randomForestExplainer
1.写在前面
上个星期花了大量的时间在做关于随机森林方面的学习,自己也编写相关的代码来实现需求。前几天和老师交流后,觉得应该做个多个因素的交互作用,比如三个或者更多,那么就需要通过三维曲面图来显示结构,但经过多种尝试,试了很多函数、R包、以及用python来编写,一直都没能成功,花了大概几天的时间,确实感觉按照目前的能力来说,还无法实现。于是,尝试着用双因子进行交互,这方面randomForest还是很快就能实现的,所以现在把自己学到的一个新的R package记录一下,如果您了解这方面的内容,或者对随机森林的交互作用有自己的见解,咱们可以进行交流,相互学习。
2. randomForestExplainer介绍

这篇文档演示了如何使用 randomForestExplainer 包。我们将使用 MASS 包中的 Boston 数据集。由于通常需要建立大型的森林,并且计算量很大,因此在这里我们使用较小的 Boston 数据集,并鼓励您阅读有关 glioblastoma 大型数据集的分析。
2.1 数据加载:
library(randomForest)
# devtools::install_github("MI2DataLab/randomForestExplainer")
library(randomForestExplainer)
2.2 数据展示:
data(Boston, package = "MASS")
Boston$chas <- as.logical(Boston$chas)
str(Boston)
'data.frame': 506 obs. of 14 variables:
$ crim : num 0.00632 0.02731 0.02729 0.03237 0.06905 ...
$ zn : num 18 0 0 0 0 0 12.5 12.5 12.5 12.5 ...
$ indus : num 2.31 7.07 7.07 2.18 2.18 2.18 7.87 7.87 7.87 7.87 ...
$ chas : logi FALSE FALSE FALSE FALSE FALSE FALSE ...
$ nox : num 0.538 0.469 0.469 0.458 0.458 0.458 0.524 0.524 0.524 0.524 ...
$ rm : num 6.58 6.42 7.18 7 7.15 ...
$ age : num 65.2 78.9 61.1 45.8 54.2 58.7 66.6 96.1 100 85.9 ...
$ dis : num 4.09 4.97 4.97 6.06 6.06 ...
$ rad : int 1 2 2 3 3 3 5 5 5 5 ...
$ tax : num 296 242 242 222 222 222 311 311 311 311 ...
$ ptratio: num 15.3 17.8 17.8 18.7 18.7 18.7 15.2 15.2 15.2 15.2 ...
$ black : num 397 397 393 395 397 ...
$ lstat : num 4.98 9.14 4.03 2.94 5.33 ...
$ medv : num 24 21.6 34.7 33.4 36.2 28.7 22.9 27.1 16.5 18.9 ...
3.构建随机森林模型
如何理解随机森林中localImp = TRUE?
在随机森林中,localImp = TRUE 是一个参数,用于指定是否计算每个预测变量在每个个体上的局部重要性(local importance)。当将此参数设置为 TRUE 时,随机森林将计算出每个个体对于模型预测结果的贡献度,并将其分配给每个预测变量。这使得可以在个体级别上分析每个预测变量的重要性,即可以了解每个预测变量对于单个观测值的预测结果的影响程度。在计算局部重要性时,通常使用袋装重抽样方法(bootstrap sampling)来减少估计偏差。
set.seed(2023)
forest <- randomForest(medv ~ ., data = Boston, localImp = TRUE)
forest
Call:
randomForest(formula = medv ~ ., data = Boston, localImp = TRUE)
Type of random forest: regression
Number of trees: 500
No. of variables tried at each split: 4
Mean of squared residuals: 9.793518
% Var explained: 88.4
4. 最小深度的分布
绘制最小深度的分布的意义?
plot_min_depth_distribution() 函数可以用来可视化随机森林中各个特征的最小深度分布,帮助我们了解每个特征对于预测的重要性。具体来说,最小深度是指在随机森林中,每个特征在所有决策树中出现的最小深度。 这个值越小,表示该特征越重要。 因此,通过观察最小深度分布图,我们可以快速确定哪些特征在随机森林中起着重要的作用,进而优化特征的选择和模型的性能。
为了获得最小深度的分布,我们将随机森林传递给 min_depth_distribution 函数,并存储结果。结果包含以下列(由于计算需要一些时间,我们将其保存在内存中以便以后使用):
## Distribution of minimal depth
# 依次使用 randomForestExplainer 的所有函数,并对获得的结果进行评论
min_depth_frame <- min_depth_distribution(forest)
save(min_depth_frame, file = "min_depth_frame.rda")
load("min_depth_frame.rda")
head(min_depth_frame, n = 10)
tree variable minimal_depth
1 1 age 3
2 1 black 5
3 1 chas 9
4 1 crim 2
5 1 dis 4
6 1 indus 3
7 1 lstat 1
8 1 nox 4
9 1 ptratio 2
10 1 rad 5
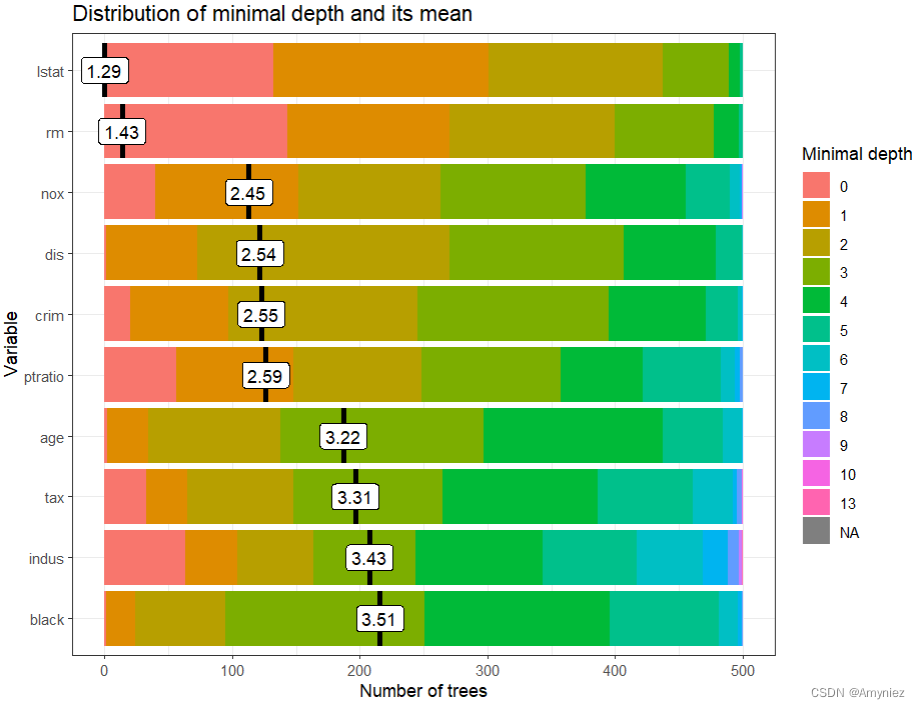
接下来,将其传递给 plot_min_depth_distribution 函数,并使用默认设置获得了一个图,显示根据使用前十棵树 (mean_sample =“top_trees”) 注意这里的参数计算的平均最小深度,每个变量的最小深度分布。如果我们要绘制多个最小深度分布图,则可以直接将我们的随机森林传递给绘图函数,但是如果要进行多个绘图,则更有效的方法是将 min_depth_frame 传递给绘图函数,这样它不会为每个绘图重新计算(这也类似于 randomForestExplainer 的其他绘图函数)。
# plot_min_depth_distribution(forest) # 结果相同但是运行时间更长
plot_min_depth_distribution(min_depth_frame)
4.1 plot_min_depth_distribution函数的参数
函数plot_min_depth_distribution提供了三种可能的选项来计算平均最小深度,它们在处理变量在树中未被用于分裂时出现的缺失值方面存在差异。它们可以描述如下:
- mean_sample = “all_trees”(填充缺失值):如果一个变量在树中没有被用于分裂,则该变量的最小深度等于所有树的平均深度。请注意,树的深度等于从根到叶子节点的最长路径的长度。这等于该树中变量的最大深度加一,因为叶子节点根据定义不会被任何变量分裂。
- mean_sample = “top_trees” 是一种限制样本的计算平均最小深度的方法。在此方法中,仅考虑 B~ (如500) 个树,其中 B~ 是任何变量用于拆分的最大树的数量。对于那些用于拆分少于 B~ 次的变量的剩余缺失值,将填充为 mean_sample = “all_trees” 中所述的方式。
- mean_sample = “relevant_trees”(忽略缺失值):计算平均最小深度时仅使用非缺失值。
这里的x轴范围从0到所有变量中使用于分裂的树的最大数目(B~),在本例中等于500,并且所有绘制的变量都达到了这个最大值。
图中,变量按平均最小深度排序,看起来相当准确,尽管存在争议,例如indus应该比dis排名更高,因为后者从未用于根节点的分裂。当我们改变mean_sample选项时,通常会获得不同的变量排序,但是如果所有树都使用变量进行分裂,则不会发生这种情况,因为此选项仅影响如何以及是否处理缺失值。默认选项“top_trees” 对缺失值进行惩罚,这种惩罚使值的解释变得不太明显。为了解决这个问题,可以仅使用非缺失观测值计算平均最小深度(mean_sample =“relevant_trees”)。对于具有许多变量和大量缺失观测值的森林,应始终考虑添加min_no_of_trees选项,以便仅在至少声明的树中用于分裂的变量。这使我们能够避免选择仅被偶然用于分裂例如只在根处使用一次的变量(它们的平均值将等于0)。但是,在我们的情况下,我们可以简单地增加k参数以绘制所有树:
plot_min_depth_distribution(min_depth_frame, mean_sample = "relevant_trees",
k = 15, mean_scale=TRUE, main= "Distribution of minimal depth") # k为最大变量数
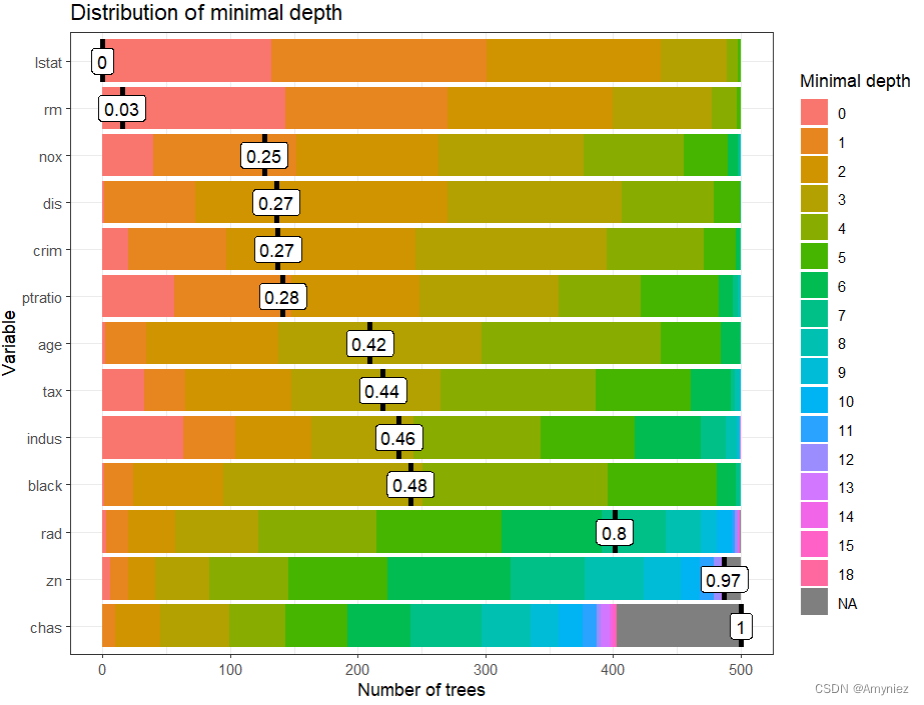
显然,只使用相关树来计算均值并不会改变那些没有缺失值的变量的均值。在这种情况下,变化并不会影响变量的排序,但在更复杂的例子中通常不是这种情况。
无论在 plot_min_depth_distribution 中使用什么参数,查看整个最小深度分布相比仅查看均值会提供更多有关预测变量在森林中发挥作用的见解,特别是因为可以以多种方式计算均值。此外,该函数允许我们指定绘制的最大变量数 k、是否将均值最小深度值缩放到 [0,1] 区间(mean_scale,逻辑)、舍入用于显示均值的位数(mean_round)和绘图的标题(main)。
5.变量重要性
将训练好的随机森林传递给measure_importance函数,获得重要性数据数组:
# Various variable importance measures
importance_frame <- measure_importance(forest) # mean_sample参数,默认为“top_trees”; measures参数,默认为NULL,导致计算所有度量
save(importance_frame, file = "importance_frame.rda")
load("importance_frame.rda")
importance_frame
variable mean_min_depth no_of_nodes mse_increase node_purity_increase no_of_trees
1 age 3.21800 9070 4.2510362 1126.8328 500
2 black 3.51400 8015 1.7101238 779.6626 500
3 chas 6.45162 736 0.7706690 223.7377 403
4 crim 2.55400 9388 8.2946300 2245.7347 500
5 dis 2.54200 9210 7.3374224 2458.3168 500
6 indus 3.43000 4239 5.6495909 2372.2088 500
7 lstat 1.28600 11129 63.2892439 12394.3668 500
8 nox 2.45400 6248 10.4210162 2814.5932 500
9 ptratio 2.58800 4595 7.3896667 2665.5869 500
10 rad 4.99746 2666 1.4400123 357.2610 499
11 rm 1.42600 11514 33.9459827 12558.5167 500
12 tax 3.31400 4420 4.8688001 1519.1153 500
13 zn 5.85152 1633 0.7628575 332.5409 488
times_a_root p_value
1 2 4.469233e-242
2 1 7.699206e-95
3 0 1.000000e+00
4 20 1.774755e-298
5 1 3.014263e-266
6 63 1.000000e+00
7 132 0.000000e+00
8 40 9.508719e-01
9 56 1.000000e+00
10 3 1.000000e+00
11 143 0.000000e+00
12 33 1.000000e+00
13 6 1.000000e+00
数据包含13行,每一行对应一个预测器,其中8列存储变量名,其余存储变量Xj的变量重要性度量:
- accuracy_reduce(分类):Xj被替换后预测精度下降的平均值,
- gini_reduce(分类):Xj上的分裂对节点杂质Gini指数的平均降低(即节点纯度的增加),
- mse_increase(回归):Xj被打乱后均方误差的平均增加量,
- node_purity_increase(回归):Xj上的平均节点纯度增加,通过平方和的减少来衡量,
- Mean_minimal_depth:用参数mean_sample指定的三种方法之一计算的最小平均深度,
- no_of_trees:在Xj上发生分裂的树的总数,
- no_of_nodes:使用Xj进行分割的节点总数(如果树很浅,通常等于no_of_trees),
- times_a_root:使用Xj拆分根节点的树的总数(即,根据Xj的值将整个样本分为两个),
- P_value - p-value:用于单边二项检验,使用以下分布:
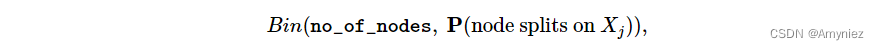
假设Xj是从r个候选变量中均匀抽取的,我们计算Xj分裂的概率

这个检验告诉我们观察到的成功数量(Xj用于分裂的节点数量)是否超过了理论成功数量,如果它们是随机的(即遵循上面给出的二项分布)。
计算特征重要性的四种度量(a)-(d)是由randomForest包计算的,因此只需从森林对象中提取,前提是在生成森林时使用了localImp = TRUE选项。请注意,度量(a)和(c)基于变量扰动后森林预测精度的降低,(b)和(d)基于变量分裂后节点纯度的变化,而(e)-(i)则基于森林结构。
函数measure_importance允许您指定计算平均最小深度的方法(mean_sample参数,默认为“top_trees”)和要计算的度量作为一个字符向量,其中包含上述度量的名称子集(measures参数,默认为NULL,导致计算所有度量)。
6.多元重要性绘制
下面我们展示了plot_multi_way_importance的默认值x_measure和y_measure的结果,它们指定了要在x和y轴上使用的特征重要性度量,点的大小反映了该特征进行分割的节点数量。对于具有许多变量的问题,我们可以将绘图限制为仅涉及至少在min_no_of_trees个树中用于分割的变量。默认情况下,绘图中突出显示了前10个最重要的变量,并进行了标记(no_of_labels)。 这些变量是使用重要性度量的排名之和来选择的(如果存在平局,则可能标记更多的变量)。
特征进行分割的节点数量越多意味着该特征在构建决策树时使用的频率更高,即在更多的情况下,该特征被视为重要的分割标准。因此,可以认为该特征对于预测目标变量的影响更加显著和重要。但需要注意的是,节点数并不是衡量特征重要性的唯一标准,还需要考虑其他因素,如该特征的变量重要性得分和其对模型预测性能的影响等。
## Multi-way importance plot
plot_multi_way_importance(forest, size_measure = "no_of_nodes") # gives the same result as below but takes longer
plot_multi_way_importance(importance_frame, size_measure = "no_of_nodes")
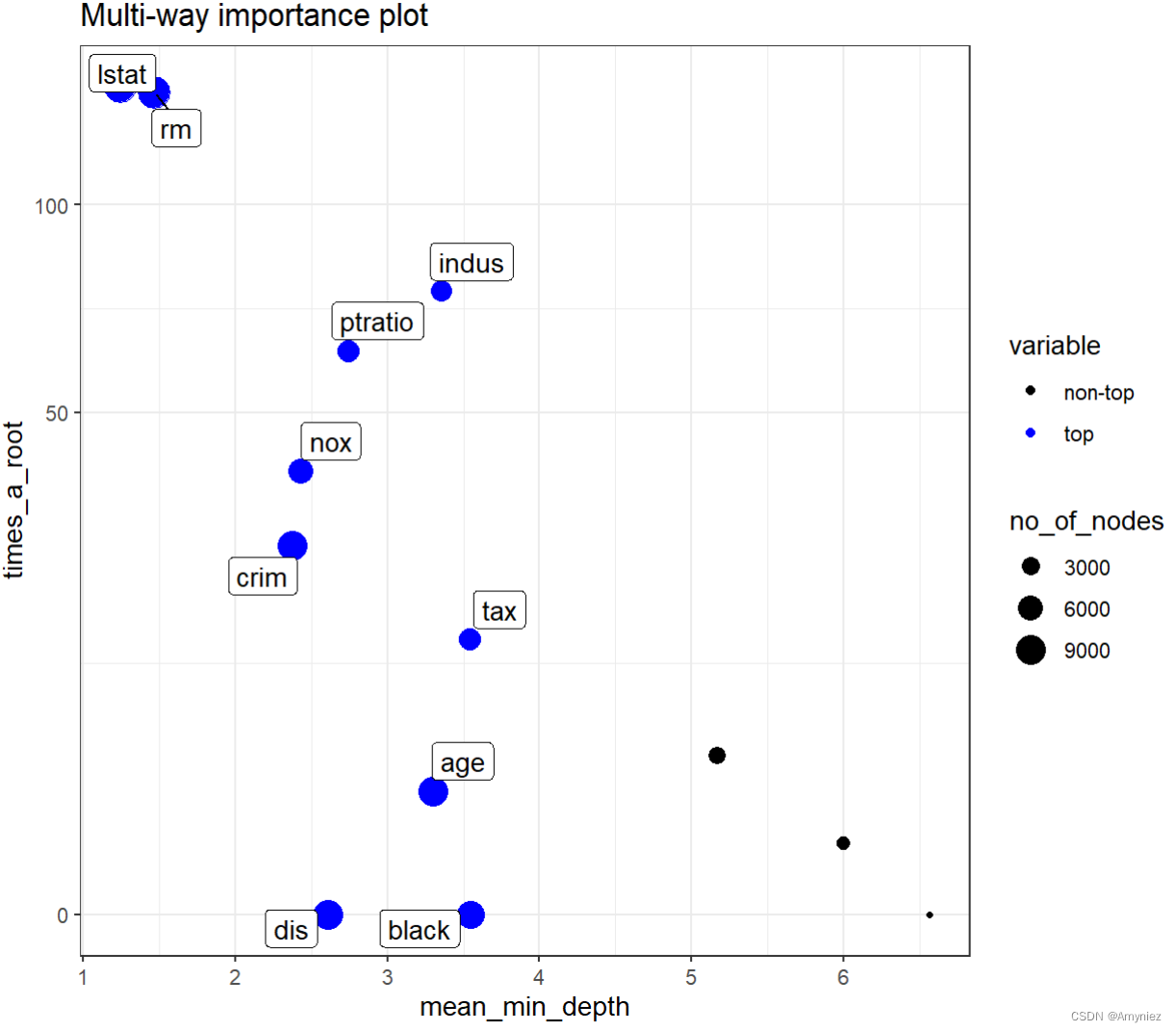
观察到 times_a_root 和 mean_min_depth 之间的显著负相关关系。此外,在所有三个维度上,lstat 和 rm 的优越性是显而易见的(尽管不清楚哪个更好)。我们还展示了另一组重要性指标的多维重要性图:随机排列后均方误差的增加量(x轴),节点纯度指数的增加量(y轴)和显著性水平(点的颜色)。我们还将 no_of_labels 设置为五,这样只会突出显示五个最重要的变量(由于存在并列,最终会标记六个)。
plot_multi_way_importance(importance_frame, x_measure = "mse_increase",
y_measure = "node_purity_increase",
size_measure = "p_value", no_of_labels = 5)
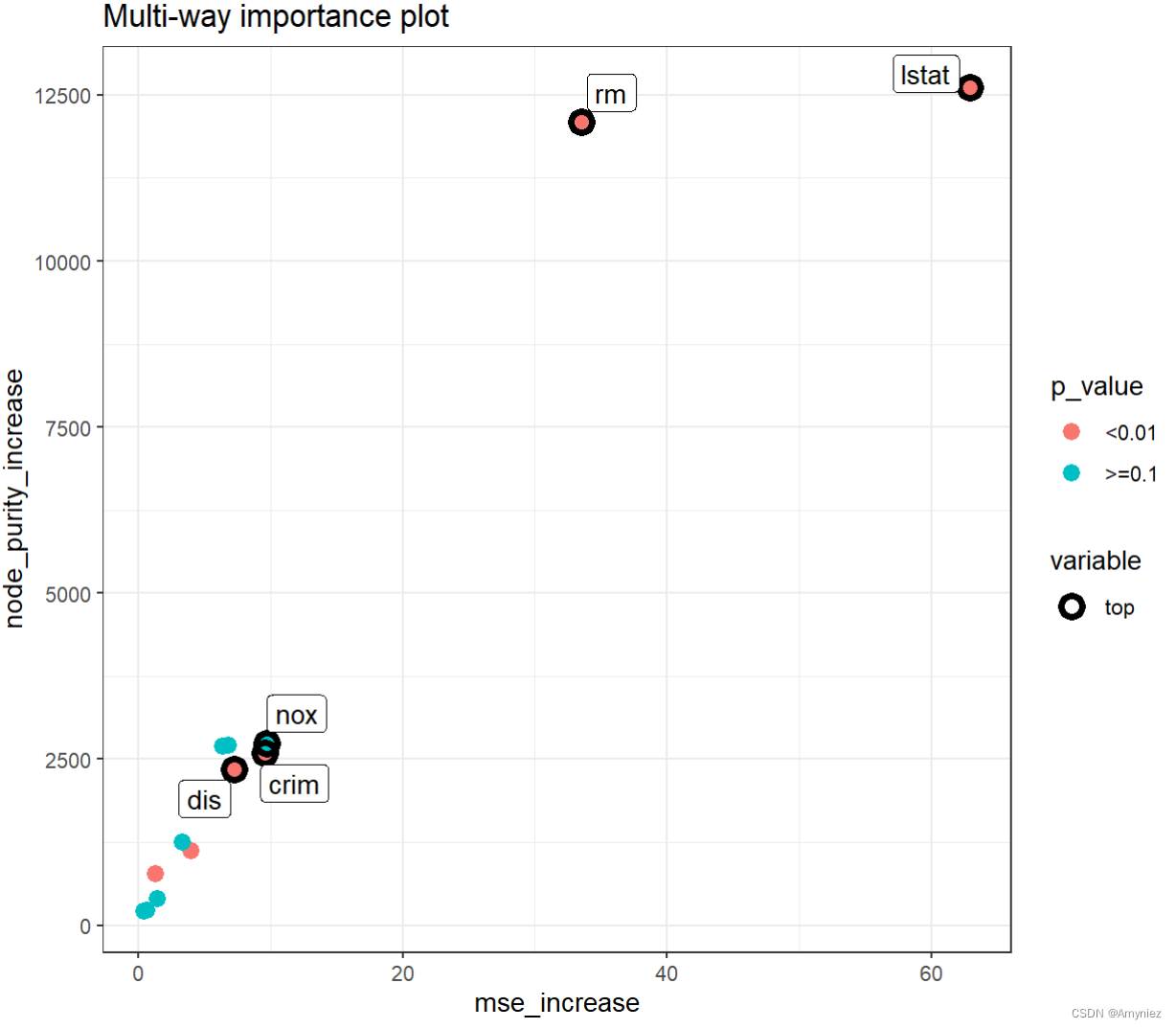
和之前的图表一样,两个坐标用作的度量似乎是相关的,但在这种情况下,这更令人惊讶,因为一个度量与森林的结构有关,另一个度量与其预测有关,而在之前的图表中,两个度量都反映了结构。此外,在这个图表中,我们可以看到尽管在节点纯度增加和p值方面lstat和rm相似,但前者在看增加MSE方面明显更好。有趣的是,无论nox和indus在两个坐标上的度量上表现得相当好,但根据我们的p值来看,它们并不重要,这是使用变量进行分裂的节点数量的导数。
7. 使用ggpair比较度量
通常来说,多元重要性图提供了广泛的可能性,因此很难选择最具信息量的图。克服这个障碍的一个想法是首先探索不同重要性指标之间的关系,然后选择三个最不相互一致的指标,并将它们用于多元重要性图以选择前几个变量。第一个想法可以通过使用plot_importance_ggpairs将所选重要性指标成对绘制在一起来轻松完成。当然,也可以将所有七个指标包括在绘图中,但默认情况下会排除p值和树的数量,因为两者都与节点数量具有类似的信息。
## Compare measures using ggpairs
# plot_importance_ggpairs(forest) # gives the same result as below but takes longer
plot_importance_ggpairs(importance_frame)
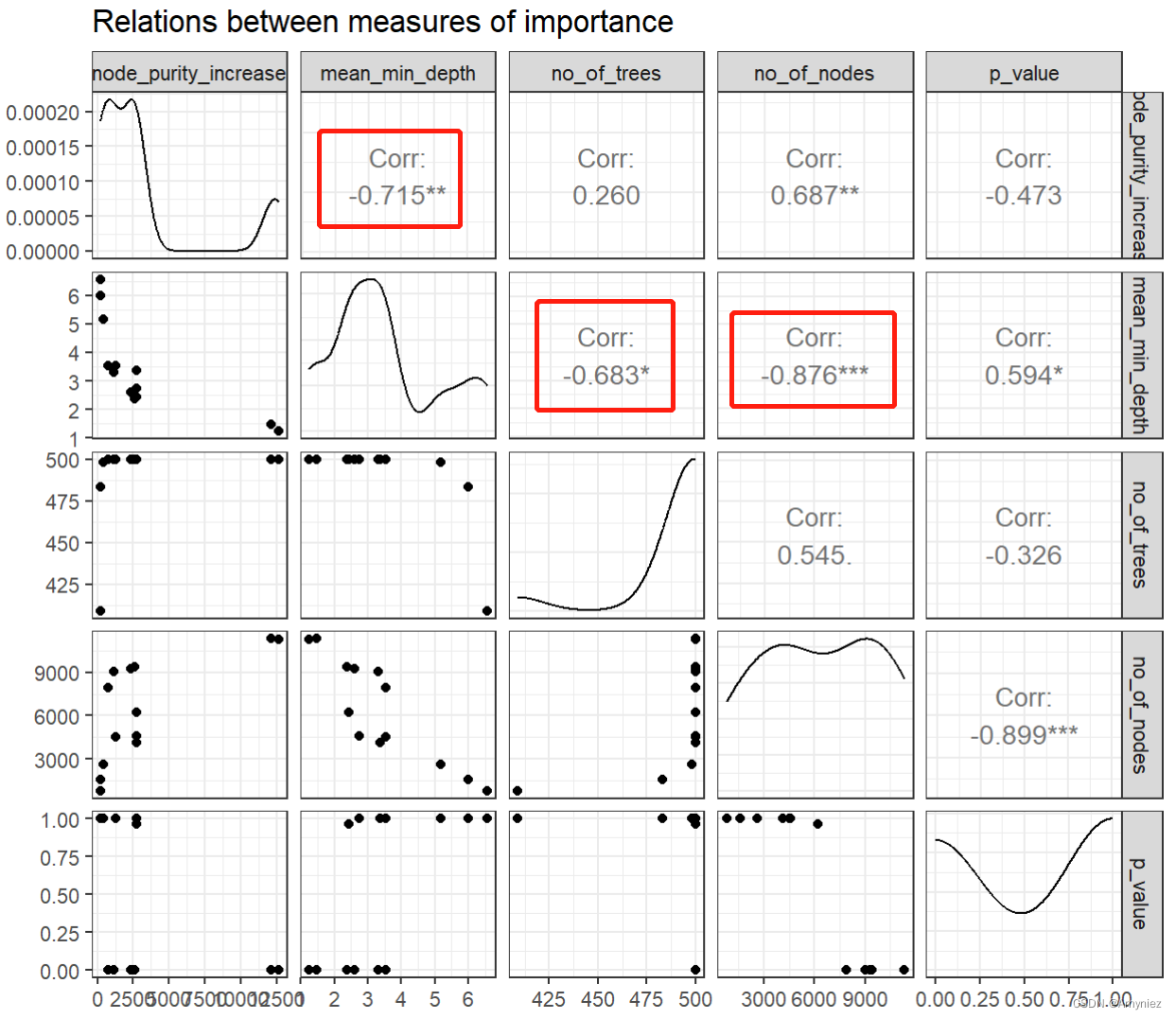
我们可以看到,所有呈现出来的度量都高度相关(当然,任何度量与平均最小深度的相关性都是负的,因为对于最佳变量,后者是最小的),但是有些相关性比其他的小。此外,无论我们比较哪些度量,总是会有两个点突出,这最可能对应于lstat和rm(为了确定,我们可以仅检查importance_frame)。
plot_importance_ggpairs(importance_frame)绘制出的图是用于可视化特征重要性的一种方法。 它显示了随机森林模型中不同特征之间的两两关系,并标出了每个特征的重要性。在图中,每个单元格代表两个特征之间的散点图,其中x轴表示一个特征的重要性,y轴表示另一个特征的重要性。每个特征的重要性在对角线上以直方图的形式显示。
通过观察这个图,我们可以获得以下信息:
特征之间的相互作用:我们可以看到每个特征与其他特征之间的关系。如果两个特征的重要性高度相关,那么它们可能是高度相关的,或者可能存在某种相互作用。
特征的重要性:我们可以看到每个特征的重要性,因为它们在对角线上的直方图表示。如果一个特征的重要性很高,那么它可能是一个关键特征,可以用于建立一个精确的模型。
此外,我们可以注意到一些在图中明显突出的点,这些可能是具有最高重要性的特征,如上述例子中的lstat和rm。
注意:每个格网中都有13个点,每个点代表一个样本特征,通过比较这些散点的分布,可以看出哪些点是更加重要的,这就是从树的结构来考虑特征重要性的方法。
8. 比较不同的排名
除了散点图和相关系数之外,ggpairs图还绘制了每个重要性指标的密度估计。在这种情况下,它们都是非常偏斜的。通过绘制排名而不是原始指标的尝试是在plot_importance_rankings函数中实现的,它还在每个图中包括拟合的LOESS曲线。
## Compare measures using ggpairs
# plot_importance_ggpairs(forest) # gives the same result as below but takes longer
plot_importance_ggpairs(importance_frame)
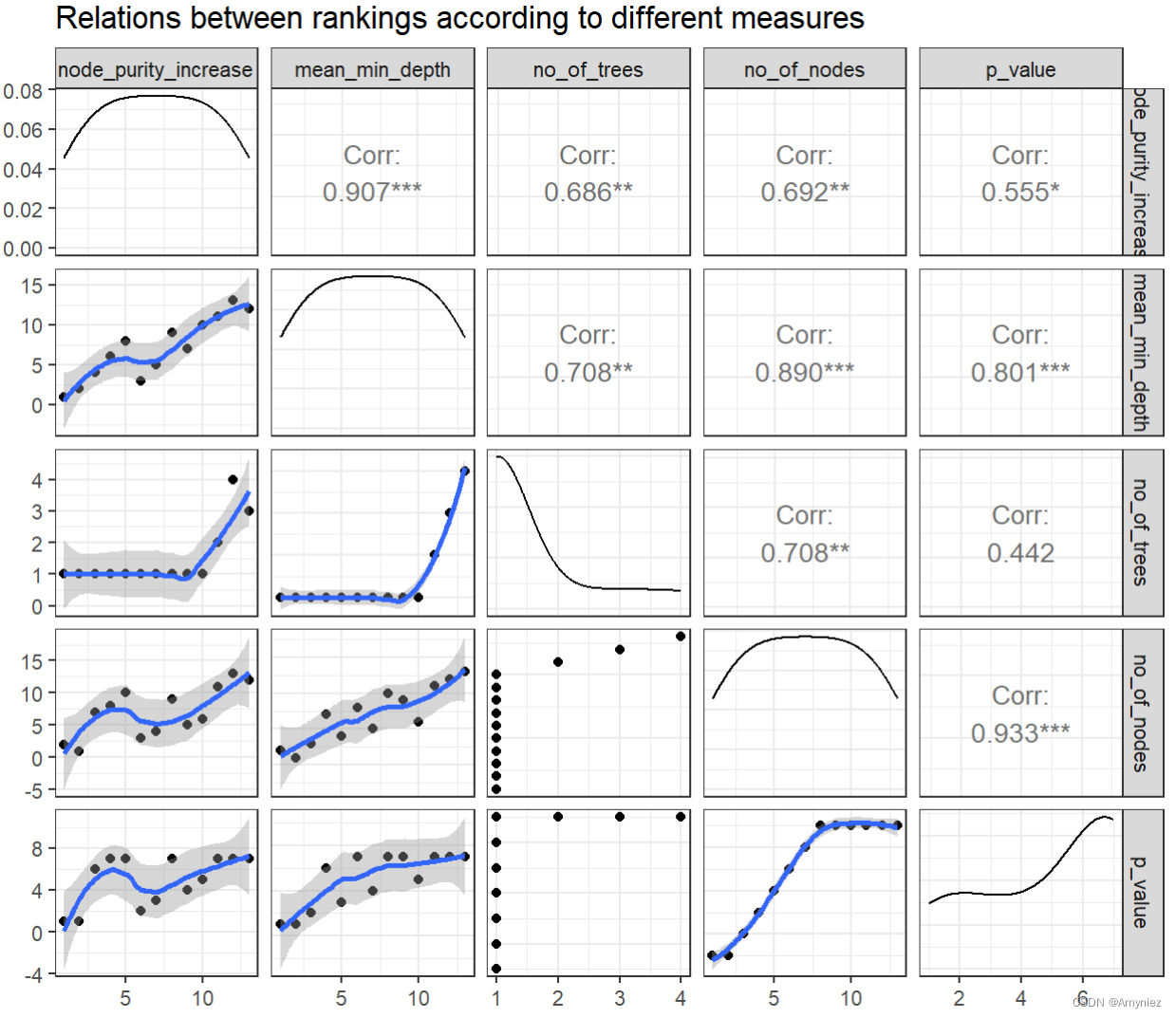
上述密度估计显示,我们的所有重要性指标的偏斜都被消除了(这并不总是这样,例如当排名中存在频繁的并列时,对于诸如times_a_root之类的离散重要性指标,排名的分布也可能是偏斜的)。
当比较上述情节中的排名时,我们可以看到两对指标的排名几乎完全一致:mean_min_depth vs. mse_increase 和 mse_increase vs. node_purity_increase。在存在许多变量的应用中,LOESS曲线可能是此情节的主要观点(如果点填充整个绘图区域,并且如果指标的分布接近均匀,这是可能的)。
9. 变量交互
在选择了一组最重要的变量之后,我们可以研究与它们有关的相互作用,即在最大子树中出现的关于所选变量之一的分裂。为了根据平均最小深度和变量出现的树的数量提取5个最重要的变量的名称,我们将importance_frame传递给important_variables函数,如下所示:
选取:"mean_min_depth"和"no_of_trees"作为重要性的评判依据:
##Variable interactions
# (vars <- important_variables(forest, k = 5, measures = c("mean_min_depth", "no_of_trees"))) # gives the same result as below but takes longer
(vars <- important_variables(importance_frame, k = 5, measures = c("mean_min_depth", "no_of_trees")))
[1] "lstat" "rm" "crim" "nox" "dis"
interactions_frame <- min_depth_interactions(forest, vars)# vars = c("lstat", "rm", "crim", "nox", "dis")
save(interactions_frame, file = "interactions_frame.rda")
load("interactions_frame.rda")
head(interactions_frame[order(interactions_frame$occurrences, decreasing = TRUE), ])
将结果与forest(构建的RF模型)一起传递给 min_depth_interactions 函数:来计算给定随机森林 forest 中,由变量集合 vars 中的变量构成的交互作用的 条件平均最小深度和无条件平均最小深度,并将结果存储在 interactions_frame 数据框中。
具体来说,min_depth_interactions 函数会返回一个数据框,其中包含所有由 vars 中变量构成的交互作用及其对应的条件平均最小深度和无条件平均最小深度。
- 交互作用的条件平均最小深度是指:给定一个交互作用时,样本在随机森林中通过该交互作用进行分类时的平均最小深度;
- 无条件平均最小深度是指:所有样本点(即样本)在随机森林中的最小深度的平均值。在计算无条件平均最小深度时,不考虑任何变量的条件影响。因此,它代表了整个随机森林对样本点的整体拟合能力;
得到这个交互作用与平均最小深度的数据框后,我们可以使用 plot_min_depth_interactions 函数将交互作用及其对应的平均最小深度可视化,以帮助我们理解变量之间的复杂关系和重要性。
如果不指定vars参数,则条件变量的向量将默认使用important_variables(measure_importance(forest))获得。
结果:
variable root_variable mean_min_depth occurrences interaction
53 rm lstat 1.215606 487 lstat:rm
3 age lstat 2.246489 482 lstat:age
33 lstat lstat 1.289610 482 lstat:lstat
8 black lstat 2.543031 480 lstat:black
23 dis lstat 1.551244 480 lstat:dis
18 crim lstat 2.098809 472 lstat:crim
uncond_mean_min_depth
53 1.320
3 3.432
33 1.080
8 3.602
23 2.536
18 2.320
在随机森林中,occurrences 通常指特征或变量在树中被使用的次数。这个概念通常用于计算特征的重要性,因为被使用越多的特征通常对模型的贡献越大。在一些实现中,occurrences还可以指交互项的出现次数,即两个或多个特征在一起被使用的次数。
9.1 交互图像绘制
# plot_min_depth_interactions(forest) # calculates the interactions_frame for default settings so may give different results than the function below depending on our settings and takes more time
plot_min_depth_interactions(interactions_frame)
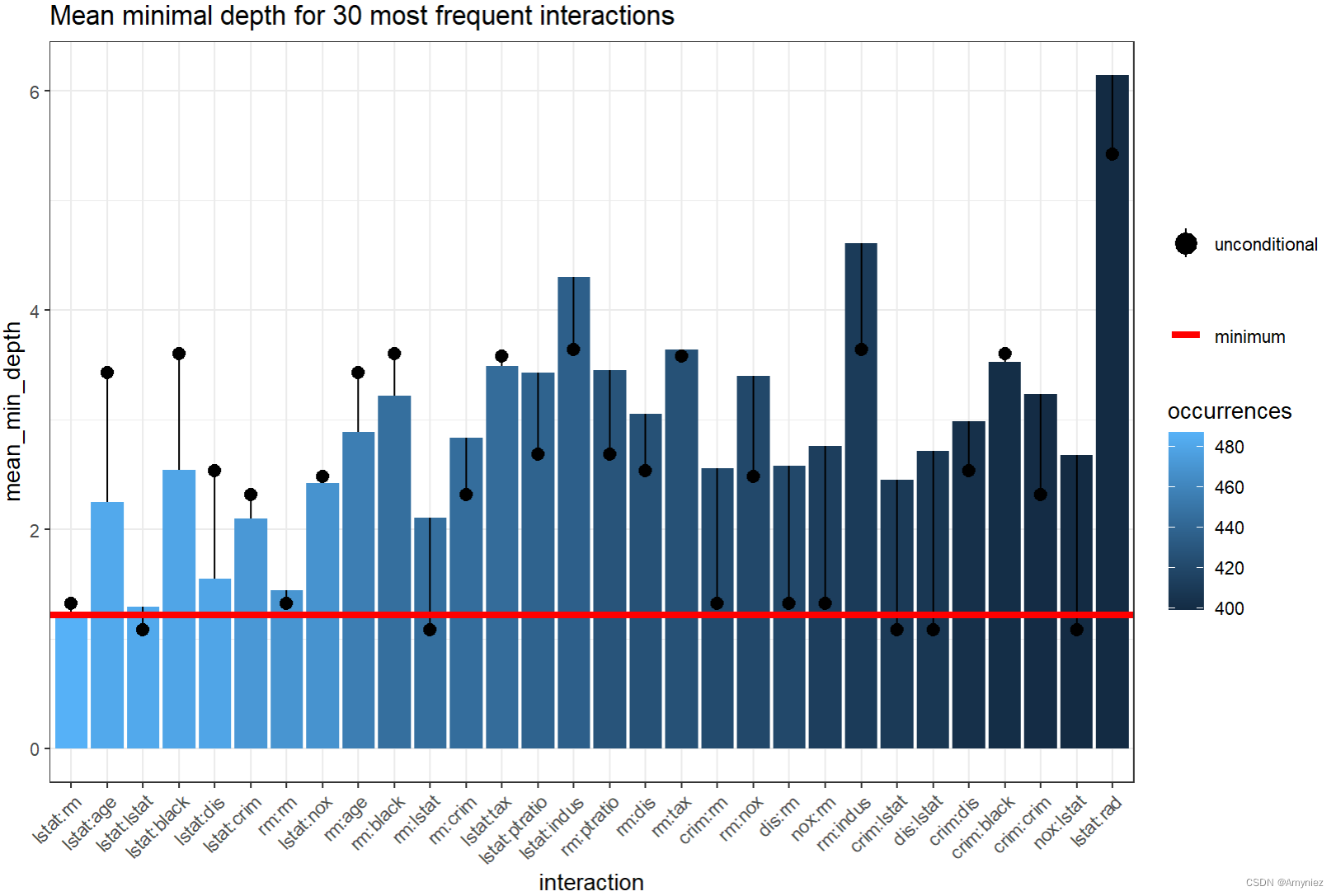
注意:交互是按出现次数的递减顺序排列的,最频繁的一个lstat:rm也是具有最小平均条件最小深度的一个。值得注意的是,森林中rm的无条件平均最小深度几乎等于它在以lstat为根变量的最大子树上的平均最小深度。
一般来说,图表包含很多信息,可以用多种方式解释,但始终牢记用于计算 条件(mean_sample参数)和无条件(uncond_mean_sample参数) 平均最小深度的方法。使用默认的“top_trees”将惩罚发生频率低于最频繁的交互。当然,我们可以在 “all_trees”,“top_trees”和“relevant_trees” 之间切换来计算条件和无条件最小深度的平均值,但它们都有其缺点,我们倾向于使用 “top_trees”(默认值)。然而,当plot_min_depth_interactions通过降低频率绘制交互作用时,仅为相关变量计算平均值的主要缺点就消失了,因为交互作用(例如,只出现一次,但条件深度为0)无论如何都不会包括在图中。因此,我们使用“relevant_trees”重复计算平均值,得到以下结果:
interactions_frame <- min_depth_interactions(forest, vars, mean_sample = "relevant_trees", uncond_mean_sample = "relevant_trees")
save(interactions_frame, file = "interactions_frame_relevant.rda")
load("interactions_frame_relevant.rda")
plot_min_depth_interactions(interactions_frame)
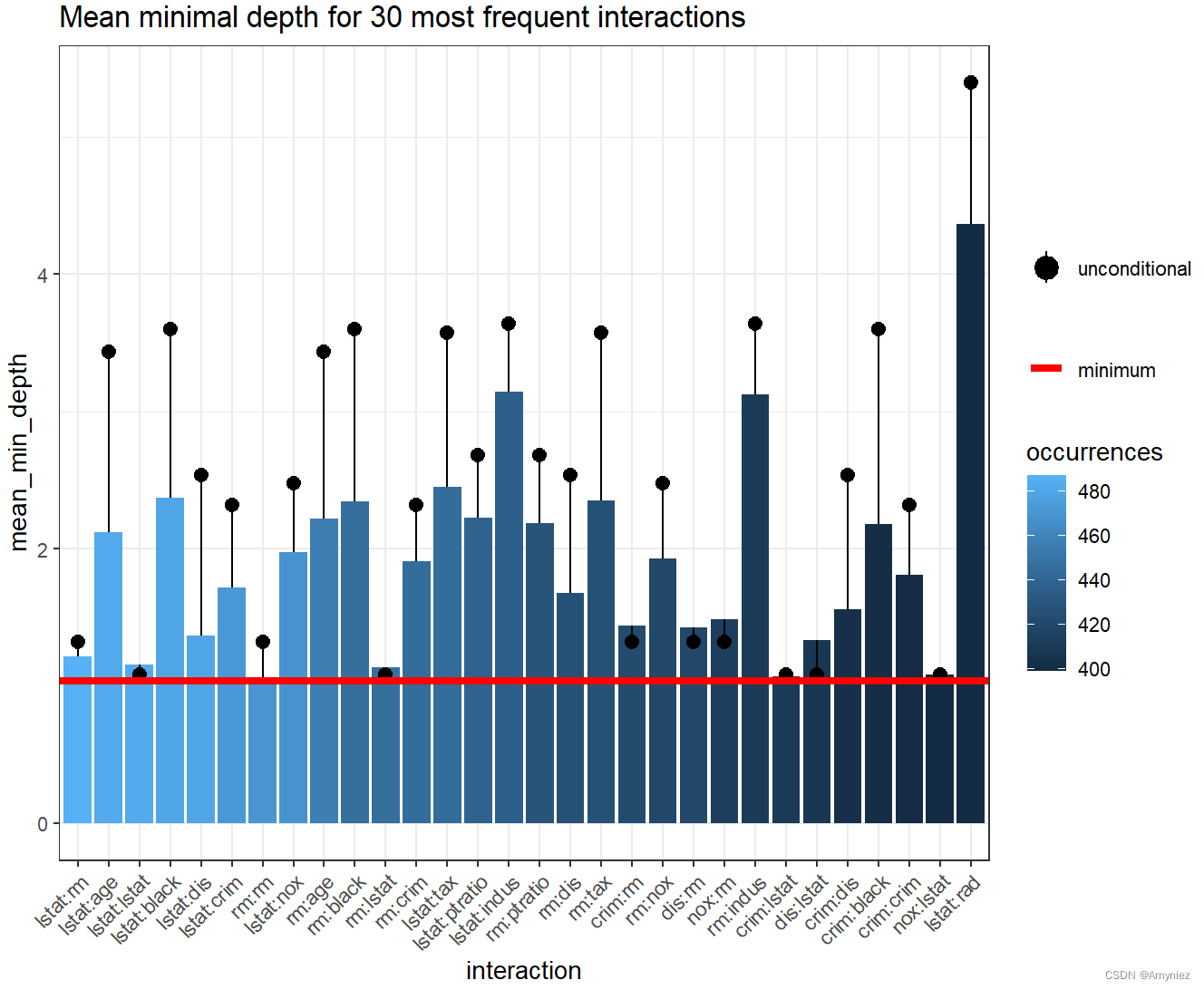
将此图与前一个图进行比较,可以看到删除缺失值的惩罚降低了所有交互的平均条件最小深度,除了最频繁的交互。现在,除了常见的,一些不太常见的,如rm:tax脱颖而出。
10. 网格上预测森林
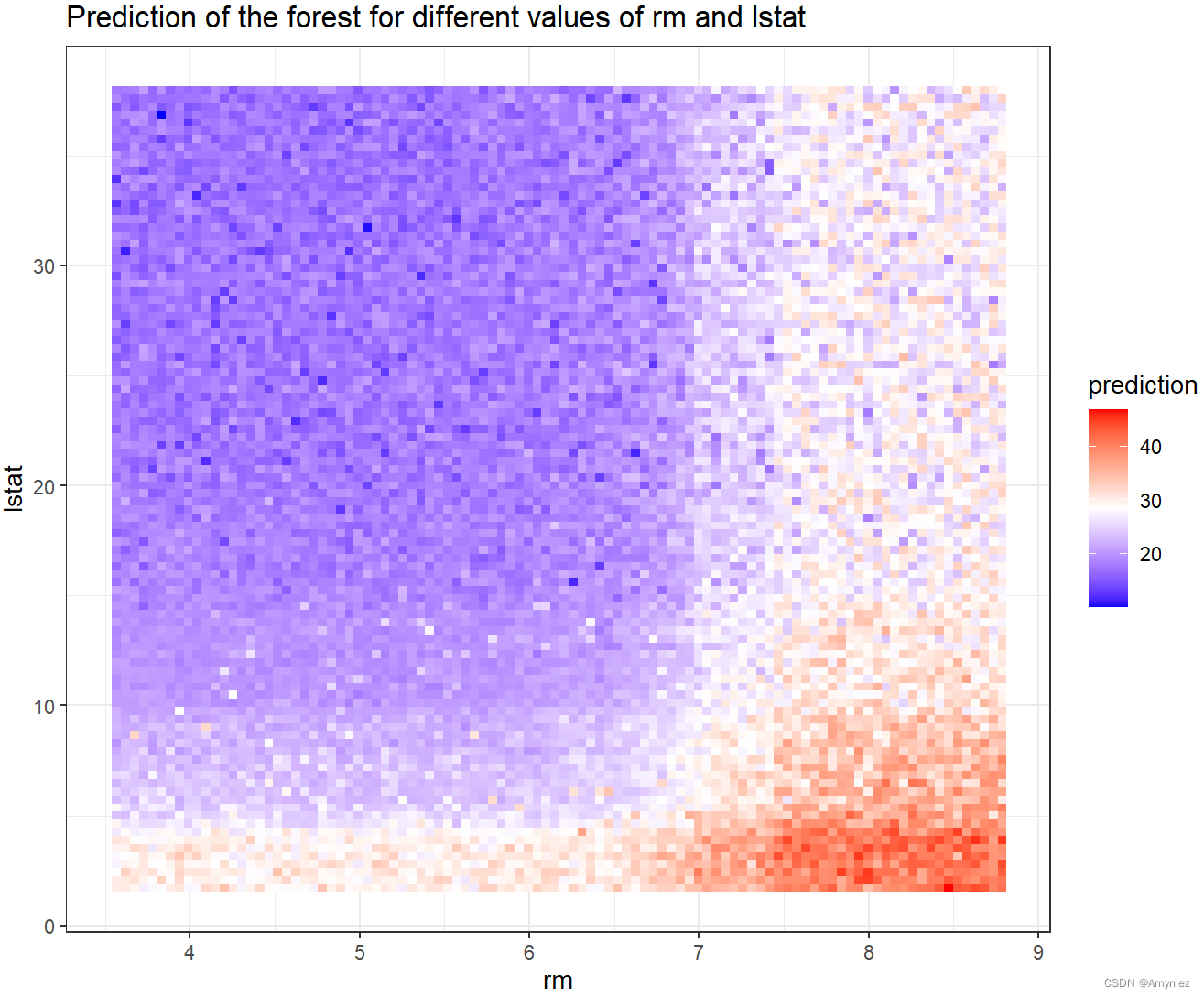
为了进一步研究最频繁的交互 lstat:rm ,我们使用函数plot_predict_interaction在每个交互组件的值网格上绘制森林的预测。该函数需要森林、训练数据、变量分别在x轴和y轴上使用。此外,在内存不足的情况下,还可以使用参数grid减少网格两个维度上的点数(默认值为100)。
plot_predict_interaction(forest, Boston, "rm", "lstat")
预测结果:
11. 解释森林
explain_forest()函数是randomForestExplainer包的旗舰函数,因为它接受随机森林并生成html报告,其中汇总了使用新包获得的森林的所有基本结果。下面,我们将展示如何在默认设置下运行这个函数(我们只提供森林、训练数据、set interactions = TRUE,与默认值相反,以显示完整的功能,并在计算量最大的示例中减少预测图的网格)。
explain_forest(forest, interactions = TRUE, data = Boston)
12. 全部代码
##---------------------------------------------
## @author:Jackson Zhao
# time: 2023/3/12 星期天
##---------------------------------------------
# Understanding random forests with randomForestExplainer
library(randomForest)
# the easiest way to get randomForestExplainer is to install it from CRAN:
install.packages("randomForestExplainer")
# Or the the development version from GitHub:
# install.packages("devtools")
devtools::install_github("ModelOriented/randomForestExplainer")
data(Boston, package = "MASS")
# 将chas的数据转换为logistic运算符,即T、F
Boston$chas <- as.logical(Boston$chas)
str(Boston)
head(Boston)
set.seed(2023)
forest <- randomForest(medv ~ ., data = Boston, localImp = TRUE,
mtry = ceiling(ncol(Boston)/3),
proximity = TRUE, importance = TRUE)
print(forest)
importance(forest,type=2) # IncNodePurity
hist(treesize(forest))
MDSplot(forest, Boston$chas,palette = rep(1,2), pch = as.numeric(Boston$medv))
## Distribution of minimal depth
# 依次使用 randomForestExplainer 的所有函数,并对获得的结果进行评论
#min_depth_frame <- min_depth_distribution(forest)
#save(min_depth_frame, file = "min_depth_frame.rda")
load("min_depth_frame.rda")
head(min_depth_frame, n = 10)
# plot_min_depth_distribution(forest) # gives the same result as below but takes longer
plot_min_depth_distribution(min_depth_frame)
plot_min_depth_distribution(min_depth_frame, mean_sample = "relevant_trees",
k = 15, mean_scale=TRUE, main= "Distribution of minimal depth") # k为最大变量数
# Various variable importance measures
#importance_frame <- measure_importance(forest) # mean_sample参数,默认为“top_trees”; measures参数,默认为NULL,导致计算所有度量
#save(importance_frame, file = "importance_frame.rda")
load("importance_frame.rda")
importance_frame
## Multi-way importance plot
plot_multi_way_importance(forest, size_measure = "no_of_nodes") # gives the same result as below but takes longer
plot_multi_way_importance(importance_frame, size_measure = "no_of_nodes")
plot_multi_way_importance(importance_frame, x_measure = "mse_increase",
y_measure = "node_purity_increase",
size_measure = "p_value", no_of_labels = 5)
## Compare measures using ggpairs
# plot_importance_ggpairs(forest) # gives the same result as below but takes longer
plot_importance_ggpairs(importance_frame)
##Compare different rankings
# plot_importance_rankings(forest) # gives the same result as below but takes longer
plot_importance_rankings(importance_frame)
##Variable interactions
# (vars <- important_variables(forest, k = 5, measures = c("mean_min_depth", "no_of_trees"))) # gives the same result as below but takes longer
(vars <- important_variables(importance_frame, k = 5, measures = c("mean_min_depth", "no_of_trees")))
interactions_frame <- min_depth_interactions(forest, vars)
save(interactions_frame, file = "interactions_frame.rda")
load("interactions_frame.rda")
head(interactions_frame[order(interactions_frame$occurrences, decreasing = TRUE), ])
# plot_min_depth_interactions(forest) # calculates the interactions_frame for default settings so may give different results than the function below depending on our settings and takes more time
plot_min_depth_interactions(interactions_frame)
interactions_frame <- min_depth_interactions(forest, vars, mean_sample = "relevant_trees", uncond_mean_sample = "relevant_trees")
save(interactions_frame, file = "interactions_frame_relevant.rda")
load("interactions_frame_relevant.rda")
plot_min_depth_interactions(interactions_frame)
plot_predict_interaction(forest, Boston, "rm", "lstat")
explain_forest(forest, interactions = TRUE, data = Boston)
13. 总结
该包的主要作用:
- 变量重要性分析:计算和可视化每个特征在模型中的重要性得分,以帮助用户识别最相关的特征;
- 单个预测的解释:解释单个预测结果,包括计算和可视化每个特征的贡献值和方向,以帮助用户理解预测结果;
- 整体模型的解释:通过计算每个决策树的结构和规则,来解释整个随机森林模型的预测过程和结果;
- 可视化工具:提供多种可视化工具,如决策树可视化、部分依赖图和条件依赖图等,以帮助用户更好地理解模型。
我想通过这个包实现交互作用,目前来看只能实现两个变量的交互,效果也还可以,主要是它不单单是从节点纯度来考虑特征的重要性,还从决策树的结构来考虑,对重要性的评估手段更加丰富、可靠,所以给特征重要性的探测提供了一种更有效的方法。但是还是不能满足我的要求,可能还需要看看其他R包是否能实现我的要求吧!
还有一点让我印象深刻的就是他能在网格上预测森林,这对于地学上的探究提供了一种有效的方法,比如是否可以和物种分布模型相结合,通过最重要的因素进行交互,来预测外来物种的分布模式。