新开一个文献分享系列。今天分享一篇UBS的研报,获取原文后台回复“paper1”。
按照报告的顺序来写吧。
01
Summary
开篇三个要点

风险模型非常重要。通过控制风险,可以提高IR,这比寻找新因子容易得多。大部分的风险模型使用时序方法或截面方法,各有优劣。
报告给出一个混合方法进行风险建模,风格风险适合用截面模型建模,市场、地域、板块、宏观因素更适合用时序模型建模,给出了一个将二者组合到一起的方法。 听起来非常的完美。
EM算法+贝叶斯先验。用EM算法估计风险模型,通过贝叶斯先验降低误差,更快收敛。
接下来summary里讲了风险模型的用处以及好的风险模型的评价标准。

01
RISK model
summary之后,首先介绍了什么是风险模型,
所有的风险模型都建立在线性多因子模型的基础上。

好处是不用直接估计N只股票的协方差,可以把股票协方差阵分解为因子协方差、特质风险两部分,速度更快。
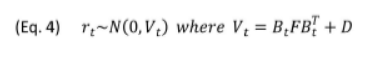
上图V是股票协方差阵,右边的B,F,D是风险模型需要估计的因子的因子暴露、协方差、特质风险。
接下来是报告重点。三种风险模型的估计方法。时序、截面、统计模型,差异在于对协方差阵结构的假设。
1. 时序模型

时序模型假设所有的因子暴露B是常数,因子收益F可以观测到,使用宏观变量或者factor-mimick portfolio作为因子收益的代理变量,这样因子协方差是已知的,进而模型简化为估计常数暴露B和残余风险D。
2.截面模型

截面模型假设因子暴露B可观测到,用基本面数据作为代理变量,这样B是时变的。模型简化为估计因子协方差阵F和残余风险D。
3. 统计风险模型

统计模型假设因子暴露和协方差都是常数,不时变,一般用PCA来估计协方差阵。
报告用的是时序和截面模型的组合。
后面还介绍了风险模型的四个用途
估计跟踪误差:短期的模型对于市场波动很敏感,统计模型对于估计跟踪误差更优。
风险归因:截面模型在风险归因上更稳健,样本期拉长也不会有太大变化。相反,时序模型比较灵敏,如果估计的beta有异常值,这种一般可以用贝叶斯方法对beta进行压缩。
收益归因:统计模型不适合,统计模型的因子难以找到直观解释,截面模型更好。
最优化:不好的风险模型优化出来,高权重可能集中在高风险股票上。因此需要判断风险模型是否很好的评估了风险,统计模型好于截面模型,因子数量更少。
最后还有一段描述也比较重要。

这块讲了风险模型和alpha模型的关系,在MPT理论里,最优组合的边际收益和边际风险相等如果收益模型和风险模型匹配的话,模型会更稳健。如果风险模型和收益模型只是近似一致,优化器只会选到高收益的股票,但对风险的把控上很少,导致组合失衡,把alpha因子加到风险因子里可以避免这一问题。有些绕。
03
Hybird Risk Model
混合模型结合了截面和时序模型,具体用哪个模型视风险来源而定。

前4个适合用时序模型,后一个适合截面模型,原因是前4个都是非常慢的变量,因子暴露基本上是不会变的,股票是哪个国家、哪个地域、哪个行业,上市以后基本上是固定的,可以视为常量。但风格风险不同,随时间变化相对快一些。

接下来是怎么把时序和截面组合起来。

这里用了EM算法,看到最后才发现作者在附录里提了一句,这篇是参考Stroyny(2005)。
具体做法如下
首先把所有因子拆分成时序模型(TS)和截面模型(XS)两组,因子模型可以分开来写成这杨
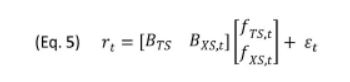
按照前面两个模型的假设,时序模型里,f已知,需要估计B,截面模型里,B已知,需要估计f。最麻烦的协方差阵D和F。因为B和F都是知道各一半,估计一半。

这里用一个贝叶斯的框架,EM算法来估计。
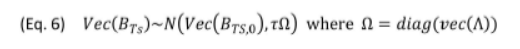
协方差阵拆成TS和XS的对角阵

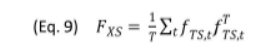

估计的标准误
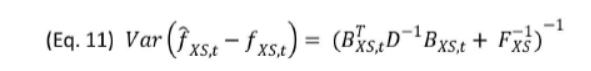
用标准误作为先验,修正协方差
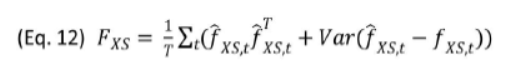
计算相应的B,D

循环到误差收敛,细节我是看晕了,不深究。
04
模型对比
最后就是模型实阵分析以及和截面模型的对比了。
首先是看是否每一个风格因子都增加了模型的解释度,报告用AIC和BIC来看,每次删一个风格因子,看指标的变化情况
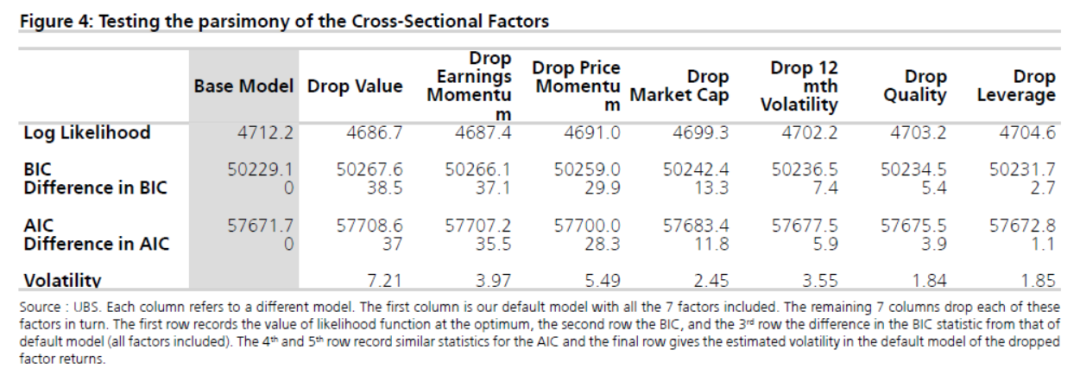
结果来看,删去任何一个因子,指标都有不同程度的上升,说明每个风格因子都是有贡献的。
混合模型和截面模型的比较,但这里的对比最终只说明混合模型和截面模型的估计结果在风格因子上高度相关,没能说明混合模型的优势。