linux:

添加用户 useradd 删除用户 userdel useradd -d指定组
添加组 groupadd 删除组 groupdel

创建目录 mkdir -p 删除目录 rm -rf 创建目录 touch

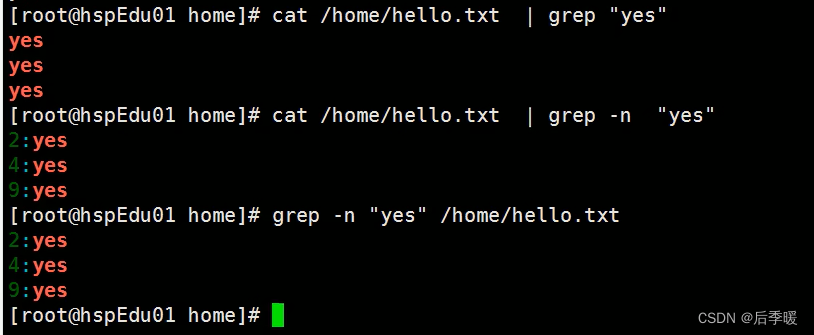
cat -n 查看文件(显示行号)




chgrp 改变文件所在组 usermod 改变用户所在组
chmod修改权限 chmod -R 777 /temp -R的意思是递归修改文件权限 这边只能大写 不能小写!! r=4 w=2 x=1

在第三行后面加 sed -i '3a xxx' /opt/t sed -i '3i xxx' /opt/t 这是第三行前面加
sed '2,3d' data6.txt 删除二三行
怎么替换一个txt文本中的,为; sed -i '1,$s/,/;/g' xx.txt
sed -i 's/test/trial/2' data4.txt 使用数字2作为标记,sed 编辑器只替换每行中第 2 次出现的匹配模式
如果把2替换成g就是全局
![]()
冒号做分隔符 print里做分割后的字符串的拼接 passwd是文件名
service mysqld restart其实是一个守护进程
systemctl disabled/stop firewalld
查看具体进程:ps -aux
linux目录“/etc”中存放的是 :系统的配置文件
动态查看文件内容:tail –f filename.log
查看ip:
Linux:ifconfig或ip addr。
Windows:ipconfig。
Mysql
大数据面试重点之mysql篇_mysql大数据面试_后季暖的博客-CSDN博客
SQL语句的执行顺序:from-----where------group by------having ----select-----order by
从向上3行开始 加到当前行

这个是加到后一行的意思(包括当前行)

很重要的一点 更新视图的时候 实际上是对原表的更新 所以和原表的字段也要匹配 所以一般不通过视图来更新表




DDL(数据定义语言) DML(数据操纵语言 增删改) DQL(查) DCL(数据控制语言 授权..)

重点在这! 大数据面试重点之mysql篇_mysql大数据面试_后季暖的博客-CSDN博客
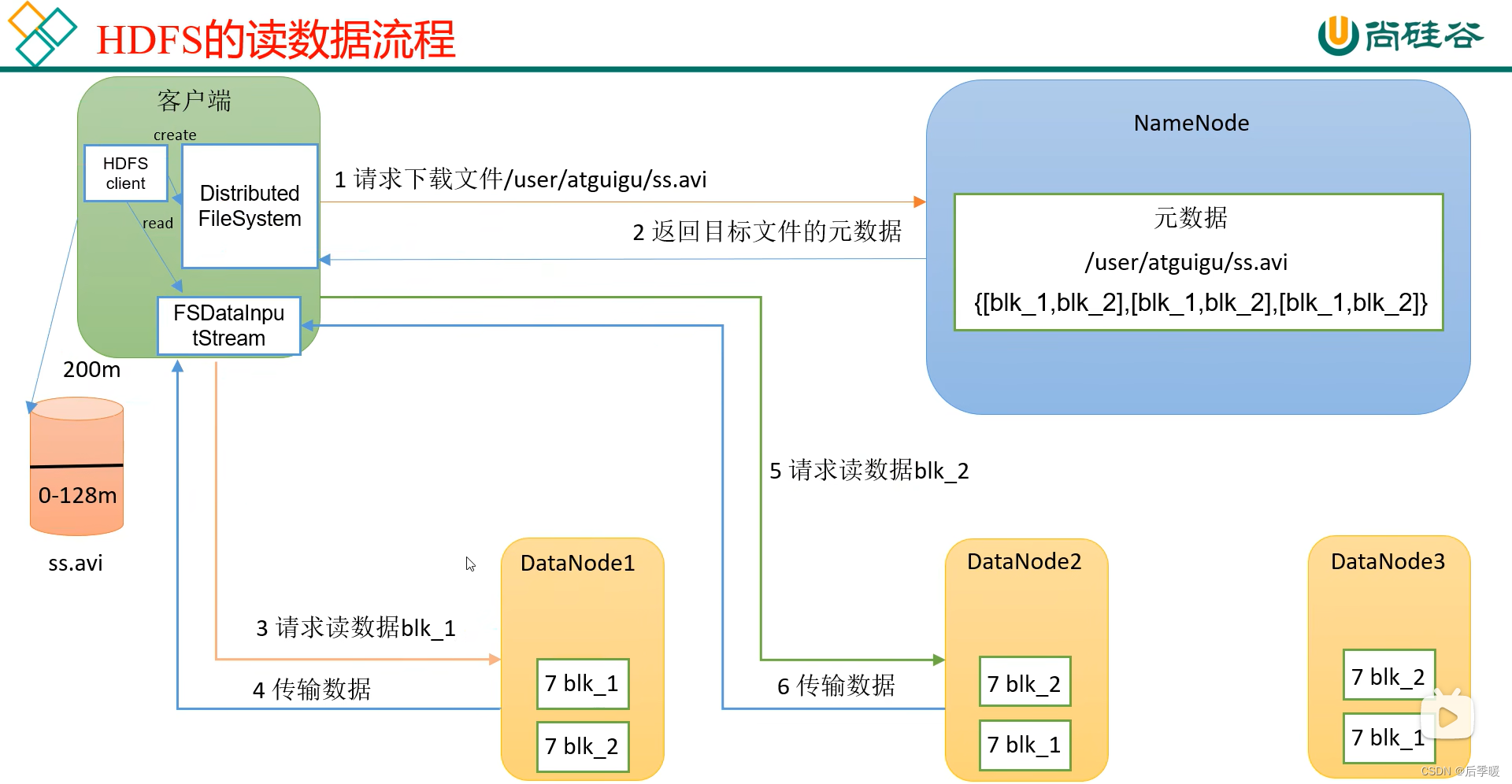
HDFS读文件:
先开启一个分布式文件系统来请求读取文件 访问NameNode 先看有没有权限读取、下载和路径里有没有这个文件
然后NameNode有的话就返回目标文件的元数据 客户端开启一个FSDataInputStream流去到DataNode中读取block
但是三个DataNode到底读哪个block呢 就近原则
但是也有负载均衡的原则 然后一块一块的读
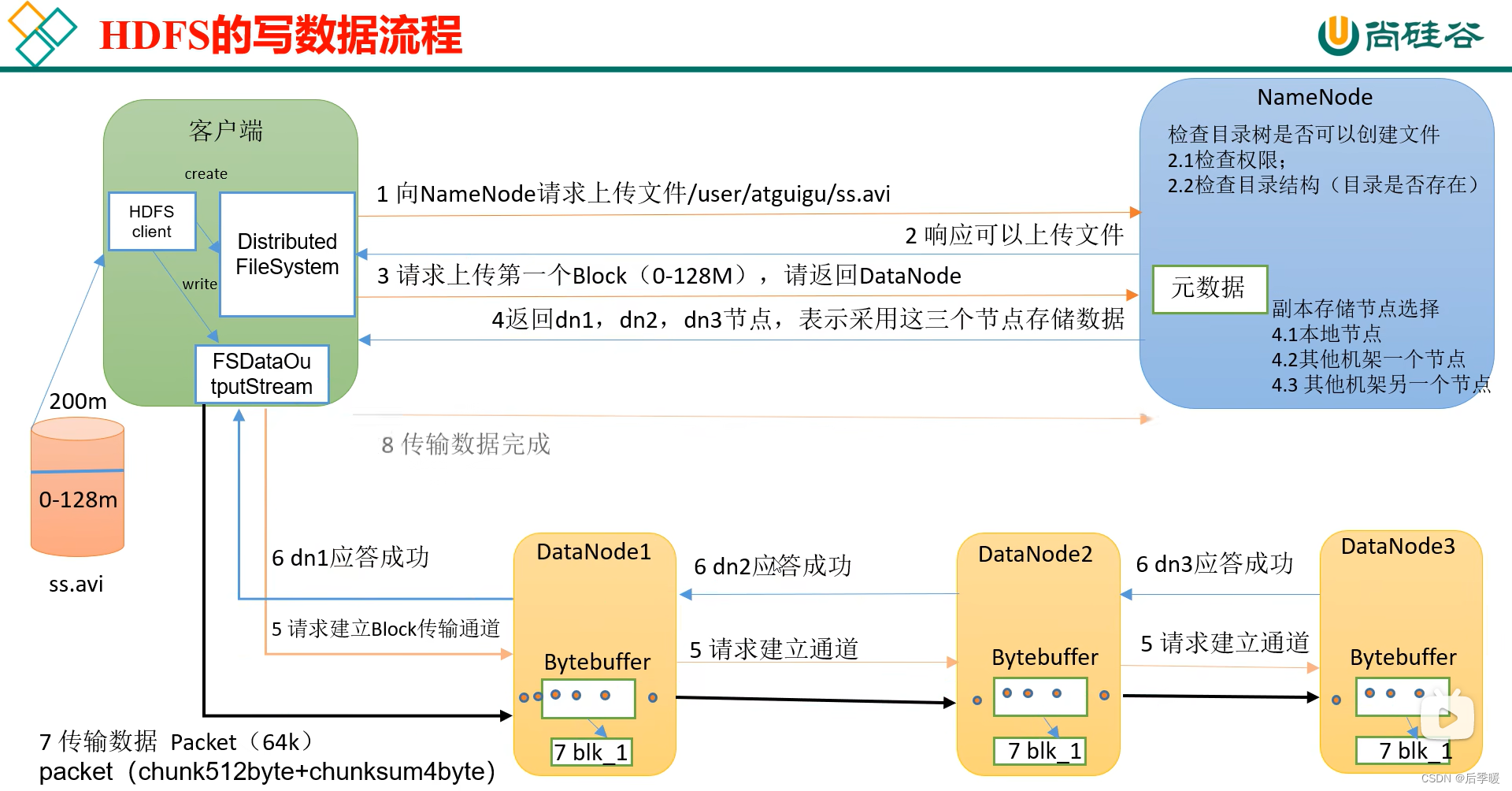
HDFS写文件:
先从客户端发送请求上传文件 检查权限、目录是否存在 然后响应可以上传文件 客户端再请求上传第一个Block 但是要知道都写在哪 所以就又去找NameNode NN分配了三个节点的位置 然后建立Block传输管道(内存写一份 磁盘写一份)首先应答成功 然后开始传输packet(packet由chunk组成)
2NN工作机制:(就是NN的数据2NN内存也保存一份)
fsimage是存储数据的 Edits存储你的操作数据(追加写的内容)所以效率高 不用每次改原文件 只需要记录追加的内容 最后和fsimage合并加载到内存中 服务器启动加载编辑日志和镜像文件到内存 此时客户端访问 发送元数据的增删改请求 先写到编辑日志 然后再修改内存 那边的2NN会定时发送是否需要checkpoint 如果需要就滚动正在写的编辑日志 同时生成一个edits002 用来接收客户端可能发送的请求 然后把edits001拷贝一份到2NN 镜像文件也拷贝到2NN 然后加载到内存并合并, 镜像文件和编辑文件(edits)最后生成一个新的镜像文件重命名成fsimage到NN


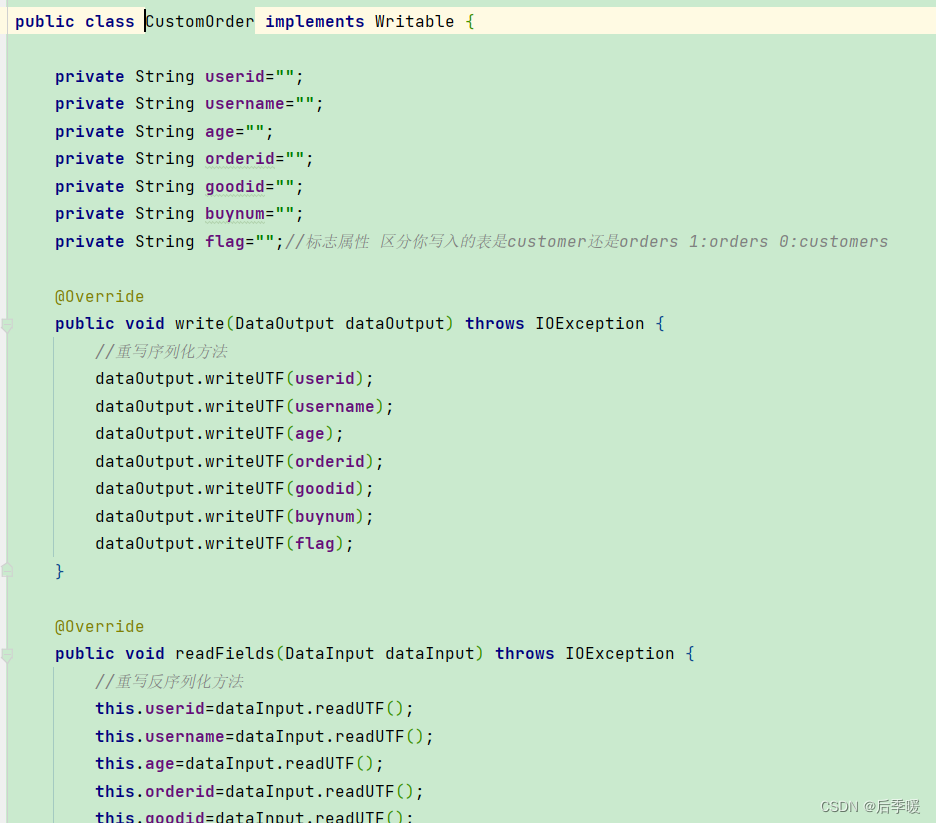
hadoop的序列化和反序列化:hadoop并没有使用java的序列化规则 因为java的序列化是一个重量级的序列化 产生的文件较大 序列化时要实现writable接口 重写write和readFile方法
大数据(MapReduce)面试题及答案_技术交流_牛客网 (nowcoder.com)


自定义分区 继承 Partitioner 实现方法getPartition
驱动类 Driver:job.setPartitionerClass
有一种优化 用于汇总之类的 排序这些没用 就是自定义Combiner extends Reducer
然后job.setCombinerClass 要求是这个Combiner类的进和出数据类型都一样
继承writable类 实现的方法:
mapreduce的join怎么理解?map端输出的key value 和 reduce端接收的key value
这两个key就是连接的字段(相当于)
mapjoin的方式 在setup方法里:

然后reduce都不需要:

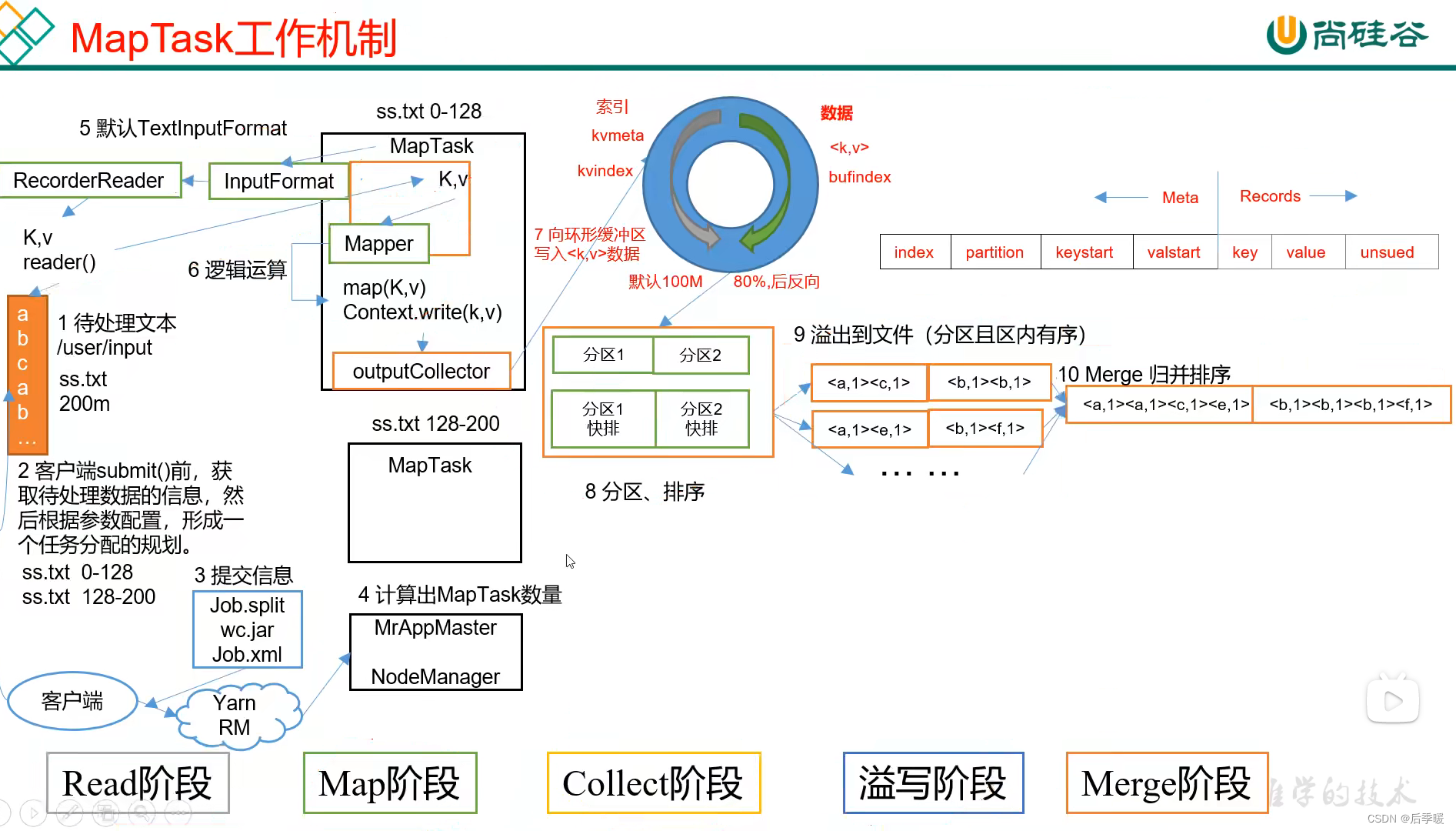 MapReduce整体流程:
MapReduce整体流程:
1、客户端submit(),提交任务(submit源码:处理新旧api兼容问题、连接本地或者yarn客户端等等)2、然后执行到submitJobInternal方法 内部会申请一个jobid 然后进入到 copyAndConfigureFiles(job, submitJobDir)方法 里面向集群提交了一些配置文件和jar包(如果是集群模式会提交JobJar,如果是本地模式则不会提交) 还设置了切片数量等等(就是切片规划) 最后wirte写到客户端( 我们可以说通过查看源码返现客户端提交了这三个文件给集群: job.xml、 job.split、 job.jar)。Yarn调用ResourceManager来创建MrAppMaster,而MrAppMaster则会根据切片的个数来创建MapTask。
其中切片规划: InputFormat(默认为TextInputFormat)通过getSplits 方法对输入目录中的文件进行逻辑切片,并序列化成job.split文件。默认情况下,HDFS上的一个block对应一个InputSplit,一个InputSplit对应开启一个MapTask。
2.然后就是读取数据 InputFormat默认是TextInputFormat 来构造一个recordreader对象调用read()方法来读取一行一行文本进入map方法 然后经过map方法内部我们自定义的逻辑运算后进入到OutPutCollector,然后被读取到环形缓冲区中
环形缓冲区(默认100M)详解:其实在进入缓冲区之前源码先进入到getpartition方法来获取每段数据的分区 然后:
3.一个方向存索引 一个方向存数据 从一个点出发 不同方向读map方法后的数据和元数据依次存放到两个方向(元数据包含了索引 每个数据的分区 起始位置和结束位置) 当空间还剩20%的时候 就从两个箭头中间开始 往回溢写(为什么要留20%,因为如果是满了开始溢写 读取数据那边不能读了 就要等溢写完 这样效率低 容易阻塞)每次溢写前都会对要溢写的文件中的key(其实是key的索引)排个序(快排)这里排序也不是拖真数据 只是让索引记录他们的位置上改变(这里是在内存上排的) 这样提升了很多效率(排序key 当然key后面的value也一样跟着排,而且只是在分区里面排,因为读到环形缓存区以后通过索引就知道他们的partiton了)每次溢写都生成的是一个文件(文件中记录着每个分区的这些排好序了的数据)可能多次溢写就是多个文件 然后进行归并排序 把所有排序好了的key value再归并到自己的分区得到了一个大文件 每个map对应一个大文件
4.然后就是shuffle 先把刚刚那些maptask得到的大文件下载到reduce task本地磁盘工作目录 一个reducetask拷贝一个分区的数据到自己这来(就是拉取数据)拉进来以后发现又不是有序了 就又要排序(就相当于分组)又是一次归并排序 排序的结果是一个大文件 所以此时一个reducetask一个大文件
5.然后开始取出key相同的键值对进入reduce方法进入逻辑运算 最后经过outputformat构造recordWriter对象调用write方法写到part-r-000**文件当中 每个reducetask对应一个输出文件

○ HDFS 上每个文件都要在 NameNode 上创建对应的元数据,这个元数据的大小约为150byte,这样当小文件比较多的时候,就会产生很多的元数据文件,一方面会大量占用NameNode 的内存空间,另一方面就是元数据文件过多,使得寻址索引速度变慢。
○ 小文件过多,在进行 MR 计算时,会生成过多切片,需要启动过多个 MapTask。每个MapTask 处理的数据量小,导致 MapTask 的处理时间比启动时间还小,白白消耗资源。
● 1) 小文件优化的方向:
○ 1)在数据采集的时候,就将小文件或小批数据合成大文件再上传 HDFS。
○ 2)在业务处理之前,在 HDFS 上使用 MapReduce 程序对小文件进行合并。
○ 3)在 MapReduce 处理时,可采用 CombineTextInputFormat 提高效率
○ 4)开启 uber 模式,实现 jvm 重用
CombineTextInputFormat可以将小文件合并的读 解决小文件过多的问题

Yarn工作机制
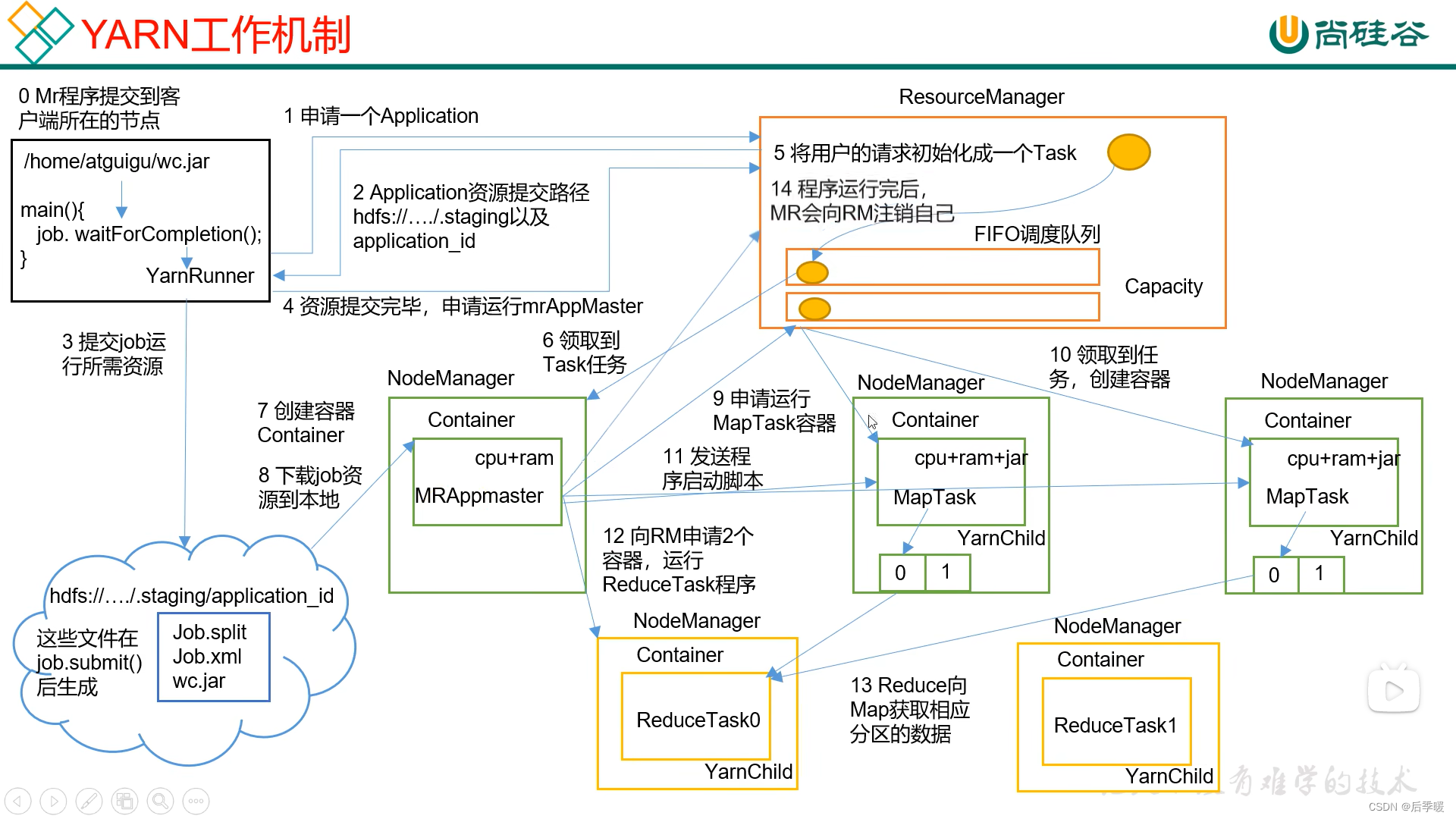
1.首先客户端提交作业,向ResourceManager申请一个jobid,然后它返回一个hdfs的资源提交路径和jobid给客户端
2.然后客户端向这个路径提交job运行所需要的资源job.xml、job.split、jar包
3.资源提交完毕以后,向ResourceManager再发请求,执行作业,然后ResourceManager中的Application Manager将请求转发到调度器Resource Scheduler,调度器将任务请求放到调度队列
4.(每次执行到相应的请求时,调度器会通知Application Manager分配容器)
此时找一个空闲的机器调用NodeManager(这个就是主节点)创建容器并存放作业对应的Application Master在主节点中,然后启动Application Master,它会下载hdfs上的资源。
5.然后Application Master向调度器申请MapTask容器,哪里可以干活,然后通知别的NodeManager创建容器,执行任务。然后又向调度器申请ReduceTask的容器,创建容器,执行任务。
6.任务完成,发送请求,释放资源。
yarn-site.xml 改配置参数
scala:

hive
load和location的区别: 表存在一般是load 表不存在一般是location



静态分区插入数据要指定插入到哪个分区

动态分区插入数据一般是insert into ... select...

分桶表:抽样的时候用的多
(3条消息) hive分桶查询详解以及分桶抽样_Mercury_春秋的博客-CSDN博客_hive查看分桶信息
left join 每次都要全扫 exists是唯一性扫描 扫到就不扫了 换下一行
sort by和order by:
order by和sort by的区别_sort by和order by_数仓白菜白的博客-CSDN博客
unix时间戳转日期:select from_unixtime(1323308943,'yyyyMMdd') from lxw_dual; 20111208
获取当前 UNIX 时间戳函数: select unix_timestamp() from lxw_dual; 1323309615
日期转 UNIX 时间戳函数:select unix_timestamp('2011-12-07 13:01:03') from lxw_dual; 1323234063
指定格式日期转 UNIX 时间戳函数:select unix_timestamp('20111207 13:01:03','yyyyMMdd HH:mm:ss') from lxw_dual; 1323234063
日期时间转日期函数:select to_date('2011-12-08 10:03:01') from lxw_dual; 2011-12-08
字符串转时间:SELECT DATE_FORMAT('2022-07-04 15:10:25', 'yyyy-MM-dd HH:mm:ss') AS time;
数据倾斜:自己csdn

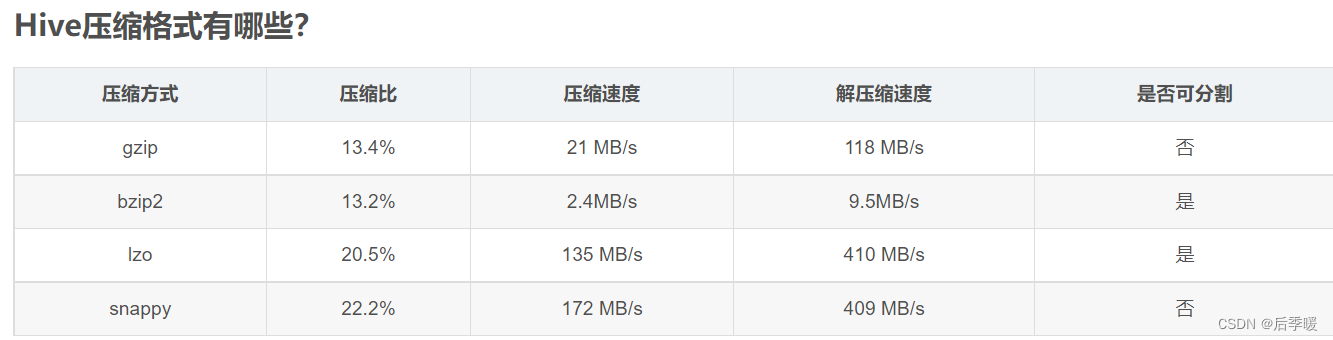


zookeeper选举机制 就是

如果票数都一样 就比较每台机器的事务id
Hbase:
HBASE是一个高可靠性、高性能、面向列、可拓展性的分布式存储系统,利用HBASE技术可在廉价PC Server上搭建起大规模结构化存储集群。

rowkey就是一个用来标识哪几条数据属于一个人的 这个意思 比如rowkey是userid这个字段
那么你添加数据的时候 下面那个rowkey你写1 就代表这条数据是属于userid为1的那个人
列族很简单 就是你一些字段的一个父类 所以添加数据必须先有rowkey,再有列族:列名 ,值名

limit就是查找几行 跟rowkey无关 比如limit=3 可能scan出来的都是一个userid的各种属性值
hbase读写原理
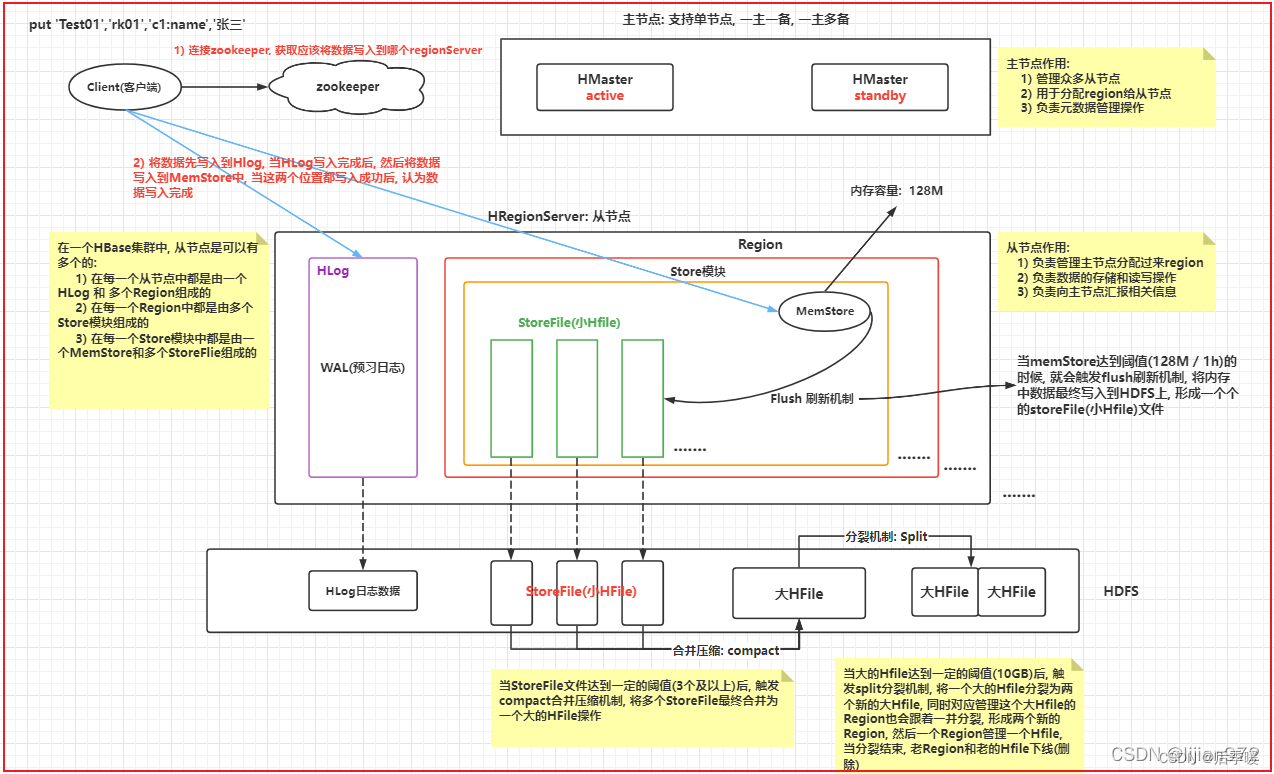
HBase首先有Client客户端、zookeeper、HMaster
HMaster管理着多个HRegionServer 它一般依附在Namenode上
其中zookeeper用来存储HBase的元数据,当Client向zookeeper发送读写请求时,zookeeper会返回元数据给Client告诉它去哪台机器(HRegionServer)读写数据,假如是写数据 会先将数据写到HLog中,HLog主要靠WAL起作用,主要为了灾难恢复,实现数据的高可靠性,为了防止缓存数据丢失,数据写入缓存之前需要首先写入HLog,这样,即使缓存数据丢失,仍然可以通过HLog日志恢复。然后HBase数据随机写入时,并非直接写入HFile数据文件,而是先写入缓存,再异步刷新落盘。
数据写入到对应Region的对应Store模块的MemStore中 当这两个地方都写入完成后,客户端认为数据写入完成了 随着客户端不断的写入操作, memstore中数据会越来越多, 当内存中数据达到阈值(128M)后, 就会触发flush刷新机制, 将数据<最终>刷新到StoreFile(Hfile)文件,当HFile达到一定的阈值(10G)后, 会触发Split分裂机制,将大HFile进行一分为二,形成两个新的HFile, 同时管理这个HFile的Region也会形成两个新的Region, 形成的两个新的Region和两个新的HFile,进行一对一的管理即可 region过多了也会触发负载均衡 重新规划分区 放到不同的regionserver上
最后storefile(HFile)序列化后存储到datanode上,
如果是读取的话,读取顺序:MemStore —> blockCache(读缓存专有) —> HFile
这里的blockCache就是读缓存的核心 和HRegionServer是同级的就像外卖员把东西放到这个区域 然后有邻近的请求或者邻近数据就去读缓存 这样就可以减少对磁盘io(读)的频度
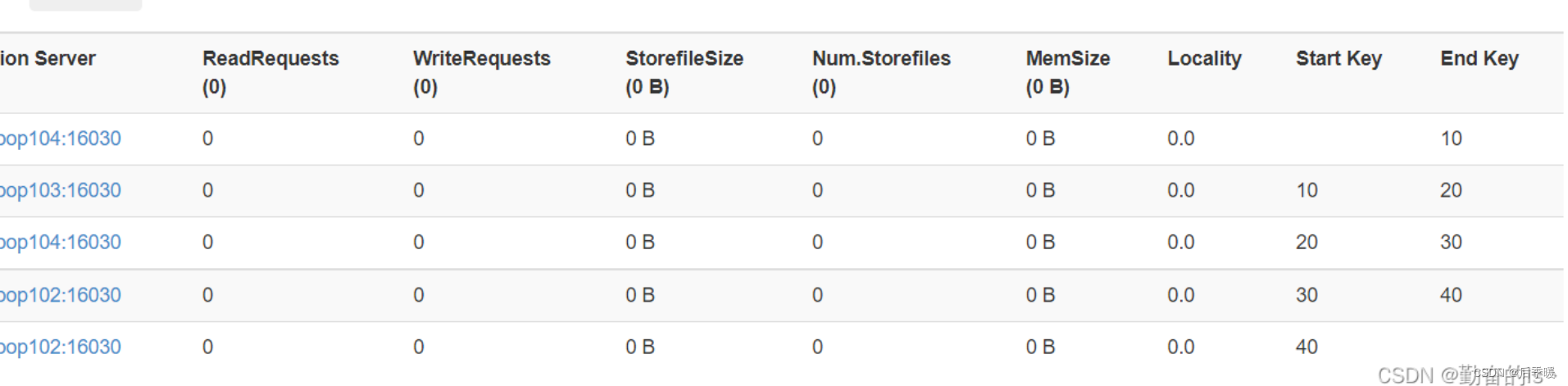
hbase预分区:

这个10 20 30 40是你自己随机便写的 如图就是五个区
它会自己根据你的rowkey选择分到不同的区 不用在意具体实现
第二种:根据rowkey的值算出他们的十六进制 分到十五个分区 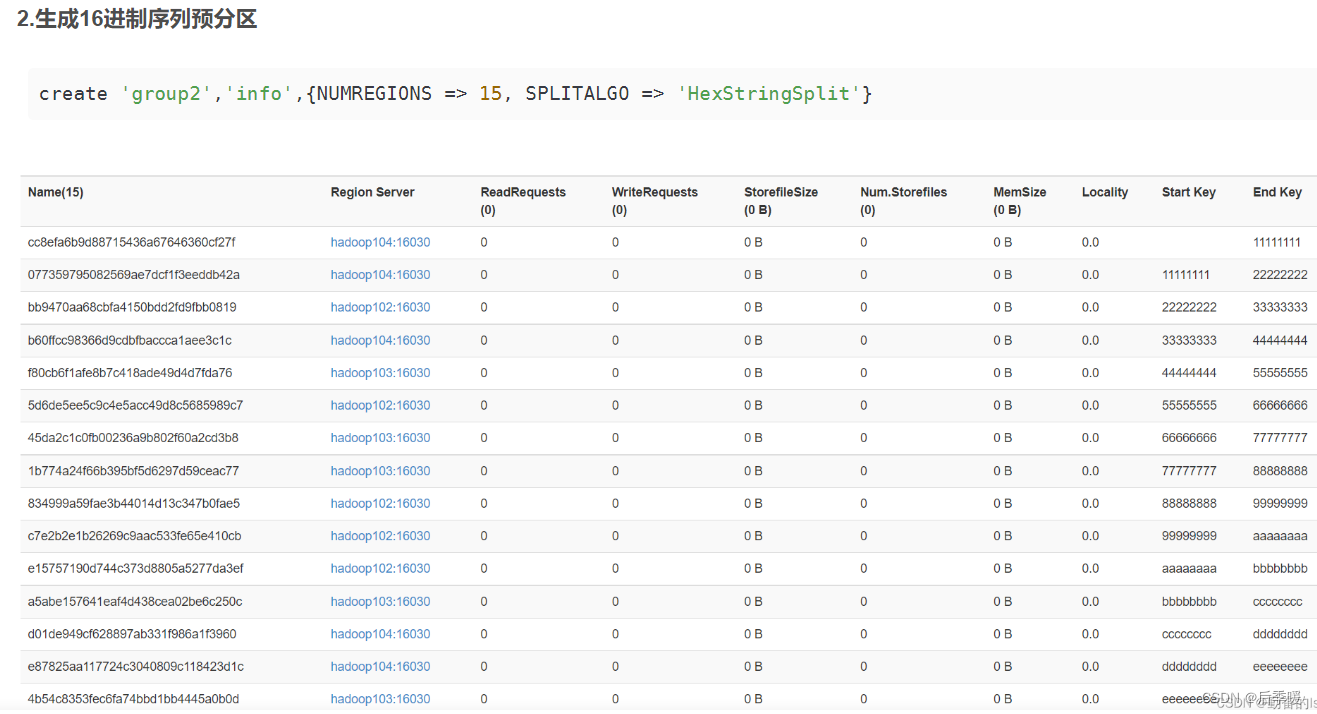
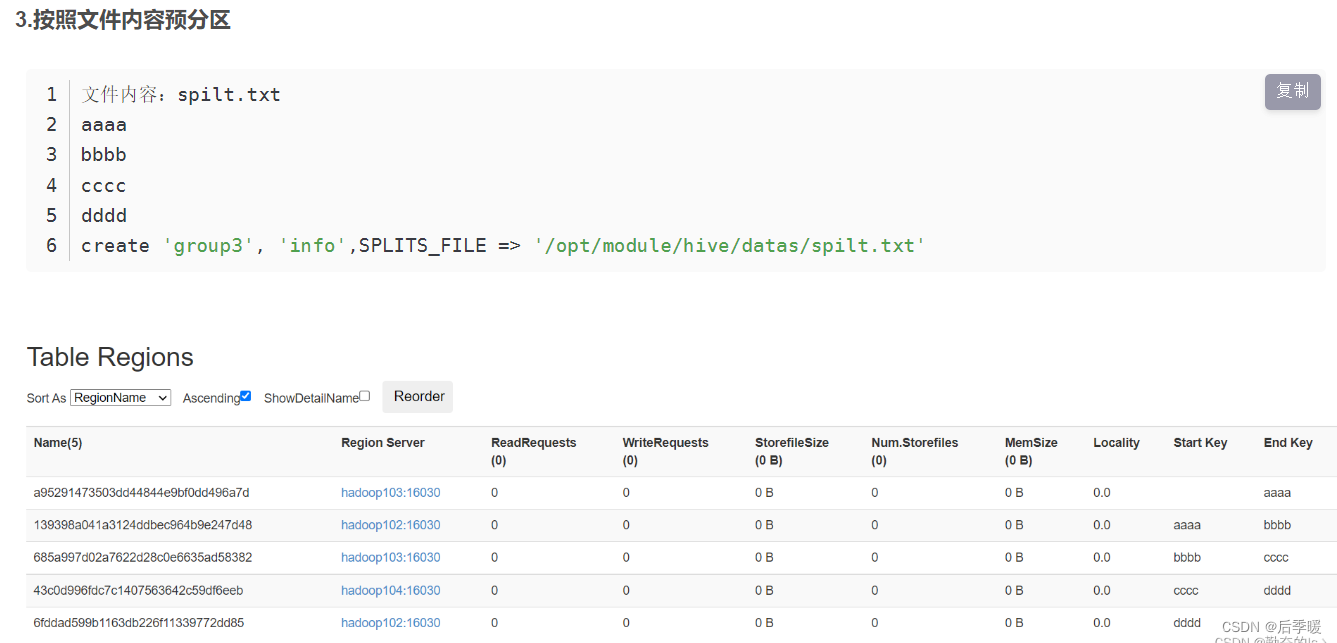
最后一个按javaapi分区不重要
什么是热点?(就是多数数据集中在少数region当中)
HBase中的行是按照rowkey的字典顺序排序的,这种设计优化了scan操作,可以将相关的行以及会被一起读取的行存取在临近位置,便于scan。然而糟糕的rowkey设计是热点的源头。热点发生在大量的client直接访问集群的一个或极少数个节点(访问可能是读,写或者其他操作)。大量访问会使热点region所在的单个机器超出自身承受能力,引起性能下降甚至region不可用,这也会影响同一个RegionServer上的其他region,由于主机无法服务其他region的请求。设计良好的数据访问模式以使集群被充分,均衡的利用。
常见的解决办法:(哈希比较常用,因为哈希还能解决去重问题 因为相同的值哈希值也相同
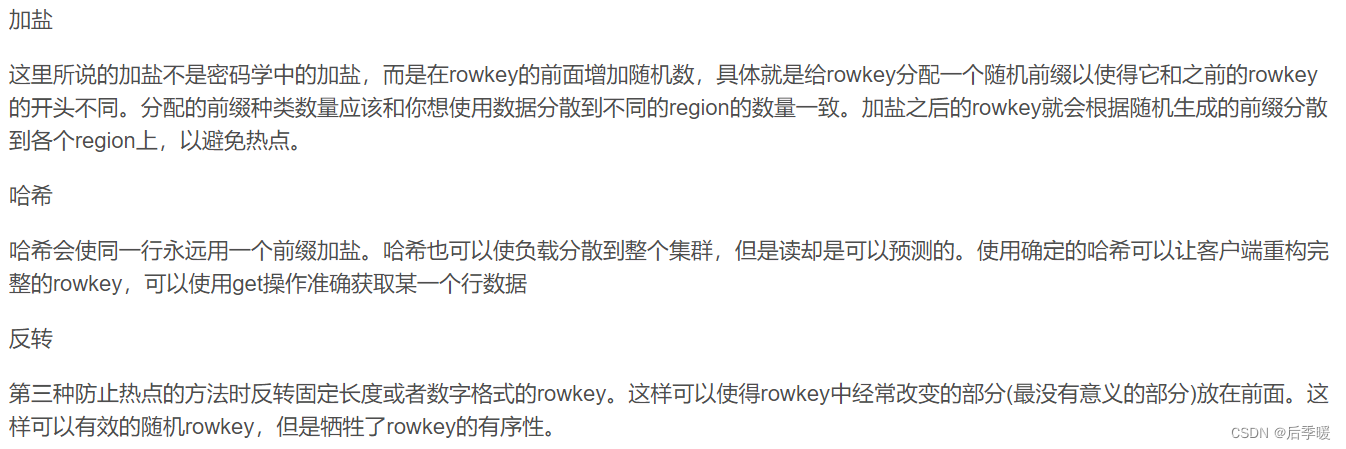
rowkey三大设计原则
第一个是散列原则:如果是rowkey按照时间戳或者是顺序递增
那么将会产生热点现象 建议将rowkey的高位作为散列字段,由程序随机生成,低位放时间字段,这样将提高数据均衡分布在每个RegionServer,以实现负载均衡的几率
第二个是长度原则:
RowKey的长度不宜过长,不宜超过16个字节,最大长度64kb,实际应用中一般为10-100bytes,以byte[]形式保存。一条数据是根据rowkey来当成索引的,如果过长就会快速占据memstore的128M,然后被刷写到磁盘,也就是说相同的空间存贮的内容被rowkey占据了一大部分,减少了主要内容的存贮。
第三个是唯一原则
必须在设计上保证其唯一性, rowkey可以锁定唯一的一行数据,rowkey重复的话后put的数据会覆盖前面插入的数据
sqoop
指定过滤 --where "order_id<500" 通过columns指定 --columns "order_id,uid"


说白了就是 append一般指定递增列(时间也行)但是只能追加
lastmodified可以追加 还可以通过merge-key xx 来合并两个xx字段相同的数据 比如merge-key id 那么这次增量导入的id已经有了的数据直接在原数据上更新即可
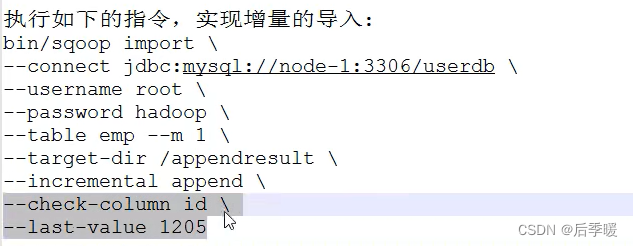
check-column是你指定的某个递增的字段 一般是id 然后last-value就是你指定的这个字段上次的最大值(也就是你最后更新到哪)所以check-column和last-value是连起来用的

直接导入到hive分区表

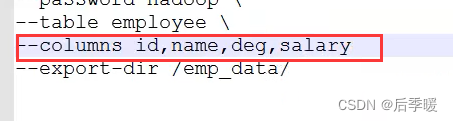
假如mysql字段顺序和hdfs中文件的不一样 那就要指定字段顺序
Sqoop导入导出Null存储一致性问题
Hive中的Null在底层是以“\N”来存储,而MySQL中的Null在底层就是Null,为了保证数据两端的一致性。在导出数据时采用--input-null-string和--input-null-non-string两个参数。导入数据时采用--null-string和--null-non-string。
Sqoop底层运行的任务是什么 只有Map阶段,没有Reduce阶段的任务。默认是4个MapTask。
