Attention与Self-Attention
对于很多从事计算机视觉的小伙伴来说,刚接触到Vision Transformer时,不理解其Self-Attention中的QKV到底表示什么,在这里简单记录自己的学习理解过程。
本文章结合沐神的动手学深度学习及B站大佬们的相关视频进行理解与学习,在此做记录:
视频1
视频2
沐神视频
文章中的图片内容均来自上方视频和动手学深度学习第二版。
什么是attention
对于数据来说,我们可以知道哪些对我们是重要的,哪些不是重要的,但是对于一个模型来说(CNN、RNN)很难去抉择哪些是重要哪些不重要。因此,从人类注意力的角度出发研究注意力机制。
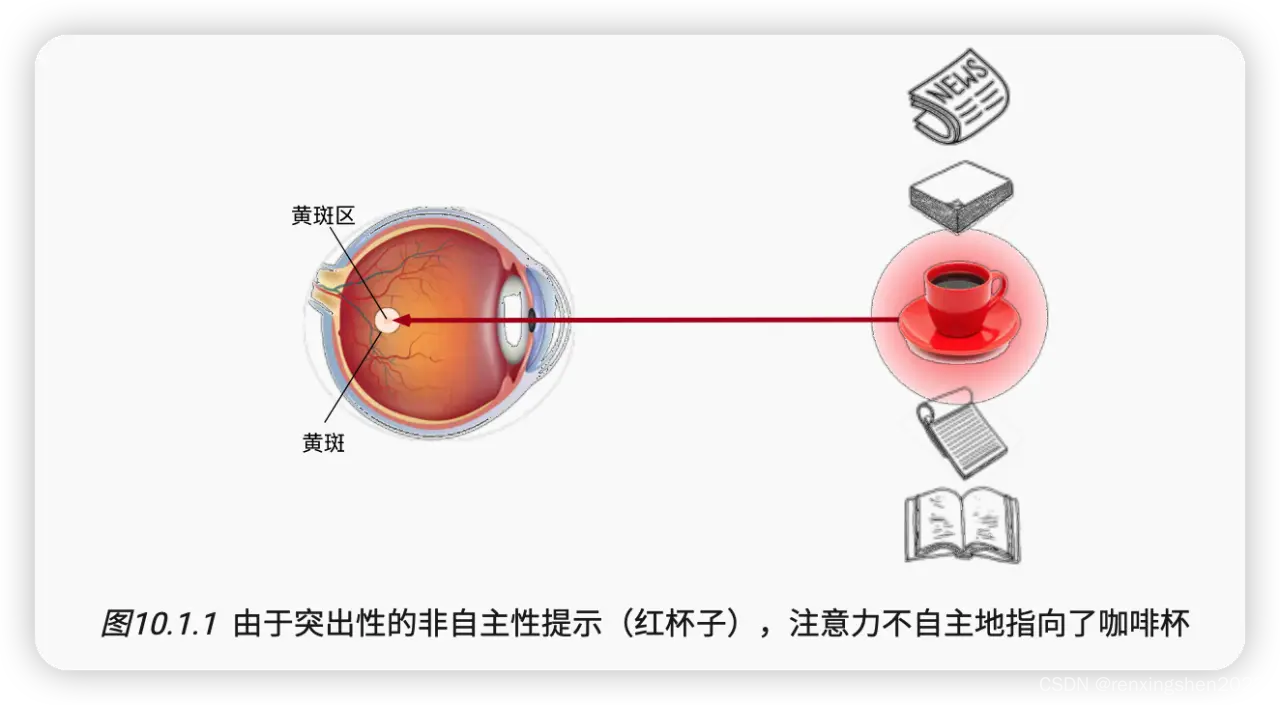
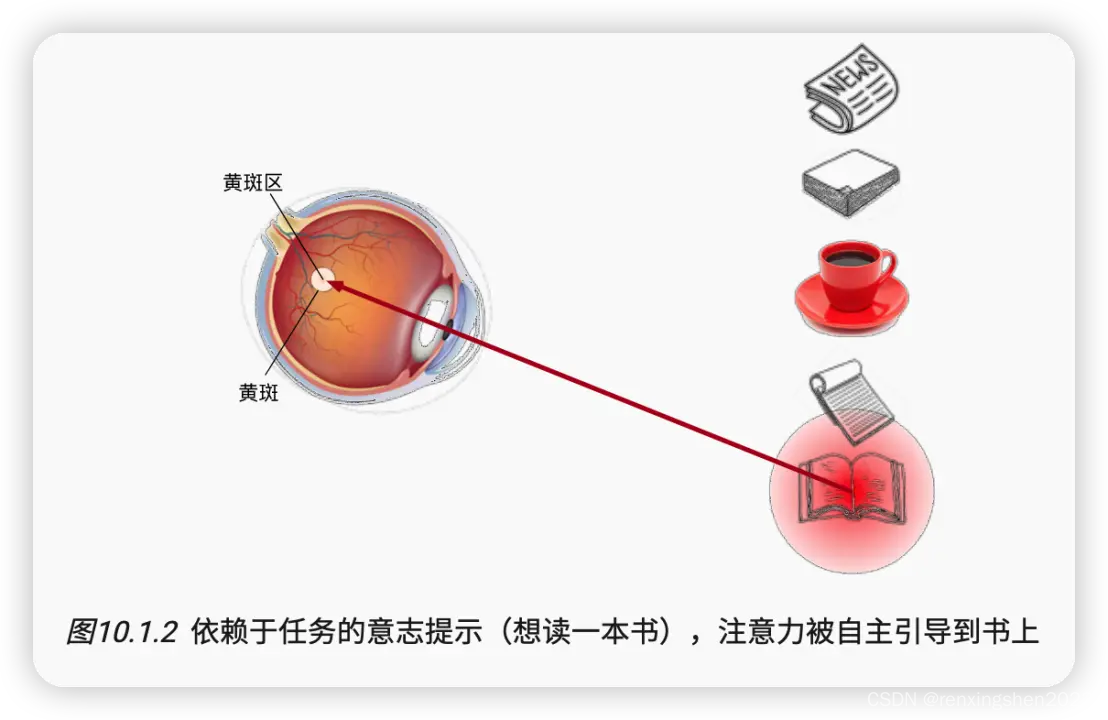
假设,我们的桌子上放着一个红色的杯子,两本颜色不太明显的笔记本和书,我们第一眼肯定会被颜色突出的杯子吸引,这就是我们非自主性的注意力被吸引。但如果我们此时自主性的想去读书,此时我们的注意力就会关注我们想要的书的特征,从而自主性的将注意力转移到书上。
查询、键和值
通过自主性与非自主性的角度去解释注意力机制。

注意力机制显性的考虑自主性的思维。将"人"自主性的思维作为查询与“环境”中非自主性特征进行相似度计算,从而将选择引导至感官输入,引导至最匹配的值(目标)。(这里可能有点抽象,后面会有示例。)
注意力评分函数

如图所示,注意力汇聚函数可以表示为

其中![]() 表示为注意力权重:
表示为注意力权重:

其中![]() 表示注意力评分函数,不同的注意力评分函数会导致不同的注意力汇聚操作。下面将简单介绍加性注意力和缩放点积注意力
表示注意力评分函数,不同的注意力评分函数会导致不同的注意力汇聚操作。下面将简单介绍加性注意力和缩放点积注意力
加性注意力
一般的当查询和键(Q和K)是不同长度的矢量是,可以使用加性注意力作为评分函数:

给定q ∈ \in ∈ R q {\Reals^q} Rq, ( k 1 , v 1 ) , … … , ( k m , v m ) (k_1, v_1),……,(k_m, v_m) (k1,v1),……,(km,vm), k i ∈ R k , v i ∈ R v k_i \in {\Reals^k}, v_i \in {\Reals^v} ki∈Rk,vi∈Rv; W q ∈ R h ∗ q W_q \in{\Reals^{h*q}} Wq∈Rh∗q、 W k ∈ R h ∗ k W_k \in{\Reals^{h*k}} Wk∈Rh∗k、 w v ∈ R h w_v \in {\Reals^h} wv∈Rh。
给定长度不等的q和k,首先通过可学习的参数 W q , W k W_q,W_k Wq,Wk对q和k进行处理,生成长度都为 h h h的 W q q , W k k W_qq,W_kk Wqq,Wkk,然后将两个向量相加,经过激活函数后与 w v w_v wv相乘,生成注意力分数。
缩放点积注意力
当q与k的长度相同时,我们可以使用缩放点积注意力评分函数,效率更高,缩放点积注意力评分函数为:

为什么要使用缩放点积,而不是直接点积呢,下面举个例子:
假设a1 = 51, a2 = 49 , 经过softmax后 0.51, 0.49,两个概率差距不大,但如果 a1 = 70, a2 = 30, 经过softmax后,0.99999, 0.000001,可能就会导致梯度消失等问题。假设向量长度 d = 64 , d = 8 d=64,\sqrt{\smash[b]{d}}=8 d=64,d=8,此时,a1 = 70 / 8 = 8.*, a2 = 30 / 8 = 3.8 经过softmax后,可能就是0.7,0.3,避免了上述情况。
由上述评分函数可以推出缩放点积注意力:

总结:注意力分数是query和key得相似度,注意力权重是分数得softmax结果。
两种常见得注意力分数计算:
加行注意力分数函数;缩放点积注意力分数函数。
下面通过一个简单得例子进行分析,摘自文章开篇视频1中的内容。
举例
视频1](https://www.bilibili.com/video/BV1dt4y1J7ov/?spm_id_from=333.337.search-card.all.click)
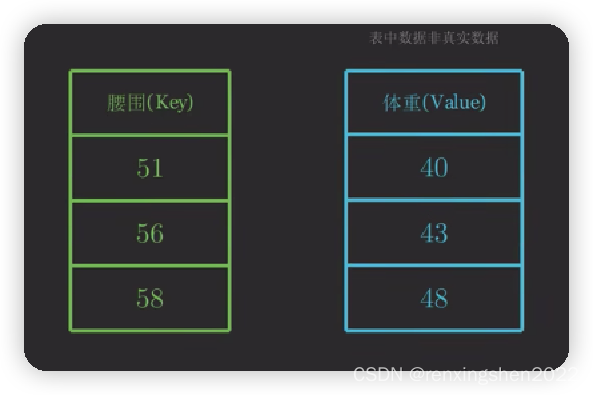
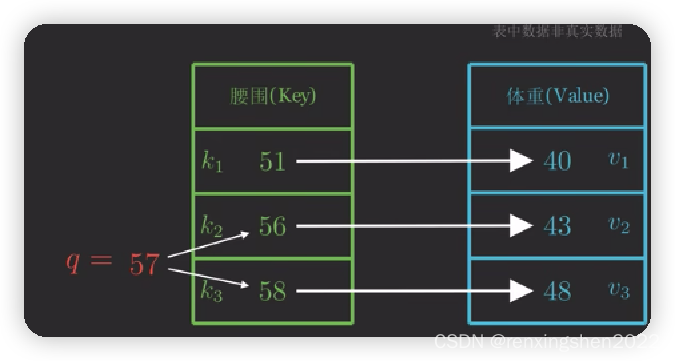 给定一组数据,如图中腰围与体重的关系,此时如果我们想查询腰围为57时,体重为多少,最简单的方法就是 43 ∗ 0.5 + 48 ∗ 0.5 43*0.5+48*0.5 43∗0.5+48∗0.5,也就是我们给定图中 K 2 K_2 K2和 K 3 K_3 K3各50%的权重,但根据其他数据可以看出,腰围与体重之间并不是简单直接的线性关系,我们需要考虑到其他的k,v对q的影响,因此可以得出
给定一组数据,如图中腰围与体重的关系,此时如果我们想查询腰围为57时,体重为多少,最简单的方法就是 43 ∗ 0.5 + 48 ∗ 0.5 43*0.5+48*0.5 43∗0.5+48∗0.5,也就是我们给定图中 K 2 K_2 K2和 K 3 K_3 K3各50%的权重,但根据其他数据可以看出,腰围与体重之间并不是简单直接的线性关系,我们需要考虑到其他的k,v对q的影响,因此可以得出

其中,
最后得出

当Q、K、V为多维数据时,
当Q为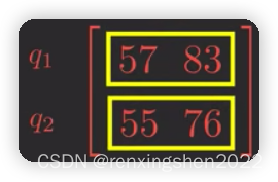 时,根据
时,根据 得到
得到

最后求出注意力权重 f ( q ) f(q) f(q)。
Self-Attention
根据上面的描述,我们可以看出以缩放点积为评分函数的注意力机制流程如下图所示。

那self-Attention与Attention有什么关系呢??
当查询、键和值来源于同一组输入时,则被称为自注意力。源于同一组输入并不代表 Q = K = V Q=K=V Q=K=V。
在上面的Attention中,我们拿到的时一组 q 1 , … … , q n q_1,……,q_n q1,……,qn和一组 ( k 1 , v 1 ) , … … , ( k m , v m ) (k_1,v_1),……,(k_m,v_m) (k1,v1),……,(km,vm)组合,注意力输出为 y 1 , … … , y n y_1,……,y_n y1,……,yn。
而在自注意力中我们拿到一组序列 x 1 , x 2 , … … , x n x_1,x_2,……,x_n x1,x2,……,xn,注意力输出同样为 y 1 , … … , y n y_1,……,y_n y1,……,yn。其中:

下面举个例子,我们拿到仅一个 X X X,按照Attention的思想, f ( X ) f(X) f(X)应给为:

但上面我们也说了QKV来源一同一组输入,但并不是Q=K=V,根据Transformer原文中我们可以看出,Self-Attention的Q、K、V等于 X W Q , X W K , X W V XW_Q,XW_K,XW_V XWQ,XWK,XWV。因此,实际的 f ( X ) f(X) f(X)应该是

到这里,Attention到Self-Attention的转变以基本完成。
最后
简单进行记录,如有问题请大家指正。