简介
2019年CVPR,从感受野的角度去分析通道注意力机制。论文连接:SKNet.
在神经视觉中,神经视觉皮层的神经单元受不同的刺激,感受野大小是动态调节的,而CNN中很少考虑到这一点。

因此,提出一种动态选择机制,允许每个神经元根据输入信息动态的调节感受野的大小。
思想
通过一种非线形操作,实现感受野的动态调整。
主要步骤
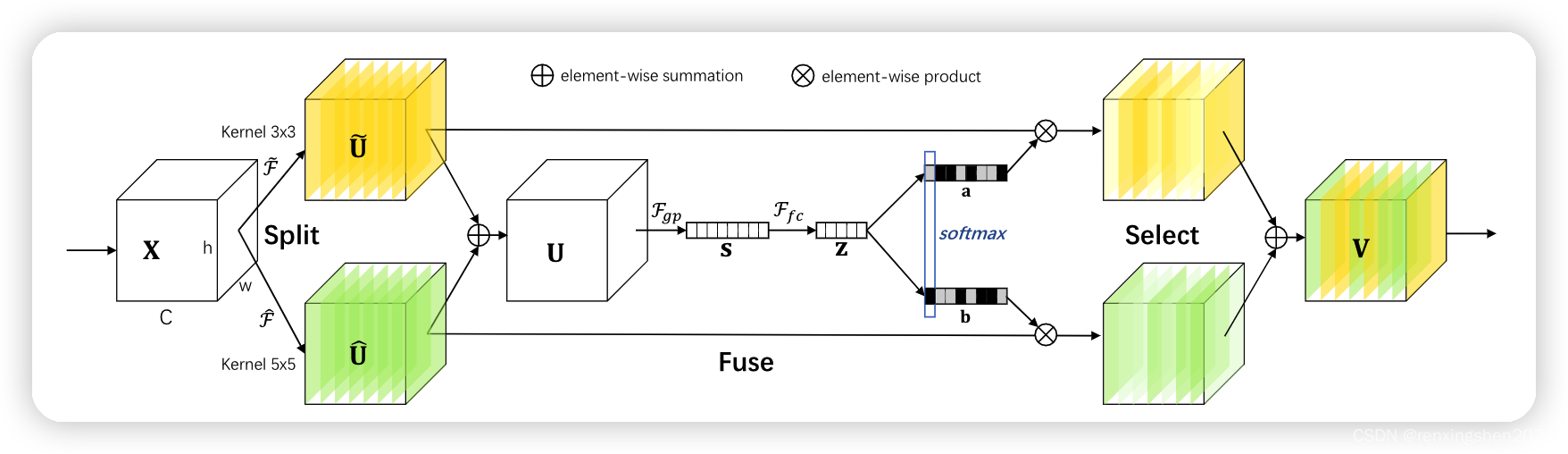
Split:该操作主要是对特征图进行多个分支使用不同卷积核(感受野不同)进行特征提取
Fuse:通过全局平局池化对特征图 U U U进行信息嵌入,然后利用全连接层进行降维。但这里在进行降维的时候限制了最低纬度。然后分别用两个全连接层层将 Z Z Z的维度升维。然后softmax处理一下。(可以看代码理解一下)
Select:经过Softmax处理后,a与b都是与 s s s相同尺寸的向量,然后特征图 U ~ \tilde{U} U~和 U ^ \hat{U} U^分别乘a和b(类似于SE中的scale操作),相乘后在按元素相加得到最终的特征图。
代码
代码粘贴自github。:SKNet代码
地址:https://github.com/pppLang/SKNet/blob/master/sknet.py
class SKConv(nn.Module):
def __init__(self, features, WH, M, G, r, stride=1 ,L=32):
""" Constructor
Args:
features: input channel dimensionality.
WH: input spatial dimensionality, used for GAP kernel size.
M: the number of branchs.
G: num of convolution groups.
r: the radio for compute d, the length of z.
stride: stride, default 1.
L: the minimum dim of the vector z in paper, default 32.
"""
super(SKConv, self).__init__()
d = max(int(features/r), L)
self.M = M
self.features = features
self.convs = nn.ModuleList([])
for i in range(M):
self.convs.append(nn.Sequential(
nn.Conv2d(features, features, kernel_size=3+i*2, stride=stride, padding=1+i, groups=G),
nn.BatchNorm2d(features),
nn.ReLU(inplace=False)
))
# self.gap = nn.AvgPool2d(int(WH/stride))
self.fc = nn.Linear(features, d)
self.fcs = nn.ModuleList([])
for i in range(M):
self.fcs.append(
nn.Linear(d, features)
)
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
for i, conv in enumerate(self.convs):
fea = conv(x).unsqueeze_(dim=1)
if i == 0:
feas = fea
else:
feas = torch.cat([feas, fea], dim=1)
fea_U = torch.sum(feas, dim=1)
# fea_s = self.gap(fea_U).squeeze_()
fea_s = fea_U.mean(-1).mean(-1)
fea_z = self.fc(fea_s)
for i, fc in enumerate(self.fcs):
vector = fc(fea_z).unsqueeze_(dim=1)
if i == 0:
attention_vectors = vector
else:
attention_vectors = torch.cat([attention_vectors, vector], dim=1)
attention_vectors = self.softmax(attention_vectors)
attention_vectors = attention_vectors.unsqueeze(-1).unsqueeze(-1)
fea_v = (feas * attention_vectors).sum(dim=1)
return fea_v
最后
简单记录,如有问题请大家指正。