目录
一、查看数据
DA1 用pandas查看牛客网用户数据

import pandas as pd
Nowcoder = pd.read_csv('Nowcoder.csv',sep=',',dtype=object)
print(Nowcoder.head(6))打开文件时需要添加dtype=object,防止年份信息读取为小数。
DA2 牛客网用户数据集的大小

import pandas as pd
Nowcoder = pd.read_csv('Nowcoder.csv',sep=',',dtype=object)
print(Nowcoder.shape)
DA3 牛客网的第10位用户

import pandas as pd
Nowcoder = pd.read_csv('Nowcoder.csv',sep=',',dtype=object)
print(Nowcoder.loc[10])
- loc : Selection by Label ,按标签取数据, loc[行索引,列名/column] (如果第二个参数的个数是全部即 : ,可以省略不写)。
例:
print(df.loc[1,'name']) # 索引1(行),名为‘name’的列- iloc : Selection by Position,即按位置选择只接受整型参数。不接受列字段名称作为参数,只支持列字段的位置索引作为参数。iloc[行索引,列索引](没有逗号及以后就是默认列为所有列)
例:
print(df.iloc[1,0]) # 第2行第1列的值DA4 统计牛客网部分用户使用语言
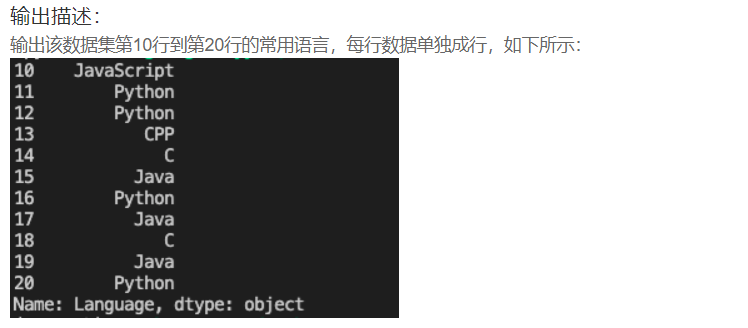
import pandas as pd
Nowcoder =pd.read_csv('Nowcoder.csv')
print(Nowcoder.loc[10:20, 'Language'])二、数据索引
DA5 牛客网用户没有补全的信息

import pandas as pd
Nowcoder = pd.read_csv("Nowcoder.csv", sep=",", dtype=object)
print(Nowcoder.isna().any())
# Python中 any () 函数的基本使用 :any () 函数用于判断给定的可迭代参数 iterable 是否都为 False,如果是,any ()操作后的结果返回 False,如果给定的可迭代参数 iterable其中有一个为 True,any ()操作后的结果则返回 True。
# axis=0:方向沿着列;axis=1方向沿着行DA6 查看牛客网哪些用户使用Python

import pandas as pd
Nowcoder = pd.read_csv("Nowcoder.csv", sep=",", dtype=object)
print(Nowcoder[Nowcoder["Language"] == "Python"])DA7 牛客网Python用户的成就值

import pandas as pd
Nowcoder = pd.read_csv("Nowcoder.csv", sep=",")
print(Nowcoder[Nowcoder["Language"] == "Python"]["Achievement_value"])
# print(Nowcoder.query('Language=="Python"')['Achievement_value'])
# print(Nowcoder.query('Language=="Python"').Achievement_value)DA8 文件最后用户的部分数据

import pandas as pd
Nowcoder = pd.read_csv("Nowcoder.csv", sep=",")
a = Nowcoder.tail(5)
print(a[["Nowcoder_ID", "Level", "Achievement_value", "Language"]])三、逻辑运算
DA9 2020年毕业的人中最喜欢用Java的用户

import pandas as pd
Nowcoder = pd.read_csv('Nowcoder.csv',sep=',')
pd.set_option('display.width', 300) # 设置字符显示宽度
pd.set_option('display.max_rows', None) # 设置显示最大行
pd.set_option('display.max_columns', None)# 设置显示最大列
print(Nowcoder[(Nowcoder['Graduate_year']==2020)&(Nowcoder['Language']=='Java')])
DA9 牛客网C系用户们的信息
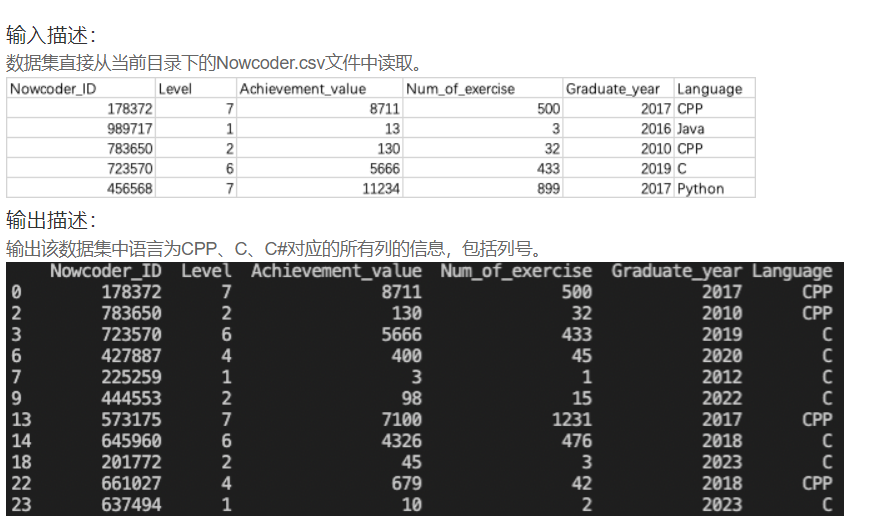
import pandas as pd
Nowcoder = pd.read_csv("Nowcoder.csv", sep=",")
pd.set_option("display.width", 300) # 设置字符显示宽度
pd.set_option("display.max_rows", None) # 设置显示最大行
pd.set_option("display.max_columns", None)
print(Nowcoder[Nowcoder["Language"].isin(["CPP", "C", "C#"])])
# isin()函数:用来清洗数据,删选过滤掉Dateframe中的一些行,直接用返回的是bool值,然后放入Nowcoder[ {内容} ]中,则返回返回为True的数据行
# print(Nowcoder.query("Language == 'CPP' or Language == 'C'"))
# query()函数查找Languague列中的CPP、CDA10 统计牛客网刷题数量500以上的大佬

import pandas as pd
Nowcoder = pd.read_csv('Nowcoder.csv',sep=',')
Nowcoder = Nowcoder[['Level','Achievement_value']]
print(Nowcoder[Nowcoder['Achievement_value']>=500])DA11 按照毕业年份与使用语言筛选牛客网7级用户
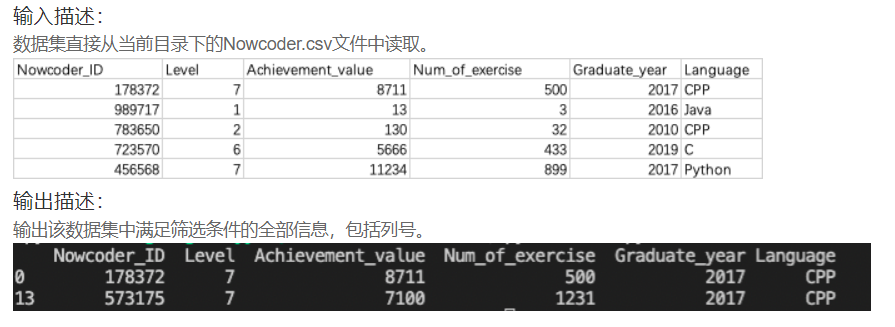
import pandas as pd
Nowcoder = pd.read_csv('Nowcoder.csv', sep=',')
pd.set_option('display.width',300)
pd.set_option('display.max_rows',None)
pd.set_option('display.max_columns',None)
print(Nowcoder.query("Level==7 and Language=='CPP' and Graduate_year!=2018"))
四、中级函数
DA12 牛客网不同语言使用人数

import pandas as pd
Nowcoder = pd.read_csv('Nowcoder.csv', sep=',')
print(Nowcoder['Language'].value_counts())DA13 牛客网用户最近的最长与最短连续签到天数

import pandas as pd
Nowcoder = pd.read_csv('Nowcoder.csv', sep=',')
# 最长
day_max = Nowcoder['Continuous_check_in_days'].max()
# 最短
day_min = Nowcoder['Continuous_check_in_days'].min()
print(day_max, '\n', day_min)DA14 Python用户的平均提交次数

import pandas as pd
Nowcoder = pd.read_csv('Nowcoder.csv', sep=',')
print((Nowcoder.query("Language == 'Python'")['Number_of_submissions'].mean().round(1)))
DA15 牛客网用户等级的中位数

import pandas as pd
Nowcoder = pd.read_csv('Nowcoder.csv', sep=',')
print(int(Nowcoder[Nowcoder['Num_of_exercise']>=10]['Level'].median()))DA16 用户常用语言有多少
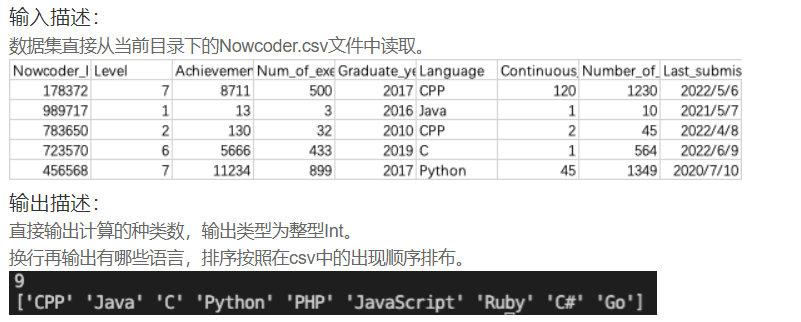
import pandas as pd
Nowcoder = pd.read_csv('Nowcoder.csv', sep=',')
# unique()方法返回的是去重之后的不同值,而nunique()方法则直接放回不同值的个数
print(Nowcoder.Language.nunique())
print(Nowcoder.Language.tolist())DA17 牛客网最多的用户等级
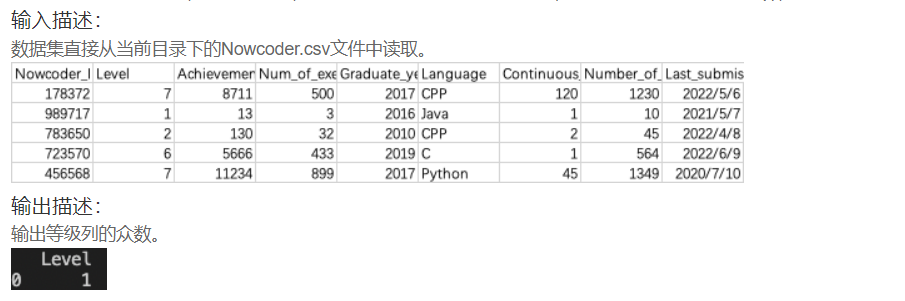
import pandas as pd
Nowcoder = pd.read_csv('Nowcoder.csv', sep=',')
print(pd.DataFrame(Nowcoder['Level'].mode(), columns=['Level']))
DA18 用分位数分析牛客网用户活动
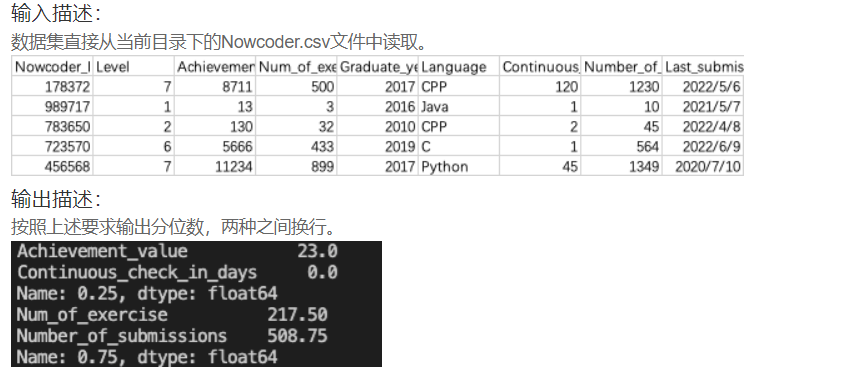
import pandas as pd
Nowcoder = pd.read_csv('Nowcoder.csv', sep=',')
print(Nowcoder[['Achievement_value', 'Continuous_check_in_days']].quantile(q=0.25))
print(Nowcoder[['Num_of_exercise', 'Number_of_submissions']].quantile(q=0.75))
DA19 牛客网大佬之间的差距

import pandas as pd
Nowcoder = pd.read_csv('Nowcoder.csv', sep=',')
a=Nowcoder[Nowcoder['Level']==7]['Achievement_value'].max()
b=Nowcoder[Nowcoder['Level']==7]['Achievement_value'].min()
print(int(a-b))DA20 牛客用户刷题量的方差与提交次数的标准差

import pandas as pd
Nowcoder = pd.read_csv('Nowcoder.csv', sep=',')
# 用户刷题量的方差
A = Nowcoder['Num_of_exercise'].var()
print('%.2f'%A)
# 提交代码次数的标准差
B = Nowcoder.iloc[:,7].std()
print('%.2f'%B)
'''
# pandas 中的 var 函数可以得到样本方差(注意不是总体方差)
# std 函数可以得到样本标准差,若要得到某一行或某一列的方差,则也可用 iloc 选取某行或某列,后面再跟 var 函数或 std 函数即可
df.var() # 显示每一列的方差
df.var(axis = 1) # 显示每一行的方差
df.std() # 显示每一列的标准差
df.std(axis = 1) # 显示每一行的标准差
df.iloc[0, :].std() # 显示第 1 行的标准差
df.iloc[:, 2].std() # 显示第 3 列的标准差
'''DA21 大佬用户成就值比例

import pandas as pd
Nowcoder = pd.read_csv('Nowcoder.csv', sep=',')
nc=Nowcoder.loc[Nowcoder['Level']==7]
print(nc['Achievement_value']/Nowcoder['Achievement_value'].sum())DA22 牛客网用户最高的正确率
import pandas as pd
Nowcoder = pd.read_csv("Nowcoder.csv")
n1 = Nowcoder[Nowcoder["Num_of_exercise"] > 10]
n2 = n1.Num_of_exercise / n1.Number_of_submissions
print(n2.max().round(3))
DA23 统计牛客网用户的名字长度
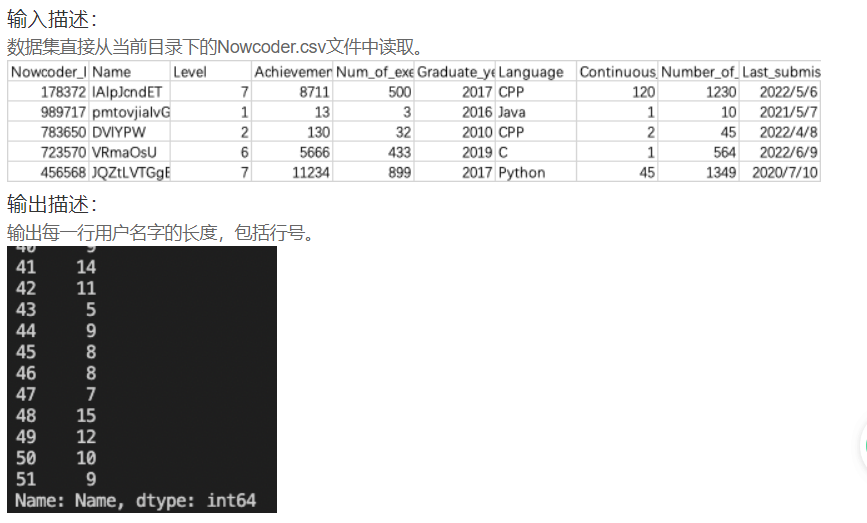
import pandas as pd
Nowcoder = pd.read_csv('Nowcoder.csv', sep=',')
print(Nowcoder['Name'].apply(lambda x : len(x)))
# print(df['Name'].str.len())