最近在学习一些关于强化学习的知识。当然仅仅学习理论知识还是不够的,还是需要从实际案例上进行出发,利用强化学习搭建自己的AI智能体。
一般来说,强化学习第一个案例都是用“cartpole”,也即是在一个平衡木上保持木杆不下落:
但是这个案例一般离我们生活比较远,因此本入门案例使用了微信“跳一跳”作为强化学习的目标。
在本案例中,大体框架如下:
- 实现“跳一跳”环境交互
- 实现强化学习算法DDPG,用来构建AI智能体
1.背景知识
首先简要介绍一下强化学习和DDPG算法的一些背景知识。
强化学习不同于传统的有监督学习,它本身没有有标签数据进行学习,只能通过不断的试错,来提升自己。在试错的过程中,就需要不断的与环境进行交互:也就是不断的在环境中做出动作,从而得到相应的反馈和奖励。
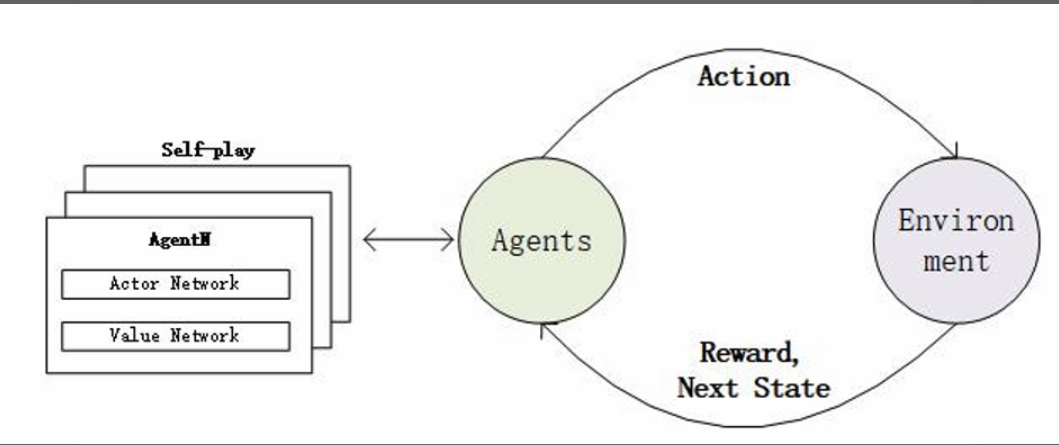
1.2 基础要素定义
首先定义强化学习的几个要素:
- 环境状态集 S S S
- 动作集 A A A
- 即时奖励 R R R
- 衰减因子 γ \gamma γ
- 状态转移概率 P P P
- 给定策略 π π π
- 评估该策略的状态价值函数 v ( π ) v(π) v(π)
最后标记为: ( S , A , P , R , γ ) (S,A,P,R,\gamma) (S,A,P,R,γ)。也即是说,在当前状态 S S S下,智能体给出最适合的动作 A A A, P P P表示在当前状态下转移到下一个状态的概率,得到对应的奖励 R R R,最后评估这个策略。而 γ \gamma γ表示折损因素。
1.3 DDPG算法
DDPG算法本质上是Actor-critic算法的扩展。因此先引入Actor-critic算法:

- Actor网络:给定当前环境状态 S S S,输出要执行的动作 A A A
- Critic网络:在当前的环境状态 S S S下,评估Actor网络输出的动作 A A A的价值情况,得到价值函数 V ( S ) V(S) V(S)
那接下来就很简单了,Actor和Critic网络可以用我们平常的神经网络进行构造。具体的算法步骤,可以再单独出一期介绍一下。
2.“跳一跳”AI智能体
要构造智能体,首先需要构造环境。在这个案例下,我们可以定义对应的要素:
- 环境状态 S S S:可以把当前跳一跳的图片进行截图,然后作为状态环境输入
- 动作 A A A:按压时间
- 奖励 R R R:这里设置比较简单,如果能够成功跳到下一个位置,则“+1”,否则为“-1”
整体项目如下:
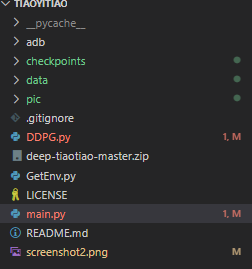
- main.py:训练智能体主函数入口
- GetEnv.py:构造智能体环境
- DDPG.py:强化学习DDPG算法
2.1 智能体环境
这里使用电脑版本的“跳一跳”小程序,这样我们就可以操作鼠标进行游戏。
在python中安装如下几个包:
pyautogui:控制鼠标
win32com:对电脑进行截图
win32gui:对电脑进行截图
cv2:把图片进行灰度化
PIL:剪裁图片
截屏函数:
def screen_pic(self, promgram_name, jpg_file, jpg_file2):
"""
截屏窗口图
"""
hWnd = win32gui.FindWindow(None, promgram_name) #窗口的类名可以用Visual Studio的SPY++工具获取
# 设置窗口在最前面
self.set_foreground(hWnd)
left, top, right, bot = win32gui.GetWindowRect(hWnd)
# print(right,left, bot,top)
self.left = left
self.top = top
self.right = right
self.bot = bot
self.tiao_x = (right + left) // 2
self.tiao_y = (bot + top) // 2
# 截屏
img = pyautogui.screenshot(region=None) # x,y,w,h
img = cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR)
cv2.imwrite(jpg_file, img)
# 识别“点击开始游戏”位置
self.start_x, self.stat_y = self._find_start_btn(jpg_file, self.start_btn_img)
pyautogui.click(x=self.start_x, y=self.stat_y, duration=0.25)
time.sleep(1)
# 重新截屏
img = pyautogui.screenshot(region=None) # x,y,w,h
img = cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR)
cv2.imwrite(jpg_file, img)
# 剪裁
rangle = (int(left) * pingmu_suofang, int(top) * pingmu_suofang, int(right) * pingmu_suofang, int(bot) * pingmu_suofang)
img = Image.open(jpg_file)
jpg = img.convert('RGB')
jpg = img.crop(rangle)
jpg.save(jpg_file2)
重启游戏:
观察游戏是否失败,首先可以看到失败之后,会出现下面这个图标:
我们把图标保存后,然后利用cv2.matchTemplate查找相似的图标,如果找到则进行点击返回主页面:
def _find_start_btn(self, screen_shot_im, find_shot_im):
"""
找到开始游戏位置的图标
"""
screen_shot_im = cv2.imread(screen_shot_im, cv2.IMREAD_GRAYSCALE)
result = cv2.matchTemplate(screen_shot_im,
find_shot_im,
cv2.TM_CCOEFF_NORMED)
if result.max() > 0.8:
y,x = np.unravel_index(result.argmax(),result.shape)
y += find_shot_im.shape[0] // 2
x += find_shot_im.shape[1] // 2
return x, y
else:
return -1, -1
最后利用pyautogui控制鼠标点击多少秒就可以了。
2.2 DDPG算法实现
在Actor网络中,输入的是跳一跳的截图图片,输出动作为控制鼠标点击多少秒,这里主要用了tanh函数控制输出值在-1~1之间。最后乘上对应的系数,控制鼠标按压时间为“最低按压0.3s,最高按压1.1s”。
而在Critic网络中,输入“跳一跳的截图图片” + “Actor网络的输出”;输出“价值函数”,用来评估当前执行的动作价值。
DDPG比Actor-critic网络还多了两个,分别是Actor目标网络和Critic目标网络,这两个网络主要是为了解耦合的,参数从Actor-critic网络中进行复制更新过来。
具体的网络实现代码可以参考我的项目代码,这里需要注意的是,为了避免AI智能体从一开始收敛在某个区域而学习不到有用的信息,因此在Actor网络输出后还加了一个noise:
def add_noise(self, x, mu, theta, sigma):
return theta * (mu - x) + sigma * np.random.randn(1)[0]
Replay经验回放:经验回放的目的是为了让网络可以重新记住之前采取过的策略,这样就可以像有监督学习一样扩充样本进行学习。在经验回放时,分别更新四个网络:Actor网络,Actor目标网络、Critic网络、Critic目标网络。
# 1.更新crtic网络
loss = 0
with tf.GradientTape() as critic_tape:
## 计算当前状态 与 下一状态的差值
pre_t = self.critic(states, actions)
loss = loss_function(y_t, pre_t)
# print(pre_t)
critic_trainable_variables = self.critic.trainable_variables
gradients = critic_tape.gradient(loss, critic_trainable_variables)
self.critic_optimizer.apply_gradients(zip(gradients, critic_trainable_variables))
# 2.更新actor网络
with tf.GradientTape(persistent=True) as actor_tape1:
a_for_grad = self.actor(states)
critic_outputs = self.critic(states, a_for_grad)
critic_grads = actor_tape1.gradient(critic_outputs, a_for_grad)
critic_grads = [-i for i in critic_grads]
# print(critic_outputs, a_for_grad)
# print(critic_grads)
critic_grads = tf.reshape(tf.concat(critic_grads, axis=0), [-1, 1])
actor_trainable_variables = self.actor.trainable_variables
params_grad = actor_tape1.gradient(a_for_grad, actor_trainable_variables, output_gradients=critic_grads)
grads = zip(params_grad, actor_trainable_variables)
self.actor_optimizer.apply_gradients(grads)
# 3.更新actor目标网络和critic目标网络
self.target_train(self.actor, self.actor_target)
self.target_train(self.critic, self.critic_target)
3.AI智能体效果
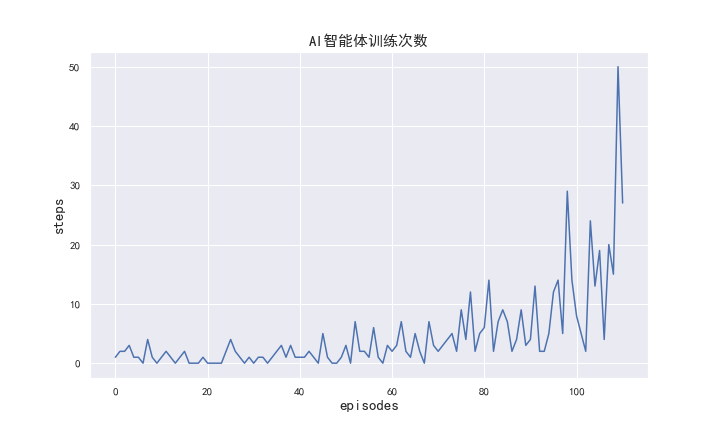
最后,在学习了大概700次迭代后,耗时大约在3小时左右,模型已经可以不断跳跃50次而不失败:

在人类来看,面积最小的,往往也是最难跳稳得,但是对应AI来说,能够较为容易的跳上去:

随着训练迭代次数的增多,跳的步数也越来越多,说明AI智能体在一定程度上学到了某种共性:
在实际中,Actor网络会输出负数x,但在后面进行更正为最终按压的毫秒数 y y y:
y = 300 ∗ x + 700 , x ∈ [ − 1 , 0 ] y=300*x + 700, x \in [-1, 0] y=300∗x+700,x∈[−1,0]
可以发现,在不同的状态环境下,给定不同的按压时间,可以得到对应的价值评估函数图,从下图可以发现价值函数有明显的区分效果。
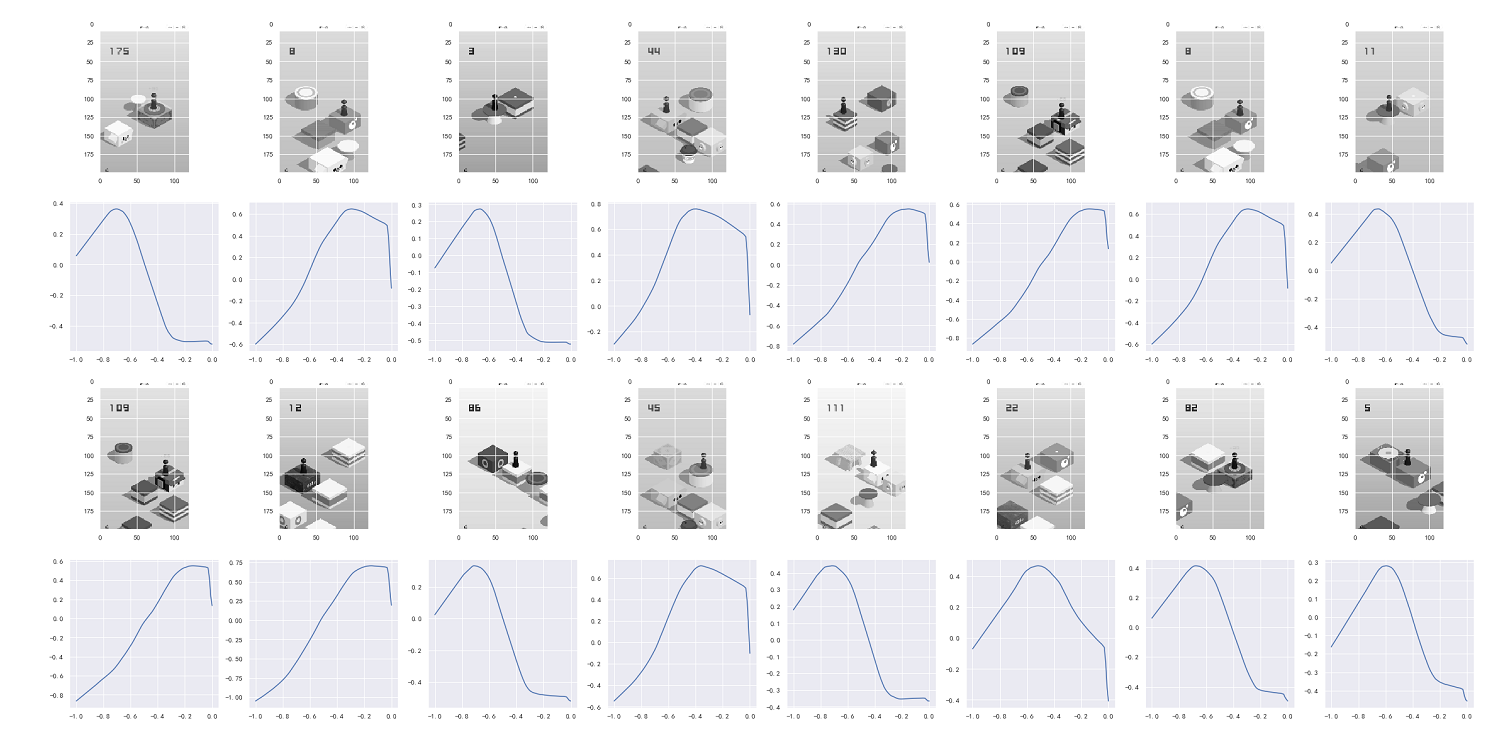
以第一列第三个图为例,其评估函数图为第二列第三个图:当 x = − 0.7 x=-0.7 x=−0.7,即按压时间为 y = 490 m s y=490 ms y=490ms,该策略执行的价值最大化,符合实际情况。(实际中由于上下位置比较接近,因此不能按压较长时间)
4.总结
上面是本次“跳一跳”AI智能体的简单介绍,更多的代码细节我已经上传的github上:
https://github.com/llq20133100095/deep-tiaotiao
实际上这个项目比较粗糙,之后也可以考虑比如
- 实现多个Agent
- 如果跳到下一个块的中间位置,奖励更多
这次从头开始实现强化学习算法,还是收获比较多的,大家感兴趣可以下载下来玩一玩。
我是leo,我们下期再见~