面试题:堆和栈的区别(往往讲的是内存zha)
为什么说访问栈栈比访问堆快些?
目录
堆和栈在不同的环境下有其不同的意义,在数据结构中堆和栈是一种数据结构,对于操作系统中的堆和栈,是内存的存储空间
我们经常说的堆栈,大多数说的的相对于内存的概念而讲,而不是数据结构。当然,今天对于堆栈我们都做下详细讲解。
一、数据结构中的堆栈
1、数据结构中的堆
1)堆的定义
堆(heap)是计算机科学中一类特殊的数据结构的统称。堆通常是一个可以被看做一棵树的数组对象。堆总是满足下列性质:
-
堆中某个结点的值总是不大于或不小于其父结点的值;
-
堆总是一棵完全二叉树。
将根结点最大的堆叫做最大堆或大根堆,根结点最小的堆叫做最小堆或小根堆。常见的堆有二叉堆、斐波那契堆等。
堆是非线性数据结构,相当于一维数组,有两个直接后继,如图:
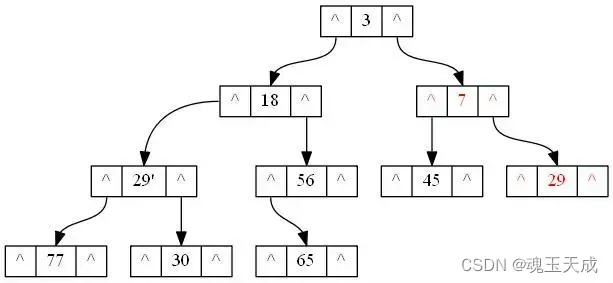
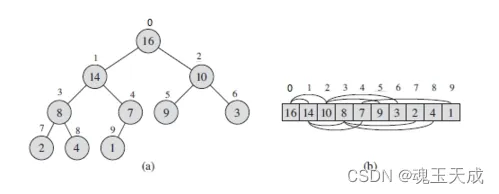
堆的定义如下:n个元素的序列{k1,k2,ki,…,kn}当且仅当满足下关系时,称之为堆。
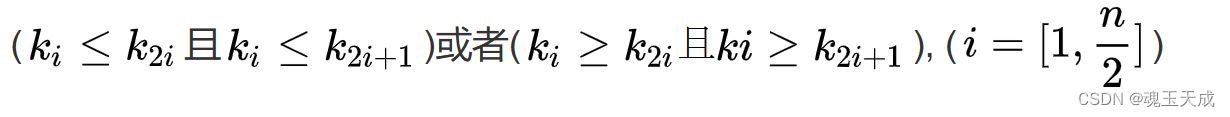

2)堆的效率

2、 数据结构中的栈
栈作为一种数据结构,是一种只能在一端进行插入和删除操作的特殊线性表。它按照后进先出的原则存储数据,先进入的数据被压入栈底,最后的数据在栈顶,需要读数据的时候从栈顶开始弹出数据(最后一个数据被第一个读出来)。栈具有记忆作用,对栈的插入与删除操作中,不需要改变栈底指针。
栈是允许在同一端进行插入和删除操作的特殊线性表。允许进行插入和删除操作的一端称为栈顶(top),另一端为栈底(bottom);栈底固定,而栈顶浮动;栈中元素个数为零时称为空栈。插入一般称为进栈(PUSH),删除则称为退栈(POP)。栈也称为先进后出表。

二、内存中的堆栈
1、内存堆的定义
堆内存是区别于栈区、全局数据区和代码区的另一个内存区域。堆允许程序在运行时动态地申请某个大小的内存空间,这个空间就是堆区

在C语言中使用malloc等内存分配函数获取内存即是从堆中分配内存。从堆中分配的内存需要程序员手动释放,如果不释放,而系统内存管理器又不自动回收这些堆内存的话(实现这一项功能的系统很少),那就一直被占用。如果一直申请堆内存,而不释放,内存会越来越少,很明显的结果是系统变慢或者申请不到新的堆内存。而过度的申请堆内存(可以试试在函数中申请一个1G的数组!),会导致堆被压爆,结果是灾难性的。
在堆内存分配时首先应该知道操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时,会遍历该链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序,另外,对于大多数系统,会在这块内存空间中的首地址处记录本次分配的大小,这样,代码中的delete语句才能正确的释放本内存空间。
另外,由于找到的堆结点的大小不一定正好等于申请的大小,系统会自动的将多余的那部分重新放入空闲链表中。堆内存是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存储的空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆内存的大小受限于计算机系统中有效的虚拟内存。由此可见,堆内存获得的空间比较灵活,也比较大。堆内存是由new分配的内存,一般速度比较慢,而且容易产生内存碎片,不过用起来最方便.另外,在WINDOWS下,最好的方式是用VirtualAlloc分配内存,它直接在进程的地址空间中保留一块内存,虽然用起来最不方便。但是速度快,也最灵活。
2、内存栈的定义
进程用户空间栈,由编译器自动分配释放,存放函数的参数值、函数内部局部变量的值所存放的空间,用于动态地存储函数之间的关系,以保证被调用函数在返回时恢复到母函数中继续执行。
栈的优势是,存取速度比堆要快,仅次于寄存器,栈数据可以共享。但缺点是,存在栈中的数据大小与生存期必须是确定的,缺乏灵活性。栈中主要存放一些基本类型的变量(,int, short, long, byte, float, double, boolean, char)和对象句柄。栈有一个很重要的特殊性,就是存在栈中的数据可以共享;系统中默认的栈的空间大小为8M。

3、栈为什么比堆的效率更高
1)栈有专门的寄存器直接对栈进行访问(esp,ebp),而对堆访问没有,只能是间接寻址。
也就是说,可以直接从地址取数据放至目标地址;使用堆时,第一步将分配的地址放到寄
存器,然后取出这个地址的值,然后放到目标地址。
2)栈中数据cpu命中率更高,满足局部性原理。
计算机中的局部性设计来源于缓存的概念,由于存储器的速度不一样,寄存器>高速缓
存存储器>主存>磁盘,为了提高系统的运行速度,会将近期使用的数据存储在高速存储器
(空间小,昂贵)中,这个就是缓存的概念,由缓存产生了系统局部性原理的设计.
硬件,操作系统都用到了局部性原理,由于高速缓冲存储器(高速缓存)小而快速的存
在,操作系统需要极大限度的利用缓存,操作系统会将近期访问过的数据以及其附近数据存
储在高速缓存中,从而提升cpu对主存的访问速度.(主存对磁盘的缓存原理一致)
3)栈是系统自动分配空间,而堆是动态查找再分配(运行时分配空间),所以栈的速度 快。
4)栈是使用的栈的数据结构,遵循先进后出的队列结构,比堆结构相对简单,分配速度优于堆。
4、内存堆与栈有什么不同
| 不同之处 | 栈 | 堆 |
| 申请方式 | 系统自动生成 | 程序自己生成 |
| 存放内容 | 存放函数的参数值、函数内部局部变量的值所存放的空间,用于动态地存储函数之间的关系 | 程序自己需要的数据内容 |
| 申请和访问速度 | 快 | 相对栈慢 |
| 内存管理的数据结构 | 栈数据结构 | 堆数据结构 |
| 存储硬件 | 高速存储器 | 内存 |
| 大小限制 | 默认8M | 与实际内存大小和编译成的程序位数决定 |
总结
对于栈和堆,该篇幅只是相对简单介绍,实际过程中,不同的系统内存栈有些许的不同。对于系统栈工作原理以及函数的完整执行过程,在后续的文章作出详细讲解。