哈喽大家好 ! 我是唐宋宋宋,很荣幸与您相见!!
Dice Loss
Dice Loss是由Dice系数而得名的,Dice系数是一种用于评估两个样本相似性的度量函数,其值越大意味着这两个样本越相似,Dice系数的数学表达式如下:

其中 |X∩Y| 是X和Y之间的交集,|X|和|Y|分表表示X和Y的元素的个数,其中,分子的系数为2是保证分母重复计算后取值范围在 [0-1] 之间。Dice Loss表达式如下:
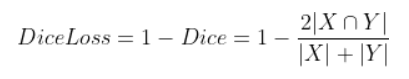
Dice Loss常用于语义分割问题中,X表示真实分割图像的像素标签,Y表示模型预测分割图像的像素类别,|X∩Y|近似为预测图像的像素与真实标签图像的像素之间的点乘,并将点乘结果相加,|X|和|Y|分别近似为它们各自对应图像中的像素相加。
对于二分类问题,真实分割标签图像的像素只有0,1两个值,因此|X∩Y|可以有效地将在预测分割图像中未在真实分割标签图像中激活的所有像素值清零,对于激活的像素,主要是惩罚低置信度的预测,置信度高的预测会得到较高的Dice系数,从而得到较低的Dice Loss。
Dice Loss可以缓解样本中前景背景(面积)不平衡带来的消极影响,前景背景不平衡也就是说图像中大部分区域是不包含目标的,只有一小部分区域包含目标。Dice Loss训练更关注对前景区域的挖掘,但会存在损失饱和问题,而CE Loss是平等地计算每个像素点的损失,当前点的损失只和当前预测值与真实标签值的距离有关,这会导致一些问题。因此单独使用Dice Loss往往并不能取得较好的结果,需要进行组合使用,比如Dice Loss+CE Loss或者Dice Loss+Focal Loss等。
Dice Loss代码如下:
def Dice_loss(inputs, target, beta=1, smooth = 1e-5):
n, c, h, w = inputs.size()
nt, ht, wt, ct = target.size()
if h != ht and w != wt:
inputs = F.interpolate(inputs, size=(ht, wt), mode="bilinear", align_corners=True)
temp_inputs = torch.softmax(inputs.transpose(1, 2).transpose(2, 3).contiguous().view(n, -1, c),-1)
temp_target = target.view(n, -1, ct)
#--------------------------------------------#
# 计算dice loss
#--------------------------------------------#
tp = torch.sum(temp_target[...,:-1] * temp_inputs, axis=[0,1])
fp = torch.sum(temp_inputs , axis=[0,1]) - tp
fn = torch.sum(temp_target[...,:-1] , axis=[0,1]) - tp
score = ((1 + beta ** 2) * tp + smooth) / ((1 + beta ** 2) * tp + beta ** 2 * fn + fp + smooth)
#torch.mean(score) 就是我们的dice系数
dice_loss = 1 - torch.mean(score)
return dice_loss补充:F.interpolate——数组采样操作
torch.nn.functional.interpolate(input, size=None, scale_factor=None, mode='nearest', align_corners=None, recompute_scale_factor=None)功能:利用插值方法,对输入的张量数组进行上\下采样操作,换句话说就是科学合理地改变数组的尺寸大小,尽量保持数据完整。
-input(Tensor):需要进行采样处理的数组。
-size(int或序列):输出空间的大小
-scale_factor(float或序列):空间大小的乘数
-mode(str):用于采样的算法。'nearest'| 'linear'| 'bilinear'| 'bicubic'| 'trilinear'| 'area'。默认:'nearest'
-align_corners(bool):在几何上,我们将输入和输出的像素视为正方形而不是点。如果设置为True,则 输入和输出张量按其角像素的中心点对齐,保留角像素处的值。如果设置为False,则输入和输出张量通过其角像素的角点对齐,并且插值使用边缘值填充用于边界外值,使此操作在保持不变时独立于输入大小scale_factor。
-recompute_scale_facto(bool):重新计算用于插值计算的 scale_factor。当scale_factor作为参数传递时,它用于计算output_size。如果recompute_scale_factor的False或没有指定,传入的scale_factor将在插值计算中使用。否则,将根据用于插值计算的输出和输入大小计算新的scale_factor(即,如果计算的output_size显式传入,则计算将相同 )。注意当scale_factor 是浮点数,由于舍入和精度问题,重新计算的 scale_factor 可能与传入的不同。
dice loss为何能够解决正负样本不平衡问题?
因为dice loss是一个区域相关的loss。区域相关的意思就是,当前像素的loss不光和当前像素的预测值相关,和其他点的值也相关。dice loss的求交的形式可以理解为mask掩码操作,因此不管图片有多大,固定大小的正样本的区域计算的loss是一样的,对网络起到的监督贡献不会随着图片的大小而变化。从上图可视化也发现,训练更倾向于挖掘前景区域,正负样本不平衡的情况就是前景占比较小。而ce loss 会公平处理正负样本,当出现正样本占比较小时,就会被更多的负样本淹没。
dice loss 为何训练会很不稳定?
在使用dice loss时,一般正样本为小目标时会产生严重的震荡。因为在只有前景和背景的情况下,小目标一旦有部分像素预测错误,那么就会导致loss值大幅度的变动,从而导致梯度变化剧烈。可以假设极端情况,只有一个像素为正样本,如果该像素预测正确了,不管其他像素预测如何,loss 就接近0,预测错误了,loss 接近1。而对于ce loss,loss的值是总体求平均的,更多会依赖负样本的地方。
总结
dice loss 对正负样本严重不平衡的场景有着不错的性能,训练过程中更侧重对前景区域的挖掘。但训练loss容易不稳定,尤其是小目标的情况下。另外极端情况会导致梯度饱和现象。因此有一些改进操作,主要是结合ce loss等改进,比如: dice+ce loss,dice + focal loss等.
引用了这些博住的知识点,我进行了一个总结,在这里表示感谢。
(44条消息) F.interpolate——数组采样操作_视觉萌新、的博客-CSDN博客