刚刚试了没必要再一步步了,然后进行单步调试。
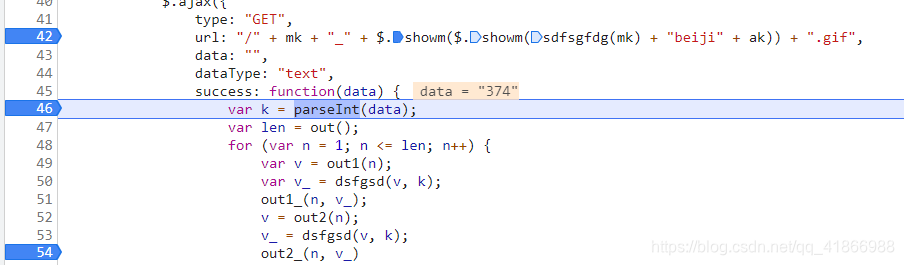
多走几遍后,就会发现这个v_,在执行到out2_的时候就会被置零,
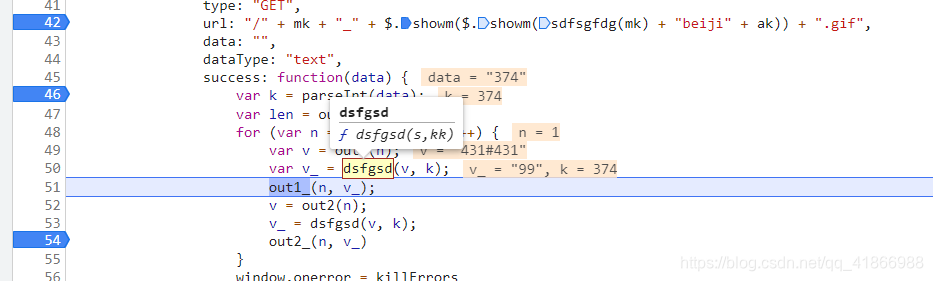
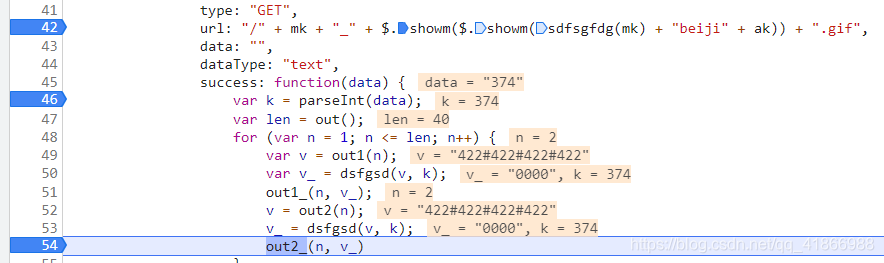
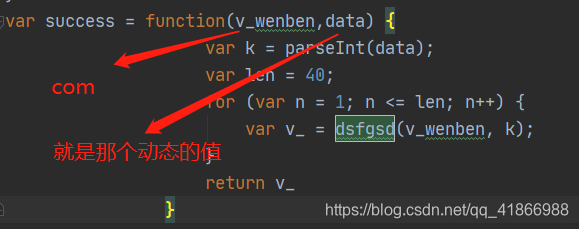
这个v_的值反而到了这个wait被替换的地方。我这是第三次循环小伙伴应该看的懂吧,刚好是第三位。data是一个一直不变的数,当然你多刷新几次就会发现只是说这个页面上不变,你再刷新一次它就变了,证明这个是个动态的data,不过想想也是,请求它的Url也是动态的,他肯定也会是动态的。
由此判断这个Url请求得到的data和wait位置的数有关系,所以我们第一步就是要去先求出data!才能得到wait的值!
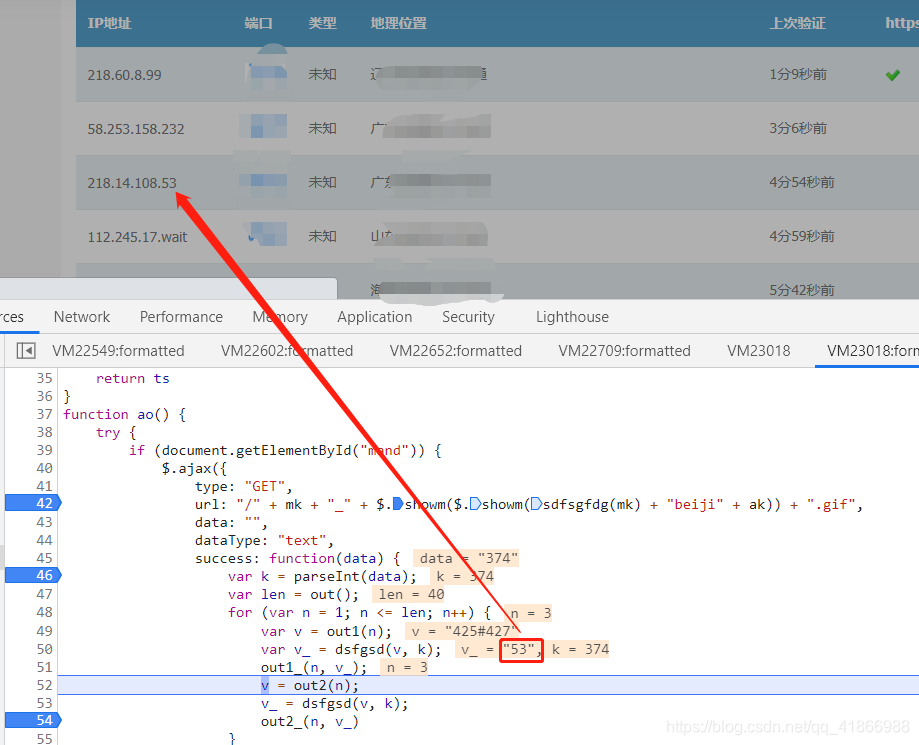
二、操作
data的值
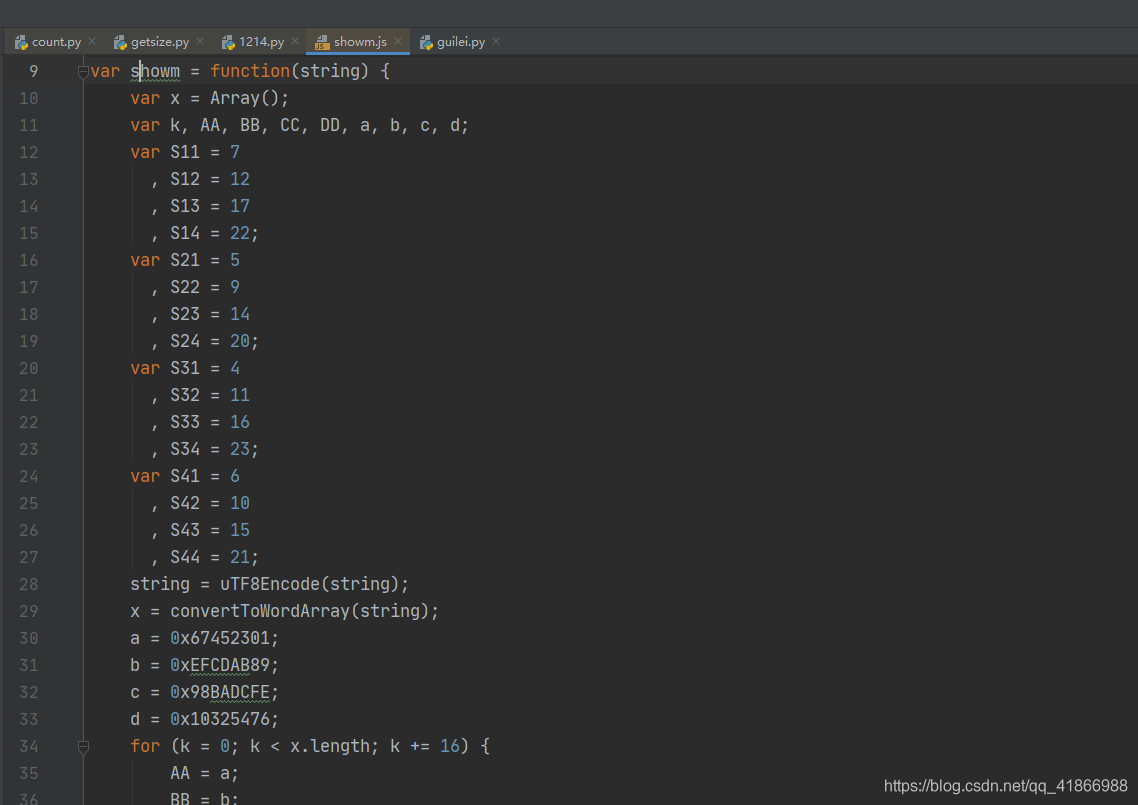
既然要求data的值,那我们就先要拿到Url的组成原理,先刷新到Url的地方进行查看组成元素,我们会发现这里有个showm()的方法用了两次,我们把鼠标放上去,看看这个方法是什么意思,点击一下这个f showm(string)
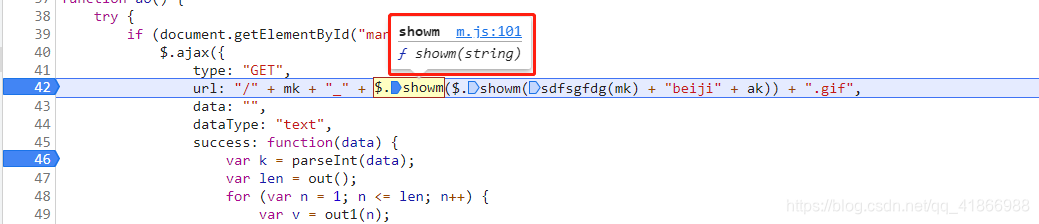
这个就是showm的函数
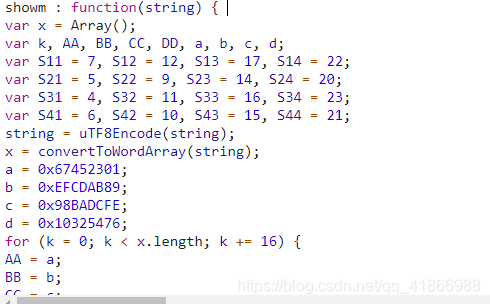
因为比较长我就没有全部拿下来了,小伙伴们可以自己把这整个函数给copy下来,保存成一个js。
回到网页,发现这个Url里还有个sdfsgfdg()方法在,老办法,给它一起放进去。
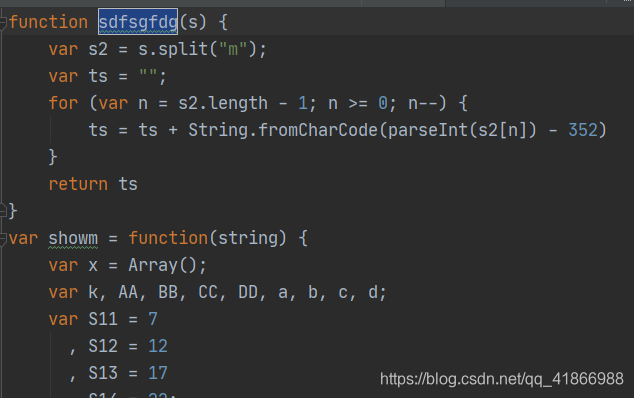
放进去后,我们再次回到网页,查看剩下的参数。


是不是很眼熟这个mk,没错就是我们请求的网址不变的那部分,后面这个ak就比较模糊了,但是由于是动态的,mk不变的情况下,这个ak应该是变的,刷新一下,发现ak果然不是这个值了。

所以这个ak是我们需要拿到的关键性元素!
我们就搜索试一下,我搜过了ak:,ak=,最后ak =才找到,所以小伙伴不要一次没找到就灰心,多试几次不同的方法获取会有惊喜。
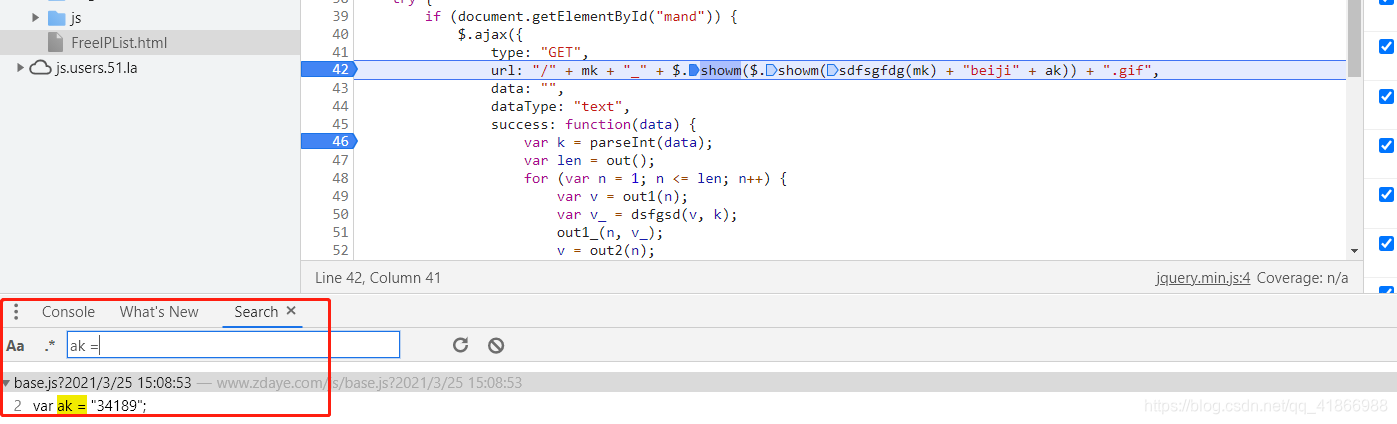
当然想要直接跳转到文件直观一点的可以去Newwork进行全局搜索(Ctrl + F)

点击后,会跳转到这里,这里就有ak的值了,那怎么请求到呢,就看上面那张图这个Request URL属性就是网站,请求返回一下就可以,记得带上请求头噢。这样就拿到ak啦!(同时也拿到mk的了,不过这个是固定的,拿不拿无所谓)
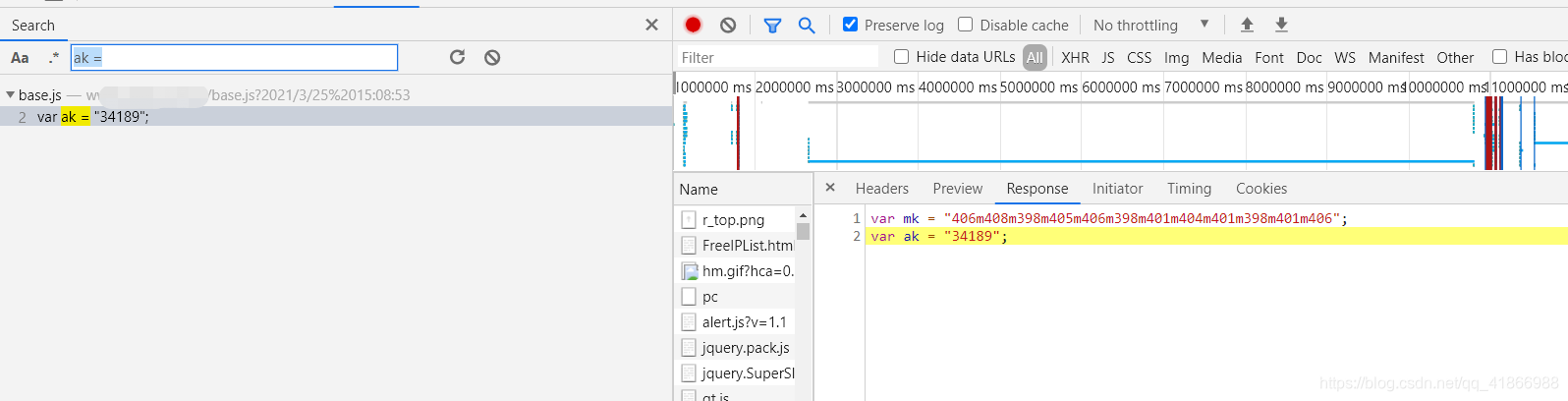
当然这个base.js可不是固定,他也是动态的。是不是很眼熟,对了这就是时间,我们还需要用Python去写一个求当前时间的代码。
import time#这是求时间的代码
y = time.strftime("%Y", time.localtime())
m = time.strftime("%m", time.localtime())
m = m.split('0')[1]
d = time.strftime('%d',time.localtime())
time1 = y+"/"+m+"/"+d
time2 = time.strftime("%H:%M:%S", time.localtime())
time = time1+"%20"+time2
print (time)
time求出来了我们现在可以组建Url了,我下面的headers你们需要自己去获得就用base.js的headers就可以了
import requests
import re
sess = requests.Session()
res = sess.get('https://www.zdaye.com/js/base.js?'+time,headers=headers)
wenben = res.text
mk_ak = re.findall(r'(?<=").*?(?=")',wenben)
mk = mk_ak[0]
ak = mk_ak[1]
mk和ak都拿到手了,我们接下来就需要去传入到这个Url的公式中。
url: "/" + mk + "_" + $.showm($.showm(sdfsgfdg(mk) + "beiji" + ak)) + ".gif"
里面的两个方法我已经保存在了本地js文件里,接下来用python调用进行复现就可以了。
import execjs
with open(r'C:\Users\voiceai\Desktop/showm.js', 'r', encoding='UTF-8') as file:
result = file.read()
js=execjs.compile(result)
result1=js.call('sdfsgfdg',mk)
result2=js.call('showm',result1 + "beiji" + ak)
result3=js.call('showm',result2)
url = 'https://www.zdaye.com/' + mk + '_'+result3+'.gif'
print(url)
得到了网站,我们马上去请求看一下会得到什么结果。
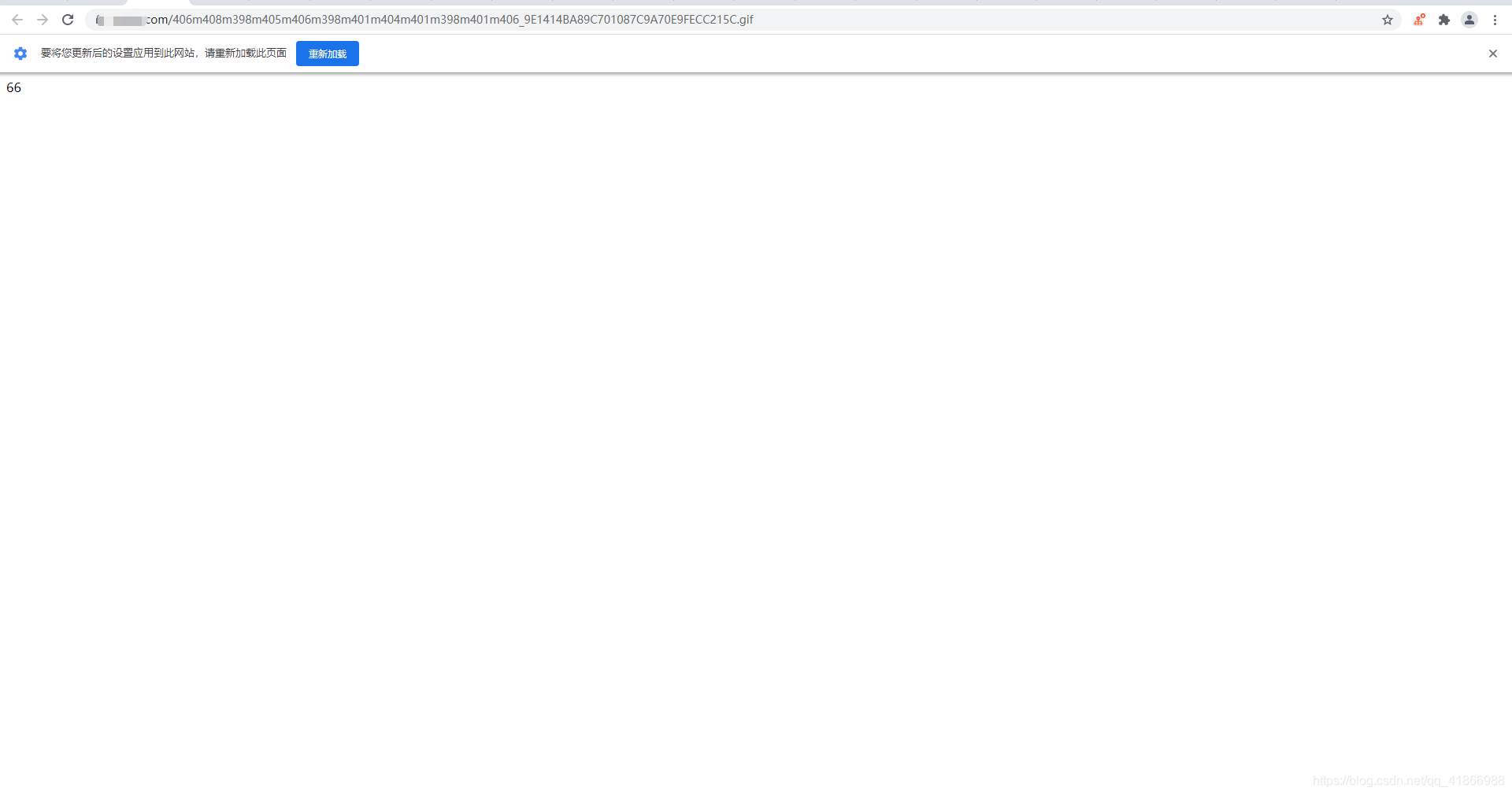
百分之一百是会告诉你是66,第一次你觉得没咋样,再去访问一次,发现还是66,问题就出来了,为啥和之前看的不一样,这都不是动态的。如果你连66都请求不到,请去再加一个headers,这个headers就用下图的。
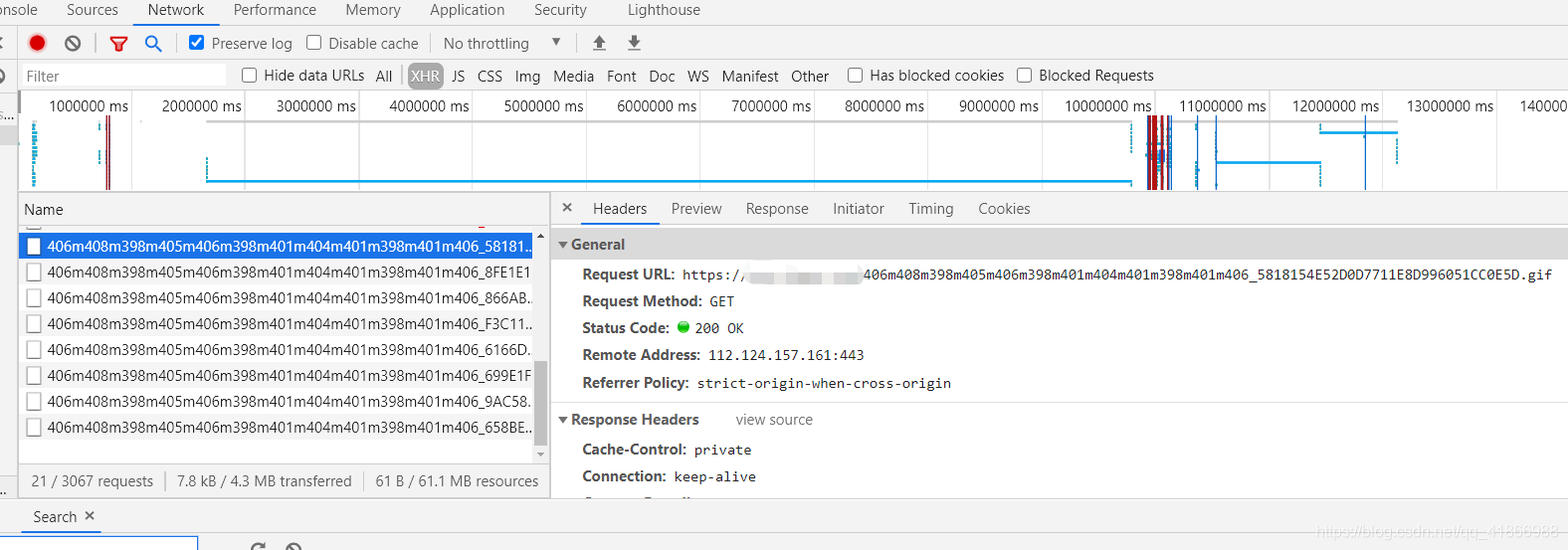
用了之后就是66了。然后我们再回网站一看。
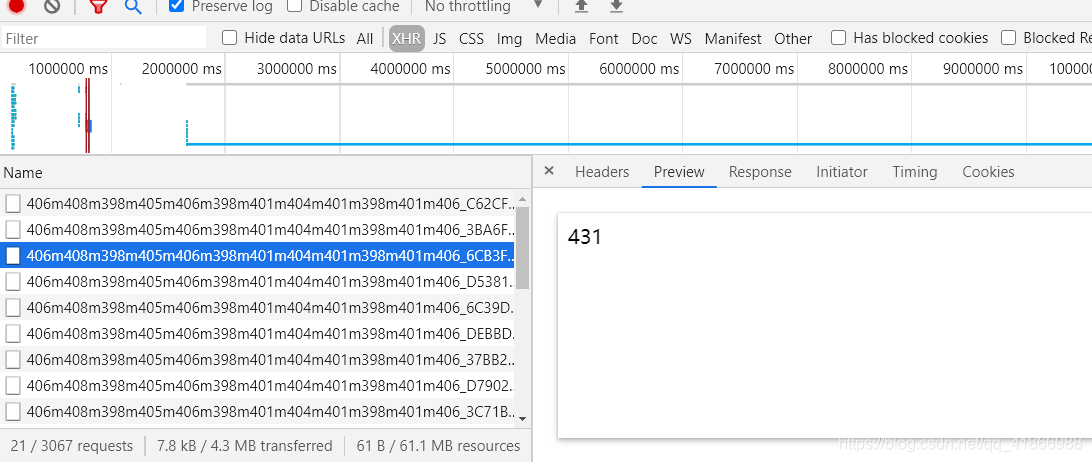
为什么和我的不一样是不是我哪里弄错了,然后我们可以点击这个网站进去看一看。
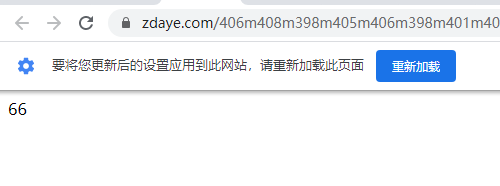
点进去发现变成66了!所以这一步其实不算是我们的问题,这个是一个请求顺序先后的问题。我试过挺多次,想要不出这样的错误,只能先去请求主页,然后再请求这个Url才会显示正常的值。

这样就不是66了,而是647了。这就是data的值!
现在有了data的值之后,我们就可以开始求wait的值了。
wait的值
这是获取到data后,进行的操作。
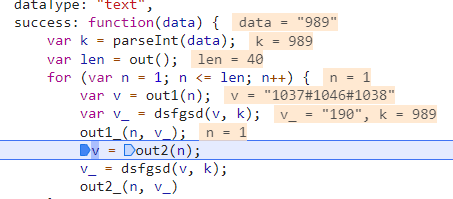
我们可以看到这个名叫success的function中有这parseInt(),out(),out()1,dsfgsd(),out1_(),out2(),out2_(),其实out2相关的可以不用管了,因为上面有说到,out2部分就会清零了,没有任何意义。
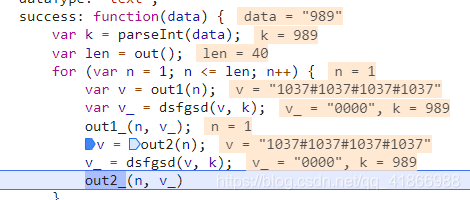
这些方法用老办法,鼠标放上去,然后定位到位置,拿下来,放到之前存的js文件。




当然那个success的function也要放进去
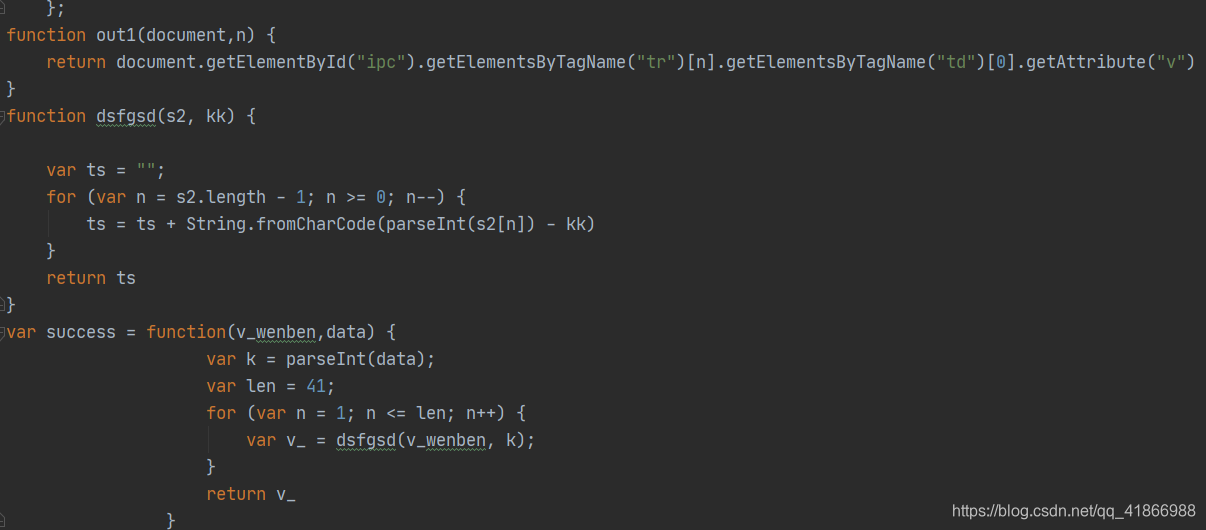
不过在这里友情提示,单单放这些是不够的,到时候运行起来会报各种错误,为什么呢,因为这些方法里面还会需要调用到一些函数,那么这些函数,你又没有放进去,所以会报错,最简单的办法就是,缺啥补啥,但是我这里就比较懒了,发现缺的,都是在一个叫m.js里面,我就全部拿下来了。
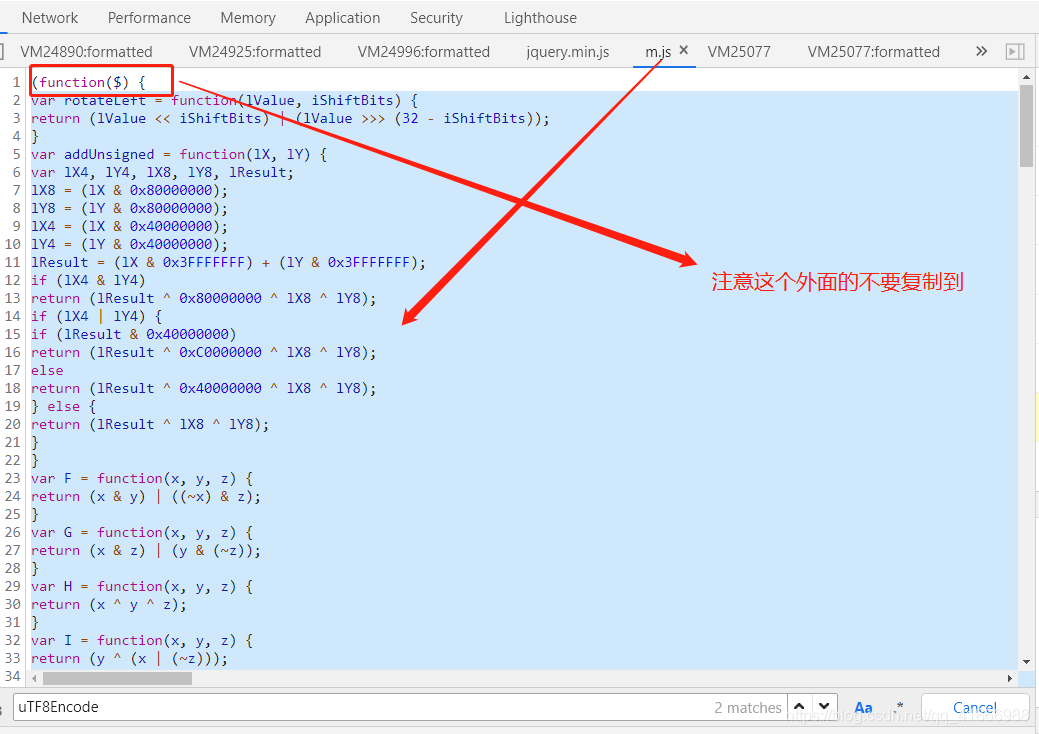
这时候就会有人问到怎么发现缺的方法,你的编译器会告诉你缺了啥,你只需要去搜索它!看它在哪里,拿下来就行!
比如uTF8Encode方法缺失:
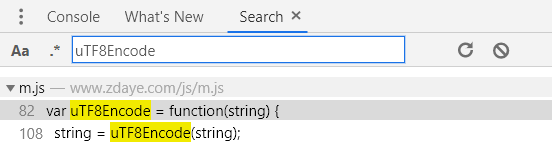
接下来就是调用python来进去传参数了。这个success,是很多新手不知道怎么调用的,原来是success:,你保存后需要重新命名用var来进行命名。这个len为什么等于40呢,看上面的图,一直截图到现在它没变,我也就不去考虑他是怎么来的了,直接放上去。
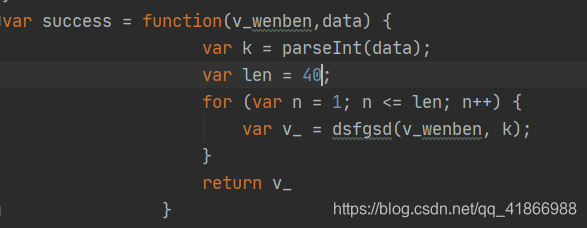
out1为什么又消失了,是因为如果你原样放进去,会出现,缺失document,
因为缺少document,所以我们就去看看网页里这个是啥(怎么查看去console输入document)
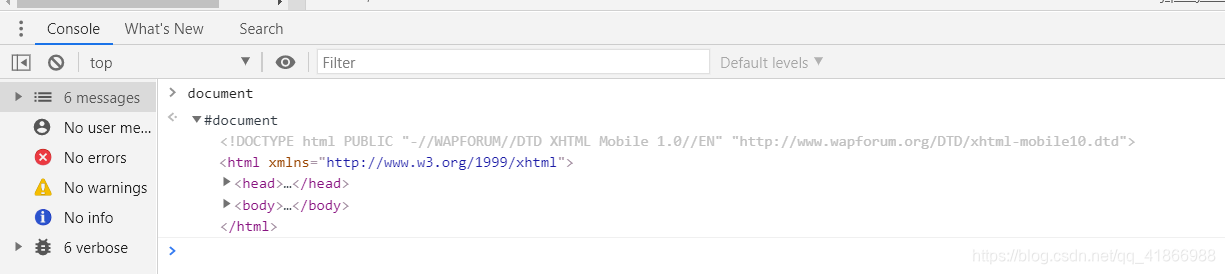
显而易见这是一个网页当前的代码
这边贴出out1()的代码:

这个返回的是这个v,然后getTlementById大家应该很眼熟,就是相当于定位元素,然后我就直接定位到ipc这个id找到他所谓的这个v,用Python实现,我这里是用xpath。
from lxml import etree
document = sess.get('https://******/FreeIPList.html',headers=headers1).text
#网址就不给了,自行摸索哈,header1,header2,headers,都需要去对应的网站拿。
html = etree.HTML(document)
v_wenben = html.xpath('//*[@id="ipc"]//tr[1]/td[1]/@v')
v_wenben = "".join(v_wenben)
print(v_wenben)
既然这个v拿到手了,那么就不用out1可以了,直接传入。
这个时候又会报错了,
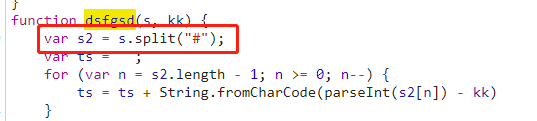
这个js是执行不通的,需要用python重写。
com = com.split("#")
重写过后吧s删了,直接s2作为参数就可以了
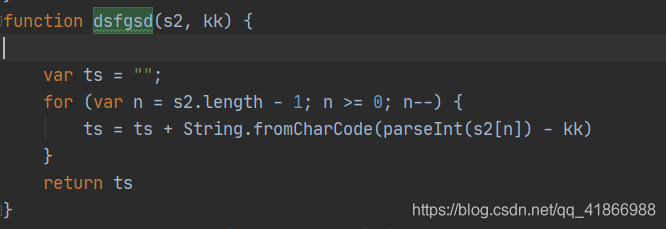

最后就会得出wait的值了!


至于怎么替换成完整的ip我这里就不说了当做保护网站的最后一步吧。纯粹为了大家更好的学习,进行分享~
小结
在js逆向这一块,相关资源太少,风险也大,我这里只是单纯为了分享我的思路和步骤,希望大家能够学习到一点新的知识,从而更好的入门!
如果对文章内容存在疑问,可以在博客评论区留言!
借鉴思路文章
Reference: https://mp.weixin.qq.com/s/XRGFE25ra-HpICzhfLkgew